Administra las recomendaciones de particiones y clústeres
En este documento, se describe cómo funciona el recomendador de particiones y clústeres, cómo ver las recomendaciones y estadísticas, y cómo aplicar las recomendaciones de particiones y clústeres.
Cómo funciona el recomendador
El recomendador de particiones y agrupamiento en clústeres de BigQuery genera recomendaciones de particiones o clústeres para optimizar tus tablas de BigQuery. El recomendador analiza los flujos de trabajo en tus tablas de BigQuery y ofrece recomendaciones para optimizar mejor tus flujos de trabajo y costos de consultas mediante la partición o el agrupamiento en clústeres de las tablas.
Para obtener más información sobre el servicio del recomendador, consulta la descripción general del recomendador.
El recomendador de partición y agrupamiento en clústeres usa los datos de ejecución de la carga de trabajo del proyecto de los últimos 30 días para analizar cada tabla de BigQuery para detectar parámetros de configuración de partición y agrupamiento en clústeres no óptimos. Además, este servicio usa el aprendizaje automático para predecir cuánto se podría optimizar la ejecución de la carga de trabajo con diferentes parámetros de configuración de partición o agrupamiento en clústeres. Si el recomendador descubre que la partición o el agrupamiento en clústeres de una tabla produce ahorros significativos, genera una recomendación. El recomendador de partición y agrupamiento en clústeres genera los siguientes tipos de recomendaciones:
| Tipo de tabla existente | Subtipo de recomendación | Ejemplo de recomendación |
|---|---|---|
| Sin particiones ni agrupamiento | Partición | “Ahorra alrededor de 64 horas de ranuras por mes con la partición en column_C by DAY” |
| Sin particiones ni agrupamiento | Clúster | “Ahorra alrededor de 64 horas de ranuras por mes mediante el agrupamiento en clústeres en column_C” |
| Con partición, sin agrupamiento | Clúster | “Ahorra alrededor de 64 horas de ranuras por mes mediante el agrupamiento en clústeres en column_C” |
Cada recomendación consta de tres partes:
- Orientación para particionar o agrupar en clústeres una tabla específica
- La columna específica de una tabla para particionar o agrupar en clústeres
- Ahorros mensuales estimados por aplicar la recomendación
Para calcular los posibles ahorros de cargas de trabajo, el recomendador supone que los datos históricos de carga de trabajo de ejecución de los últimos 30 días representan la carga de trabajo futura.
La API del recomendador también muestra información de las cargas de trabajo de la tabla en forma de estadísticas. Las estadísticas son hallazgos que te ayudan a comprender la carga de trabajo de tu proyecto y proporcionan más contexto sobre cómo una recomendación de particiones o clústeres podría mejorar los costos de carga de trabajo.
Limitaciones
El recomendador de partición y agrupamiento en clústeres no admite tablas de BigQuery con SQL heredado. Cuando se genera una recomendación, el recomendador excluye cualquier consulta de SQL heredado en su análisis. Además, la aplicación de recomendaciones de partición en tablas de BigQuery con SQL heredado interrumpe los flujos de trabajo de SQL heredado en esa tabla.
Antes de aplicar las recomendaciones de partición, migra tus flujos de trabajo de SQL heredado a GoogleSQL.
BigQuery no admite el cambio del esquema de partición de una tabla. Solo puedes cambiar la partición de una tabla en una copia de la tabla. Para obtener más información, consulta Aplica recomendaciones de particiones.
Ubicaciones
El recomendador de partición y agrupamiento en clústeres está disponible en las siguientes ubicaciones de procesamiento:
| Descripción de la región | Nombre de la región | Detalles | |
|---|---|---|---|
| Asia-Pacífico | |||
| Delhi | asia-south2 |
||
| Hong Kong | asia-east2 |
||
| Yakarta | asia-southeast2 |
||
| Bombay | asia-south1 |
||
| Osaka | asia-northeast2 |
||
| Seúl | asia-northeast3 |
||
| Singapur | asia-southeast1 |
||
| Sídney | australia-southeast1 |
||
| Taiwán | asia-east1 |
||
| Tokio | asia-northeast1 |
||
| Europa | |||
| Bélgica | europe-west1 |
|
|
| Berlín | europe-west10 |
|
|
| UE multirregión | eu |
||
| Fráncfort | europe-west3 |
|
|
| Londres | europe-west2 |
|
|
| Países Bajos | europe-west4 |
|
|
| Zúrich | europe-west6 |
|
|
| América | |||
| Iowa | us-central1 |
|
|
| Las Vegas | us-west4 |
||
| Los Ángeles | us-west2 |
||
| Montreal | northamerica-northeast1 |
|
|
| Virginia del Norte | us-east4 |
||
| Oregón | us-west1 |
|
|
| Salt Lake City | us-west3 |
||
| São Paulo | southamerica-east1 |
|
|
| Toronto | northamerica-northeast2 |
|
|
| EE.UU. multirregión | us |
||
Antes de comenzar
- Asegúrate de que Gemini en BigQuery esté habilitado para tu proyecto de Google Cloud.
- Habilita la API del Recomendador.
Permisos necesarios
A fin de obtener los permisos que necesitas para acceder a las recomendaciones de particiones y clústeres,
pídele a tu administrador que te otorgue el rol de IAM de
visualizador del recomendador de agrupamiento en clústeres por particiones de BigQuery (roles/recommender.bigqueryPartitionClusterViewer).
Para obtener más información sobre cómo otorgar roles, consulta Administra el acceso a proyectos, carpetas y organizaciones.
Este rol predefinido contiene los permisos necesarios para acceder a las recomendaciones de particiones y clústeres. Para ver los permisos exactos que son necesarios, expande la sección Permisos requeridos:
Permisos necesarios
Se requieren los siguientes permisos para acceder a las recomendaciones de particiones y clústeres:
-
recommender.bigqueryPartitionClusterRecommendations.get -
recommender.bigqueryPartitionClusterRecommendations.list
También puedes obtener estos permisos con roles personalizados o con otros roles predefinidos.
Para obtener más información sobre los roles y permisos de IAM en BigQuery, consulta Introducción a IAM.
Ver recomendaciones
En esta sección, se describe cómo ver recomendaciones y estadísticas de particiones y clústeres mediante la consola de Google Cloud, Google Cloud CLI o la API del recomendador.
Selecciona una de las opciones siguientes:
Console
En la consola de Google Cloud, ve a la página de BigQuery.
Para abrir la pestaña Recomendaciones, haz clic en Recomendaciones > Ver todas las recomendaciones.
En la pestaña de recomendaciones, se muestran todas las recomendaciones disponibles para tu proyecto.
En el panel Optimizar el costo de la carga de trabajo de BigQuery, haz clic en Ver todo.
En la tabla de recomendaciones de costos, se muestran todas las recomendaciones generadas para el proyecto actual. Por ejemplo, en la siguiente captura de pantalla, se muestra que el recomendador analizó la tabla
example_tabley, luego, recomendó el agrupamiento en clústeres de la columnaexample_columnpara ahorrar una cantidad aproximada de bytes y ranuras.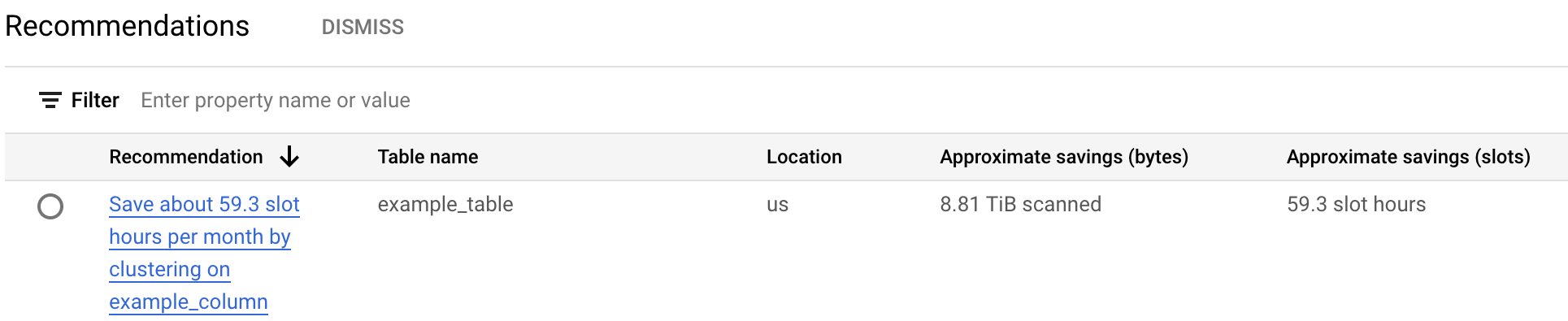
Para ver más información sobre las estadísticas y recomendaciones de la tabla, haz clic en una recomendación.
gcloud
Para ver las recomendaciones de particiones o clústeres de un proyecto específico, usa el comando gcloud recommender recommendations list:
gcloud recommender recommendations list \
--project=PROJECT_NAME \
--location=REGION_NAME \
--recommender=google.bigquery.table.PartitionClusterRecommender \
--format=FORMAT_TYPE \
Reemplaza lo siguiente:
PROJECT_NAME: es el nombre del proyecto que contiene tu tabla de BigQueryREGION_NAME: es la región en la que se encuentra tu proyectoFORMAT_TYPE: un formato de salida de CLI de gcloud compatible; por ejemplo, JSON
| Propiedad | Relevante para el subtipo | Descripción |
|---|---|---|
recommenderSubtype |
Partición o clúster | Indica el tipo de recomendación. |
content.overview.partitionColumn |
Partición | Nombre de columna de partición recomendada. |
content.overview.partitionTimeUnit |
Partición | Unidad de tiempo de partición recomendada. Por ejemplo, DAY significa que la recomendación es tener particiones diarias en la columna recomendada. |
content.overview.clusterColumns |
Clúster | Nombres de columnas de agrupamiento en clústeres recomendados. |
- Para obtener más información sobre otros campos de la respuesta del recomendador, consulta Recurso de REST:
projects.locations.recommendersrecommendation. - Para obtener más información sobre la API del recomendador, consulta Usa la API: Recomendaciones.
Para ver las estadísticas de tablas mediante la CLI de gcloud, usa el comando gcloud recommender insights list:
gcloud recommender insights list \
--project=PROJECT_NAME \
--location=REGION_NAME \
--insight-type=google.bigquery.table.StatsInsight \
--format=FORMAT_TYPE \
Reemplaza lo siguiente:
PROJECT_NAME: es el nombre del proyecto que contiene tu tabla de BigQueryREGION_NAME: es la región en la que se encuentra tu proyectoFORMAT_TYPE: un formato de salida de CLI de gcloud compatible; por ejemplo, JSON
| Propiedad | Relevante para el subtipo | Descripción |
|---|---|---|
content.existingPartitionColumn |
Clúster | Columna de partición existente, si existe |
content.tableSizeTb |
Todos | Tamaño de la tabla en terabytes |
content.bytesReadMonthly |
Todos | Bytes mensuales leídos de la tabla |
content.slotMsConsumedMonthly |
Todos | Milisegundos de ranura mensuales que consume la carga de trabajo que se ejecuta en la tabla |
content.queryJobsCountMonthly |
Todos | Recuento mensual de trabajos que se ejecutan en la tabla |
- Para obtener más información sobre otros campos de la respuesta de las estadísticas, consulta Recurso de REST:
projects.locations.insightTypes.insights. - Para obtener más información sobre el uso de estadísticas, consulta Usa la API: Estadísticas.
API de REST
Para ver las recomendaciones de particiones o clústeres de un proyecto específico, usa la API de REST. Con cada comando, debes proporcionar un token de autenticación, que puedes obtener mediante la CLI de gcloud. Si deseas obtener más información sobre cómo obtener un token de autenticación, consulta Métodos para obtener un token de ID.
Puedes usar la solicitud curl list para ver todas las recomendaciones de un proyecto específico:
curl
-H "Authorization: Bearer $GCLOUD_AUTH_TOKEN"
-H "x-goog-user-project: PROJECT_NAME" https://recommender.googleapis.com/v1/projects/my-project/locations/us/recommenders/google.bigquery.table.PartitionClusterRecommender/recommendations
Reemplaza lo siguiente:
GCLOUD_AUTH_TOKEN: el nombre de un token de acceso a gcloud CLI válidoPROJECT_NAME: el nombre del proyecto que contiene tu tabla de BigQuery
| Propiedad | Relevante para el subtipo | Descripción |
|---|---|---|
recommenderSubtype |
Partición o clúster | Indica el tipo de recomendación. |
content.overview.partitionColumn |
Partición | Nombre de columna de partición recomendada. |
content.overview.partitionTimeUnit |
Partición | Unidad de tiempo de partición recomendada. Por ejemplo, DAY significa que la recomendación es tener particiones diarias en la columna recomendada. |
content.overview.clusterColumns |
Clúster | Nombres de columnas de agrupamiento en clústeres recomendados. |
- Para obtener más información sobre otros campos de la respuesta del recomendador, consulta Recurso de REST:
projects.locations.recommendersrecommendation. - Para obtener más información sobre la API del recomendador, consulta Usa la API: Recomendaciones.
Para ver las estadísticas de las tablas mediante la API de REST, ejecuta el siguiente comando:
curl -H "Authorization: Bearer $GCLOUD_AUTH_TOKEN" -H "x-goog-user-project: PROJECT_NAME" https://recommender.googleapis.com/v1/projects/my-project/locations/us/insightTypes/google.bigquery.table.StatsInsight/insights
Reemplaza lo siguiente:
GCLOUD_AUTH_TOKEN: el nombre de un token de acceso a gcloud CLI válidoPROJECT_NAME: el nombre del proyecto que contiene tu tabla de BigQuery
| Propiedad | Relevante para el subtipo | Descripción |
|---|---|---|
content.existingPartitionColumn |
Clúster | Columna de partición existente, si existe |
content.tableSizeTb |
Todos | Tamaño de la tabla en terabytes |
content.bytesReadMonthly |
Todos | Bytes mensuales leídos de la tabla |
content.slotMsConsumedMonthly |
Todos | Milisegundos de ranura mensuales que consume la carga de trabajo que se ejecuta en la tabla |
content.queryJobsCountMonthly |
Todos | Recuento mensual de trabajos que se ejecutan en la tabla |
- Para obtener más información sobre otros campos de la respuesta de las estadísticas, consulta Recurso de REST:
projects.locations.insightTypes.insights. - Para obtener más información sobre el uso de estadísticas, consulta Usa la API: Estadísticas.
Aplica recomendaciones de clústeres
Para aplicar las recomendaciones de clústeres, haz una de las siguientes acciones:
- Aplicar clústeres directamente a la tabla original
- Aplicar clústeres a una tabla copiada
- Aplicar clústeres en una vista materializada
Aplicar clústeres directamente a la tabla original
Puedes aplicar recomendaciones de clústeres directamente a una tabla de BigQuery existente. Este método es más rápido que aplicar las recomendaciones a una tabla copiada, pero no conserva una tabla de copia de seguridad.
Sigue estos pasos para aplicar una especificación de agrupamiento en clústeres nueva a tablas no particionadas o particionadas.
En la herramienta de bq, actualiza la especificación de agrupamiento en clústeres de tu tabla para que coincida con el agrupamiento en clústeres nuevo:
bq update --clustering_fields=CLUSTER_COLUMN DATASET.ORIGINAL_TABLE
Reemplaza lo siguiente:
CLUSTER_COLUMN: la columna en la que se agrupa en clústeres, por ejemplo,mycolumnDATASET: el nombre del conjunto de datos que contiene la tabla; por ejemplo,mydatasetORIGINAL_TABLE: el nombre de tu tabla original; por ejemplo,mytable
También puedes llamar al método
tables.updateotables.patchde la API para modificar la especificación del agrupamiento en clústeres.Para agrupar todas las filas según la especificación de agrupamiento en clústeres nueva, ejecuta la siguiente declaración
UPDATE:UPDATE DATASET.ORIGINAL_TABLE SET CLUSTER_COLUMN=CLUSTER_COLUMN WHERE true
Aplica clústeres a una tabla copiada
Cuando aplicas recomendaciones de clústeres a una tabla de BigQuery, primero puedes copiar la tabla original y, luego, aplicar la recomendación a la tabla copiada. Este método garantiza que se conserven los datos originales si necesitas revertir el cambio a la configuración de agrupamiento en clústeres.
Puedes usar este método para aplicar recomendaciones de clústeres a tablas no particionadas y particionadas.
En la consola de Google Cloud, ve a la página de BigQuery.
En el editor de consultas, crea una tabla vacía con los mismos metadatos (incluidas las especificaciones de agrupamiento en clústeres) de la tabla original mediante el operador
LIKE:CREATE TABLE DATASET.COPIED_TABLE LIKE DATASET.ORIGINAL_TABLE
Reemplaza lo siguiente:
DATASET: el nombre del conjunto de datos que contiene la tabla; por ejemplo,mydatasetCOPIED_TABLE: un nombre para tu tabla copiada; por ejemplo,copy_mytableORIGINAL_TABLE: el nombre de tu tabla original; por ejemplo,mytable
En la consola de Google Cloud, abre el editor de Cloud Shell.
En el editor de Cloud Shell, actualiza la especificación de agrupamiento en clústeres de la tabla copiada para que coincida con el agrupamiento en clústeres recomendado mediante el comando
bq update:bq update --clustering_fields=CLUSTER_COLUMN DATASET.COPIED_TABLE
Reemplaza
CLUSTER_COLUMNpor la columna en la que se agrupa en clústeres, por ejemplo,mycolumn.También puedes llamar al método
tables.updateotables.patchde la API para modificar la especificación del agrupamiento en clústeres.En el editor de consultas, recupera el esquema de la tabla con la configuración de partición y agrupamiento en clústeres de la tabla original, si existe. Puedes recuperar el esquema visualizando la vista
INFORMATION_SCHEMA.TABLESde la tabla original:SELECT ddl FROM DATASET.INFORMATION_SCHEMA.TABLES WHERE table_name = 'DATASET.ORIGINAL_TABLE;'
El resultado es la declaración completa del lenguaje de definición de datos (DDL) de ORIGINAL_TABLE, incluida la cláusula
PARTITION BY. Para obtener más información sobre los argumentos en tu resultado de DDL, consulta declaraciónCREATE TABLE.El resultado de DDL indica el tipo de partición en la tabla original:
Tipo de partición Ejemplo de resultado Sin particionar La cláusula PARTITION BYestá ausente.Particionado por columna de tabla PARTITION BY c0PARTITION BY DATE(c0)PARTITION BY DATETIME_TRUNC(c0, MONTH)Particionado por tiempo de transferencia PARTITION BY _PARTITIONDATEPARTITION BY DATETIME_TRUNC(_PARTITIONTIME, MONTH)Transfiere datos a la tabla copiada. El proceso que uses se basa en el tipo de partición.
- Si la tabla original no está particionada o está particionada por una columna de tabla, transfiere los datos de la tabla original a la tabla copiada:
INSERT INTO DATASET.COPIED_TABLE SELECT * FROM DATASET.ORIGINAL_TABLE
Si la tabla original se particiona por tiempo de transferencia, sigue estos pasos:
Recupera la lista de columnas para formar la expresión de transferencia de datos mediante la vista
INFORMATION_SCHEMA.COLUMNS:SELECT ARRAY_TO_STRING(( SELECT ARRAY( SELECT column_name FROM DATASET.INFORMATION_SCHEMA.COLUMNS WHERE table_name = 'ORIGINAL_TABLE')), ", ")
El resultado es una lista separada por comas de los nombres de las columnas.
Transfiere los datos de la tabla original a la tabla copiada:
INSERT DATASET.COPIED_TABLE (COLUMN_NAMES, _PARTITIONTIME) SELECT *, _PARTITIONTIME FROM DATASET.ORIGINAL_TABLE
Reemplaza
COLUMN_NAMESpor la lista de columnas que eran el resultado en el paso anterior, separadas por comas, por ejemplo,col1, col2, col3.
Ahora tienes una tabla copiada agrupada con los mismos datos que la tabla original. En los siguientes pasos, reemplazarás la tabla original por una tabla recién agrupada.
- Si la tabla original no está particionada o está particionada por una columna de tabla, transfiere los datos de la tabla original a la tabla copiada:
Cambia el nombre de la tabla original al de una tabla de copia de seguridad:
ALTER TABLE DATASET.ORIGINAL_TABLE RENAME TO DATASET.BACKUP_TABLE
Reemplaza
BACKUP_TABLEpor un nombre para la tabla de copia de seguridad, por ejemplo,backup_mytable.Cambia el nombre de la tabla copiada a la tabla original:
ALTER TABLE DATASET.COPIED_TABLE RENAME TO DATASET.ORIGINAL_TABLE
Ahora, tu tabla original se agrupa en clústeres según la recomendación de clústeres.
- Acceso y permisos, como los permisos de IAM, el acceso a nivel de fila o el acceso a nivel de columna
- Artefactos de tablas, como clonaciones de tablas, instantáneas de tablas o índices de la búsqueda
- El estado de los procesos de tabla en curso, como las vistas materializadas o cualquier trabajo que se haya ejecutado cuando copiaste la tabla
- La capacidad de acceder a los datos históricos de la tabla mediante el viaje en el tiempo
- Cualquier metadato asociado con la tabla original, por ejemplo,
table_option_listocolumn_option_listPara obtener más información, consulta Declaraciones del lenguaje de definición de datos.
Si surge algún problema, debes migrar de forma manual los artefactos afectados a la tabla nueva.
Después de revisar la tabla agrupada, puedes borrar la tabla de copia de seguridad con el siguiente comando:DROP TABLE DATASET.BACKUP_TABLE
Aplica clústeres en una vista materializada
Puedes crear una vista materializada de la tabla para almacenar datos de la tabla original con la recomendación aplicada. El uso de vistas materializadas para aplicar recomendaciones garantiza que los datos agrupados en clústeres se mantengan actualizados mediante actualizaciones automáticas. Existen consideraciones de precios para las consultas, el mantenimiento y el almacenamiento de vistas materializadas. Para aprender a crear una vista materializada en clústeres, consulta Vistas materializadas agrupadas en clústeres.Aplica recomendaciones de partición
Para aplicar recomendaciones de partición, debes aplicarlas a una copia de la tabla original. BigQuery no admite el cambio de un esquema de partición de una tabla en su lugar, como el cambio de una tabla no particionada a una tabla particionada, el cambio del esquema de partición de una tabla o la creación de una vista materializada con un esquema de partición diferente de la tabla base. Solo puedes cambiar la partición de una tabla en una copia de la tabla.
Aplica recomendaciones de partición a una tabla copiada
Cuando aplicas recomendaciones de partición a una tabla de BigQuery, primero debes copiar la tabla original y, luego, aplicar la recomendación a la tabla copiada. Este enfoque garantiza que se conserven los datos originales si necesitas revertir una partición.
En el siguiente procedimiento, se usa una recomendación de ejemplo para particionar una tabla por la unidad de tiempo de partición DAY.
Crea una tabla copiada con las recomendaciones de partición:
CREATE TABLE DATASET.COPIED_TABLE PARTITION BY DATE_TRUNC(PARTITION_COLUMN, DAY) AS SELECT * FROM DATASET.ORIGINAL_TABLE
Reemplaza lo siguiente:
DATASET: el nombre del conjunto de datos que contiene la tabla; por ejemplo,mydatasetCOPIED_TABLE: un nombre para tu tabla copiada; por ejemplo,copy_mytablePARTITION_COLUMN: la columna a la que realizas la partición; por ejemplo,mycolumn
Para obtener más información sobre cómo crear tablas particionadas, consulta Crea tablas particionadas.
Cambia el nombre de la tabla original al de una tabla de copia de seguridad:
ALTER TABLE DATASET.ORIGINAL_TABLE RENAME TO DATASET.BACKUP_TABLE
Reemplaza
BACKUP_TABLEpor un nombre para la tabla de copia de seguridad, por ejemplo,backup_mytable.Cambia el nombre de la tabla copiada a la tabla original:
ALTER TABLE DATASET.COPIED_TABLE RENAME TO DATASET.ORIGINAL_TABLE
La tabla original ahora está particionada según la recomendación de partición.
- Acceso y permisos, como los permisos de IAM, el acceso a nivel de fila o el acceso a nivel de columna
- Artefactos de tablas, como clonaciones de tablas, instantáneas de tablas o índices de la búsqueda
- El estado de los procesos de tabla en curso, como las vistas materializadas o cualquier trabajo que se haya ejecutado cuando copiaste la tabla
- La capacidad de acceder a los datos históricos de la tabla mediante el viaje en el tiempo
- Cualquier metadato asociado con la tabla original, por ejemplo,
table_option_listocolumn_option_listPara obtener más información, consulta Declaraciones del lenguaje de definición de datos. - Capacidad de usar SQL heredado para escribir resultados de consultas en tablas particionadas. El uso de SQL heredado no es compatible por completo en tablas particionadas. Una solución es migrar tus flujos de trabajo de SQL heredado a GoogleSQL antes de aplicar una recomendación de partición.
Si surge algún problema, debes migrar de forma manual los artefactos afectados a la tabla nueva.
Después de revisar la tabla particionada, puedes borrar la tabla de copia de seguridad con el siguiente comando:DROP TABLE DATASET.BACKUP_TABLE
Precios
Para obtener detalles sobre los precios de esta función, consulta la descripción general de los precios de Gemini en BigQuery.
Cuando aplicas una recomendación a una tabla, puedes generar los siguientes costos:- Costos de procesamiento. Cuando aplicas una recomendación, ejecutas una consulta de lenguaje de definición de datos (DDL) o de lenguaje de manipulación de datos (DML) en tu proyecto de BigQuery.
- Costos de almacenamiento. Si usas el método de copia de una tabla, usas almacenamiento adicional para la tabla copiada (o la copia de seguridad).
Se aplican cargos de procesamiento y almacenamiento estándar según la cuenta de facturación asociada con el proyecto. Si deseas obtener más información, consulta los Precios de BigQuery.
Cuotas y límites
Si deseas obtener información sobre las cuotas y los límites de esta función, consulta Cuotas para Gemini en BigQuery.
Soluciona problemas
Problema: No aparecen recomendaciones para una tabla específica.
Es posible que las recomendaciones de particiones y clústeres no aparezcan en las siguientes circunstancias:
- El tamaño de la tabla es inferior a 10 GB.
- La tabla tiene un costo de escritura alto por operaciones de lenguaje de manipulación de datos (DML).
- La tabla no se leyó en los últimos 30 días.
- El ahorro mensual estimado es demasiado insignificante (menos de 1 hora de ahorro).
- La tabla ya está agrupada en clústeres.