Panoramica: eseguire la migrazione dei data warehouse in BigQuery
Questo documento illustra i concetti generali applicabili a qualsiasi tecnologia di data warehousing e descrive un framework che puoi utilizzare per organizzare e strutturare la migrazione a BigQuery.
Terminologia
Quando parliamo della migrazione del data warehouse, utilizziamo la seguente terminologia:
- Caso d'uso
-
Un caso d'uso è costituito da tutti i
set di dati, dall'elaborazione dei dati e dalle interazioni tra sistema e utenti necessarie per
ottenere valore aziendale, ad esempio il monitoraggio dei volumi di vendita di un prodotto nel
tempo. Nel data warehousing, il caso d'uso spesso consiste in:
- Data pipelines che importano dati non elaborati da varie origini dati, come il database di gestione dei rapporti con i clienti (CRM).
- I dati archiviati nel data warehouse.
- Script e procedure per manipolare, elaborare e analizzare ulteriormente i dati.
- Un'applicazione aziendale che legge o interagisce con i dati.
- Carico di lavoro
-
Un insieme di casi d'uso che sono connessi e con dipendenze condivise. Ad
esempio, un caso d'uso potrebbe avere le seguenti relazioni e dipendenze:
- I report sugli acquisti possono essere utilizzati da soli ed sono utili per comprendere le spese e richiedere sconti.
- I report sulle vendite possono essere utilizzati da soli ed sono utili per pianificare le campagne di marketing.
- Tuttavia, la generazione di report sui profitti e sulle perdite dipende dagli acquisti e dalle vendite ed è utile per determinare il valore dell'azienda.
- Applicazione aziendale
- Un sistema con cui gli utenti finali interagiscono, ad esempio un report visivo o una dashboard. Un'applicazione aziendale può anche assumere la forma di pipeline di dati operativi o ciclo di feedback. Ad esempio, dopo aver calcolato o previsto le variazioni di prezzo dei prodotti, una pipeline di dati operativi potrebbe aggiornare i nuovi prezzi dei prodotti in un database transazionale.
- Processo upstream
- I sistemi di origine e le pipeline di dati che caricano i dati nel data warehouse.
- Processo downstream
- Gli script, le procedure e le applicazioni aziendali utilizzati per elaborare, eseguire query e visualizzare i dati nel data warehouse.
- Trasferisci migrazione
-
Una strategia di migrazione volta a far funzionare il caso d'uso per l'utente finale nel nuovo ambiente il più rapidamente possibile o a sfruttare la capacità aggiuntiva disponibile nel nuovo ambiente. I casi d'uso vengono scaricati
eseguendo queste operazioni:
- Copia e poi sincronizza lo schema e i dati del data warehouse legacy.
- Migrazione di script, procedure e applicazioni aziendali downstream.
L'offload della migrazione può aumentare la complessità e il lavoro necessari per la migrazione delle pipeline di dati.
- Migrazione completa
- Un approccio alla migrazione simile a una migrazione con offload, ma invece di copiare e sincronizzare lo schema e i dati, devi configurare la migrazione per importare i dati direttamente nel nuovo data warehouse cloud dai sistemi di origine upstream. In altre parole, viene eseguita la migrazione anche delle pipeline di dati richieste per il caso d'uso.
- Data warehouse aziendale (EDW)
- Un data warehouse composto non solo da un database analitico, ma da più componenti e procedure analitici critici. Queste includono pipeline di dati, query e applicazioni aziendali necessarie per soddisfare i carichi di lavoro dell'organizzazione.
- Data warehouse su cloud (CDW)
- Un data warehouse che ha le stesse caratteristiche di un EDW, ma viene eseguito su un servizio completamente gestito nel cloud, in questo caso BigQuery.
- Pipeline di dati
- Un processo che collega i sistemi di dati tramite una serie di funzioni e attività che eseguono vari tipi di trasformazione dei dati. Per maggiori dettagli, consulta Che cos'è una pipeline di dati? di questa serie.
Perché eseguire la migrazione a BigQuery?
Negli ultimi decenni le organizzazioni hanno padroneggiato la scienza del data warehouse. Hanno applicato sempre più analisi descrittive a grandi quantità di dati archiviati, ricavando insight sulle loro operazioni aziendali principali. La business intelligence convenzionale (BI), che si concentra su query, rapporti e elaborazione analitica online, potrebbe essere stato un fattore distintivo in passato, come la creazione o la rottura di un'azienda, ma non è più sufficiente.
Oggi, le organizzazioni non solo hanno bisogno di comprendere gli eventi passati utilizzando l'analisi descrittiva, ma hanno bisogno dell' analisi predittiva, che spesso utilizza il machine learning (ML) per estrarre pattern di dati e fare affermazioni probabilistiche sul futuro. L'obiettivo finale è sviluppare analisi prescrittive che combinano lezioni del passato con previsioni sul futuro per guidare automaticamente le azioni in tempo reale.
Le pratiche di data warehouse tradizionali acquisiscono dati non elaborati da varie origini, che spesso sono sistemi di elaborazione transazionale online (OLTP). Quindi, un sottoinsieme di dati viene estratto in batch, trasformato in base a uno schema definito e caricato nel data warehouse. Poiché i data warehouse tradizionali acquisiscono un sottoinsieme di dati in batch e archiviano i dati in base a schemi rigidi, non sono adatti per gestire l'analisi in tempo reale o per rispondere a query spontanee. Google ha progettato BigQuery in parte in risposta a queste limitazioni intrinseche.
Le idee innovative sono spesso rallentate dalle dimensioni e dalla complessità dell'organizzazione IT che implementa e gestisce i data warehouse tradizionali. La creazione di un'architettura di data warehouse scalabile, alta disponibilità e sicura può richiedere anni e investimenti significativi. BigQuery offre una sofisticata tecnologia Software as a Service (SaaS) che può essere utilizzata per le operazioni di data warehouse serverless. Questo ti consente di concentrarti sul miglioramento del tuo core business, delega la manutenzione dell'infrastruttura e lo sviluppo della piattaforma a Google Cloud.
BigQuery offre accesso a dati strutturati, archiviazione, elaborazione e analisi scalabili, flessibili ed economicamente convenienti. Queste caratteristiche sono essenziali quando i volumi di dati aumentano in modo esponenziale, per rendere disponibili le risorse di archiviazione ed elaborazione in base alle esigenze e per ottenere valore da questi dati. Inoltre, per le organizzazioni che sono alle prime armi con l'analisi dei big data e il machine learning e che vogliono evitare le potenziali complessità dei sistemi di big data on-premise, BigQuery offre una modalità di pagamento a consumo per sperimentare i servizi gestiti.
Con BigQuery puoi trovare risposte a problemi precedentemente intrattabili, applicare il machine learning per scoprire pattern di dati emergenti e testare nuove ipotesi. Di conseguenza, puoi disporre di informazioni tempestive sul rendimento della tua attività, in modo da poter modificare i processi per ottenere risultati migliori. Inoltre, l'esperienza dell'utente finale è spesso arricchita da insight pertinenti ricavati dall'analisi dei big data, come spiegheremo più avanti in questa serie.
Cosa e come eseguire la migrazione: framework per la migrazione
Intraprendere una migrazione può essere un compito complesso e lungo. Pertanto, consigliamo di aderire a un framework per organizzare e strutturare il lavoro di migrazione in più fasi:
- Preparati e scopri: preparati per la migrazione con il carico di lavoro e l'individuazione dei casi d'uso.
- Pianifica: assegna priorità ai casi d'uso, definisci le misure di successo e pianifica la migrazione.
- Esegui: ripeti i passaggi per la migrazione, dalla valutazione alla convalida.
Prepara e scopri
Nella fase iniziale, l'attenzione è rivolta alla preparazione e alla scoperta. Si tratta di offrire a te e agli stakeholder un'opportunità tempestiva per scoprire i casi d'uso esistenti e sollevare le preoccupazioni iniziali. È importante anche condurre un'analisi iniziale sui vantaggi attesi. Questi includono l'aumento delle prestazioni (ad esempio, una migliore contemporaneità) e le riduzioni del costo totale di proprietà (TCO). Questa fase è fondamentale per stabilire il valore della migrazione.
Un data warehouse in genere supporta un'ampia gamma di casi d'uso e include un gran numero di stakeholder, dagli analisti di dati ai responsabili delle decisioni aziendali. Ti consigliamo di coinvolgere i rappresentanti di questi gruppi per capire meglio quali casi d'uso esistono, se hanno un buon rendimento e se gli stakeholder stanno pianificando nuovi casi d'uso.
Il processo della fase di rilevamento prevede le seguenti attività:
- Esamina la proposta di valore di BigQuery e confrontala con quella del tuo data warehouse legacy.
- Eseguire un'analisi iniziale del TCO.
- Stabilisci quali casi d'uso sono interessati dalla migrazione.
- Modellare le caratteristiche dei set di dati e delle pipeline di dati sottostanti di cui vuoi eseguire la migrazione per identificare le dipendenze.
Per ottenere insight sui casi d'uso, puoi sviluppare un questionario per raccogliere informazioni da esperti in materia (PMI), utenti finali e stakeholder. Il questionario deve contenere le seguenti informazioni:
- Qual è l'obiettivo del caso d'uso? Qual è il valore aziendale?
- Quali sono i requisiti non funzionali? l'aggiornamento dei dati, l'uso simultaneo e così via.
- Il caso d'uso fa parte di un carico di lavoro più grande? Dipende da altri casi d'uso?
- Quali set di dati, tabelle e schemi sono alla base del caso d'uso?
- Cosa sai delle pipeline di dati che alimentano questi set di dati?
- Quali strumenti di BI, report e dashboard vengono attualmente utilizzati?
- Quali sono gli attuali requisiti tecnici in materia di esigenze operative, prestazioni, autenticazione e larghezza di banda della rete?
Il seguente diagramma mostra un'architettura legacy di alto livello prima della migrazione. Illustra il catalogo di origini dati disponibili, pipeline di dati legacy, pipeline operative legacy e cicli di feedback, nonché dashboard e report BI legacy a cui gli utenti finali accedono.

Piano
La fase di pianificazione prevede l'acquisizione dell'input della fase di preparazione e rilevamento, la valutazione dell'input e quindi il suo utilizzo per pianificare la migrazione. Questa fase può essere suddivisa nelle seguenti attività:
Catalogo e priorità dei casi d'uso
Ti consigliamo di suddividere il processo di migrazione in iterazioni. Cataloga i casi d'uso esistenti e quelli nuovi e assegna loro una priorità. Per maggiori dettagli, consulta le sezioni Eseguire la migrazione con un approccio iterativo e Assegnare priorità ai casi d'uso di questo documento.
Definire le misure di successo
È utile definire misure chiare del successo, come gli indicatori chiave di prestazione (KPI), prima della migrazione. Le misure ti consentiranno di valutare il successo della migrazione a ogni iterazione. Ciò consente di apportare miglioramenti al processo di migrazione nelle iterazioni successive.
Crea una definizione di "fine"
Nel caso di migrazioni complesse, non è necessariamente evidente quando hai completato la migrazione di un determinato caso d'uso. È quindi bene delineare una definizione formale dello stato finale previsto. Questa definizione dovrebbe essere abbastanza generica da poter essere applicata a tutti i casi d'uso di cui vuoi eseguire la migrazione. La definizione dovrebbe fungere da insieme di criteri minimi da considerare per la migrazione completa del caso d'uso. Questa definizione in genere include punti di controllo per garantire che il caso d'uso sia stato integrato, testato e documentato.
Progettare e proporre un proof-of-concept (POC), uno stato a breve termine e uno stato finale ideale
Dopo aver dato priorità ai casi d'uso, puoi iniziare a pensarli per l'intero periodo della migrazione. Considera la prima migrazione del caso d'uso come proof of concept (PDC) per convalidare l'approccio iniziale alla migrazione. Pensa a ciò che puoi ottenere nelle prime settimane o mesi come stato a breve termine. In che modo i tuoi piani di migrazione influenzeranno gli utenti? L'azienda avrà una soluzione ibrida o puoi prima eseguire la migrazione di un intero carico di lavoro per un sottoinsieme di utenti?
Creare stime di tempi e costi
Per garantire il successo del progetto di migrazione, è importante produrre stime di tempo realistiche. Per raggiungere questo obiettivo, devi coinvolgere tutti gli stakeholder interessati per discutere della loro disponibilità e concordare il loro livello di coinvolgimento durante l'intero progetto. Questo ti aiuterà a stimare i costi di manodopera in modo più accurato. Per stimare i costi relativi al consumo previsto di risorse cloud, vedi Stima dei costi di archiviazione e query e Introduzione al controllo dei costi di BigQuery nella documentazione di BigQuery.
Identificare e coinvolgere un partner per la migrazione
La documentazione di BigQuery descrive molti strumenti e risorse che puoi usare per eseguire la migrazione. Tuttavia, può essere difficile eseguire in autonomia una migrazione grande e complessa se non si ha già alcuna esperienza o non si dispone di tutte le competenze tecniche necessarie all'interno della tua organizzazione. Pertanto, consigliamo di identificare e coinvolgere fin dall'inizio un partner per la migrazione. Per ulteriori dettagli, consulta i nostri programmi per i partner globali e i servizi di consulenza.
Esegui la migrazione con un approccio iterativo
Quando si esegue la migrazione di un'operazione di data warehousing di grandi dimensioni nel cloud, è consigliabile adottare un approccio iterativo. Ti consigliamo quindi di eseguire la transizione a BigQuery in iterazioni. La suddivisione dello sforzo di migrazione in iterazioni semplifica l'intero processo, riduce i rischi e offre opportunità di apprendimento e miglioramento dopo ogni iterazione.
Un'iterazione consiste in tutto il lavoro necessario per eseguire l'offload o la migrazione completa di uno o più casi d'uso correlati entro un periodo di tempo limitato. Puoi pensare a un'iterazione come a un ciclo sprint nella metodologia agile, composta da una o più storie utente.
Per praticità e facilità di monitoraggio, puoi valutare l'associazione di un caso d'uso individuale a una o più storie utente. Ad esempio, prendi in considerazione la seguente storia utente: "In qualità di analista dei prezzi, voglio analizzare le variazioni di prezzo dei prodotti nell'ultimo anno in modo da poter calcolare i prezzi futuri".
Il caso d'uso corrispondente potrebbe essere:
- Importare i dati da un database transazionale in cui sono archiviati prodotti e prezzi.
- Trasformazione dei dati in un'unica serie temporale per ogni prodotto e inserimento di valori mancanti.
- Archiviazione dei risultati in una o più tabelle nel data warehouse.
- Rendere disponibili i risultati tramite un blocco note Python (l'applicazione business).
Il valore aziendale di questo caso d'uso consiste nel supportare l'analisi dei prezzi.
Come nella maggior parte dei casi d'uso, questo caso d'uso probabilmente supporterà più storie utente.
Un caso d'uso scaricato sarà probabilmente seguito da una successiva iterazione per eseguire la migrazione completa del caso d'uso. In caso contrario, potresti comunque avere una dipendenza dal data warehouse legacy esistente, perché i dati vengono copiati da lì. La successiva migrazione completa è il delta tra l'offload e una migrazione completa non preceduta da un offload, in altre parole la migrazione delle pipeline di dati per estrarre, trasformare e caricare i dati nel data warehouse.
Priorità ai casi d'uso
L'inizio e la fine della migrazione dipendono dalle esigenze aziendali specifiche. Decidere l'ordine in cui eseguire la migrazione dei casi d'uso è importante, perché il successo tempestivo di una migrazione è fondamentale per continuare il percorso di adozione del cloud. Un errore in una fase iniziale può rappresentare un grave impedimento per l'impegno complessivo di migrazione. Potresti essere d'accordo con i vantaggi di Google Cloud e BigQuery, ma l'elaborazione di tutti i set di dati e di tutte le pipeline di dati creati o gestiti nel tuo data warehouse legacy per diversi casi d'uso può essere complicato e richiedere molto tempo.
Sebbene non esista una soluzione universale, esistono best practice che puoi utilizzare per valutare i casi d'uso e le applicazioni aziendali on-premise. Questo tipo di pianificazione anticipata può semplificare il processo di migrazione e rendere più fluida l'intera transizione a BigQuery.
Le sezioni seguenti esplorano i possibili approcci per dare priorità ai casi d'uso.
Approccio: sfruttare le opportunità attuali
Osserva le opportunità attuali che potrebbero aiutarti a massimizzare il ritorno sull'investimento di un caso d'uso specifico. Questo approccio è particolarmente utile se ti senti sotto pressione per giustificare il valore aziendale della migrazione al cloud. Inoltre, offre l'opportunità di raccogliere ulteriori punti dati per valutare il costo totale della migrazione.
Ecco alcuni esempi di domande da porre per aiutarti a identificare i casi d'uso a cui dare la priorità:
- Il caso d'uso consiste in set di dati o pipeline di dati attualmente limitati dal data warehouse aziendale legacy?
- Il tuo data warehouse aziendale esistente richiede un aggiornamento dell'hardware o prevedi l'espansione dell'hardware? In tal caso, può essere interessante trasferire i casi d'uso in BigQuery il prima possibile.
Identificare le opportunità di migrazione può creare vantaggi rapidi e offrire vantaggi tangibili e immediati per gli utenti e l'azienda.
Approccio: prima la migrazione dei carichi di lavoro analitici
Esegui la migrazione dei carichi di lavoro dell'elaborazione analitica online (OLAP) prima dei carichi di lavoro dell'elaborazione (OLTP). Un data warehouse è spesso l'unico posto nell'organizzazione in cui si trovano tutti i dati per creare un'unica vista globale delle operazioni dell'organizzazione. Di conseguenza, è comune per le organizzazioni avere alcune pipeline di dati che si alimentano nei sistemi transazionali per aggiornare lo stato o attivare processi, ad esempio per acquistare più articoli quando l'inventario di un prodotto è basso. I carichi di lavoro OLTP tendono a essere più complessi, hanno requisiti operativi più rigorosi e accordi sul livello del servizio (SLA) rispetto ai carichi di lavoro OLAP, per cui tende a essere più semplice eseguire prima la migrazione dei carichi di lavoro OLAP.
Approccio: attenzione all'esperienza utente
Identifica le opportunità per migliorare l'esperienza utente eseguendo la migrazione di set di dati specifici e abilitando nuovi tipi di analisi avanzate. Ad esempio, un modo per migliorare l'esperienza utente è con l'analisi in tempo reale. Puoi creare esperienze utente sofisticate basandoti su un flusso di dati in tempo reale unito a dati storici. Ad esempio:
- Un dipendente del back office ha avvisato tramite un'app mobile che le scorte sono in esaurimento.
- Un cliente online che potrebbe trarre vantaggio dalla consapevolezza che spendendo un altro dollaro lo porterebbe al livello di premio successivo.
- Infermiere che viene avvisato sui parametri vitali di un paziente sullo smartwatch, consentendogli di intraprendere la linea d'azione migliore visualizzando la cronologia di trattamento del paziente sul tablet.
Puoi anche migliorare l'esperienza utente con l'analisi predittiva e prescrittiva. A questo scopo, puoi utilizzare BigQuery ML, dati tabulari AutoML di Vertex AI o i modelli preaddestrati di Google per analisi delle immagini, analisi video, riconoscimento vocale, linguaggio naturale e traduzione. Oppure puoi gestire il tuo modello con addestramento personalizzato utilizzando Vertex AI per i casi d'uso su misura per le tue esigenze aziendali. Ciò potrebbe riguardare quanto segue:
- Consigliare un prodotto in base alle tendenze di mercato e al comportamento di acquisto degli utenti.
- Previsione di un ritardo dei voli.
- Rilevamento di attività fraudolente.
- Segnalare contenuti inappropriati.
- Altre idee innovative che potrebbero differenziare la tua app dalla concorrenza.
Approccio: dare priorità ai casi d'uso meno rischiosi
Ci sono una serie di domande che il reparto IT può porsi per valutare quali casi d'uso sono i meno rischiosi da migrare, il che li rende i più interessanti da sottoporre a migrazione nelle prime fasi della migrazione. Ad esempio:
- Qual è la criticità aziendale di questo caso d'uso?
- Un numero elevato di dipendenti o clienti dipende dal caso d'uso?
- Qual è l'ambiente di destinazione (ad esempio, sviluppo o produzione) per il caso d'uso?
- Qual è la comprensione del caso d'uso da parte del nostro team IT?
- Quante dipendenze e integrazioni ha il caso d'uso?
- Il nostro team IT dispone di una documentazione adeguata, aggiornata e completa per il caso d'uso?
- Quali sono i requisiti operativi (SLA) per il caso d'uso?
- Quali sono i requisiti di conformità legali o governativi per il caso d'uso?
- Quali sono le sensibilità di tempo di inattività e latenza per accedere al set di dati sottostante?
- Ci sono titolari di line-of-business desiderosi e disposti a migrare il proprio caso d'uso in anticipo?
Analizzare questo elenco di domande può aiutarti a classificare i set di dati e le pipeline di dati dal rischio più basso a quello più alto. Occorre eseguire prima la migrazione degli asset a basso rischio, mentre di quelli più a rischio.
Esegui
Dopo aver raccolto informazioni sui sistemi legacy e creato un backlog dei casi d'uso prioritario, puoi raggruppare i casi d'uso in carichi di lavoro e procedere con la migrazione in iterazioni.
Un'iterazione può essere composta da un singolo caso d'uso, alcuni casi d'uso separati o una serie di casi d'uso relativi a un singolo carico di lavoro. Quale di queste opzioni scegli per l'iterazione dipende dall'interconnessione dei casi d'uso, dalle dipendenze condivise e dalle risorse a tua disposizione per svolgere il lavoro.
In genere, una migrazione prevede i seguenti passaggi:
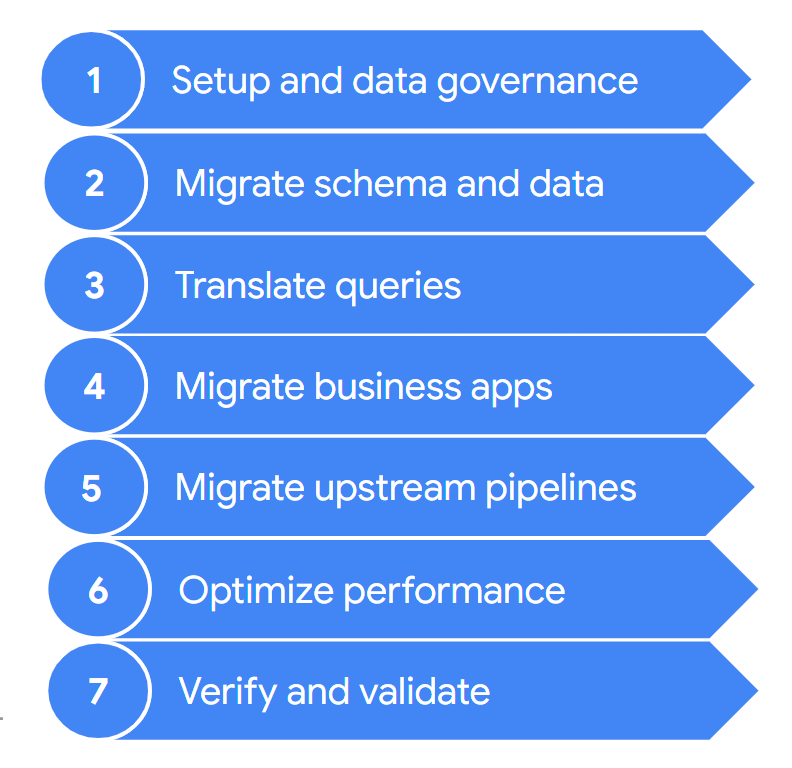
Questi passaggi sono descritti in modo più dettagliato nelle sezioni seguenti. Potresti non dover eseguire tutti questi passaggi in ogni iterazione. Ad esempio, in un'iterazione potresti decidere di concentrarti sulla copia di alcuni dati dal tuo data warehouse legacy a BigQuery. Al contrario, in un'iterazione successiva potresti concentrarti sulla modifica della pipeline di importazione da un'origine dati originale direttamente a BigQuery.
1. Configurazione e governance dei dati
La configurazione è il lavoro di base necessario per consentire l'esecuzione dei casi d'uso su Google Cloud. La configurazione può includere la configurazione dei progetti Google Cloud, della rete, del VPC (Virtual Private Cloud) e della governance dei dati. Inoltre, è necessario capire a fondo dove ti trovi oggi, cosa funziona e cosa no. Questo ti aiuta a comprendere i requisiti per la tua migrazione. Per completare questo passaggio, puoi utilizzare la funzionalità di valutazione della migrazione di BigQuery.
La governance dei dati è un solido approccio per gestire i dati durante il loro ciclo di vita, dall'acquisizione all'uso e allo smaltimento. Il tuo programma di governance dei dati definisce chiaramente norme, procedure, responsabilità e controlli relativi alle attività relative ai dati. Questo programma contribuisce a garantire che le informazioni vengano raccolte, mantenute, utilizzate e distribuite in modo da soddisfare sia l'integrità dei dati che le esigenze di sicurezza della tua organizzazione. Inoltre, consente ai dipendenti di scoprire e usare i dati al massimo delle sue potenzialità.
La documentazione sulla governance dei dati consente di comprendere la governance dei dati e i controlli di cui hai bisogno durante la migrazione del data warehouse on-premise a BigQuery.
2. Esegui la migrazione di schema e dati
Lo schema di data warehouse definisce il modo in cui sono strutturati i dati e le relazioni tra le entità di dati. Lo schema è al centro della progettazione dei dati e influenza molti processi, sia upstream che downstream.
La documentazione su schema e trasferimento di dati fornisce informazioni esaustive su come è possibile spostare i tuoi dati in BigQuery, oltre a suggerimenti per l'aggiornamento dello schema per sfruttare al meglio le funzionalità di BigQuery.
3. Traduci query
Utilizza la traduzione SQL batch per eseguire la migrazione in blocco del codice SQL o la traduzione SQL interattiva per tradurre query ad hoc.
Alcuni data warehouse legacy includono estensioni allo standard SQL per abilitare le funzionalità per il loro prodotto. BigQuery non supporta queste estensioni proprietarie, ma è conforme allo standard ANSI/ISO SQL:2011. Ciò significa che alcune query potrebbero comunque richiedere il refactoring manuale se i traduttori SQL non sono in grado di interpretarle.
4. Migrazione delle applicazioni aziendali
Le applicazioni aziendali possono assumere molte forme, dalle dashboard alle applicazioni personalizzate fino alle pipeline di dati operativi che forniscono cicli di feedback ai sistemi transazionali.
Per ulteriori informazioni sulle opzioni di analisi disponibili con BigQuery, consulta Panoramica dell'analisi di BigQuery. Questo argomento fornisce una panoramica degli strumenti di generazione di report e analisi che puoi utilizzare per ottenere approfondimenti interessanti dai dati.
La sezione sui cicli di feedback nella documentazione relativa alla pipeline di dati descrive come utilizzare una pipeline di dati per creare un ciclo di feedback per il provisioning di sistemi a monte.
5. Esegui la migrazione delle pipeline di dati
La documentazione relativa alle pipeline di dati presenta le procedure, i pattern e le tecnologie per la migrazione delle pipeline di dati legacy a Google Cloud. Ti aiuta a capire cos'è una pipeline di dati, quali procedure e pattern può utilizzare, nonché quali opzioni e tecnologie di migrazione sono disponibili per la migrazione del data warehouse più ampio.
6. Ottimizzazione del rendimento
BigQuery elabora i dati in modo efficiente, sia per set di dati di piccole che petabyte. Con l'aiuto di BigQuery, i job di analisi dei dati dovrebbero funzionare correttamente senza modifiche nel data warehouse appena migrato. Se ritieni che in determinate circostanze le prestazioni delle query non corrispondano alle aspettative, consulta Introduzione all'ottimizzazione delle prestazioni delle query per istruzioni.
7. Verifica e convalida
Al termine di ogni iterazione, verifica che la migrazione dei casi d'uso sia andata a buon fine verificando quanto segue:
- La migrazione dei dati e dello schema è stata completata.
- I problemi di governance dei dati sono stati completamente soddisfatti e testati.
- Sono state stabilite procedure di manutenzione e monitoraggio e automazione.
- Le query sono state tradotte correttamente.
- Le pipeline di dati migrate funzionano come previsto.
- Le applicazioni aziendali sono configurate correttamente per accedere ai dati e alle query di cui è stata eseguita la migrazione.
Puoi iniziare con lo strumento di convalida dei dati, uno strumento dell'interfaccia a riga di comando Python open source che confronta i dati degli ambienti di origine e di destinazione per garantire la corrispondenza. Supporta diversi tipi di connessione oltre alla funzionalità di convalida multilivello.
Inoltre, è una buona idea misurare l'impatto della migrazione dei casi d'uso, ad esempio in termini di miglioramento delle prestazioni, riduzione dei costi o creazione di nuove opportunità tecniche o di business. A questo punto, puoi quantificare con maggiore precisione il valore del ritorno sull'investimento e confrontare il valore con i criteri di successo per l'iterazione.
Dopo la convalida dell'iterazione, puoi rilasciare il caso d'uso migrato in produzione e consentire agli utenti di accedere alle applicazioni aziendali e ai set di dati di cui è stata eseguita la migrazione.
Infine, prendi appunti e documenta le lezioni apprese da questa iterazione, in modo da poterle applicare nella prossima iterazione e accelerare la migrazione.
Sintesi dell'attività di migrazione
Durante la migrazione, esegui sia il data warehouse legacy che BigQuery, come descritto in questo documento. L'architettura di riferimento nel diagramma seguente evidenzia che entrambi i data warehouse offrono funzionalità e percorsi simili: entrambi possono importare dai sistemi di origine, integrarsi con le applicazioni aziendali e fornire l'accesso utente richiesto. È importante sottolineare anche che i dati vengono sincronizzati dal data warehouse a BigQuery. In questo modo è possibile eseguire l'offload dei casi d'uso per l'intera durata dell'attività di migrazione.

Supponendo che il tuo intento sia eseguire la migrazione completa dal tuo data warehouse a BigQuery, lo stato finale della migrazione sarà il seguente:

Passaggi successivi
Scopri di più sui seguenti passaggi della migrazione del data warehouse:
- Valutazione della migrazione
- Panoramica del trasferimento di schemi e dati
- Pipeline di dati
- Traduzione SQL batch
- Traduzione SQL interattiva
- Sicurezza e governance dei dati
- Strumento di convalida dei dati
Puoi anche scoprire come passare da tecnologie di data warehouse specifiche a BigQuery:
- Migrazione da Netezza
- Migrazione da Oracle
- Eseguire la migrazione da Amazon Redshift
- Migrazione da Teradata
- Migrazione da Snowflake