Vertex AI ofrece un servicio de entrenamiento gestionado que te ayuda a poner en marcha el entrenamiento de modelos a gran escala. Puedes usar Vertex AI para ejecutar aplicaciones de entrenamiento basadas en cualquier framework de aprendizaje automático (ML) en la infraestructura deGoogle Cloud . Vertex AI también ofrece compatibilidad integrada con los siguientes frameworks de aprendizaje automático populares, lo que simplifica el proceso de preparación para el entrenamiento y el servicio de modelos:
En esta página se explican las ventajas del entrenamiento personalizado en Vertex AI, el flujo de trabajo que implica y las diferentes opciones de entrenamiento disponibles.
Vertex AI pone en práctica el entrenamiento a gran escala
Hay varios retos a la hora de poner en práctica el entrenamiento de modelos. Entre estos desafíos se incluyen el tiempo y el coste necesarios para entrenar modelos, la profundidad de las habilidades necesarias para gestionar la infraestructura de computación y la necesidad de proporcionar seguridad de nivel empresarial. Vertex AI aborda estos retos y ofrece otras ventajas.
Infraestructura de computación totalmente gestionada
|
|
El entrenamiento de modelos en Vertex AI es un servicio totalmente gestionado que no requiere la administración de ninguna infraestructura física. Puedes entrenar modelos de aprendizaje automático sin necesidad de aprovisionar ni gestionar servidores. Solo pagas por los recursos de computación que consumes. Vertex AI también gestiona el registro, la puesta en cola y la monitorización de las tareas. |
Alto rendimiento
|
|
Los trabajos de entrenamiento de Vertex AI están optimizados para el entrenamiento de modelos de aprendizaje automático, lo que puede proporcionar un rendimiento más rápido que ejecutar directamente tu aplicación de entrenamiento en un clúster de Google Kubernetes Engine (GKE). También puedes identificar y depurar los cuellos de botella del rendimiento de tu tarea de entrenamiento con Cloud Profiler. |
Preparación distribuida
|
|
Reduction Server es un algoritmo de reducción total de Vertex AI que puede aumentar el rendimiento y reducir la latencia del entrenamiento distribuido de varios nodos en unidades de procesamiento gráfico (GPUs) de NVIDIA. Esta optimización ayuda a reducir el tiempo y el coste de completar grandes trabajos de entrenamiento. |
Optimización de hiperparámetros
|
|
Las tareas de ajuste de hiperparámetros ejecutan varias pruebas de tu aplicación de entrenamiento con diferentes valores de hiperparámetros. Especificas un intervalo de valores para probar y Vertex AI descubre los valores óptimos para tu modelo dentro de ese intervalo. |
Seguridad empresarial
|
|
Vertex AI ofrece las siguientes funciones de seguridad empresarial:
|
Integraciones de operaciones de aprendizaje automático (MLOps)
|
|
Vertex AI ofrece un conjunto de herramientas y funciones de MLOps integradas que puedes usar para lo siguiente:
|
Flujo de trabajo para el entrenamiento personalizado
En el siguiente diagrama se muestra una descripción general del flujo de trabajo de entrenamiento personalizado en Vertex AI. En las siguientes secciones se describe cada paso en detalle.
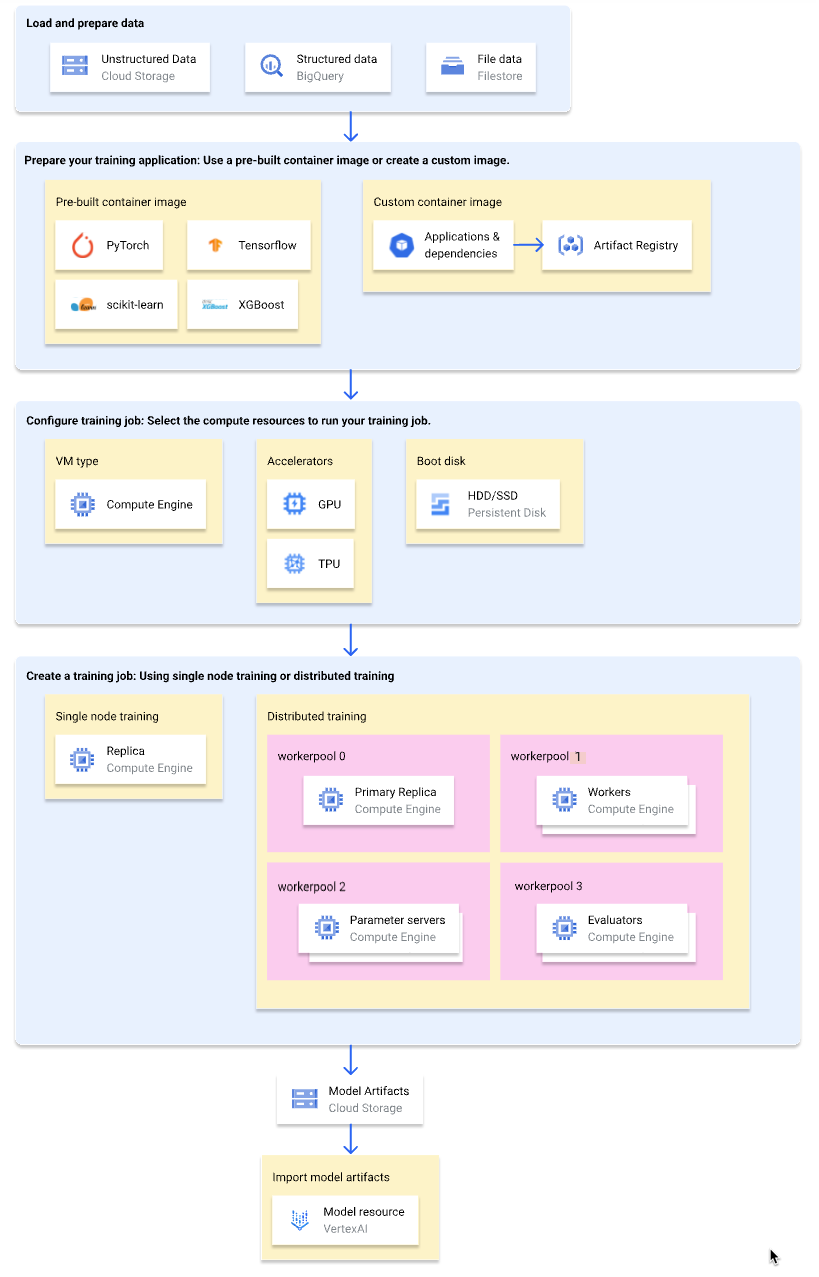
Cargar y preparar los datos de entrenamiento
Para obtener el mejor rendimiento y asistencia, utiliza uno de los siguientes Google Cloud servicios como fuente de datos:
Para ver una comparación de estos servicios, consulta el artículo Descripción general de la preparación de datos.
También puede especificar un conjunto de datos gestionado de Vertex AI como fuente de datos al usar una canalización de entrenamiento para entrenar su modelo. Entrenar un modelo personalizado y un modelo de AutoML con el mismo conjunto de datos te permite comparar el rendimiento de ambos modelos.
Prepara tu solicitud de formación
Para preparar tu aplicación de entrenamiento para usarla en Vertex AI, haz lo siguiente:
- Implementa las prácticas recomendadas de código de entrenamiento para Vertex AI.
- Determina el tipo de imagen de contenedor que vas a usar.
- Empaqueta tu aplicación de entrenamiento en un formato compatible en función del tipo de imagen de contenedor seleccionado.
Implementar las prácticas recomendadas del código de entrenamiento
Tu aplicación de entrenamiento debe implementar las prácticas recomendadas de código de entrenamiento de Vertex AI. Estas prácticas recomendadas se refieren a la capacidad de tu aplicación de entrenamiento para hacer lo siguiente:
- Acceder a los servicios de Google Cloud .
- Carga los datos de entrada.
- Habilita el registro automático para el seguimiento de experimentos.
- Permiso para exportar artefactos de modelos.
- Usa las variables de entorno de Vertex AI.
- Asegura la resiliencia ante reinicios de máquinas virtuales.
Seleccione un tipo de contenedor
Vertex AI ejecuta tu aplicación de entrenamiento en una imagen de contenedor de Docker. Una imagen de contenedor Docker es un paquete de software independiente que incluye código y todas las dependencias, y que se puede ejecutar en casi cualquier entorno informático. Puedes especificar el URI de una imagen de contenedor predefinida que quieras usar o crear y subir una imagen de contenedor personalizada que tenga preinstalada tu aplicación de entrenamiento y sus dependencias.
En la siguiente tabla se muestran las diferencias entre las imágenes de contenedor prediseñadas y las personalizadas:
| Especificaciones | Imágenes de contenedor prediseñadas | Imágenes de contenedor personalizadas |
|---|---|---|
| Framework de aprendizaje automático | Cada imagen de contenedor es específica de un framework de aprendizaje automático. | Puedes usar cualquier framework de aprendizaje automático o no usar ninguno. |
| Versión del framework de aprendizaje automático | Cada imagen de contenedor es específica de una versión de framework de aprendizaje automático. | Usa cualquier versión del framework de aprendizaje automático, incluidas las versiones secundarias y las compilaciones nocturnas. |
| Dependencias de la aplicación | Las dependencias habituales del framework de aprendizaje automático están preinstaladas. Puedes especificar dependencias adicionales para instalar en tu aplicación de entrenamiento. | Preinstala las dependencias que necesite tu aplicación de entrenamiento. |
| Formato de entrega de la aplicación |
|
Preinstala la aplicación de entrenamiento en la imagen de contenedor personalizada. |
| Dificultad de configuración | Bajo | Alta |
| Recomendado para | Aplicaciones de entrenamiento de Python basadas en un framework de aprendizaje automático y una versión del framework que tenga una imagen de contenedor prediseñada disponible. |
|
Empaqueta tu aplicación de entrenamiento
Una vez que hayas determinado el tipo de imagen de contenedor que vas a usar, empaqueta tu aplicación de entrenamiento en uno de los siguientes formatos en función del tipo de imagen de contenedor:
Archivo de Python único para usar en un contenedor prediseñado
Escribe tu aplicación de entrenamiento como un único archivo de Python y usa el SDK de Vertex AI para Python para crear una clase
CustomJoboCustomTrainingJob. El archivo de Python se empaqueta en una distribución de origen de Python y se instala en una imagen de contenedor prediseñada. Enviar tu aplicación de entrenamiento como un único archivo de Python es adecuado para crear prototipos. En el caso de las aplicaciones de entrenamiento de producción, es probable que la aplicación de entrenamiento esté organizada en más de un archivo.Distribución de la fuente de Python para usarla en un contenedor prediseñado
Empaqueta tu aplicación de entrenamiento en una o varias distribuciones de origen de Python y súbelas a un segmento de Cloud Storage. Vertex AI instala las distribuciones de origen en una imagen de contenedor prediseñada cuando creas una tarea de entrenamiento.
Imagen de contenedor personalizada
Crea tu propia imagen de contenedor Docker con tu aplicación de entrenamiento y las dependencias preinstaladas, y súbela a Artifact Registry. Si tu aplicación de entrenamiento está escrita en Python, puedes seguir estos pasos con un solo comando de la CLI de Google Cloud.
Configurar una tarea de entrenamiento
Una tarea de entrenamiento de Vertex AI realiza las siguientes acciones:
- Proporciona una (entrenamiento de un solo nodo) o varias (entrenamiento distribuido) máquinas virtuales.
- Ejecuta tu aplicación de entrenamiento en contenedores en las VMs aprovisionadas.
- Elimina las VMs una vez que se completa el trabajo de entrenamiento.
Vertex AI ofrece tres tipos de trabajos de entrenamiento para ejecutar tu aplicación de entrenamiento:
-
Una tarea personalizada (
CustomJob) ejecuta tu aplicación de entrenamiento. Si usas una imagen de contenedor prediseñada, los artefactos del modelo se enviarán al segmento de Cloud Storage especificado. En el caso de las imágenes de contenedor personalizadas, tu aplicación de entrenamiento también puede generar artefactos de modelo en otras ubicaciones. Tarea de ajuste de hiperparámetros
Una tarea de ajuste de hiperparámetros (
HyperparameterTuningJob) ejecuta varias pruebas de tu aplicación de entrenamiento con diferentes valores de hiperparámetros hasta que genera artefactos de modelo con los valores de hiperparámetros de mejor rendimiento. Especifica el intervalo de valores de hiperparámetros que quieres probar y las métricas que quieres optimizar.Flujo de procesamiento de entrenamiento
Una canalización de entrenamiento (
CustomTrainingJob) ejecuta una tarea personalizada o una tarea de ajuste de hiperparámetros y, opcionalmente, exporta los artefactos del modelo a Vertex AI para crear un recurso de modelo. Puedes especificar un conjunto de datos gestionado de Vertex AI como fuente de datos.
Cuando crees una tarea de entrenamiento, especifica los recursos de computación que se van a usar para ejecutar tu aplicación de entrenamiento y configura los ajustes del contenedor.
Configuraciones de procesamiento
Especifica los recursos de computación que se van a usar en una tarea de entrenamiento. Vertex AI admite el entrenamiento de un solo nodo, en el que la tarea de entrenamiento se ejecuta en una VM, y el entrenamiento distribuido, en el que la tarea de entrenamiento se ejecuta en varias VMs.
Los recursos de computación que puedes especificar para tu tarea de entrenamiento son los siguientes:
Tipo de máquina virtual
Los distintos tipos de máquinas ofrecen diferentes CPUs, tamaños de memoria y anchos de banda.
Unidades de procesamiento gráfico (GPUs)
Puedes añadir una o varias GPUs a las VMs de tipo A2 o N1. Si tu aplicación de entrenamiento está diseñada para usar GPUs, añadir GPUs puede mejorar significativamente el rendimiento.
Unidades de procesamiento de tensor (TPUs)
Las TPU se han diseñado específicamente para acelerar las cargas de trabajo de aprendizaje automático. Cuando se usa una VM de TPU para el entrenamiento, solo se puede especificar un grupo de trabajadores. Ese grupo de trabajadores solo puede tener una réplica.
Discos de arranque
Puedes usar unidades SSD (opción predeterminada) o HDD para tu disco de arranque. Si tu aplicación de entrenamiento lee y escribe en el disco, usar SSDs puede mejorar el rendimiento. También puedes especificar el tamaño del disco de arranque en función de la cantidad de datos temporales que tu aplicación de entrenamiento escriba en el disco. Los discos de arranque pueden tener entre 100 GiB (valor predeterminado) y 64.000 GiB. Todas las VMs de un grupo de trabajadores deben usar el mismo tipo y tamaño de disco de arranque.
Configuraciones de contenedores
Las configuraciones de contenedor que debes hacer dependen de si usas una imagen de contenedor prediseñada o personalizada.
Configuraciones de contenedores precompilados:
- Especifica el URI de la imagen de contenedor prediseñada que quieras usar.
- Si tu aplicación de entrenamiento se empaqueta como una distribución de origen de Python, especifica el URI de Cloud Storage donde se encuentra el paquete.
- Especifica el módulo del punto de entrada de tu aplicación de entrenamiento.
- Opcional: Especifica una lista de argumentos de línea de comandos que se pasarán al módulo del punto de entrada de tu aplicación de entrenamiento.
Configuraciones de contenedores personalizadas:
- Especifica el URI de tu imagen de contenedor personalizada, que puede ser un URI de Artifact Registry o Docker Hub.
- Opcional: Anula las instrucciones
ENTRYPOINToCMDde tu imagen de contenedor.
Crear una tarea de entrenamiento
Una vez que haya preparado los datos y la aplicación de entrenamiento, ejecute la aplicación de entrenamiento creando uno de los siguientes trabajos de entrenamiento:
- Crea una tarea personalizada.
- Crea una tarea de ajuste de hiperparámetros.
- Crea un flujo de procesamiento de entrenamiento.
Para crear la tarea de entrenamiento, puedes usar la Google Cloud consola, la CLI de Google Cloud, el SDK de Vertex AI para Python o la API de Vertex AI.
Opcional: Importar artefactos de modelos a Vertex AI
Es probable que tu aplicación de entrenamiento genere uno o varios artefactos de modelo en una ubicación especificada, normalmente un segmento de Cloud Storage. Para obtener inferencias en Vertex AI a partir de los artefactos de tu modelo, primero debes importar los artefactos del modelo al registro de modelos de Vertex AI.
Al igual que con las imágenes de contenedor para el entrenamiento, Vertex AI te permite elegir entre imágenes de contenedor prediseñadas o personalizadas para las inferencias. Si hay disponible una imagen de contenedor prediseñada para las inferencias de tu framework de aprendizaje automático y de la versión del framework, te recomendamos que la uses.
Siguientes pasos
- Obtener inferencias de tu modelo.
- Evalúa tu modelo.
- Prueba el tutorial Entrenamiento personalizado de tipo "Hello" para obtener instrucciones paso a paso sobre cómo entrenar un modelo de clasificación de imágenes de TensorFlow Keras en Vertex AI.