Ce tutoriel présente aux analystes de données le modèle de factorisation matricielle dans BigQuery ML. BigQuery ML permet aux utilisateurs de créer et d'exécuter des modèles de machine learning dans BigQuery à l'aide de requêtes SQL. L'objectif est de démocratiser le machine learning en permettant aux utilisateurs SQL de créer des modèles à l'aide de leurs propres outils et d'accélérer le rythme de développement en leur évitant d'avoir à transférer des données.
Dans ce tutoriel, vous apprendrez à créer un modèle à partir de commentaires explicites à l'aide de l'ensemble de données movielens1m. Vous pourrez ainsi émettre des recommandations à partir d'un ID de film et d'un ID d'utilisateur.
L'ensemble de données MovieLens contient les notes que les utilisateurs ont attribuées aux films sur une échelle de 1 à 5, ainsi que les métadonnées des films, par exemple leur genre.
Objectifs
Dans ce tutoriel, vous allez utiliser :
- BigQuery ML, pour créer un modèle de recommandations explicite à l'aide de l'instruction
CREATE MODEL; - la fonction
ML.EVALUATE, pour évaluer les modèles de ML ; - la fonction
ML.WEIGHTS, pour inspecter les pondérations des facteurs latents générées lors de l'entraînement ; - la fonction
ML.RECOMMEND, qui permet de produire des recommandations pour un utilisateur.
Coûts
Ce tutoriel utilise des composants facturables de Google Cloud dont :
- BigQuery
- BigQuery ML
Pour en savoir plus sur le coût de BigQuery, consultez la page Tarifs de BigQuery.
Pour en savoir plus sur le coût de BigQuery ML, consultez la page Tarifs de BigQuery ML.
Avant de commencer
- Connectez-vous à votre compte Google Cloud. Si vous débutez sur Google Cloud, créez un compte pour évaluer les performances de nos produits en conditions réelles. Les nouveaux clients bénéficient également de 300 $ de crédits gratuits pour exécuter, tester et déployer des charges de travail.
-
Dans Google Cloud Console, sur la page de sélection du projet, sélectionnez ou créez un projet Google Cloud.
-
Vérifiez que la facturation est activée pour votre projet Google Cloud.
-
Dans Google Cloud Console, sur la page de sélection du projet, sélectionnez ou créez un projet Google Cloud.
-
Vérifiez que la facturation est activée pour votre projet Google Cloud.
- BigQuery est automatiquement activé dans les nouveaux projets.
Pour activer BigQuery dans un projet préexistant, accédez à
Activez l'API BigQuery
Étape 1 : Créer un ensemble de données
Vous allez créer un ensemble de données BigQuery pour stocker votre modèle de ML :
Dans la console Google Cloud, accédez à la page "BigQuery".
Dans le volet Explorateur, cliquez sur le nom de votre projet.
Cliquez sur Afficher les actions > Créer un ensemble de données.

Sur la page Créer un ensemble de données, procédez comme suit :
Dans le champ ID de l'ensemble de données, saisissez
bqml_tutorial.Pour Type d'emplacement, sélectionnez Multirégional, puis sélectionnez US (plusieurs régions aux États-Unis).
Les ensembles de données publics sont stockés dans l'emplacement multirégional
US. Par souci de simplicité, stockez votre ensemble de données dans le même emplacement.Conservez les autres paramètres par défaut, puis cliquez sur Créer un ensemble de données.

Étape 2 : Charger l'ensemble de données MovieLens dans BigQuery
Voici la procédure à suivre pour charger l'ensemble de données MovieLens 1m dans BigQuery à l'aide des outils de ligne de commande BigQuery.
Un ensemble de données appelé movielens sera créé et les tables correspondantes de MovieLens y seront stockées.
curl -O 'http://files.grouplens.org/datasets/movielens/ml-1m.zip'
unzip ml-1m.zip
bq mk --dataset movielens
sed 's/::/,/g' ml-1m/ratings.dat > ratings.csv
bq load --source_format=CSV movielens.movielens_1m ratings.csv \
user_id:INT64,item_id:INT64,rating:FLOAT64,timestamp:TIMESTAMP
Étant donné que les titres des films contiennent des signes deux-points, des virgules et des barres verticales, nous devons utiliser un autre délimiteur. Pour charger les titres des films, utilisez une variante légèrement différente des deux dernières commandes.
sed 's/::/@/g' ml-1m/movies.dat > movie_titles.csv
bq load --source_format=CSV --field_delimiter=@ \
movielens.movie_titles movie_titles.csv \
movie_id:INT64,movie_title:STRING,genre:STRING
Étape 3 : Créer votre modèle de recommandations explicite
Vous allez ensuite créer un modèle de recommandations explicite à l'aide de l'exemple de table MovieLens chargé à l'étape précédente. La requête GoogleSQL suivante permet de créer le modèle qui servira à prédire une note pour chaque paire utilisateur-élément.
#standardSQL CREATE OR REPLACE MODEL `bqml_tutorial.my_explicit_mf_model` OPTIONS (model_type='matrix_factorization', user_col='user_id', item_col='item_id', l2_reg=9.83, num_factors=34) AS SELECT user_id, item_id, rating FROM `movielens.movielens_1m`
En plus de créer le modèle, l'exécution de la commande CREATE MODEL entraîne le modèle que vous créez.
Détails de la requête
La clause CREATE MODEL permet de créer et d'entraîner le modèle nommé bqml_tutorial.my_explicit_mf_model.
La clause OPTIONS(model_type='matrix_factorization', user_col='user_id', ...) indique que vous créez un modèle de factorisation matricielle. Par défaut, un modèle de factorisation matricielle explicite est créé, sauf si feedback_type='IMPLICIT' est spécifié. Vous trouverez un exemple de création d'un modèle de factorisation matricielle implicite dans la section Utiliser BigQuery ML pour formuler des recommandations en matière de commentaires implicites.
L'instruction SELECT de cette requête utilise les colonnes suivantes pour générer des recommandations.
user_id: ID d'utilisateur (INT64)item_id: ID de film (INT64)rating: note explicite de 1 à 5 attribuée par l'ID d'utilisateur (user_id) à l'ID d'élément (item_id) (FLOAT64)
La clause FROM (movielens.movielens_1m) indique que vous interrogez la table movielens_1m de l'ensemble de données movielens.
Cet ensemble de données se trouve dans votre projet BigQuery si les instructions de la deuxième étape ont été suivies.
Exécuter la requête CREATE MODEL
Pour exécuter la requête CREATE MODEL qui permet de créer et d'entraîner votre modèle, procédez comme suit :
Dans la console Google Cloud, cliquez sur le bouton Saisir une nouvelle requête.
Saisissez la requête GoogleSQL suivante dans la zone de texte Éditeur de requête.
#standardSQL CREATE OR REPLACE MODEL `bqml_tutorial.my_explicit_mf_model` OPTIONS (model_type='matrix_factorization', user_col='user_id', item_col='item_id', l2_reg=9.83, num_factors=34) AS SELECT user_id, item_id, rating FROM `movielens.movielens_1m`
Cliquez sur Exécuter.
L'exécution de la requête prend environ 10 minutes, puis votre modèle (
my_explicit_mf_model) s'affiche dans le panneau de navigation de la console Google Cloud. Étant donné que la requête utilise une instructionCREATE MODELpour créer un modèle, les résultats de la requête ne sont pas affichés.
Étape 4 (facultative): Obtenir des statistiques d'entraînement
Pour afficher les résultats de l'entraînement du modèle, vous pouvez utiliser la fonction ML.TRAINING_INFO ou afficher les statistiques dans la console Google Cloud. Dans ce tutoriel, vous utilisez la console Google Cloud.
Pour créer un modèle, un algorithme de machine learning examine de nombreux exemples et essaie de trouver un modèle qui minimise la perte. Ce processus est appelé minimisation du risque empirique.
Pour afficher les statistiques d'entraînement du modèle qui ont été générées lors de l'exécution de la requête CREATE MODEL, procédez comme suit :
Dans le panneau de navigation de la console Google Cloud, dans la section Ressources, développez [PROJECT_ID] > bqml_tutorial, puis cliquez sur my_explicit_mf_model.
Cliquez sur l'onglet Entraînement, puis sur Table. Les résultats doivent se présenter sous la forme suivante :
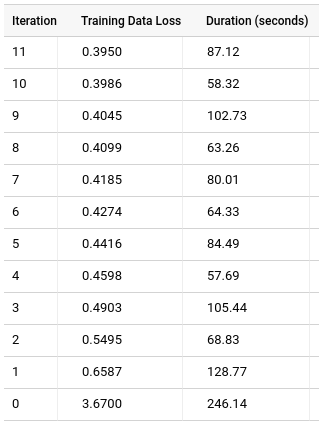
La colonne Training Data Loss (Perte de données d'entraînement) représente la métrique de perte calculée après entraînement du modèle dans l'ensemble de données d'entraînement. Étant donné que vous avez effectué une factorisation matricielle, cette colonne correspond à l'erreur quadratique moyenne. Par défaut, les modèles de factorisation matricielle ne répartissent pas les données. Par conséquent, la colonne Perte des données d'évaluation n'est présente que si un ensemble de données exclues est spécifié, car la répartition des données risque d'entraîner la perte de toutes les notes d'un utilisateur ou d'un élément. Le modèle ne disposera donc pas d'informations sur les facteurs de latence concernant les utilisateurs ou éléments manquants.
Pour en savoir plus sur la fonction
ML.TRAINING_INFO, consultez la documentation de référence sur la syntaxe BigQuery ML.
Étape 5 : Évaluer votre modèle
Après avoir créé votre modèle, vous allez évaluer les performances de l'outil de recommandation à l'aide de la fonction ML.EVALUATE. La fonction ML.EVALUATE compare les prédictions aux notes réelles.
La requête permettant d'évaluer le modèle est la suivante :
#standardSQL
SELECT
*
FROM
ML.EVALUATE(MODEL `bqml_tutorial.my_explicit_mf_model`,
(
SELECT
user_id,
item_id,
rating
FROM
`movielens.movielens_1m`))
Détails de la requête
La toute première instruction SELECT récupère les colonnes de votre modèle.
La clause FROM utilise la fonction ML.EVALUATE basée sur votre modèle : bqml_tutorial.my_explicit_mf_model.
L'instruction SELECT et la clause FROM imbriquées de cette requête sont identiques à celles de la requête CREATE MODEL.
Vous pouvez également appeler ML.EVALUATE sans fournir de données d'entrée. Les métriques d'évaluation calculées au cours de l'entraînement seront alors utilisées :
#standardSQL SELECT * FROM ML.EVALUATE(MODEL `bqml_tutorial.my_explicit_mf_model`)
Exécuter la requête ML.EVALUATE
Pour exécuter la requête ML.EVALUATE permettant d'évaluer le modèle, procédez comme suit :
Dans la console Google Cloud, cliquez sur le bouton Saisir une nouvelle requête.
Saisissez la requête GoogleSQL suivante dans la zone de texte Éditeur de requête.
#standardSQL SELECT * FROM ML.EVALUATE(MODEL `bqml_tutorial.my_explicit_mf_model`, ( SELECT user_id, item_id, rating FROM `movielens.movielens_1m`))
(Facultatif) Pour définir l'emplacement de traitement, cliquez sur Plus > Paramètres de requête. Pour Processing location (Emplacement de traitement), choisissez
US. Cette étape est facultative, car l'emplacement de traitement est automatiquement détecté selon l'emplacement de l'ensemble de données.
Cliquez sur Run (Exécuter).
Lorsque la requête est terminée, cliquez sur l'onglet Results (Résultats) sous la zone de texte de la requête. Les résultats doivent se présenter sous la forme suivante :

Étant donné que vous avez effectué une factorisation matricielle explicite, les résultats incluent les colonnes suivantes :
mean_absolute_errormean_squared_errormean_squared_log_errormedian_absolute_errorr2_scoreexplained_variance
Le score R2 est une métrique importante dans les résultats de l'évaluation. Le score R2 est une mesure statistique qui détermine si les prédictions de la régression linéaire se rapprochent des données réelles. 0 indique que le modèle n'apporte aucune explication sur la variabilité des données de réponse autour de la moyenne. 1 indique que le modèle explique toute la variabilité des données de réponse autour de la moyenne.
Étape 6 : Utiliser votre modèle pour prédire les notes et formuler des recommandations
Rechercher toutes les notes d'éléments pour un ensemble d'utilisateurs
La fonction ML.RECOMMEND n'a pas besoin d'accepter d'arguments supplémentaires en plus du modèle, mais elle peut intégrer une table facultative. Si la table d'entrée ne comporte qu'une seule colonne qui correspond au nom de la colonne utilisateur (user) d'entrée ou de la colonne élément (item) d'entrée, toutes les prédictions de notes d'éléments pour chaque utilisateur (user) seront générées, et inversement. Notez que si tous les utilisateurs (users) ou tous les éléments (items) se trouvent dans la table d'entrée, les résultats affichés seront les mêmes que si aucun argument facultatif n'avait été transmis à ML.RECOMMEND.
Voici un exemple de requête qui récupère toutes les prédictions de notes de films de cinq utilisateurs :
#standardSQL
SELECT
*
FROM
ML.RECOMMEND(MODEL `bqml_tutorial.my_explicit_mf_model`,
(
SELECT
user_id
FROM
`movielens.movielens_1m`
LIMIT 5))
Détails des requêtes
La toute première instruction SELECT récupère les colonnes user, item et predicted_rating.
Cette dernière colonne est générée par la fonction ML.RECOMMEND. Lorsque vous utilisez la fonction ML.RECOMMEND, le nom de la colonne de résultats pour le modèle est predicted_<rating_column_name>. Pour les modèles de factorisation matricielle explicites, predicted_rating est la valeur estimée de la note (rating).
La fonction ML.RECOMMEND permet de prédire les notes à l'aide de votre modèle : bqml_tutorial.my_explicit_mf_model.
L'instruction SELECT imbriquée de cette requête sélectionne uniquement la colonne user_id de la table d'origine utilisée pour l'entraînement.
La clause LIMIT (LIMIT 5) filtre cinq ID d'utilisateurs (user_id) à envoyer à ML.RECOMMEND.
Rechercher les notes de toutes les paires utilisateur-élément
Maintenant que vous avez évalué votre modèle, l'étape suivante consiste à l'utiliser pour prédire une note. Vous utilisez votre modèle pour prédire les notes de chaque combinaison utilisateur-élément dans la requête suivante :
#standardSQL SELECT * FROM ML.RECOMMEND(MODEL `bqml_tutorial.my_explicit_mf_model`)
Détails des requêtes
La toute première instruction SELECT récupère les colonnes user, item et predicted_rating.
Cette dernière colonne est générée par la fonction ML.RECOMMEND. Lorsque vous utilisez la fonction ML.RECOMMEND, le nom de la colonne de résultats pour le modèle est predicted_<rating_column_name>. Pour les modèles de factorisation matricielle explicites, predicted_rating est la valeur estimée de la note (rating).
La fonction ML.RECOMMEND permet de prédire les notes à l'aide de votre modèle : bqml_tutorial.my_explicit_mf_model.
Pour enregistrer le résultat dans la table, vous pouvez procéder comme ci-dessous :
#standardSQL CREATE OR REPLACE TABLE `bqml_tutorial.recommend_1m` OPTIONS() AS SELECT * FROM ML.RECOMMEND(MODEL `bqml_tutorial.my_explicit_mf_model`)
Si ML.RECOMMEND affiche l'erreur Query Exceeded Resource Limits (la requête a excédé les limites de ressources), réessayez avec un niveau de facturation plus élevé. Dans l'outil de ligne de commande BigQuery, vous pouvez définir ce paramètre à l'aide de l'option --maximum_billing_tier.
Générer des recommandations
À l'aide de la requête de recommandations précédente, nous pouvons trier les données selon la note prédite et générer pour chaque utilisateur les éléments ayant la plus haute note prédite. La requête suivante associe les ID d'élément (item_ids) aux ID de film (movie_ids) présents dans la table movielens.movie_titles importée précédemment, et génère les cinq recommandations de films les mieux notés par utilisateur.
#standardSQL SELECT user_id, ARRAY_AGG(STRUCT(movie_title, genre, predicted_rating) ORDER BY predicted_rating DESC LIMIT 5) FROM ( SELECT user_id, item_id, predicted_rating, movie_title, genre FROM `bqml_tutorial.recommend_1m` JOIN `movielens.movie_titles` ON item_id = movie_id) GROUP BY user_id
Détails des requêtes
L'instruction SELECT interne effectue une jointure interne sur les ID d'élément (item_id) à partir de la table des résultats de recommandation, et sur les ID de film (movie_id) à partir de la table movielens.movie_titles. La table movielens.movie_titles mappe non seulement le movie_id sur le nom d'un film, mais elle inclut également le genre du film tel qu'il figure dans IMDB.
L'instruction SELECT de premier niveau regroupe les résultats de l'instruction SELECT imbriquée. Pour cela, elle utilise GROUPS BY user_id pour agréger les données movie_title,
genre, et predicted_rating par ordre décroissant, et elle ne conserve que les cinq meilleurs films.
Exécuter la requête ML.RECOMMEND
Pour exécuter la requête ML.RECOMMEND qui génère les cinq recommandations de films les mieux notés par utilisateur :
Dans la console Google Cloud, cliquez sur le bouton Saisir une nouvelle requête.
Saisissez la requête GoogleSQL suivante dans la zone de texte Éditeur de requête.
#standardSQL CREATE OR REPLACE TABLE `bqml_tutorial.recommend_1m` OPTIONS() AS SELECT * FROM ML.RECOMMEND(MODEL `bqml_tutorial.my_explicit_mf_model`)
Cliquez sur Exécuter.
Une fois la requête terminée, (
bqml_tutorial.recommend_1m) apparaît dans le panneau de navigation. Étant donné que la requête utilise une instructionCREATE TABLEpour créer une table, les résultats de la requête ne sont pas affichés.Rédigez une autre requête. Saisissez la requête GoogleSQL suivante dans la zone de texte Éditeur de requête, une fois la requête précédente terminée.
#standardSQL SELECT user_id, ARRAY_AGG(STRUCT(movie_title, genre, predicted_rating) ORDER BY predicted_rating DESC LIMIT 5) FROM ( SELECT user_id, item_id, predicted_rating, movie_title, genre FROM `bqml_tutorial.recommend_1m` JOIN `movielens.movie_titles` ON item_id = movie_id) GROUP BY user_id
(Facultatif) Pour définir l'emplacement de traitement, cliquez sur Plus > Paramètres de requête. Pour Processing location (Emplacement de traitement), choisissez
US. Cette étape est facultative, car l'emplacement de traitement est automatiquement détecté selon l'emplacement de l'ensemble de données. Cliquez sur Run (Exécuter).
Lorsque la requête est terminée, cliquez sur l'onglet Results (Résultats) sous la zone de texte de la requête. Les résultats doivent se présenter sous la forme suivante :
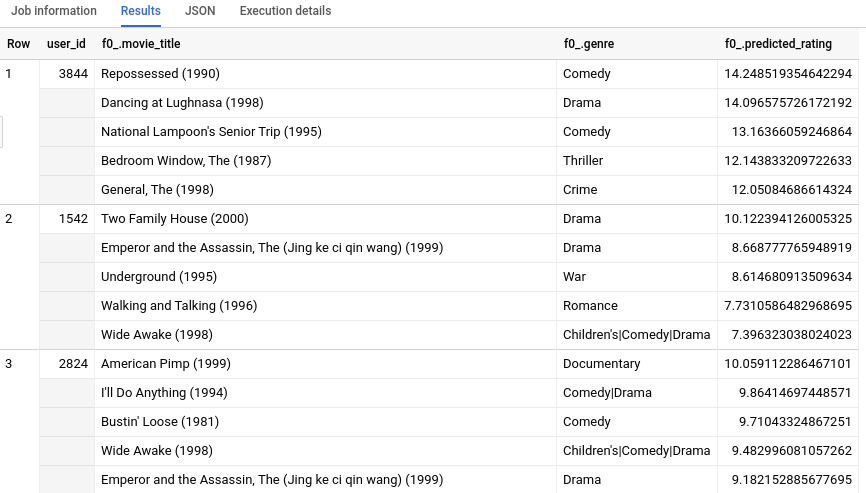
Étant donné que nous disposions de métadonnées supplémentaires pour chaque ID de film (movie_id) en plus de la valeur INT64, nous pouvons afficher par exemple le genre du film pour chacune des cinq meilleures recommandations de chaque utilisateur. Si vous ne disposez pas de table movietitles équivalente pour vos données d'entraînement, l'interprétabilité humaine des résultats à l'aide d'ID numériques ou de hachages seuls pourrait être rendue plus difficile.
Top des genres par facteur
Si vous souhaitez connaître le genre auquel chaque facteur latent se rapporte, vous pouvez exécuter la requête suivante :
#standardSQL
SELECT
factor,
ARRAY_AGG(STRUCT(feature, genre,
weight)
ORDER BY
weight DESC
LIMIT
10) AS weights
FROM (
SELECT
* EXCEPT(factor_weights)
FROM (
SELECT
*
FROM (
SELECT
factor_weights,
CAST(feature AS INT64) as feature
FROM
ML.WEIGHTS(model `bqml_tutorial.my_explicit_mf_model`)
WHERE
processed_input= 'item_id')
JOIN
`movielens.movie_titles`
ON
feature = movie_id) weights
CROSS JOIN
UNNEST(weights.factor_weights)
ORDER BY
feature,
weight DESC)
GROUP BY
factor
Détails des requêtes
La première instruction SELECT interne obtient la table item_id ou la table des pondérations de facteurs de film, puis l'associe à la table movielens.movie_titles pour obtenir le genre de chaque ID d'élément.
Une jointure croisée (CROSS JOIN) est alors effectuée sur ce résultat avec chaque table factor_weights dont le résultat est alors ORDER BY feature, weight DESC.
Enfin, l'instruction SELECT de premier niveau regroupe les résultats de son instruction interne par facteur (factor) et crée une table pour chaque facteur, classée selon la pondération de chaque genre.
Exécuter la requête
Pour exécuter la requête ci-dessus qui génère les 10 principaux genres de films par facteur :
Dans la console Google Cloud, cliquez sur le bouton Saisir une nouvelle requête.
Saisissez la requête GoogleSQL suivante dans la zone de texte Éditeur de requête.
#standardSQL
SELECT
factor,
ARRAY_AGG(STRUCT(feature, genre,
weight)
ORDER BY
weight DESC
LIMIT
10) AS weights
FROM (
SELECT
* EXCEPT(factor_weights)
FROM (
SELECT
*
FROM (
SELECT
factor_weights,
CAST(feature AS INT64) as feature
FROM
ML.WEIGHTS(model `bqml_tutorial.my_explicit_mf_model`)
WHERE
processed_input= 'item_id')
JOIN
`movielens.movie_titles`
ON
feature = movie_id) weights
CROSS JOIN
UNNEST(weights.factor_weights)
ORDER BY
feature,
weight DESC)
GROUP BY
factor
(Facultatif) Pour définir l'emplacement de traitement, cliquez sur Plus > Paramètres de requête. Pour Processing location (Emplacement de traitement), choisissez
US. Cette étape est facultative, car l'emplacement de traitement est automatiquement détecté selon l'emplacement de l'ensemble de données. Cliquez sur Run (Exécuter).
Lorsque la requête est terminée, cliquez sur l'onglet Results (Résultats) sous la zone de texte de la requête. Les résultats doivent se présenter sous la forme suivante :
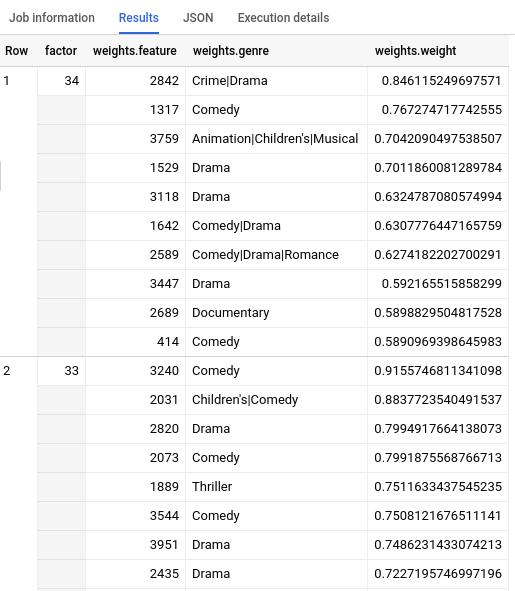
Nettoyer
Pour éviter que les ressources utilisées lors de ce tutoriel soient facturées sur votre compte Google Cloud, supprimez le projet contenant les ressources, ou conservez le projet et supprimez les ressources individuelles.
- Supprimez le projet que vous avez créé.
- Ou conservez le projet et supprimez l'ensemble de données.
Supprimer l'ensemble de données
La suppression de votre projet entraîne celle de tous les ensembles de données et de toutes les tables qui lui sont associés. Si vous préférez réutiliser le projet, vous pouvez supprimer l'ensemble de données que vous avez créé dans ce tutoriel :
Si nécessaire, ouvrez la page BigQuery dans la console Google Cloud.
Dans le panneau de navigation, cliquez sur l'ensemble de données bqml_tutorial que vous avez créé.
Cliquez sur Delete dataset (Supprimer l'ensemble de données) dans la partie droite de la fenêtre. Cette action supprime l'ensemble de données, la table et toutes les données.
Dans la boîte de dialogue Supprimer l'ensemble de données, confirmez la commande de suppression en saisissant le nom de votre ensemble de données (
bqml_tutorial), puis cliquez sur Supprimer.
Supprimer votre projet
Pour supprimer le projet :
- Dans la console Google Cloud, accédez à la page Gérer les ressources.
- Dans la liste des projets, sélectionnez le projet que vous souhaitez supprimer, puis cliquez sur Supprimer.
- Dans la boîte de dialogue, saisissez l'ID du projet, puis cliquez sur Arrêter pour supprimer le projet.
Étape suivante
- Pour en savoir plus sur le machine learning, consultez le Cours d'initiation au Machine Learning.
- Pour obtenir plus d'informations sur BigQuery ML, consultez la page Présentation de BigQuery ML.
- Pour en savoir plus sur la console Google Cloud, consultez la page Utiliser la console Google Cloud.