이 튜토리얼에서는 다변량 시계열 모델을 사용하여 여러 입력 특성의 이전 값을 기반으로 지정된 열의 미래 값을 예측하는 방법을 설명합니다.
이 튜토리얼에서는 여러 시계열을 예측합니다. 예측 값은 하나 이상의 지정된 열에 있는 각 값에 대해 각 시점으로 계산됩니다. 예를 들어, 날씨를 예측하고 상태 데이터를 포함하는 열을 지정하려면, 예측된 데이터에 상태 A의 모든 시점에 대한 예측 값과 상태 B의 모든 시점에 대한 예측 값 등이 포함됩니다. 날씨를 예측하고 주 및 도시 데이터가 포함된 열을 지정하려는 경우 예측된 데이터에는 주 A와 도시 A의 모든 시점에 대한 예측 값, 주 A와 도시 B의 모든 시점에 대한 예측 값 등이 포함됩니다.
이 튜토리얼에서는 공개 bigquery-public-data.iowa_liquor_sales.sales 및 bigquery-public-data.covid19_weathersource_com.postal_code_day_history 테이블의 데이터를 사용합니다. bigquery-public-data.iowa_liquor_sales.sales 테이블에는 아이오와주 여러 도시에서 수집된 주류 판매 데이터가 포함되어 있습니다. bigquery-public-data.covid19_weathersource_com.postal_code_day_history 테이블에는 전 세계의 온도 및 습도와 같은 이전 날씨 데이터가 포함되어 있습니다.
이 튜토리얼을 읽기 전에 다변량 모델로 단일 시계열 예측을 읽어보는 것이 좋습니다.
목표
이 튜토리얼에서는 다음 작업을 완료하는 방법을 안내합니다.
CREATE MODEL문을 사용하여 주류 판매점 주문을 예측하는 시계열 모델을 만듭니다.ML.FORECAST함수를 사용하여 모델에서 예측된 주문 값을 검색합니다.ML.EXPLAIN_FORECAST함수를 사용하여 계절성, 트렌드, 특성 기여 분석과 같은 시계열 구성요소를 검색합니다. 이러한 시계열 구성요소를 검사하여 예측 값을 설명할 수 있습니다.ML.EVALUATE함수를 사용하여 모델의 정확성을 평가합니다.ML.DETECT_ANOMALIES함수와 함께 모델을 사용하여 이상치를 감지합니다.
비용
이 튜토리얼에서는 비용이 청구될 수 있는 다음과 같은 Google Cloud구성요소를 사용합니다.
- BigQuery
- BigQuery ML
BigQuery 비용에 대한 자세한 내용은 BigQuery 가격 책정 페이지를 참조하세요.
BigQuery ML 비용에 대한 자세한 내용은 BigQuery ML 가격 책정을 참조하세요.
시작하기 전에
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Verify that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Verify that billing is enabled for your Google Cloud project.
- BigQuery는 새 프로젝트에서 자동으로 사용 설정됩니다.
기존 프로젝트에서 BigQuery를 활성화하려면 다음으로 이동합니다.
Enable the BigQuery API.
데이터 세트 만들기
ML 모델을 저장할 BigQuery 데이터 세트를 만듭니다.
콘솔
Google Cloud 콘솔에서 BigQuery 페이지로 이동합니다.
탐색기 창에서 프로젝트 이름을 클릭합니다.
작업 보기 > 데이터 세트 만들기를 클릭합니다.
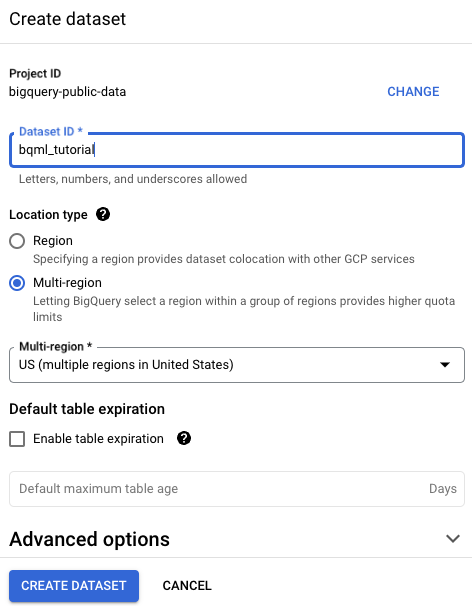
데이터 세트 만들기 페이지에서 다음을 수행합니다.
데이터 세트 ID에
bqml_tutorial를 입력합니다.위치 유형에 대해 멀티 리전을 선택한 다음 US(미국 내 여러 리전)를 선택합니다.
공개 데이터 세트는
US멀티 리전에 저장됩니다. 편의상 같은 위치에 데이터 세트를 저장합니다.- 나머지 기본 설정은 그대로 두고 데이터 세트 만들기를 클릭합니다.
bq
새 데이터 세트를 만들려면 --location 플래그와 함께 bq mk 명령어를 실행합니다. 사용할 수 있는 전체 파라미터 목록은 bq mk --dataset 명령어 참조를 확인하세요.
데이터 위치가
US로 설정되고 설명이BigQuery ML tutorial dataset인bqml_tutorial데이터 세트를 만듭니다.bq --location=US mk -d \ --description "BigQuery ML tutorial dataset." \ bqml_tutorial
--dataset플래그를 사용하는 대신 이 명령어는-d단축키를 사용합니다.-d와--dataset를 생략하면 이 명령어는 기본적으로 데이터 세트를 만듭니다.데이터 세트가 생성되었는지 확인합니다.
bq ls
API
데이터 세트 리소스가 정의된 datasets.insert 메서드를 호출합니다.
{ "datasetReference": { "datasetId": "bqml_tutorial" } }
입력 데이터 테이블 만들기
모델을 학습시키고 평가하는 데 사용할 수 있는 데이터 테이블을 만듭니다. 이 테이블은 bigquery-public-data.iowa_liquor_sales.sales 및 bigquery-public-data.covid19_weathersource_com.postal_code_day_history 테이블의 열을 결합하여 날씨가 주류 판매점에서 주문하는 상품의 유형과 수에 미치는 영향을 분석합니다. 또한 모델의 입력 변수로 사용할 수 있는 다음과 같은 추가 열을 생성합니다:
date: 주문 날짜store_number: 주문한 매장의 고유 번호item_number: 주문된 상품의 고유 번호bottles_sold: 연결된 상품의 주문된 병 수temperature: 주문 날짜의 매장 위치 평균 기온humidity: 주문 날짜의 매장 위치의 평균 습도
입력 데이터 테이블을 만들려면 다음 단계를 따르세요.
Google Cloud 콘솔에서 BigQuery 페이지로 이동합니다.
쿼리 편집기에 다음 쿼리를 붙여넣고 실행을 클릭합니다.
CREATE OR REPLACE TABLE `bqml_tutorial.iowa_liquor_sales_with_weather` AS WITH sales AS ( SELECT DATE, store_number, item_number, bottles_sold, SAFE_CAST(SAFE_CAST(zip_code AS FLOAT64) AS INT64) AS zip_code FROM `bigquery-public-data.iowa_liquor_sales.sales` AS sales WHERE SAFE_CAST(zip_code AS FLOAT64) IS NOT NULL ), aggregated_sales AS ( SELECT DATE, store_number, item_number, ANY_VALUE(zip_code) AS zip_code, SUM(bottles_sold) AS bottles_sold, FROM sales GROUP BY DATE, store_number, item_number ), weather AS ( SELECT DATE, SAFE_CAST(postal_code AS INT64) AS zip_code, avg_temperature_air_2m_f AS temperature, avg_humidity_specific_2m_gpkg AS humidity, FROM `bigquery-public-data.covid19_weathersource_com.postal_code_day_history` WHERE SAFE_CAST(postal_code AS INT64) IS NOT NULL ), avg_weather AS ( SELECT DATE, zip_code, AVG(temperature) AS temperature, AVG(humidity) AS humidity, FROM weather GROUP BY DATE, zip_code ) SELECT aggregated_sales.date, aggregated_sales.store_number, aggregated_sales.item_number, aggregated_sales.bottles_sold, avg_weather.temperature AS temperature, avg_weather.humidity AS humidity FROM aggregated_sales LEFT JOIN avg_weather ON aggregated_sales.zip_code=avg_weather.zip_code AND aggregated_sales.DATE=avg_weather.DATE;
시계열 모델 만들기
2022년 9월 1일 이전의 bqml_tutorial.iowa_liquor_sales_with_weather 테이블에 있는 각 날짜에 대해 매장 ID와 상품 ID의 각 조합에 대해 판매된 병을 예측하는 시계열 모델을 만듭니다. 예측 중에 평가할 특성으로 각 날짜의 매장 위치 평균 온도 및 습도를 사용합니다. bqml_tutorial.iowa_liquor_sales_with_weather 테이블에는 상품 번호와 매장 번호의 고유한 조합이 약 100만 개 있으며, 이는 예측할 서로 다른 시계열이 100만 개 있다는 의미입니다.
모델을 만들려면 다음 단계를 따르세요.
Google Cloud 콘솔에서 BigQuery 페이지로 이동합니다.
쿼리 편집기에 다음 쿼리를 붙여넣고 실행을 클릭합니다.
CREATE OR REPLACE MODEL `bqml_tutorial.multi_time_series_arimax_model` OPTIONS( model_type = 'ARIMA_PLUS_XREG', time_series_id_col = ['store_number', 'item_number'], time_series_data_col = 'bottles_sold', time_series_timestamp_col = 'date' ) AS SELECT * FROM `bqml_tutorial.iowa_liquor_sales_with_weather` WHERE DATE < DATE('2022-09-01');
이 쿼리는 완료하는 데 약 38분이 소요되며 이후에는
multi_time_series_arimax_model모델이 탐색기 창에 표시됩니다. 이 쿼리에서는CREATE MODEL문을 사용하여 모델을 만들므로 쿼리 결과가 표시되지 않습니다.
모델을 사용하여 데이터 예측
ML.FORECAST 함수를 사용하여 미래 시계열 값을 예측합니다.
다음 GoogleSQL 쿼리에서 STRUCT(5 AS horizon, 0.8 AS confidence_level) 절은 쿼리가 5개의 미래 시점을 예측하고 80% 신뢰 수준의 예측 구간을 생성함을 나타냅니다.
ML.FORECAST 함수에 대한 입력 데이터의 데이터 서명은 모델을 만드는 데 사용한 학습 데이터의 데이터 서명과 동일합니다. bottles_sold 열은 모델이 예측하려는 데이터이므로 입력에 포함되지 않습니다.
모델을 사용하여 데이터를 예측하려면 다음 단계를 따르세요.
Google Cloud 콘솔에서 BigQuery 페이지로 이동합니다.
쿼리 편집기에 다음 쿼리를 붙여넣고 실행을 클릭합니다.
SELECT * FROM ML.FORECAST ( model `bqml_tutorial.multi_time_series_arimax_model`, STRUCT (5 AS horizon, 0.8 AS confidence_level), ( SELECT * EXCEPT (bottles_sold) FROM `bqml_tutorial.iowa_liquor_sales_with_weather` WHERE DATE>=DATE('2022-09-01') ) );
결과는 다음과 비슷하게 표시됩니다.
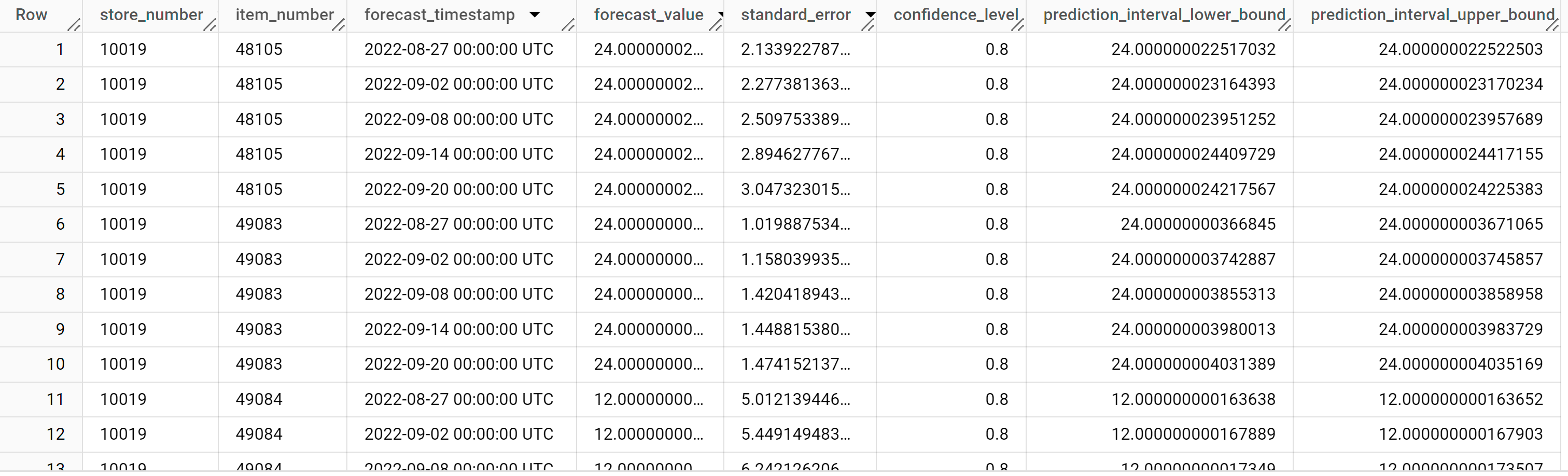
출력 행은
store_number값,item_ID값,forecast_timestamp열 값 순으로 시간순으로 정렬됩니다. 시계열 예측에서prediction_interval_lower_bound및prediction_interval_upper_bound열 값으로 표시되며 예측 구간은forecast_value열 값만큼 중요합니다.forecast_value값은 예측 구간의 중간 포인트입니다. 예측 구간은standard_error및confidence_level열 값에 따라 달라집니다.출력 열에 관한 자세한 내용은
ML.FORECAST를 참고하세요.
예측 결과 설명
ML.EXPLAIN_FORECAST 함수를 사용하여 예측 데이터 외에 설명 가능성 측정항목을 가져올 수 있습니다. ML.EXPLAIN_FORECAST 함수는 미래 시계열 값을 예측하고 시계열의 모든 개별 구성요소도 반환합니다.
ML.FORECAST 함수와 마찬가지로 ML.EXPLAIN_FORECAST 함수에 사용된 STRUCT(5 AS horizon, 0.8 AS confidence_level) 절에서 쿼리가 미래 시점 30개를 예측하고 80% 신뢰도로 예측 구간을 생성함을 나타냅니다.
ML.EXPLAIN_FORECAST 함수는 이전 데이터와 예측 데이터를 모두 제공합니다. 예측 데이터만 보려면 쿼리에 time_series_type 옵션을 추가하고 forecast를 옵션 값으로 지정합니다.
모델의 결과를 설명하려면 다음 단계를 따르세요.
Google Cloud 콘솔에서 BigQuery 페이지로 이동합니다.
쿼리 편집기에 다음 쿼리를 붙여넣고 실행을 클릭합니다.
SELECT * FROM ML.EXPLAIN_FORECAST ( model `bqml_tutorial.multi_time_series_arimax_model`, STRUCT (5 AS horizon, 0.8 AS confidence_level), ( SELECT * EXCEPT (bottles_sold) FROM `bqml_tutorial.iowa_liquor_sales_with_weather` WHERE DATE >= DATE('2022-09-01') ) );
결과는 다음과 비슷하게 표시됩니다.
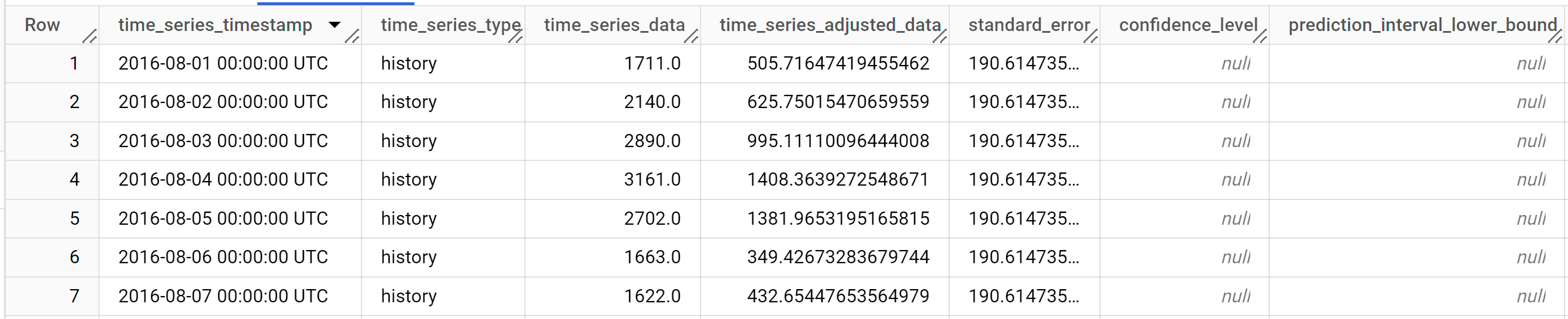
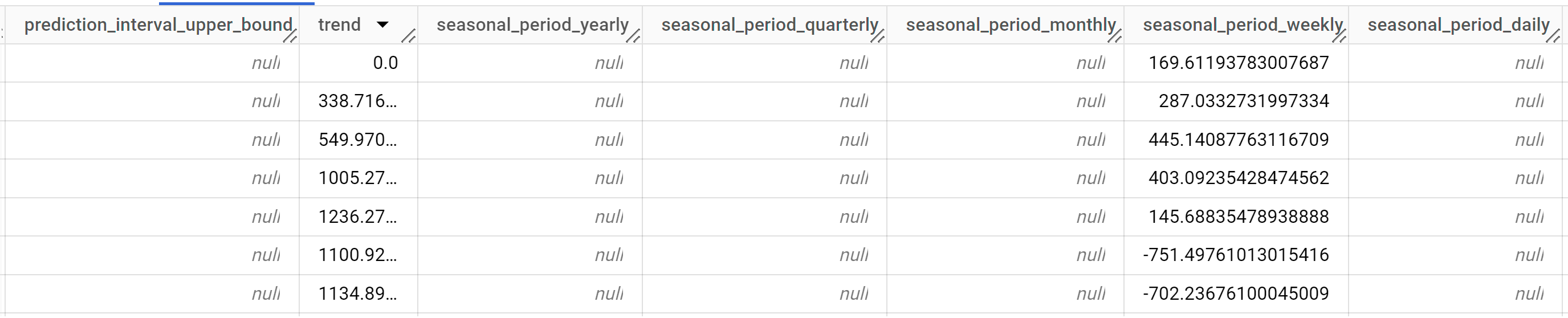
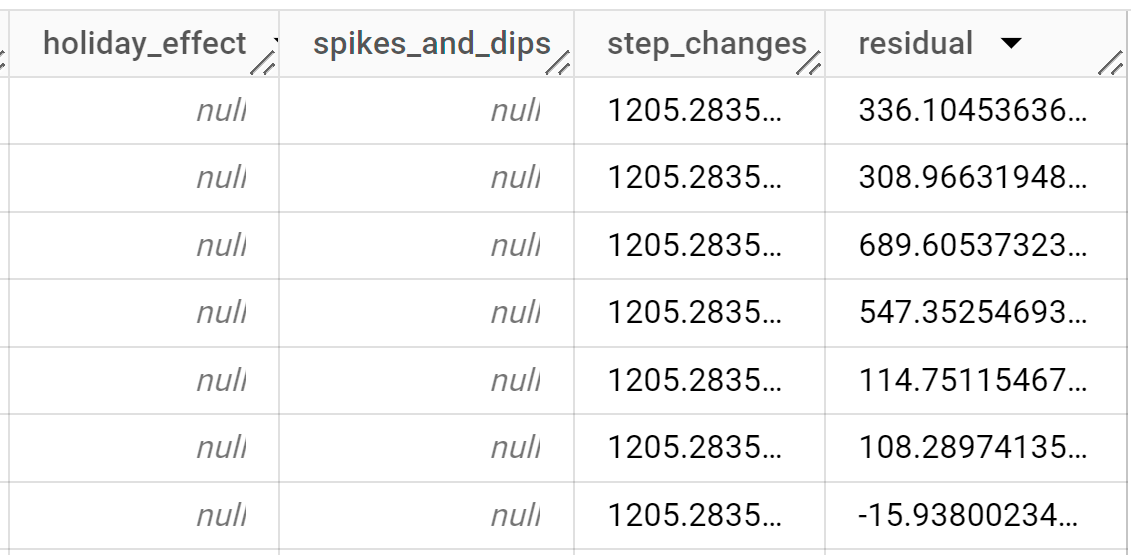
출력 행은
time_series_timestamp열 값을 기준으로 시간순으로 정렬됩니다.출력 열에 관한 자세한 내용은
ML.EXPLAIN_FORECAST를 참고하세요.
예측 정확도 평가
모델이 학습되지 않은 데이터에 대해 모델을 실행하여 모델의 예측 정확성을 평가합니다. ML.EVALUATE 함수를 사용하여 이 작업을 수행할 수 있습니다. ML.EVALUATE 함수는 각 시계열을 독립적으로 평가합니다.
다음 GoogleSQL 쿼리에서 두 번째 SELECT 문은 데이터에 미래 특징을 제공하며, 이는 실제 데이터와 비교할 미래 값을 예측하는 데 사용됩니다.
모델의 정확성을 평가하려면 다음 단계를 따르세요.
Google Cloud 콘솔에서 BigQuery 페이지로 이동합니다.
쿼리 편집기에 다음 쿼리를 붙여넣고 실행을 클릭합니다.
SELECT * FROM ML.EVALUATE ( model `bqml_tutorial.multi_time_series_arimax_model`, ( SELECT * FROM `bqml_tutorial.iowa_liquor_sales_with_weather` WHERE DATE >= DATE('2022-09-01') ) );
결과는 다음과 비슷하게 표시됩니다.
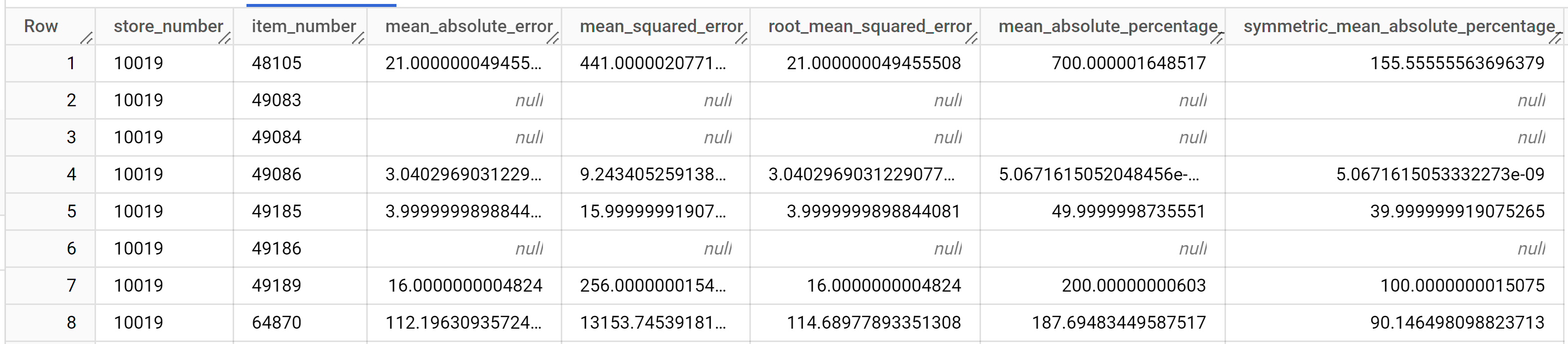
출력 열에 관한 자세한 내용은
ML.EVALUATE를 참고하세요.
모델을 사용하여 이상 감지
ML.DETECT_ANOMALIES 함수를 사용하여 학습 데이터에서 이상치를 감지합니다.
다음 쿼리에서 STRUCT(0.95 AS anomaly_prob_threshold) 절은 ML.DETECT_ANOMALIES 함수가 95% 신뢰 수준으로 비정상적인 데이터 포인트를 식별하도록 합니다.
학습 데이터에서 이상치를 감지하려면 다음 단계를 따르세요.
Google Cloud 콘솔에서 BigQuery 페이지로 이동합니다.
쿼리 편집기에 다음 쿼리를 붙여넣고 실행을 클릭합니다.
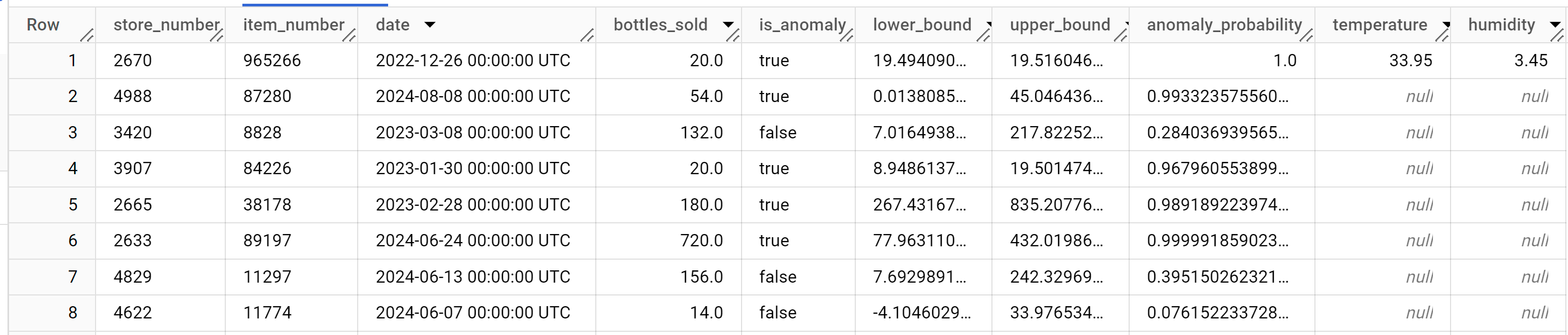
SELECT * FROM ML.DETECT_ANOMALIES ( model `bqml_tutorial.multi_time_series_arimax_model`, STRUCT (0.95 AS anomaly_prob_threshold) );
결과는 다음과 비슷하게 표시됩니다.
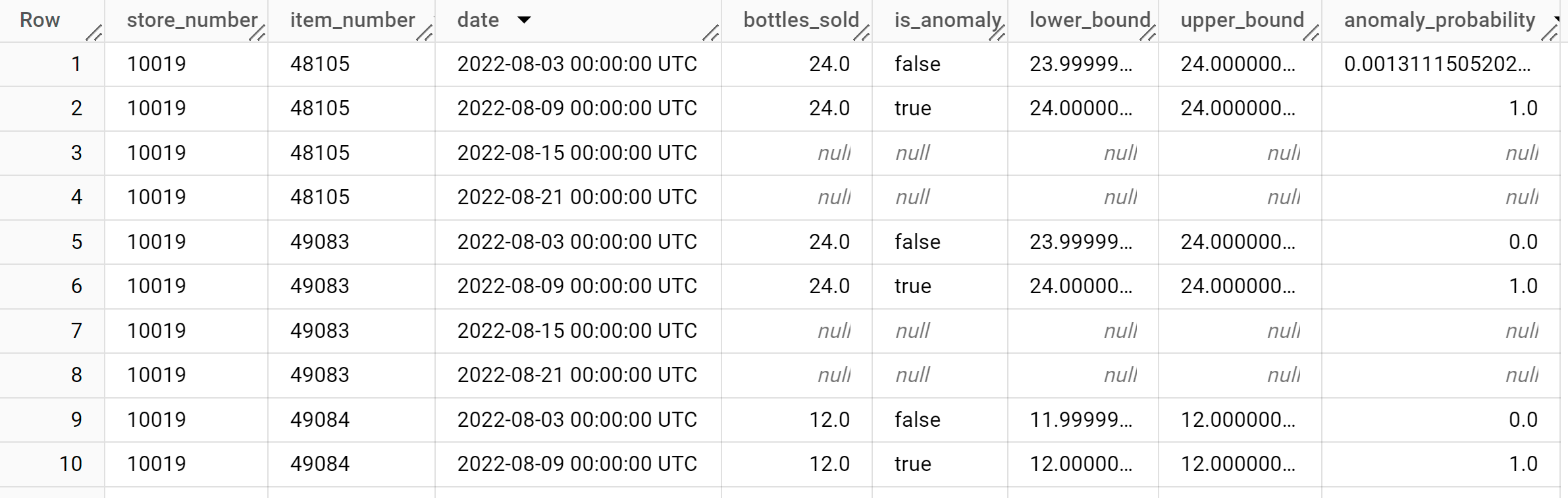
결과의
anomaly_probability열은 특정bottles_sold열 값이 비정상일 가능성을 나타냅니다.출력 열에 관한 자세한 내용은
ML.DETECT_ANOMALIES를 참고하세요.
새 데이터에서 이상 감지
ML.DETECT_ANOMALIES 함수에 입력 데이터를 제공하여 새 데이터의 이상치를 감지합니다. 새 데이터는 학습 데이터와 동일한 데이터 서명을 가져야 합니다.
새 데이터에서 이상치를 감지하려면 다음 단계를 따르세요.
Google Cloud 콘솔에서 BigQuery 페이지로 이동합니다.
쿼리 편집기에 다음 쿼리를 붙여넣고 실행을 클릭합니다.
SELECT * FROM ML.DETECT_ANOMALIES ( model `bqml_tutorial.multi_time_series_arimax_model`, STRUCT (0.95 AS anomaly_prob_threshold), ( SELECT * FROM `bqml_tutorial.iowa_liquor_sales_with_weather` WHERE DATE >= DATE('2022-09-01') ) );
결과는 다음과 비슷하게 표시됩니다.
삭제
이 튜토리얼에서 사용된 리소스 비용이 Google Cloud 계정에 청구되지 않도록 하려면 리소스가 포함된 프로젝트를 삭제하거나 프로젝트를 유지하고 개별 리소스를 삭제하세요.
- 만든 프로젝트를 삭제할 수 있습니다.
- 또는 프로젝트를 유지하고 데이터 세트를 삭제할 수 있습니다.
데이터 세트 삭제
프로젝트를 삭제하면 프로젝트의 데이터 세트와 테이블이 모두 삭제됩니다. 프로젝트를 다시 사용하려면 이 튜토리얼에서 만든 데이터 세트를 삭제할 수 있습니다.
필요한 경우 Google Cloud 콘솔에서 BigQuery 페이지를 엽니다.
앞서 만든 bqml_tutorial 데이터 세트를 탐색에서 선택합니다.
창의 오른쪽에 있는 데이터 세트 삭제를 클릭합니다. 데이터 세트, 테이블, 모든 데이터가 삭제됩니다.
데이터 세트 삭제 대화상자에서 데이터 세트 이름(
bqml_tutorial)을 입력하고 삭제를 클릭하여 삭제 명령어를 확인합니다.
프로젝트 삭제
프로젝트를 삭제하는 방법은 다음과 같습니다.
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
다음 단계
- 일변량 모델로 단일 시계열을 예측하는 방법 알아보기
- 단변량 모델로 여러 시계열을 예측하는 방법 알아보기
- 여러 행의 여러 시계열을 예측할 때 단변량 모델을 확장하는 방법 알아보기
- 단변량 모델로 여러 시계열을 계층적으로 예측하는 방법 알아보기
- BigQuery의 AI 및 ML 소개에서 BigQuery ML 개요 참조하기