Migration de Snowflake vers BigQuery : présentation
Ce document vous explique comment migrer vos données de Snowflake vers BigQuery.
Pour obtenir un cadre général pour migrer d'autres entrepôts de données vers BigQuery, consultez Présentation : Migrer des entrepôts de données vers BigQuery.
Présentation de la migration de Snowflake vers BigQuery
Pour une migration Snowflake, nous vous recommandons de configurer une architecture de migration qui affecte le moins possible les opérations existantes. L'exemple suivant montre une architecture dans laquelle vous pouvez réutiliser vos outils et processus existants tout en déchargeant d'autres charges de travail vers BigQuery.
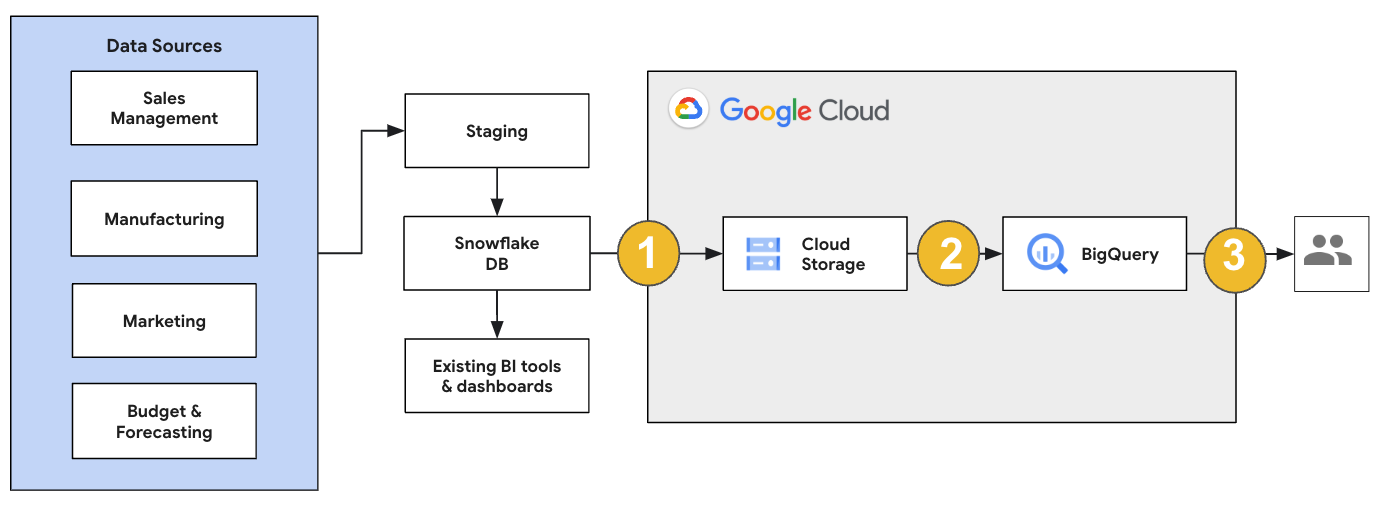
Vous pouvez également valider les rapports et les tableaux de bord par rapport aux versions précédentes. Pour en savoir plus, consultez Migrer des entrepôts de données vers BigQuery : Vérifier et valider.
Migrer des charges de travail individuelles
Lorsque vous planifiez votre migration Snowflake, nous vous recommandons de migrer les charges de travail suivantes individuellement et dans l'ordre suivant :
Migrer le schéma
Commencez par répliquer les schémas nécessaires de votre environnement Snowflake dans BigQuery. Nous vous recommandons d'utiliser le service de migration BigQuery pour migrer votre schéma. Le service de migration BigQuery est compatible avec un large éventail de modèles de conception de modèles de données, tels que le schéma en étoile ou le schéma en flocon de neige. Vous n'avez donc pas besoin de mettre à jour vos pipelines de données en amont pour un nouveau schéma. Le service de migration BigQuery propose également la migration automatisée des schémas, y compris des fonctionnalités d'extraction et de traduction des schémas, pour simplifier votre processus de migration.
Migrer des requêtes SQL
Pour migrer vos requêtes SQL, le service de migration BigQuery propose différentes fonctionnalités de traduction SQL permettant d'automatiser la conversion de vos requêtes SQL Snowflake en requêtes SQL GoogleSQL. Par exemple, le traducteur SQL par lot permet de traduire les requêtes de manière groupée, le traducteur SQL interactif permet de traduire les requêtes individuelles et l'API de traduction SQL. Ces services de traduction incluent également des fonctionnalités optimisées par Gemini pour simplifier davantage le processus de migration de vos requêtes SQL.
Lorsque vous traduisez vos requêtes SQL, examinez-les attentivement pour vérifier que les types de données et les structures de table sont correctement gérés. Pour ce faire, nous vous recommandons de créer un large éventail de cas de test avec différents scénarios et données. Exécutez ensuite ces cas de test sur BigQuery pour comparer les résultats à ceux d'origine de Snowflake. S'il y en a, analysez et corrigez les requêtes converties.
Migrer les données
Il existe plusieurs façons de configurer votre pipeline de migration de données pour transférer vos données vers BigQuery. En général, ces pipelines suivent le même schéma :
Extraire les données de votre source : copiez les fichiers extraits de votre source vers un stockage de préproduction dans votre environnement sur site. Pour en savoir plus, consultez la section Migrer des entrepôts de données vers BigQuery : extraire les données sources.
Transférer des données vers un bucket Cloud Storage de préproduction : une fois l'extraction des données de votre source terminée, vous les transférez vers un bucket temporaire dans Cloud Storage. Selon la quantité de données transférées et la bande passante réseau disponible, vous avez le choix entre plusieurs options.
Il est important de vérifier que l'emplacement de votre ensemble de données BigQuery et celui de votre source de données externe, ou de votre bucket Cloud Storage, se trouvent dans la même région.
Charger les données du bucket Cloud Storage dans BigQuery : vos données se trouvent désormais dans un bucket Cloud Storage. Plusieurs options permettent d'importer les données dans BigQuery. Ces options dépendent du degré de transformation nécessaire sur les données. Vous pouvez également transformer vos données dans BigQuery en suivant l'approche ELT.
Lorsque vous importez vos données de manière groupée à partir d'un fichier JSON, Avro ou CSV, BigQuery détecte automatiquement le schéma. Vous n'avez donc pas besoin de le prédéfinir. Pour obtenir une présentation détaillée du processus de migration de schéma pour les charges de travail d'entreposage de données, consultez la page Processus de migration du schéma et des données.
Pour obtenir la liste des outils permettant de migrer des données Snowflake, consultez Outils de migration.
Pour obtenir des exemples de bout en bout de configuration d'un pipeline de migration de données Snowflake, consultez Exemples de pipeline de migration Snowflake.
Optimiser le schéma et les requêtes
Après la migration du schéma, vous pouvez tester les performances et effectuer des optimisations en fonction des résultats. Par exemple, vous pouvez introduire le partitionnement pour améliorer la gestion et l'interrogation de vos données. Le partitionnement de tables vous permet d'améliorer les performances des requêtes et de contrôler les coûts en effectuant un partitionnement par temps d'ingestion, horodatage ou plage d'entiers. Pour plus d'informations, consultez la page Présentation des tables partitionnées.
Les tables en cluster constituent une autre optimisation de schéma. Vous pouvez regrouper vos tables pour organiser les données en fonction du contenu du schéma de la table. Cela améliore les performances des requêtes qui utilisent des clauses de filtre ou qui agrègent des données. Pour en savoir plus, consultez Présentation des tables en cluster.
Types de données, de propriétés et de formats de fichiers compatibles
Snowflake et BigQuery sont compatibles avec la plupart des mêmes types de données, bien qu'ils utilisent parfois des noms différents. Pour obtenir la liste complète des types de données compatibles avec Snowflake et BigQuery, consultez Types de données. Vous pouvez également utiliser des outils de traduction SQL, tels que le traducteur SQL interactif, l'API de traduction SQL ou le traducteur SQL par lot, pour traduire différents dialectes SQL en GoogleSQL.
Pour en savoir plus sur les types de données compatibles avec BigQuery, consultez la page Types de données GoogleSQL.
Snowflake peut exporter des données aux formats suivants : Vous pouvez charger les formats suivants directement dans BigQuery :
- Charger des données CSV à partir de Cloud Storage
- Charger des données Parquet depuis Cloud Storage
- Charger des données JSON à partir de Cloud Storage
- Interrogez des données à partir d'Apache Iceberg.
Outils de migration
La liste suivante décrit les outils que vous pouvez utiliser pour migrer des données depuis Snowflake vers BigQuery. Pour obtenir des exemples d'utilisation conjointe de ces outils dans un pipeline de migration Snowflake, consultez Exemples de pipeline de migration Snowflake.
- Commande
COPY INTO <location>: utilisez cette commande dans Snowflake pour extraire les données d'une table Snowflake directement dans un bucket Cloud Storage spécifié. Pour obtenir un exemple de bout en bout, consultez la page Snowflake vers BigQuery (snowflake2bq) sur GitHub. - Apache Sqoop : pour extraire les données de Snowflake dans HDFS ou Cloud Storage, envoyez des tâches Hadoop avec le pilote JDBC de Sqoop et de Snowflake. Sqoop s'exécute dans un environnement Dataproc.
- Pilote JDBC de Snowflake : utilisez ce pilote avec la plupart des outils clients ou des applications compatibles avec JDBC.
Vous pouvez utiliser les outils génériques suivants pour migrer des données depuis Snowflake vers BigQuery :
- Connecteur Service de transfert de données BigQuery pour Snowflake Aperçu : effectuez un transfert par lot automatisé de données Cloud Storage vers BigQuery.
- Google Cloud CLI : copiez les fichiers Snowflake téléchargés dans Cloud Storage à l'aide de cet outil de ligne de commande.
- Outil de ligne de commande bq : interagissez avec BigQuery à l'aide de cet outil de ligne de commande. Les cas d'utilisation courants incluent la création de schémas de table BigQuery, le chargement de données Cloud Storage dans des tables et l'exécution de requêtes.
- Bibliothèques clientes Cloud Storage: copiez les fichiers Snowflake téléchargés dans Cloud Storage à l'aide d'un outil personnalisé qui utilise les bibliothèques clientes Cloud Storage.
- Bibliothèques clientes BigQuery: interagissez avec BigQuery à l'aide d'un outil personnalisé basé sur la bibliothèque cliente BigQuery.
- Programmeur de requêtes BigQuery : programmez des requêtes SQL récurrentes grâce à cette fonctionnalité BigQuery intégrée.
- Cloud Composer: utilisez cet environnement entièrement géré Apache Airflow pour orchestrer des tâches de chargement et des transformations BigQuery.
Pour en savoir plus sur le chargement des données dans BigQuery, consultez la page Charger des données dans BigQuery.
Exemples de pipelines de migration Snowflake
Les sections suivantes présentent des exemples de migration de données depuis Snowflake vers BigQuery à l'aide de trois processus différents : ELT, ETL et outils partenaires.
Extraction, chargement et transformation
Vous pouvez configurer un processus ELT (extraction, chargement et transformation) de deux manières :
- Utiliser un pipeline pour extraire des données de Snowflake et les charger dans BigQuery
- Extrayez des données de Snowflake à l'aide d'autres produits Google Cloud .
Utiliser un pipeline pour extraire des données depuis Snowflake
Pour extraire des données de Snowflake et les charger directement dans Cloud Storage, utilisez l'outil snowflake2bq.
Vous pouvez ensuite charger vos données depuis Cloud Storage vers BigQuery à l'aide de l'un des outils suivants :
- Connecteur du service de transfert de données BigQuery pour Cloud Storage
- La commande
LOADà l'aide de l'outil de ligne de commande bq - Bibliothèques clientes de l'API BigQuery
Autres outils pour extraire des données de Snowflake
Vous pouvez également utiliser les outils suivants pour extraire des données de Snowflake :
- Dataflow
- Cloud Data Fusion
- Dataproc
- Connecteur Apache Spark BigQuery
- Connecteur Snowflake pour Apache Spark
- Connecteur Hadoop BigQuery
- Le pilote JDBC de Snowflake et Sqoop pour extraire les données de Snowflake dans Cloud Storage :
Autres outils pour charger des données dans BigQuery
Vous pouvez également utiliser les outils suivants pour charger des données dans BigQuery :
- Dataflow
- Cloud Data Fusion
- Dataproc
- Dataprep by Trifacta
Extraction, transformation et chargement
Si vous souhaitez transformer vos données avant de les charger dans BigQuery, pensez aux outils suivants :
- Dataflow
- Clonez le code du modèle JDBC vers BigQuery, puis modifiez-le pour ajouter des transformations Apache Beam.
- Cloud Data Fusion
- Créez un pipeline réutilisable et transformez vos données à l'aide des plug-ins CDAP.
- Dataproc
- Transformez vos données à l'aide de Spark SQL ou de code personnalisé dans l'un des langages Spark compatibles, tels que Scala, Java, Python ou R.
Outils partenaires pour la migration
Plusieurs fournisseurs sont spécialisés dans l'espace de migration d'entrepôt de données d'entreprise. Pour obtenir la liste des partenaires clés et des solutions qu'ils proposent, consultez la page Partenaires BigQuery.
Tutoriel sur l'exportation Snowflake
Le tutoriel suivant présente un exemple d'exportation de données depuis Snowflake vers BigQuery utilisant la commande COPY INTO <location> de Snowflake.
Pour obtenir un processus détaillé avec des exemples de code, consultez l'outil de services professionnelsGoogle Cloud Snowflake vers BigQuery.
Préparer l'exportation
Pour préparer vos données Snowflake à l'exportation, vous pouvez les extraire dans un bucket Cloud Storage ou Amazon Simple Storage Service (Amazon S3) en suivant les étapes ci-dessous :
Cloud Storage
Ce tutoriel prépare le fichier au format PARQUET.
Utilisez les instructions SQL Snowflake pour créer une spécification de format de fichier nommé.
create or replace file format NAMED_FILE_FORMAT type = 'PARQUET'
Remplacez
NAMED_FILE_FORMATpar le nom du format de fichier. Exemple :my_parquet_unload_formatCréez une intégration avec la commande
CREATE STORAGE INTEGRATION.create storage integration INTEGRATION_NAME type = external_stage storage_provider = gcs enabled = true storage_allowed_locations = ('BUCKET_NAME')
Remplacez les éléments suivants :
INTEGRATION_NAME: nom de l'intégration de stockage. Par exemple,gcs_int.BUCKET_NAME: chemin d'accès au bucket Cloud Storage. Par exemple,gcs://mybucket/extract/.
Récupérez le compte de service Cloud Storage pour Snowflake avec la commande
DESCRIBE INTEGRATION.desc storage integration INTEGRATION_NAME;
Le résultat ressemble à ce qui suit :
+-----------------------------+---------------+-----------------------------------------------------------------------------+------------------+ | property | property_type | property_value | property_default | +-----------------------------+---------------+-----------------------------------------------------------------------------+------------------| | ENABLED | Boolean | true | false | | STORAGE_ALLOWED_LOCATIONS | List | gcs://mybucket1/path1/,gcs://mybucket2/path2/ | [] | | STORAGE_BLOCKED_LOCATIONS | List | gcs://mybucket1/path1/sensitivedata/,gcs://mybucket2/path2/sensitivedata/ | [] | | STORAGE_GCP_SERVICE_ACCOUNT | String | service-account-id@iam.gserviceaccount.com | | +-----------------------------+---------------+-----------------------------------------------------------------------------+------------------+
Accordez au compte de service listé en tant que
STORAGE_GCP_SERVICE_ACCOUNTun accès en lecture et en écriture au bucket spécifié dans la commande d'intégration de stockage. Dans cet exemple, accordez au compte de serviceservice-account-id@un accès en lecture et en écriture au bucket<var>UNLOAD_BUCKET</var>.Créez une étape Cloud Storage externe qui fait référence à l'intégration que vous avez créée précédemment.
create or replace stage STAGE_NAME url='UNLOAD_BUCKET' storage_integration = INTEGRATION_NAME file_format = NAMED_FILE_FORMAT;
Remplacez les éléments suivants :
STAGE_NAME: nom de l'objet Cloud Storage intermédiaire. Par exemple,my_ext_unload_stage.
Amazon S3
L'exemple suivant montre comment déplacer des données d'une table Snowflake vers un bucket Amazon S3 :
Dans Snowflake, configurez un objet d'intégration de stockage pour permettre à Snowflake d'écrire dans un bucket Amazon S3 référencé lors d'une étape Cloud Storage externe.
Cette étape implique de configurer les autorisations d'accès au bucket Amazon S3, créer le rôle IAM Amazon Web Services (AWS) et créer une intégration de stockage dans Snowflake avec la commande
CREATE STORAGE INTEGRATION:create storage integration INTEGRATION_NAME type = external_stage storage_provider = s3 enabled = true storage_aws_role_arn = 'arn:aws:iam::001234567890:role/myrole' storage_allowed_locations = ('BUCKET_NAME')
Remplacez les éléments suivants :
INTEGRATION_NAME: nom de l'intégration de stockage. Par exemple,s3_int.BUCKET_NAME: chemin d'accès au bucket Amazon S3 dans lequel charger les fichiers. Par exemple,s3://unload/files/.
Récupérez l'utilisateur AWS IAM à l'aide de la commande
DESCRIBE INTEGRATION.desc integration INTEGRATION_NAME;
Le résultat ressemble à ce qui suit :
+---------------------------+---------------+================================================================================+------------------+ | property | property_type | property_value | property_default | +---------------------------+---------------+================================================================================+------------------| | ENABLED | Boolean | true | false | | STORAGE_ALLOWED_LOCATIONS | List | s3://mybucket1/mypath1/,s3://mybucket2/mypath2/ | [] | | STORAGE_BLOCKED_LOCATIONS | List | s3://mybucket1/mypath1/sensitivedata/,s3://mybucket2/mypath2/sensitivedata/ | [] | | STORAGE_AWS_IAM_USER_ARN | String | arn:aws:iam::123456789001:user/abc1-b-self1234 | | | STORAGE_AWS_ROLE_ARN | String | arn:aws:iam::001234567890:role/myrole | | | STORAGE_AWS_EXTERNAL_ID | String | MYACCOUNT_SFCRole=
| | +---------------------------+---------------+================================================================================+------------------+ Créez un rôle disposant du droit
CREATE STAGEpour le schéma et du droitUSAGEpour l'intégration Storage :CREATE role ROLE_NAME; GRANT CREATE STAGE ON SCHEMA public TO ROLE ROLE_NAME; GRANT USAGE ON INTEGRATION s3_int TO ROLE ROLE_NAME;
Remplacez
ROLE_NAMEpar le nom du rôle. Exemple :myroleAccordez à l'utilisateur IAM AWS les autorisations pour accéder au bucket Amazon S3 et créez une étape externe à l'aide de la commande
CREATE STAGE:USE SCHEMA mydb.public; create or replace stage STAGE_NAME url='BUCKET_NAME' storage_integration = INTEGRATION_NAMEt file_format = NAMED_FILE_FORMAT;
Remplacez les éléments suivants :
STAGE_NAME: nom de l'objet Cloud Storage intermédiaire. Par exemple,my_ext_unload_stage.
Exporter des données Snowflake
Une fois vos données préparées, vous pouvez les déplacer vers Google Cloud.
Utilisez la commande COPY INTO pour copier les données de la table de base de données Snowflake dans un bucket Cloud Storage ou Amazon S3 en spécifiant l'objet de l'étape externe, STAGE_NAME.
copy into @STAGE_NAME/d1 from TABLE_NAME;
Remplacez TABLE_NAME par le nom de la table de votre base de données Snowflake.
À la suite de cette commande, les données de la table sont copiées dans l'objet intermédiaire, qui est associé au bucket Cloud Storage ou Amazon S3. Le fichier inclut le préfixe d1.
Autres méthodes d'exportation
Pour utiliser Azure Blob Storage pour vos exportations de données, suivez les étapes décrites dans Déchargement vers Microsoft Azure. Transférez ensuite les fichiers exportés vers Cloud Storage à l'aide du service de transfert de stockage.
Tarifs
Lorsque vous planifiez votre migration Snowflake, tenez compte du coût du transfert et du stockage des données, ainsi que de l'utilisation des services dans BigQuery. Pour en savoir plus, reportez-vous à la page Tarifs.
Des frais de sortie peuvent s'appliquer pour le transfert de données hors de Snowflake ou d'AWS. Des frais supplémentaires peuvent également s'appliquer lorsque vous transférez des données entre régions ou entre différents fournisseurs de services cloud.