Snowflake에서 BigQuery로 마이그레이션: 개요
이 문서에서는 Snowflake에서 BigQuery로 데이터를 마이그레이션하는 방법을 보여줍니다.
다른 데이터 웨어하우스에서 BigQuery로 마이그레이션하는 일반적인 프레임워크는 개요: BigQuery로 데이터 웨어하우스 마이그레이션을 참고하세요.
Snowflake에서 BigQuery로 마이그레이션 개요
Snowflake 마이그레이션의 경우 기존 작업에 미치는 영향이 최소화되는 마이그레이션 아키텍처를 설정하는 것이 좋습니다. 다음 예에서는 다른 워크로드를 BigQuery로 오프로드하면서 기존 도구와 프로세스를 재사용할 수 있는 아키텍처를 보여줍니다.
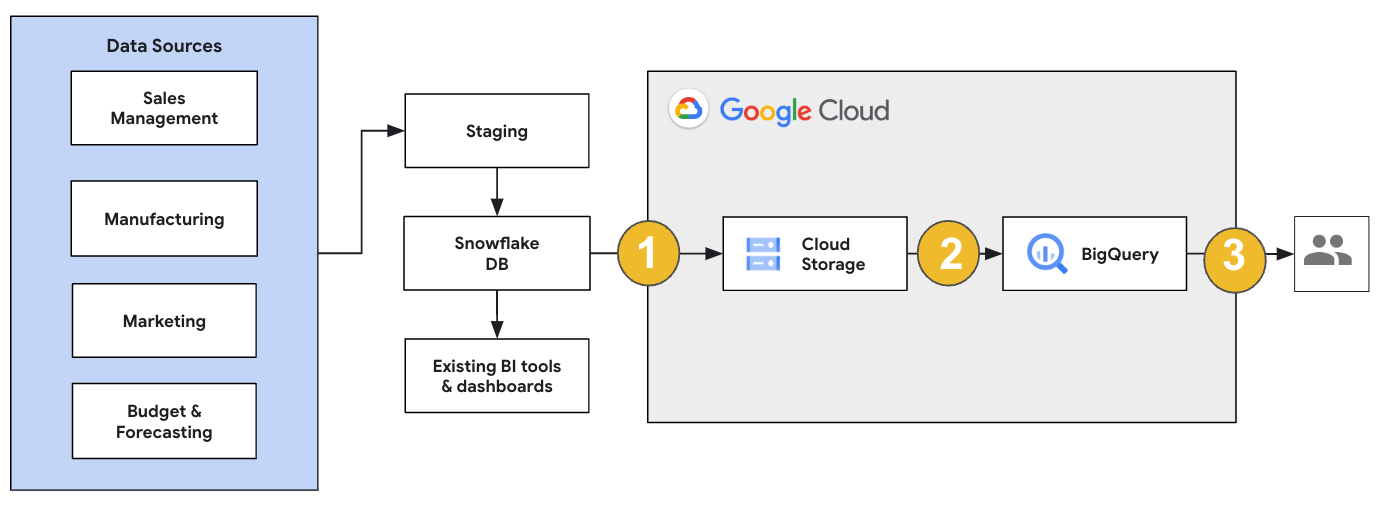
또한 이전 버전에 대해 보고서 및 대시보드를 검증할 수 있습니다. 자세한 내용은 BigQuery로 데이터 웨어하우스 마이그레이션: 확인 및 검증을 참고하세요.
개별 워크로드 마이그레이션
Snowflake 마이그레이션을 계획할 때 다음 순서로 다음 워크로드를 개별적으로 마이그레이션하는 것이 좋습니다.
스키마 마이그레이션
Snowflake 환경에서 필요한 스키마를 BigQuery로 복제하는 것부터 시작하세요. BigQuery Migration Service를 사용하여 스키마를 마이그레이션하는 것이 좋습니다. BigQuery Migration Service는 별표 스키마 또는 눈송이 스키마와 같은 다양한 데이터 모델 설계 패턴을 지원하므로 새 스키마를 위해 업스트림 데이터 파이프라인을 업데이트할 필요가 없습니다. BigQuery Migration Service는 스키마 추출 및 변환 기능을 비롯한 자동 스키마 마이그레이션도 제공하여 마이그레이션 프로세스를 간소화합니다.
SQL 쿼리 마이그레이션
SQL 쿼리를 마이그레이션하기 위해 BigQuery Migration Service는 Snowflake SQL 쿼리를 GoogleSQL SQL로 자동 변환하는 다양한 SQL 변환 기능을 제공합니다. 예를 들어 쿼리를 일괄적으로 변환하는 일괄 SQL 변환기, 개별 쿼리를 변환하는 대화형 SQL 변환기, SQL 변환 API 등이 있습니다. 이러한 변환 서비스에는 SQL 쿼리 이전 프로세스를 더욱 간소화하는 Gemini로 향상된 기능도 포함되어 있습니다.
SQL 쿼리를 번역할 때 번역된 쿼리를 주의 깊게 검토하여 데이터 유형과 테이블 구조가 올바르게 처리되었는지 확인하세요. 이를 위해 다양한 시나리오와 데이터로 광범위한 테스트 사례를 만드는 것이 좋습니다. 그런 다음 BigQuery에서 이러한 테스트 사례를 실행하여 결과를 원래 Snowflake 결과와 비교합니다. 차이가 있는 경우 변환된 쿼리를 분석하고 수정합니다.
데이터 이전
데이터를 BigQuery로 전송하도록 데이터 마이그레이션 파이프라인을 설정하는 방법에는 여러 가지가 있습니다. 일반적으로 이러한 파이프라인은 동일한 패턴을 따릅니다.
소스에서 데이터 추출: 소스에서 추출된 데이터를 온프레미스 환경의 스테이징 스토리지에 복사합니다. 자세한 내용은 BigQuery로 데이터 웨어하우스 마이그레이션: 소스 데이터 추출을 참조하세요.
스테이징 Cloud Storage 버킷으로 데이터 전송: 소스에서 데이터 추출을 완료한 후 Cloud Storage에서 임시 버킷으로 데이터를 전송합니다. 전송 중인 데이터 양과 사용 가능한 네트워크 대역폭에 따라 몇 가지 옵션이 있습니다.
BigQuery 데이터 세트 및 외부 데이터 소스 위치 또는 Cloud Storage 버킷이 동일한 리전에 있는지 확인해야 합니다.
Cloud Storage 버킷에서 BigQuery로 데이터 로드: 데이터가 이제 Cloud Storage 버킷에 배치되었습니다. BigQuery로 데이터를 업로드하는 데에는 몇 가지 옵션이 있습니다. 이러한 옵션은 변환할 데이터 양에 따라 달라집니다. 또는 ELT 방식에 따라 BigQuery 내에서 데이터를 변환할 수도 있습니다.
JSON 파일, Avro 파일 또는 CSV 파일에서 대량으로 데이터를 가져올 때는 BigQuery가 스키마를 자동으로 감지하므로 이를 사전에 정의할 필요가 없습니다. EDW 워크로드의 스키마 마이그레이션 프로세스 개요를 자세히 살펴보려면 스키마 및 데이터 마이그레이션 프로세스를 참조하세요.
Snowflake 데이터 마이그레이션을 지원하는 도구 목록은 마이그레이션 도구를 참고하세요.
Snowflake 데이터 이전 파이프라인 설정의 엔드 투 엔드 예시는 Snowflake 이전 파이프라인 예시를 참고하세요.
스키마 및 쿼리 최적화
스키마 마이그레이션 후에는 결과에 따라 성능을 테스트하고 최적화할 수 있습니다. 예를 들어 데이터를 보다 효율적으로 관리하고 쿼리할 수 있도록 파티션 나누기를 도입할 수 있습니다. 테이블 파티션 나누기를 사용하면 수집 시간, 타임스탬프, 정수 범위에 따라 파티션 나누기를 수행해서 쿼리 성능을 향상시키고 비용을 제어할 수 있습니다. 자세한 내용은 파티션을 나눈 테이블 소개를 참조하세요.
클러스터링된 테이블은 또 다른 스키마 최적화입니다. 테이블을 클러스터링하여 테이블 스키마의 콘텐츠를 기반으로 테이블 데이터를 정리하고 절을 필터링하는 데 사용하는 쿼리나 데이터를 집계하는 쿼리의 성능을 개선할 수 있습니다. 자세한 내용은 클러스터링된 테이블 소개를 참고하세요.
지원되는 데이터 유형, 속성 및 파일 형식
Snowflake와 BigQuery는 이름이 다른 경우도 있지만 대부분 동일한 데이터 유형을 지원합니다. Snowflake 및 BigQuery에서 지원되는 전체 데이터 유형 목록은 데이터 유형을 참고하세요. 대화형 SQL 변환기, SQL 변환 API, 일괄 SQL 변환기와 같은 SQL 변환 도구를 사용하여 다양한 SQL 언어를 GoogleSQL로 변환할 수도 있습니다.
BigQuery에서 지원되는 데이터 유형에 대한 자세한 내용은 GoogleSQL 데이터 유형을 참고하세요.
Snowflake는 다음 파일 형식으로 데이터를 내보낼 수 있습니다. 다음 형식을 BigQuery에 직접 로드할 수 있습니다.
- Cloud Storage에서 CSV 데이터 로드
- Cloud Storage에서 Parquet 데이터 로드
- Cloud Storage에서 JSON 데이터 로드
- Apache Iceberg에서 데이터 쿼리
마이그레이션 도구
다음 목록은 Snowflake에서 BigQuery로 데이터를 마이그레이션하는 데 사용할 수 있는 도구를 보여줍니다. Snowflake 마이그레이션 파이프라인에서 이러한 도구를 함께 사용하는 방법의 예는 Snowflake 마이그레이션 파이프라인 예시를 참고하세요.
COPY INTO <location>명령어: Snowflake에서 이 명령어를 사용하여 Snowflake 테이블에서 지정된 Cloud Storage 버킷으로 직접 데이터를 추출합니다. 엔드 투 엔드 예시는 GitHub에서 Snowflake에서 BigQuery로(snowflake2bq)를 참조하세요.- Apache Sqoop: Snowflake에서 HDFS 또는 Cloud Storage로 데이터를 추출하려면 Sqoop 및 Snowflake의 JDBC 드라이버를 사용하여 Hadoop 작업을 제출합니다. Sqoop는 Dataproc 환경에서 실행됩니다.
- Snowflake JDBC: JDBC를 지원하는 대부분의 클라이언트 도구 또는 애플리케이션에 이 드라이버를 사용합니다.
다음 일반 도구를 사용해서 Snowflake에서 BigQuery로 데이터를 마이그레이션할 수 있습니다.
- Snowflake용 BigQuery Data Transfer Service 커넥터 미리보기: Cloud Storage 데이터를 BigQuery로 자동화된 방식으로 일괄 전송할 수 있습니다.
- Google Cloud CLI: 이 명령줄 도구를 사용해서 다운로드한 Snowflake 파일을 Cloud Storage에 복사합니다.
- bq 명령줄 도구: 이 명령줄 도구를 사용해서 BigQuery와 상호작용합니다. 일반적인 사용 사례에는 BigQuery 테이블 스키마 만들기, 테이블에 Cloud Storage 데이터 로드, 쿼리 실행이 포함됩니다.
- Cloud Storage 클라이언트 라이브러리: Cloud Storage 클라이언트 라이브러리가 사용되는 커스텀 도구를 사용해서 다운로드한 Snowflake 파일을 Cloud Storage에 복사합니다.
- BigQuery 클라이언트 라이브러리: BigQuery 클라이언트 라이브러리로 빌드된 커스텀 도구를 사용해서 BigQuery와 상호작용합니다.
- BigQuery 쿼리 스케줄러: 이 기본 제공되는 BigQuery 기능을 사용해서 반복되는 SQL 쿼리를 예약합니다.
- Cloud Composer: 이 완전 관리형 Apache Airflow 환경을 사용해서 BigQuery 로드 작업 및 변환을 조정합니다.
BigQuery에 데이터 로드에 대한 자세한 내용은 BigQuery에 데이터 로드를 참조하세요.
Snowflake 마이그레이션 파이프라인 예시
다음 섹션에서는 ELT, ETL, 파트너 도구의 세 가지 프로세스를 사용하여 Snowflake에서 BigQuery로 데이터를 마이그레이션하는 방법에 대한 예시를 보여줍니다.
추출, 로드, 변환
다음 두 가지 방법으로 추출, 로드, 변환 (ELT) 프로세스를 설정할 수 있습니다.
- 파이프라인을 사용하여 Snowflake에서 데이터를 추출하고 BigQuery로 데이터를 로드
- 다른 Google Cloud 제품을 사용하여 Snowflake에서 데이터를 추출합니다.
파이프라인을 사용하여 Snowflake에서 데이터 추출
Snowflake에서 데이터를 추출하여 Cloud Storage에 직접 로드하려면 snowflake2bq 도구를 사용하세요.
그런 다음 다음 도구 중 하나를 사용하여 Cloud Storage에서 BigQuery로 데이터를 로드할 수 있습니다.
- Cloud Storage용 BigQuery Data Transfer Service 커넥터
- bq 명령줄 도구를 사용하는
LOAD명령어 - BigQuery API 클라이언트 라이브러리
Snowflake에서 데이터를 추출하는 기타 도구
다음 도구를 사용하여 Snowflake에서 데이터를 추출할 수도 있습니다.
- Dataflow
- Cloud Data Fusion
- Dataproc
- Apache Spark BigQuery 커넥터
- Apache Spark용 Snowflake 커넥터
- Hadoop BigQuery 커넥터
- Snowflake에서 Cloud Storage로 데이터를 추출하기 위한 Snowflake 및 Sqoop의 JDBC 드라이버:
BigQuery에 데이터를 로드하는 기타 도구
다음 도구를 사용하여 BigQuery에 데이터를 로드할 수도 있습니다.
- Dataflow
- Cloud Data Fusion
- Dataproc
- Trifacta 제공 Dataprep
추출, 변환, 로드
BigQuery에 로드하기 전 데이터를 변환하려면 다음 도구를 고려하세요.
- Dataflow
- JDBC to BigQuery 템플릿 코드를 클론하고 템플릿을 수정하여 Apache Beam 변환을 추가합니다.
- Cloud Data Fusion
- 재사용 가능한 파이프라인을 만들고 CDAP 플러그인을 사용하여 데이터를 변환합니다.
- Dataproc
- Spark SQL 또는 지원되는 Spark 언어(예: Scala, Java, Python, R)로 커스텀 코드를 사용하여 데이터를 변환합니다.
마이그레이션을 위한 파트너 도구
EDW 마이그레이션을 전문으로 하는 여러 공급업체가 있습니다. 주요 파트너 및 제공 솔루션 목록은 BigQuery 파트너를 참고하세요.
Snowflake 내보내기 튜토리얼
다음 튜토리얼에서는 COPY INTO <location> Snowflake 명령어를 사용하는 Snowflake에서 BigQuery로의 샘플 데이터 내보내기를 보여줍니다.
코드 샘플이 포함된 자세한 단계별 프로세스는 Google Cloud 전문 서비스 Snowflake to BigQuery 도구를 참고하세요.
내보내기 준비
다음 단계에 따라 Snowflake 데이터를 Cloud Storage 또는 Amazon Simple Storage Service (Amazon S3) 버킷으로 추출하여 내보내기를 위해 Snowflake 데이터를 준비할 수 있습니다.
Cloud Storage
이 튜토리얼에서는 PARQUET 형식으로 파일을 준비합니다.
Snowflake SQL 문을 사용하여 명명된 파일 형식 사양을 만듭니다.
create or replace file format NAMED_FILE_FORMAT type = 'PARQUET'
NAMED_FILE_FORMAT을 파일 형식 이름으로 바꿉니다. 예를 들면my_parquet_unload_format입니다.CREATE STORAGE INTEGRATION명령어로 통합을 만듭니다.create storage integration INTEGRATION_NAME type = external_stage storage_provider = gcs enabled = true storage_allowed_locations = ('BUCKET_NAME')
다음을 바꿉니다.
INTEGRATION_NAME: 스토리지 통합의 이름입니다. 예를 들면gcs_int입니다.BUCKET_NAME: Cloud Storage 버킷의 경로입니다. 예를 들면gcs://mybucket/extract/입니다.
DESCRIBE INTEGRATION명령어로 Snowflake의 Cloud Storage 서비스 계정을 검색합니다.desc storage integration INTEGRATION_NAME;
출력은 다음과 비슷합니다.
+-----------------------------+---------------+-----------------------------------------------------------------------------+------------------+ | property | property_type | property_value | property_default | +-----------------------------+---------------+-----------------------------------------------------------------------------+------------------| | ENABLED | Boolean | true | false | | STORAGE_ALLOWED_LOCATIONS | List | gcs://mybucket1/path1/,gcs://mybucket2/path2/ | [] | | STORAGE_BLOCKED_LOCATIONS | List | gcs://mybucket1/path1/sensitivedata/,gcs://mybucket2/path2/sensitivedata/ | [] | | STORAGE_GCP_SERVICE_ACCOUNT | String | service-account-id@iam.gserviceaccount.com | | +-----------------------------+---------------+-----------------------------------------------------------------------------+------------------+
STORAGE_GCP_SERVICE_ACCOUNT로 나열된 서비스 계정에 스토리지 통합 명령에 지정된 버킷에 대한 읽기 및 쓰기 액세스 권한을 부여합니다. 이 예시에서는service-account-id@서비스 계정에<var>UNLOAD_BUCKET</var>버킷에 대한 읽기 및 쓰기 액세스 권한을 부여합니다.이전에 만든 통합을 참조하는 외부 Cloud Storage 스테이지를 만듭니다.
create or replace stage STAGE_NAME url='UNLOAD_BUCKET' storage_integration = INTEGRATION_NAME file_format = NAMED_FILE_FORMAT;
다음을 바꿉니다.
STAGE_NAME: Cloud Storage 스테이지 객체의 이름입니다. 예를 들면my_ext_unload_stage입니다.
Amazon S3
다음 예시에서는 Snowflake 테이블에서 Amazon S3 버킷으로 데이터를 이동하는 방법을 보여줍니다.
Snowflake에서 Snowflake가 외부 Cloud Storage 스테이지에 참조된 Amazon S3 버킷에 쓰기를 수행할 수 있도록 스토리지 통합 객체를 구성합니다.
이 단계에는 Amazon S3 버킷에 대한 액세스 권한 구성, Amazon Web Services (AWS) IAM 역할 만들기, Snowflake에서
CREATE STORAGE INTEGRATION명령어를 사용한 스토리지 통합 만들기가 포함됩니다.create storage integration INTEGRATION_NAME type = external_stage storage_provider = s3 enabled = true storage_aws_role_arn = 'arn:aws:iam::001234567890:role/myrole' storage_allowed_locations = ('BUCKET_NAME')
다음을 바꿉니다.
INTEGRATION_NAME: 스토리지 통합의 이름입니다. 예를 들면s3_int입니다.BUCKET_NAME: 파일을 로드할 Amazon S3 버킷의 경로 예를 들면s3://unload/files/입니다.
DESCRIBE INTEGRATION명령어를 사용하여 AWS IAM 사용자를 검색합니다.desc integration INTEGRATION_NAME;
출력은 다음과 비슷합니다.
+---------------------------+---------------+================================================================================+------------------+ | property | property_type | property_value | property_default | +---------------------------+---------------+================================================================================+------------------| | ENABLED | Boolean | true | false | | STORAGE_ALLOWED_LOCATIONS | List | s3://mybucket1/mypath1/,s3://mybucket2/mypath2/ | [] | | STORAGE_BLOCKED_LOCATIONS | List | s3://mybucket1/mypath1/sensitivedata/,s3://mybucket2/mypath2/sensitivedata/ | [] | | STORAGE_AWS_IAM_USER_ARN | String | arn:aws:iam::123456789001:user/abc1-b-self1234 | | | STORAGE_AWS_ROLE_ARN | String | arn:aws:iam::001234567890:role/myrole | | | STORAGE_AWS_EXTERNAL_ID | String | MYACCOUNT_SFCRole=
| | +---------------------------+---------------+================================================================================+------------------+ 스키마에 대한
CREATE STAGE권한과 스토리지 통합에 대한USAGE권한이 있는 역할을 만듭니다.CREATE role ROLE_NAME; GRANT CREATE STAGE ON SCHEMA public TO ROLE ROLE_NAME; GRANT USAGE ON INTEGRATION s3_int TO ROLE ROLE_NAME;
ROLE_NAME을 역할 이름으로 바꿉니다. 예를 들면myrole입니다.AWS IAM 사용자에게 Amazon S3 버킷에 액세스하도록 권한을 부여하고
CREATE STAGE명령어를 사용하여 외부 스테이지를 만듭니다.USE SCHEMA mydb.public; create or replace stage STAGE_NAME url='BUCKET_NAME' storage_integration = INTEGRATION_NAMEt file_format = NAMED_FILE_FORMAT;
다음을 바꿉니다.
STAGE_NAME: Cloud Storage 스테이지 객체의 이름입니다. 예를 들면my_ext_unload_stage입니다.
Snowflake 데이터 내보내기
데이터를 준비한 후 데이터를 Google Cloud로 이동할 수 있습니다.
COPY INTO 명령어를 사용하여 외부 스테이지 객체 STAGE_NAME를 지정하여 Snowflake 데이터베이스 테이블에서 Cloud Storage 또는 Amazon S3 버킷으로 데이터를 복사합니다.
copy into @STAGE_NAME/d1 from TABLE_NAME;
TABLE_NAME을 Snowflake 데이터베이스 테이블 이름으로 바꿉니다.
이 명령어를 실행하면 테이블 데이터가 Cloud Storage 또는 Amazon S3 버킷에 연결된 스테이지 객체에 복사됩니다. 파일에 d1 접두사가 포함되어 있습니다.
기타 내보내기 방법
데이터 내보내기에 Azure Blob Storage를 사용하려면 Microsoft Azure에 언로드에 설명된 단계를 따르세요. 그런 다음 Storage Transfer Service를 사용하여 내보낸 파일을 Cloud Storage에 전송합니다.
가격 책정
Snowflake 마이그레이션을 계획할 때는 BigQuery에서 데이터를 전송하고, 데이터를 저장하고, 서비스를 사용하는 비용을 고려하세요. 자세한 내용은 가격 책정을 참조하세요.
Snowflake 또는 AWS에서 데이터를 이동하는 데 이그레스 비용이 발생할 수 있습니다. 리전 간에 데이터를 전송하거나 서로 다른 클라우드 제공업체 간에 데이터를 전송할 때 추가 비용이 발생할 수도 있습니다.
다음 단계
- 마이그레이션 후 성능 및 최적화