En esta sección se describen los servicios de Vertex AI que te ayudan a implementar operaciones de aprendizaje automático (MLOps) en tu flujo de trabajo de aprendizaje automático (ML).
Una vez que se hayan desplegado los modelos, deben adaptarse a los cambios en los datos del entorno para funcionar de forma óptima y seguir siendo relevantes. MLOps es un conjunto de prácticas que mejora la estabilidad y la fiabilidad de tus sistemas de aprendizaje automático.
Las herramientas de MLOps de Vertex AI te ayudan a colaborar con los equipos de IA y a mejorar tus modelos mediante la monitorización, las alertas, el diagnóstico y las explicaciones prácticas de los modelos predictivos. Todas las herramientas son modulares, por lo que puedes integrarlas en tus sistemas actuales según sea necesario.
Para obtener más información sobre las operaciones de aprendizaje automático, consulta Entrega continua y automatización de flujos de trabajo en el aprendizaje automático y la guía para profesionales sobre las operaciones de aprendizaje automático.
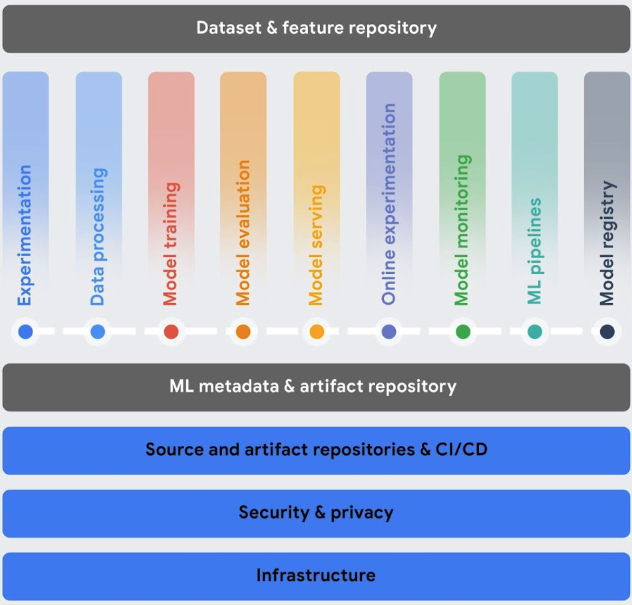
Orquestar flujos de trabajo: entrenar y servir tus modelos manualmente puede llevar mucho tiempo y dar lugar a errores, sobre todo si tienes que repetir los procesos muchas veces.
- Vertex AI Pipelines te ayuda a automatizar, monitorizar y gobernar tus flujos de trabajo de aprendizaje automático.
Hacer un seguimiento de los metadatos usados en tu sistema de aprendizaje automático: en la ciencia de datos, es importante hacer un seguimiento de los parámetros, los artefactos y las métricas usados en tu flujo de trabajo de aprendizaje automático, sobre todo cuando repites el flujo de trabajo varias veces.
- Vertex ML Metadata te permite registrar los metadatos, los parámetros y los artefactos que se usan en tu sistema de aprendizaje automático. Después, puedes consultar esos metadatos para analizar, depurar y auditar el rendimiento de tu sistema de aprendizaje automático o de los artefactos que produce.
Identificar el mejor modelo para un caso práctico: cuando pruebas nuevos algoritmos de entrenamiento, debes saber qué modelo entrenado ofrece el mejor rendimiento.
Vertex AI Experiments te permite monitorizar y analizar diferentes arquitecturas de modelos, hiperparámetros y entornos de entrenamiento para identificar el mejor modelo para tu caso práctico.
Vertex AI TensorBoard te ayuda a monitorizar, visualizar y comparar experimentos de aprendizaje automático para medir el rendimiento de tus modelos.
Gestionar versiones de modelos: añadir modelos a un repositorio central te ayuda a hacer un seguimiento de las versiones de los modelos.
- Vertex AI Model Registry ofrece una vista general de tus modelos para que puedas organizarlos, monitorizarlos y entrenar nuevas versiones de forma más eficaz. En Model Registry, puede evaluar modelos, desplegarlos en un endpoint, crear inferencias por lotes y ver detalles sobre modelos y versiones de modelos específicos.
Gestionar funciones: cuando reutilizas funciones de aprendizaje automático en varios equipos, necesitas una forma rápida y eficiente de compartir y suministrar las funciones.
- Vertex AI Feature Store proporciona un repositorio centralizado para organizar, almacenar y publicar características de aprendizaje automático. Usar un almacén de características centralizado permite a una organización reutilizar las características de aprendizaje automático a gran escala y aumentar la velocidad de desarrollo e implementación de nuevas aplicaciones de aprendizaje automático.
Monitorizar la calidad del modelo: un modelo implementado en producción funciona mejor con datos de entrada de inferencia similares a los datos de entrenamiento. Cuando los datos de entrada se desvían de los datos utilizados para entrenar el modelo, el rendimiento del modelo puede deteriorarse, aunque el modelo en sí no haya cambiado.
- Vertex AI Model Monitoring monitoriza los modelos para detectar el sesgo entre el entrenamiento y el servicio, así como la deriva de la inferencia, y te envía alertas cuando los datos de inferencia entrantes se desvían demasiado de la línea de base del entrenamiento. Puedes usar las alertas y las distribuciones de funciones para evaluar si necesitas volver a entrenar tu modelo.
Escalar aplicaciones de IA y Python: Ray es un framework de código abierto para escalar aplicaciones de IA y Python. Ray proporciona la infraestructura para realizar computación distribuida y procesamiento en paralelo en tu flujo de trabajo de aprendizaje automático.
- Ray en Vertex AI se ha diseñado para que puedas usar el mismo código de Ray de código abierto para escribir programas y desarrollar aplicaciones en Vertex AI con cambios mínimos. Después, puedes usar las integraciones de Vertex AI con otros Google Cloud servicios, como Vertex AI Inference y BigQuery, como parte de tu flujo de trabajo de aprendizaje automático (ML).