In questo tutorial imparerai ad accelerare in modo significativo l'addestramento di un insieme di modelli di serie temporali per eseguire più previsioni delle serie temporali con una singola query. Imparerai anche a valutare l'accuratezza delle previsioni.
Questo tutorial ti insegna ad accelerare in modo significativo l'addestramento di un modello di serie temporali univariate per la previsione.
Questo tutorial prevede più serie temporali. I valori previsti vengono calcolati per ogni punto temporale, per ogni valore in una o più colonne specificate. Ad esempio, se volessi prevedere il meteo e hai specificato una colonna contenente i dati della città, i dati previsti conterranno le previsioni per tutti i punti in cui è presente la città A, poi i valori previsti per tutti i punti in cui è presente la città B e così via.
Questo tutorial utilizza i dati delle tabelle pubbliche
bigquery-public-data.new_york.citibike_trips
e
iowa_liquor_sales.sales. I dati sui percorsi in bicicletta contengono solo alcune centinaia di serie temporali, pertanto vengono utilizzati per illustrare varie strategie per accelerare l'addestramento del modello.
I dati sulle vendite di liquori contengono più di 1 milione di serie temporali, pertanto vengono utilizzati per mostrare
le previsioni delle serie temporali su larga scala.
Prima di leggere questo tutorial, ti consigliamo di leggere Prevedere più serie temporali con un modello univariabile e Best practice per la previsione delle serie temporali su larga scala.
Obiettivi
In questo tutorial utilizzi quanto segue:
- Creare un modello di serie temporali utilizzando l'istruzione
CREATE MODEL. - Valutare l'accuratezza del modello utilizzando la
funzione
ML.EVALUATE. - Utilizza le opzioni
AUTO_ARIMA_MAX_ORDER,TIME_SERIES_LENGTH_FRACTION,MIN_TIME_SERIES_LENGTH, eMAX_TIME_SERIES_LENGTHdell'istruzioneCREATE MODELper ridurre in modo significativo il tempo di addestramento del modello.
Per semplicità, questo tutorial non illustra come utilizzare le funzioni
ML.FORECAST
o
ML.EXPLAIN_FORECAST
per generare le previsioni. Per scoprire come utilizzare queste funzioni, consulta
Prevedere più serie temporali con un modello univariabile.
Costi
Questo tutorial utilizza i componenti fatturabili di Google Cloud, tra cui:
- BigQuery
- BigQuery ML
Per ulteriori informazioni sui costi, consulta la pagina Prezzi di BigQuery e la pagina Prezzi di BigQuery ML.
Prima di iniziare
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
- BigQuery viene attivato automaticamente nei nuovi progetti.
Per attivare BigQuery in un progetto preesistente, vai a
Enable the BigQuery API.
Autorizzazioni richieste
- Per creare il set di dati, devi disporre dell'autorizzazione IAM
bigquery.datasets.create. Per creare la risorsa di connessione, devi disporre delle seguenti autorizzazioni:
bigquery.connections.createbigquery.connections.get
Per creare il modello, devi disporre delle seguenti autorizzazioni:
bigquery.jobs.createbigquery.models.createbigquery.models.getDatabigquery.models.updateDatabigquery.connections.delegate
Per eseguire l'inferenza, devi disporre delle seguenti autorizzazioni:
bigquery.models.getDatabigquery.jobs.create
Per saperne di più sui ruoli e sulle autorizzazioni IAM in BigQuery, consulta Introduzione a IAM.
Crea un set di dati
Crea un set di dati BigQuery per archiviare il tuo modello ML:
Nella console Google Cloud, vai alla pagina BigQuery.
Nel riquadro Explorer, fai clic sul nome del progetto.
Fai clic su Visualizza azioni > Crea set di dati.
Nella pagina Crea set di dati:
In ID set di dati, inserisci
bqml_tutorial.Per Tipo di località, seleziona Più regioni e poi Stati Uniti (più regioni negli Stati Uniti).
I set di dati pubblici sono archiviati nella
USmultiregione. Per semplicità, archivia il set di dati nella stessa posizione.Lascia invariate le restanti impostazioni predefinite e fai clic su Crea set di dati.
Crea una tabella di dati di input
L'istruzione SELECT della seguente query utilizza la
funzione EXTRACT
per estrarre le informazioni sulla data dalla colonna starttime. La query utilizza la clausola COUNT(*) per ottenere il numero totale giornaliero di corse in bicicletta di Citi Bike.
table_1 ha 679 serie temporali. La query utilizza una logica INNER JOIN aggiuntiva per selezionare tutte le serie temporali con più di 400 punti temporali, con un totale di 383 serie temporali.
Per creare la tabella di dati di input:
Nella console Google Cloud, vai alla pagina BigQuery.
Nell'editor di query, incolla la seguente query e fai clic su Esegui:
CREATE OR REPLACE TABLE `bqml_tutorial.nyc_citibike_time_series` AS WITH input_time_series AS ( SELECT start_station_name, EXTRACT(DATE FROM starttime) AS date, COUNT(*) AS num_trips FROM `bigquery-public-data.new_york.citibike_trips` GROUP BY start_station_name, date ) SELECT table_1.* FROM input_time_series AS table_1 INNER JOIN ( SELECT start_station_name, COUNT(*) AS num_points FROM input_time_series GROUP BY start_station_name) table_2 ON table_1.start_station_name = table_2.start_station_name WHERE num_points > 400;
Creare un modello per più serie temporali con parametri predefiniti
Vuoi prevedere il numero di corse in bicicletta per ogni
stazione Citi Bike, il che richiede molti modelli di serie temporali; uno per ogni
stazione Citi Bike inclusa nei dati di input. Per farlo, puoi scrivere più
CREATE MODEL
query, ma questa può essere una procedura tediosa e lunga, soprattutto se hai un numero elevato di serie temporali. In alternativa, puoi utilizzare una singola query per creare e adattare un insieme di modelli di serie temporali al fine di prevedere più serie temporali contemporaneamente.
La clausola OPTIONS(model_type='ARIMA_PLUS', time_series_timestamp_col='date', ...)
indica che stai creando un insieme di modelli ARIMA_PLUS di serie temporali basati su ARIMA. L'opzione time_series_timestamp_col specifica la colonna contenente le serie temporali, l'opzione time_series_data_col specifica la colonna per la quale eseguire la previsione e time_series_id_col specifica una o più dimensioni per le quali creare serie temporali.
In questo esempio vengono esclusi i punti temporali nella serie temporale dopo il 1° giugno 2016
in modo che questi punti temporali possano essere utilizzati per valutare la precisione della previsione
in un secondo momento utilizzando la funzione ML.EVALUATE.
Per creare il modello:
Nella console Google Cloud, vai alla pagina BigQuery.
Nell'editor di query, incolla la seguente query e fai clic su Esegui:
CREATE OR REPLACE MODEL `bqml_tutorial.nyc_citibike_arima_model_default` OPTIONS (model_type = 'ARIMA_PLUS', time_series_timestamp_col = 'date', time_series_data_col = 'num_trips', time_series_id_col = 'start_station_name' ) AS SELECT * FROM bqml_tutorial.nyc_citibike_time_series WHERE date < '2016-06-01';
La query richiede circa 15 minuti.
Valutare l'accuratezza della previsione per ogni serie temporale
Valuta l'accuratezza delle previsioni del modello utilizzando la funzione ML.EVALUATE.
Per valutare il modello:
Nella console Google Cloud, vai alla pagina BigQuery.
Nell'editor di query, incolla la seguente query e fai clic su Esegui:
SELECT * FROM ML.EVALUATE(MODEL `bqml_tutorial.nyc_citibike_arima_model_default`, TABLE `bqml_tutorial.nyc_citibike_time_series`, STRUCT(7 AS horizon, TRUE AS perform_aggregation));
Questa query riporta diverse metriche di previsione, tra cui:
I risultati dovrebbero essere simili ai seguenti:
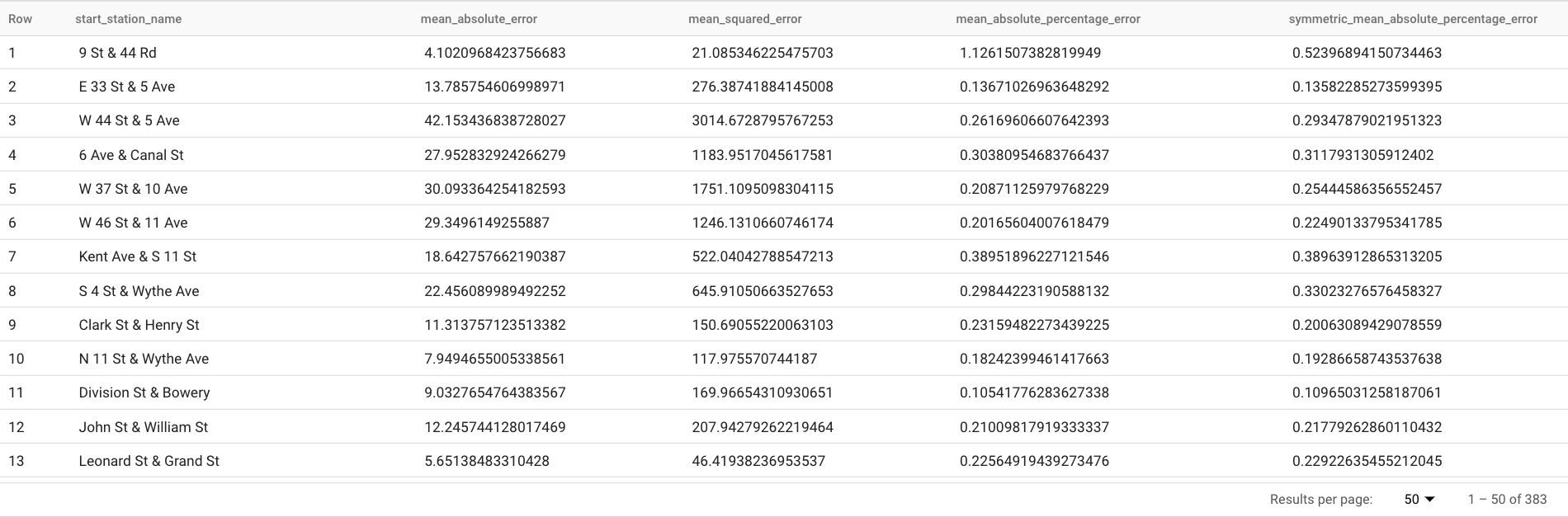
La clausola
TABLEnella funzioneML.EVALUATEidentifica una tabella contenente i dati di fatto. I risultati della previsione vengono confrontati con i dati basati su dati empirici reali per calcolare le metriche di accuratezza. In questo caso,nyc_citibike_time_seriescontiene sia i punti della serie temporale che si verificano prima sia quelli che si verificano dopo il 1° giugno 2016. I punti successivi al 1° giugno 2016 sono i dati di riferimento. I punti precedenti al 1° giugno 2016 vengono utilizzati per addestrare il modello a generare previsioni dopo questa data. Per il calcolo delle metriche sono necessari solo i punti acquisiti dopo il 1° giugno 2016. I punti precedenti al 1° giugno 2016 vengono ignorati nel calcolo delle metriche.La clausola
STRUCTnella funzioneML.EVALUATEha specificato i parametri per la funzione. Il valorehorizonè7, il che significa che la query calcola la precisione della previsione in base a una previsione di sette punti. Tieni presente che se i dati basati su dati empirici reali hanno meno di sette punti per il confronto, le metriche di accuratezza vengono calcolate solo in base ai punti disponibili. Il valoreperform_aggregationèTRUE, il che significa che le metriche di accuratezza della previsione vengono aggregate in base alle metriche in base al punto temporale. Se specifichi un valoreperform_aggregationpari aFALSE, viene restituita l'accuratezza della previsione per ogni punto temporale previsto.Per ulteriori informazioni sulle colonne di output, consulta la funzione
ML.EVALUATE.
Valutare l'accuratezza complessiva delle previsioni
Valuta l'accuratezza della previsione per tutte le 383 serie temporali.
Delle metriche di previsione restituite da ML.EVALUATE, solo
l'errore percentuale assoluto medio e l'errore percentuale assoluto medio simmetrico sono
indipendenti dal valore della serie temporale. Pertanto, per valutare l'intera accuratezza di previsione dell'insieme di serie temporali, è significativo solo l'aggregato di queste due metriche.
Per valutare il modello:
Nella console Google Cloud, vai alla pagina BigQuery.
Nell'editor di query, incolla la seguente query e fai clic su Esegui:
SELECT AVG(mean_absolute_percentage_error) AS MAPE, AVG(symmetric_mean_absolute_percentage_error) AS sMAPE FROM ML.EVALUATE(MODEL `bqml_tutorial.nyc_citibike_arima_model_default`, TABLE `bqml_tutorial.nyc_citibike_time_series`, STRUCT(7 AS horizon, TRUE AS perform_aggregation));
Questa query restituisce un valore MAPE di 0.3471 e un valore sMAPE di 0.2563.
Crea un modello per prevedere più serie temporali con uno spazio di ricerca degli iperparametri più piccolo
Nella sezione Creare un modello per più serie temporali con parametri predefiniti, hai utilizzato i valori predefiniti per tutte le opzioni di addestramento, inclusa l'opzione auto_arima_max_order. Questa opzione controlla lo spazio di ricerca per l'ottimizzazione degli iperparametri nell'algoritmo auto.ARIMA.
Nel modello creato dalla seguente query, utilizzi uno spazio di ricerca più piccolo per gli iperparametri modificando il valore dell'opzione auto_arima_max_order dal valore predefinito 5 a 2.
Per valutare il modello:
Nella console Google Cloud, vai alla pagina BigQuery.
Nell'editor di query, incolla la seguente query e fai clic su Esegui:
CREATE OR REPLACE MODEL `bqml_tutorial.nyc_citibike_arima_model_max_order_2` OPTIONS (model_type = 'ARIMA_PLUS', time_series_timestamp_col = 'date', time_series_data_col = 'num_trips', time_series_id_col = 'start_station_name', auto_arima_max_order = 2 ) AS SELECT * FROM `bqml_tutorial.nyc_citibike_time_series` WHERE date < '2016-06-01';
La query richiede circa 2 minuti. Ricorda che il completamento del modello precedente richiedeva circa 15 minuti quando il valore
auto_arima_max_orderera5, quindi questa modifica migliora la velocità di addestramento del modello di circa 7 volte. Se ti stai chiedendo perché il guadagno in termini di velocità non è5/2=2.5x, è perché quando il valore5/2=2.5xaumenta, aumenta non solo il numero di modelli candidati, ma anche la complessità.auto_arima_max_orderDi conseguenza, il tempo di addestramento del modello aumenta.
Valutare l'accuratezza della previsione per un modello con uno spazio di ricerca degli iperparametri più piccolo
Per valutare il modello:
Nella console Google Cloud, vai alla pagina BigQuery.
Nell'editor di query, incolla la seguente query e fai clic su Esegui:
SELECT AVG(mean_absolute_percentage_error) AS MAPE, AVG(symmetric_mean_absolute_percentage_error) AS sMAPE FROM ML.EVALUATE(MODEL `bqml_tutorial.nyc_citibike_arima_model_max_order_2`, TABLE `bqml_tutorial.nyc_citibike_time_series`, STRUCT(7 AS horizon, TRUE AS perform_aggregation));
Questa query restituisce un valore MAPE di 0.3337 e un valore sMAPE di 0.2337.
Nella sezione
Valutare l'accuratezza complessiva della previsione
hai valutato un modello con uno spazio di ricerca degli iperparametri più ampio,
dove il valore dell'opzione auto_arima_max_order è 5. Il risultato è stato un valore MAPE
di 0.3471 e un valore sMAPE di 0.2563. In questo caso, puoi vedere
che uno spazio di ricerca degli iperparametri più piccolo offre effettivamente una maggiore accuratezza della previsione. Uno dei motivi è che l'algoritmo auto.ARIMA esegue solo l'ottimizzazione degli iperparametri per il modulo di tendenza dell'intera pipeline di definizione del modello. Il
modello ARIMA migliore selezionato dall'algoritmo auto.ARIMA potrebbe non generare
i risultati di previsione migliori per l'intera pipeline.
Crea un modello per prevedere più serie temporali con uno spazio di ricerca degli iperparametri più piccolo e strategie di addestramento rapide e intelligenti
In questo passaggio, utilizzi sia uno spazio di ricerca degli iperparametri più piccolo sia la strategia di addestramento rapido intelligente utilizzando una o più delle opzioni di addestramento max_time_series_length,
max_time_series_length o time_series_length_fraction.
Mentre la definizione di modelli periodici, come la stagionalità, richiede un determinato numero di punti di tempo, la definizione di modelli di tendenza richiede meno punti di tempo. Nel frattempo, la creazione di modelli di tendenza è molto più dispendiosa in termini di risorse di calcolo rispetto ad altri componenti delle serie temporali, come la stagionalità. Utilizzando le opzioni di addestramento rapido riportate sopra, puoi modellare in modo efficiente il componente di tendenza con un sottoinsieme della serie temporale, mentre gli altri componenti della serie temporale utilizzano l'intera serie temporale.
L'esempio seguente utilizza l'opzione max_time_series_length per ottenere un'addestramento rapido. Se imposti il valore dell'opzione max_time_series_length su 30, per modellare il componente di tendenza vengono utilizzati solo i 30 punti in tempo più recenti. Tutte e 383
le serie temporali vengono comunque utilizzate per modellare i componenti non di tendenza.
Per creare il modello:
Nella console Google Cloud, vai alla pagina BigQuery.
Nell'editor di query, incolla la seguente query e fai clic su Esegui:
CREATE OR REPLACE MODEL `bqml_tutorial.nyc_citibike_arima_model_max_order_2_fast_training` OPTIONS (model_type = 'ARIMA_PLUS', time_series_timestamp_col = 'date', time_series_data_col = 'num_trips', time_series_id_col = 'start_station_name', auto_arima_max_order = 2, max_time_series_length = 30 ) AS SELECT * FROM `bqml_tutorial.nyc_citibike_time_series` WHERE date < '2016-06-01';
Il completamento della query richiede circa 35 secondi. È 3 volte più veloce rispetto alla query utilizzata nella sezione Creare un modello per prevedere più serie temporali con uno spazio di ricerca degli iperparametri più piccolo. A causa dell'overhead costante per la parte della query non di addestramento, ad esempio la preelaborazione dei dati, il guadagno in termini di velocità è molto più elevato quando il numero di serie temporali è molto più elevato rispetto a questo esempio. Per un milione di serie temporali, il guadagno in termini di velocità si avvicina al rapporto tra la lunghezza della serie temporale e il valore dell'opzione
max_time_series_length. In questo caso, la velocità aumenta più di 10 volte.
Valutare l'accuratezza della previsione per un modello con uno spazio di ricerca degli iperparametri più piccolo e strategie di addestramento rapide e intelligenti
Per valutare il modello:
Nella console Google Cloud, vai alla pagina BigQuery.
Nell'editor di query, incolla la seguente query e fai clic su Esegui:
SELECT AVG(mean_absolute_percentage_error) AS MAPE, AVG(symmetric_mean_absolute_percentage_error) AS sMAPE FROM ML.EVALUATE(MODEL `bqml_tutorial.nyc_citibike_arima_model_max_order_2_fast_training`, TABLE `bqml_tutorial.nyc_citibike_time_series`, STRUCT(7 AS horizon, TRUE AS perform_aggregation));
Questa query restituisce un valore MAPE di 0.3515 e un valore sMAPE di 0.2473.
Ricorda che, senza l'utilizzo di strategie di addestramento rapide, l'accuratezza della previsione genera un valore MAPE pari a 0.3337 e un valore sMAPE pari a 0.2337.
La differenza tra i due set di valori delle metriche rientra nel 3%, valore statisticamente non significativo.
In breve, hai utilizzato uno spazio di ricerca degli iperparametri più piccolo e strategie di addestramento rapide e intelligenti per accelerare l'addestramento del modello più di 20 volte senza sacrificare l'accuratezza della previsione. Come accennato in precedenza, con un maggior numero di serie temporali,
l'aumento della velocità delle strategie di addestramento rapido intelligenti può essere molto più elevato. Inoltre, la libreria ARIMA di base utilizzata dai modelli ARIMA_PLUS è stata ottimizzata per funzionare 5 volte più velocemente di prima. Insieme, questi vantaggi consentono di fare previsioni su milioni di serie temporali in poche ore.
Creare un modello per prevedere un milione di serie temporali
In questo passaggio, prevedi le vendite di alcolici per oltre 1 milione di prodotti in diversi negozi utilizzando i dati pubblici sulle vendite di alcolici dell'Iowa. L'addestramento del modello utilizza un piccolo spazio di ricerca degli iperparametri e la strategia di addestramento rapido intelligente.
Per valutare il modello:
Nella console Google Cloud, vai alla pagina BigQuery.
Nell'editor di query, incolla la seguente query e fai clic su Esegui:
CREATE OR REPLACE MODEL `bqml_tutorial.liquor_forecast_by_product` OPTIONS( MODEL_TYPE = 'ARIMA_PLUS', TIME_SERIES_TIMESTAMP_COL = 'date', TIME_SERIES_DATA_COL = 'total_bottles_sold', TIME_SERIES_ID_COL = ['store_number', 'item_description'], HOLIDAY_REGION = 'US', AUTO_ARIMA_MAX_ORDER = 2, MAX_TIME_SERIES_LENGTH = 30 ) AS SELECT store_number, item_description, date, SUM(bottles_sold) as total_bottles_sold FROM `bigquery-public-data.iowa_liquor_sales.sales` WHERE date BETWEEN DATE("2015-01-01") AND DATE("2021-12-31") GROUP BY store_number, item_description, date;
Il completamento della query richiede circa 1 ora e 16 minuti.
Esegui la pulizia
Per evitare che al tuo account Google Cloud vengano addebitati costi relativi alle risorse utilizzate in questo tutorial, elimina il progetto che contiene le risorse oppure mantieni il progetto ed elimina le singole risorse.
- Puoi eliminare il progetto che hai creato.
- In alternativa, puoi conservare il progetto ed eliminare il set di dati.
Eliminare il set di dati
L'eliminazione del progetto rimuove tutti i set di dati e tutte le tabelle nel progetto. Se preferisci riutilizzare il progetto, puoi eliminare il set di dati creato in questo tutorial:
Se necessario, apri la pagina BigQuery nella console Google Cloud.
Nella barra di navigazione, fai clic sul set di dati bqml_tutorial che hai creato.
Fai clic su Elimina set di dati per eliminare il set di dati, la tabella e tutti i dati.
Nella finestra di dialogo Elimina set di dati, conferma il comando di eliminazione digitando il nome del set di dati (
bqml_tutorial) e poi fai clic su Elimina.
Elimina il progetto
Per eliminare il progetto:
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Passaggi successivi
- Scopri come prevedere una singola serie temporale con un modello univariabile
- Scopri come prevedere una singola serie temporale con un modello multivariabile
- Scopri come prevedere più serie temporali con un modello univariato
- Scopri come prevedere in modo gerarchico più serie temporali con un modello univariabile
- Per una panoramica di BigQuery ML, consulta Introduzione all'AI e all'apprendimento automatico in BigQuery.