データセットを使用して AutoML モデルをトレーニングすると、Vertex AI はデータをトレーニング、検証、テストの 3 つに分割します。データ分割を作成する際の主な目標は、テストセットが本番環境のデータを正確に表すようにすることです。この目標が達成されると、評価指標は、モデルが実際の環境でどのような結果を出せるかを正確に示すようになります。
このページでは、Vertex AI がデータのトレーニング セット、検証セット、テストセットを使用して AutoML モデルをトレーニングする方法について説明します。また、これらの 3 つのセット間でデータを分割する方法を制御する方法についても説明します。分類と回帰のデータ分割アルゴリズムは、予測のデータ分割アルゴリズムとは異なります。
分類と回帰のためのデータ分割
データ分割の用途
データ分割は、トレーニング プロセスで次のように使用されます。
モデルの試行
トレーニング セットは、さまざまな前処理、アーキテクチャ、ハイパーパラメータ オプションの組み合わせを使用してモデルをトレーニングするために使用されます。Vertex AI は、検証セットに基づいてこれらのモデルの品質を評価し、さらに別のオプションの組み合わせの探索につなげます。この検証セットは、トレーニング時の定期的な評価から最適なチェックポイントを選択するためにも使用されます。Vertex AI は、並列チューニング フェーズで決定された最適なパラメータとアーキテクチャを使用して、以下で説明するように 2 つのアンサンブル モデルをトレーニングします。
モデルの評価
Vertex AI は、トレーニング データと検証セットをトレーニング データとして使用して、評価モデルをトレーニングします。また、テストセットを使用して、このモデルの最終的なモデル評価指標を生成します。このプロセスでテストセットが使用されるのはこれが初めてです。この方法により、最終的なトレーニング済みモデルが本番環境でどの程度的確な結果を出せるかを、最終的な評価指標が偏りなく反映しているかが確認されます。
モデルのサービング
Vertex AI は、トレーニング データの量を最大にするために、トレーニング セット、検証セット、テストセットを使用してモデルをトレーニングします。このモデルを使用して、オンライン予測またはバッチ予測をリクエストします。
デフォルトのデータ分割
デフォルトでは、Vertex AI はランダム分割アルゴリズムを使用して、データを 3 つの分割データに仕分けします。Vertex AI はトレーニング データの 80% をトレーニング セット、10% を検証セット、10% をテストセットにランダムに選択します。次のようなデータセットには、デフォルトの分割をおすすめします。
- 時間とともに変化しない。
- 相対的にバランスが取れている。
- 本番環境での予測に使用されるデータと同様に分布している。
デフォルトのデータ分割を使用するには、 Google Cloud コンソールでデフォルト値をそのまま使用するか、API の split フィールドを空白のままにします。
データ分割を制御する方法
どの分割に対してどの行を選択するかを制御するには、次のいずれかの方法を使用します。
- ランダム分割: 分割の割合を設定し、データ行をランダムに割り当てます。
- 手動分割: データ分割列のトレーニング、検証、テストに使用する特定の行を選択します。
- 時系列分割: [時間] 列の時間でデータを分割します。
これらのオプションからいずれか 1 つだけを選択します。選択はモデルのトレーニングの際に行います。オプションによっては、トレーニング データ(データ分割列や時間列など)の変更が必要なものもあります。データ分割オプション用のデータを含めても、そうしたオプションを使用する必要はありません。モデルをトレーニングするときに、別のオプションを選択することもできます。
以下の場合、デフォルトの分割は最適な選択ではありません。
予測モデルをトレーニングしていないが、データが時間に依存している。
テストデータに、本番環境を代表していない集団のデータが含まれている。
たとえば、多数の店舗の購入データでモデルをトレーニングするとします。このモデルは本来、トレーニング データに含まれない店舗について予測を行うために使用されるものです。モデルがデータにない店舗にも対応するように汎用性を持たせるには、店舗ごとにデータセットを分離します。つまり、テストセットには検証セットと異なる店舗だけを含め、検証セットにはトレーニング セットと異なる店舗だけを含める必要があります。
クラスの数が不均衡である。
トレーニング データにある特定のクラスが別のクラスの数より多い場合、テストデータで少ない方のクラスのサンプルを手動で増やす必要が生じる可能性があります。Vertex AI では層化サンプリングは行われないため、テストセットに含まれている少数派のクラスのサンプル数がわずか数個、場合によってゼロということもあります。
ランダム分割
ランダム分割は、「数学的分割」または「比率による分割」とも呼ばれます。
デフォルトでは、トレーニング、検証、テストセットに使用されるトレーニング データの割合はそれぞれ 80、10、10 です。 Google Cloud コンソールを使用する場合は、割合の合計が 100 になる任意の値に変更できます。Vertex AI API を使用する場合は、合計で 1.0 になる分割値を使用します。
割合(比率)を変更するには、FractionSplit オブジェクトを使用して比率を定義します。
Vertex AI は、データ分割の行をランダムに(しかし確定的に)選択します。生成されたデータ分割の構成が適切でない場合は、手動分割を使用するか、トレーニング データを変更します。同じトレーニング データを使用して新しいモデルをトレーニングしても、同じデータ分割になります。
手動分割
手動分割は「事前定義分割」とも呼ばれます。
データ分割列を使用すると、トレーニング、検証、テストに使用する特定の行を選択できます。トレーニング データを作成するときに、次のいずれかの値(大文字と小文字を区別)を含む列を追加します。
TRAINVALIDATETESTUNASSIGNED
この列の値は、次の 2 つの組み合わせのいずれかにする必要があります。
TRAIN、VALIDATE、TESTのすべてTESTとUNASSIGNEDのみ
すべての行にはこの列の値が必要です。空の文字列にすることはできません。
たとえば、すべてのセットが指定されている場合:
"TRAIN","John","Doe","555-55-5555" "TEST","Jane","Doe","444-44-4444" "TRAIN","Roger","Rogers","123-45-6789" "VALIDATE","Sarah","Smith","333-33-3333"
テストセットのみが指定されている場合:
"UNASSIGNED","John","Doe","555-55-5555" "TEST","Jane","Doe","444-44-4444" "UNASSIGNED","Roger","Rogers","123-45-6789" "UNASSIGNED","Sarah","Smith","333-33-3333"
データ分割列には、任意の有効な列名を指定できます。変換タイプは、カテゴリ、テキスト、自動のいずれかになります。
データ分割列の値が UNASSIGNED の場合、Vertex AI はその行を自動的にトレーニング セットまたは検証セットに割り当てます。
列は、モデルをトレーニングするときに、データ分割列として指定します。
時系列分割
時系列分割は、「タイムスタンプ分割」とも呼ばれます。
データが時間に依存する場合は、1 つの列を時間列として指定できます。Vertex AI は、時間列を使用してデータを分割し、最も古い行をトレーニング、次の行を検証、最新の行をテストに使用します。
Vertex AI では、各行を独立同分布トレーニングのサンプルとして扱います。これは時間列を設定しても変わりません。時間列はデータセットの分割にのみ使用されます。
時間列を指定する場合は、データセットのすべての行に、時間列の値が入っている必要があります。検証セットとテストセットが空にならないように、時間列に十分な数の固有の値があることを確認してください。通常は、少なくとも 20 個の固有の値があれば十分です。
時間列のデータは、タイムスタンプ変換でサポートされている形式にする必要があります。ただし、時間列にはサポートされている任意の変換を行うことができます。変換は、トレーニングで列が使用される方法に影響しますが、データ分割に影響することはありません。
各セットに割り当てられるトレーニング データの割合を指定することもできます。
モデルをトレーニングするときに、列を時間列として指定します。
予測のためのデータ分割
デフォルトでは、Vertex AI は時系列分割アルゴリズムを使用して、予測データを 3 つの分割データに仕分けします。デフォルトの分割を使用することをおすすめします。ただし、どのトレーニング データ行をどの分割に使用するかを制御する場合は、手動分割を使用してください。
データ分割の用途
データ分割は、トレーニング プロセスで次のように使用されます。
モデルの試行
トレーニング セットは、さまざまな前処理、アーキテクチャ、ハイパーパラメータ オプションの組み合わせを使用してモデルをトレーニングするために使用されます。Vertex AI は、検証セットに基づいてこれらのモデルの品質を評価し、さらに別のオプションの組み合わせの探索につなげます。検証セットは、トレーニング時の定期的な評価から最適なチェックポイントを選択するためにも使用されます。Vertex AI は、並列チューニング フェーズで決定された最適なパラメータとアーキテクチャを使用して、以下で説明するように 2 つのアンサンブル モデルをトレーニングします。
モデルの評価
Vertex AI は、トレーニング データと検証セットをトレーニング データとして使用して、評価モデルをトレーニングします。また、テストセットを使用して、このモデルの最終的なモデル評価指標を生成します。このプロセスでテストセットが使用されるのはこれが初めてです。この方法により、最終的なトレーニング済みモデルが本番環境でどの程度的確な結果を出せるかを、最終的な評価指標が偏りなく反映しているかが確認されます。
モデルのサービング
Vertex AI は、トレーニング セットと検証セットを使用してモデルをトレーニングします。モデルは、テストセットを使用して検証されます(最適なチェックポイントを選択するため)。そこから損失が計算されるという意味で、テストセットではトレーニングされません。このモデルを使用して推論を取得します。
デフォルト分割
デフォルトの(時系列)データ分割は次のように機能します。
- Vertex AI は、トレーニング データを日付で並べ替えます。
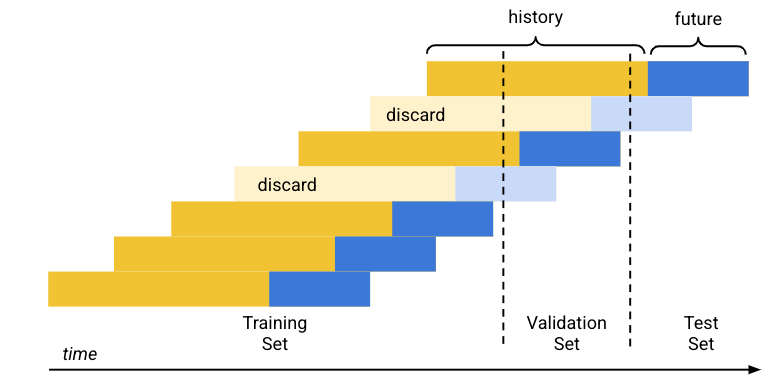
- 事前に定義された設定割合(80/10/10)を使用して、Vertex AI はトレーニング データが対象とする期間を 3 つのブロック(トレーニング セットごとに 1 つ)に分割します。
- Vertex AI は、十分な履歴(コンテキスト ウィンドウ)がない行からモデルが学習できるように、各時系列の先頭に空の行を追加します。追加される行の数は、トレーニングの際に設定したコンテキスト ウィンドウのサイズです。
トレーニング時に設定した予測ホライズン サイズを使用して、将来のデータ(予測ホライズン)がデータセットのいずれかに完全に収まる各行が、そのセットに使用されます。(データ漏洩を防ぐため、Vertex AI は 2 つのセットにまたがる予測ホライズンの行を破棄します)。
手動分割
データ分割列を使用すると、トレーニング、検証、テストに使用する特定の行を選択できます。トレーニング データを作成するときに、次のいずれかの値(大文字と小文字を区別)を含む列を追加します。
TRAINVALIDATETEST
すべての行にはこの列の値が必要です。空の文字列にすることはできません。
次に例を示します。
"TRAIN","sku_id_1","2020-09-21","10" "TEST","sku_id_1","2020-09-22","23" "TRAIN","sku_id_2","2020-09-22","3" "VALIDATE","sku_id_2","2020-09-23","45"
データ分割列には、任意の有効な列名を指定できます。変換タイプは、カテゴリ、テキスト、自動のいずれかになります。
列は、モデルをトレーニングするときに、データ分割列として指定します。
時系列間のデータ漏洩が発生しないように注意してください。