Von IBM Netezza migrieren
Dieses Dokument bietet eine allgemeine Anleitung für die Migration von Netezza zu BigQuery. Sie beschreibt die grundlegenden Architekturunterschiede zwischen Netezza und BigQuery und die zusätzlichen Funktionen, die BigQuery bietet. Außerdem erfahren Sie, wie Sie Ihr vorhandenes Datenmodell überdenken und wie Sie extrahieren, transformieren und laden können (ETL), um die Vorteile von BigQuery zu maximieren.
Dieses Dokument richtet sich an Unternehmensarchitekten, Datenbankadministratoren, Anwendungsentwickler und IT-Sicherheitsexperten, die von Netezza zu BigQuery migrieren und technische Herausforderungen im Migrationsprozess lösen möchten. In diesem Dokument finden Sie Details zu den folgenden Phasen des Migrationsprozesses:
- Daten exportieren
- Daten aufnehmen
- Drittanbieter-Tools nutzen
Verwenden Sie die Batch-SQL-Übersetzung, um Ihre SQL-Skripts im Bulk zu migrieren, oder die interaktive SQL-Übersetzung, um Ad-hoc-Abfragen zu übersetzen. IBM Netezza SQL/NZPLSQL wird von beiden Tools in der Vorabversion unterstützt.
Architekturvergleich
Netezza ist ein leistungsstarkes System, mit dem Sie große Datenmengen speichern und analysieren können. Ein System wie Netezza erfordert jedoch hohe Investitionen in Hardware, Wartung und Lizenzierung. Dies kann aufgrund von Herausforderungen bei der Knotenverwaltung, dem Datenvolumen pro Quelle und den Archivierungskosten schwierig zu skalieren sein. Bei Netezza werden Speicher- und Verarbeitungskapazität durch Hardware-Appliances begrenzt. Wenn die maximale Auslastung erreicht ist, ist das Erweitern der Kapazität der Anwendung schwierig und manchmal gar nicht möglich.
Mit BigQuery müssen Sie keine Infrastruktur verwalten und benötigen keinen Datenbankadministrator. BigQuery ist ein vollständig verwaltetes, serverloses Data Warehouse im Petabytebereich, das ohne Index in Sekundenbruchteilen Milliarden von Zeilen scannen kann. Da BigQuery die Infrastruktur von Google nutzt, kann jede Abfrage parallelisiert und auf Zehntausenden von Servern gleichzeitig ausgeführt werden. Die folgenden Kerntechnologien heben BigQuery ab:
- Spaltenorientierte Speicherung: Die Daten werden in Spalten statt in Zeilen gespeichert. Dadurch lassen sich ein sehr hohes Komprimierungsverhältnis und ein sehr hoher Scandurchsatz erreichen.
- Baumarchitektur: Abfragen werden weitergeleitet und die Ergebnisse werden innerhalb weniger Sekunden über Tausende von Maschinen hinweg zusammengefasst.
Netezza-Architektur
Netezza ist eine hardwarebeschleunigte Appliance, die mit einer Softwaredaten-Abstraktionsschicht ausgestattet ist. Die Datenabstraktionsebene verwaltet die Datenverteilung in der Appliance und optimiert Abfragen durch die Verteilung der Datenverarbeitung auf die zugrunde liegenden CPUs und FPGAs.
Netezza TwinFin- und Striper-Modelle haben im Juni 2019 das Ende ihres Supports erreicht.
Das folgende Diagramm zeigt die Datenabstraktionsschichten in Netezza:
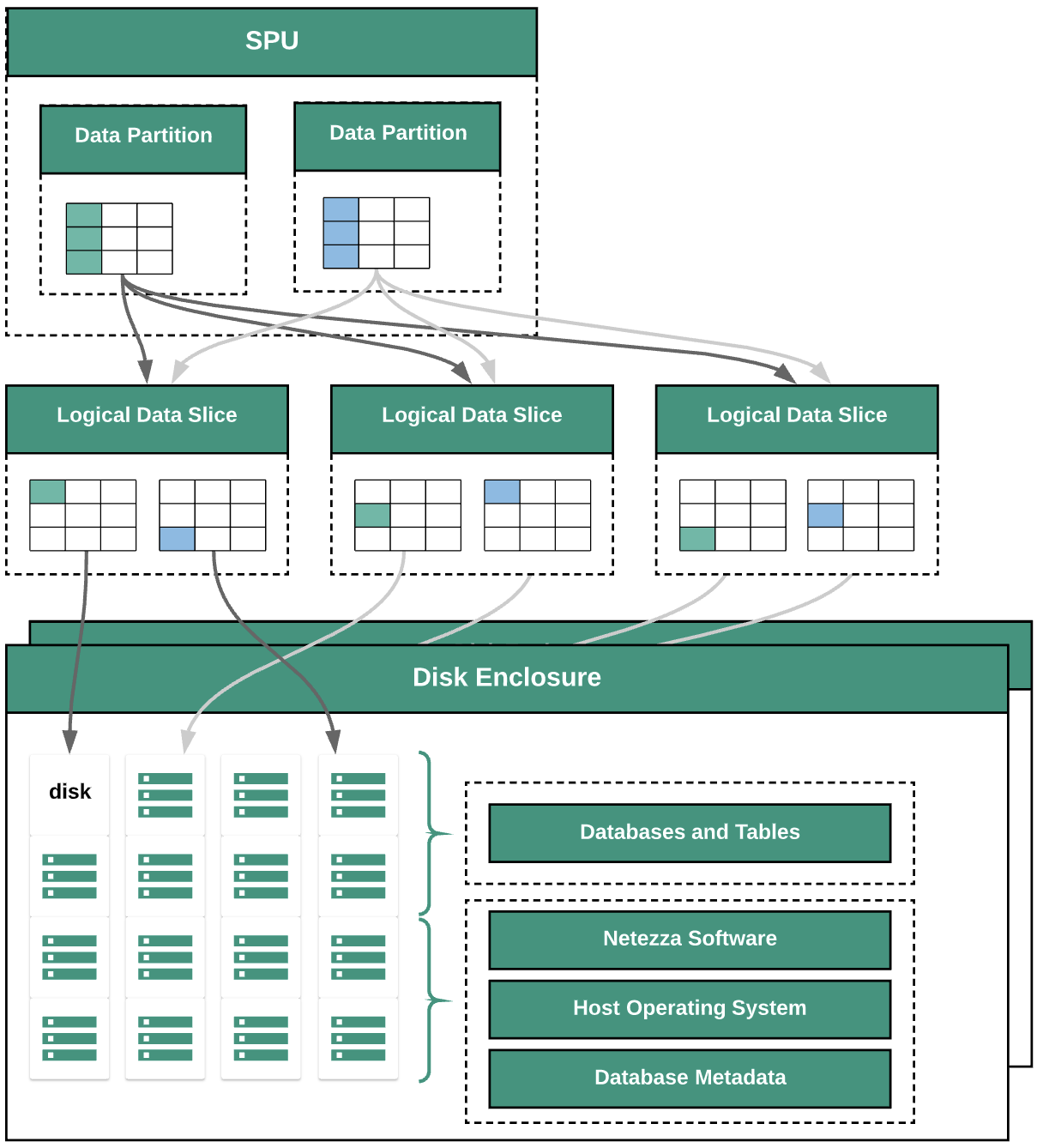
Das Diagramm zeigt die folgenden Datenabstraktionsschichten:
- Laufwerkgehäuse Der physische Bereich innerhalb der Appliance, in dem die Laufwerke befestigt sind.
- Laufwerke. Die Datenbanken und Tabellen werden auf physischen Laufwerken in den Laufwerkgehäusen gespeichert.
- Daten-Slices: Logische Darstellung der Daten, die auf einem Laufwerk gespeichert sind.
Daten werden mithilfe eines Verteilungsschlüssels auf die Daten-Slices verteilt. Sie können den Status von Daten-Slices mit
nzds-Befehlen überwachen. - Datenpartitionen Logische Darstellung eines Daten-Slices, das von einer bestimmten Snippet Processing Units (SPUs) verwaltet wird. Jede SPU besitzt eine oder mehrere Datenpartitionen mit den Nutzerdaten, für deren Verarbeitung die SPU während Abfragen verantwortlich ist.
Alle Systemkomponenten sind über das Netzwerk-Fabric verbunden. Die Netezza-Appliance verwendet ein benutzerdefiniertes Protokoll, das auf IP-Adressen basiert.
BigQuery-Architektur
BigQuery ist ein vollständig verwaltetes Data Warehouse für Unternehmen, mit dem Sie Ihre Daten mit integrierten Features wie maschinellem Lernen, raumbezogenen Analysen und Business Intelligence verwalten und analysieren können. Weitere Informationen finden Sie unter Was ist BigQuery?.
BigQuery übernimmt das Speichern und Berechnen, um eine dauerhafte Datenspeicherung und leistungsstarke Antworten auf Analyseabfragen zu ermöglichen. Weitere Informationen finden Sie unter BigQuery.
Informationen zu den Preisen von BigQuery finden Sie unter BigQuery: Schnelle Skalierung und unkomplizierte Preismodelle.
Vor der Migration
Um eine erfolgreiche Data Warehouse-Migration zu gewährleisten, sollten Sie Ihre Migrationsstrategie frühzeitig im Zeitplan Ihres Projekts planen. Weitere Informationen zur systematischen Planung Ihrer Migration finden Sie unter Was und wie migrieren: der Migrations-Framework.
BigQuery-Kapazitätsplanung
Der Analysedurchsatz in BigQuery wird in Slots gemessen. Ein BigQuery-Slot ist die proprietäre Einheit von Google für Computing, RAM und Netzwerkdurchsatz, welche zum Ausführen von SQL-Abfragen erforderlich sind. BigQuery berechnet automatisch je nach Größe und Komplexität der Abfrage, wie viele Slots für jede Abfrage erforderlich sind.
Wählen Sie eines der folgenden Preismodelle aus, um Abfragen in BigQuery auszuführen:
- On-demand. Das Standardpreismodell, bei dem Ihnen die Anzahl der Byte in Rechnung gestellt wird, die pro Abfrage verarbeitet werden.
- Kapazitätsbasierte Preise. Sie erwerben Slots, die virtuelle CPUs sind. Wenn Sie Slots erwerben, erwerben Sie dedizierte Verarbeitungskapazität, die Sie zum Ausführen von Abfragen verwenden können. Slots sind in folgenden Zusicherungsplänen verfügbar:
- Jährlich: Sie verpflichten sich zu 365 Tagen.
- Dreijährige Sie verpflichten sich zu 365*3 Tagen.
Ein BigQuery-Slot hat einige Ähnlichkeiten mit den SPUs von Netezza, darunter CPU, Arbeitsspeicher und Datenverarbeitung. Sie stellen jedoch nicht dieselbe Maßeinheit dar. Netezza-SPUs sind fest den zugrunde liegenden Hardwarekomponenten zugeordnet, während der BigQuery-Slot eine virtuelle CPU darstellt, die zum Ausführen von Abfragen verwendet wird. Um die Slot-Schätzung zu unterstützen, empfehlen wir die Einrichtung von BigQuery-Monitoring mit Cloud Monitoring und die Analyse Ihrer Audit-Logs mit BigQuery. Sie können die Auslastung von BigQuery-Slot auch mit Tools wie Looker Studio oder Looker visualisieren. Durch regelmäßiges Monitoring und Analyse der Slot-Auslastung können Sie abschätzen, wie viele Slots Ihr Unternehmen benötigt, während Sie in Google Cloud wachsen.
Beispiel: Sie reservieren zuerst 2.000 BigQuery-Slots, um 50 Abfragen mit mittlerer Komplexität gleichzeitig auszuführen. Wenn Abfragen regelmäßig länger als ein paar Stunden dauern und Ihre Dashboards eine hohe Slot-Auslastung aufweisen, sind Ihre Abfragen möglicherweise nicht optimiert oder Sie benötigen möglicherweise zusätzliche BigQuery-Slots, um Ihre Arbeitslasten zu unterstützen. Wenn Sie Slots selbst über jährliche oder dreijährige Zusicherungen erwerben möchten, können Sie BigQuery-Reservierungen erstellen. Verwenden Sie dazu die Google Cloud Console oder das bq-Befehlszeilentool. Wenn Sie eine Offline-Vereinbarung über einen Kapazität-basierten Kauf abgeschlossen haben, können deren Bestimmungen von den hier beschriebenen abweichen.
Informationen zum Kontrollieren der Speicher- und Abfrageverarbeitungskosten in BigQuery finden Sie unter Arbeitslasten optimieren.
Sicherheit in Google Cloud
In den folgenden Abschnitten werden allgemeine Sicherheitskontrollen von Netezza beschrieben und wie Sie Ihr Data Warehouse in einer Google Cloud-Umgebung schützen können.
Identitäts- und Zugriffsverwaltung
Die Netezza-Datenbank enthält eine Reihe von vollständig integrierten System-Zugriffssteuerungsfunktionen, mit denen Nutzer auf Ressourcen zugreifen können, für die sie autorisiert sind.
Der Zugriff auf Netezza wird über das Netzwerk zur Netezza-Appliance gesteuert. Dazu werden die Linux-Nutzerkonten verwaltet, die sich beim Betriebssystem anmelden können. Der Zugriff auf Datenbanken, Objekte und Aufgaben von Netezza wird über die Netezza-Datenbanknutzerkonten verwaltet, die SQL-Verbindungen zum System herstellen können.
BigQuery verwendet den Identitäts- und Zugriffsverwaltungsdienst (Identity and Access Management, IAM) von Google, um den Zugriff auf Ressourcen zu verwalten. In BigQuery stehen folgende Ressourcentypen zur Verfügung: Organisationen, Projekte, Datasets, Tabellen und Ansichten. In der Richtlinienhierarchie von IAM sind die Datasets die untergeordneten Ressourcen von Projekten. Eine Tabelle übernimmt die Berechtigungen des Datasets, das sie enthält.
Wenn Sie Zugriff auf eine Ressource erteilen möchten, müssen Sie einem Nutzer, einer Gruppe oder einem Dienstkonto eine oder mehrere Rollen zuweisen. Organisations- und Projektrollen steuern den Zugriff zum Ausführen von Jobs oder zum Verwalten des Projekts, während Dataset-Rollen den Zugriff zum Anzeigen oder Ändern der Daten in einem Projekt steuern.
IAM bietet die folgenden Rollentypen:
- Vordefinierte Rollen Sie sollen allgemeine Anwendungsfälle und Zugriffskontrollmuster unterstützen.
- Einfache Rollen Schließt die Rollen "Inhaber", "Bearbeiter" und "Betrachter" ein. Einfache Rollen, die einen detaillierten Zugriff auf einen bestimmten Dienst ermöglichen und von Google Cloud verwaltet werden.
- Benutzerdefinierte Rollen, die genau definierten Zugriff entsprechend einer vom Nutzer angegebenen Liste von Berechtigungen ermöglichen.
Wenn Sie einem Nutzer sowohl vordefinierte als auch einfache Rollen zuweisen, werden ihm die Berechtigungen beider Rollen gewährt.
Sicherheit auf Zeilenebene
Die mehrstufige Sicherheit ist ein abstraktes Sicherheitsmodell, mit dem Netezza Regeln definiert, um den Nutzerzugriff auf Zeilengesicherte Tabellen (RSTs) zu steuern. Eine zeilengesicherte Tabelle ist eine Datenbanktabelle mit Sicherheitslabels in den Zeilen, um Nutzer herauszufiltern, die nicht die entsprechenden Berechtigungen haben. Die zurückgegebenen Ergebnisse von Abfragen unterscheiden sich je nach den Berechtigungen des Nutzers, der die Abfrage ausführt.
Um die Sicherheit auf Zeilenebene in BigQuery zu erlangen, können Sie autorisierte Ansichten und Zugriffsrichtlinien auf Zeilenebene verwenden. Weitere Informationen zum Entwerfen und Implementieren dieser Richtlinien finden Sie unter Einführung in die BigQuery-Sicherheit auf Zeilenebene.
Datenverschlüsselung
Netezza-Appliances verwenden selbstverschlüsselnde Laufwerke (SEDs), um die Sicherheit und den Schutz der auf der Appliance gespeicherten Daten zu verbessern. SEDs verschlüsseln Daten, wenn sie auf das Laufwerk geschrieben werden. Jedes Laufwerk hat einen Laufwerksverschlüsselungsschlüssel (Disk Encryption Key, DEK), der in der Fabrik festgelegt wird und auf dem Laufwerk gespeichert ist. Das Laufwerk verwendet den DEK, um Daten während des Schreibens zu verschlüsseln und dann beim Entschlüsseln der Daten wenn sie vom Laufwerk gelesen werden. Der Vorgangsweise des Laufwerks sowie seine Ver- und Entschlüsselung ist für die Nutzer, die Daten lesen und schreiben, transparent. Dieser Standardmodus für Verschlüsselung und Entschlüsselung wird als sicheres Löschen-Modus bezeichnet.
Im Modus für sicheres Löschen benötigen Sie keinen Authentifizierungsschlüssel und kein Passwort, um Daten zu entschlüsseln und zu lesen. SEDs bieten verbesserte Funktionen für ein einfaches und schnelles sicheres Löschen in Situationen, in denen Laufwerke umfunktioniert oder aus Support- oder Gewährleistungsgründen zurückgegeben werden müssen.
Netezza nutzt die symmetrische Verschlüsselung. Wenn Ihre Daten auf Feldebene verschlüsselt sind, können Sie Daten mit der folgenden Entschlüsselungsfunktion lesen und exportieren:
varchar = decrypt(varchar text, varchar key [, int algorithm [, varchar IV]]); nvarchar = decrypt(nvarchar text, nvarchar key [, int algorithm[, varchar IV]]);
Alle in BigQuery gespeicherten Daten werden im inaktiven Zustand verschlüsselt. Wenn Sie die Verschlüsselung selbst steuern möchten, können Sie von Kunden verwaltete Verschlüsselungsschlüssel (Customer-Managed Encryption Keys, CMEK) für BigQuery verwenden. Statt es Google zu überlassen, können Sie auch selbst über Cloud KMS die Schlüsselverschlüsselungsschlüssel, die Ihre Daten schützen, steuern und verwalten. Weitere Informationen finden Sie unter Verschlüsselung ruhender Daten.
Leistungsbenchmarking
Damit Sie den Fortschritt und die Verbesserung während des gesamten Migrationsprozesses verfolgen können, ist es wichtig, eine Referenzleistung für den aktuelle Status der Netezza-Umgebung zu erstellen. Wählen Sie zur Erstellung der Referenzleistung eine Reihe von repräsentativen Abfragen aus, die aus den nutzenden Anwendungen wie Tableau oder Cognos erfasst werden.
| Umgebung | Netezza | BigQuery |
|---|---|---|
| Datengröße | size TB | - |
| Abfrage 1: Name (vollständiger Tabellenscan) | mm:ss.ms | - |
| Abfrage 2: name | mm:ss.ms | - |
| Abfrage 3: name | mm:ss.ms | - |
| Total (Gesamtzahl) | mm:ss.ms | - |
Grundlegende Einrichtung von Projekten
Bevor Sie Speicherressourcen für die Migration von Daten bereitstellen, müssen Sie die Projekteinrichtung beenden.
- Informationen zum Einrichten von Projekten und zum Aktivieren von IAM auf Projektebene finden Sie unter Google Cloud-Architektur-Framework.
- Informationen zum Entwerfen grundlegender Ressourcen, um Ihre Cloud-Bereitstellung für Nutzung durch Unternehmen vorzubereiten, finden Sie unter Design der Landing Zone in Google Cloud.
- Informationen zu Data Governance und den Kontrollelementen, die Sie bei der Migration Ihres lokalen Data Warehouse zu BigQuery benötigen, finden Sie unter Datensicherheit und Governance.
Netzwerkverbindung
Es ist eine zuverlässige und sichere Netzwerkverbindung zwischen dem lokalen Rechenzentrum, in dem die Netezza-Instanz ausgeführt wird, und der Google Cloud-Umgebung nötig. Informationen zum Schützen Ihrer Verbindung finden Sie unter Einführung in die Data Governance in BigQuery. Wenn Sie Datenextrakte hochladen, kann die Netzwerkbandbreite ein begrenzender Faktor sein. Informationen dazu, wie Sie die Anforderungen an die Datenübertragung erfüllen, finden Sie unter Netzwerkbandbreite erhöhen.
Unterstützte Datentypen und Properties
Netezza-Datentypen unterscheiden sich von BigQuery-Datentypen. Weitere Informationen zu BigQuery-Datentypen finden Sie unter Datentypen. Einen detaillierten Vergleich der Datentypen von Netezza und BigQuery finden Sie im IBM Netezza SQL Übersetzung-Leitfaden.
SQL-Vergleich
Netezza-Daten-SQL besteht aus DDL, DML und einer von GoogleSQL verschiedenen nur-Netezza Data Control Language (DCL). GoogleSQL ist mit dem SQL 2011-Standard kompatibel und bietet Erweiterungen, die die Abfrage verschachtelter und wiederkehrender Daten unterstützen. Wenn Sie den Legacy-SQL-Dialekt von BigQuery verwenden, finden Sie weitere Informationen unter Legacy-SQL-Funktionen und -Operatoren. Einen detaillierten Vergleich von SQL und Funktionen von Netezza und BigQuery finden Sie im IBM Netezza SQL-Übersetzungsleitfaden.
Um die Migration Ihres SQL-Codes zu vereinfachen, verwenden Sie die Batch-SQL-Übersetzung, um Ihren SQL-Code im Bulk zu migrieren, oder die interaktive SQL-Übersetzung um Ad-hoc-Abfragen zu übersetzen.
Funktionsvergleich
Es ist wichtig zu verstehen, wie Netezza-Funktionen in BigQuery-Funktionen abgebildet werden. Die Netezza-Funktion Months_Between gibt beispielsweise eine Dezimalzahl aus, während die BigQuery-Funktion DateDiff eine Ganzzahl ausgibt. Daher müssen Sie eine benutzerdefinierte UDF-Funktion verwenden, um den richtigen Datentyp auszugeben. Einen detaillierten Vergleich zwischen den Funktionen von Netezza SQL und GoogleSQL finden Sie im Leitfaden zur Übersetzung von IBM Netezza SQL.
Datenmigration
Wenn Sie Daten von Netezza zu BigQuery migrieren möchten, exportieren Sie Daten aus Netezza, übertragen sie nach Google Cloud und stellen sie in Google Cloud bereit und laden sie dann in BigQuery. Dieser Abschnitt bietet einen allgemeinen Überblick über den Datenmigrationsprozess. Eine detaillierte Beschreibung des Datenmigrationsprozesses finden Sie unter Schema- und Datenmigrationsprozess. Einen detaillierten Vergleich der Datentypen unterstützt von Netezza und BigQuery finden Sie im IBM Netezza SQL Übersetzung-Leitfaden.
Daten aus Netezza exportieren
Zum Untersuchen von Daten aus Netezza-Datenbanktabellen empfehlen wir, dass Sie sie in eine externe Tabelle im CSV-Format exportieren. Weitere Informationen finden Sie unter Daten in ein Remote-Clientsystem auslagern. Sie können Daten auch mit Drittanbietersystemen wie Informatica (oder benutzerdefiniertem ETL) mit JDBC/ODBC-Connectors lesen, um CSV-Dateien zu erstellen.
Netezza unterstützt nur den Export von unkomprimierten FlatFiles (CSV) für jede Tabelle.
Wenn Sie jedoch große Tabellen exportieren, kann die unkomprimierte CSV-Datei sehr groß werden. Konvertieren Sie die CSV nach Möglichkeit in ein schemabewusstes Format wie Parquet, Avro oder ORC. So erhalten Sie kleinere Exportdateien mit höherer Zuverlässigkeit. Wenn CSV das einzige verfügbare Format ist, empfehlen wir, die Exportdateien zu komprimieren, um die Dateigröße zu verringern, bevor Sie sie in Google Cloud hochladen.
Wenn Sie die Dateigröße verringern, wird der Upload beschleunigt und die Zuverlässigkeit der Übertragung erhöht. Wenn Sie Dateien in Cloud Storage übertragen, können Sie das Flag --gzip-local in einem gcloud storage cp-Befehl verwenden, um die Dateien vor dem Hochladen zu komprimieren.
Datenübertragung und -Staging
Nach dem Export müssen die Daten in Google Cloud übertragen und bereitgestellt werden. Je nach der übertragenen Datenmenge und der verfügbaren Netzwerkbandbreite stehen mehrere Optionen für die Datenübertragung zur Verfügung. Weitere Informationen finden Sie unter Schema und Datenübertragung.
Mit der Google Cloud CLI können Sie die Übertragung von Dateien in Cloud Storage automatisieren und parallelisieren. Beschränken Sie die Dateigrößen auf 4 TB (unkomprimiert), um ein schnelleres Laden in BigQuery zu ermöglichen. Sie müssen jedoch das Schema vorher exportieren. Das ist eine gute Gelegenheit, BigQuery mithilfe von Partitionierung und Clustering zu optimieren.
Verwenden Sie gcloud storage bucket create, um die Staging-Buckets zum Speichern der exportierten Daten zu erstellen, und gcloud storage cp, um die Datenexport-Dateien in Cloud Storage-Buckets zu übertragen.
Die gcloud CLI führt den Kopiervorgang automatisch mit einer Kombination aus Multithreading und Multiprocessing aus.
Daten in BigQuery laden
Nach der Bereitstellung von Daten in Google Cloud haben Sie mehrere Möglichkeiten, sie in BigQuery zu laden. Weitere Informationen finden Sie unter Schema und Daten in BigQuery laden.
Partnertools und -support
Sie können erhalten Partnersupport während des Migrationsvorgangs. Um die Migration Ihres SQL-Codes zu vereinfachen, verwenden Sie die Batch-SQL-Übersetzung, um Ihren SQL-Code im Bulk zu migrieren.
Viele Google Cloud-Partner bieten auch Data Warehouse-Migrationsdienste an. Eine Liste der Partner und ihrer Lösungen finden Sie unter Mit einem Experten für BigQuery zusammenarbeiten.
Nach der Migration
Nach Abschluss der Datenmigration können Sie die Nutzung von Google Cloud optimieren, um Geschäftsanforderungen zu erfüllen. Dazu gehören möglicherweise die Verwendung der Explorations- und Visualisierungstools von Google Cloud, um Erkenntnisse für Stakeholder des Unternehmens abzuleiten, Abfragen mit unzureichender Leistung zu optimieren oder ein Programm zu entwickeln, das die Akzeptanz durch die Nutzer unterstützt.
Über das Internet eine Verbindung zu BigQuery APIs herstellen
Das folgende Diagramm zeigt, wie eine externe Anwendung über die API eine Verbindung zu BigQuery herstellen kann:
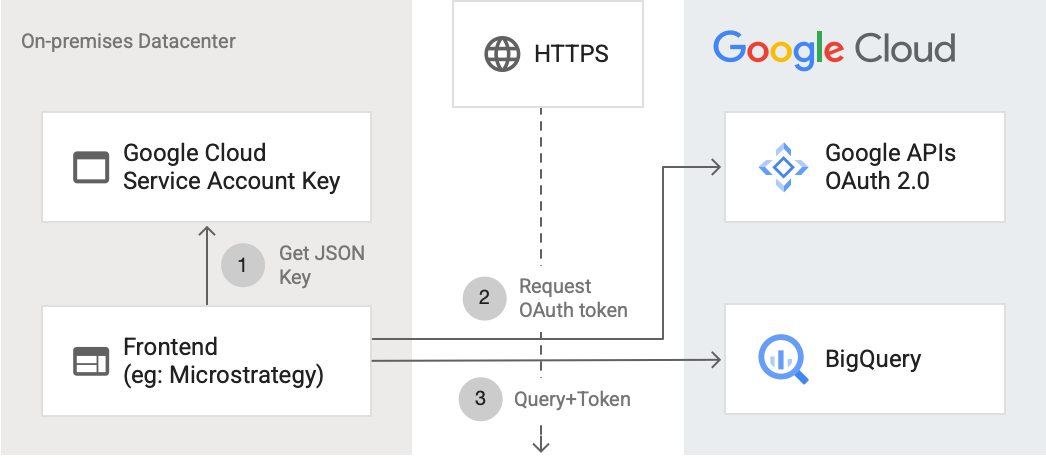
Das Diagramm zeigt die folgenden Schritte:
- In Google Cloud wird ein Dienstkonto mit IAM-Berechtigungen erstellt. Der Dienstkontoschlüssel wird im JSON-Format generiert und auf den Frontend-Server kopiert (z. B. MicroStrategy).
- Das Frontend liest den Schlüssel und fordert über HTTPS ein OAuth-Token von den Google APIs an.
- Das Frontend sendet dann BigQuery-Anfragen zusammen mit dem Token an BigQuery.
Weitere Informationen finden Sie unter API-Anfragen autorisieren.
Für BigQuery optimieren
GoogleSQL ist mit dem SQL 2011-Standard kompatibel und bietet Erweiterungen, die die Abfrage verschachtelter und wiederholter Daten unterstützen. Die Optimierung von Abfragen für BigQuery ist entscheidend für die Verbesserung von Leistung und Antwortzeit.
Funktion "Months_Between" in BigQuery durch UDF ersetzen
Netezza behandelt die Tage in einem Monat als immer 31. Die folgende benutzerdefinierte UDF erstellt die Netezza-Funktion mit hoher Genauigkeit neu. Sie können diese dann über Ihre Abfragen aufrufen:
CREATE TEMP FUNCTION months_between(date_1 DATE, date_2 DATE) AS ( CASE WHEN date_1 = date_2 THEN 0 WHEN EXTRACT(DAY FROM DATE_ADD(date_1, INTERVAL 1 DAY)) = 1 AND EXTRACT(DAY FROM DATE_ADD(date_2, INTERVAL 1 DAY)) = 1 THEN date_diff(date_1,date_2, MONTH) WHEN EXTRACT(DAY FROM date_1) = 1 AND EXTRACT(DAY FROM DATE_ADD(date_2, INTERVAL 1 DAY)) = 1 THEN date_diff(DATE_ADD(date_1, INTERVAL -1 DAY), date_2, MONTH) + 1/31 ELSE date_diff(date_1, date_2, MONTH) - 1 + ((EXTRACT(DAY FROM date_1) + (31 - EXTRACT(DAY FROM date_2))) / 31) END );
In Netezza Gespeicherte Verfahren migrieren
Wenn Sie in Netezza gespeicherte Verfahren in ETL-Arbeitslasten zum Erstellen von Faktentabellen verwenden, müssen Sie diese gespeicherten Prozeduren in BigQuery-kompatible SQL-Abfragen migrieren. Netezza verwendet die Skriptsprache NZPLSQL, um mit gespeicherten Prozeduren zu arbeiten. NZPLSQL basiert auf der Postgres PL/pgSQL-Sprache. Weitere Informationen finden Sie im Leitfaden zur Übersetzung von IBM Netezza SQL.
Benutzerdefinierte UDF zum Simulieren von Netezza-ASCII
Mit der folgenden benutzerdefinierten UDF für BigQuery werden Codierungsfehler in Spalten korrigiert:
CREATE TEMP FUNCTION ascii(X STRING) AS (TO_CODE_POINTS(x)[ OFFSET (0)]);
Nächste Schritte
- Erfahren Sie, wie Sie Arbeitslasten optimieren, um die Gesamtleistung zu optimieren und Kosten zu reduzieren.
- Erfahren Sie, wie Sie Speicher in BigQuery optimieren.
- Lesen Sie den Leitfaden zur Übersetzung von IBM Netezza SQL.