Este tutorial ensina como usar um modelo de série temporal multivariada para prever o valor futuro de uma determinada coluna, com base no valor histórico de várias caraterísticas de entrada.
Este tutorial faz previsões para várias séries cronológicas. Os valores previstos são calculados para cada ponto temporal, para cada valor numa ou mais colunas especificadas. Por exemplo, se quiser prever o tempo e especificar uma coluna com dados de estado, os dados previstos vão conter previsões para todos os pontos temporais do estado A, seguidas dos valores previstos para todos os pontos temporais do estado B e assim sucessivamente. Se quisesse prever o tempo e especificasse colunas com dados de estado e cidade, os dados previstos conteriam previsões para todos os pontos temporais para o estado A e a cidade A, seguidas dos valores previstos para todos os pontos temporais para o estado A e a cidade B, e assim sucessivamente.
Este tutorial usa dados das tabelas públicas
bigquery-public-data.iowa_liquor_sales.sales
e
bigquery-public-data.covid19_weathersource_com.postal_code_day_history. A tabela bigquery-public-data.iowa_liquor_sales.sales contém dados de vendas de bebidas alcoólicas recolhidos em várias cidades no estado de Iowa. A
bigquery-public-data.covid19_weathersource_com.postal_code_day_history tabela
contém dados meteorológicos do histórico, como a temperatura e a humidade, de
todo o mundo.
Antes de ler este tutorial, recomendamos vivamente que leia o artigo Preveja uma única série cronológica com um modelo multivariável.
Crie um conjunto de dados
Crie um conjunto de dados do BigQuery para armazenar o seu modelo de ML.
Consola
Na Google Cloud consola, aceda à página BigQuery.
No painel Explorador, clique no nome do projeto.
Clique em Ver ações > Criar conjunto de dados
Na página Criar conjunto de dados, faça o seguinte:
Para o ID do conjunto de dados, introduza
bqml_tutorial.Em Tipo de localização, selecione Várias regiões e, de seguida, selecione EUA (várias regiões nos Estados Unidos).
Deixe as restantes predefinições como estão e clique em Criar conjunto de dados.
bq
Para criar um novo conjunto de dados, use o comando
bq mk
com a flag --location. Para uma lista completa de parâmetros possíveis, consulte a referência do comando bq mk --dataset.
Crie um conjunto de dados com o nome
bqml_tutorialcom a localização dos dados definida comoUSe uma descrição deBigQuery ML tutorial dataset:bq --location=US mk -d \ --description "BigQuery ML tutorial dataset." \ bqml_tutorial
Em vez de usar a flag
--dataset, o comando usa o atalho-d. Se omitir-de--dataset, o comando cria um conjunto de dados por predefinição.Confirme que o conjunto de dados foi criado:
bq ls
API
Chame o método datasets.insert
com um recurso de conjunto de dados definido.
{ "datasetReference": { "datasetId": "bqml_tutorial" } }
DataFrames do BigQuery
Antes de experimentar este exemplo, siga as instruções de configuração dos DataFrames do BigQuery no início rápido do BigQuery com os DataFrames do BigQuery. Para mais informações, consulte a documentação de referência do BigQuery DataFrames.
Para se autenticar no BigQuery, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure o ADC para um ambiente de desenvolvimento local.
Crie uma tabela de dados de entrada
Crie uma tabela de dados que possa usar para preparar e avaliar o modelo. Esta tabela combina colunas das tabelas bigquery-public-data.iowa_liquor_sales.sales e bigquery-public-data.covid19_weathersource_com.postal_code_day_history para analisar como as condições meteorológicas afetam o tipo e o número de artigos encomendados por lojas de bebidas alcoólicas. Também cria as seguintes colunas adicionais que pode usar como variáveis de entrada para o modelo:
date: a data da encomendastore_number: o número exclusivo da loja que fez a encomendaitem_number: o número exclusivo do artigo que foi encomendadobottles_sold: o número de garrafas encomendadas do artigo associadotemperature: a temperatura média na localização da loja na data da encomendahumidity: a humidade média na localização da loja na data da encomenda
Siga estes passos para criar a tabela de dados de entrada:
Na Google Cloud consola, aceda à página BigQuery.
No editor de consultas, cole a seguinte consulta e clique em Executar:
CREATE OR REPLACE TABLE `bqml_tutorial.iowa_liquor_sales_with_weather` AS WITH sales AS ( SELECT DATE, store_number, item_number, bottles_sold, SAFE_CAST(SAFE_CAST(zip_code AS FLOAT64) AS INT64) AS zip_code FROM `bigquery-public-data.iowa_liquor_sales.sales` AS sales WHERE SAFE_CAST(zip_code AS FLOAT64) IS NOT NULL ), aggregated_sales AS ( SELECT DATE, store_number, item_number, ANY_VALUE(zip_code) AS zip_code, SUM(bottles_sold) AS bottles_sold, FROM sales GROUP BY DATE, store_number, item_number ), weather AS ( SELECT DATE, SAFE_CAST(postal_code AS INT64) AS zip_code, avg_temperature_air_2m_f AS temperature, avg_humidity_specific_2m_gpkg AS humidity, FROM `bigquery-public-data.covid19_weathersource_com.postal_code_day_history` WHERE country = 'US' AND SAFE_CAST(postal_code AS INT64) IS NOT NULL ) SELECT aggregated_sales.date, aggregated_sales.store_number, aggregated_sales.item_number, aggregated_sales.bottles_sold, weather.temperature AS temperature, weather.humidity AS humidity FROM aggregated_sales LEFT JOIN weather ON aggregated_sales.zip_code=weather.zip_code AND aggregated_sales.DATE=weather.DATE;
Crie o modelo de séries cronológicas
Crie um modelo de série cronológica para prever as garrafas vendidas para cada combinação do ID da loja e do ID do artigo, para cada data na tabela bqml_tutorial.iowa_liquor_sales_with_weather antes de 1 de setembro de 2022. Use a temperatura e a humidade médias da localização da loja
em cada data como caraterísticas a avaliar durante a previsão. Existem cerca de 1 milhão de combinações distintas do número do artigo e do número da loja na tabela bqml_tutorial.iowa_liquor_sales_with_weather, o que significa que existem 1 milhão de séries cronológicas diferentes para prever.
Siga estes passos para criar o modelo:
Na Google Cloud consola, aceda à página BigQuery.
No editor de consultas, cole a seguinte consulta e clique em Executar:
CREATE OR REPLACE MODEL `bqml_tutorial.multi_time_series_arimax_model` OPTIONS( model_type = 'ARIMA_PLUS_XREG', time_series_id_col = ['store_number', 'item_number'], time_series_data_col = 'bottles_sold', time_series_timestamp_col = 'date' ) AS SELECT * FROM `bqml_tutorial.iowa_liquor_sales_with_weather` WHERE DATE < DATE('2022-09-01');
A consulta demora cerca de 38 minutos a ser concluída. Depois disso, pode aceder ao modelo
multi_time_series_arimax_model. Uma vez que a consulta usa uma declaraçãoCREATE MODELpara criar um modelo, não vê os resultados da consulta.
Use o modelo para prever dados
Preveja valores de séries cronológicas futuras através da função ML.FORECAST.
Na consulta GoogleSQL seguinte, a cláusula STRUCT(5 AS horizon, 0.8 AS confidence_level) indica que a consulta prevê 5 pontos temporais futuros e gera um intervalo de previsão com um nível de confiança de 80%.
A assinatura de dados dos dados de entrada para a função ML.FORECAST é igual à assinatura de dados dos dados de preparação que usou para criar o modelo. A coluna bottles_sold não está incluída na entrada, porque são os dados que o modelo está a tentar prever.
Siga estes passos para prever dados com o modelo:
Na Google Cloud consola, aceda à página BigQuery.
No editor de consultas, cole a seguinte consulta e clique em Executar:
SELECT * FROM ML.FORECAST ( model `bqml_tutorial.multi_time_series_arimax_model`, STRUCT (5 AS horizon, 0.8 AS confidence_level), ( SELECT * EXCEPT (bottles_sold) FROM `bqml_tutorial.iowa_liquor_sales_with_weather` WHERE DATE>=DATE('2022-09-01') ) );
Os resultados devem ter um aspeto semelhante ao seguinte:
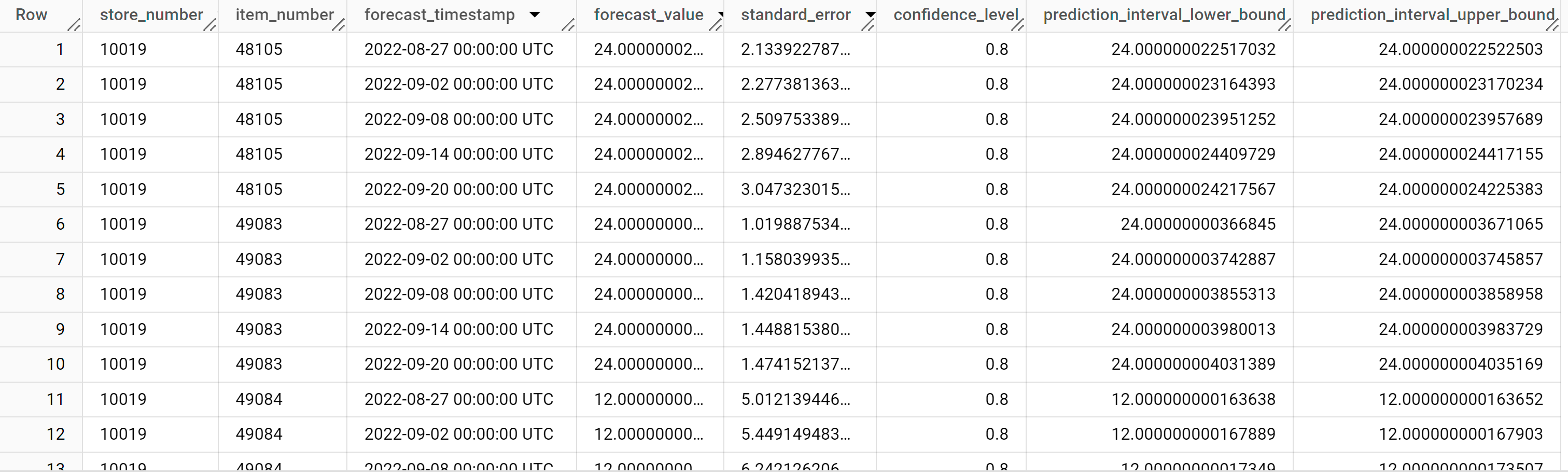
As linhas de saída estão ordenadas pelo valor
store_number, depois pelo valoritem_IDe, em seguida, por ordem cronológica pelo valor da colunaforecast_timestamp. Na previsão de séries cronológicas, o intervalo de previsão, representado pelos valores das colunasprediction_interval_lower_boundeprediction_interval_upper_bound, é tão importante quanto o valor da colunaforecast_value. O valorforecast_valueé o ponto médio do intervalo de previsão. O intervalo de previsão depende dos valores das colunasstandard_erroreconfidence_level.Para mais informações sobre as colunas de saída, consulte
ML.FORECAST.
Explicar os resultados da previsão
Pode obter métricas de explicabilidade, além dos dados de previsão, usando a função ML.EXPLAIN_FORECAST. A função ML.EXPLAIN_FORECAST prevê
valores de séries cronológicas futuras e também devolve todos os componentes separados das
séries cronológicas.
Semelhante à função ML.FORECAST, a cláusula STRUCT(5 AS horizon, 0.8 AS confidence_level) usada na função ML.EXPLAIN_FORECAST indica que a consulta prevê 30 pontos temporais futuros e gera um intervalo de previsão com 80% de confiança.
A função ML.EXPLAIN_FORECAST fornece dados do histórico e dados de previsão. Para ver apenas os dados de previsão, adicione a opção time_series_type à consulta e especifique forecast como o valor da opção.
Siga estes passos para explicar os resultados do modelo:
Na Google Cloud consola, aceda à página BigQuery.
No editor de consultas, cole a seguinte consulta e clique em Executar:
SELECT * FROM ML.EXPLAIN_FORECAST ( model `bqml_tutorial.multi_time_series_arimax_model`, STRUCT (5 AS horizon, 0.8 AS confidence_level), ( SELECT * EXCEPT (bottles_sold) FROM `bqml_tutorial.iowa_liquor_sales_with_weather` WHERE DATE >= DATE('2022-09-01') ) );
Os resultados devem ter um aspeto semelhante ao seguinte:
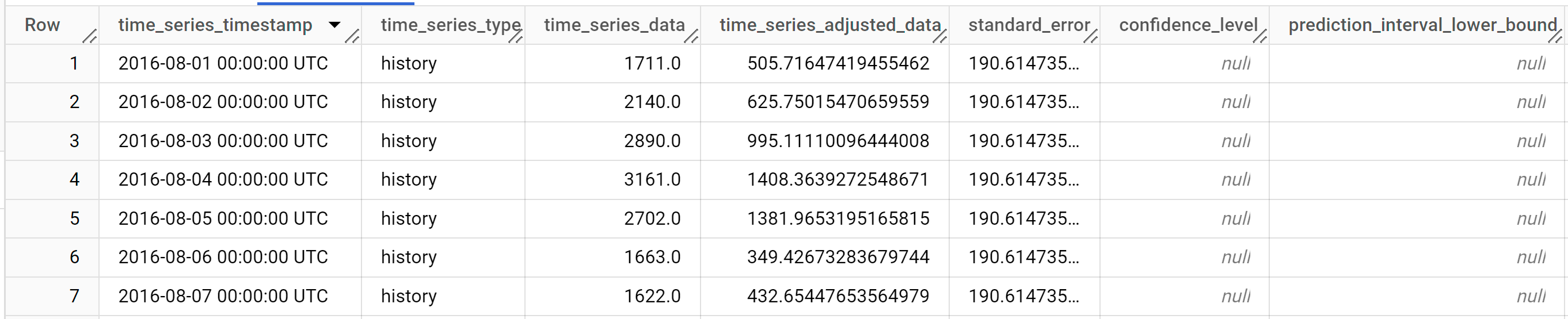
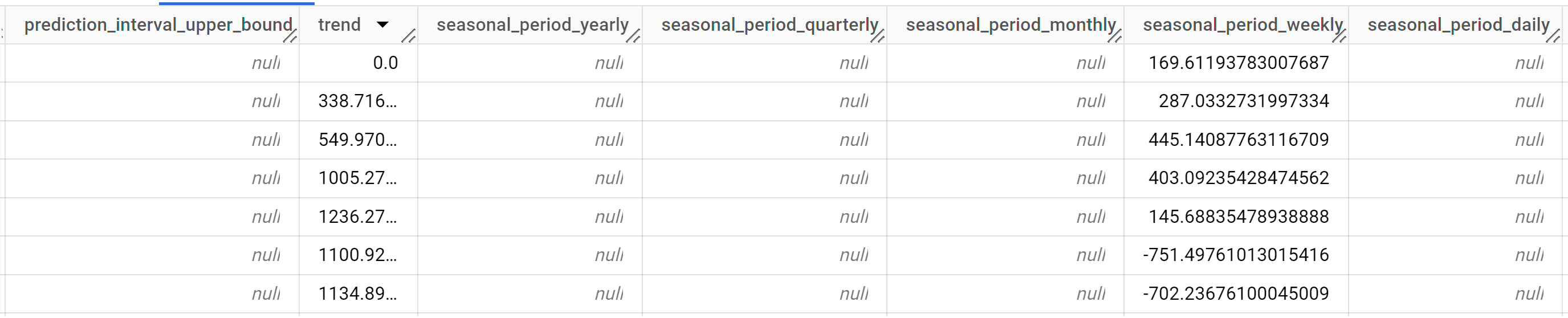
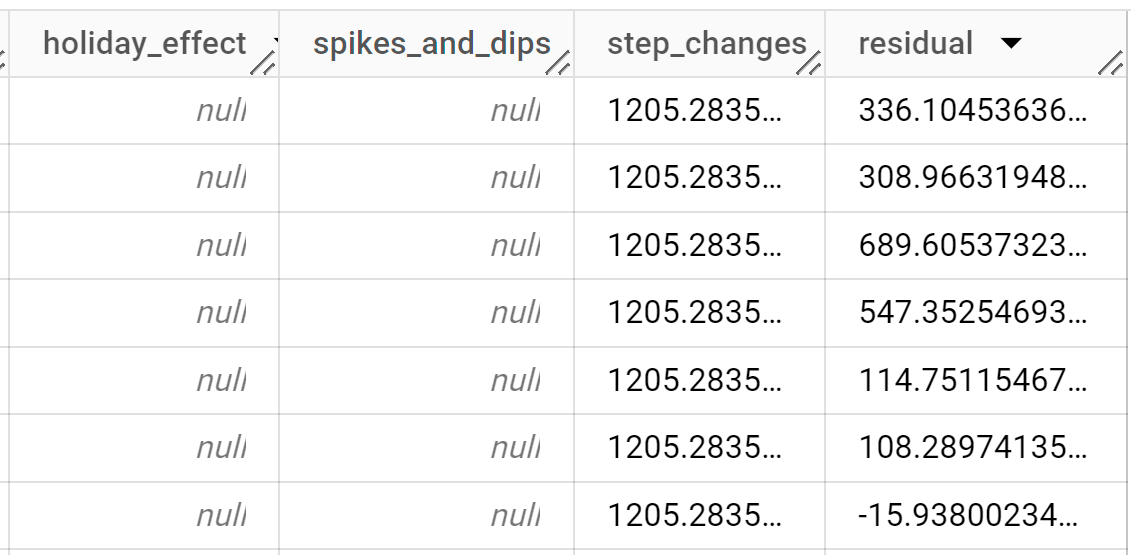
As linhas de saída são ordenadas cronologicamente pelo valor da coluna
time_series_timestamp.Para mais informações sobre as colunas de saída, consulte
ML.EXPLAIN_FORECAST.
Avalie a precisão da previsão
Avalie a precisão da previsão do modelo executando-o em dados com os quais o modelo não foi preparado. Pode fazê-lo através da função ML.EVALUATE. A função ML.EVALUATE avalia cada série cronológica de forma independente.
Na seguinte consulta GoogleSQL, a segunda declaração SELECT fornece os dados com as funcionalidades futuras, que são usados para prever os valores futuros a comparar com os dados reais.
Siga estes passos para avaliar a precisão do modelo:
Na Google Cloud consola, aceda à página BigQuery.
No editor de consultas, cole a seguinte consulta e clique em Executar:
SELECT * FROM ML.EVALUATE ( model `bqml_tutorial.multi_time_series_arimax_model`, ( SELECT * FROM `bqml_tutorial.iowa_liquor_sales_with_weather` WHERE DATE >= DATE('2022-09-01') ) );
Os resultados devem ser semelhantes aos seguintes:
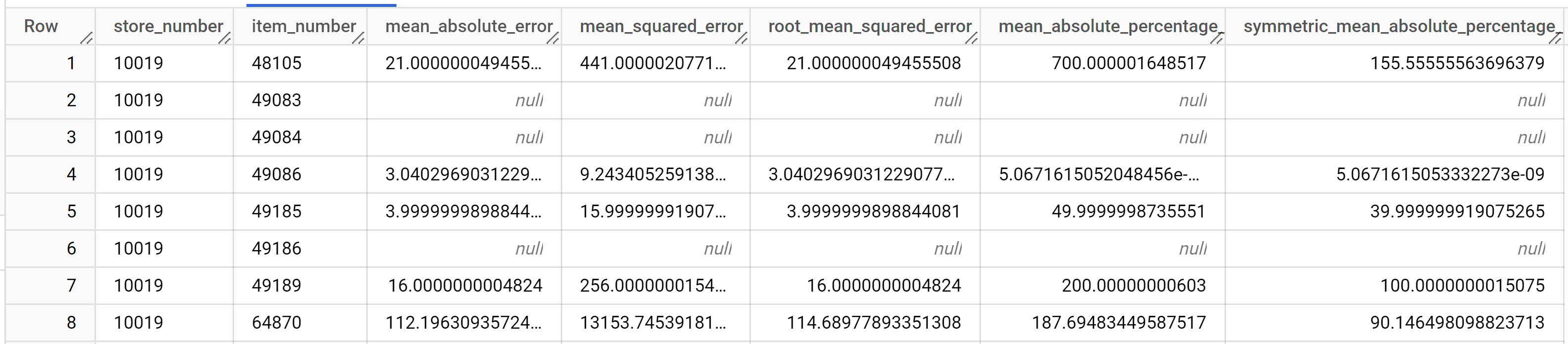
Para mais informações sobre as colunas de saída, consulte
ML.EVALUATE.
Use o modelo para detetar anomalias
Detete anomalias nos dados de preparação através da função ML.DETECT_ANOMALIES.
Na consulta seguinte, a cláusula STRUCT(0.95 AS anomaly_prob_threshold) faz com que a função ML.DETECT_ANOMALIES identifique pontos de dados anómalos com um nível de confiança de 95%.
Siga estes passos para detetar anomalias nos dados de preparação:
Na Google Cloud consola, aceda à página BigQuery.
No editor de consultas, cole a seguinte consulta e clique em Executar:
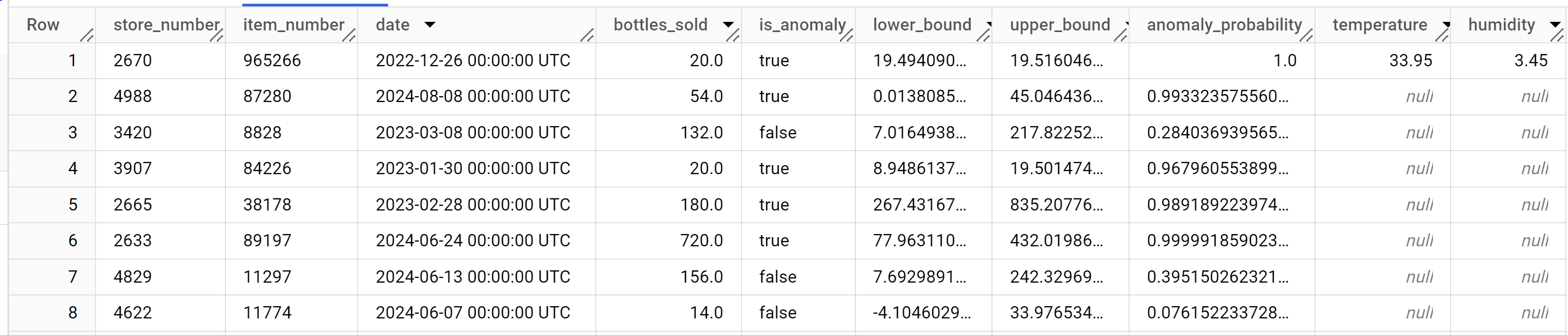
SELECT * FROM ML.DETECT_ANOMALIES ( model `bqml_tutorial.multi_time_series_arimax_model`, STRUCT (0.95 AS anomaly_prob_threshold) );
Os resultados devem ser semelhantes aos seguintes:
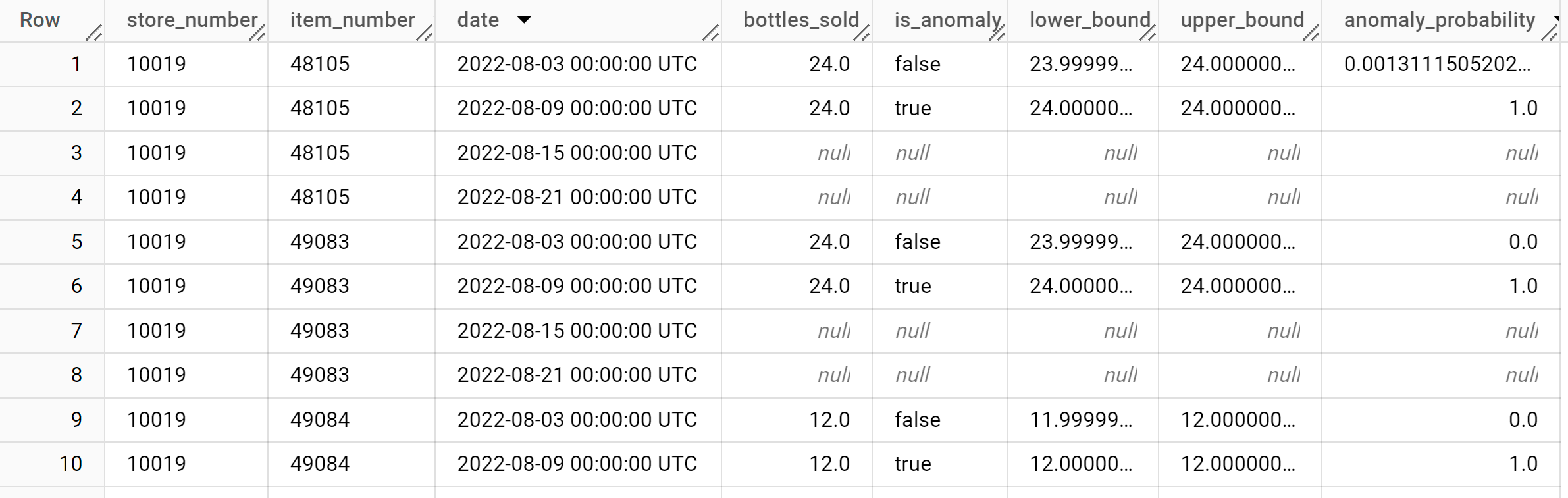
A coluna
anomaly_probabilitynos resultados identifica a probabilidade de um determinado valor da colunabottles_soldser anómalo.Para mais informações sobre as colunas de saída, consulte
ML.DETECT_ANOMALIES.
Detete anomalias em novos dados
Detete anomalias nos novos dados fornecendo dados de entrada à função ML.DETECT_ANOMALIES. Os novos dados têm de ter a mesma assinatura de dados que os dados de preparação.
Siga estes passos para detetar anomalias em novos dados:
Na Google Cloud consola, aceda à página BigQuery.
No editor de consultas, cole a seguinte consulta e clique em Executar:
SELECT * FROM ML.DETECT_ANOMALIES ( model `bqml_tutorial.multi_time_series_arimax_model`, STRUCT (0.95 AS anomaly_prob_threshold), ( SELECT * FROM `bqml_tutorial.iowa_liquor_sales_with_weather` WHERE DATE >= DATE('2022-09-01') ) );
Os resultados devem ser semelhantes aos seguintes: