En este instructivo, aprenderás a crear un modelo de serie temporal multivariable (ARIMA_PLUS_XREG) para realizar previsiones de series temporales con las siguientes tablas de muestra del conjunto de datos epa_historical_air_quality:
- tabla de muestra
epa_historical_air_quality.pm25_nonfrm_daily_summary. - tabla de muestra
epa_historical_air_quality.wind_daily_summary. - tabla de muestra
epa_historical_air_quality.temperature_daily_summary.
El conjunto de datos epa_historical_air_quality contiene la información diaria de PM 2.5, temperatura y velocidad del viento recopilada de varias ciudades de EE.UU.
Objetivos
En este instructivo usarás lo siguiente:
- La declaración
CREATE MODEL, para crear un modelo de serie temporal - La función
ML.ARIMA_EVALUATE, para inspeccionar la información de evaluación relacionada con ARIMA en el modelo - La función
ML.ARIMA_COEFFICIENTS, para inspeccionar los coeficientes del modelo - La función
ML.FORECAST, para prever el PM 2.5 diario - La función
ML.EVALUATE, para evaluar el modelo con datos reales. - La función
ML.EXPLAIN_FORECAST, que permite recuperar varios componentes de las series temporales (como la temporada, las tendencias y las atribuciones de atributos) que puedes usar para explicar los resultados de la previsión.
Costos
En este instructivo, se usan componentes facturables de Google Cloud, incluidos los siguientes:
- BigQuery
- BigQuery ML
Para obtener más información sobre los costos de BigQuery, consulta la página de precios de BigQuery.
Para obtener más información sobre los costos de BigQuery ML, consulta los precios de BigQuery ML.
Antes de comenzar
- Accede a tu cuenta de Google Cloud. Si eres nuevo en Google Cloud, crea una cuenta para evaluar el rendimiento de nuestros productos en situaciones reales. Los clientes nuevos también obtienen $300 en créditos gratuitos para ejecutar, probar y, además, implementar cargas de trabajo.
-
En la página del selector de proyectos de la consola de Google Cloud, selecciona o crea un proyecto de Google Cloud.
-
Asegúrate de que la facturación esté habilitada para tu proyecto de Google Cloud.
-
En la página del selector de proyectos de la consola de Google Cloud, selecciona o crea un proyecto de Google Cloud.
-
Asegúrate de que la facturación esté habilitada para tu proyecto de Google Cloud.
- BigQuery se habilita de forma automática en proyectos nuevos.
Para activar BigQuery en un proyecto existente, ve a
Habilita la API de BigQuery.
Paso uno: Crea tu conjunto de datos
Crea un conjunto de datos de BigQuery para almacenar tu modelo de AA:
En la consola de Google Cloud, ve a la página de BigQuery.
En el panel Explorador, haz clic en el nombre de tu proyecto.
Haz clic en Ver acciones > Crear conjunto de datos.

En la página Crear conjunto de datos, haz lo siguiente:
En ID del conjunto de datos, ingresa
bqml_tutorial.En Tipo de ubicación, selecciona Multirregión y, luego, EE.UU. (varias regiones en Estados Unidos).
Los conjuntos de datos públicos se almacenan en la multirregión
US. Para que sea más simple, almacena tu conjunto de datos en la misma ubicación.Deja la configuración predeterminada restante como está y haz clic en Crear conjunto de datos.

Paso dos: Crea una tabla de series temporales con atributos adicionales
Los datos de PM2.5, temperatura y velocidad del viento están en tablas separadas.
Para simplificar las siguientes consultas, puedes unir las tablas con las columnas siguientes para crear una tabla nueva bqml_tutorial.seattle_air_quality_daily:
- fecha: la fecha de la observación
- PM2.5: el valor promedio de PM2.5 de cada día.
- wind_speed: la velocidad del viento promedio de cada día
- temperatura: la temperatura más alta de cada día
La tabla nueva tiene datos diarios del 11/08/2009 al 31/01/2022.
En la siguiente consulta de Google SQL, la cláusula FROM bigquery-public-data.epa_historical_air_quality.*_daily_summary indica que consultas las tablas *_daily_summary en el conjunto de datos epa_historical_air_quality. Estas tablas son tablas particionadas.
#standardSQL
CREATE TABLE `bqml_tutorial.seattle_air_quality_daily`
AS
WITH
pm25_daily AS (
SELECT
avg(arithmetic_mean) AS pm25, date_local AS date
FROM
`bigquery-public-data.epa_historical_air_quality.pm25_nonfrm_daily_summary`
WHERE
city_name = 'Seattle'
AND parameter_name = 'Acceptable PM2.5 AQI & Speciation Mass'
GROUP BY date_local
),
wind_speed_daily AS (
SELECT
avg(arithmetic_mean) AS wind_speed, date_local AS date
FROM
`bigquery-public-data.epa_historical_air_quality.wind_daily_summary`
WHERE
city_name = 'Seattle' AND parameter_name = 'Wind Speed - Resultant'
GROUP BY date_local
),
temperature_daily AS (
SELECT
avg(first_max_value) AS temperature, date_local AS date
FROM
`bigquery-public-data.epa_historical_air_quality.temperature_daily_summary`
WHERE
city_name = 'Seattle' AND parameter_name = 'Outdoor Temperature'
GROUP BY date_local
)
SELECT
pm25_daily.date AS date, pm25, wind_speed, temperature
FROM pm25_daily
JOIN wind_speed_daily USING (date)
JOIN temperature_daily USING (date)
Para ejecutar la consulta, sigue estos pasos:
En la consola de Google Cloud, haz clic en el botón Redactar consulta nueva.
Ingresa la consulta de GoogleSQL anterior en el área de texto del Editor de consultas.
Haz clic en Ejecutar.
Paso tres (opcional): Visualiza la serie temporal que deseas prever
Antes de crear el modelo, es útil ver cómo se ve la serie temporal de entrada. Puedes hacer esto con Looker Studio.
En la siguiente consulta de GoogleSQL, la cláusula FROM bqml_tutorial.seattle_air_quality_daily indica que consultas la tabla seattle_air_quality_daily en el conjunto de datos bqml_tutorial que acabas de crear.
#standardSQL SELECT * FROM `bqml_tutorial.seattle_air_quality_daily`
Para ejecutar la consulta, sigue estos pasos:
En la consola de Google Cloud, haz clic en el botón Redactar consulta nueva.
Ingresa la siguiente consulta de GoogleSQL en el área de texto del Editor de consultas.
#standardSQL SELECT * FROM `bqml_tutorial.seattle_air_quality_daily`
Haz clic en Ejecutar.
Después de que se ejecuta esta consulta, el resultado es similar a la siguiente captura de pantalla. En la captura de pantalla, puedes ver que esta serie temporal tiene 3960 datos. Haz clic en el botón Explorar datos y, luego, en Explorar con Looker Studio. Looker Studio se abre en una pestaña nueva. Completa los siguientes pasos en la pestaña nueva.
En el panel Gráfico (Chart), elige Gráfico de serie temporal (Time series chart):
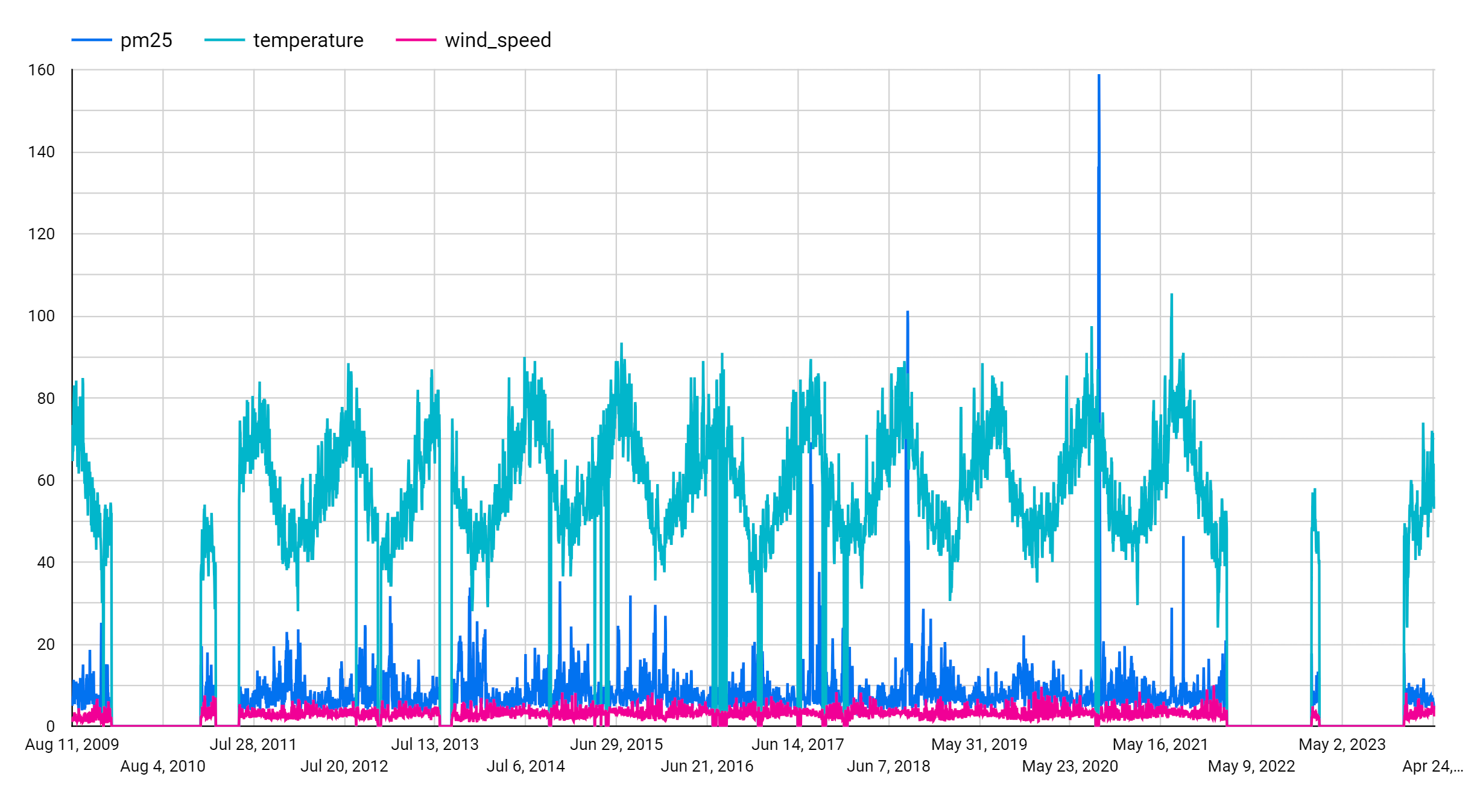
En el panel SETUP, debajo del panel Gráfico, ve a la sección Métrica. Agrega los campos pm25, temperatura y wind_speed y, luego, quita la métrica predeterminada Conteo de registros. También puede establecer un período personalizado, p.ej., Del 1 de enero de 2019 al 31 de diciembre de 2021, para que las series temporales sean más cortas. Esto se muestra en la siguiente figura.
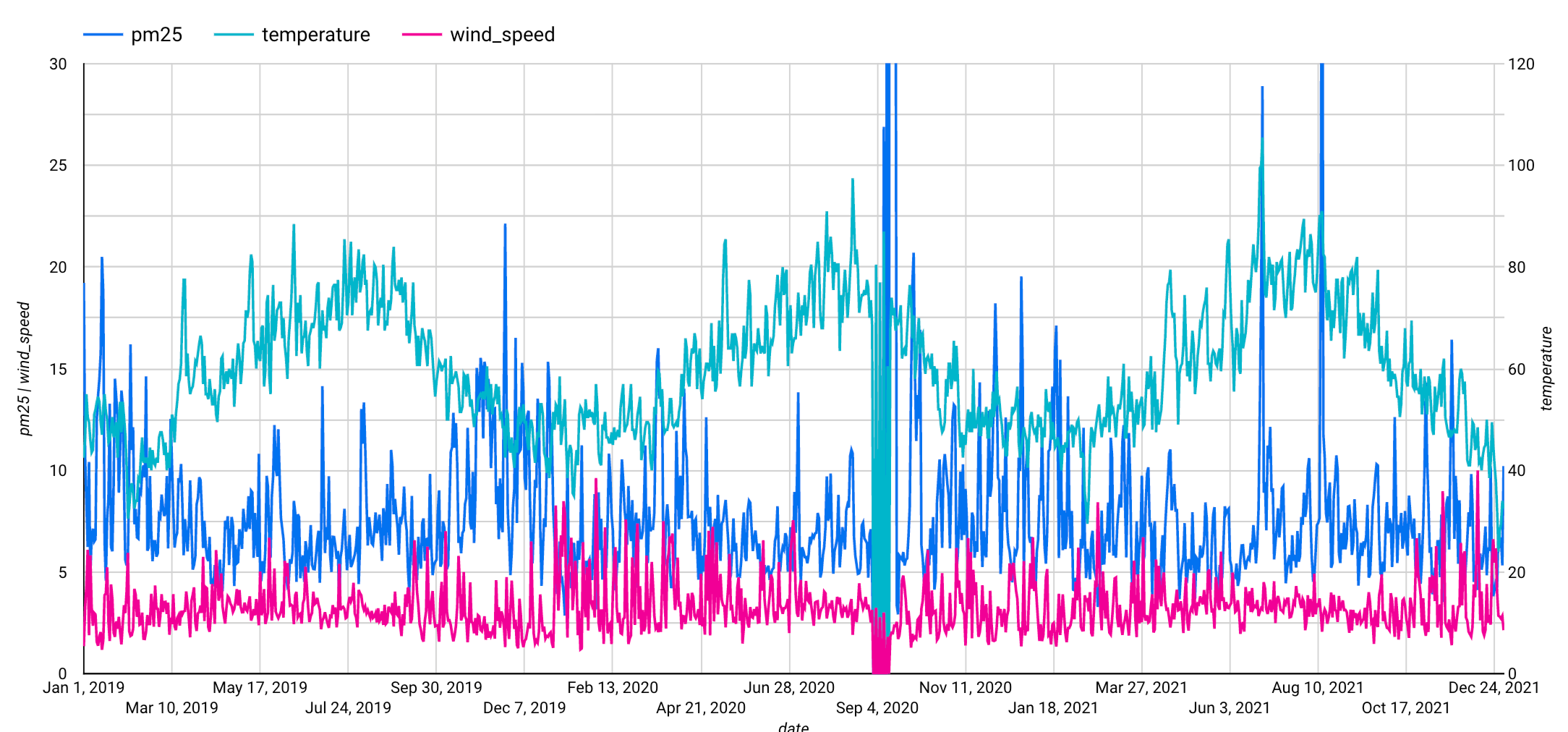
Después de completar estos pasos, aparecerá el siguiente gráfico. El gráfico muestra que la serie temporal de entrada tiene un patrón estacional semanal.
Paso cuatro: Crea un modelo de serie temporal
A continuación, crea un modelo de serie temporal con los datos de calidad de aire anteriores.
En la siguiente consulta de GoogleSQL, se crea un modelo que se usa para prever pm25.
La cláusula CREATE MODEL crea y entrena un modelo llamado bqml_tutorial.seattle_pm25_xreg_model.
#standardSQL
CREATE OR REPLACE
MODEL
`bqml_tutorial.seattle_pm25_xreg_model`
OPTIONS (
MODEL_TYPE = 'ARIMA_PLUS_XREG',
time_series_timestamp_col = 'date',
time_series_data_col = 'pm25')
AS
SELECT
date,
pm25,
temperature,
wind_speed
FROM
`bqml_tutorial.seattle_air_quality_daily`
WHERE
date
BETWEEN DATE('2012-01-01')
AND DATE('2020-12-31')
La cláusula OPTIONS(model_type='ARIMA_PLUS_XREG', time_series_timestamp_col='date', ...) indica que creas un ARIMA con un modelo de regresores externos. De forma predeterminada, auto_arima=TRUE, por lo que el algoritmo auto.ARIMA ajusta de forma automática los hiperparámetros en los modelos ARIMA_PLUS_XREG. El algoritmo se adapta a decenas de modelos de candidatos y elige el mejor con el criterio de información Akaike (AIC) más bajo.
Además, debido a que el valor predeterminado es data_frequency='AUTO_FREQUENCY', el proceso de entrenamiento infiere de forma automática la frecuencia de datos de la serie temporal de entrada.
Ejecuta la consulta CREATE MODEL para crear y entrenar el modelo:
En la consola de Google Cloud, haz clic en el botón Redactar consulta nueva.
Ingresa la consulta de GoogleSQL anterior en el área de texto del Editor de consultas.
Haz clic en Ejecutar.
La consulta toma unos 20 segundos en completarse, después de eso, tu modelo (
seattle_pm25_xreg_model) aparece en el panel de navegación. Debido a que en la consulta se usa una declaraciónCREATE MODELpara crear un modelo, no se muestran los resultados.
Paso cinco: Inspecciona las métricas de evaluación de todos los modelos evaluados
Después de crear el modelo, puedes usar la función ML.ARIMA_EVALUATE para ver las métricas de evaluación de todos los modelos candidatos que se evaluaron durante el proceso de ajuste automático de hiperparámetros.
En la siguiente consulta de GoogleSQL, la cláusula FROM usa la función ML.ARIMA_EVALUATE en el modelo, bqml_tutorial.seattle_pm25_xreg_model. De forma predeterminada, esta consulta muestra las métricas de evaluación de todos los modelos candidatos.
Para ejecutar la ML.ARIMA_EVALUATE, sigue estos pasos:
En la consola de Google Cloud, haz clic en el botón Redactar consulta nueva.
Ingresa la siguiente consulta de GoogleSQL en el área de texto del Editor de consultas.
#standardSQL SELECT * FROM ML.ARIMA_EVALUATE(MODEL `bqml_tutorial.seattle_pm25_xreg_model`)
Haz clic en Ejecutar.
Cuando la consulta finalice, haga clic en la pestaña Resultados (Results) debajo del área de texto de la consulta. Los resultados deberían ser similares a los de la siguiente captura de pantalla:

Los resultados incluyen las siguientes columnas:
non_seasonal_pnon_seasonal_dnon_seasonal_qhas_driftlog_likelihoodAICvarianceseasonal_periodshas_holiday_effecthas_spikes_and_dipshas_step_changeserror_message
Las siguientes cuatro columnas (
non_seasonal_{p,d,q}yhas_drift) definen un modelo ARIMA en la canalización de entrenamiento. Las tres métricas posteriores (log_likelihood,AICyvariance) son relevantes para el proceso de ajuste del modelo ARIMA.El algoritmo
auto.ARIMAprimero usa la prueba de KPSS para decidir que el mejor valor denon_seasonal_des 1. Cuandonon_seasonal_des 1, auto.ARIMA entrena 42 candidatos diferentes de modelos ARIMA en paralelo. Ten en cuenta que, cuandonon_seasonal_dno es 1, auto.ARIMA entrena 21 modelos candidatos diferentes. En este ejemplo, los 42 modelos candidatos son válidos. Por lo tanto, el resultado contiene 42 filas y cada una está asociada con un candidato de modelo ARIMA. Ten en cuenta que, para algunas series temporales, algunos modelos candidatos no son válidos, ya que no son invertibles o no son fijos. Estos modelos no válidos se excluyen del resultado, lo que hará que tenga menos de 42 filas. Estos modelos candidatos se ordenan por AIC en orden ascendente. El modelo de la primera fila tiene el AIC más bajo y se considera el mejor modelo. El mejor modelo se guarda como el modelo final y se usa cuando llamas aML.FORECAST,ML.EVALUATE, yML.ARIMA_COEFFICIENTScomo se muestra en los siguientes pasos.La columna
seasonal_periodses el patrón estacional dentro de la serie temporal de entrada. No tiene nada que ver con el modelo ARIMA, por lo tanto, tiene el mismo valor en todas las filas de salida. Informa un patrón semanal, que está dentro de nuestras expectativas, como se describe en el paso dos.Las columnas
has_holiday_effect,has_spikes_and_dipsyhas_step_changessolo se propagan cuandodecompose_time_series=TRUE. Se relacionan con el efecto, los aumentos y las disminuciones de las festividades, y los cambios de pasos dentro de la serie temporal de entrada, que no están relacionados con el modelo ARIMA. Por lo tanto, todas son iguales en todas las filas de salida, excepto en los modelos con fallas.La columna
error_messagemuestra el posible error generado durante el proceso de ajusteauto.ARIMA. Un motivo posible es que las columnasnon_seasonal_p,non_seasonal_d,non_seasonal_qyhas_driftseleccionadas no pueden estabilizar la serie temporal. Para recuperar el mensaje de error posible de todos los modelos candidatos, configurashow_all_candidate_models=true.
Paso seis: Inspecciona los coeficientes del modelo
La función ML.ARIMA_COEFFICIENTS recupera los coeficientes del modelo ARIMA, bqml_tutorial.seattle_pm25_xreg_model. ML.ARIMA_COEFFICIENTS toma el modelo como la única entrada.
Ejecuta la consulta ML.ARIMA_COEFFICIENTS:
En la consola de Google Cloud, haz clic en el botón Redactar consulta nueva.
Ingresa la siguiente consulta de GoogleSQL en el área de texto del Editor de consultas.
#standardSQL SELECT * FROM ML.ARIMA_COEFFICIENTS(MODEL `bqml_tutorial.seattle_pm25_xreg_model`)
Haz clic en Ejecutar.
Los resultados deberían verse así:
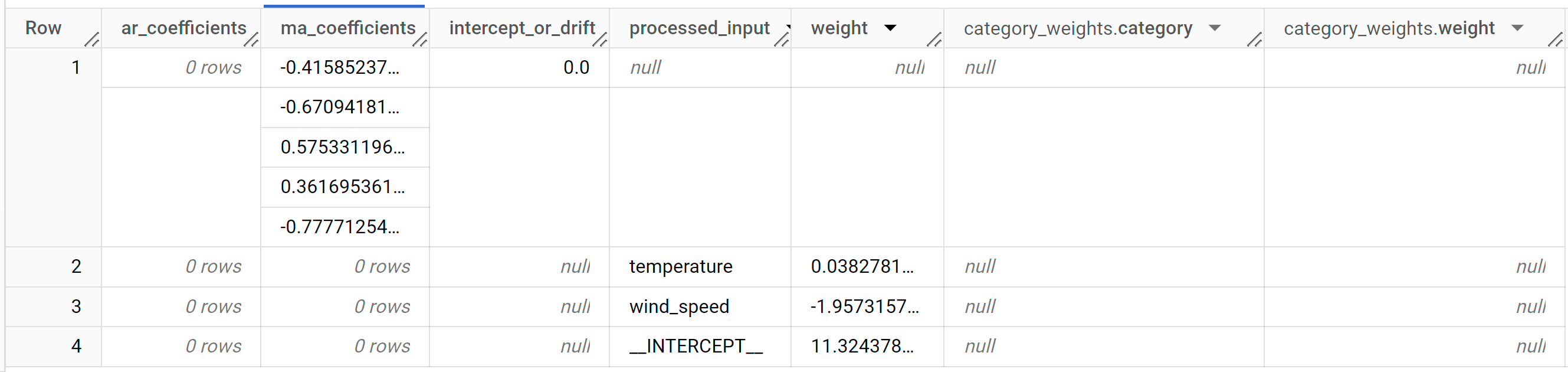
Los resultados incluyen las siguientes columnas:
ar_coefficientsma_coefficientsintercept_or_driftprocessed_inputweightcategory_weights.categorycategory_weights.weight
ar_coefficientsmuestra los coeficientes del modelo de la parte autorregresiva (AR) del modelo ARIMA. De manera similar,ma_coefficientsmuestra los coeficientes del modelo de la parte de promedio móvil (MA). Ambos son arrays, cuyas longitudes son iguales anon_seasonal_pynon_seasonal_q, respectivamente. A partir del resultado deML.ARIMA_EVALUATE, el mejor modelo de la fila superior tiene unnon_seasonal_pde 0 y unnon_seasonal_qde 5. Por lo tanto,ar_coefficientses un array vacío yma_coefficientses un arreglo de longitud 5. Elintercept_or_driftes el término constante en el modelo ARIMA.processed_inputy la columnaweightycategory_weightscorrespondientes muestran los pesos de cada atributo y la interceptación en el modelo de regresión lineal. Si el atributo es numérico, el peso está en la columnaweight. Si el atributo es un atributo categórico, elcategory_weightses unARRAYdeSTRUCT, en el queSTRUCTcontiene los nombres y los pesos de las categorías.
Paso siete: Usa el modelo para prever la serie temporal
La función ML.FORECAST prevé valores de series temporales futuras con un intervalo de predicción mediante el modelo bqml_tutorial.seattle_pm25_xreg_model y los valores de atributos futuros.
En la siguiente consulta de GoogleSQL, la cláusula STRUCT(30 AS horizon, 0.8 AS confidence_level) indica que la consulta prevé 30 puntos futuros y genera un intervalo de predicción con un nivel de confianza del 80%. ML.FORECAST toma el modelo, los valores de atributos futuros y algunos argumentos opcionales.
Para ejecutar la consulta ML.FORECAST, sigue estos pasos:
En la consola de Google Cloud, haz clic en el botón Redactar consulta nueva.
Ingresa la siguiente consulta de GoogleSQL en el área de texto del Editor de consultas.
#standardSQL SELECT * FROM ML.FORECAST( MODEL `bqml_tutorial.seattle_pm25_xreg_model`, STRUCT(30 AS horizon, 0.8 AS confidence_level), ( SELECT date, temperature, wind_speed FROM `bqml_tutorial.seattle_air_quality_daily` WHERE date > DATE('2020-12-31') ))Haz clic en Ejecutar.
Los resultados deberían verse así:
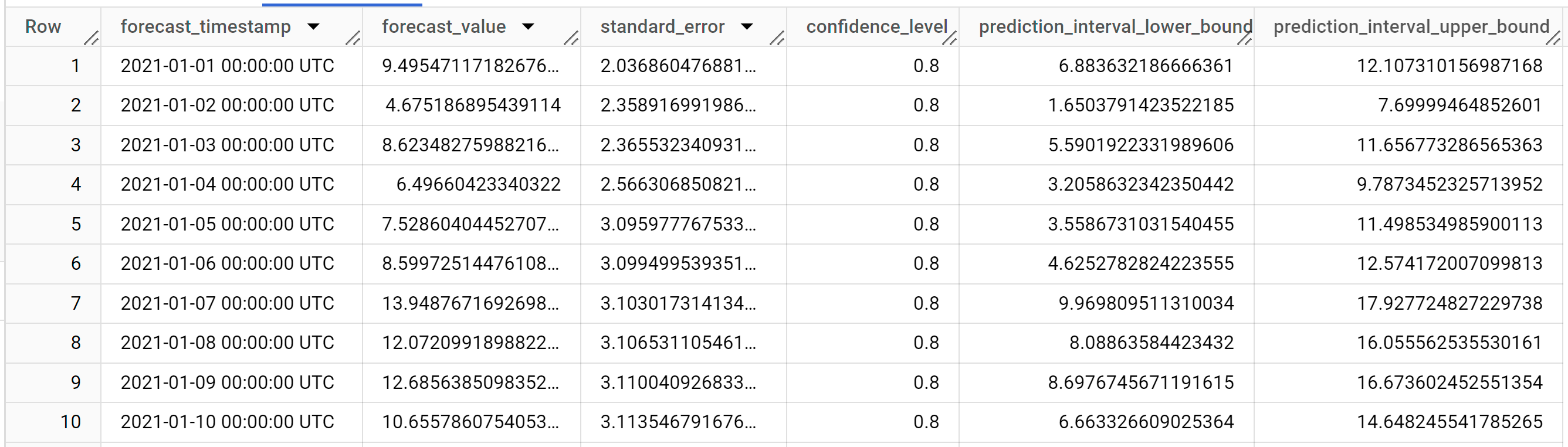
Los resultados incluyen las siguientes columnas:
forecast_timestampforecast_valuestandard_errorconfidence_levelprediction_interval_lower_boundprediction_interval_upper_bound
Las filas de salida se ordenan en orden cronológico de
forecast_timestamp. En la previsión de series temporales, el intervalo de confianza, que capturan los límites inferior y superior, es tan importante como elforecast_value. Elforecast_valuees el punto medio del intervalo de confianza. El intervalo de confianza depende delstandard_errory elconfidence_level.
Paso ocho: Evalúa la exactitud de la previsión con datos reales
Para evaluar la precisión de la previsión con los datos reales, puedes usar la función ML.EVALUATE con tu modelo, bqml_tutorial.seattle_pm25_xreg_model y la tabla de datos real.
Para ejecutar la consulta ML.EVALUATE, sigue estos pasos:
En la consola de Google Cloud, haz clic en el botón Redactar consulta nueva.
Ingresa la siguiente consulta de GoogleSQL en el área de texto del Editor de consultas.
#standardSQL SELECT * FROM ML.EVALUATE( MODEL `bqml_tutorial.seattle_pm25_xreg_model`, ( SELECT date, pm25, temperature, wind_speed FROM `bqml_tutorial.seattle_air_quality_daily` WHERE date > DATE('2020-12-31') ), STRUCT( TRUE AS perform_aggregation, 30 AS horizon))El segundo parámetro corresponde a los datos reales con las características futuras, que se usan para prever los valores futuros a fin de compararlos con los datos reales. El tercer parámetro es una estructura de parámetros para esta función.
Haz clic en Ejecutar.
Los resultados deberían verse así:

Paso nueve: Explica los resultados de la previsión
Para comprender cómo se prevén las series temporales, la función ML.EXPLAIN_FORECAST
prevé valores de series temporales futuras con un intervalo de predicción a través del
modelo bqml_tutorial.seattle_pm25_xreg_model y, al mismo tiempo. time muestra todos los
componentes separados de la serie temporal.
Al igual que la función ML.FORECAST, la cláusula STRUCT(30 AS horizon, 0.8 AS confidence_level) indica que la consulta prevé 30 puntos temporales futuros y genera un intervalo de predicción con una confianza del 80%. La función ML.EXPLAIN_FORECAST toma el modelo,
los valores de atributos futuros y algunos argumentos opcionales como entrada.
Para ejecutar la consulta ML.EXPLAIN_FORECAST, sigue estos pasos:
En la consola de Google Cloud, haz clic en el botón Redactar consulta nueva.
Ingresa la siguiente consulta de GoogleSQL en el área de texto del Editor de consultas.
#standardSQL SELECT * FROM ML.EXPLAIN_FORECAST( MODEL `bqml_tutorial.seattle_pm25_xreg_model`, STRUCT(30 AS horizon, 0.8 AS confidence_level), ( SELECT date, temperature, wind_speed FROM `bqml_tutorial.seattle_air_quality_daily` WHERE date > DATE('2020-12-31') ))Haz clic en Ejecutar.
La consulta toma menos de un segundo en completarse. Los resultados deberían verse como estos:
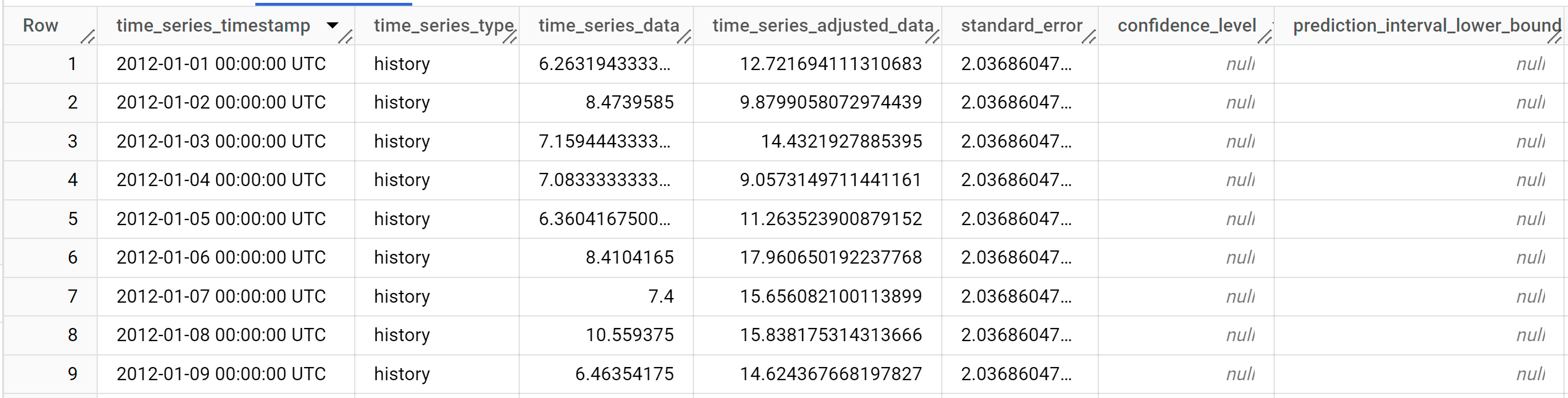
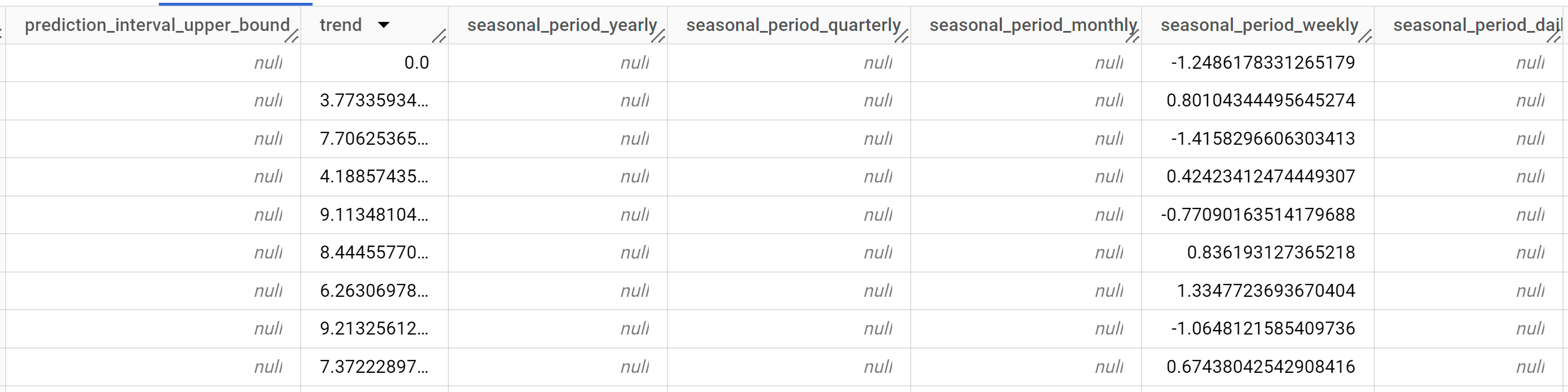
Los resultados incluyen las siguientes columnas:
time_series_timestamptime_series_typetime_series_datatime_series_adjusted_datastandard_errorconfidence_levelprediction_interval_lower_boundprediction_interval_lower_boundtrendseasonal_period_yearlyseasonal_period_quarterlyseasonal_period_monthlyseasonal_period_weeklyseasonal_period_dailyholiday_effectspikes_and_dipsstep_changesresidualattribution_temperatureattribution_wind_speedattribution___INTERCEPT__
Las filas de salida se ordenan en orden cronológico de
time_series_timestamp. Los diferentes componentes se enumeran como columnas del resultado. Para obtener más información, consultaML.EXPLAIN_FORECAST.
Limpia
Para evitar que se apliquen cargos a tu cuenta de Google Cloud por los recursos usados en este instructivo, borra el proyecto que contiene los recursos o conserva el proyecto y borra los recursos individuales.
- Puedes borrar el proyecto que creaste.
- De lo contrario, puedes mantener el proyecto y borrar el conjunto de datos.
Borra tu conjunto de datos
Borrar tu proyecto quita todos sus conjuntos de datos y tablas. Si prefieres volver a usar el proyecto, puedes borrar el conjunto de datos que creaste en este instructivo:
Si es necesario, abre la página de BigQuery en la consola de Google Cloud.
En el panel de navegación, haz clic en el conjunto de datos bqml_tutorial que creaste.
Haz clic en Borrar conjunto de datos en el lado derecho de la ventana. Esta acción borra el conjunto de datos, la tabla y todos los datos.
En el cuadro de diálogo Borrar conjunto de datos, ingresa el nombre del conjunto de datos (
bqml_tutorial) y, luego, haz clic en Borrar para confirmar el comando de borrado.
Borra tu proyecto
Para borrar el proyecto, haz lo siguiente:
- En la consola de Google Cloud, ve a la página Administrar recursos.
- En la lista de proyectos, elige el proyecto que quieres borrar y haz clic en Borrar.
- En el diálogo, escribe el ID del proyecto y, luego, haz clic en Cerrar para borrar el proyecto.
¿Qué sigue?
- Obtén información sobre cómo realizar varias previsiones de series temporales con una sola consulta a partir de los datos de viajes de Citi Bike en NYC.
- Obtén información sobre cómo acelerar ARIMA_PLUS para habilitar el pronóstico de 1 millón de series temporales en horas.
- Para obtener más información sobre el aprendizaje automático, consulta el Curso intensivo de aprendizaje automático.
- Para obtener una descripción general de BigQuery ML, consulta Introducción a BigQuery ML.
- Para obtener más información sobre la consola de Google Cloud, consulta Usa la consola de Google Cloud.