Auf dieser Seite erfahren Sie, wie Sie eine Prognose mit Ihrem trainierten Prognosemodell erstellen.
Um eine Prognose zu erstellen, stellen Sie eine Batchvorhersageanfrage direkt an Ihr Prognosemodell und geben eine Eingabequelle und einen Ausgabespeicherort an, um die Prognoseergebnisse zu speichern.
Prognosen mit AutoML sind nicht mit der Endpunktbereitstellung oder Onlinevorhersagen kompatibel. Wenn Sie Onlinevorhersagen mit Ihrem Prognosemodell anfordern möchten, verwenden Sie den Tabellen-Workflow für Prognosen.
Sie können eine Vorhersage mit Erläuterungen anfordern, die auch als Featureattribute bezeichnet werden, um zu sehen, wie Ihr Modell zu einer Vorhersage gelangt ist. Die Werte der lokalen Merkmalwichtigkeit geben an, wie viel jedes Feature zum Vorhersageergebnis beigetragen hat. Eine konzeptionelle Übersicht finden Sie unter Featureattributionen für Prognosen.
Vorbereitung
Bevor Sie eine Prognose erstellen können, müssen Sie ein Prognosemodell trainieren.
Eingabedaten
Die Eingabedaten für Batchvorhersageanfragen sind die Daten, die Ihr Modell zum Erstellen von Prognosen verwendet. Sie können Eingabedaten in einem von zwei Formaten bereitstellen:
- CSV-Objekte in Cloud Storage
- BigQuery-Tabellen
Wir empfehlen, dass Sie für Ihre Eingabedaten dasselbe Format verwenden, das Sie zum Trainieren des Modells verwendet haben. Wenn Sie Ihr Modell beispielsweise mit Daten in BigQuery trainiert haben, empfiehlt es sich, eine BigQuery-Tabelle als Quelle für Ihre Batchvorhersagen zu verwenden. Da Vertex AI alle CSV-Eingabefelder als Strings behandelt, kann eine Kombination der Formate von Trainings- und Eingabedaten zu Fehlern führen.
Die Datenquelle muss tabellarische Daten enthalten, die alle Spalten (in beliebiger Reihenfolge) enthalten, die zum Trainieren des Modells verwendet wurden. Sie können Spalten einfügen, die nicht in den Trainingsdaten enthalten waren, oder die in den Trainingsdaten enthalten waren, aber nicht für das Training verwendet wurden. Diese zusätzlichen Spalten sind in der Ausgabe enthalten, haben aber keinen Einfluss auf die Prognoseergebnisse.
Anforderungen an Eingabedaten
Eingaben für Prognosemodelle müssen die folgenden Anforderungen erfüllen:
- Alle Werte in der Zeitspalte müssen vorhanden und gültig sein.
- Die Datenhäufigkeit für die Eingabedaten und die Trainingsdaten müssen übereinstimmen. Wenn in der Zeitreihe Zeilen fehlen, müssen Sie diese mit dem richtigen Fachwissen manuell einfügen.
- Zeitachsen mit doppelten Zeitstempeln werden aus Vorhersagen entfernt. Entfernen Sie doppelte Zeitstempel, um sie einzubeziehen.
- Stellen Sie Verlaufsdaten für jede Zeitreihe bereit, die vorhergesagt werden kann. Um genaue Prognosen zu erhalten, sollte die Datenmenge mit dem Kontextfenster übereinstimmen, das während des Modelltrainings festgelegt wird. Wenn das Kontextfenster z. B. 14 Tage umfasst, geben Sie die Daten von mindestens 14 Tagen an. Wenn Sie weniger Daten bereitstellen, füllt Vertex AI die Daten mit leeren Werten.
- Die Prognose beginnt in der ersten Zeile einer Zeitreihe (sortiert nach Zeit) mit einem Nullwert in der Zielspalte. Der Nullwert muss innerhalb der Zeitreihe kontinuierlich sein. Wenn die Zielspalte beispielsweise nach Zeit sortiert ist, können Sie nicht
1,2,null,3,4,nullundnullfür eine einzelne Zeitreihe haben. Bei CSV-Dateien behandelt Vertex AI einen leeren String als null und bei BigQuery werden Nullwerte nativ unterstützt.
BigQuery-Tabelle
Wenn Sie eine BigQuery-Tabelle als Eingabe auswählen, müssen Sie Folgendes beachten:
- BigQuery-Datenquellentabellen dürfen nicht größer als 100 GB sein.
- Wenn sich die Tabelle in einem anderen Projekt befindet, müssen Sie dem Vertex AI-Dienstkonto in diesem Projekt die Rolle
BigQuery Data Editorzuweisen.
CSV-Datei
Wenn Sie ein CSV-Objekt in Cloud Storage als Eingabe auswählen, müssen Sie Folgendes beachten:
- Die Datenquelle muss mit einer Kopfzeile mit den Spaltennamen beginnen.
- Jede Datenquellendatei darf nicht größer als 10 GB sein. Sie können mehrere Dateien mit einer Gesamtgröße von maximal 100 GB importieren.
- Wenn sich der Cloud Storage-Bucket in einem anderen Projekt befindet, müssen Sie dem Vertex AI-Dienstkonto in diesem Projekt die Rolle
Storage Object Creatorzuweisen. - Alle Strings müssen in doppelte Anführungszeichen (") gesetzt werden.
Ausgabeformat
Das Ausgabeformat Ihrer Batchvorhersageanfrage muss nicht mit dem für die Eingabe verwendeten Format übereinstimmen. Wenn Sie beispielsweise BigQuery-Tabelle als Eingabe verwendet haben, können Sie die Prognoseergebnisse an ein CSV-Objekt in Cloud Storage ausgeben.
Batchvorhersageanfrage an das Modell stellen
Sie können die Google Cloud Console oder die Vertex AI API verwenden, um Batchvorhersageanfragen zu stellen. Die Eingabedatenquelle können CSV-Objekte sein, die in einem Cloud Storage-Bucket oder in BigQuery-Tabellen gespeichert sind. Abhängig von der Datenmenge, die Sie als Eingabe senden, kann eine Batchvorhersage einige Zeit in Anspruch nehmen.
Google Cloud Console
Verwenden Sie die Google Cloud Console, um eine Batchvorhersage anzufordern.
- Rufen Sie in der Google Cloud Console im Abschnitt "Vertex AI" die Seite Batchvorhersagen auf.
- Klicken Sie auf Erstellen, um das Fenster Neue Batchvorhersage zu öffnen.
- Führen Sie für Batchvorhersage definieren folgende Schritte aus:
- Geben Sie einen Namen für die Batchvorhersage ein.
- Wählen Sie unter Modellname den Namen des Modells aus, das für diese Batchvorhersage verwendet werden soll.
- Wählen Sie unter Version die Version des Modells aus.
- Wählen Sie unter Quelle auswählen aus, ob Ihre Quelleingabedaten eine CSV-Datei in Cloud Storage oder eine Tabelle in BigQuery sind.
- Geben Sie für CSV-Dateien den Cloud Storage-Speicherort an, in dem sich Ihre CSV-Eingabedatei befindet.
- Geben Sie für BigQuery-Tabellen die Projekt-ID an, in der sich die Tabelle befindet, die BigQuery-Dataset-ID sowie die BigQuery-Tabellen- oder -Ansichts-ID.
- Wählen Sie für die Ausgabe der Batchvorhersage CSV oder BigQuery aus.
- Geben Sie für CSV den Cloud Storage-Bucket an, in dem Vertex AI Ihre Ausgabe speichert.
- Für BigQuery können Sie eine Projekt-ID oder ein vorhandenes Dataset angeben:
- Geben Sie die Projekt-ID in das Feld Google Cloud-Projekt-ID ein. Vertex AI erstellt ein neues Ausgabe-Dataset.
- Geben Sie den vorhandenen BigQuery-Pfad in das Feld Google Cloud-Projekt-ID ein, z. B.
bq://projectid.datasetid, um ein vorhandenes Dataset anzugeben.
- Optional. Wenn Ihr Ausgabeziel BigQuery oder JSONL in Cloud Storage ist, können Sie zusätzlich zu Vorhersagen Feature-Attributionen aktivieren. Wählen Sie dazu Feature-Attributionen für dieses Modell aktivieren aus. Feature-Attributionen werden für CSV in Cloud Storage nicht unterstützt. Weitere Informationen
- Optional: Die Modellmonitoring-Analyse für Batchvorhersagen ist in der Vorschau verfügbar. Informationen für das Hinzufügen einer Konfiguration zur Abweichungserkennung zu Ihrem Batchvorhersagejob finden Sie unter Voraussetzungen.
- Klicken Sie, um die Option Model Monitoring für diese Batchvorhersage aktivieren einzuschalten.
- Wählen Sie eine Quelle der Trainingsdaten aus. Geben Sie den Datenpfad oder den Speicherort für die ausgewählte Trainingsdatenquelle ein.
- (Optional) Geben Sie unter Benachrichtigungsgrenzwert Grenzwerte an, ab denen Benachrichtigungen ausgelöst werden sollen.
- Geben Sie unter Benachrichtigungs-E-Mails eine oder mehrere durch Kommas getrennte E-Mail-Adressen ein, um Benachrichtigungen zu erhalten, wenn ein Modell einen Benachrichtigungsgrenzwert überschreitet.
- Optional: Fügen Sie unter Benachrichtigungskanäle Cloud Monitoring-Kanäle hinzu, um Benachrichtigungen zu erhalten, wenn ein Modell einen Benachrichtigungsgrenzwert überschreitet. Sie können vorhandene Cloud Monitoring-Kanäle auswählen oder neue erstellen. Klicken Sie dazu auf Benachrichtigungskanäle verwalten. Die Console unterstützt PagerDuty-, Slack- und Pub/Sub-Benachrichtigungskanäle.
- Klicken Sie auf Erstellen.
API : BigQuery
REST
Mit der Methode batchPredictionJobs.create können Sie eine Batchvorhersage anfordern.
Ersetzen Sie diese Werte in den folgenden Anfragedaten:
- LOCATION_ID: Region, in der das Modell gespeichert ist .und der Batchvorhersagejob ausgeführt wird. Beispiel:
us-central1. - PROJECT_ID: Ihre Projekt-ID
- BATCH_JOB_NAME: Anzeigename für den Batchjob
- MODEL_ID: Die ID für das Modell, das für Vorhersagen verwendet werden soll
-
INPUT_URI: Referenz zur BigQuery-Datenquelle. Füllen Sie das Formular aus:
bq://bqprojectId.bqDatasetId.bqTableId
-
OUTPUT_URI: Referenz zum BigQuery-Ziel, in das die Vorhersagen geschrieben werden Geben Sie die Projekt-ID und optional eine vorhandene Dataset-ID an. Verwenden Sie das folgende Formular:
bq://bqprojectId.bqDatasetId
bq://bqprojectId
- GENERATE_EXPLANATION: Der Standardwert ist false. Setzen Sie diesen Wert auf true, um Featureattributionen zu aktivieren. Weitere Informationen finden Sie unter Feature-Attributionen für Prognosen.
HTTP-Methode und URL:
POST https://LOCATION_ID-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION_ID/batchPredictionJobs
JSON-Text der Anfrage:
{
"displayName": "BATCH_JOB_NAME",
"model": "projects/PROJECT_ID/locations/LOCATION_ID/models/MODEL_ID",
"inputConfig": {
"instancesFormat": "bigquery",
"bigquerySource": {
"inputUri": "INPUT_URI"
}
},
"outputConfig": {
"predictionsFormat": "bigquery",
"bigqueryDestination": {
"outputUri": "OUTPUT_URI"
}
},
"generate_explanation": GENERATE_EXPLANATION
}
Wenn Sie die Anfrage senden möchten, wählen Sie eine der folgenden Optionen aus:
curl
Speichern Sie den Anfragetext in einer Datei mit dem Namen request.json und führen Sie den folgenden Befehl aus:
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION_ID-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION_ID/batchPredictionJobs"
PowerShell
Speichern Sie den Anfragetext in einer Datei mit dem Namen request.json und führen Sie den folgenden Befehl aus:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://LOCATION_ID-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION_ID/batchPredictionJobs" | Select-Object -Expand Content
Sie sollten eine JSON-Antwort ähnlich wie diese erhalten:
{
"name": "projects/PROJECT_ID/locations/LOCATION_ID/batchPredictionJobs/67890",
"displayName": "batch_job_1 202005291958",
"model": "projects/12345/locations/us-central1/models/5678",
"state": "JOB_STATE_PENDING",
"inputConfig": {
"instancesFormat": "bigquery",
"bigquerySource": {
"inputUri": "INPUT_URI"
}
},
"outputConfig": {
"predictionsFormat": "bigquery",
"bigqueryDestination": {
"outputUri": bq://12345
}
},
"dedicatedResources": {
"machineSpec": {
"machineType": "n1-standard-32",
"acceleratorCount": "0"
},
"startingReplicaCount": 2,
"maxReplicaCount": 6
},
"manualBatchTuningParameters": {
"batchSize": 4
},
"outputInfo": {
"bigqueryOutputDataset": "bq://12345.reg_model_2020_10_02_06_04
}
"state": "JOB_STATE_PENDING",
"createTime": "2020-09-30T02:58:44.341643Z",
"updateTime": "2020-09-30T02:58:44.341643Z",
}
Java
Bevor Sie dieses Beispiel anwenden, folgen Sie den Java-Einrichtungsschritten in der Vertex AI-Kurzanleitung zur Verwendung von Clientbibliotheken. Weitere Informationen finden Sie in der Referenzdokumentation zur Vertex AI Java API.
Richten Sie zur Authentifizierung bei Vertex AI Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Ersetzen Sie im folgenden Beispiel INSTANCES_FORMAT und PREDICTIONS_FORMAT durch "bigquery". Informationen zum Ersetzen der anderen Platzhalter finden Sie auf dem Tab "REST UND BEFEHLSZEILE" in diesem Abschnitt.Python
Informationen zur Installation des Vertex AI SDK for Python finden Sie unter Vertex AI SDK for Python installieren. Weitere Informationen finden Sie in der Referenzdokumentation zur Python API.
API: Cloud Storage
REST
Mit der Methode batchPredictionJobs.create können Sie eine Batchvorhersage anfordern.
Ersetzen Sie diese Werte in den folgenden Anfragedaten:
- LOCATION_ID: Region, in der das Modell gespeichert ist .und der Batchvorhersagejob ausgeführt wird. Beispiel:
us-central1. - PROJECT_ID: Ihre Projekt-ID
- BATCH_JOB_NAME: Anzeigename für den Batchjob
- MODEL_ID: Die ID für das Modell, das für Vorhersagen verwendet werden soll
-
URI: Pfade (URIs) zu den Cloud Storage-Buckets mit den Trainingsdaten.
Es können mehrere sein. Jeder URI hat das folgende Format:
gs://bucketName/pathToFileName
-
OUTPUT_URI_PREFIX: Pfad zu einem Cloud Storage-Ziel, in das die Vorhersagen geschrieben werden. Vertex AI schreibt Batchvorhersagen in ein mit einem Zeitstempel versehenes Unterverzeichnis dieses Pfads. Geben Sie für diesen Wert einen String im folgenden Format an:
gs://bucketName/pathToOutputDirectory
- GENERATE_EXPLANATION: Der Standardwert ist false. Setzen Sie diesen Wert auf true, um Featureattributionen zu aktivieren. Diese Option ist nur verfügbar, wenn das Ausgabeziel JSONL ist. Feature-Attributionen werden für CSV in Cloud Storage nicht unterstützt. Weitere Informationen finden Sie unter Feature-Attributionen für Prognosen.
HTTP-Methode und URL:
POST https://LOCATION_ID-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION_ID/batchPredictionJobs
JSON-Text der Anfrage:
{
"displayName": "BATCH_JOB_NAME",
"model": "projects/PROJECT_ID/locations/LOCATION_ID/models/MODEL_ID",
"inputConfig": {
"instancesFormat": "csv",
"gcsSource": {
"uris": [
URI1,...
]
},
},
"outputConfig": {
"predictionsFormat": "csv",
"gcsDestination": {
"outputUriPrefix": "OUTPUT_URI_PREFIX"
}
},
"generate_explanation": GENERATE_EXPLANATION
}
Wenn Sie die Anfrage senden möchten, wählen Sie eine der folgenden Optionen aus:
curl
Speichern Sie den Anfragetext in einer Datei mit dem Namen request.json und führen Sie den folgenden Befehl aus:
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION_ID-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION_ID/batchPredictionJobs"
PowerShell
Speichern Sie den Anfragetext in einer Datei mit dem Namen request.json und führen Sie den folgenden Befehl aus:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://LOCATION_ID-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION_ID/batchPredictionJobs" | Select-Object -Expand Content
Sie sollten eine JSON-Antwort ähnlich wie diese erhalten:
{
"name": "projects/PROJECT_ID/locations/LOCATION_ID/batchPredictionJobs/67890",
"displayName": "batch_job_1 202005291958",
"model": "projects/12345/locations/us-central1/models/5678",
"state": "JOB_STATE_PENDING",
"inputConfig": {
"instancesFormat": "csv",
"gcsSource": {
"uris": [
"gs://bp_bucket/reg_mode_test"
]
}
},
"outputConfig": {
"predictionsFormat": "csv",
"gcsDestination": {
"outputUriPrefix": "OUTPUT_URI_PREFIX"
}
},
"dedicatedResources": {
"machineSpec": {
"machineType": "n1-standard-32",
"acceleratorCount": "0"
},
"startingReplicaCount": 2,
"maxReplicaCount": 6
}
"outputInfo": {
"gcsOutputDataset": "OUTPUT_URI_PREFIX/prediction-batch_job_1 202005291958-2020-09-30T02:58:44.341643Z"
}
"state": "JOB_STATE_PENDING",
"createTime": "2020-09-30T02:58:44.341643Z",
"updateTime": "2020-09-30T02:58:44.341643Z",
}
Python
Informationen zur Installation des Vertex AI SDK for Python finden Sie unter Vertex AI SDK for Python installieren. Weitere Informationen finden Sie in der Referenzdokumentation zur Python API.
Batchvorhersageergebnisse abrufen
Vertex AI sendet die Ausgabe von Batchvorhersagen an das von Ihnen angegebene Ziel, entweder BigQuery oder Cloud Storage.
Die Cloud Storage-Ausgabe für Featureattributionen wird derzeit nicht unterstützt.
BigQuery
Ausgabe-Dataset
Wenn Sie BigQuery verwenden, wird die Ausgabe der Batchvorhersage in einem Ausgabe-Dataset gespeichert. Wenn Sie ein Dataset für Vertex AI bereitgestellt haben, ist der Name des Datasets (BQ_DATASET_NAME) der Name, den Sie zuvor angegeben haben. Wenn Sie kein Ausgabe-Dataset angegeben haben, hat Vertex AI ein Dataset für Sie erstellt. Sie finden den Namen (BQ_DATASET_NAME) mit den folgenden Schritten:
- Rufen Sie in der Google Cloud Console die Seite für Vertex AI-Batchvorhersagen auf.
- Wählen Sie die erstellte Vorhersage aus.
-
Das Ausgabe-Dataset ist unter Exportspeicherort angegeben. Der Dataset-Name wird so erstellt:
prediction_MODEL_NAME_TIMESTAMP
Ausgabetabellen
Das Ausgabe-Dataset enthält eine oder mehrere der folgenden drei Ausgabetabellen:
-
Vorhersagetabelle
Diese Tabelle enthält eine Zeile für jede Zeile in Ihren Eingabedaten, in der eine Vorhersage angefordert wurde (d. h., wenn TARGET_COLUMN_NAME = null ist). Wenn Ihre Eingabe beispielsweise 14 Nulleinträge für die Zielspalte (z. B. Verkäufe für die nächsten 14 Tage) enthielt, gibt Ihre Vorhersageanfrage 14 Zeilen zurück, die Summe der Verkäufe für jeden Tag. Wenn Ihre Vorhersageanfrage den Prognosehorizont des Modells überschreitet, gibt Vertex AI nur Vorhersagen bis zum Prognosehorizont zurück.
-
Fehlervalidierungstabelle
Diese Tabelle enthält eine Zeile für jeden nicht kritischen Fehler, der während der Aggregationsphase aufgetreten ist, die vor der Batchvorhersage erfolgt. Jeder nicht kritische Fehler entspricht einer Zeile in den Eingabedaten, für die Vertex AI keine Prognose zurückgeben konnte.
-
Fehlertabelle
Diese Tabelle enthält eine Zeile für jeden nicht kritischen Fehler, der während der Batchvorhersage aufgetreten ist. Jeder nicht kritische Fehler entspricht einer Zeile in den Eingabedaten, für die Vertex AI keine Prognose zurückgeben konnte.
Vorhersagetabelle
Der Name der Tabelle (BQ_PREDICTIONS_TABLE_NAME) wird durch Anfügen von "predictions_" mit dem Zeitstempel gebildet, wann der Batchvorhersagejob gestartet wurde: predictions_TIMESTAMP
So rufen Sie die Vorhersagetabelle ab:
-
Rufen Sie in der Console die Seite "BigQuery" auf.
BigQuery aufrufen -
Führen Sie die folgende Abfrage aus:
SELECT * FROM BQ_DATASET_NAME.BQ_PREDICTIONS_TABLE_NAME
Vertex AI speichert Vorhersagen in der Spalte predicted_TARGET_COLUMN_NAME.value.
Wenn Sie ein Modell mit dem TFT (Temporären Fusion Transformer) trainiert haben, finden Sie die TFT-Interpretierbarkeitsausgabe in der Spalte predicted_TARGET_COLUMN_NAME.tft_feature_importance:
Diese Spalte ist weiter unterteilt:
context_columns: Prognosefeatures, deren Kontextfensterwerte als Eingaben für den LSTM-Encoder (TFT Long Short-Term Memory) dienen.context_weights: Die Featurewichtigkeit, die mit jeder dercontext_columnsfür die vorhergesagte Instanz verknüpft ist.horizon_columns: Prognosefeatures, deren Prognosehorizont-Werte als Eingaben für den (LSTM)-Decoder (TFT Long Short-Term Memory) dienen.horizon_weights: Die Featurewichtigkeit, die mit jeder derhorizon_columnsfür die vorhergesagte Instanz verknüpft ist.attribute_columns: Prognosefunktionen, die zeitunabhängig sind.attribute_weights: Die mit jeder derattribute_columnsverknüpften Gewichtungen.
Wenn Ihr Modell für Quantilverlust optimiert ist und Ihr Quantilsatz den Medianwert enthält, ist predicted_TARGET_COLUMN_NAME.value der Vorhersagewert am Median. Andernfalls ist predicted_TARGET_COLUMN_NAME.value der Vorhersagewert im niedrigsten Quantil des Satzes. Wenn Ihr Quantilsatz beispielsweise [0.1, 0.5, 0.9] lautet, ist value die Vorhersage für das Quantil 0.5.
Wenn der Quantilsatz [0.1, 0.9] lautet, ist value die Vorhersage für das Quantil 0.1.
Darüber hinaus speichert Vertex AI Quantilwerte und Vorhersagen in den folgenden Spalten:
-
predicted_TARGET_COLUMN_NAME.quantile_values: Die Werte der Quantile, die während des Modelltrainings festgelegt werden. Dies können beispielsweise0.1,0.5und0.9sein. predicted_TARGET_COLUMN_NAME.quantile_predictions: Die Vorhersagewerte, die den Quantilwerten zugeordnet sind.
Wenn Ihr Modell die probabilistische Inferenz verwendet, enthält predicted_TARGET_COLUMN_NAME.value den Minimierer des Optimierungsziels. Wenn Ihr Optimierungsziel beispielsweise minimize-rmse ist, enthält predicted_TARGET_COLUMN_NAME.value den Mittelwert. Ist es minimize-mae, enthält predicted_TARGET_COLUMN_NAME.value den Medianwert.
Wenn Ihr Modell die probabilistische Inferenz mit Quantilen verwendet, speichert Vertex AI Quantilwerte und Vorhersagen in den folgenden Spalten:
-
predicted_TARGET_COLUMN_NAME.quantile_values: Die Werte der Quantile, die während des Modelltrainings festgelegt werden. Dies können beispielsweise0.1,0.5und0.9sein. predicted_TARGET_COLUMN_NAME.quantile_predictions: Die Vorhersagewerte, die den Quantilwerten zugeordnet sind.
Wenn Sie Feature-Attributionen aktiviert haben, finden Sie diese auch in der Vorhersagetabelle. Führen Sie die folgende Abfrage aus, um auf Zuordnungen für ein Feature BQ_FEATURE_NAME zuzugreifen:
SELECT explanation.attributions[OFFSET(0)].featureAttributions.BQ_FEATURE_NAME FROM BQ_DATASET_NAME.BQ_PREDICTIONS_TABLE_NAME
Weitere Informationen finden Sie unter Feature-Attributionen für Prognosen.
Fehlervalidierungstabelle
Der Name der Tabelle (BQ_ERRORS_VALIDATION_TABLE_NAME) wird durch Anfügen von "errors_validation" mit dem Zeitstempel gebildet, ab dem der Batchvorhersagejob gestartet wurde: errors_validation_TIMESTAMP
-
Rufen Sie in der Console die Seite "BigQuery" auf.
BigQuery aufrufen -
Führen Sie die folgende Abfrage aus:
SELECT * FROM BQ_DATASET_NAME.BQ_ERRORS_VALIDATION_TABLE_NAME
- errors_TARGET_COLUMN_NAME
Fehlertabelle
Der Name der Tabelle (BQ_ERRORS_TABLE_NAME) wird durch Anfügen von "errors_" mit dem Zeitstempel gebildet, ab dem der Batchvorhersagejob gestartet wurde: errors_TIMESTAMP
-
Rufen Sie in der Console die Seite "BigQuery" auf.
BigQuery aufrufen -
Führen Sie die folgende Abfrage aus:
SELECT * FROM BQ_DATASET_NAME.BQ_ERRORS_TABLE_NAME
- errors_TARGET_COLUMN_NAME.code
- errors_TARGET_COLUMN_NAME.message
Cloud Storage
Wenn Sie Cloud Storage als Ausgabeziel angegeben haben, werden die Ergebnisse Ihrer Batchvorhersageanfrage als CSV-Dateien in einem neuen Ordner in dem von Ihnen angegebenen Bucket zurückgegeben. Der Name des Ordners ist der Name Ihres Modells, dem "prediction_" vorangestellt wird und der Zeitstempel vom Start des Vorhersagejobs angehängt wird. Sie finden den Namen des Cloud Storage-Ordners auf dem Tab Batchvorhersagen für Ihr Modell.
Der Cloud Storage-Ordner enthält zwei Arten von Objekten:-
Vorhersageobjekte
Die Vorhersageobjekte heißen "predictions_1.csv", "predictions_2.csv" usw. Sie enthalten eine Kopfzeile mit den Spaltennamen und eine Zeile für jede zurückgegebene Vorhersage. Die Anzahl der Vorhersagewerte hängt von der Vorhersageeingabe und dem Vorhersagezeitraum ab. Wenn Ihre Eingabe beispielsweise 14 Nulleinträge für die Zielspalte (z. B. Verkäufe für die nächsten 14 Tage) enthielt, gibt Ihre Vorhersageanfrage 14 Zeilen zurück, die Summe der Verkäufe für jeden Tag. Wenn Ihre Vorhersageanfrage den Prognosehorizont des Modells überschreitet, gibt Vertex AI nur Vorhersagen bis zum Prognosehorizont zurück.
Die Prognosewerte werden in einer Spalte mit dem Namen "predicted_TARGET_COLUMN_NAME" zurückgegeben. Bei Quantilprognosen enthält die Ausgabespalte die Quantilvorhersagen und Quantilwerte im JSON-Format.
-
Fehlerobjekte
Die Fehlerobjekte heißen "errors_1.csv", "errors_2.csv" usw. Sie enthalten eine Kopfzeile und eine Zeile für jede Zeile in Ihren Eingabedaten, für die Vertex AI keine Prognose zurückgeben konnte, z. B. wenn eine Funktion, die keinen Nullwert zulässt, null war.
Hinweis: Wenn die Ergebnisse umfangreich sind, werden sie in mehrere Objekte aufgeteilt.
Beispiele für Abfragen der Feature-Attribution in BigQuery
Beispiel 1: Attributionen für eine einzelne Vorhersage ermitteln
Stellen Sie sich folgende Frage:
Wie stark hat ein Advertising für ein Produkt die für den 24. November in einem bestimmten Geschäft vorhergesagten Umsätze gesteigert?
Die entsprechende Abfrage sieht so aus:
SELECT
* EXCEPT(explanation, predicted_sales),
ROUND(predicted_sales.value, 2) AS predicted_sales,
ROUND(
explanation.attributions[OFFSET(0)].featureAttributions.advertisement,
2
) AS attribution_advertisement
FROM
`project.dataset.predictions`
WHERE
product = 'product_0'
AND store = 'store_0'
AND date = '2019-11-24'
Beispiel 2: Globale Merkmalwichtigkeit ermitteln
Stellen Sie sich folgende Frage:
Wie viel hat jedes Feature insgesamt zum vorhergesagten Umsatz beigetragen?
Sie können die globale Merkmalwichtigkeit manuell berechnen, indem Sie die Attributionen der lokalen Merkmalwichtigkeit zusammenfassen. Die entsprechende Abfrage sieht so aus:
WITH
/*
* Aggregate from (id, date) level attributions to global feature importance.
*/
attributions_aggregated AS (
SELECT
SUM(ABS(attributions.featureAttributions.date)) AS date,
SUM(ABS(attributions.featureAttributions.advertisement)) AS advertisement,
SUM(ABS(attributions.featureAttributions.holiday)) AS holiday,
SUM(ABS(attributions.featureAttributions.sales)) AS sales,
SUM(ABS(attributions.featureAttributions.store)) AS store,
SUM(ABS(attributions.featureAttributions.product)) AS product,
FROM
project.dataset.predictions,
UNNEST(explanation.attributions) AS attributions
),
/*
* Calculate the normalization constant for global feature importance.
*/
attributions_aggregated_with_total AS (
SELECT
*,
date + advertisement + holiday + sales + store + product AS total
FROM
attributions_aggregated
)
/*
* Calculate the normalized global feature importance.
*/
SELECT
ROUND(date / total, 2) AS date,
ROUND(advertisement / total, 2) AS advertisement,
ROUND(holiday / total, 2) AS holiday,
ROUND(sales / total, 2) AS sales,
ROUND(store / total, 2) AS store,
ROUND(product / total, 2) AS product,
FROM
attributions_aggregated_with_total
Beispielausgabe einer Batchvorhersage in BigQuery
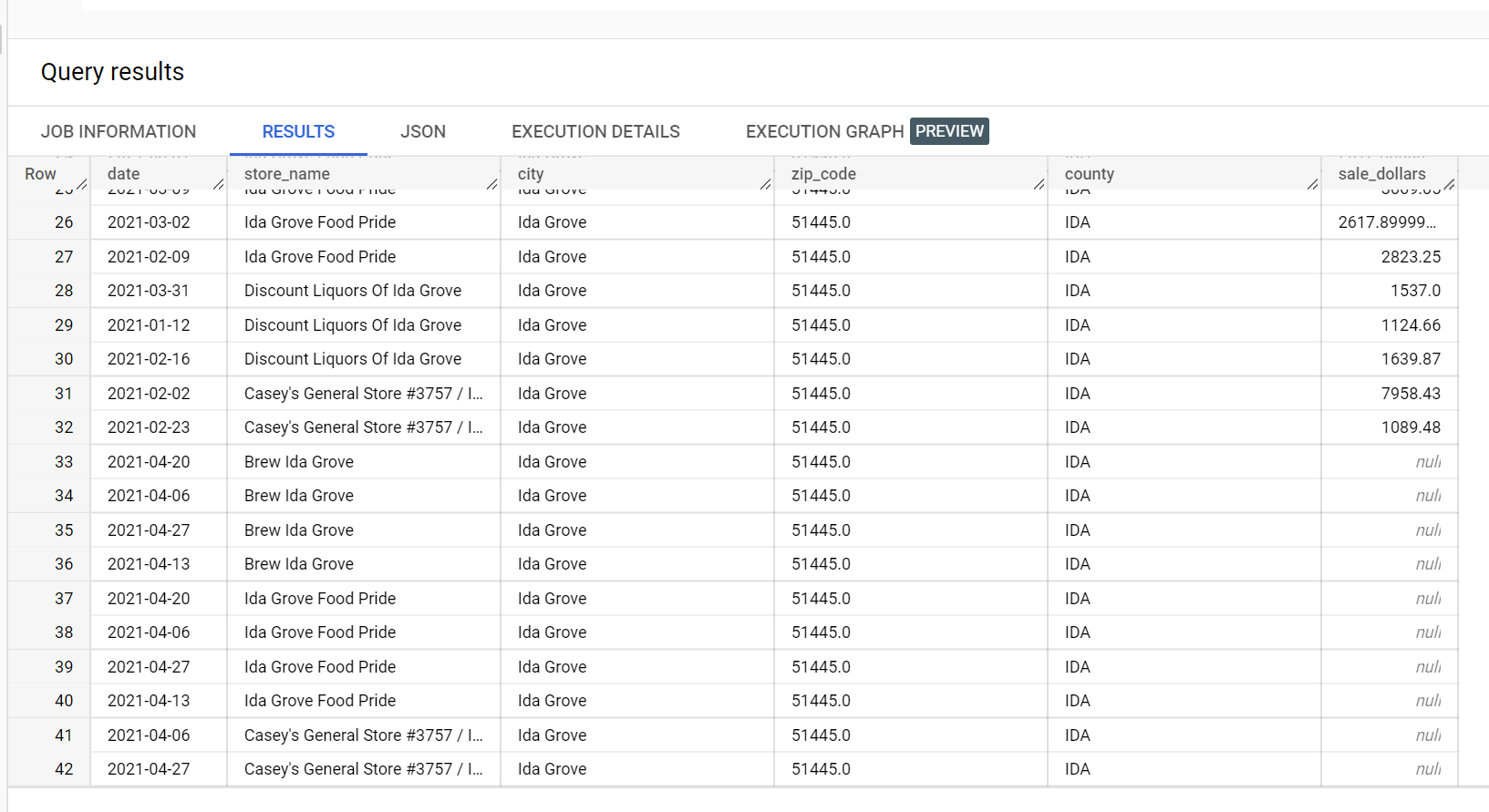
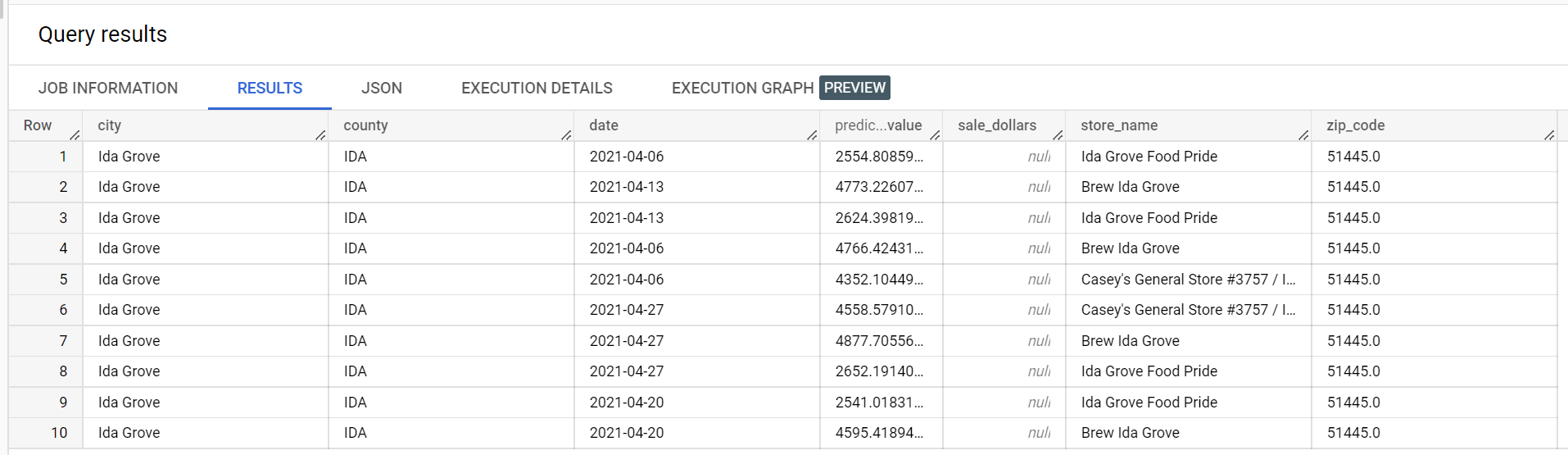
In einem Beispiel-Dataset von Spirituosen gibt es vier Geschäfte in der Stadt "Ida Grove": "Ida Grove Food Pride", "Discount Liquors of Ida Grove", "Casey's General Store #3757", und "Brew Ida Grove". store_name ist der series identifier und drei der vier Speicheranfragevorhersagen für die Zielspalte sale_dollars. Ein Validierungsfehler wird generiert, da keine Prognose für "Discount Liquors of Ida Grove" angefordert wurde.
Es folgt ein Auszug aus dem Eingabe-Dataset, das für die Vorhersage verwendet wird:
Dies ist ein Auszug aus den Vorhersageergebnissen:
Hier ein Auszug aus den Validierungsfehlern:

Beispielausgabe einer Batchvorhersage für ein für Quantilverlust optimiertes Modell
Das folgende Beispiel zeigt die Batchvorhersageausgabe für ein für einen Quantilverlust optimiertes Modell. In diesem Szenario hat das Prognosemodell den Umsatz für die kommenden 14 Tage für jedes Filiale vorhergesagt.
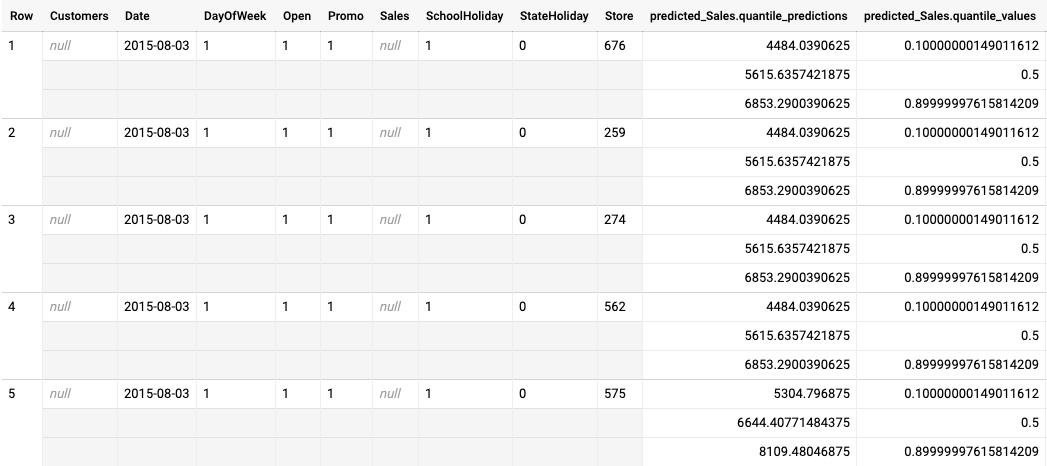
Die Quantilwerte werden in der Spalte predicted_Sales.quantile_values angegeben. In diesem Beispiel hat das Modell Werte in den Quantilen 0.1, 0.5 und 0.9 vorhergesagt.
Die Vorhersagewerte werden in der Spalte predicted_Sales.quantile_predictions angegeben.
Dies ist ein Array von Umsatzwerten, die den Quantilwerten in der Spalte predicted_Sales.quantile_values zugeordnet sind. In der ersten Zeile sehen wir, dass die Wahrscheinlichkeit, dass der Verkaufswerts unter 4484.04 liegt, 10 % beträgt. Die Wahrscheinlichkeit, dass der Verkaufswert unter 5615.64 liegt, beträgt 50 %. Die Wahrscheinlichkeit, dass der Verkaufswert unter 6853.29 liegt, beträgt 90 %. Die Vorhersage für die erste Zeile, dargestellt als ein einzelner Wert, ist 5615.64.