使用 ARIMA_PLUS 单变量模型预测分层时序
本教程介绍了如何使用ARIMA_PLUS 单变量时序模型来预测分层时序。该函数可根据给定列的历史值预测该列的未来值,还可计算该列在一个或多个感兴趣维度上的汇总值。
系统会针对每个时间点,为一个或多个指定感兴趣维度的列中的每个值计算预测值。例如,如果您想预测每日交通事件,并指定了一个包含州数据的维度列,则预测数据会包含州 A 每天的值,然后是州 B 每天的值,依此类推。如果您想预测每日交通事故,并指定包含州和城市数据的维度列,则预测数据会包含州 A 和城市 A 每天的值,然后是州 A 和城市 B 每天的值,依此类推。在分层时序模型中,分层调和用于将每个子时序汇总并与其父时序进行调和。例如,州 A 中所有城市的预测值之和必须等于州 A 的预测值。
在本教程中,您可基于相同的数据创建两个时序模型,其中一个使用分层预测,另一个不使用。这样,您就可以比较这两个模型返回的结果。
本教程使用来自公开的 bigquery-public-data.iowa_liquor.sales.sales 表中的数据。此表使用公开的爱荷华州酒类销售数据,包含不同商店中超过一百万种酒类商品的信息。
在阅读本教程之前,我们强烈建议您阅读使用单变量模型预测多个时序。
所需权限
如需创建数据集,您需要拥有
bigquery.datasets.createIAM 权限。如需创建模型,您需要以下权限:
bigquery.jobs.createbigquery.models.createbigquery.models.getDatabigquery.models.updateData
如需运行推理,您需要以下权限:
bigquery.models.getDatabigquery.jobs.create
如需详细了解 BigQuery 中的 IAM 角色和权限,请参阅 IAM 简介。
目标
在本教程中,您将使用以下内容:
- 使用
CREATE MODEL语句创建多个时序模型和多个分层时序模型,以预测瓶装酒销售额。 - 使用
ML.FORECAST函数从模型中检索预测的瓶装饮料销售值。
费用
本教程使用 Google Cloud的可计费组件,包括以下组件:
- BigQuery
- BigQuery ML
如需详细了解 BigQuery 费用,请参阅 BigQuery 价格页面。
如需详细了解 BigQuery ML 费用,请参阅 BigQuery ML 价格。
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Verify that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Verify that billing is enabled for your Google Cloud project.
- 新项目会自动启用 BigQuery。如需在现有项目中激活 BigQuery,请前往
Enable the BigQuery API.
在 Google Cloud 控制台中,前往 BigQuery 页面。
在探索器窗格中,点击您的项目名称。
点击 查看操作 > 创建数据集
在 创建数据集 页面上,执行以下操作:
在数据集 ID 部分,输入
bqml_tutorial。在位置类型部分,选择多区域,然后选择 US (multiple regions in United States)(美国[美国的多个区域])。
保持其余默认设置不变,然后点击创建数据集。
创建一个名为
bqml_tutorial的数据集,并将数据位置设置为US,说明为BigQuery ML tutorial dataset:bq --location=US mk -d \ --description "BigQuery ML tutorial dataset." \ bqml_tutorial
该命令使用的不是
--dataset标志,而是-d快捷方式。如果省略-d和--dataset,该命令会默认创建一个数据集。确认已创建数据集:
bq ls在 Google Cloud 控制台中,前往 BigQuery 页面。
在查询编辑器中,粘贴以下查询,然后点击运行:
CREATE OR REPLACE MODEL `bqml_tutorial.liquor_forecast` OPTIONS ( MODEL_TYPE = 'ARIMA_PLUS', TIME_SERIES_TIMESTAMP_COL = 'date', TIME_SERIES_DATA_COL = 'total_bottles_sold', TIME_SERIES_ID_COL = ['store_number', 'zip_code', 'city', 'county'], HOLIDAY_REGION = 'US') AS SELECT store_number, zip_code, city, county, date, SUM(bottles_sold) AS total_bottles_sold FROM `bigquery-public-data.iowa_liquor_sales.sales` WHERE date BETWEEN DATE('2015-01-01') AND DATE('2015-12-31') AND county IN ('POLK', 'LINN', 'SCOTT') GROUP BY store_number, date, city, zip_code, county;
查询大约需要 37 秒才能完成,之后
liquor_forecast模型会显示在探索器窗格中。由于查询使用CREATE MODEL语句来创建模型,因此没有查询结果。在 Google Cloud 控制台中,前往 BigQuery 页面。
在查询编辑器中,粘贴以下查询,然后点击运行:
SELECT * FROM ML.FORECAST( MODEL `bqml_tutorial.liquor_forecast`, STRUCT(20 AS horizon, 0.8 AS confidence_level)) ORDER BY store_number, county, city, zip_code, forecast_timestamp;
结果应如下所示:
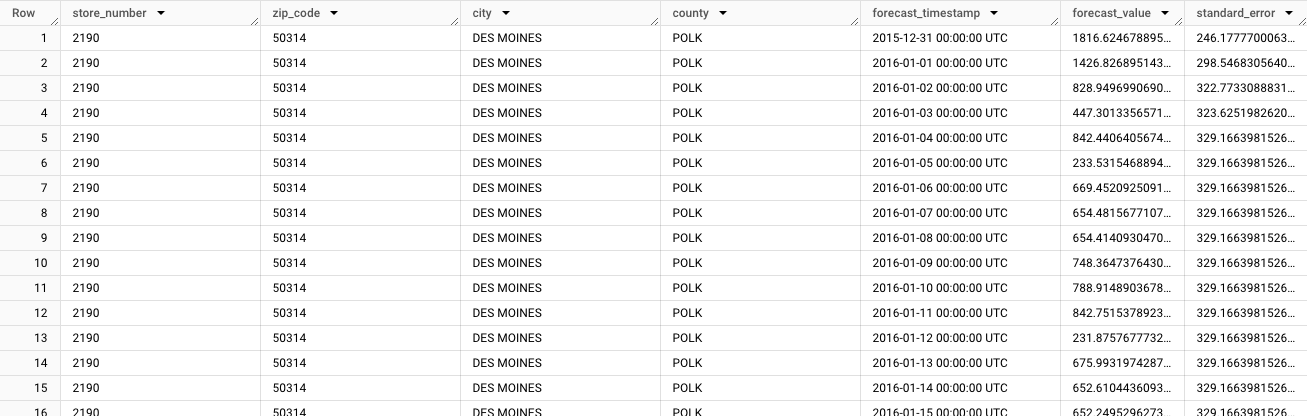
输出以第一个时序的预测数据开头:
store_number=2190、zip_code=50314、city=DES MOINES、county=POLK。当您滚动浏览数据时,会看到每个后续唯一时序的预测。若要生成汇总不同维度总数的预测(例如特定县/郡的预测),您必须生成分层预测。在 Google Cloud 控制台中,前往 BigQuery 页面。
在查询编辑器中,粘贴以下查询,然后点击运行:
CREATE OR REPLACE MODEL `bqml_tutorial.liquor_forecast_hierarchical` OPTIONS ( MODEL_TYPE = 'ARIMA_PLUS', TIME_SERIES_TIMESTAMP_COL = 'date', TIME_SERIES_DATA_COL = 'total_bottles_sold', TIME_SERIES_ID_COL = ['store_number', 'zip_code', 'city', 'county'], HIERARCHICAL_TIME_SERIES_COLS = ['zip_code', 'store_number'], HOLIDAY_REGION = 'US') AS SELECT store_number, zip_code, city, county, date, SUM(bottles_sold) AS total_bottles_sold FROM `bigquery-public-data.iowa_liquor_sales.sales` WHERE date BETWEEN DATE('2015-01-01') AND DATE('2015-12-31') AND county IN ('POLK', 'LINN', 'SCOTT') GROUP BY store_number, date, city, zip_code, county;
查询大约需要 45 秒才能完成,之后
bqml_tutorial.liquor_forecast_hierarchical模型会显示在探索器窗格中。由于查询使用CREATE MODEL语句来创建模型,因此没有查询结果。在 Google Cloud 控制台中,前往 BigQuery 页面。
在查询编辑器中,粘贴以下查询,然后点击运行:
SELECT * FROM ML.FORECAST( MODEL `bqml_tutorial.liquor_forecast_hierarchical`, STRUCT(30 AS horizon, 0.8 AS confidence_level)) WHERE city = 'LECLAIRE' ORDER BY county, city, zip_code, store_number, forecast_timestamp;
结果应如下所示:
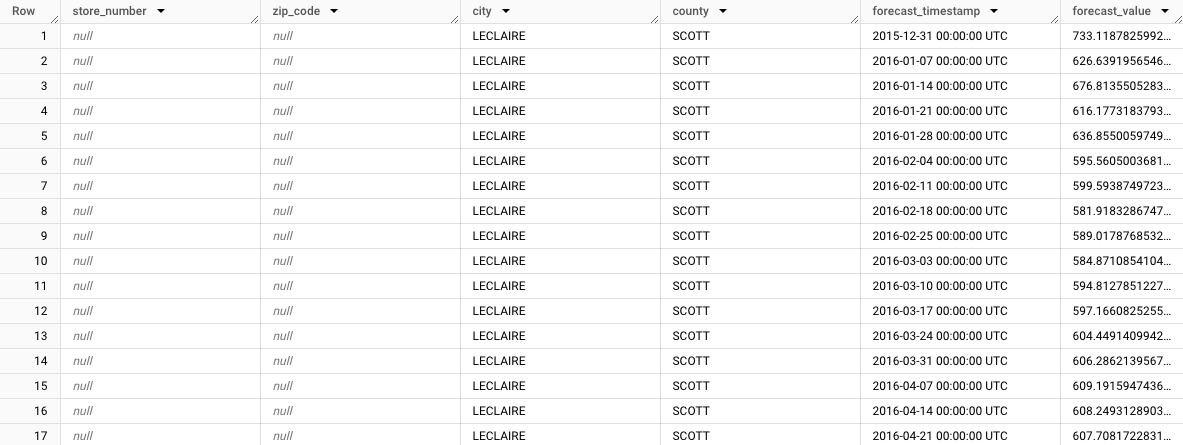
请注意 LeClaire 市(
store_number=NULL、zip_code=NULL、city=LECLAIRE、county=SCOTT)的汇总预测结果的显示方式。查看其余行时,请注意其他子群组的预测数据。例如,下图显示了邮政编码52753、store_number=NULL、zip_code=52753、city=LECLAIRE、county=SCOTT的汇总天气预报: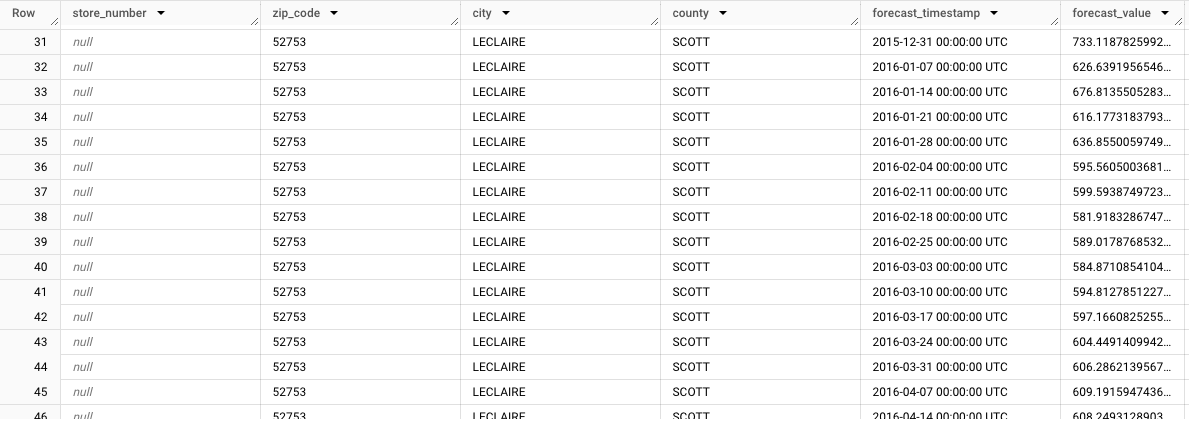
- 您可以删除自己创建的项目。
- 或者,保留项目但删除数据集。
如有必要,请在Google Cloud 控制台中打开 BigQuery 页面。
在导航窗格中,点击您创建的 bqml_tutorial 数据集。
点击窗口右侧的删除数据集。此操作会删除相关数据集、表和所有数据。
在删除数据集对话框中,通过输入数据集的名称 (
bqml_tutorial) 来确认该删除命令,然后点击删除。- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
- 了解如何使用单变量模型预测单个时序
- 了解如何使用单变量模型预测多个时序
- 了解如何在预测多行中的多个时序时扩展单变量模型。
- 了解如何使用多变量模型预测单个时序
- 如需大致了解 BigQuery ML,请参阅 BigQuery 中的 AI 和机器学习简介。
创建数据集
创建 BigQuery 数据集以存储机器学习模型。
控制台
bq
如需创建新数据集,请使用带有 --location 标志的 bq mk 命令。 如需查看完整的潜在参数列表,请参阅 bq mk --dataset 命令参考文档。
API
使用已定义的数据集资源调用 datasets.insert 方法。
{ "datasetReference": { "datasetId": "bqml_tutorial" } }
BigQuery DataFrame
在尝试此示例之前,请按照《BigQuery 快速入门:使用 BigQuery DataFrames》中的 BigQuery DataFrames 设置说明进行操作。如需了解详情,请参阅 BigQuery DataFrames 参考文档。
如需向 BigQuery 进行身份验证,请设置应用默认凭证。如需了解详情,请参阅为本地开发环境设置 ADC。
创建时序模型
使用爱荷华州酒类销售数据创建一个时序模型。
以下 GoogleSQL 查询会创建一个模型,用于预测 2015 年波尔克县、林恩县和斯科特县的每日销售瓶数。
在以下查询中,OPTIONS(model_type='ARIMA_PLUS', time_series_timestamp_col='date', ...) 子句指示您正在创建一个基于 ARIMA 的时序模型。您可以使用 CREATE MODEL 语句的 TIME_SERIES_ID 选项来指定输入数据中要获取预测结果的一个或多个列。CREATE MODEL 语句的 auto_arima_max_order 选项可控制 auto.ARIMA 算法中超参数调节的搜索空间。CREATE MODEL 语句的 decompose_time_series 选项默认为 TRUE,以便在您在下一步中评估模型时返回有关时序数据的信息。
OPTIONS(model_type='ARIMA_PLUS', time_series_timestamp_col='date', ...) 子句指示您正在创建一个基于 ARIMA 的时序模型。默认情况下,auto_arima=TRUE,因此 auto.ARIMA 算法会自动调整 ARIMA_PLUS 模型中的超参数。该算法会拟合数十个候选模型,并选择具有最低 Akaike 信息准则 (AIC) 的最佳模型。如果时序中存在美国节假日模式,则将 holiday_region 选项设置为 US 可以对这些美国节假日时间点进行更准确的建模。
请按照以下步骤创建模型:
使用模型预测数据
使用 ML.FORECAST 函数预测未来的时序值。
在以下查询中,STRUCT(20 AS horizon, 0.8 AS confidence_level) 子句指示查询会预测 20 个未来的时间点,并生成置信度为 80% 的预测区间。
请按照以下步骤使用模型预测数据:
创建分层时序模型
使用爱荷华州酒类销售数据创建分层时序预测。
以下 GoogleSQL 查询会创建一个模型,用于生成分层预测,对 2015 年波尔克县、林恩县和斯科特县销售的酒瓶总数进行分层预测。
在以下查询中,CREATE MODEL 语句中的 HIERARCHICAL_TIME_SERIES_COLS 选项表示您正在根据指定的一组列创建分层预测。每一列都会进行汇总。例如,在上一个查询中,这意味着将 store_number 列值汇总在一起,以显示每个 county、city 和 zip_code 值的预测。系统还会将 zip_code 和 store_number 值分别汇总,以显示每个 county 和 city 值的预测数据。列顺序很重要,因为它定义了层次结构的结构。
请按照以下步骤创建模型:
使用分层模型预测数据
使用 ML.FORECAST 函数从模型中检索分层预测数据。
请按照以下步骤使用模型预测数据:
清理
为避免因本教程中使用的资源导致您的 Google Cloud 账号产生费用,请删除包含这些资源的项目,或者保留该项目但删除各个资源。
删除数据集
删除项目也将删除项目中的所有数据集和所有表。如果您希望重复使用该项目,则可以删除在本教程中创建的数据集:
删除项目
如需删除项目,请执行以下操作: