이 튜토리얼에서는 BigQuery ML의 선형 회귀 모델을 사용하여 펭귄의 통계 정보를 기반으로 펭귄의 체중을 예측합니다. 선형 회귀는 입력 특성의 선형 조합에서 연속 값을 생성하는 회귀 모델의 한 유형입니다.
이 튜토리얼에서는 bigquery-public-data.ml_datasets.penguins 데이터 세트를 사용합니다.
목표
이 튜토리얼에서는 다음 작업을 수행합니다.
- 선형 회귀 모델 만들기
- 모델 평가
- 모델을 사용하여 예측 수행
비용
이 튜토리얼에서는 비용이 청구될 수 있는 다음과 같은 Google Cloud구성요소를 사용합니다.
- BigQuery
- BigQuery ML
BigQuery 비용에 대한 자세한 내용은 BigQuery 가격 책정 페이지를 참조하세요.
BigQuery ML 비용에 대한 자세한 내용은 BigQuery ML 가격 책정을 참조하세요.
시작하기 전에
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the BigQuery API.
필수 권한
BigQuery ML을 사용하여 모델을 만들려면 다음 IAM 권한이 필요합니다.
bigquery.jobs.createbigquery.models.createbigquery.models.getDatabigquery.models.updateDatabigquery.models.updateMetadata
추론을 실행하려면 다음 권한이 필요합니다.
- 모델에 대한
bigquery.models.getData bigquery.jobs.create
데이터 세트 만들기
ML 모델을 저장할 BigQuery 데이터 세트를 만듭니다.
콘솔
Google Cloud 콘솔에서 BigQuery 페이지로 이동합니다.
탐색기 창에서 프로젝트 이름을 클릭합니다.
작업 보기 > 데이터 세트 만들기를 클릭합니다.

데이터 세트 만들기 페이지에서 다음을 수행합니다.
데이터 세트 ID에
bqml_tutorial를 입력합니다.위치 유형에 대해 멀티 리전을 선택한 다음 US(미국 내 여러 리전)를 선택합니다.
나머지 기본 설정은 그대로 두고 데이터 세트 만들기를 클릭합니다.
bq
새 데이터 세트를 만들려면 --location 플래그와 함께 bq mk 명령어를 실행합니다. 사용할 수 있는 전체 파라미터 목록은 bq mk --dataset 명령어 참조를 확인하세요.
데이터 위치가
US로 설정되고 설명이BigQuery ML tutorial dataset인bqml_tutorial데이터 세트를 만듭니다.bq --location=US mk -d \ --description "BigQuery ML tutorial dataset." \ bqml_tutorial
--dataset플래그를 사용하는 대신 이 명령어는-d단축키를 사용합니다.-d와--dataset를 생략하면 이 명령어는 기본적으로 데이터 세트를 만듭니다.데이터 세트가 생성되었는지 확인합니다.
bq ls
API
데이터 세트 리소스가 정의된 datasets.insert 메서드를 호출합니다.
{ "datasetReference": { "datasetId": "bqml_tutorial" } }
BigQuery DataFrames
이 샘플을 사용해 보기 전에 BigQuery DataFrames를 사용하여 BigQuery 빠른 시작의 BigQuery DataFrames 설정 안내를 따르세요. 자세한 내용은 BigQuery DataFrames 참고 문서를 확인하세요.
BigQuery에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 로컬 개발 환경의 ADC 설정을 참조하세요.
모델 만들기
BigQuery용 애널리틱스 샘플 데이터 세트를 사용하여 선형 회귀 모델을 만듭니다.
SQL
CREATE MODEL 문을 사용하고 모델 유형에 LINEAR_REG를 지정하여 선형 회귀 모델을 만들 수 있습니다. 모델 생성에는 모델 학습이 포함됩니다.
다음은 CREATE MODEL 문에 대해 알아두면 유용한 정보입니다.
input_label_cols옵션은SELECT문에서 라벨 열로 사용할 열을 지정합니다. 여기에서 라벨 열은body_mass_g입니다. 선형 회귀 모델에서 라벨 열은 실수치여야 합니다. 즉, 해당 열 값이 실수여야 합니다.이 쿼리의
SELECT문은bigquery-public-data.ml_datasets.penguins테이블의 다음 열을 사용하여 펭귄의 몸무게를 예측합니다.species: 펭귄의 종입니다.island: 펭귄이 서식하는 섬입니다.culmen_length_mm: 펭귄 부리 길이(밀리미터)입니다.culmen_depth_mm: 펭귄 부리 두께(밀리미터)입니다.flipper_length_mm: 펭귄 지느러미 길이(밀리미터)입니다.sex: 펭귄의 성별입니다.
이 쿼리의
SELECT문WHERE body_mass_g IS NOT NULL의WHERE절은body_mass_g열이NULL인 행을 제외합니다.
선형 회귀 모델을 만드는 쿼리를 실행합니다.
Google Cloud 콘솔에서 BigQuery 페이지로 이동합니다.
쿼리 편집기 창에서 다음 쿼리를 실행합니다.
CREATE OR REPLACE MODEL `bqml_tutorial.penguins_model` OPTIONS (model_type='linear_reg', input_label_cols=['body_mass_g']) AS SELECT * FROM `bigquery-public-data.ml_datasets.penguins` WHERE body_mass_g IS NOT NULL;
penguins_model모델을 만드는 데 약 30초가 걸립니다. 모델을 보려면 탐색기 창으로 이동하여bqml_tutorial데이터 세트를 펼친 다음 모델 폴더를 펼칩니다.
BigQuery DataFrames
이 샘플을 사용해 보기 전에 BigQuery DataFrames를 사용하여 BigQuery 빠른 시작의 BigQuery DataFrames 설정 안내를 따르세요. 자세한 내용은 BigQuery DataFrames 참고 문서를 확인하세요.
BigQuery에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 로컬 개발 환경의 ADC 설정을 참조하세요.
모델을 만드는 데 약 30초가 걸립니다. 모델을 보려면 탐색기 창으로 이동하여 bqml_tutorial 데이터 세트를 펼친 다음 모델 폴더를 펼칩니다.
학습 통계 가져오기
모델 학습 결과를 확인하려면 ML.TRAINING_INFO 함수를 사용하거나 Google Cloud 콘솔에서 통계를 보면 됩니다. 이 튜토리얼에서는 Google Cloud 콘솔을 사용합니다.
머신러닝 알고리즘은 많은 예를 검사하고 손실을 최소화하는 모델을 찾으려고 시도함으로써 모델을 빌드합니다. 이 프로세스를 경험적 위험 최소화라고 합니다.
손실은 잘못된 예측에 대한 페널티입니다. 예를 들어 모델 예측이 얼마나 잘못되었는지를 나타내는 숫자입니다. 모델의 예측이 완벽하면 손실은 0이고 그렇지 않으면 손실은 그보다 커집니다. 모델 학습의 목표는 모든 예시에서 평균적으로 손실이 적은 가중치와 편향의 집합을 찾는 것입니다.
CREATE MODEL 쿼리를 실행할 때 생성된 모델 학습 통계를 확인합니다.
탐색기 창에서
bqml_tutorial데이터 세트를 펼친 다음 모델 폴더를 펼칩니다. penguins_model을 클릭하여 모델 정보 창을 엽니다.학습 탭을 클릭한 후 테이블을 클릭합니다. 결과는 다음과 비슷하게 표시됩니다.
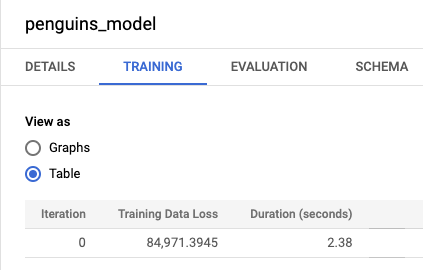
학습 데이터 손실 열은 학습 데이터 세트에서 모델 학습이 진행된 후 계산된 손실 측정항목을 나타냅니다. 선형 회귀를 수행했으므로 이 열에는 평균 제곱 오차 값이 표시됩니다. 이 학습에는 normal_equation 최적화 전략이 자동으로 사용되므로 반복 1회만 최종 모델에 수렴하면 됩니다. 모델 최적화 전략 설정에 관한 자세한 내용은
optimize_strategy를 참고하세요.
모델 평가
모델을 만든 후 ML.EVALUATE 함수 또는 score BigQuery DataFrames 함수를 사용하여 모델이 생성한 예측 값을 실제 데이터와 비교하여 모델의 성능을 평가합니다.
SQL
입력의 경우 ML.EVALUATE 함수는 모델을 학습시키는 데 사용한 데이터의 스키마와 일치하는 데이터 세트와 학습된 모델을 사용합니다. 프로덕션 환경에서는 모델 학습에 사용한 데이터와 다른 데이터로 모델을 평가해야 합니다.
입력 데이터를 제공하지 않고 ML.EVALUATE를 실행하면 이 함수는 학습 중에 계산된 평가 측정항목을 가져옵니다. 이러한 측정항목은 자동으로 예약된 평가 데이터 세트를 사용하여 계산됩니다.
SELECT
*
FROM
ML.EVALUATE(MODEL bqml_tutorial.penguins_model);
ML.EVALUATE 쿼리 실행:
Google Cloud 콘솔에서 BigQuery 페이지로 이동합니다.
쿼리 편집기 창에서 다음 쿼리를 실행합니다.
SELECT * FROM ML.EVALUATE(MODEL `bqml_tutorial.penguins_model`, ( SELECT * FROM `bigquery-public-data.ml_datasets.penguins` WHERE body_mass_g IS NOT NULL));
BigQuery DataFrames
이 샘플을 사용해 보기 전에 BigQuery DataFrames를 사용하여 BigQuery 빠른 시작의 BigQuery DataFrames 설정 안내를 따르세요. 자세한 내용은 BigQuery DataFrames 참고 문서를 확인하세요.
BigQuery에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 로컬 개발 환경의 ADC 설정을 참조하세요.
결과는 다음과 비슷하게 표시됩니다.
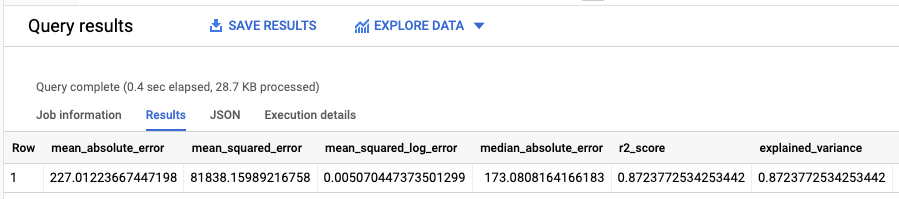
선형 회귀를 수행했으므로 결과에 다음 열이 포함됩니다.
mean_absolute_errormean_squared_errormean_squared_log_errormedian_absolute_errorr2_scoreexplained_variance
평가 결과에서 중요 측정항목은 R2 점수입니다.
R2 점수는 선형 회귀 예측이 실제 데이터에 가까운지 알 수 있는 통계 척도입니다. 0 값은 모델이 평균 주위 응답 데이터의 변동성을 전혀 설명하지 못한다는 것을 나타냅니다. 1 값은 모델이 평균 주위 응답 데이터의 변동성을 모두 설명한다는 것을 나타냅니다.
Google Cloud 콘솔의 모델 정보 창에서도 평가 측정항목을 볼 수 있습니다.
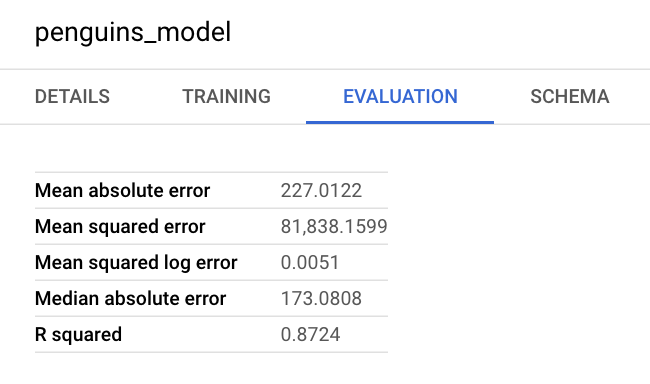
모델을 사용하여 결과 예측
모델을 평가했으므로 다음 단계에서는 이 모델을 사용하여 결과를 예측합니다. 모델에서 ML.PREDICT 함수 또는 predict BigQuery DataFrames 함수를 실행하면 비스코 제도에 서식하는 모든 펭귄의 체질량을 그램 단위로 예측할 수 있습니다.
SQL
입력의 경우 ML.PREDICT 함수는 라벨 열을 제외하고 모델을 학습시키는 데 사용한 데이터의 스키마와 일치하는 데이터 세트와 학습된 모델을 사용합니다.
ML.PREDICT 쿼리 실행:
Google Cloud 콘솔에서 BigQuery 페이지로 이동합니다.
쿼리 편집기 창에서 다음 쿼리를 실행합니다.
SELECT * FROM ML.PREDICT(MODEL `bqml_tutorial.penguins_model`, ( SELECT * FROM `bigquery-public-data.ml_datasets.penguins` WHERE island = 'Biscoe'));
BigQuery DataFrames
이 샘플을 사용해 보기 전에 BigQuery DataFrames를 사용하여 BigQuery 빠른 시작의 BigQuery DataFrames 설정 안내를 따르세요. 자세한 내용은 BigQuery DataFrames 참고 문서를 확인하세요.
BigQuery에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 로컬 개발 환경의 ADC 설정을 참조하세요.
결과는 다음과 비슷하게 표시됩니다.

예측 결과 설명
SQL
모델에서 이러한 예측 결과를 생성하는 이유를 알아보려면 ML.EXPLAIN_PREDICT 함수를 사용하면 됩니다.
ML.EXPLAIN_PREDICT는 ML.PREDICT 함수의 확장된 버전입니다.
ML.EXPLAIN_PREDICT는 예측 결과를 출력할 뿐만 아니라 예측 결과를 설명하는 추가 열을 출력합니다. 실제로는 ML.PREDICT 대신 ML.EXPLAIN_PREDICT를 실행할 수 있습니다. 자세한 내용은 BigQuery ML Explainable AI 개요를 참조하세요.
ML.EXPLAIN_PREDICT 쿼리 실행:
- Google Cloud 콘솔에서 BigQuery 페이지로 이동합니다.
- 쿼리 편집기 창에서 다음 쿼리를 실행합니다.
SELECT * FROM ML.EXPLAIN_PREDICT(MODEL `bqml_tutorial.penguins_model`, ( SELECT * FROM `bigquery-public-data.ml_datasets.penguins` WHERE island = 'Biscoe'), STRUCT(3 as top_k_features));
결과는 다음과 비슷하게 표시됩니다.
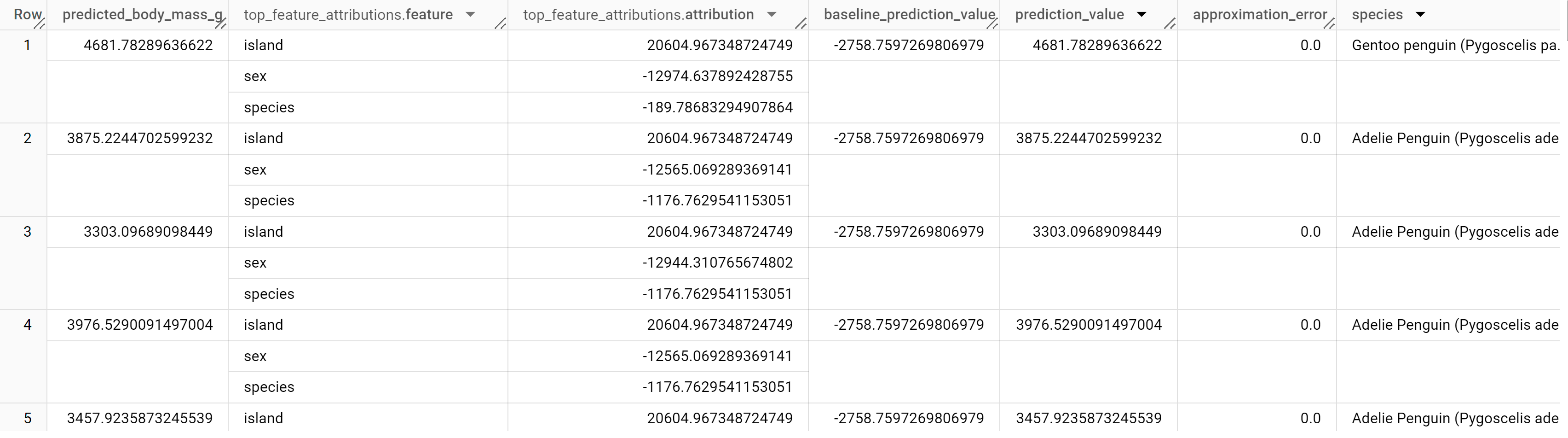
BigQuery DataFrames
이 샘플을 사용해 보기 전에 BigQuery DataFrames를 사용하여 BigQuery 빠른 시작의 BigQuery DataFrames 설정 안내를 따르세요. 자세한 내용은 BigQuery DataFrames 참고 문서를 확인하세요.
BigQuery에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 로컬 개발 환경의 ADC 설정을 참조하세요.
선형 회귀 모델에서 Shapley 값은 모델의 각 특성에 대해 특성 기여값을 생성하는 데 사용됩니다. top_k_features가 3으로 설정되어 있었으므로 출력에는 penguins 테이블의 행당 특성 기여 항목 최상위 3개가 포함됩니다. 이러한 기여 항목은 절댓값을 기준으로 내림차순으로 정렬됩니다. 모든 예시에서 sex 특성이 전체 예측에 가장 많이 기여했습니다.
모델을 전역적으로 설명
SQL
일반적으로 펭귄 체중을 결정하는 데 가장 중요한 특성이 무엇인지 알아보려면 ML.GLOBAL_EXPLAIN 함수를 사용하면 됩니다.
ML.GLOBAL_EXPLAIN을 사용하려면 ENABLE_GLOBAL_EXPLAIN 옵션을 TRUE로 설정하여 모델을 다시 학습시켜야 합니다.
다시 학습시키고 모델의 전역 설명을 가져옵니다.
- Google Cloud 콘솔에서 BigQuery 페이지로 이동합니다.
쿼리 편집기에서 다음 쿼리를 실행하여 모델을 재학습합니다.
#standardSQL CREATE OR REPLACE MODEL `bqml_tutorial.penguins_model` OPTIONS ( model_type = 'linear_reg', input_label_cols = ['body_mass_g'], enable_global_explain = TRUE) AS SELECT * FROM `bigquery-public-data.ml_datasets.penguins` WHERE body_mass_g IS NOT NULL;
쿼리 편집기에서 다음 쿼리를 실행하여 전역 설명을 가져옵니다.
SELECT * FROM ML.GLOBAL_EXPLAIN(MODEL `bqml_tutorial.penguins_model`)
결과는 다음과 비슷하게 표시됩니다.
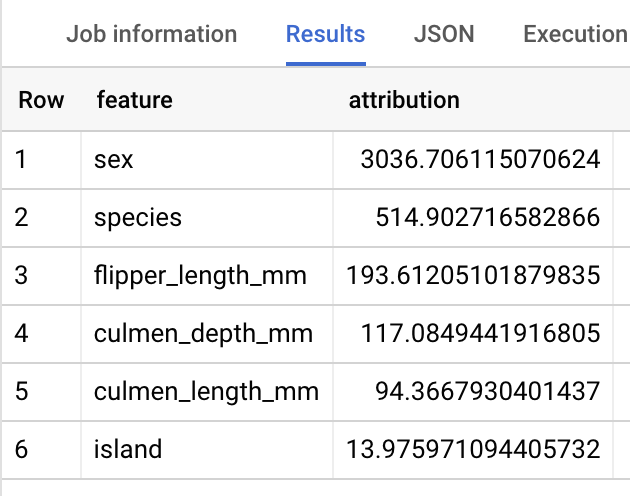
BigQuery DataFrames
이 샘플을 사용해 보기 전에 BigQuery DataFrames를 사용하여 BigQuery 빠른 시작의 BigQuery DataFrames 설정 안내를 따르세요. 자세한 내용은 BigQuery DataFrames 참고 문서를 확인하세요.
BigQuery에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 로컬 개발 환경의 ADC 설정을 참조하세요.
삭제
이 튜토리얼에서 사용된 리소스 비용이 Google Cloud 계정에 청구되지 않도록 하려면 리소스가 포함된 프로젝트를 삭제하거나 프로젝트를 유지하고 개별 리소스를 삭제하세요.
- 만든 프로젝트를 삭제할 수 있습니다.
- 또는 프로젝트를 유지하고 데이터 세트를 삭제할 수 있습니다.
데이터 세트 삭제
프로젝트를 삭제하면 프로젝트의 데이터 세트와 테이블이 모두 삭제됩니다. 프로젝트를 다시 사용하려면 이 튜토리얼에서 만든 데이터 세트를 삭제할 수 있습니다.
필요한 경우Google Cloud 콘솔에서 BigQuery 페이지를 엽니다.
앞서 만든 bqml_tutorial 데이터 세트를 탐색에서 선택합니다.
창의 오른쪽에 있는 데이터 세트 삭제를 클릭합니다. 데이터 세트, 테이블, 모든 데이터가 삭제됩니다.
데이터 세트 삭제 대화상자에서 데이터 세트 이름(
bqml_tutorial)을 입력하여 삭제 명령어를 확인한 후 삭제를 클릭합니다.
프로젝트 삭제
프로젝트를 삭제하는 방법은 다음과 같습니다.
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
다음 단계
- BigQuery ML 개요는 BigQuery ML 소개를 참조하세요.
- 모델 만들기에 대한 자세한 내용은
CREATE MODEL구문 페이지를 참조하세요.