Trasferimenti dei rapporti Cloud Storage
Il connettore BigQuery Data Transfer Service per Cloud Storage ti consente di pianificare e caricamenti ricorrenti di dati da Cloud Storage a BigQuery.
Prima di iniziare
Prima di creare un trasferimento di dati Cloud Storage, svolgi i seguenti passaggi:
- Verifica di aver completato tutte le azioni richieste in Attivazione di BigQuery Data Transfer Service.
- Recupera l'URI Cloud Storage.
- Crea un set di dati BigQuery per archiviare i dati.
- Crea la tabella di destinazione per il trasferimento dei dati e specifica la definizione dello schema.
- Se prevedi di specificare una chiave di crittografia gestita dal cliente (CMEK), assicurati che il tuo account di servizio disponga delle autorizzazioni necessarie per criptare e decriptare, e che tu abbia l'ID risorsa della chiave Cloud KMS necessario per usare CMEK. Per informazioni su come CMEK funziona con BigQuery Data Transfer Service, consulta Specificare la chiave di crittografia con i trasferimenti.
Limitazioni
I trasferimenti di dati ricorrenti da Cloud Storage a BigQuery sono soggetti alle seguenti limitazioni:
- Tutti i file corrispondenti ai pattern definiti da un carattere jolly o dal runtime per il trasferimento di dati devono condividere lo stesso schema definito per la tabella di destinazione, altrimenti il trasferimento non andrà a buon fine. Lo schema della tabella cambia tra causa anche la mancata riuscita del trasferimento.
- Poiché gli oggetti Cloud Storage possono essere versionati, è importante notare che gli oggetti Cloud Storage archiviati non sono supportati per i trasferimenti di dati di BigQuery. Per essere conformi, gli oggetti devono essere attivi trasferito.
- A differenza dei caricamenti singoli di dati da Cloud Storage a BigQuery, per i trasferimenti di dati continui devi creare la tabella di destinazione prima di configurare il trasferimento. Per i file CSV e JSON, devi anche definire schema della tabella in anticipo. BigQuery Impossibile creare la tabella nell'ambito del processo di trasferimento di dati ricorrente.
- Data Transfer da Cloud Storage imposta il parametro Write preference su
APPENDper impostazione predefinita. In questa modalità, un file non modificato può essere caricato solo BigQuery una sola volta. Se la proprietàlast modification timedel file viene aggiornato, il file verrà ricaricato. BigQuery Data Transfer Service non garantisce che tutti i file saranno trasferiti o trasferiti solo una volta se vengono modificati i file di Cloud Storage durante un trasferimento di dati. Quando carichi dati in: BigQuery da un bucket Cloud Storage:
Se la località del set di dati è impostata su un valore diverso dall'area multiregionale
US, il bucket Cloud Storage deve trovarsi nella stessa regione o contenuto nella stessa località (multiregionale) del set di dati.BigQuery non garantisce la coerenza dei dati esterni fonti. Le modifiche ai dati sottostanti durante l'esecuzione di una query possono comportare un comportamento imprevisto.
BigQuery non supporta il controllo delle versioni degli oggetti Cloud Storage. Se includi un numero di generazione nell'URI di Cloud Storage, il job di caricamento non riesce.
A seconda del formato dei dati di origine di Cloud Storage, potrebbero esserci limitazioni aggiuntive. Per ulteriori informazioni, vedi:
Il bucket Cloud Storage deve trovarsi in una località compatibile con la regione o le regioni del set di dati di destinazione in in BigQuery. Questa operazione è nota come colocation. Per maggiori dettagli, consulta le Località dei dati per il trasferimento di Cloud Storage.
Intervalli minimi
- I file di origine vengono rilevati immediatamente per il trasferimento dei dati, senza limiti di tempo minimi.
- L'intervallo di tempo minimo tra un trasferimento di dati ricorrente è di 15 minuti. L'intervallo predefinito per un trasferimento dati ricorrente è ogni 24 ore.
Autorizzazioni obbligatorie
Quando carichi i dati in BigQuery, hai bisogno di autorizzazioni che ti consentano di caricare i dati in tabelle e partizioni BigQuery nuove o esistenti. Se carichi i dati da Cloud Storage, devi anche avere accesso al bucket che li contiene. Assicurati di disporre delle seguenti autorizzazioni obbligatorie:
BigQuery: assicurati che la persona o l'account di servizio la creazione del trasferimento di dati le seguenti autorizzazioni in BigQuery:
- Autorizzazioni
bigquery.transfers.updateper creare il trasferimento di dati - Autorizzazioni
bigquery.datasets.getebigquery.datasets.updateattive il set di dati di destinazione
Il ruolo IAM predefinito
bigquery.admininclude le autorizzazionibigquery.transfers.update,bigquery.datasets.updateebigquery.datasets.get. Per ulteriori informazioni sui ruoli IAM in BigQuery Data Transfer Service, consulta Controllo dell'accesso.- Autorizzazioni
Cloud Storage: sono necessarie
storage.objects.getautorizzazioni su al singolo bucket o di livello superiore. Se utilizzi un URI jolly, devi disporre anche delle autorizzazionistorage.objects.list. Se desideri eliminare i file di origine dopo ogni trasferimento riuscito, è necessariostorage.objects.deleteautorizzazioni. Il ruolo IAM predefinitostorage.objectAdmininclude tutte queste autorizzazioni.
Configura un trasferimento Cloud Storage
Per creare un trasferimento di dati Cloud Storage in BigQuery Data Transfer Service:
Console
Vai alla pagina Trasferimenti di dati nella console Google Cloud.
Fai clic su Crea trasferimento.
Nella sezione Tipo di origine, per Origine, scegli Google Cloud Storage.
Nella sezione Nome configurazione di trasferimento, in Nome visualizzato, inserisci un nome per il trasferimento dei dati, ad esempio
My Transfer. Il nome del trasferimento può essere qualsiasi valore che ti consenta di identificare il trasferimento se devi modificarlo in un secondo momento.
Nella sezione Opzioni di pianificazione:
Seleziona Frequenza di ripetizione. Se selezioni Ore, Giorni, Settimane o Mesi, devi anche specificare una frequenza. Puoi anche selezionare Personalizzata per specificare una frequenza di ripetizione personalizzata. Se selezioni On demand, questo trasferimento di dati viene eseguito attivi manualmente il trasferimento.
Se applicabile, seleziona Inizia ora o Inizia all'ora impostata e fornisci una data di inizio e un'ora di esecuzione.
Nella sezione Impostazioni destinazione, per Set di dati di destinazione, scegli il set di dati che hai creato per archiviare i tuoi dati.
Nella sezione Dettagli origine dati:
- In Tabella di destinazione, inserisci il nome della tabella di destinazione. La tabella di destinazione deve seguire le regole di denominazione delle tabelle. I nomi delle tabelle di destinazione supportano anche i parametri.
- In URI Cloud Storage, inserisci URI Cloud Storage. I caratteri jolly e i parametri sono supportati.
- Per Preferenza di scrittura, scegli:
- APPEND per aggiungere in modo incrementale nuovi dati ai tuoi dati esistenti tabella di destinazione. APPEND è il valore predefinito per Scrittura la tua preferenza.
- MIRROR per sovrascrivere i dati nella tabella di destinazione durante ogni esecuzione del trasferimento dati.
Per ulteriori informazioni su come BigQuery Data Transfer Service importa utilizzando APPEND o MIRROR, vedi Importazione dei dati per i trasferimenti di Cloud Storage. Per ulteriori informazioni sul campo
writeDisposition, consultaJobConfigurationLoad- Per Elimina file di origine dopo il trasferimento, seleziona la casella se vuoi eliminare i file di origine dopo ogni trasferimento di dati riuscito. L'eliminazione dei job avviene secondo il criterio del massimo impegno. I job di eliminazione non riprovano se il primo tentativo di eliminazione dei file di origine non va a buon fine.
Nella sezione Opzioni di trasferimento:
- In Tutti i formati:
- In Numero di errori consentiti, inserisci il numero massimo
di record non validi che BigQuery può ignorare quando
che esegue il job. Se il numero di record non validi supera questo
valore, un valore "non valido" viene restituito un errore nel risultato del job,
e il job non va a buon fine. Il valore predefinito è
0. - (Facoltativo) Per Tipi di targeting decimale, inserisci un
un elenco separato da virgole di possibili tipi di dati SQL che
i valori decimali di origine. Il tipo di dato SQL selezionato per la conversione dipende dalle seguenti condizioni:
- Il tipo di dati selezionato per la conversione sarà il primo tipo di dati dell'elenco seguente che supporta la precisione e la scala dei dati di origine, ordine: NUMERIC, BIGNUMERIC e STRING.
- Se nessuno dei tipi di dati elencati supporta la precisione e la scala, viene selezionato il tipo di dati che supporta l'intervallo più ampio nell'elenco specificato. Se un valore supera l'intervallo supportato durante la lettura dei dati di origine, verrà generato un errore.
- Il tipo di dati STRING supporta tutti i valori di precisione e scala.
- Se questo campo viene lasciato vuoto, il tipo di dati sarà "NUMERIC,STRING" per ORC e "NUMERIC" per gli altri formati file.
- Questo campo non può contenere tipi di dati duplicati.
- L'ordine dei tipi di dati elencati in questa viene ignorato.
- In Numero di errori consentiti, inserisci il numero massimo
di record non validi che BigQuery può ignorare quando
che esegue il job. Se il numero di record non validi supera questo
valore, un valore "non valido" viene restituito un errore nel risultato del job,
e il job non va a buon fine. Il valore predefinito è
- In JSON, CSV:
- Per Ignora valori sconosciuti, seleziona la casella se vuoi che il trasferimento dei dati elimini i dati che non corrispondono allo schema della tabella di destinazione.
- In AVRO:
- Per Utilizza tipi logici Avro, seleziona la casella se vuoi che il trasferimento dei dati converta i tipi logici Avro nei tipi di dati BigQuery corrispondenti. La
Il comportamento predefinito è ignorare l'attributo
logicalTypeper la maggior parte dei tipi e utilizza il tipo Avro sottostante .
- Per Utilizza tipi logici Avro, seleziona la casella se vuoi che il trasferimento dei dati converta i tipi logici Avro nei tipi di dati BigQuery corrispondenti. La
Il comportamento predefinito è ignorare l'attributo
In CSV:
- In Delimitatore di campo, inserisci il carattere che separa campi. Il valore predefinito è una virgola.
- In Carattere virgolette, inserisci il carattere utilizzato per citare le sezioni di dati in un file CSV. Il valore predefinito è una quota doppia (
"). - In Righe di intestazione da saltare, inserisci il numero di righe di intestazione
nei file sorgente se non vuoi importarli. Il valore predefinito è
0. - In Consenti nuove righe tra virgolette, seleziona la casella se vuoi consenti ritorni a capo all'interno dei campi tra virgolette.
- Per Consenti righe frastagliate, seleziona la casella se vuoi consentire il trasferimento dei dati delle righe con colonne
NULLABLEmancanti.
- In Tutti i formati:
Nel menu Account di servizio, seleziona un account di servizio dagli account di servizio associati progetto Google Cloud. Puoi associare un account di servizio al trasferimento dei dati anziché utilizzare le credenziali utente. Per ulteriori informazioni sull'utilizzo degli account di servizio con i trasferimenti di dati, consulta Utilizzare gli account di servizio.
- Se hai eseguito l'accesso con un'identità federata, è necessario un account di servizio per creare un trasferimento di dati. Se hai firmato con un Account Google, poi l'account di servizio per il trasferimento di dati è facoltativo.
- L'account di servizio deve disporre delle autorizzazioni richieste. sia per BigQuery che per Cloud Storage.
(Facoltativo) Nella sezione Opzioni di notifica:
- Fai clic sul pulsante di attivazione/disattivazione per attivare le notifiche via email. Quando attivi questa opzione, il proprietario della configurazione del trasferimento dati riceve una notifica via email quando un'esecuzione del trasferimento non va a buon fine.
- In Seleziona un argomento Pub/Sub, scegli il nome dell'argomento o fai clic su Crea un argomento. Questa opzione configura le notifiche di esecuzione di Pub/Sub per il trasferimento.
(Facoltativo) Nella sezione Opzioni avanzate:
- Se utilizzi le chiavi CMEK, seleziona Chiave gestita dal cliente. Un elenco delle CMEK disponibili tra cui scegliere.
Per informazioni sul funzionamento delle CMEK con BigQuery Data Transfer Service, consulta Specificare la chiave di crittografia con i trasferimenti.
Fai clic su Salva.
bq
Inserisci il comando bq mk e fornisci il flag di creazione del trasferimento:
--transfer_config. Sono necessari anche i seguenti flag:
--data_source--display_name--target_dataset--params
Flag facoltativi:
--destination_kms_key: specifica l'ID risorsa chiave per la chiave Cloud KMS se utilizzi una chiave di crittografia gestita dal cliente (CMEK) per questo trasferimento di dati. Per informazioni su come funzionano le CMEK in BigQuery Data Transfer Service, consulta Specificare la chiave di crittografia con i trasferimenti.--service_account_name: specifica un account di servizio da utilizzare per l'autenticazione del trasferimento di Cloud Storage anziché il tuo account utente.
bq mk \ --transfer_config \ --project_id=PROJECT_ID \ --data_source=DATA_SOURCE \ --display_name=NAME \ --target_dataset=DATASET \ --destination_kms_key="DESTINATION_KEY" \ --params='PARAMETERS' \ --service_account_name=SERVICE_ACCOUNT_NAME
Dove:
- PROJECT_ID è l'ID progetto. Se
--project_idnon è fornito per specificare un particolare progetto, viene usato il progetto predefinito. - DATA_SOURCE è l'origine dati, ad esempio
google_cloud_storage. - NAME è il nome visualizzato della configurazione di trasferimento dei dati. La Transfer name può essere qualsiasi valore che ti consenta di identificare se devi modificarlo in un secondo momento.
- DATASET è il set di dati di destinazione per la configurazione del trasferimento.
- DESTINATION_KEY: l'ID risorsa chiave Cloud KMS, ad esempio
projects/project_name/locations/us/keyRings/key_ring_name/cryptoKeys/key_name. - PARAMETERS contiene i parametri per il trasferimento creato
configurazione in formato JSON. Ad esempio:
--params='{"param":"param_value"}'.destination_table_name_template: il nome della destinazione Tabella BigQuery.data_path_template: l'URI Cloud Storage che contiene file da trasferire, che può includere un carattere jolly.write_disposition: determina se i file corrispondenti vengono aggiunti alla tabella di destinazione o se ne viene eseguito il mirroring per intero. I valori supportati sonoAPPENDoMIRROR. Per informazioni su come BigQuery Data Transfer Service aggiunge o esegue il mirroring dei dati nei trasferimenti di Cloud Storage, consulta Importazione dei dati per i trasferimenti di Cloud Storage.file_format: il formato dei file che vuoi trasferire. Il formato può essereCSV,JSON,AVRO,PARQUEToORC. Il valore predefinito èCSV.max_bad_records: per qualsiasi valorefile_format, il numero massimo di record non validi che possono essere ignorati. Il valore predefinito è0.decimal_target_types: per qualsiasi valorefile_format, separato da virgole elenco dei possibili tipi di dati SQL da cui potrebbero essere i valori decimali di origine in cui viene convertito. Se questo campo non viene fornito, il tipo di dati predefinito sarà"NUMERIC,STRING"perORCe"NUMERIC"per gli altri formati file.ignore_unknown_values: per qualsiasi valorefile_format, imposta suTRUEper accettare righe contenenti valori che non corrispondono . Per ulteriori informazioni, consulta i dettagli del campoignoreUnknownvaluesnella tabella di riferimentoJobConfigurationLoad.use_avro_logical_types: per i valoriAVROfile_format, imposta suTRUEper interpretare i tipi logici nei tipi corrispondenti (per esempio,TIMESTAMP), anziché utilizzare solo i tipi non elaborati (per esempio,INTEGER).parquet_enum_as_string: per i valoriPARQUETfile_format, imposta suTRUEper dedurre il tipo logicoPARQUETENUMcomeSTRINGanziché il valore predefinitoBYTES.parquet_enable_list_inference: perPARQUETvalorifile_format, impostato aTRUEper utilizzare l'inferenza dello schema specifica perPARQUETLISTtipo logico.reference_file_schema_uri: un percorso URI a un file di riferimento con lo schema del lettore.field_delimiter: perCSVvalorifile_format, un carattere che separa i campi. Il valore predefinito è una virgola.quote: per i valorifile_formatdiCSV, un carattere utilizzato per le sezioni di dati delle citazioni in un file CSV. Il valore predefinito è una doppia virgolette (").skip_leading_rows: per i valorifile_formatdiCSV, indica il numero di righe di intestazione iniziali che non si desidera importare. Il valore predefinito è 0.allow_quoted_newlines: per i valoriCSVfile_format, impostaTRUEper consentire i ritorni a capo all'interno dei campi tra virgolette.allow_jagged_rows: per i valoriCSVfile_format, imposta suTRUEper accettare le righe che non hanno le colonne finali facoltative. I valori mancanti vengono compilati conNULL.preserve_ascii_control_characters: perCSVvalorifile_format, impostato suTRUEper conservare tutti i caratteri di controllo ASCII incorporati.encoding: specifica il tipo di codificaCSV. I valori supportati sonoUTF8,ISO_8859_1,UTF16BE,UTF16LE,UTF32BEeUTF32LE.delete_source_files: impostato suTRUEper eliminare i file di origine dopo ogni trasferimento riuscito. I job di eliminazione non vengono eseguiti di nuovo se il primo tentativo di eliminare il file di origine non va a buon fine. Il valore predefinito èFALSE.
- SERVICE_ACCOUNT_NAME è il nome dell'account di servizio utilizzato
di autenticare il trasferimento. L'account di servizio deve
essere di proprietà dello stesso
project_idusato per creare il trasferimento; devono disporre di tutte le autorizzazioni richieste.
Ad esempio, il seguente comando crea un trasferimento di dati Cloud Storage denominato My Transfer utilizzando un valore data_path_template di gs://mybucket/myfile/*.csv, il set di dati di destinazione mydataset e file_format
CSV. Questo esempio include valori non predefiniti per i parametri facoltativi associati al file_format CSV.
Il trasferimento dei dati viene creato nel progetto predefinito:
bq mk --transfer_config \
--target_dataset=mydataset \
--project_id=myProject \
--display_name='My Transfer' \
--destination_kms_key=projects/myproject/locations/mylocation/keyRings/myRing/cryptoKeys/myKey \
--params='{"data_path_template":"gs://mybucket/myfile/*.csv",
"destination_table_name_template":"MyTable",
"file_format":"CSV",
"max_bad_records":"1",
"ignore_unknown_values":"true",
"field_delimiter":"|",
"quote":";",
"skip_leading_rows":"1",
"allow_quoted_newlines":"true",
"allow_jagged_rows":"false",
"delete_source_files":"true"}' \
--data_source=google_cloud_storage \
--service_account_name=abcdef-test-sa@abcdef-test.iam.gserviceaccount.com projects/862514376110/locations/us/transferConfigs/ 5dd12f26-0000-262f-bc38-089e0820fe38
Dopo aver eseguito il comando, viene visualizzato un messaggio simile al seguente:
[URL omitted] Please copy and paste the above URL into your web browser and
follow the instructions to retrieve an authentication code.
Segui le istruzioni e incolla il codice di autenticazione nel comando dalla riga di comando.
API
Utilizza la projects.locations.transferConfigs.create
e fornisce un'istanza del metodo TransferConfig
risorsa.
Java
Prima di provare questo esempio, segui le istruzioni per la configurazione di Java nel Guida rapida di BigQuery con librerie client. Per ulteriori informazioni, consulta API Java BigQuery documentazione di riferimento.
Per eseguire l'autenticazione su BigQuery, configura Credenziali predefinite dell'applicazione. Per saperne di più, consulta Configurare l'autenticazione per le librerie client.
Specifica la chiave di crittografia con trasferimenti
Puoi specificare le chiavi di crittografia gestite dal cliente (CMEK) per crittografare i dati per un'esecuzione di trasferimento. Puoi utilizzare una CMEK per supportare i trasferimenti da Cloud Storage.Quando specifichi una CMEK con un trasferimento, BigQuery Data Transfer Service applica la CMEK a qualsiasi cache intermedia su disco dei dati importati in modo che l'intero flusso di lavoro di trasferimento dei dati sia conforme alla CMEK.
Non puoi aggiornare un trasferimento esistente per aggiungere un CMEK se il trasferimento non è stato creato inizialmente con un CMEK. Ad esempio, non puoi modificare una destinazione che in origine era criptata per impostazione predefinita e ora è crittografata con CMEK. Al contrario, non puoi neanche modificare una tabella di destinazione criptata con CMEK un tipo diverso di crittografia.
Puoi aggiornare un CMEK per un trasferimento se la configurazione del trasferimento è stata creata inizialmente con una crittografia CMEK. Quando aggiorni una CMEK per un trasferimento configurazione, BigQuery Data Transfer Service propaga la CMEK alla destinazione alla successiva esecuzione del trasferimento, in cui BigQuery Data Transfer Service sostituisce qualsiasi CMEK obsoleta con la nuova durante l'esecuzione del trasferimento. Per ulteriori informazioni, consulta Aggiornare un trasferimento.
Puoi anche usare le chiavi predefinite di progetto. Quando specifichi una chiave predefinita del progetto con un trasferimento, BigQuery Data Transfer Service la utilizza come chiave predefinita per tutte le nuove configurazioni di trasferimento.
Attivare manualmente un trasferimento
Oltre ai trasferimenti di dati pianificati automaticamente da Cloud Storage, puoi attivare manualmente un trasferimento per caricare file di dati aggiuntivi.
Se la configurazione di trasferimento è runtime con parametri, devi specificare un intervallo di date per le quali i trasferimenti aggiuntivi saranno a iniziare.
Per attivare un trasferimento di dati:
Console
Vai alla pagina BigQuery nella console Google Cloud.
Fai clic su Trasferimenti di dati.
Seleziona il trasferimento dati dall'elenco.
Fai clic su Esegui trasferimento ora o Pianifica backfill (per il runtime configurazioni di trasferimento parametrizzate).
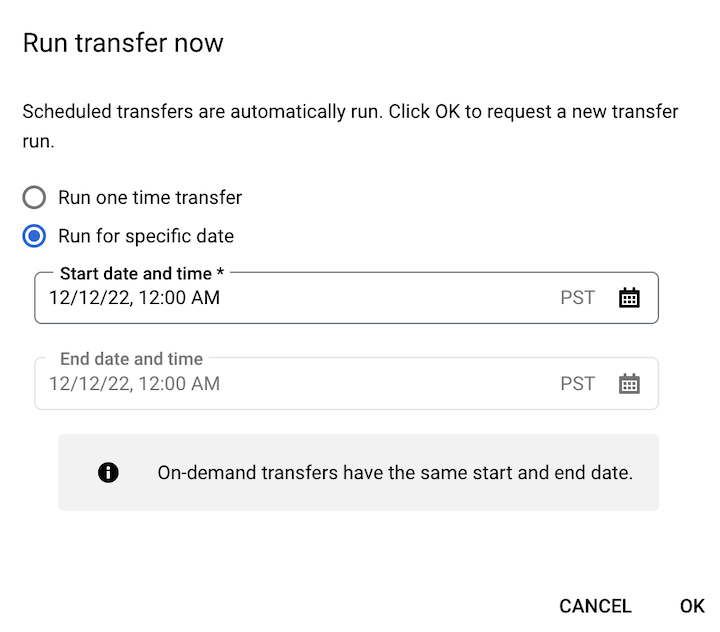
Se hai fatto clic su Esegui trasferimento ora, seleziona Esegui trasferimento una tantum o Esegui per data specifica, a seconda dei casi. Se hai selezionato Esegui per una data specifica, seleziona una data e un'ora specifiche:
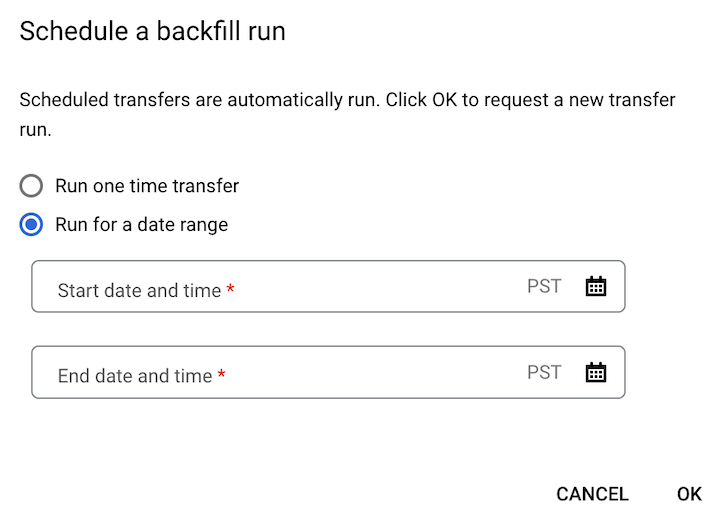
Se hai fatto clic su Pianifica backfill, seleziona Esegui trasferimento una tantum o Esegui per un intervallo di date, a seconda dei casi. Se hai selezionato Esegui per un intervallo di date, seleziona una data e un'ora di inizio e di fine:
Fai clic su Ok.
bq
Inserisci il comando bq mk.
e fornisce il flag --transfer_run. Puoi utilizzare --run_time
o i flag --start_time e --end_time.
bq mk \ --transfer_run \ --start_time='START_TIME' \ --end_time='END_TIME' \ RESOURCE_NAME
bq mk \ --transfer_run \ --run_time='RUN_TIME' \ RESOURCE_NAME
Dove:
START_TIME e END_TIME sono timestamp che terminano con
Zo contenere un offset di fuso orario valido. Ad esempio:2017-08-19T12:11:35.00Z2017-05-25T00:00:00+00:00
RUN_TIME è un timestamp che specifica l'orario di pianificazione durante l'esecuzione del trasferimento dei dati. Se vuoi eseguire un trasferimento una tantum per il momento corrente, puoi utilizzare il flag
--run_time.RESOURCE_NAME è il nome della risorsa del trasferimento (chiamato anche come configurazione di trasferimento), ad esempio
projects/myproject/locations/us/transferConfigs/1234a123-1234-1a23-1be9-12ab3c456de7. Se non conosci la risorsa del trasferimento esegui il comandobq ls --transfer_config --transfer_location=LOCATIONper trovare il nome della risorsa.
API
Utilizza la projects.locations.transferConfigs.startManualRuns
e fornire la risorsa di configurazione del trasferimento utilizzando il metodo parent
.
Passaggi successivi
- Scopri di più sui parametri di runtime nei trasferimenti di Cloud Storage.
- Scopri di più su BigQuery Data Transfer Service.