Google Cloud コンソールを使用してモデルのパフォーマンスを確認します。テストエラーを分析し、データの問題を修正してモデルの品質を繰り返し改善します。
このチュートリアルには複数のページが含まれます。
モデルのパフォーマンスを評価して分析します。
各ページは、前のページのチュートリアルの手順をすでに実施していることを前提としています。
1. AutoML モデルの評価結果を理解する
トレーニングが完了すると、テストデータの分割に対してモデルが自動的に評価されます。[モデル レジストリ] ページまたは [データセット] ページでモデルの名前をクリックすると、対応する評価結果が表示されます。
ここで、モデルのパフォーマンスを測定するための指標を見つけることができます。
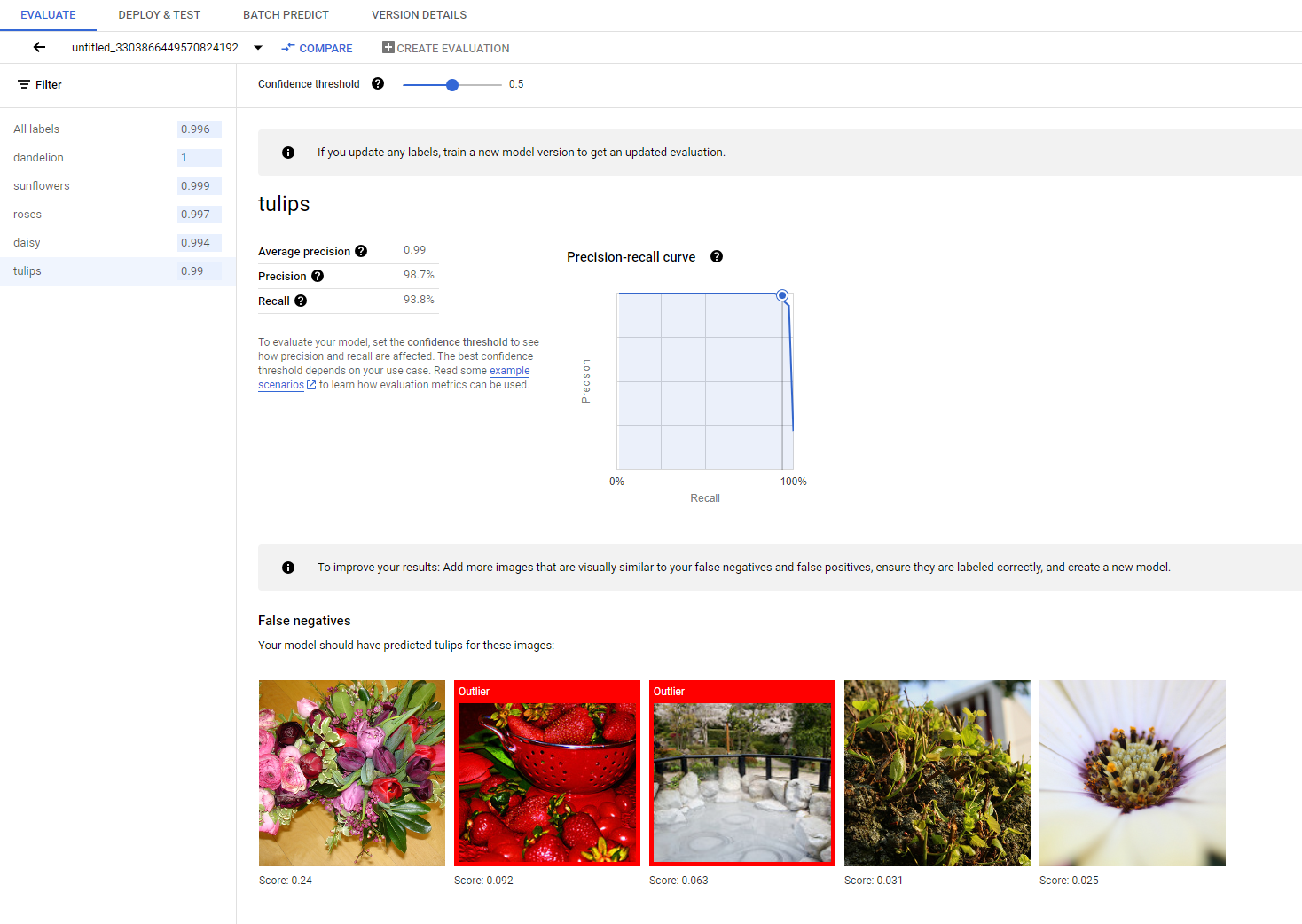
さまざまな評価指標の詳細については、モデルの評価、テスト、デプロイのセクションをご覧ください。
2. テスト結果を分析する
モデルのパフォーマンスを継続的に向上させる場合、最初のステップは多くの場合、エラーケースを調査し、考えられる原因を調査する作業になります。各クラスの評価ページには、偽陰性、偽陽性、真陽性に分類された特定のクラスの詳細なテスト画像が表示されます。各カテゴリの定義については、モデルの評価、テスト、デプロイのセクションをご覧ください。
各カテゴリの画像について、画像をクリックして詳細な分析結果にアクセスすることで、予測の詳細を確認できます。ページの右側には [類似画像の確認] パネルが表示されます。このパネルには、トレーニング セット内の最も類似するサンプルが、特徴量空間で測定された距離とともに表示されます。
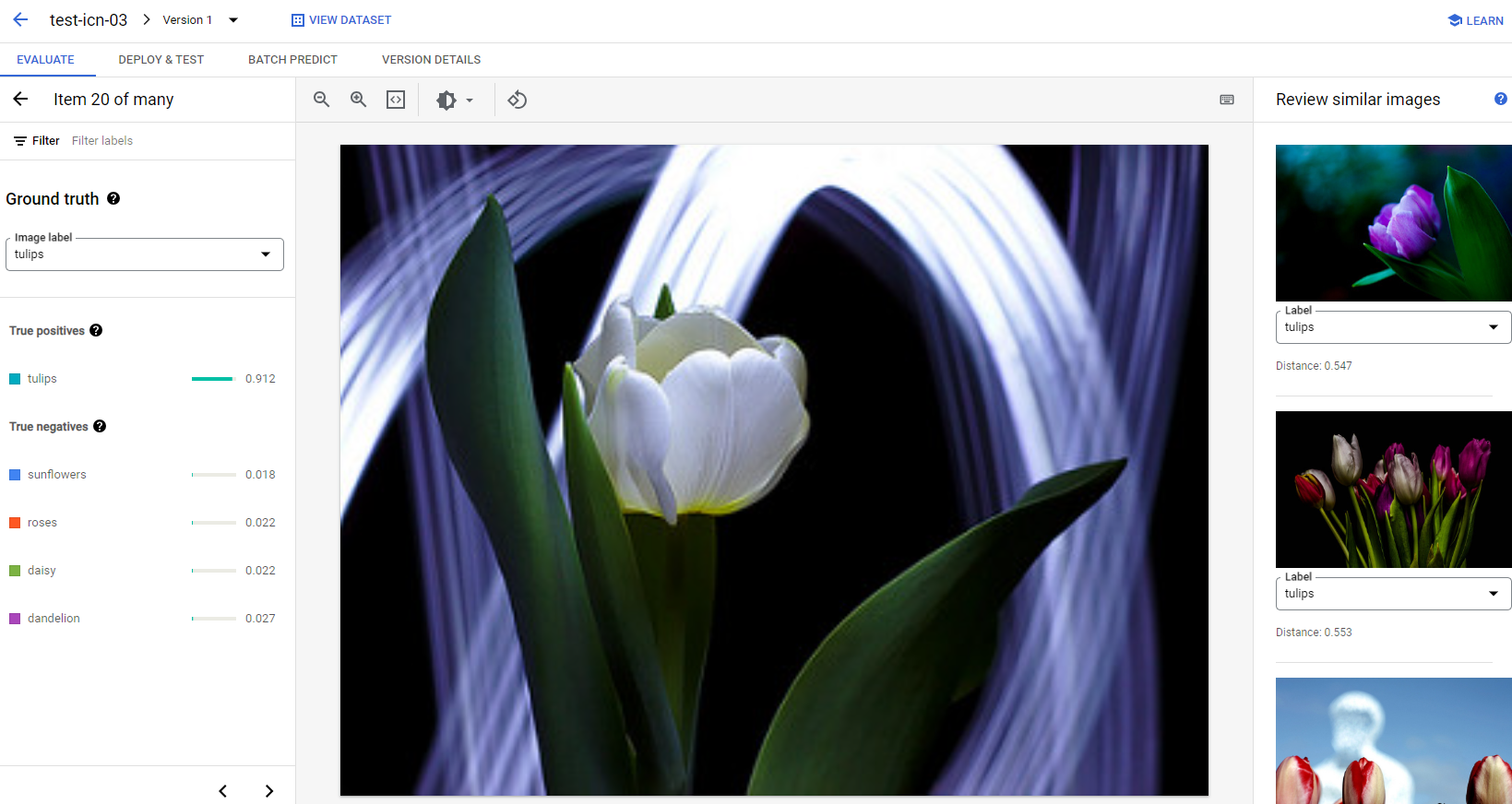
注意すべきデータの問題は、次の 2 種類に分けられます。
ラベルの不整合。トレーニング セット内の視覚的に類似したサンプルがテストサンプルと異なるラベルを持つ場合、ラベルのいずれかが正しくないか、微妙な違いが原因でモデルが学習するためのデータがさらに必要か、現在のクラスラベルの精度が、与えられたサンプルを表現するのに十分でない可能性があります。類似画像を確認し、エラーケースを修正するか、問題のあるサンプルをテストセットから除外することで、ラベル情報の精度を高めることができます。テスト画像またはトレーニング画像のラベルは、同じページの [類似画像の確認] パネルで簡単に変更できます。
外れ値。テストサンプルが外れ値としてマークされている場合、モデルのトレーニングに役立つ視覚的に類似したサンプルがトレーニング セットに存在しない可能性があります。トレーニング セット内の類似画像を確認することで、そのようなサンプルを特定し、類似の画像をトレーニング セットに追加して、このようなケースのモデルのパフォーマンスをさらに改善できます。
次のステップ
モデルのパフォーマンスが満足できるものである場合は、このチュートリアルの次のページの説明に沿って、トレーニングした AutoML モデルをエンドポイントにデプロイし、予測用の画像をモデルに送信します。パフォーマンスに満足できず、データを修正する場合は、AutoML 画像分類モデルのトレーニングのチュートリアルを使用して、新しいモデルをトレーニングします。