BigQuery ML admite el aprendizaje no supervisado. Puedes aplicar el algoritmo k-means para agrupar tus datos en clústeres. A diferencia del aprendizaje automático supervisado, que es sobre estadísticas predictivas, el aprendizaje no supervisado tiene que ver con estadísticas descriptivas. Se trata de comprender los datos para poder tomar decisiones basadas en datos.
En este instructivo, usas un modelo de k-means en BigQuery ML para compilar clústeres de datos en el conjunto de datos públicos Alquileres de bicicletas de Londres. Los datos de Alquileres de bicicletas de Londres contienen la cantidad de alquileres del Esquema de alquileres de bicicletas Santander de Londres desde 2011 hasta el presente. Los datos incluyen marcas de tiempo de inicio y parada, nombres de estaciones y duración del viaje.
Las consultas en este instructivo usan Funciones de geografía disponibles en estadísticas geoespaciales. Si deseas obtener más información sobre las estadísticas geoespaciales, consulta Introducción a las estadísticas geoespaciales.
Objetivos
En este instructivo, harás lo siguiente:- Crear un modelo de agrupamiento en clústeres de k-means
- Tomar decisiones basadas en datos según la visualización de BigQuery ML de los clústeres.
Costos
En este instructivo, se usan componentes facturables de Google Cloud, incluidos los siguientes:
- BigQuery
- BigQuery ML
Para obtener información sobre los costos de BigQuery, consulta la página Precios de BigQuery.
Si deseas obtener información sobre los precios de BigQuery ML, consulta los precios de BigQuery ML.
Antes de comenzar
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
- BigQuery se habilita automáticamente en proyectos nuevos.
Para activar BigQuery en un proyecto existente, ve a
Enable the BigQuery API.
Introducción
Tus datos pueden contener agrupaciones o clústeres de datos naturales, y se recomienda identificar estas agrupaciones de forma descriptiva para tomar decisiones basadas en datos. Por ejemplo, si eres un minorista, es posible que desees identificar las agrupaciones naturales de clientes que tengan hábitos o lugares de compra similares. Este proceso se conoce como segmentación de clientes.
Los datos que usas para realizar la segmentación de clientes pueden incluir la tienda que visitaron, qué artículos compraron y cuánto pagaron. Deberías crear un modelo para tratar de entender cómo son estos grupos de clientes a fin de que puedas diseñar artículos que atraigan a los miembros del grupo.
También puedes encontrar grupos de productos entre los artículos comprados. En este caso, agruparías los artículos en clústeres, en función de quién los compró, cuándo se compraron, dónde se compraron y otras características similares. Deberías crear un modelo para determinar las características de un grupo de productos para que puedas tomar decisiones fundamentadas, como la forma de mejorar la venta cruzada.
En este instructivo, usas BigQuery ML para crear un modelo de k-means que agrupa en clústeres los datos de Alquileres de bicicletas en Londres en función de los atributos de las estaciones de bicicletas.
La creación de tu modelo de k-means consta de los siguientes pasos:
- Paso uno: Crea un conjunto de datos para almacenar tu modelo.
- El primer paso es crear un conjunto de datos que almacene tu modelo.
- Paso dos: Examina tus datos de entrenamiento.
- El siguiente paso es examinar los datos que utilizas para entrenar tu modelo de agrupamiento en clústeres mediante la ejecución de una consulta en la tabla
london_bicycles. Debido a que k-means es una técnica de aprendizaje no supervisado, el entrenamiento de modelos no requiere etiquetas ni que dividas los datos en datos de entrenamiento y de evaluación.
- Paso tres: Crea un modelo de k-means.
- El tercer paso es crear tu modelo de k-means. Cuando creas el modelo, el campo de agrupación en clústeres es
station_namey agrupa los datos según el atributo de estación, por ejemplo, la distancia de la estación al centro de la ciudad.
- Paso cuatro: Usa la función
ML.PREDICTpara predecir el clúster de una estación. - A continuación, usa la función
ML.PREDICTpara predecir el clúster de un conjunto determinado de estaciones. Puedes predecir clústeres para todos los nombres de estaciones que contengan la stringKennington.
- Paso cuatro: Usa la función
- Paso cinco: Usa tu modelo para tomar decisiones basadas en datos.
- El último paso es usar el modelo para tomar decisiones basadas en datos. Por ejemplo, en función de los resultados del modelo, puedes determinar qué estaciones se beneficiarían de una capacidad adicional.
Paso uno: Crea tu conjunto de datos
Crea un conjunto de datos de BigQuery para almacenar tu modelo de AA:
En la consola de Google Cloud, ve a la página de BigQuery.
En el panel Explorador, haz clic en el nombre de tu proyecto.
Haz clic en Ver acciones > Crear conjunto de datos.
En la página Crear conjunto de datos, haz lo siguiente:
En ID del conjunto de datos, ingresa
bqml_tutorial.En Tipo de ubicación (Location type), selecciona Multirregión (Multi-region) y, luego, UE (varias regiones en la Unión Europea) (EU [multiple regions in European Union]).
El conjunto de datos públicos de Alquileres de bicicletas de Londres se almacena en la multirregión
EU. Tu conjunto de datos debe estar en la misma ubicación.Deja la configuración predeterminada restante como está y haz clic en Crear conjunto de datos(Create dataset).

Paso dos: Examina los datos de entrenamiento.
A continuación, examina los datos usados para entrenar tu modelo de k-means. En este instructivo, agruparás en clústeres las estaciones de bicicletas en función de los siguientes atributos:
- Duración de los alquileres
- Cantidad de viajes por día
- Distancia desde el centro de la ciudad
SQL
La siguiente consulta de GoogleSQL se usa a fin de examinar los datos usados para entrenar tu modelo de k-means.
#standardSQL
WITH
hs AS (
SELECT
h.start_station_name AS station_name,
IF
(EXTRACT(DAYOFWEEK
FROM
h.start_date) = 1
OR EXTRACT(DAYOFWEEK
FROM
h.start_date) = 7,
"weekend",
"weekday") AS isweekday,
h.duration,
ST_DISTANCE(ST_GEOGPOINT(s.longitude,
s.latitude),
ST_GEOGPOINT(-0.1,
51.5))/1000 AS distance_from_city_center
FROM
`bigquery-public-data.london_bicycles.cycle_hire` AS h
JOIN
`bigquery-public-data.london_bicycles.cycle_stations` AS s
ON
h.start_station_id = s.id
WHERE
h.start_date BETWEEN CAST('2015-01-01 00:00:00' AS TIMESTAMP)
AND CAST('2016-01-01 00:00:00' AS TIMESTAMP) ),
stationstats AS (
SELECT
station_name,
isweekday,
AVG(duration) AS duration,
COUNT(duration) AS num_trips,
MAX(distance_from_city_center) AS distance_from_city_center
FROM
hs
GROUP BY
station_name, isweekday )
SELECT
*
FROM
stationstats
ORDER BY
distance_from_city_center ASC
Detalles de la consulta
Esta consulta extrae datos sobre el alquiler de bicicletas, incluidos start_station_name y duration, y los une con la información de la estación, incluida distance-from-city-center. Luego, calcula los atributos de la estación en stationstats, incluida la duración promedio de los viajes y la cantidad de viajes, y pasa por el atributo de estación distance_from_city_center.
En esta consulta, se usa la cláusula WITH para definir subconsultas. También se usan las funciones de estadísticas geoespaciales ST_DISTANCE y ST_GEOGPOINT. Para obtener más información sobre estas funciones, consulta Funciones geográficas. Si deseas obtener más información sobre las estadísticas geoespaciales, consulta Introducción a las estadísticas geoespaciales.
Ejecuta la consulta
La siguiente consulta compila tus datos de entrenamiento y también se usa en la declaración CREATE MODEL más adelante en este instructivo.
Para ejecutar la consulta, haz lo siguiente:
- Ve a la página de BigQuery.
En el panel del editor, ejecuta la siguiente instrucción de SQL:
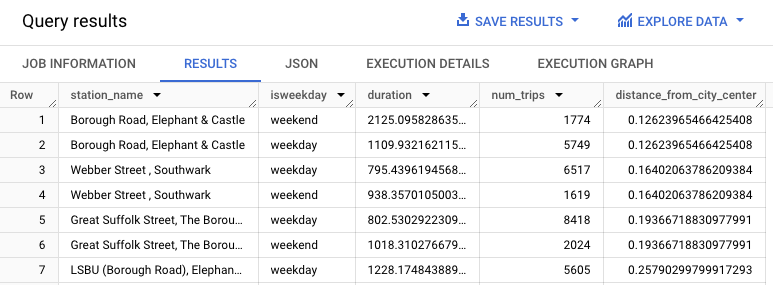
WITH hs AS ( SELECT h.start_station_name AS station_name, IF (EXTRACT(DAYOFWEEK FROM h.start_date) = 1 OR EXTRACT(DAYOFWEEK FROM h.start_date) = 7, "weekend", "weekday") AS isweekday, h.duration, ST_DISTANCE(ST_GEOGPOINT(s.longitude, s.latitude), ST_GEOGPOINT(-0.1, 51.5))/1000 AS distance_from_city_center FROM `bigquery-public-data.london_bicycles.cycle_hire` AS h JOIN `bigquery-public-data.london_bicycles.cycle_stations` AS s ON h.start_station_id = s.id WHERE h.start_date BETWEEN CAST('2015-01-01 00:00:00' AS TIMESTAMP) AND CAST('2016-01-01 00:00:00' AS TIMESTAMP) ), stationstats AS ( SELECT station_name, isweekday, AVG(duration) AS duration, COUNT(duration) AS num_trips, MAX(distance_from_city_center) AS distance_from_city_center FROM hs GROUP BY station_name, isweekday ) SELECT * FROM stationstats ORDER BY distance_from_city_center ASCCuando la consulta finalice, haz clic en la pestaña Resultados (Results) debajo del área de texto de la consulta. La pestaña de resultados muestra las columnas consultadas que se utilizan para entrenar su modelo:
station_name,duration,num_trips,distance_from_city_center. Los resultados deberían verse de la siguiente manera.
BigQuery DataFrames
Antes de probar este ejemplo, sigue las instrucciones de configuración de BigQuery DataFrames en la guía de inicio rápido de BigQuery con BigQuery DataFrames. Para obtener más información, consulta la documentación de referencia de BigQuery DataFrames.
Para autenticarte en BigQuery, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
Paso tres: Crea un modelo de k-means
Ahora que examinaste tus datos de entrenamiento, el siguiente paso es crear un modelo de k-means con los datos.
SQL
Puedes crear y entrenar un modelo k-means mediante la declaración CREATE MODEL con la opción model_type=kmeans.
Detalles de la consulta
La declaración CREATE MODEL especifica la cantidad de clústeres que se usarán: cuatro. En la declaración SELECT, la cláusula EXCEPT excluye la columna station_name porque station_name no es un atributo. La consulta crea una fila única por station_name y en la declaración SELECT solo se mencionan los atributos.
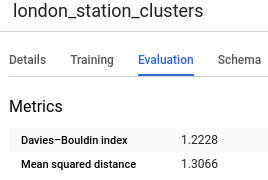
Si omites la opción num_clusters, BigQuery ML elige un valor predeterminado razonable según la cantidad total de filas en los datos de entrenamiento. También puedes realizar el ajuste de hiperparámetros para encontrar una cantidad apropiada. Con el fin de determinar una cantidad óptima de clústeres, deberías ejecutar la consulta CREATE MODEL para diferentes valores de num_clusters, buscar la medida de error y elegir el punto en el que la medida de error esté en su valor mínimo. Para obtener la medida de error, selecciona tu modelo y haz clic en la pestaña Evaluación. En esta pestaña, se muestra el índice de Davies-Bouldin.
Ejecuta la consulta
En la siguiente consulta, se agrega una declaración CREATE MODEL a la consulta que usaste para examinar los datos de entrenamiento y, también, se quitan los campos id en los datos.
Para ejecutar la consulta y crear un modelo de k-means, haz lo siguiente:
- Ve a la página de BigQuery.
En el panel del editor, ejecuta la siguiente instrucción de SQL:
CREATE OR REPLACE MODEL `bqml_tutorial.london_station_clusters` OPTIONS(model_type='kmeans', num_clusters=4) AS WITH hs AS ( SELECT h.start_station_name AS station_name, IF (EXTRACT(DAYOFWEEK FROM h.start_date) = 1 OR EXTRACT(DAYOFWEEK FROM h.start_date) = 7, "weekend", "weekday") AS isweekday, h.duration, ST_DISTANCE(ST_GEOGPOINT(s.longitude, s.latitude), ST_GEOGPOINT(-0.1, 51.5))/1000 AS distance_from_city_center FROM `bigquery-public-data.london_bicycles.cycle_hire` AS h JOIN `bigquery-public-data.london_bicycles.cycle_stations` AS s ON h.start_station_id = s.id WHERE h.start_date BETWEEN CAST('2015-01-01 00:00:00' AS TIMESTAMP) AND CAST('2016-01-01 00:00:00' AS TIMESTAMP) ), stationstats AS ( SELECT station_name, isweekday, AVG(duration) AS duration, COUNT(duration) AS num_trips, MAX(distance_from_city_center) AS distance_from_city_center FROM hs GROUP BY station_name, isweekday) SELECT * EXCEPT(station_name, isweekday) FROM stationstatsEn el panel de navegación, en la sección Recursos, expande el nombre de tu proyecto, haz clic en bqml_tutorial y, luego, en london_station_clusters.
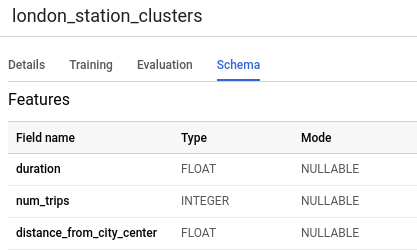
Haz clic en la pestaña Esquema (Schema). El esquema del modelo enumera los cuatro atributos de estación que BigQuery ML usó para realizar el agrupamiento en clústeres. El esquema debe verse de la siguiente manera.
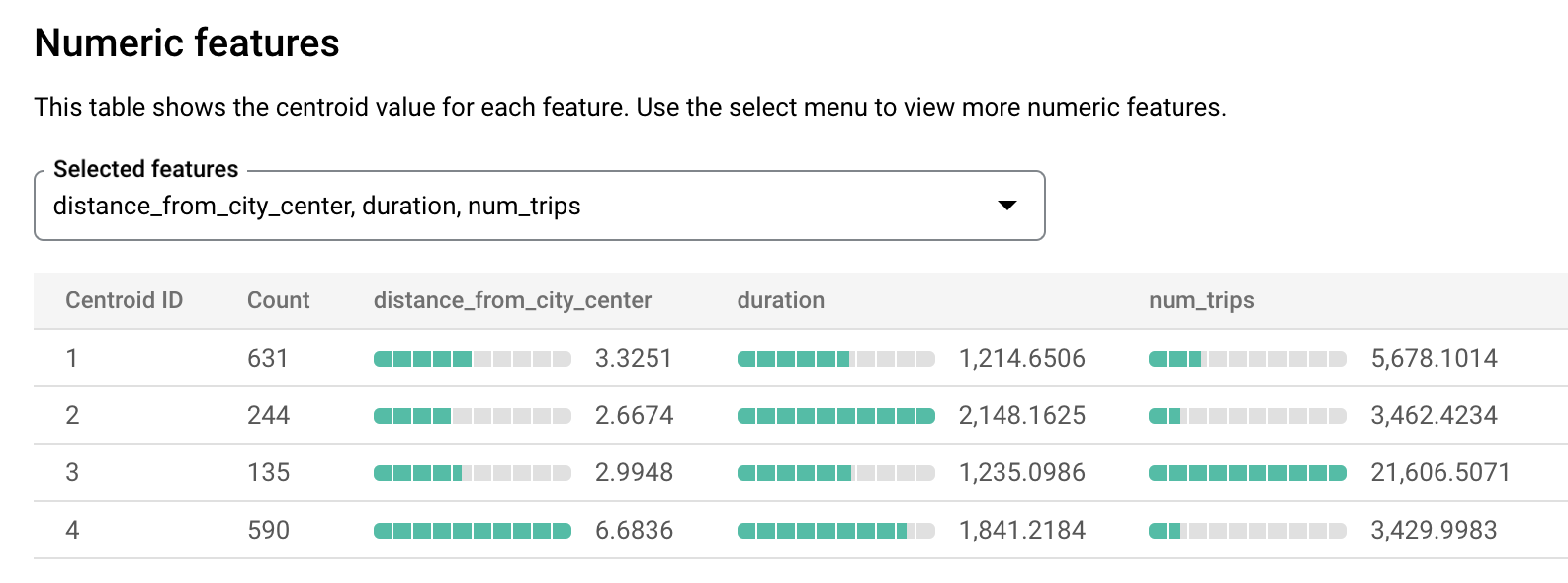
- Haz clic en la pestaña Evaluación (Evaluation). Esta pestaña muestra visualizaciones de los clústeres identificados por el modelo k-means. En Atributos numéricos, los gráficos de barras muestran hasta 10 de los valores de atributos numéricos más importantes para cada centroide. Puedes seleccionar qué atributos visualizar en el menú desplegable.
BigQuery DataFrames
Antes de probar este ejemplo, sigue las instrucciones de configuración de BigQuery DataFrames en la guía de inicio rápido de BigQuery con BigQuery DataFrames. Para obtener más información, consulta la documentación de referencia de BigQuery DataFrames.
Para autenticarte en BigQuery, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
Paso cuatro: Usa la función ML.PREDICT para predecir el clúster de una estación
Para identificar el clúster al que pertenece una estación en particular, usa la función ML.PREDICT de SQL o la función predict de BigQuery DataFrame
SQL
Detalles de la consulta
En esta consulta, se usa la función REGEXP_CONTAINS para buscar todas las entradas en la columna station_name que contienen la string “Kennington”. La función ML.PREDICT usa esos valores para predecir qué clústeres contendrían esas estaciones.
Ejecuta la consulta
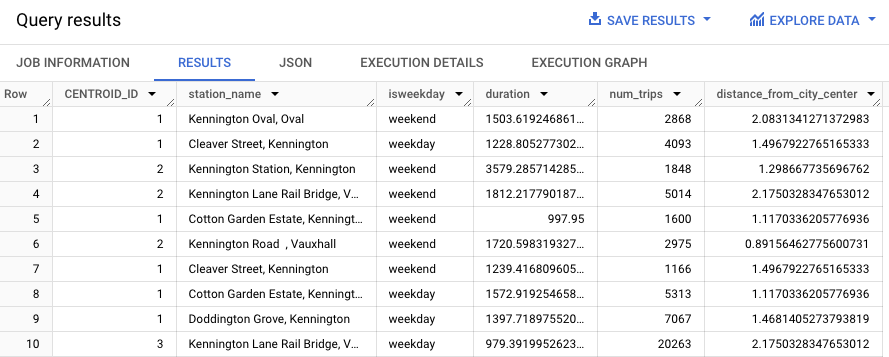
La siguiente consulta predice el clúster de cada estación que tiene la string “Kennington” en su nombre.
Para ejecutar la consulta ML.PREDICT, sigue estos pasos:
- Ve a la página de BigQuery.
En el panel del editor, ejecuta la siguiente instrucción de SQL:
WITH hs AS ( SELECT h.start_station_name AS station_name, IF (EXTRACT(DAYOFWEEK FROM h.start_date) = 1 OR EXTRACT(DAYOFWEEK FROM h.start_date) = 7, "weekend", "weekday") AS isweekday, h.duration, ST_DISTANCE(ST_GEOGPOINT(s.longitude, s.latitude), ST_GEOGPOINT(-0.1, 51.5))/1000 AS distance_from_city_center FROM `bigquery-public-data.london_bicycles.cycle_hire` AS h JOIN `bigquery-public-data.london_bicycles.cycle_stations` AS s ON h.start_station_id = s.id WHERE h.start_date BETWEEN CAST('2015-01-01 00:00:00' AS TIMESTAMP) AND CAST('2016-01-01 00:00:00' AS TIMESTAMP) ), stationstats AS ( SELECT station_name, isweekday, AVG(duration) AS duration, COUNT(duration) AS num_trips, MAX(distance_from_city_center) AS distance_from_city_center FROM hs GROUP BY station_name, isweekday ) SELECT * EXCEPT(nearest_centroids_distance) FROM ML.PREDICT( MODEL `bqml_tutorial.london_station_clusters`, ( SELECT * FROM stationstats WHERE REGEXP_CONTAINS(station_name, 'Kennington')))Cuando la consulta finalice, haz clic en la pestaña Resultados (Results) debajo del área de texto de la consulta. Los resultados deberían verse de la siguiente manera.
BigQuery DataFrames
Antes de probar este ejemplo, sigue las instrucciones de configuración de BigQuery DataFrames en la guía de inicio rápido de BigQuery con BigQuery DataFrames. Para obtener más información, consulta la documentación de referencia de BigQuery DataFrames.
Para autenticarte en BigQuery, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
Paso cinco: Usa tu modelo para tomar decisiones basadas en datos
Los resultados de la evaluación pueden ayudarte a interpretar los diferentes clústeres. En el siguiente ejemplo, el centroide 3 muestra una estación urbana concurrida que está cerca del centro de la ciudad. El Centroide 2 muestra la segunda estación de la ciudad que está menos ocupada y que se usa para alquileres de mayor duración. El centroide 1 muestra una estación de la ciudad menos ocupada, con alquileres de menor duración. El centroide 4 muestra una estación suburbana con viajes que son más largos.
En función de estos resultados, puedes usar los datos para comunicar tus decisiones. Por ejemplo:
Supongamos que necesitas experimentar con un tipo nuevo de anclaje. ¿Qué clúster de estaciones deberías elegir para realizar este experimento? Las estaciones los centroides 1, 2 o 4 parecen opciones lógicas porque no son las estaciones más concurridas.
Supongamos que deseas abastecer algunas estaciones con bicicletas de carrera. ¿Qué estaciones debes elegir? El centroide 4 es el grupo de estaciones que están lejos del centro de la ciudad y tienen los viajes más largos. Estas son las posibles candidatas para las bicicletas de carrera.
Limpia
Para evitar que se apliquen cargos a tu cuenta de Google Cloud por los recursos usados en este instructivo, borra el proyecto que contiene los recursos o conserva el proyecto y borra los recursos individuales.
- Puedes borrar el proyecto que creaste.
- De lo contrario, puedes mantener el proyecto y borrar el conjunto de datos.
Borra tu conjunto de datos
Borrar tu proyecto quita todos sus conjuntos de datos y tablas. Si prefieres volver a usar el proyecto, puedes borrar el conjunto de datos que creaste en este instructivo:
Si es necesario, abre la página de BigQuery en la consola de Google Cloud.
En el panel de navegación, haz clic en el conjunto de datos bqml_tutorial que creaste.
Haz clic en Borrar conjunto de datos en el lado derecho de la ventana. Esta acción borra el conjunto de datos y el modelo.
En el cuadro de diálogo Borrar conjunto de datos, escribe el nombre del conjunto de datos (
bqml_tutorial) para confirmar el comando de borrado y, luego, haz clic en Borrar.
Borra tu proyecto
Para borrar el proyecto, haz lo siguiente:
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Próximos pasos
- Para obtener una descripción general de BigQuery ML, consulta Introducción a BigQuery ML.
- Para obtener información sobre cómo crear modelos, consulta la página de sintaxis de
CREATE MODEL.