In dieser Anleitung erfahren Sie, wie Sie das Training einer Reihe von univariaten Zeitachsenmodellen für ARIMA_PLUS erheblich beschleunigen können, um mehrere Zeitachsenprognosen mit einer einzigen Abfrage durchzuführen. Außerdem erfahren Sie, wie Sie die Prognosegenauigkeit bewerten.
In dieser Anleitung werden Prognosen für mehrere Zeitreihen erstellt. Die prognostizierten Werte werden für jeden Zeitpunkt und für jeden Wert in einer oder mehreren angegebenen Spalten berechnet. Wenn Sie beispielsweise das Wetter vorhersagen möchten und eine Spalte mit Stadtinformationen angeben, enthalten die prognostizierten Daten Vorhersagen für alle Zeitpunkte für Stadt A, dann prognostizierte Werte für alle Zeitpunkte für Stadt B usw.
In dieser Anleitung werden Daten aus den öffentlichen Tabellen bigquery-public-data.new_york.citibike_trips und iowa_liquor_sales.sales verwendet. Die Daten zu Fahrradtouren enthalten nur einige hundert Zeitreihen. Sie werden verwendet, um verschiedene Strategien zur Beschleunigung des Modelltrainings zu veranschaulichen.
Die Verkaufsdaten für Spirituosen enthalten mehr als eine Million Zeitreihen. Sie werden verwendet, um Zeitreihenprognosen im großen Maßstab zu demonstrieren.
Bevor Sie diese Anleitung lesen, sollten Sie Prognosen für mehrere Zeitachsen mit einem univariaten Modell erstellen und Best Practices für umfangreiche Zeitachsenprognosen lesen.
Ziele
In dieser Anleitung verwenden Sie Folgendes:
- Erstellen eines Zeitreihenmodells mit der Anweisung
CREATE MODEL. - Bewerten der Modellgenauigkeit mit der Funktion
ML.EVALUATE. - Mit den Optionen
AUTO_ARIMA_MAX_ORDER,TIME_SERIES_LENGTH_FRACTION,MIN_TIME_SERIES_LENGTHundMAX_TIME_SERIES_LENGTHderCREATE MODEL-Anweisung lässt sich die Modelltrainingszeit deutlich reduzieren.
Der Einfachheit halber wird in dieser Anleitung nicht behandelt, wie Sie mit den Funktionen ML.FORECAST oder ML.EXPLAIN_FORECAST Prognosen erstellen. Weitere Informationen zur Verwendung dieser Funktionen finden Sie unter Prognosen für mehrere Zeitachsen mit einem univariaten Modell erstellen.
Kosten
In dieser Anleitung werden kostenpflichtige Komponenten von Google Cloudverwendet, darunter:
- BigQuery
- BigQuery ML
Weitere Informationen zu Kosten finden Sie auf den Seiten BigQuery-Preise und Preise für BigQuery ML.
Hinweise
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
- BigQuery ist in neuen Projekten automatisch aktiviert.
So aktivieren Sie BigQuery in einem vorhandenen Projekt:
Enable the BigQuery API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. Sie benötigen die IAM-Berechtigung
bigquery.datasets.create, um das Dataset zu erstellen.Zum Erstellen des Modells benötigen Sie die folgenden Berechtigungen:
bigquery.jobs.createbigquery.models.createbigquery.models.getDatabigquery.models.updateData
Zum Ausführen von Inferenzen benötigen Sie die folgenden Berechtigungen:
bigquery.models.getDatabigquery.jobs.create
Erforderliche Berechtigungen
Weitere Informationen zu IAM-Rollen und Berechtigungen in BigQuery finden Sie unter Einführung in IAM.
Dataset erstellen
Erstellen Sie ein BigQuery-Dataset zum Speichern Ihres ML-Modells.
Konsole
Öffnen Sie in der Google Cloud Console die Seite BigQuery.
Klicken Sie im Bereich Explorer auf den Namen Ihres Projekts.
Klicken Sie auf Aktionen ansehen > Dataset erstellen.
Führen Sie auf der Seite Dataset erstellen die folgenden Schritte aus:
Geben Sie unter Dataset-ID
bqml_tutorialein.Wählen Sie als Standorttyp die Option Mehrere Regionen und dann USA (mehrere Regionen in den USA) aus.
Übernehmen Sie die verbleibenden Standardeinstellungen unverändert und klicken Sie auf Dataset erstellen.
bq
Wenn Sie ein neues Dataset erstellen möchten, verwenden Sie den Befehl bq mk mit dem Flag --location. Eine vollständige Liste der möglichen Parameter finden Sie in der bq mk --dataset-Befehlsreferenz.
Erstellen Sie ein Dataset mit dem Namen
bqml_tutorial, wobei der Datenspeicherort aufUSund die Beschreibung aufBigQuery ML tutorial datasetfestgelegt ist:bq --location=US mk -d \ --description "BigQuery ML tutorial dataset." \ bqml_tutorial
Anstelle des Flags
--datasetverwendet der Befehl die verkürzte Form-d. Wenn Sie-dund--datasetauslassen, wird standardmäßig ein Dataset erstellt.Prüfen Sie, ob das Dataset erstellt wurde:
bq ls
API
Rufen Sie die Methode datasets.insert mit einer definierten Dataset-Ressource auf.
{ "datasetReference": { "datasetId": "bqml_tutorial" } }
BigQuery DataFrames
Bevor Sie dieses Beispiel ausprobieren, folgen Sie den Schritten zur Einrichtung von BigQuery DataFrames in der BigQuery-Kurzanleitung: BigQuery DataFrames verwenden. Weitere Informationen finden Sie in der Referenzdokumentation zu BigQuery DataFrames.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter ADC für eine lokale Entwicklungsumgebung einrichten.
Tabelle mit Eingabedaten erstellen
Die SELECT-Anweisung der folgenden Abfrage verwendet die EXTRACT-Funktion, um die Datumsinformationen aus der Spalte starttime zu extrahieren. Die Abfrage verwendet die COUNT(*)-Klausel, um die Gesamtzahl der Citi Bike-Touren pro Tag abzurufen.
table_1 hat 679 Zeitachsen. Die Abfrage verwendet eine zusätzliche INNER JOIN-Logik, um alle Zeitachsen auszuwählen, die mehr als 400 Zeitpunkte haben, was insgesamt 383 Zeitachsen ergibt.
So erstellen Sie die Eingabedatentabelle:
Öffnen Sie in der Google Cloud Console die Seite BigQuery.
Fügen Sie die folgende Abfrage in den Abfrageeditor ein und klicken Sie auf Ausführen:
CREATE OR REPLACE TABLE `bqml_tutorial.nyc_citibike_time_series` AS WITH input_time_series AS ( SELECT start_station_name, EXTRACT(DATE FROM starttime) AS date, COUNT(*) AS num_trips FROM `bigquery-public-data.new_york.citibike_trips` GROUP BY start_station_name, date ) SELECT table_1.* FROM input_time_series AS table_1 INNER JOIN ( SELECT start_station_name, COUNT(*) AS num_points FROM input_time_series GROUP BY start_station_name) table_2 ON table_1.start_station_name = table_2.start_station_name WHERE num_points > 400;
Modell für mehrere Zeitachsen mit Standardparametern erstellen
Sie möchten die Anzahl der Fahrradfahrten für jede Citi Bike-Station prognostizieren. Dazu sind viele Zeitreihenmodelle erforderlich, nämlich eines für jede Citi Bike-Station, die in den Eingabedaten enthalten ist. Sie können dazu mehrere CREATE MODEL-Abfragen schreiben. Dies kann jedoch mühsam und zeitaufwendig sein, insbesondere wenn Sie sehr viele Zeitachsen haben. Stattdessen können Sie eine einzelne Abfrage verwenden, um eine Reihe von Zeitachsenmodellen zu erstellen und anzupassen, um mehrere Zeitachsen gleichzeitig vorherzusagen.
Die OPTIONS(model_type='ARIMA_PLUS', time_series_timestamp_col='date', ...)-Klausel gibt an, dass Sie eine Reihe von ARIMA-basierten Zeitachsenmodellen ARIMA_PLUS erstellen. Mit der Option time_series_timestamp_col wird die Spalte angegeben, die die Zeitreihen enthält, mit der Option time_series_data_col die Spalte, für die eine Prognose erstellt werden soll, und mit time_series_id_col eine oder mehrere Dimensionen, für die Sie Zeitreihen erstellen möchten.
In diesem Beispiel werden die Zeitpunkte in der Zeitreihe nach dem 1. Juni 2016 weggelassen , damit diese Zeitpunkte später mithilfe der Funktion ML.EVALUATE zur Auswertung der Prognosegenauigkeit verwendet werden können.
So erstellen Sie das Modell:
Öffnen Sie in der Google Cloud Console die Seite BigQuery.
Fügen Sie die folgende Abfrage in den Abfrageeditor ein und klicken Sie auf Ausführen:
CREATE OR REPLACE MODEL `bqml_tutorial.nyc_citibike_arima_model_default` OPTIONS (model_type = 'ARIMA_PLUS', time_series_timestamp_col = 'date', time_series_data_col = 'num_trips', time_series_id_col = 'start_station_name' ) AS SELECT * FROM bqml_tutorial.nyc_citibike_time_series WHERE date < '2016-06-01';
Die Abfrage dauert etwa 15 Minuten.
Prognosegenauigkeit für jede Zeitreihe bewerten
Bewerten Sie die Prognosegenauigkeit des Modells mit der Funktion ML.EVALUATE.
So bewerten Sie das Modell:
Öffnen Sie in der Google Cloud Console die Seite BigQuery.
Fügen Sie die folgende Abfrage in den Abfrageeditor ein und klicken Sie auf Ausführen:
SELECT * FROM ML.EVALUATE(MODEL `bqml_tutorial.nyc_citibike_arima_model_default`, TABLE `bqml_tutorial.nyc_citibike_time_series`, STRUCT(7 AS horizon, TRUE AS perform_aggregation));
Diese Abfrage meldet mehrere Prognosemesswerte, einschließlich:
Die Ergebnisse sollten so aussehen:
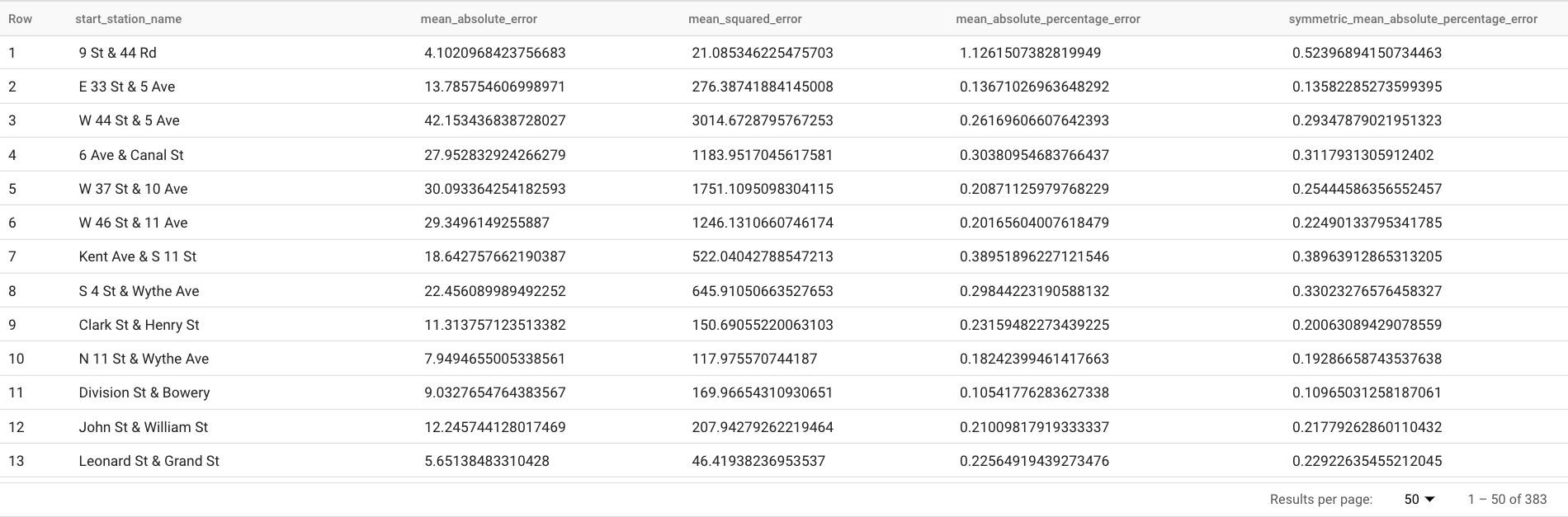
Die
TABLE-Klausel in derML.EVALUATE-Funktion gibt eine Tabelle mit den Ground-Truth-Daten an. Die Prognoseergebnisse werden mit den Ground-Truth-Daten verglichen, um Genauigkeitsmesswerte zu berechnen. In diesem Fall enthältnyc_citibike_time_seriessowohl die Zeitachsenpunkte, die vor dem 1. Juni 2016 und nach dem 1. Juni 2016 liegen. Die Punkte nach dem 1. Juni 2016 sind die Ground-Truth-Daten. Die Punkte vor dem 1. Juni 2016 werden verwendet, um das Modell so zu trainieren, dass es nach diesem Datum Prognosen erstellt. Nur die Punkte nach dem 1. Juni 2016 sind für die Berechnung der Messwerte erforderlich. Die Punkte vor dem 1. Juni 2016 werden in der Messwertberechnung ignoriert.In der
STRUCT-Klausel derML.EVALUATE-Funktion wurden Parameter für die Funktion angegeben. Der Wert fürhorizonist7. Das bedeutet, dass die Prognosegenauigkeit auf der Grundlage einer 7-Punkte-Prognose berechnet wird. Wenn die Ground-Truth-Daten für den Vergleich weniger als sieben Punkte haben, werden Genauigkeitsmesswerte nur auf Grundlage der verfügbaren Punkte berechnet. Der Wert fürperform_aggregationistTRUE. Das bedeutet, dass die Messwerte der Prognosegenauigkeit über die Messwerte auf der Basis von Zeitpunkten aggregiert werden. Wenn Sie fürperform_aggregationden WertFALSEangeben, wird die Prognosegenauigkeit für jeden prognostizierten Zeitpunkt zurückgegeben.Weitere Informationen zu den Ausgabespalten finden Sie unter
ML.EVALUATE-Funktion.
Gesamtprognosegenauigkeit bewerten
Bewerten Sie die Vorhersagegenauigkeit für alle 383 Zeitreihen.
Von den von ML.EVALUATE zurückgegebenen Prognosemetriken sind nur der mittlere absolute prozentuale Fehler und der symmetrische mittlere absolute prozentuale Fehler zeitachsenwertunabhängig. Für die Bewertung der gesamten Prognosegenauigkeit der Zeitreihe ist daher nur das Aggregat dieser beiden Messgrößen aussagekräftig.
So bewerten Sie das Modell:
Öffnen Sie in der Google Cloud Console die Seite BigQuery.
Fügen Sie die folgende Abfrage in den Abfrageeditor ein und klicken Sie auf Ausführen:
SELECT AVG(mean_absolute_percentage_error) AS MAPE, AVG(symmetric_mean_absolute_percentage_error) AS sMAPE FROM ML.EVALUATE(MODEL `bqml_tutorial.nyc_citibike_arima_model_default`, TABLE `bqml_tutorial.nyc_citibike_time_series`, STRUCT(7 AS horizon, TRUE AS perform_aggregation));
Diese Abfrage gibt einen MAPE-Wert von 0.3471 und einen sMAPE-Wert von 0.2563 zurück.
Modell erstellen, um mehrere Zeitreihen mit einem kleineren Hyperparameter-Suchbereich zu prognostizieren
Im Abschnitt Modell für mehrere Zeitreihen mit Standardparametern erstellen haben Sie die Standardwerte für alle Trainingsoptionen verwendet, einschließlich der Option auto_arima_max_order. Diese Option steuert den Suchbereich für die Hyperparameter-Abstimmung im Algorithmus auto.ARIMA.
Im Modell, das mit der folgenden Abfrage erstellt wird, verwenden Sie einen kleineren Suchbereich für die Hyperparameter. Dazu ändern Sie den Wert der Option auto_arima_max_order vom Standardwert 5 in 2.
So bewerten Sie das Modell:
Öffnen Sie in der Google Cloud Console die Seite BigQuery.
Fügen Sie die folgende Abfrage in den Abfrageeditor ein und klicken Sie auf Ausführen:
CREATE OR REPLACE MODEL `bqml_tutorial.nyc_citibike_arima_model_max_order_2` OPTIONS (model_type = 'ARIMA_PLUS', time_series_timestamp_col = 'date', time_series_data_col = 'num_trips', time_series_id_col = 'start_station_name', auto_arima_max_order = 2 ) AS SELECT * FROM `bqml_tutorial.nyc_citibike_time_series` WHERE date < '2016-06-01';
Die Abfrage dauert etwa 2 Minuten. Das vorherige Modell hat bei einem
auto_arima_max_order-Wert von5etwa 15 Minuten gedauert. Durch diese Änderung wird die Geschwindigkeit des Modelltrainings also um das Siebenfache gesteigert. Wenn Sie sich fragen, warum die Geschwindigkeitssteigerung nicht5/2=2.5xbeträgt, so liegt das daran, dass mit der Erhöhung desauto_arima_max_order-Werts nicht nur die Anzahl der Modellkandidaten, sondern auch die Komplexität zunimmt. Dadurch verlängert sich die Trainingszeit des Modells.
Prognosegenauigkeit für ein Modell mit einem kleineren Hyperparameter-Suchbereich bewerten
So bewerten Sie das Modell:
Öffnen Sie in der Google Cloud Console die Seite BigQuery.
Fügen Sie die folgende Abfrage in den Abfrageeditor ein und klicken Sie auf Ausführen:
SELECT AVG(mean_absolute_percentage_error) AS MAPE, AVG(symmetric_mean_absolute_percentage_error) AS sMAPE FROM ML.EVALUATE(MODEL `bqml_tutorial.nyc_citibike_arima_model_max_order_2`, TABLE `bqml_tutorial.nyc_citibike_time_series`, STRUCT(7 AS horizon, TRUE AS perform_aggregation));
Diese Abfrage gibt einen MAPE-Wert von 0.3337 und einen sMAPE-Wert von 0.2337 zurück.
Im Abschnitt Gesamtprognosegenauigkeit bewerten haben Sie ein Modell mit einem größeren Hyperparameter-Suchbereich ausgewertet, wobei der Optionswert auto_arima_max_order 5 ist. Daraus ergab sich ein MAPE-Wert von 0.3471 und ein sMAPE-Wert von 0.2563. In diesem Fall sehen Sie, dass ein kleinerer Hyperparameter-Suchbereich tatsächlich eine höhere Prognosegenauigkeit bietet. Ein Grund dafür ist, dass der Algorithmus auto.ARIMA nur Hyperparameter-Abstimmung für das Trendmodul der gesamten Modellierungspipeline durchführt. Das beste ARIMA-Modell, das vom Algorithmus auto.ARIMA ausgewählt wurde, generiert möglicherweise nicht die besten Prognoseergebnisse für die gesamte Pipeline.
Modell erstellen, um mehrere Zeitreihen mit einem kleineren Hyperparameter-Suchbereich und intelligenten schnellen Trainingsstrategien zu prognostizieren
In diesem Schritt verwenden Sie sowohl einen kleineren Hyperparameter-Suchbereich als auch eine intelligente schnelle Trainingsstrategie mit einer oder mehreren der Trainingsoptionen max_time_series_length, max_time_series_length oder time_series_length_fraction.
Während regelmäßige Modelle wie Saisonabhängigkeit eine bestimmte Anzahl von Zeitpunkten erfordern, erfordert die Trendmodellierung weniger Zeitpunkte. In der Zwischenzeit ist die Trendmodellierung viel rechenintensiver als andere Zeitachsenkomponenten wie Saisonabhängigkeit. Wenn Sie die obigen Trainingsoptionen verwenden, können Sie die Trendkomponente effizient mit einer Teilmenge der Zeitreihen modellieren, während die anderen Zeitreihenkomponenten die gesamte Zeitreihe verwenden.
Im folgenden Beispiel wird die Option max_time_series_length für ein schnelles Training verwendet. Wenn Sie den Wert der Option max_time_series_length auf 30 festlegen, werden nur die 30 neuesten Zeitpunkte verwendet, um die Trendkomponente zu modellieren. Alle 383 Zeitachsen werden weiterhin zur Modellierung der Nicht-Trendkomponenten verwendet.
So erstellen Sie das Modell:
Öffnen Sie in der Google Cloud Console die Seite BigQuery.
Fügen Sie die folgende Abfrage in den Abfrageeditor ein und klicken Sie auf Ausführen:
CREATE OR REPLACE MODEL `bqml_tutorial.nyc_citibike_arima_model_max_order_2_fast_training` OPTIONS (model_type = 'ARIMA_PLUS', time_series_timestamp_col = 'date', time_series_data_col = 'num_trips', time_series_id_col = 'start_station_name', auto_arima_max_order = 2, max_time_series_length = 30 ) AS SELECT * FROM `bqml_tutorial.nyc_citibike_time_series` WHERE date < '2016-06-01';
Die Abfrage dauert etwa 35 Sekunden. Das ist dreimal schneller als die Abfrage, die Sie im Abschnitt Modell zum Prognostizieren mehrerer Zeitreihen mit einem kleineren Hyperparameter-Suchbereich erstellen verwendet haben. Aufgrund des konstanten Zeitaufwands für den nicht trainingsbezogenen Teil der Abfrage, wie z. B. die Datenvorverarbeitung, ist der Geschwindigkeitsgewinn viel höher, wenn die Zahl der Zeitachsen viel größer ist als in diesem Beispiel. Bei einer Million Zeitachsen nähert sich der Geschwindigkeitsfaktor dem Verhältnis der Zeitachsenlänge und dem Wert der Option
max_time_series_length. In diesem Fall ist die Geschwindigkeitssteigerung größer als das 10-Fache.
Prognosegenauigkeit für ein Modell mit einem kleineren Hyperparameter-Suchbereich und intelligenten schnellen Trainingsstrategien bewerten
So bewerten Sie das Modell:
Öffnen Sie in der Google Cloud Console die Seite BigQuery.
Fügen Sie die folgende Abfrage in den Abfrageeditor ein und klicken Sie auf Ausführen:
SELECT AVG(mean_absolute_percentage_error) AS MAPE, AVG(symmetric_mean_absolute_percentage_error) AS sMAPE FROM ML.EVALUATE(MODEL `bqml_tutorial.nyc_citibike_arima_model_max_order_2_fast_training`, TABLE `bqml_tutorial.nyc_citibike_time_series`, STRUCT(7 AS horizon, TRUE AS perform_aggregation));
Diese Abfrage gibt einen MAPE-Wert von 0.3515 und einen sMAPE-Wert von 0.2473 zurück.
Ohne die Verwendung schneller Trainingsstrategien ergibt sich für die Prognosegenauigkeit ein MAPE-Wert von 0.3337 und ein sMAPE-Wert von 0.2337.
Die Differenz zwischen den beiden Messwerten liegt innerhalb von 3%, was statistisch unbedeutend ist.
Mit anderen Worten: Sie haben einen kleineren Hyperparameter-Suchbereich und intelligente schnelle Trainingsstrategien verwendet, um Ihr Modelltraining mehr als 20-mal schneller zu machen, ohne die Genauigkeit der Prognose zu beeinträchtigen. Wie bereits erwähnt, kann bei schnelleren Zeitachsen die Geschwindigkeit der intelligenten schnellen Trainingsstrategien erheblich höher sein. Außerdem wurde die ARIMA-Bibliothek, die ARIMA_PLUS-Modellen zugrunde liegt, so optimiert, dass sie nun 5-mal schneller ausgeführt wird als zuvor. Zusammen ermöglichen diese Ergebnisse die Prognose von Millionen von Zeitachsen innerhalb von Stunden.
Modell zum Prognostizieren von einer Million Zeitreihen erstellen
In diesem Schritt prognostizieren Sie den Alkoholabsatz für über eine Million Spirituosenprodukte in verschiedenen Geschäften anhand der öffentlichen Verkaufsdaten für Spirituosen in Iowa. Das Modelltraining verwendet einen kleinen Hyperparameter-Suchbereich sowie die intelligente schnelle Trainingsstrategie.
So bewerten Sie das Modell:
Öffnen Sie in der Google Cloud Console die Seite BigQuery.
Fügen Sie die folgende Abfrage in den Abfrageeditor ein und klicken Sie auf Ausführen:
CREATE OR REPLACE MODEL `bqml_tutorial.liquor_forecast_by_product` OPTIONS( MODEL_TYPE = 'ARIMA_PLUS', TIME_SERIES_TIMESTAMP_COL = 'date', TIME_SERIES_DATA_COL = 'total_bottles_sold', TIME_SERIES_ID_COL = ['store_number', 'item_description'], HOLIDAY_REGION = 'US', AUTO_ARIMA_MAX_ORDER = 2, MAX_TIME_SERIES_LENGTH = 30 ) AS SELECT store_number, item_description, date, SUM(bottles_sold) as total_bottles_sold FROM `bigquery-public-data.iowa_liquor_sales.sales` WHERE date BETWEEN DATE("2015-01-01") AND DATE("2021-12-31") GROUP BY store_number, item_description, date;
Die Abfrage dauert etwa 1 Stunde und 16 Minuten.
Bereinigen
Damit Ihrem Google Cloud-Konto die in dieser Anleitung verwendeten Ressourcen nicht in Rechnung gestellt werden, löschen Sie entweder das Projekt, das die Ressourcen enthält, oder Sie behalten das Projekt und löschen die einzelnen Ressourcen.
- Sie können das von Ihnen erstellte Projekt löschen.
- Sie können das Projekt aber auch behalten und das Dataset löschen.
Dataset löschen
Wenn Sie Ihr Projekt löschen, werden alle Datasets und Tabellen entfernt. Wenn Sie das Projekt wieder verwenden möchten, können Sie das in dieser Anleitung erstellte Dataset löschen:
Rufen Sie, falls erforderlich, die Seite „BigQuery“ in derGoogle Cloud Console auf.
Wählen Sie im Navigationsbereich das Dataset bqml_tutorial aus, das Sie erstellt haben.
Klicken Sie auf Dataset löschen, um das Dataset, die Tabelle und alle Daten zu löschen.
Bestätigen Sie im Dialogfeld Dataset löschen den Löschbefehl. Geben Sie dazu den Namen des Datasets (
bqml_tutorial) ein und klicken Sie auf Löschen.
Projekt löschen
So löschen Sie das Projekt:
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Nächste Schritte
- Informationen zum Prognostizieren einer einzelnen Zeitachse mit einem univariaten Modell
- Weitere Informationen zum Prognostizieren einer einzelnen Zeitachse mit einem multivariaten Modell
- Mehrere Zeitreihen mit einem univariaten Modell prognostizieren
- Hierarchische Prognosen für mehrere Zeitachsen mit einem univariaten Modell erstellen
- Eine Übersicht über BigQuery ML finden Sie unter Einführung in KI und ML in BigQuery.