이 튜토리얼에서는 데이터 분석가에게 BigQuery ML의 행렬 분해 모델을 소개합니다. BigQuery ML을 사용하면 BigQuery에서 SQL 쿼리를 사용하여 머신러닝 모델을 만들고 실행할 수 있습니다. 목표는 SQL 실무자가 기존 도구를 사용하여 모델을 빌드할 수 있도록 지원하여 머신러닝을 대중화하고 데이터 이동의 필요성을 제거하여 개발 속도를 향상시키는 것입니다.
이 가이드에서는 movielens1m 데이터 세트를 사용하여 명시적 의견에서 모델을 만들어 영화 ID와 사용자 ID를 기반으로 추천을 생성하는 방법을 알아봅니다.
movielens 데이터 세트에는 사용자가 영화에 부여한 평점(1~5점)과 장르 등의 영화 메타데이터가 포함됩니다.
목표
이 가이드에서는 다음을 수행합니다.
- BigQuery ML에서
CREATE MODEL문을 사용하여 명시적 추천 모델 만들기 ML.EVALUATE함수를 사용하여 ML 모델 평가ML.WEIGHTS함수를 사용하여 학습 중에 생성된 잠재 계수 가중치를 검사ML.RECOMMEND함수를 사용하여 사용자를 위한 추천 생성
비용
이 튜토리얼에서는 다음을 포함하여 Google Cloud의 청구 가능한 구성요소가 사용됩니다.
- BigQuery
- BigQuery ML
BigQuery 비용에 대한 자세한 내용은 BigQuery 가격 책정 페이지를 참조하세요.
BigQuery ML 비용에 대한 자세한 내용은 BigQuery ML 가격 책정을 참조하세요.
시작하기 전에
- Google Cloud 계정에 로그인합니다. Google Cloud를 처음 사용하는 경우 계정을 만들고 Google 제품의 실제 성능을 평가해 보세요. 신규 고객에게는 워크로드를 실행, 테스트, 배포하는 데 사용할 수 있는 $300의 무료 크레딧이 제공됩니다.
-
Google Cloud Console의 프로젝트 선택기 페이지에서 Google Cloud 프로젝트를 선택하거나 만듭니다.
-
Google Cloud Console의 프로젝트 선택기 페이지에서 Google Cloud 프로젝트를 선택하거나 만듭니다.
- BigQuery는 새 프로젝트에서 자동으로 사용 설정됩니다.
기존 프로젝트에서 BigQuery를 활성화하려면 다음으로 이동합니다.
BigQuery API 사용 설정
1단계: 데이터세트 만들기
ML 모델을 저장할 BigQuery 데이터 세트를 만듭니다.
Google Cloud 콘솔에서 BigQuery 페이지로 이동합니다.
탐색기 창에서 프로젝트 이름을 클릭합니다.
작업 보기 > 데이터 세트 만들기를 클릭합니다.

데이터 세트 만들기 페이지에서 다음을 수행합니다.
데이터 세트 ID에
bqml_tutorial를 입력합니다.위치 유형에 대해 멀티 리전을 선택한 다음 US(미국 내 여러 리전)를 선택합니다.
공개 데이터 세트는
US멀티 리전에 저장됩니다. 편의상 같은 위치에 데이터 세트를 저장합니다.나머지 기본 설정은 그대로 두고 데이터 세트 만들기를 클릭합니다.

2단계: Movielens 데이터 세트를 BigQuery에 로드
다음은 BigQuery 명령줄 도구를 사용하여 BigQuery에 1m movielens 데이터 세트를 로드하는 단계입니다.
movielens라는 데이터 세트가 생성되고 그 안에 관련 movielens 테이블이 저장됩니다.
curl -O 'http://files.grouplens.org/datasets/movielens/ml-1m.zip'
unzip ml-1m.zip
bq mk --dataset movielens
sed 's/::/,/g' ml-1m/ratings.dat > ratings.csv
bq load --source_format=CSV movielens.movielens_1m ratings.csv \
user_id:INT64,item_id:INT64,rating:FLOAT64,timestamp:TIMESTAMP
영화 제목에는 콜론, 쉼표, 파이프가 포함되어 있으므로 다른 구분 기호를 사용해야 합니다. 영화 제목을 로드하려면 마지막 두 명령어의 약간 다른 변형을 사용해야 합니다.
sed 's/::/@/g' ml-1m/movies.dat > movie_titles.csv
bq load --source_format=CSV --field_delimiter=@ \
movielens.movie_titles movie_titles.csv \
movie_id:INT64,movie_title:STRING,genre:STRING
3단계: 명시적 추천 모델 만들기
다음 단계에서는 이전 단계에서 로드한 movielens 샘플 테이블을 사용하여 명시적 추천 모델을 만듭니다. 다음 GoogleSQL 쿼리는 모든 사용자-항목 쌍의 평점을 예측하는 데 사용할 모델을 만드는 데 사용됩니다.
#standardSQL CREATE OR REPLACE MODEL `bqml_tutorial.my_explicit_mf_model` OPTIONS (model_type='matrix_factorization', user_col='user_id', item_col='item_id', l2_reg=9.83, num_factors=34) AS SELECT user_id, item_id, rating FROM `movielens.movielens_1m`
CREATE MODEL 명령어를 실행하면 모델 만들기 외에도 만든 모델을 학습시킬 수 있습니다.
쿼리 세부정보
CREATE MODEL 절을 사용하여 bqml_tutorial.my_explicit_mf_model이라는 모델을 만들고 학습시킵니다.
OPTIONS(model_type='matrix_factorization', user_col='user_id', ...) 절은 행렬 분해 모델을 만든다는 것을 나타냅니다. feedback_type='IMPLICIT'가 지정되지 않으면 기본적으로 명시적 행렬 분해 모델이 생성됩니다. 암시적 행렬 분해 모델을 만드는 방법의 예시는 BigQuery ML을 사용하여 암시적 의견에 대한 추천 만들기에서 설명합니다.
이 쿼리의 SELECT 문은 다음 열을 사용하여 추천을 생성합니다.
user_id: 사용자 ID(INT64)item_id: 영화 ID(INT64)rating:user_id가item_id에 지정한 1~5의 명시적 평점(FLOAT64)
FROM 절(movielens.movielens_1m)은 movielens 데이터 세트에서 movielens_1m 테이블을 쿼리함을 나타냅니다.
2단계의 안내를 따른 경우 이 데이터 세트는 BigQuery 프로젝트에 있습니다.
CREATE MODEL 쿼리 실행
CREATE MODEL 쿼리를 실행하여 모델을 만들고 학습시키려면 다음 안내를 따르세요.
Google Cloud 콘솔에서 새 쿼리 작성 버튼을 클릭합니다.
쿼리 편집기 텍스트 영역에 다음 GoogleSQL 쿼리를 입력합니다.
#standardSQL CREATE OR REPLACE MODEL `bqml_tutorial.my_explicit_mf_model` OPTIONS (model_type='matrix_factorization', user_col='user_id', item_col='item_id', l2_reg=9.83, num_factors=34) AS SELECT user_id, item_id, rating FROM `movielens.movielens_1m`
실행을 클릭합니다.
이 쿼리는 완료하는 데 약 10분이 소요되며 이후에는 모델(
my_explicit_mf_model)이 Google Cloud 콘솔의 탐색 패널에 표시됩니다. 이 쿼리에서는CREATE MODEL문을 사용하여 모델을 만들므로 쿼리 결과가 표시되지 않습니다.
(선택사항) 4단계: 학습 통계 가져오기
모델 학습 결과를 확인하려면 ML.TRAINING_INFO 함수를 사용하거나 Google Cloud 콘솔에서 통계를 보면 됩니다. 이 가이드에서는 Google Cloud 콘솔을 사용합니다.
머신러닝 알고리즘은 많은 예시를 검사하고 손실을 최소화하는 모델을 찾으려고 시도하여 모델을 빌드합니다. 이 프로세스를 경험적 위험 최소화라고 합니다.
CREATE MODEL 쿼리를 실행할 때 생성된 모델 학습 통계를 확인하려면 다음 안내를 따르세요.
Google Cloud 콘솔 탐색 패널의 리소스 섹션에서 [PROJECT_ID] > bqml_tutorial을 펼친 후 my_explicit_mf_model을 클릭합니다.
학습 탭을 클릭한 후 테이블을 클릭합니다. 다음과 같은 결과가 표시됩니다.
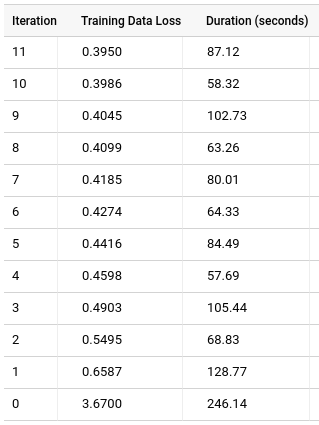
학습 데이터 손실 열은 학습 데이터 세트에서 모델 학습이 진행된 후 계산된 손실 측정항목을 나타냅니다. 행렬 분해를 수행했으므로 이 열은 평균 제곱 오차입니다. 기본적으로 행렬 분해 모델은 데이터를 분할하지 않습니다. 데이터를 분할하면 사용자 또는 항목의 모든 평점이 손실될 수 있으므로 홀드아웃 데이터 세트가 지정되지 않으면 평가 데이터 손실 열이 표시되지 않습니다. 따라서 모델에 누락된 사용자 또는 항목에 대한 잠재 계수 정보가 없습니다.
ML.TRAINING_INFO함수에 대한 자세한 내용은 BigQuery ML 구문 참조를 확인하세요.
5단계: 모델 평가
모델을 만든 후에는 ML.EVALUATE 함수를 사용하여 추천자의 성능을 평가합니다. ML.EVALUATE 함수는 예측된 평점을 실제 평점과 비교하여 평가합니다.
모델을 평가하는 데 사용되는 쿼리는 다음과 같습니다.
#standardSQL
SELECT
*
FROM
ML.EVALUATE(MODEL `bqml_tutorial.my_explicit_mf_model`,
(
SELECT
user_id,
item_id,
rating
FROM
`movielens.movielens_1m`))
쿼리 세부정보
맨 위에 있는 SELECT 문은 모델의 열을 검색합니다.
FROM 절은 bqml_tutorial.my_explicit_mf_model 모델에 ML.EVALUATE 함수를 사용합니다.
이 쿼리의 중첩된 SELECT 문과 FROM 절은 CREATE MODEL 쿼리와 동일합니다.
또한 입력 데이터를 제공하지 않고 ML.EVALUATE를 호출할 수도 있습니다. 그러면 학습 중에 계산된 평가 측정항목을 사용합니다.
#standardSQL SELECT * FROM ML.EVALUATE(MODEL `bqml_tutorial.my_explicit_mf_model`)
ML.EVALUATE 쿼리 실행
모델을 평가하는 ML.EVALUATE 쿼리를 실행하려면 다음 안내를 따르세요.
Google Cloud 콘솔에서 새 쿼리 작성 버튼을 클릭합니다.
쿼리 편집기 텍스트 영역에 다음 GoogleSQL 쿼리를 입력합니다.
#standardSQL SELECT * FROM ML.EVALUATE(MODEL `bqml_tutorial.my_explicit_mf_model`, ( SELECT user_id, item_id, rating FROM `movielens.movielens_1m`))
(선택사항) 처리 위치를 설정하려면 더보기 > 쿼리 설정을 클릭합니다. 데이터 위치에
US를 선택합니다. 처리 위치는 데이터 세트 위치를 기준으로 자동 감지되므로 이 단계는 선택사항입니다.
실행을 클릭합니다.
쿼리가 완료되면 쿼리 텍스트 영역 아래의 결과 탭을 클릭합니다. 다음과 같은 결과가 표시됩니다.

명시적 행렬 분해를 수행했으므로 결과에 다음 열이 포함됩니다.
mean_absolute_errormean_squared_errormean_squared_log_errormedian_absolute_errorr2_scoreexplained_variance
평가 결과에서 중요 측정항목은 R2 점수입니다. R2 점수는 선형 회귀 예측이 실제 데이터에 가까운지 알 수 있는 통계 척도입니다. 0은 모델이 평균 주위 응답 데이터의 변동성을 전혀 설명하지 못한다는 것을 나타냅니다. 1은 모델이 평균을 기준으로 응답 데이터의 변동성을 모두 설명한다는 것을 나타냅니다.
6단계: 모델을 사용하여 평점 예측 및 추천 생성
사용자 집합의 모든 항목 평점 찾기
ML.RECOMMEND는 모델 이외의 추가 인수를 사용할 필요가 없지만 선택적 테이블을 사용할 수 있습니다. 입력 테이블에 입력 user 또는 입력 item 열의 이름과 일치하는 열이 하나뿐이면 각 user의 예측된 항목 평점이 모두 출력되며 그 반대도 마찬가지입니다. 입력 테이블에 모든 users 또는 모든 items가 있으면 ML.RECOMMEND에 선택적 인수를 전달하지 않는 경우와 동일한 결과가 출력됩니다.
다음은 사용자 5명의 예상 영화 평점을 모두 가져오는 쿼리의 예시입니다.
#standardSQL
SELECT
*
FROM
ML.RECOMMEND(MODEL `bqml_tutorial.my_explicit_mf_model`,
(
SELECT
user_id
FROM
`movielens.movielens_1m`
LIMIT 5))
쿼리 세부정보
맨 위에 있는 SELECT 문은 user, item, predicted_rating 열을 검색합니다.
이 마지막 열은 ML.RECOMMEND 함수에 의해 생성됩니다. ML.RECOMMEND 함수를 사용할 때 모델의 출력 열 이름은 predicted_<rating_column_name>입니다. 명시적 행렬 분해 모델에서 predicted_rating은 rating의 추정 값입니다.
ML.RECOMMEND 함수는 bqml_tutorial.my_explicit_mf_model 모델을 사용하여 평점을 예측하는 데 사용됩니다.
이 쿼리의 중첩된 SELECT 문은 학습에 사용된 원본 테이블에서 user_id 열만 선택합니다.
LIMIT절(LIMIT 5)은 ML.RECOMMEND로 전송할 user_id 5개를 무작위로 필터링합니다.
모든 사용자-항목 쌍의 평점 찾기
모델을 평가했으므로 다음 단계는 모델을 사용하여 평점을 예측하는 것입니다. 모델을 사용하여 다음 쿼리에서 모든 사용자-항목 조합의 평점을 예측합니다.
#standardSQL SELECT * FROM ML.RECOMMEND(MODEL `bqml_tutorial.my_explicit_mf_model`)
쿼리 세부정보
맨 위에 있는 SELECT 문은 user, item, predicted_rating 열을 검색합니다.
이 마지막 열은 ML.RECOMMEND 함수에 의해 생성됩니다. ML.RECOMMEND 함수를 사용할 때 모델의 출력 열 이름은 predicted_<rating_column_name>입니다. 명시적 행렬 분해 모델에서 predicted_rating은 rating의 추정 값입니다.
ML.RECOMMEND 함수는 bqml_tutorial.my_explicit_mf_model 모델을 사용하여 평점을 예측하는 데 사용됩니다.
결과를 테이블에 저장하는 방법 중 하나는 다음과 같습니다.
#standardSQL CREATE OR REPLACE TABLE `bqml_tutorial.recommend_1m` OPTIONS() AS SELECT * FROM ML.RECOMMEND(MODEL `bqml_tutorial.my_explicit_mf_model`)
ML.RECOMMEND에 Query Exceeded Resource Limits 오류가 발생하면 더 높은 결제 등급으로 다시 시도하세요. BigQuery 명령줄 도구에서 --maximum_billing_tier 플래그를 사용하여 설정할 수 있습니다.
추천 생성
이전의 추천 쿼리를 사용하여 예측 평점을 기준으로 정렬하고 각 사용자의 최상위 예측 항목을 출력할 수 있습니다. 다음 쿼리는 item_ids를 이전에 업로드된 movielens.movie_titles 테이블에 있는 movie_ids와 조인하고 사용자마다 상위 5개의 추천 영화를 출력합니다.
#standardSQL SELECT user_id, ARRAY_AGG(STRUCT(movie_title, genre, predicted_rating) ORDER BY predicted_rating DESC LIMIT 5) FROM ( SELECT user_id, item_id, predicted_rating, movie_title, genre FROM `bqml_tutorial.recommend_1m` JOIN `movielens.movie_titles` ON item_id = movie_id) GROUP BY user_id
쿼리 세부정보
내부 SELECT 문은 추천 결과 테이블의 item_id와 movielens.movie_titles 테이블의 movie_id에 대한 내부 조인을 수행합니다. movielens.movie_titles는 movie_id를 영화 이름에 매핑할 뿐만 아니라 IMDB에 나열된 영화 장르도 포함합니다.
최상위 SELECT 문은 GROUPS BY user_id를 사용해서 movie_title,
genre,, predicted_rating를 내림차순으로 집계하여 중첩된 SELECT 문의 결과를 집계하고 상위 5개의 영화만 유지합니다.
ML.RECOMMEND 쿼리 실행
사용자마다 상위 5개의 추천 영화를 출력하는 ML.RECOMMEND 쿼리를 실행하려면 다음 안내를 따르세요.
Google Cloud 콘솔에서 새 쿼리 작성 버튼을 클릭합니다.
쿼리 편집기 텍스트 영역에 다음 GoogleSQL 쿼리를 입력합니다.
#standardSQL CREATE OR REPLACE TABLE `bqml_tutorial.recommend_1m` OPTIONS() AS SELECT * FROM ML.RECOMMEND(MODEL `bqml_tutorial.my_explicit_mf_model`)
실행을 클릭합니다.
쿼리 실행이 완료되면 탐색 패널에 (
bqml_tutorial.recommend_1m)가 표시됩니다. 이 쿼리는CREATE TABLE문을 사용하여 테이블을 만들기 때문에 쿼리 결과가 표시되지 않습니다.다른 새 쿼리를 작성합니다. 이전 쿼리 실행이 완료되면 쿼리 편집기 텍스트 영역에 다음 GoogleSQL 쿼리를 입력합니다.
#standardSQL SELECT user_id, ARRAY_AGG(STRUCT(movie_title, genre, predicted_rating) ORDER BY predicted_rating DESC LIMIT 5) FROM ( SELECT user_id, item_id, predicted_rating, movie_title, genre FROM `bqml_tutorial.recommend_1m` JOIN `movielens.movie_titles` ON item_id = movie_id) GROUP BY user_id
(선택사항) 처리 위치를 설정하려면 더보기 > 쿼리 설정을 클릭합니다. 데이터 위치에
US를 선택합니다. 처리 위치는 데이터 세트 위치를 기준으로 자동 감지되므로 이 단계는 선택사항입니다. 실행을 클릭합니다.
쿼리가 완료되면 쿼리 텍스트 영역 아래의 결과 탭을 클릭합니다. 다음과 같은 결과가 표시됩니다.
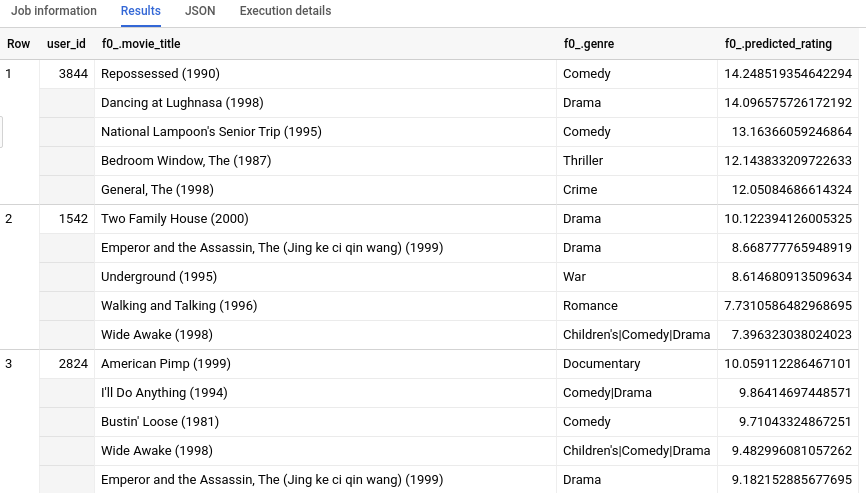
INT64 외에 각 movie_id에 대한 추가 메타데이터 정보가 있으므로 각 사용자의 상위 5개 영화에 대한 정보를 볼 수 있습니다. 학습 데이터에 해당하는 movietitles 테이블이 없는 경우 숫자 ID나 해시만으로는 사람이 이해할 수 있는 결과를 얻지 못할 수 있습니다.
계수당 상위 장르
각 잠재 계수가 어떤 장르와 상관 관계가 있는지 알아보려면 다음 쿼리를 실행합니다.
#standardSQL
SELECT
factor,
ARRAY_AGG(STRUCT(feature, genre,
weight)
ORDER BY
weight DESC
LIMIT
10) AS weights
FROM (
SELECT
* EXCEPT(factor_weights)
FROM (
SELECT
*
FROM (
SELECT
factor_weights,
CAST(feature AS INT64) as feature
FROM
ML.WEIGHTS(model `bqml_tutorial.my_explicit_mf_model`)
WHERE
processed_input= 'item_id')
JOIN
`movielens.movie_titles`
ON
feature = movie_id) weights
CROSS JOIN
UNNEST(weights.factor_weights)
ORDER BY
feature,
weight DESC)
GROUP BY
factor
쿼리 세부정보
가장 안쪽의 SELECT 문은 item_id 또는 영화 계수 가중치 배열을 가져온 다음 이를 movielens.movie_titles 테이블과 조인하여 각 항목 ID의 장르를 가져옵니다.
그 결과는 각 factor_weights 배열과 CROSS JOIN되고 그러면 ORDER BY feature, weight DESC가 됩니다.
마지막으로, 최상위 SELECT 문은 내부 문의 결과를 factor로 집계하고 각 장르의 가중치에 따라 각 계수의 배열을 만듭니다.
쿼리 실행
계수당 상위 10개의 영화 장르를 출력하는 위의 쿼리를 실행하려면 다음 안내를 따르세요.
Google Cloud 콘솔에서 새 쿼리 작성 버튼을 클릭합니다.
쿼리 편집기 텍스트 영역에 다음 GoogleSQL 쿼리를 입력합니다.
#standardSQL
SELECT
factor,
ARRAY_AGG(STRUCT(feature, genre,
weight)
ORDER BY
weight DESC
LIMIT
10) AS weights
FROM (
SELECT
* EXCEPT(factor_weights)
FROM (
SELECT
*
FROM (
SELECT
factor_weights,
CAST(feature AS INT64) as feature
FROM
ML.WEIGHTS(model `bqml_tutorial.my_explicit_mf_model`)
WHERE
processed_input= 'item_id')
JOIN
`movielens.movie_titles`
ON
feature = movie_id) weights
CROSS JOIN
UNNEST(weights.factor_weights)
ORDER BY
feature,
weight DESC)
GROUP BY
factor
(선택사항) 처리 위치를 설정하려면 더보기 > 쿼리 설정을 클릭합니다. 데이터 위치에
US를 선택합니다. 처리 위치는 데이터 세트 위치를 기준으로 자동 감지되므로 이 단계는 선택사항입니다. 실행을 클릭합니다.
쿼리가 완료되면 쿼리 텍스트 영역 아래의 결과 탭을 클릭합니다. 다음과 같은 결과가 표시됩니다.
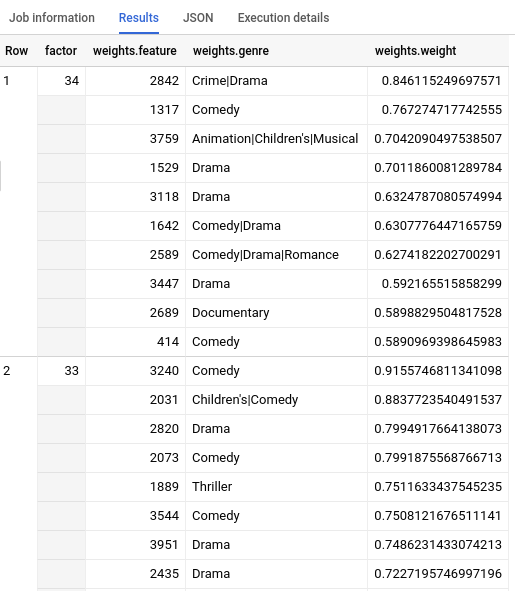
삭제
이 튜토리얼에서 사용된 리소스 비용이 Google Cloud 계정에 청구되지 않도록 하려면 리소스가 포함된 프로젝트를 삭제하거나 프로젝트를 유지하고 개별 리소스를 삭제하세요.
- 만든 프로젝트를 삭제할 수 있습니다.
- 또는 프로젝트를 유지하고 데이터 세트를 삭제할 수 있습니다.
데이터 세트 삭제
프로젝트를 삭제하면 프로젝트의 데이터 세트와 테이블이 모두 삭제됩니다. 프로젝트를 다시 사용하려면 이 가이드에서 만든 데이터 세트를 삭제할 수 있습니다.
필요한 경우 Google Cloud 콘솔에서 BigQuery 페이지를 엽니다.
앞서 만든 bqml_tutorial 데이터 세트를 탐색에서 선택합니다.
창의 오른쪽에 있는 데이터 세트 삭제를 클릭합니다. 데이터 세트, 테이블, 모든 데이터가 삭제됩니다.
데이터 세트 삭제 대화상자에서 데이터 세트 이름(
bqml_tutorial)을 입력하여 삭제 명령어를 확인한 후 삭제를 클릭합니다.
프로젝트 삭제
프로젝트를 삭제하는 방법은 다음과 같습니다.
- Google Cloud 콘솔에서 리소스 관리 페이지로 이동합니다.
- 프로젝트 목록에서 삭제할 프로젝트를 선택하고 삭제를 클릭합니다.
- 대화상자에서 프로젝트 ID를 입력한 후 종료를 클릭하여 프로젝트를 삭제합니다.
다음 단계
- 머신러닝 단기집중과정을 참조하여 머신러닝 알아보기
- BigQuery ML 개요는 BigQuery ML 소개를 참조하세요.
- Google Cloud 콘솔에 대한 자세한 내용은 Google Cloud 콘솔 사용을 참조하세요.