En este instructivo, se presenta a los analistas de datos el modelo de factorización de matrices en BigQuery ML. BigQuery ML permite a los usuarios crear y ejecutar modelos de aprendizaje automático en BigQuery mediante consultas de SQL. El objetivo es democratizar el aprendizaje automático. Para lograrlo, se habilita a los profesionales de SQL a que compilen modelos mediante sus herramientas existentes y se quita la necesidad de trasladar datos con el fin de aumentar la velocidad de desarrollo.
En este instructivo, aprenderás a crear un modelo a partir de comentarios explícitos mediante el conjunto de datos movielens1m para hacer recomendaciones con un ID de película y un ID de usuario.
El conjunto de datos de Movielens contiene las calificaciones, en una escala del 1 al 5, que los usuarios asignaron a las películas, junto con los metadatos de estas películas, como el género.
Objetivos
En este instructivo usarás:
- BigQuery ML para crear un modelo de recomendaciones explícitas mediante la declaración
CREATE MODEL - La función
ML.EVALUATEpara evaluar los modelos de AA - La función
ML.WEIGHTSpara inspeccionar los pesos de los factores latentes generados durante el entrenamiento - La función
ML.RECOMMENDa fin de generar recomendaciones para los usuarios
Costos
En este instructivo, se usan componentes facturables de Google Cloud, incluidos los siguientes:
- BigQuery
- BigQuery ML
Para obtener más información sobre los costos de BigQuery, consulta la página Precios de BigQuery.
Para obtener más información sobre los costos de BigQuery ML, consulta los precios de BigQuery ML.
Antes de comenzar
- Accede a tu cuenta de Google Cloud. Si eres nuevo en Google Cloud, crea una cuenta para evaluar el rendimiento de nuestros productos en situaciones reales. Los clientes nuevos también obtienen $300 en créditos gratuitos para ejecutar, probar y, además, implementar cargas de trabajo.
-
En la página del selector de proyectos de la consola de Google Cloud, selecciona o crea un proyecto de Google Cloud.
-
Asegúrate de que la facturación esté habilitada para tu proyecto de Google Cloud.
-
En la página del selector de proyectos de la consola de Google Cloud, selecciona o crea un proyecto de Google Cloud.
-
Asegúrate de que la facturación esté habilitada para tu proyecto de Google Cloud.
- BigQuery se habilita de forma automática en proyectos nuevos.
Para activar BigQuery en un proyecto existente, ve a
Habilita la API de BigQuery.
Paso uno: Crea tu conjunto de datos
Crea un conjunto de datos de BigQuery para almacenar tu modelo de AA:
En la consola de Google Cloud, ve a la página de BigQuery.
En el panel Explorador, haz clic en el nombre de tu proyecto.
Haz clic en Ver acciones > Crear conjunto de datos.
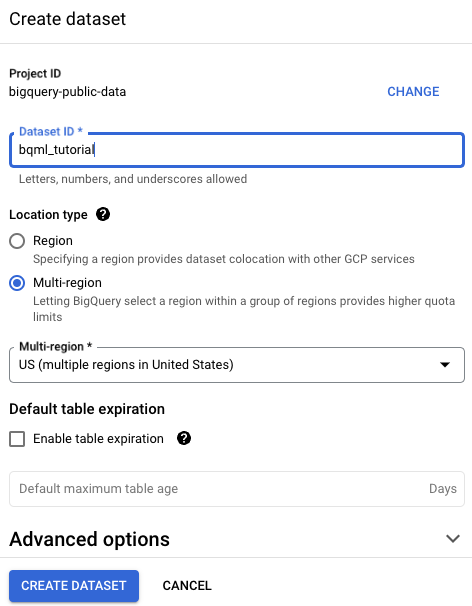
En la página Crear conjunto de datos, haz lo siguiente:
En ID del conjunto de datos, ingresa
bqml_tutorial.En Tipo de ubicación, selecciona Multirregión y, luego, EE.UU. (varias regiones en Estados Unidos).
Los conjuntos de datos públicos se almacenan en la multirregión
US. Para que sea más simple, almacena tu conjunto de datos en la misma ubicación.Deja la configuración predeterminada restante como está y haz clic en Crear conjunto de datos.
Paso dos: Carga el conjunto de datos de Movielens en BigQuery
A continuación, se muestran los pasos para cargar el conjunto de datos 1m de Movielens en BigQuery mediante las herramientas de línea de comandos de BigQuery.
Se creará un conjunto de datos llamado movielens y se almacenarán en él las tablas de movielens relevantes.
curl -O 'http://files.grouplens.org/datasets/movielens/ml-1m.zip'
unzip ml-1m.zip
bq mk --dataset movielens
sed 's/::/,/g' ml-1m/ratings.dat > ratings.csv
bq load --source_format=CSV movielens.movielens_1m ratings.csv \
user_id:INT64,item_id:INT64,rating:FLOAT64,timestamp:TIMESTAMP
Debido a que los títulos de las películas contienen dos puntos, comas y barras, debemos usar otro delimitador. Para cargar los títulos de las películas, se debe usar una variante un poco diferente de los últimos dos comandos.
sed 's/::/@/g' ml-1m/movies.dat > movie_titles.csv
bq load --source_format=CSV --field_delimiter=@ \
movielens.movie_titles movie_titles.csv \
movie_id:INT64,movie_title:STRING,genre:STRING
Paso tres: Crea el modelo de recomendaciones explícitas
A continuación, crea un modelo de recomendaciones explícitas mediante la tabla de muestra que se cargó en el paso anterior. La siguiente consulta de GoogleSQL se usa con el fin de crear el modelo que se usará para predecir una calificación de cada par de usuario y elemento.
#standardSQL CREATE OR REPLACE MODEL `bqml_tutorial.my_explicit_mf_model` OPTIONS (model_type='matrix_factorization', user_col='user_id', item_col='item_id', l2_reg=9.83, num_factors=34) AS SELECT user_id, item_id, rating FROM `movielens.movielens_1m`
Además de crear el modelo, ejecutar el comando CREATE MODEL entrena el modelo que creas.
Detalles de la consulta
La cláusula CREATE MODEL se usa para crear y entrenar el modelo llamado bqml_tutorial.my_explicit_mf_model.
La cláusula OPTIONS(model_type='matrix_factorization', user_col='user_id', ...) indica que estás creando un modelo de factorización de matrices. De forma predeterminada, esto creará un modelo de factorización de matrices explícita, a menos que se especifique feedback_type='IMPLICIT'. En Usa BigQuery ML para hacer recomendaciones de comentarios implícitos, se explicará con un ejemplo cómo crear un modelo de factorización de matrices implícita.
La declaración SELECT de esta consulta usa las siguientes columnas para generar recomendaciones.
user_id: El ID de usuario (INT64)item_id: El ID de la película (INT64)rating: La calificación explícita del 1 al 5 queuser_idotorgó aitem_id(FLOAT64)
La cláusula FROM (movielens.movielens_1m) indica que consultas la tabla movielens_1m en el conjunto de datos movielens.
Si se siguieron las instrucciones del paso dos, este conjunto de datos se encuentra en el proyecto de BigQuery.
Ejecuta la consulta CREATE MODEL
A fin de ejecutar la consulta CREATE MODEL para crear y entrenar tu modelo, sigue estos pasos:
En la consola de Google Cloud, haz clic en el botón Redactar consulta nueva.
Ingresa la siguiente consulta de GoogleSQL en el área de texto del Editor de consultas.
#standardSQL CREATE OR REPLACE MODEL `bqml_tutorial.my_explicit_mf_model` OPTIONS (model_type='matrix_factorization', user_col='user_id', item_col='item_id', l2_reg=9.83, num_factors=34) AS SELECT user_id, item_id, rating FROM `movielens.movielens_1m`
Haz clic en Ejecutar.
La consulta toma unos 10 minutos en completarse, después de eso, tu modelo (
my_explicit_mf_model) aparecerá en el panel de navegación de la consola de Google Cloud. Debido a que en la consulta se usa una declaraciónCREATE MODELpara crear un modelo, no se muestran los resultados.
Paso cuatro (opcional): Obtén estadísticas de entrenamiento
Para ver los resultados del entrenamiento de modelos, puedes usar la función ML.TRAINING_INFO o puedes ver las estadísticas en la consola de Google Cloud En este instructivo, usarás la consola de Google Cloud.
Para compilar un modelo, los algoritmos de aprendizaje automático examinan muchos ejemplos y buscan un modelo que minimice la pérdida. Este proceso se llama minimización del riesgo empírico.
Para ver las estadísticas de entrenamiento de modelos que se generaron cuando ejecutaste la consulta CREATE MODEL, sigue estos pasos:
En el panel de navegación de la consola de Google Cloud, en la sección Recursos, expande [PROJECT_ID] > bqml_tutorial y, luego, haz clic en my_explicit_mf_model.
Haga clic en la pestaña Entrenamiento y, luego, en Tabla. Los resultados deberían verse como estos:
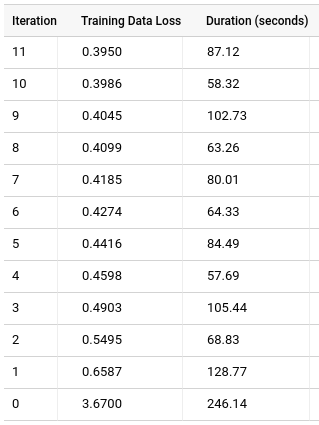
La columna Training Data Loss (Pérdida de datos de entrenamiento) representa la métrica de pérdida calculada después de que se entrena el modelo en el conjunto de datos de entrenamiento. Dado que realizaste la factorización de matrices, esta columna es el error cuadrático medio. De forma predeterminada, los modelos de factorización de matrices no dividirán los datos, por lo que la columna Pérdida de datos de evaluación no estará presente, a menos que se especifique un conjunto de datos de exclusión, ya que dividir los datos implica la posibilidad de perder todas las calificaciones de un usuario o un elemento. Como resultado, el modelo no tendrá información de factores latentes sobre usuarios o elementos faltantes.
Para obtener más detalles sobre la función
ML.TRAINING_INFO, consulta la referencia de la sintaxis de BigQuery ML.
Paso cinco: Evalúa el modelo
Después de crear el modelo, evalúa el rendimiento del recomendador mediante la función ML.EVALUATE. La función ML.EVALUATE evalúa las calificaciones previstas en comparación con las reales.
La consulta que se usa para evaluar el modelo es la siguiente:
#standardSQL
SELECT
*
FROM
ML.EVALUATE(MODEL `bqml_tutorial.my_explicit_mf_model`,
(
SELECT
user_id,
item_id,
rating
FROM
`movielens.movielens_1m`))
Detalles de la consulta
La primera sentencia SELECT recupera las columnas de tu modelo.
La cláusula FROM usa la función ML.EVALUATE en el modelo bqml_tutorial.my_explicit_mf_model.
La declaración SELECT anidada de esta consulta y la cláusula FROM son las mismas que las de la consulta CREATE MODEL.
También puedes llamar a ML.EVALUATE sin proporcionar los datos de entrada. Usará las métricas de evaluación calculadas durante el entrenamiento:
#standardSQL SELECT * FROM ML.EVALUATE(MODEL `bqml_tutorial.my_explicit_mf_model`)
Ejecuta la consulta ML.EVALUATE
Para ejecutar la consulta ML.EVALUATE que evalúa el modelo, sigue estos pasos:
En la consola de Google Cloud, haz clic en el botón Redactar consulta nueva.
Ingresa la siguiente consulta de GoogleSQL en el área de texto del Editor de consultas.
#standardSQL SELECT * FROM ML.EVALUATE(MODEL `bqml_tutorial.my_explicit_mf_model`, ( SELECT user_id, item_id, rating FROM `movielens.movielens_1m`))
De modo opcional, para configurar la ubicación de procesamiento, haga clic en Más > Configuración de la consulta (More > Query Settings). En Processing location (Ubicación de procesamiento), elige
US. Este paso es opcional porque la ubicación de procesamiento se detecta de forma automática en función de la ubicación del conjunto de datos.
Haz clic en Ejecutar.
Cuando la consulta finalice, haz clic en la pestaña Results (Resultados) debajo del área de texto de la consulta. Los resultados deberían verse así:

Debido a que realizaste una factorización de matrices explícita, los resultados incluyen las siguientes columnas:
mean_absolute_errormean_squared_errormean_squared_log_errormedian_absolute_errorr2_scoreexplained_variance
Una métrica importante en los resultados de la evaluación es la puntuación R2. La puntuación R2 es una medida estadística que determina si las predicciones de regresión lineal se aproximan a los datos reales. 0 indica que el modelo no explica la variabilidad de los datos de respuesta en torno a la media. 1 indica que el modelo explica toda la variabilidad de los datos de respuesta alrededor de la media.
Paso seis: Usa el modelo para predecir calificaciones y hacer recomendaciones
Busca todas las calificaciones de elementos de un conjunto de usuarios
ML.RECOMMEND no necesita tomar ningún argumento adicional además del modelo, pero puede incluir una tabla opcional. Si la tabla de entrada solo tiene una columna que coincide con el nombre de la columna de entrada user o item, se generarán todas las calificaciones de elementos previstas para cada user y viceversa. Ten en cuenta que si todos los users o items están en la tabla de entrada, se muestran los mismos resultados que si no pasas ningún argumento opcional a ML.RECOMMEND.
El siguiente es un ejemplo de una consulta que se ejecuta para recuperar todas las calificaciones de películas previstas de 5 usuarios:
#standardSQL
SELECT
*
FROM
ML.RECOMMEND(MODEL `bqml_tutorial.my_explicit_mf_model`,
(
SELECT
user_id
FROM
`movielens.movielens_1m`
LIMIT 5))
Detalles de la consulta
La declaración SELECT superior recupera las columnas user, item y predicted_rating.
La función ML.RECOMMEND genera la última columna mencionada. Cuando usas la función ML.RECOMMEND, el nombre de la columna de resultado del modelo es predicted_<rating_column_name>. En los modelos de factorización de matrices explícita, predicted_rating es el valor estimado de rating.
La función ML.RECOMMEND se usa para predecir calificaciones mediante el modelo bqml_tutorial.my_explicit_mf_model.
La declaración SELECT anidada de esta consulta solo selecciona la columna user_id de la tabla original que se usó para el entrenamiento.
La cláusula LIMIT (LIMIT 5) filtrará de forma aleatoria 5 user_id para enviarlos a ML.RECOMMEND.
Busca las calificaciones de todos los pares de usuario y elemento
Ahora que ya evaluaste el modelo, el siguiente paso es usarlo para predecir una calificación. Usa el modelo para predecir las calificaciones de las combinaciones de usuario y elemento de la siguiente consulta:
#standardSQL SELECT * FROM ML.RECOMMEND(MODEL `bqml_tutorial.my_explicit_mf_model`)
Detalles de la consulta
La declaración SELECT superior recupera las columnas user, item y predicted_rating.
La función ML.RECOMMEND genera la última columna mencionada. Cuando usas la función ML.RECOMMEND, el nombre de la columna de resultado del modelo es predicted_<rating_column_name>. En los modelos de factorización de matrices explícita, predicted_rating es el valor estimado de rating.
La función ML.RECOMMEND se usa para predecir calificaciones mediante el modelo bqml_tutorial.my_explicit_mf_model.
Una forma de guardarlo es la siguiente:
#standardSQL CREATE OR REPLACE TABLE `bqml_tutorial.recommend_1m` OPTIONS() AS SELECT * FROM ML.RECOMMEND(MODEL `bqml_tutorial.my_explicit_mf_model`)
Si se produce un error Query Exceeded Resource Limits con ML.RECOMMEND, vuelve a intentarlo con un nivel de facturación superior. En la herramienta de línea de comandos de BigQuery, esto se puede configurar mediante la marca --maximum_billing_tier.
Genera recomendaciones
Mediante la consulta de recomendaciones anterior, podemos establecer un orden según la calificación prevista y mostrar los elementos previstos más importantes para cada usuario. Con la siguiente consulta, se unen los item_ids con los movie_ids que se encuentran en la tabla movielens.movie_titles subida antes y muestra las 5 películas más recomendadas por usuario.
#standardSQL SELECT user_id, ARRAY_AGG(STRUCT(movie_title, genre, predicted_rating) ORDER BY predicted_rating DESC LIMIT 5) FROM ( SELECT user_id, item_id, predicted_rating, movie_title, genre FROM `bqml_tutorial.recommend_1m` JOIN `movielens.movie_titles` ON item_id = movie_id) GROUP BY user_id
Detalles de la consulta
La declaración SELECT interna realiza una unión interna en item_id desde la tabla de resultados de recomendaciones y movie_id desde la tabla movielens.movie_titles. movielens.movie_titles asigna movie_id al nombre de una película y, también, incluye los géneros de esa película según la lista de IMDB.
La declaración SELECT de nivel superior agrega los resultados de la declaración SELECT anidada mediante GROUPS BY user_id para agregar movie_title,
genre, y predicted_rating en orden descendente y solo conserva las 5 películas principales.
Ejecuta la consulta ML.RECOMMEND
Para ejecutar la consulta ML.RECOMMEND, que muestra las 5 películas más recomendadas por usuario, haz lo siguiente:
En la consola de Google Cloud, haz clic en el botón Redactar consulta nueva.
Ingresa la siguiente consulta de GoogleSQL en el área de texto del Editor de consultas.
#standardSQL CREATE OR REPLACE TABLE `bqml_tutorial.recommend_1m` OPTIONS() AS SELECT * FROM ML.RECOMMEND(MODEL `bqml_tutorial.my_explicit_mf_model`)
Haz clic en Ejecutar.
Cuando la consulta termine de ejecutarse, aparecerá (
bqml_tutorial.recommend_1m) en el panel de navegación. Debido a que en la consulta se usa una declaraciónCREATE TABLEpara crear una tabla, no verás los resultados.Redacta otra consulta nueva. Ingresa la siguiente consulta de GoogleSQL en el área de texto del Editor de consultas una vez que la consulta anterior termine de ejecutarse.
#standardSQL SELECT user_id, ARRAY_AGG(STRUCT(movie_title, genre, predicted_rating) ORDER BY predicted_rating DESC LIMIT 5) FROM ( SELECT user_id, item_id, predicted_rating, movie_title, genre FROM `bqml_tutorial.recommend_1m` JOIN `movielens.movie_titles` ON item_id = movie_id) GROUP BY user_id
De modo opcional, para configurar la ubicación de procesamiento, haga clic en Más > Configuración de la consulta (More > Query Settings). En Processing location (Ubicación de procesamiento), elige
US. Este paso es opcional porque la ubicación de procesamiento se detecta de forma automática en función de la ubicación del conjunto de datos. Haz clic en Ejecutar.
Cuando la consulta finalice, haz clic en la pestaña Results (Resultados) debajo del área de texto de la consulta. Los resultados deberían verse así:
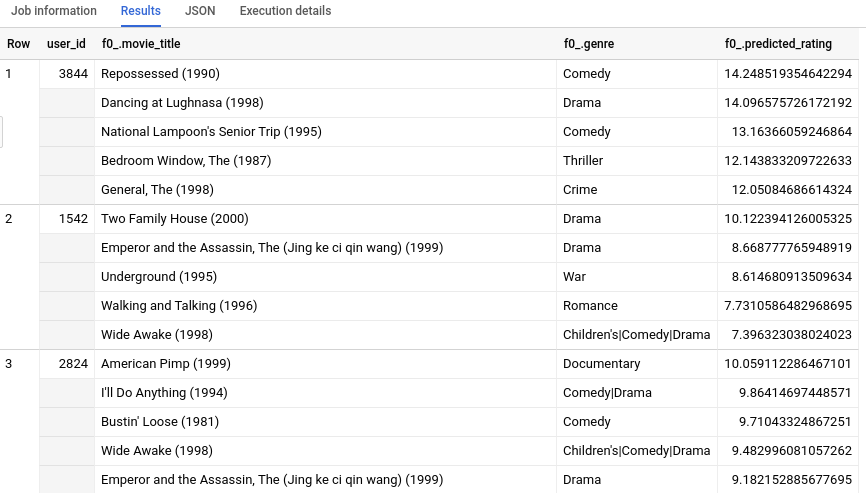
Debido a que teníamos información de metadatos adicional sobre cada movie_id además de un INT64, podemos ver información como el género de las 5 películas más recomendadas para cada usuario. Si no tienes una tabla equivalente a movietitles para los datos de entrenamiento, puede que los resultados no sean fáciles de interpretar para las personas con solo los ID de número o los hashes.
Géneros principales por factor
Si quieres conocer la correlación entre los géneros y los factores latentes, puedes ejecutar la siguiente consulta:
#standardSQL
SELECT
factor,
ARRAY_AGG(STRUCT(feature, genre,
weight)
ORDER BY
weight DESC
LIMIT
10) AS weights
FROM (
SELECT
* EXCEPT(factor_weights)
FROM (
SELECT
*
FROM (
SELECT
factor_weights,
CAST(feature AS INT64) as feature
FROM
ML.WEIGHTS(model `bqml_tutorial.my_explicit_mf_model`)
WHERE
processed_input= 'item_id')
JOIN
`movielens.movie_titles`
ON
feature = movie_id) weights
CROSS JOIN
UNNEST(weights.factor_weights)
ORDER BY
feature,
weight DESC)
GROUP BY
factor
Detalles de la consulta
La declaración SELECT más interna obtiene el item_id o el arreglo de pesos de factores de películas y, luego, lo une a la tabla movielens.movie_titles para obtener el género de cada ID de elemento.
Luego, se hace una unión cruzada (CROSS JOIN) del resultado con cada arreglo factor_weights cuyo resultado es ORDER BY feature, weight DESC.
Por último, la declaración SELECT de nivel superior agrega los resultados de su declaración interna por factor y crea un arreglo para cada factor ordenado según el peso de cada género.
Ejecuta la consulta
Para ejecutar la consulta anterior que muestra los 10 géneros principales de películas por factor, haz lo siguiente:
En la consola de Google Cloud, haz clic en el botón Redactar consulta nueva.
Ingresa la siguiente consulta de GoogleSQL en el área de texto del Editor de consultas.
#standardSQL
SELECT
factor,
ARRAY_AGG(STRUCT(feature, genre,
weight)
ORDER BY
weight DESC
LIMIT
10) AS weights
FROM (
SELECT
* EXCEPT(factor_weights)
FROM (
SELECT
*
FROM (
SELECT
factor_weights,
CAST(feature AS INT64) as feature
FROM
ML.WEIGHTS(model `bqml_tutorial.my_explicit_mf_model`)
WHERE
processed_input= 'item_id')
JOIN
`movielens.movie_titles`
ON
feature = movie_id) weights
CROSS JOIN
UNNEST(weights.factor_weights)
ORDER BY
feature,
weight DESC)
GROUP BY
factor
De modo opcional, para configurar la ubicación de procesamiento, haga clic en Más > Configuración de la consulta (More > Query Settings). En Processing location (Ubicación de procesamiento), elige
US. Este paso es opcional porque la ubicación de procesamiento se detecta de forma automática en función de la ubicación del conjunto de datos. Haz clic en Ejecutar.
Cuando la consulta finalice, haz clic en la pestaña Results (Resultados) debajo del área de texto de la consulta. Los resultados deberían verse así:
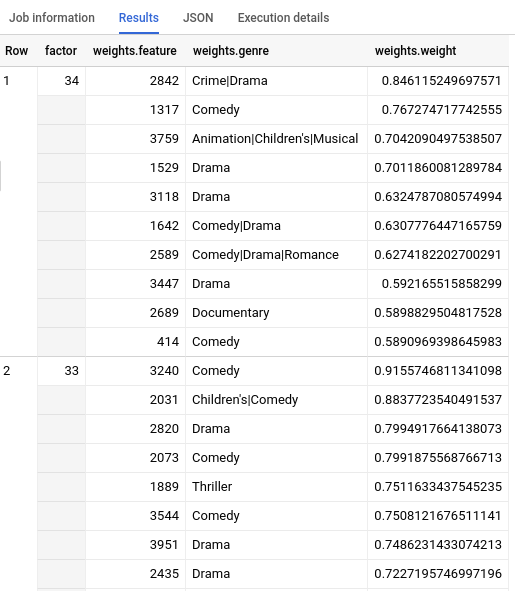
Limpia
Para evitar que se apliquen cargos a tu cuenta de Google Cloud por los recursos usados en este instructivo, borra el proyecto que contiene los recursos o conserva el proyecto y borra los recursos individuales.
- Puedes borrar el proyecto que creaste.
- De lo contrario, puedes mantener el proyecto y borrar el conjunto de datos.
Borra tu conjunto de datos
Borrar tu proyecto quita todos sus conjuntos de datos y tablas. Si prefieres volver a usar el proyecto, puedes borrar el conjunto de datos que creaste en este instructivo:
Si es necesario, abre la página de BigQuery en la consola de Google Cloud.
En el panel de navegación, haz clic en el conjunto de datos bqml_tutorial que creaste.
Haz clic en Borrar conjunto de datos en el lado derecho de la ventana. Esta acción borra el conjunto de datos, la tabla y todos los datos.
En el cuadro de diálogo Borrar conjunto de datos, ingresa el nombre del conjunto de datos (
bqml_tutorial) y, luego, haz clic en Borrar para confirmar el comando de borrado.
Borra tu proyecto
Para borrar el proyecto, haz lo siguiente:
- En la consola de Google Cloud, ve a la página Administrar recursos.
- En la lista de proyectos, elige el proyecto que quieres borrar y haz clic en Borrar.
- En el diálogo, escribe el ID del proyecto y, luego, haz clic en Cerrar para borrar el proyecto.
Próximos pasos
- Para obtener más información sobre el aprendizaje automático, consulta el Curso intensivo de aprendizaje automático.
- Para obtener una descripción general de BigQuery ML, consulta Introducción a BigQuery ML.
- Para obtener más información sobre la consola de Google Cloud, consulta Usa la consola de Google Cloud.