Questo tutorial ti insegna a utilizzare un
ARIMA_PLUS modello di serie temporale univariata per prevedere il valore futuro di una determinata
colonna, in base ai valori storici di quella colonna.
Questo tutorial esegue previsioni per più serie temporali. I valori previsti vengono calcolati per ogni punto temporale, per ogni valore in una o più colonne specificate. Ad esempio, se vuoi prevedere il meteo e hai specificato una colonna contenente i dati delle città, i dati previsti conterranno le previsioni per tutti i punti temporali per la città A, poi i valori previsti per tutti i punti temporali per la città B e così via.
Questo tutorial utilizza i dati della tabella pubblica
bigquery-public-data.new_york.citibike_trips. Questa tabella contiene informazioni sulle corse di Citi Bike a New York.
Prima di leggere questo tutorial, ti consigliamo vivamente di leggere Previsione di una singola serie temporale con un modello univariato.
Obiettivi
Questo tutorial ti guiderà nel completamento delle seguenti attività:
- Creazione di un modello di serie temporali per prevedere il numero di tragitti in bicicletta utilizzando l'istruzione
CREATE MODEL. - Valutare le informazioni sulla media mobile integrata autoregressiva (ARIMA) nel modello utilizzando la funzione
ML.ARIMA_EVALUATE. - Esaminare i coefficienti del modello utilizzando la
funzione
ML.ARIMA_COEFFICIENTS. - Recupero delle informazioni sulla corsa in bicicletta previste dal modello utilizzando la
funzione
ML.FORECAST. - Recupero dei componenti della serie temporale, come stagionalità e tendenza, utilizzando la funzione
ML.EXPLAIN_FORECAST. Puoi esaminare questi componenti delle serie temporali per spiegare i valori previsti.
Costi
Questo tutorial utilizza componenti fatturabili di Google Cloud, tra cui:
- BigQuery
- BigQuery ML
Per ulteriori informazioni sui costi di BigQuery, consulta la pagina Prezzi di BigQuery.
Per ulteriori informazioni sui costi di BigQuery ML, consulta Prezzi di BigQuery ML.
Prima di iniziare
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
- BigQuery viene attivato automaticamente nei nuovi progetti.
Per attivare BigQuery in un progetto preesistente, vai a
Enable the BigQuery API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. Per creare il set di dati, devi disporre dell'autorizzazione IAM
bigquery.datasets.create.Per creare il modello, devi disporre delle seguenti autorizzazioni:
bigquery.jobs.createbigquery.models.createbigquery.models.getDatabigquery.models.updateData
Per eseguire l'inferenza, devi disporre delle seguenti autorizzazioni:
bigquery.models.getDatabigquery.jobs.create
Autorizzazioni richieste
Per saperne di più sui ruoli e sulle autorizzazioni IAM in BigQuery, consulta Introduzione a IAM.
Crea un set di dati
Crea un set di dati BigQuery per archiviare il tuo modello ML.
Console
Nella console Google Cloud , vai alla pagina BigQuery.
Nel riquadro Explorer, fai clic sul nome del progetto.
Fai clic su Visualizza azioni > Crea set di dati.
Nella pagina Crea set di dati:
In ID set di dati, inserisci
bqml_tutorial.Per Tipo di località, seleziona Multi-regione e poi Stati Uniti (più regioni negli Stati Uniti).
Lascia invariate le restanti impostazioni predefinite e fai clic su Crea set di dati.
bq
Per creare un nuovo set di dati, utilizza il
comando bq mk
con il flag --location. Per un elenco completo dei possibili parametri, consulta la
documentazione di riferimento del
comando bq mk --dataset.
Crea un set di dati denominato
bqml_tutorialcon la località dei dati impostata suUSe una descrizione diBigQuery ML tutorial dataset:bq --location=US mk -d \ --description "BigQuery ML tutorial dataset." \ bqml_tutorial
Anziché utilizzare il flag
--dataset, il comando utilizza la scorciatoia-d. Se ometti-de--dataset, il comando crea per impostazione predefinita un dataset.Verifica che il set di dati sia stato creato:
bq ls
API
Chiama il metodo datasets.insert con una risorsa dataset definita.
{ "datasetReference": { "datasetId": "bqml_tutorial" } }
BigQuery DataFrames
Prima di provare questo esempio, segui le istruzioni di configurazione di BigQuery DataFrames nella guida rapida di BigQuery che utilizza BigQuery DataFrames. Per ulteriori informazioni, consulta la documentazione di riferimento di BigQuery DataFrames.
Per eseguire l'autenticazione in BigQuery, configura le Credenziali predefinite dell'applicazione. Per maggiori informazioni, vedi Configurare ADC per un ambiente di sviluppo locale.
Visualizzare i dati di input
Prima di creare il modello, puoi visualizzare facoltativamente i dati delle serie temporali di input per farti un'idea della distribuzione. Puoi farlo utilizzando Looker Studio.
SQL
L'istruzione SELECT della seguente query utilizza la
funzione EXTRACT
per estrarre le informazioni sulla data dalla colonna starttime. La query utilizza
la clausola COUNT(*) per ottenere il numero totale giornaliero di viaggi in Citi Bike.
Segui questi passaggi per visualizzare i dati delle serie temporali:
Nella console Google Cloud , vai alla pagina BigQuery.
Nell'editor di query, incolla la seguente query e fai clic su Esegui:
SELECT EXTRACT(DATE from starttime) AS date, COUNT(*) AS num_trips FROM `bigquery-public-data.new_york.citibike_trips` GROUP BY date;
Al termine della query, fai clic su Esplora i dati > Esplora con Looker Studio. Looker Studio si apre in una nuova scheda. Completa i seguenti passaggi nella nuova scheda.
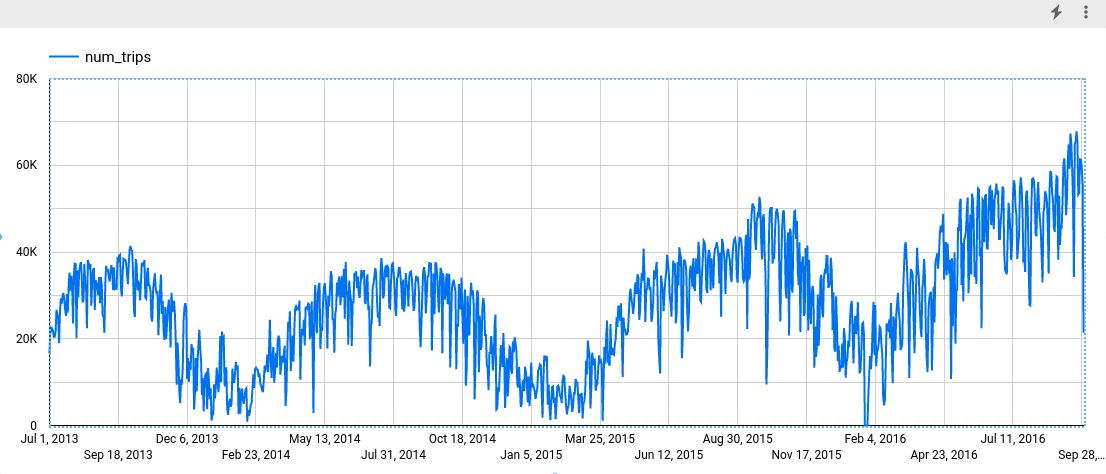
In Looker Studio, fai clic su Inserisci > Grafico delle serie temporali.
Nel riquadro Grafico, scegli la scheda Configurazione.
Nella sezione Metrica, aggiungi il campo num_trips e rimuovi la metrica predefinita Conteggio record. Il grafico risultante è simile al seguente:
BigQuery DataFrames
Prima di provare questo esempio, segui le istruzioni di configurazione di BigQuery DataFrames nella guida rapida di BigQuery che utilizza BigQuery DataFrames. Per ulteriori informazioni, consulta la documentazione di riferimento di BigQuery DataFrames.
Per eseguire l'autenticazione in BigQuery, configura le Credenziali predefinite dell'applicazione. Per maggiori informazioni, vedi Configurare ADC per un ambiente di sviluppo locale.
Crea il modello di serie temporali
Vuoi prevedere il numero di viaggi in bicicletta per ogni stazione Citi Bike, il che richiede molti modelli di serie temporali, uno per ogni stazione Citi Bike inclusa nei dati di input. Puoi creare più modelli per farlo, ma può essere un processo noioso e dispendioso in termini di tempo, soprattutto se hai un gran numero di serie temporali. In alternativa, puoi utilizzare una singola query per creare e adattare un insieme di modelli di serie temporali per prevedere più serie temporali contemporaneamente.
SQL
Nella seguente query, la clausola
OPTIONS(model_type='ARIMA_PLUS', time_series_timestamp_col='date', ...)
indica che stai creando un modello di serie temporale basato su
ARIMA. Utilizzi l'opzione
time_series_id_col
dell'istruzione CREATE MODEL per specificare una o più colonne nei dati di input
per cui vuoi ottenere le previsioni, in questo caso la stazione Citi Bike, come
rappresentato dalla colonna start_station_name. Utilizzi la clausola WHERE per
limitare le stazioni di partenza a quelle con Central Park nel nome. L'opzione
auto_arima_max_order
dell'istruzione CREATE MODEL controlla lo
spazio di ricerca per l'ottimizzazione degli iperparametri nell'algoritmo auto.ARIMA. L'opzione decompose_time_series dell'istruzione CREATE MODEL è impostata su TRUE per impostazione predefinita, in modo che le informazioni sui dati delle serie temporali vengano restituite quando valuti il modello nel passaggio successivo.
Per creare il modello:
Nella console Google Cloud , vai alla pagina BigQuery.
Nell'editor di query, incolla la seguente query e fai clic su Esegui:
CREATE OR REPLACE MODEL `bqml_tutorial.nyc_citibike_arima_model_group` OPTIONS (model_type = 'ARIMA_PLUS', time_series_timestamp_col = 'date', time_series_data_col = 'num_trips', time_series_id_col = 'start_station_name', auto_arima_max_order = 5 ) AS SELECT start_station_name, EXTRACT(DATE from starttime) AS date, COUNT(*) AS num_trips FROM `bigquery-public-data.new_york.citibike_trips` WHERE start_station_name LIKE '%Central Park%' GROUP BY start_station_name, date;
Il completamento della query richiede circa 24 secondi, dopodiché il modello
nyc_citibike_arima_model_groupviene visualizzato nel riquadro Explorer. Poiché la query utilizza un'istruzioneCREATE MODEL, non vengono visualizzati i risultati della query.
Questa query crea dodici modelli di serie temporali, uno per ciascuna delle dodici stazioni di partenza di Citi Bike nei dati di input. Il costo in termini di tempo, circa 24
secondi, è solo 1,4 volte superiore a quello della creazione di un singolo modello
di serie temporale a causa del parallelismo. Tuttavia, se rimuovi la clausola
WHERE ... LIKE ..., ci sarebbero più di 600 serie temporali da prevedere e
non verrebbero previste completamente in parallelo a causa delle limitazioni
della capacità degli slot. In questo caso, la query richiederebbe circa 15 minuti per
terminare. Per ridurre il tempo di esecuzione della query a scapito di un potenziale leggero
calo della qualità del modello, puoi diminuire il valore di
auto_arima_max_order.
In questo modo si riduce lo spazio di ricerca dell'ottimizzazione degli iperparametri nell'algoritmo auto.ARIMA. Per ulteriori informazioni, vedi
Large-scale time series forecasting best practices.
BigQuery DataFrames
Nel seguente snippet, stai creando un modello di serie temporali basato su ARIMA.
Prima di provare questo esempio, segui le istruzioni di configurazione di BigQuery DataFrames nella guida rapida di BigQuery che utilizza BigQuery DataFrames. Per ulteriori informazioni, consulta la documentazione di riferimento di BigQuery DataFrames.
Per eseguire l'autenticazione in BigQuery, configura le Credenziali predefinite dell'applicazione. Per maggiori informazioni, vedi Configurare ADC per un ambiente di sviluppo locale.
In questo modo vengono creati dodici modelli di serie temporali, uno per ciascuna delle dodici stazioni di partenza di Citi Bike nei dati di input. Il costo in termini di tempo, pari a circa 24 secondi, è solo 1,4 volte superiore a quello della creazione di un singolo modello di serie temporale a causa del parallelismo.
Valuta il modello
SQL
Valuta il modello di serie temporale utilizzando la funzione ML.ARIMA_EVALUATE. La funzione ML.ARIMA_EVALUATE mostra le metriche di valutazione
generate per il modello durante il processo di tuning automatico
degli iperparametri.
Per valutare il modello:
Nella console Google Cloud , vai alla pagina BigQuery.
Nell'editor di query, incolla la seguente query e fai clic su Esegui:
SELECT * FROM ML.ARIMA_EVALUATE(MODEL `bqml_tutorial.nyc_citibike_arima_model_group`);
I risultati dovrebbero essere simili ai seguenti:

Mentre
auto.ARIMAvaluta decine di modelli ARIMA candidati per ogni serie temporale,ML.ARIMA_EVALUATEper impostazione predefinita restituisce solo le informazioni del modello migliore per rendere compatta la tabella di output. Per visualizzare tutti i modelli candidati, puoi impostare l'argomentoshow_all_candidate_modeldella funzioneML.ARIMA_EVALUATEsuTRUE.
BigQuery DataFrames
Prima di provare questo esempio, segui le istruzioni di configurazione di BigQuery DataFrames nella guida rapida di BigQuery che utilizza BigQuery DataFrames. Per ulteriori informazioni, consulta la documentazione di riferimento di BigQuery DataFrames.
Per eseguire l'autenticazione in BigQuery, configura le Credenziali predefinite dell'applicazione. Per maggiori informazioni, vedi Configurare ADC per un ambiente di sviluppo locale.
La colonna start_station_name identifica la colonna di dati di input per cui
sono state create le serie temporali. Questa è la colonna specificata con l'opzione
time_series_id_col durante la creazione del modello.
Le colonne di output non_seasonal_p, non_seasonal_d, non_seasonal_q e has_drift
definiscono un modello ARIMA nella pipeline di addestramento. Le colonne di output
log_likelihood, AIC e variancesono pertinenti per la procedura di adattamento del modello ARIMA.La procedura di adattamento determina il modello ARIMA migliore utilizzando l'algoritmo auto.ARIMA, uno per ogni serie temporale.
L'algoritmo auto.ARIMA utilizza il
test KPSS per determinare il valore migliore
per non_seasonal_d, che in questo caso è 1. Quando non_seasonal_d è 1,
l'algoritmo auto.ARIMA addestra 42 diversi modelli ARIMA candidati in parallelo.
In questo esempio, tutti i 42 modelli candidati sono validi, quindi l'output contiene 42
righe, una per ogni modello ARIMA candidato; nei casi in cui alcuni modelli
non sono validi, vengono esclusi dall'output. Questi modelli candidati vengono
restituiti in ordine crescente in base all'AIC. Il modello nella prima riga ha l'AIC più basso ed è considerato il migliore. Questo modello migliore viene salvato come modello finale e viene utilizzato quando prevedi i dati, valuti il modello ed esamini i coefficienti del modello, come mostrato nei passaggi successivi.
La colonna seasonal_periods contiene informazioni sul pattern stagionale
identificato nei dati delle serie temporali. Ogni serie temporale può avere pattern stagionali
diversi. Ad esempio, dalla figura puoi notare che una serie temporale ha un
pattern annuale, mentre altre no.
Le colonne has_holiday_effect, has_spikes_and_dips e has_step_changes
vengono compilate solo quando decompose_time_series=TRUE. Queste colonne riflettono anche
informazioni sui dati delle serie temporali di input e non sono correlate alla modellazione
ARIMA. Queste colonne hanno anche gli stessi valori in tutte le righe di output.
Ispezionare i coefficienti del modello
SQL
Esamina i coefficienti del modello di serie temporale utilizzando la funzione
ML.ARIMA_COEFFICIENTS.
Per recuperare i coefficienti del modello:
Nella console Google Cloud , vai alla pagina BigQuery.
Nell'editor di query, incolla la seguente query e fai clic su Esegui:
SELECT * FROM ML.ARIMA_COEFFICIENTS(MODEL `bqml_tutorial.nyc_citibike_arima_model_group`);
Il completamento della query richiede meno di un secondo. I risultati dovrebbero essere simili ai seguenti:
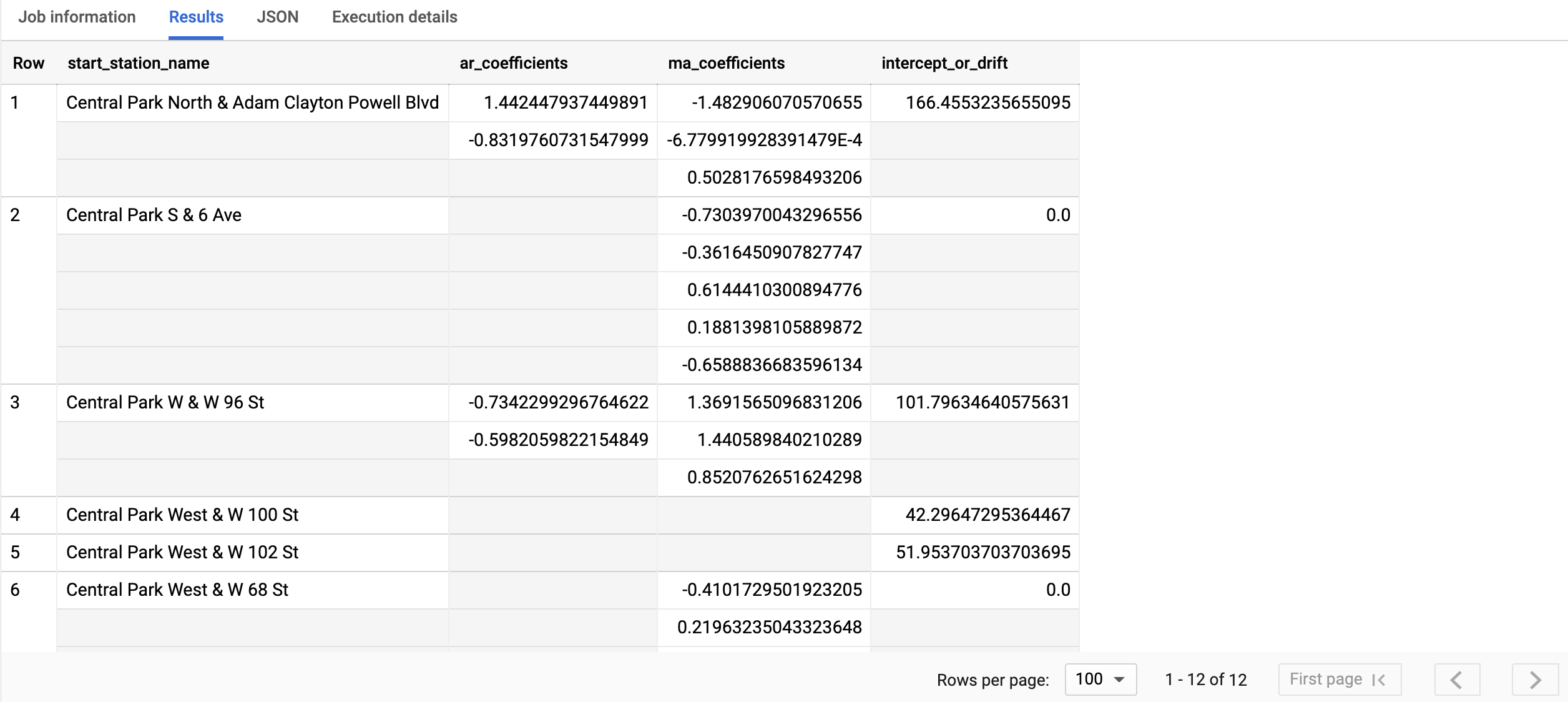
Per ulteriori informazioni sulle colonne di output, consulta la funzione
ML.ARIMA_COEFFICIENTS.
BigQuery DataFrames
Esamina i coefficienti del modello di serie temporale utilizzando la funzione
coef_.
Prima di provare questo esempio, segui le istruzioni di configurazione di BigQuery DataFrames nella guida rapida di BigQuery che utilizza BigQuery DataFrames. Per ulteriori informazioni, consulta la documentazione di riferimento di BigQuery DataFrames.
Per eseguire l'autenticazione in BigQuery, configura le Credenziali predefinite dell'applicazione. Per maggiori informazioni, vedi Configurare ADC per un ambiente di sviluppo locale.
La colonna start_station_name identifica la colonna di dati di input per cui
sono state create le serie temporali. Questa è la colonna che hai specificato nell'opzione
time_series_id_col durante la creazione del modello.
La colonna di output ar_coefficients mostra i coefficienti del modello della parte autoregressiva (AR) del modello ARIMA. Analogamente, la colonna di output ma_coefficients
mostra i coefficienti del modello della parte di media mobile (MA) del
modello ARIMA. Entrambe queste colonne contengono valori di array, le cui lunghezze sono
uguali a non_seasonal_p e non_seasonal_q, rispettivamente. Il valore
intercept_or_drift è il termine costante nel modello ARIMA.
Utilizzare il modello per prevedere i dati
SQL
Prevedi i valori futuri delle serie temporali utilizzando la funzione ML.FORECAST.
Nella seguente query GoogleSQL, la
clausola STRUCT(3 AS horizon, 0.9 AS confidence_level) indica che la
query prevede tre punti temporali futuri e genera un intervallo di previsione
con un livello di confidenza del 90%.
Per prevedere i dati con il modello:
Nella console Google Cloud , vai alla pagina BigQuery.
Nell'editor di query, incolla la seguente query e fai clic su Esegui:
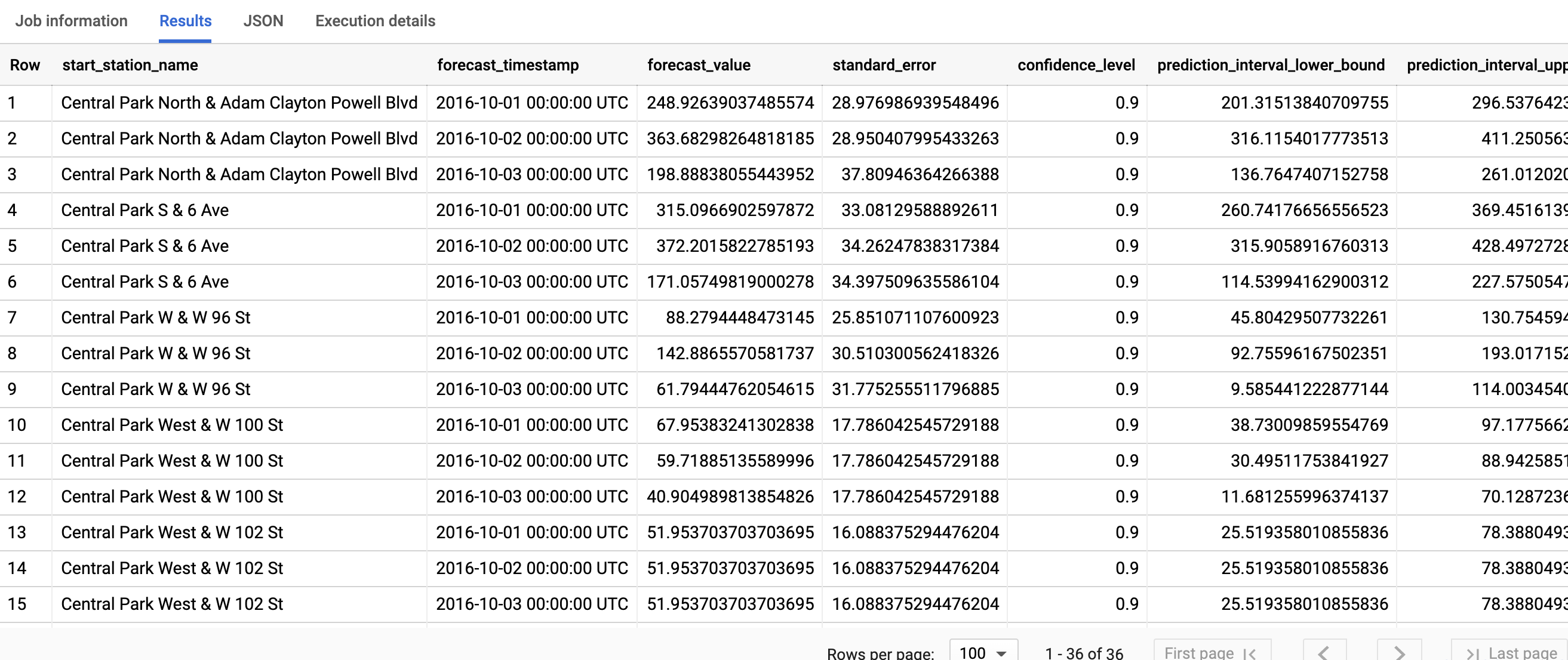
SELECT * FROM ML.FORECAST(MODEL `bqml_tutorial.nyc_citibike_arima_model_group`, STRUCT(3 AS horizon, 0.9 AS confidence_level))
Fai clic su Esegui.
Il completamento della query richiede meno di un secondo. I risultati dovrebbero essere simili ai seguenti:
Per ulteriori informazioni sulle colonne di output, consulta la
funzione ML.FORECAST.
BigQuery DataFrames
Prevedi i valori futuri delle serie temporali utilizzando la funzione
predict.
Prima di provare questo esempio, segui le istruzioni di configurazione di BigQuery DataFrames nella guida rapida di BigQuery che utilizza BigQuery DataFrames. Per ulteriori informazioni, consulta la documentazione di riferimento di BigQuery DataFrames.
Per eseguire l'autenticazione in BigQuery, configura le Credenziali predefinite dell'applicazione. Per maggiori informazioni, vedi Configurare ADC per un ambiente di sviluppo locale.
La prima colonna, start_station_name, annota la serie temporale a cui è adattato ogni modello di serie temporale. Ogni start_station_name ha tre
righe di risultati previsti, come specificato dal valore horizon.
Per ogni start_station_name, le righe di output sono in ordine cronologico in base al valore della colonna
forecast_timestamp. Nella previsione delle serie temporali, l'intervallo di previsione, rappresentato dai valori delle colonne prediction_interval_lower_bound e prediction_interval_upper_bound, è importante quanto il valore della colonna forecast_value. Il valore forecast_value è il punto medio
dell'intervallo di previsione. L'intervallo di previsione dipende dai valori delle colonne
standard_error e confidence_level.
Spiegare i risultati delle previsioni
SQL
Puoi ottenere metriche di interpretabilità oltre ai dati di previsione utilizzando la
funzione ML.EXPLAIN_FORECAST. La funzione ML.EXPLAIN_FORECAST prevede
i valori futuri delle serie temporali e restituisce anche tutti i componenti separati delle
serie temporali. Se vuoi solo restituire i dati di previsione, utilizza la funzione ML.FORECAST, come mostrato in Utilizzare il modello per prevedere i dati.
La clausola STRUCT(3 AS horizon, 0.9 AS confidence_level) utilizzata nella funzione
ML.EXPLAIN_FORECAST indica che la query prevede tre punti temporali futuri e genera un intervallo di previsione con un livello di confidenza del 90%.
Per spiegare i risultati del modello:
Nella console Google Cloud , vai alla pagina BigQuery.
Nell'editor di query, incolla la seguente query e fai clic su Esegui:
SELECT * FROM ML.EXPLAIN_FORECAST(MODEL `bqml_tutorial.nyc_citibike_arima_model_group`, STRUCT(3 AS horizon, 0.9 AS confidence_level));
Il completamento della query richiede meno di un secondo. I risultati dovrebbero essere simili ai seguenti:


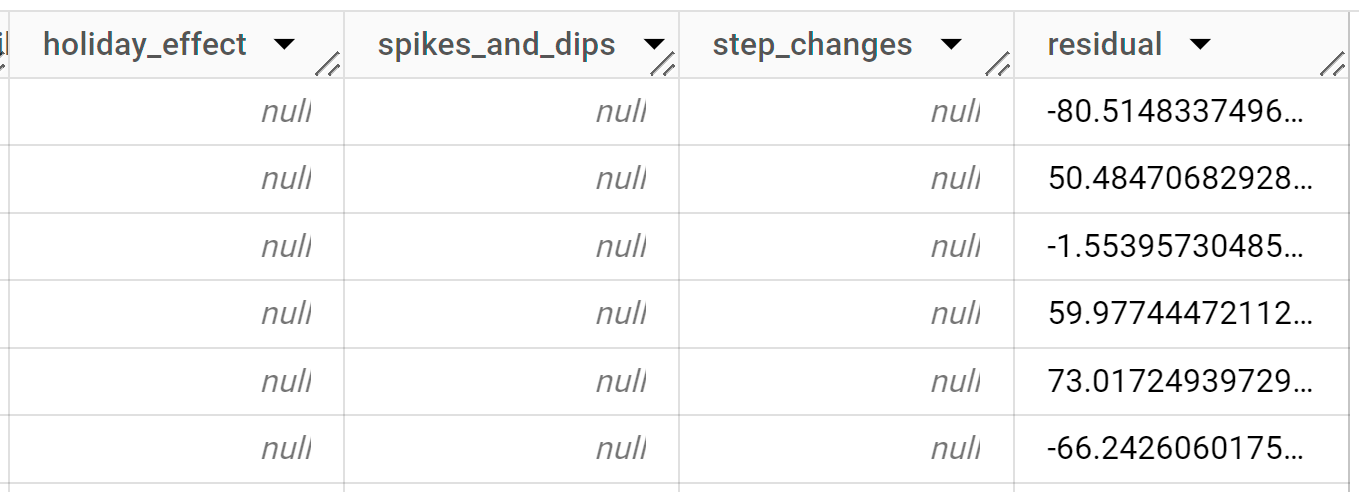
Le prime migliaia di righe restituite sono tutti dati cronologici. Devi scorrere i risultati per visualizzare i dati delle previsioni.
Le righe di output vengono ordinate prima in base a
start_station_name, poi cronologicamente in base al valore della colonnatime_series_timestamp. Nella previsione delle serie temporali, l'intervallo di previsione, rappresentato dai valori delle colonneprediction_interval_lower_boundeprediction_interval_upper_bound, è importante quanto il valore della colonnaforecast_value. Il valoreforecast_valueè il punto medio dell'intervallo di previsione. L'intervallo di previsione dipende dai valori delle colonnestandard_erroreconfidence_level.Per ulteriori informazioni sulle colonne di output, vedi
ML.EXPLAIN_FORECAST.
BigQuery DataFrames
Puoi ottenere metriche di interpretabilità oltre ai dati di previsione utilizzando la
funzione predict_explain. La funzione predict_explain prevede
i valori futuri delle serie temporali e restituisce anche tutti i componenti separati delle
serie temporali. Se vuoi solo restituire i dati di previsione, utilizza la funzione predict, come mostrato in Utilizzare il modello per prevedere i dati.
La clausola horizon=3, confidence_level=0.9 utilizzata nella funzione
predict_explain indica che la query prevede tre punti temporali futuri e genera un intervallo di previsione con un livello di confidenza del 90%.
Prima di provare questo esempio, segui le istruzioni di configurazione di BigQuery DataFrames nella guida rapida di BigQuery che utilizza BigQuery DataFrames. Per ulteriori informazioni, consulta la documentazione di riferimento di BigQuery DataFrames.
Per eseguire l'autenticazione in BigQuery, configura le Credenziali predefinite dell'applicazione. Per maggiori informazioni, vedi Configurare ADC per un ambiente di sviluppo locale.
Le righe di output vengono ordinate prima in base a time_series_timestamp, poi
cronologicamente in base al valore della colonna start_station_name. Nella previsione delle serie temporali, l'intervallo di previsione, rappresentato dai valori delle colonne prediction_interval_lower_bound e prediction_interval_upper_bound, è importante quanto il valore della colonna forecast_value. Il valore forecast_value è il punto medio
dell'intervallo di previsione. L'intervallo di previsione dipende dai valori delle colonne
standard_error e confidence_level.
Esegui la pulizia
Per evitare che al tuo account Google Cloud vengano addebitati costi relativi alle risorse utilizzate in questo tutorial, elimina il progetto che contiene le risorse oppure mantieni il progetto ed elimina le singole risorse.
- Puoi eliminare il progetto che hai creato.
- In alternativa, puoi conservare il progetto ed eliminare il set di dati.
Elimina il set di dati
L'eliminazione del progetto rimuove tutti i set di dati e tutte le tabelle nel progetto. Se preferisci riutilizzare il progetto, puoi eliminare il set di dati creato in questo tutorial:
Se necessario, apri la pagina BigQuery nella consoleGoogle Cloud .
Nella navigazione, fai clic sul set di dati bqml_tutorial che hai creato.
Fai clic su Elimina set di dati per eliminare il set di dati, la tabella e tutti i dati.
Nella finestra di dialogo Elimina set di dati, conferma il comando di eliminazione digitando il nome del set di dati (
bqml_tutorial) e poi fai clic su Elimina.
Elimina il progetto
Per eliminare il progetto:
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Passaggi successivi
- Scopri come prevedere una singola serie temporale con un modello univariato
- Scopri come prevedere una singola serie temporale con un modello multivariato.
- Scopri come scalare un modello univariato quando prevedi più serie temporali su più righe.
- Scopri come prevedere gerarchicamente più serie temporali con un modello univariato.
- Per una panoramica di BigQuery ML, consulta Introduzione all'AI e al ML in BigQuery.