このドキュメントでは、Vertex AI Pipelines と Cloud Run functions を使用して、定期的なスケジュールで、または新しいデータがデータセットに挿入されたときに、カスタムモデルを自動的にトレーニングするパイプラインを構築する手順について説明します。
目標
このプロセスは次の手順で行います。
BigQuery でデータセットを取得して準備する。
カスタム トレーニング パッケージを作成してアップロードする。実行すると、データセットからデータが読み取られ、モデルがトレーニングされます。
Vertex AI Pipelines を構築する。このパイプラインは、カスタム トレーニング パッケージを実行してモデルを Vertex AI Model Registry にアップロードし、評価ジョブを実行して通知メールを送信します。
パイプラインを手動で実行する。
BigQuery データセットに新しいデータが挿入されるたびにパイプラインを実行する Eventarc トリガーを使用して、Cloud Functions の関数を作成します。
始める前に
プロジェクトとノートブックを設定します。
プロジェクトの設定
-
In the Google Cloud console, go to the project selector page.
-
Select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
ノートブックを作成する
このチュートリアルでは、コードの一部を Colab Enterprise ノートブックで実行します。
プロジェクト オーナーでない場合は、
roles/resourcemanager.projectIamAdminとroles/aiplatform.colabEnterpriseUserの IAM ロールを付与するようプロジェクト オーナーに依頼してください。Colab Enterprise を使用し、自分自身とサービス アカウントに IAM のロールと権限を付与するには、これらのロールが必要です。
Google Cloud コンソールで、[Colab Enterprise ノートブック] ページに移動します。
必要な API がまだ有効になっていない場合は、API を有効にするように Colab Enterprise から求められます。
- Vertex AI API
- Dataform API
- Compute Engine API
[リージョン] メニューで、ノートブックを作成するリージョンを選択します。わからない場合は、リージョンとして us-central1 を使用します。
このチュートリアルでは、すべてのリソースに同じリージョンを使用します。
[新しいノートブックを作成] をクリックします。
新しいノートブックが [マイ ノートブック] タブに表示されます。ノートブックでコードを実行するには、コードセルを追加して、[ セルを実行] ボタンをクリックします。
開発環境をセットアップする
ノートブックで、次の Python3 パッケージをインストールします。
! pip3 install google-cloud-aiplatform==1.34.0 \ google-cloud-pipeline-components==2.6.0 \ kfp==2.4.0 \ scikit-learn==1.0.2 \ mlflow==2.10.0次のコマンドを実行して、Google Cloud CLI プロジェクトを設定します。
PROJECT_ID = "PROJECT_ID" # Set the project id ! gcloud config set project {PROJECT_ID}PROJECT_ID は、実際のプロジェクト ID に置き換えます。プロジェクト ID は Google Cloud コンソールでも確認できます。
Google アカウントにロールを付与します。
! gcloud projects add-iam-policy-binding PROJECT_ID --member="user:"EMAIL_ADDRESS"" --role=roles/bigquery.admin ! gcloud projects add-iam-policy-binding PROJECT_ID --member="user:"EMAIL_ADDRESS"" --role=roles/aiplatform.user ! gcloud projects add-iam-policy-binding PROJECT_ID --member="user:"EMAIL_ADDRESS"" --role=roles/storage.admin ! gcloud projects add-iam-policy-binding PROJECT_ID --member="user:"EMAIL_ADDRESS"" --role=roles/pubsub.editor ! gcloud projects add-iam-policy-binding PROJECT_ID --member="user:"EMAIL_ADDRESS"" --role=roles/cloudfunctions.admin ! gcloud projects add-iam-policy-binding PROJECT_ID --member="user:"EMAIL_ADDRESS"" --role=roles/logging.viewer ! gcloud projects add-iam-policy-binding PROJECT_ID --member="user:"EMAIL_ADDRESS"" --role=roles/logging.configWriter ! gcloud projects add-iam-policy-binding PROJECT_ID --member="user:"EMAIL_ADDRESS"" --role=roles/iam.serviceAccountUser ! gcloud projects add-iam-policy-binding PROJECT_ID --member="user:"EMAIL_ADDRESS"" --role=roles/eventarc.admin ! gcloud projects add-iam-policy-binding PROJECT_ID --member="user:"EMAIL_ADDRESS"" --role=roles/aiplatform.colabEnterpriseUser ! gcloud projects add-iam-policy-binding PROJECT_ID --member="user:"EMAIL_ADDRESS"" --role=roles/artifactregistry.admin ! gcloud projects add-iam-policy-binding PROJECT_ID --member="user:"EMAIL_ADDRESS"" --role=roles/serviceusage.serviceUsageAdmin次の API を有効にします。
- Artifact Registry API
- BigQuery API
- Cloud Build API
- Cloud Functions API
- Cloud Logging API
- Pub/Sub API
- Cloud Run Admin API
- Cloud Storage API
- Eventarc API
- Service Usage API
- Vertex AI API
! gcloud services enable artifactregistry.googleapis.com bigquery.googleapis.com cloudbuild.googleapis.com cloudfunctions.googleapis.com logging.googleapis.com pubsub.googleapis.com run.googleapis.com storage-component.googleapis.com eventarc.googleapis.com serviceusage.googleapis.com aiplatform.googleapis.comプロジェクトのサービス アカウントにロールを付与します。
サービス アカウントの名前を表示します。
! gcloud iam service-accounts listCompute サービス エージェントの名前をメモします。
xxxxxxxx-compute@developer.gserviceaccount.comの形式になっているはずです。サービス エージェントに必要なロールを付与します。
! gcloud projects add-iam-policy-binding PROJECT_ID --member="serviceAccount:"SA_ID-compute@developer.gserviceaccount.com"" --role=roles/aiplatform.serviceAgent ! gcloud projects add-iam-policy-binding PROJECT_ID --member="serviceAccount:"SA_ID-compute@developer.gserviceaccount.com"" --role=roles/eventarc.eventReceiver
データセットを取得して準備する
このチュートリアルでは、乗車時間、場所、距離などの特徴に基づいてタクシー運賃を予測するモデルを構築します。ここでは、一般公開データセットの Chicago Taxi Trips のデータを使用します。このデータセットは、2013 年から現在までのタクシーの賃走情報で構成されており、規制当局であるシカゴ市に報告されます。タクシーの運転手と乗客のプライバシーを保護すると同時に、データの分析をアグリゲータに許可するため、タクシー ID はタクシーの営業許可番号と一致するように維持されますが、その番号は表示されません。また、国勢統計区も表示されないこともあります。時間は 15 分単位に丸められます。
詳しくは、Marketplace で Chicago Taxi Trips をご覧ください。
BigQuery データセットを作成する
Google Cloud コンソールで、[BigQuery Studio] に移動します。
[エクスプローラ] パネルでプロジェクトを見つけ、[アクション] をクリックして [データセットを作成] をクリックします。
[データセットを作成する] ページで次の操作を行います。
[データセット ID] に「
mlops」と入力します。詳細については、データセットの命名をご覧ください。[ロケーション タイプ] で、マルチリージョンを選択します。たとえば、
us-central1を使用している場合は、[US(米国内の複数のリージョン)] を選択します。データセットの作成後にロケーションを変更することはできません。[データセットを作成] をクリックします。
詳細については、データセットの作成方法をご覧ください。
BigQuery テーブルを作成してデータを入力する
このセクションでは、テーブルを作成し、一般公開データセットからプロジェクトのデータセットに 1 年分のデータをまとめてインポートします。
BigQuery Studio に移動します。
[SQL クエリを作成] をクリックし、[ 実行] をクリックして、次の SQL クエリを実行します。
CREATE OR REPLACE TABLE `PROJECT_ID.mlops.chicago` AS ( WITH taxitrips AS ( SELECT trip_start_timestamp, trip_end_timestamp, trip_seconds, trip_miles, payment_type, pickup_longitude, pickup_latitude, dropoff_longitude, dropoff_latitude, tips, tolls, fare, pickup_community_area, dropoff_community_area, company, unique_key FROM `bigquery-public-data.chicago_taxi_trips.taxi_trips` WHERE pickup_longitude IS NOT NULL AND pickup_latitude IS NOT NULL AND dropoff_longitude IS NOT NULL AND dropoff_latitude IS NOT NULL AND trip_miles > 0 AND trip_seconds > 0 AND fare > 0 AND EXTRACT(YEAR FROM trip_start_timestamp) = 2019 ) SELECT trip_start_timestamp, EXTRACT(MONTH from trip_start_timestamp) as trip_month, EXTRACT(DAY from trip_start_timestamp) as trip_day, EXTRACT(DAYOFWEEK from trip_start_timestamp) as trip_day_of_week, EXTRACT(HOUR from trip_start_timestamp) as trip_hour, trip_seconds, trip_miles, payment_type, ST_AsText( ST_SnapToGrid(ST_GeogPoint(pickup_longitude, pickup_latitude), 0.1) ) AS pickup_grid, ST_AsText( ST_SnapToGrid(ST_GeogPoint(dropoff_longitude, dropoff_latitude), 0.1) ) AS dropoff_grid, ST_Distance( ST_GeogPoint(pickup_longitude, pickup_latitude), ST_GeogPoint(dropoff_longitude, dropoff_latitude) ) AS euclidean, CONCAT( ST_AsText(ST_SnapToGrid(ST_GeogPoint(pickup_longitude, pickup_latitude), 0.1)), ST_AsText(ST_SnapToGrid(ST_GeogPoint(dropoff_longitude, dropoff_latitude), 0.1)) ) AS loc_cross, IF((tips/fare >= 0.2), 1, 0) AS tip_bin, tips, tolls, fare, pickup_longitude, pickup_latitude, dropoff_longitude, dropoff_latitude, pickup_community_area, dropoff_community_area, company, unique_key, trip_end_timestamp FROM taxitrips LIMIT 1000000 )次のクエリは、テーブル
<PROJECT_ID>.mlops.chicagoを作成し、公開されているbigquery-public-data.chicago_taxi_trips.taxi_tripsテーブルのデータを入力します。テーブルのスキーマを表示するには、[テーブルに移動] をクリックし、[スキーマ] タブをクリックします。
テーブルの内容を確認するには、[プレビュー] タブをクリックします。
カスタム トレーニング パッケージを作成してアップロードする
このセクションでは、データセットを読み取り、データをトレーニング セットとテストセットに分割し、カスタムモデルのトレーニング コードを含む Python パッケージを作成します。パッケージは、パイプラインのタスクの一つとして実行されます。詳細については、ビルド済みコンテナ用の Python トレーニング アプリケーションを作成するをご覧ください。
カスタム トレーニング パッケージを作成する
Colab ノートブックで、トレーニング アプリケーションの親フォルダを作成します。
!mkdir -p training_package/trainer次のコマンドを使用して、各フォルダに
__init__.pyファイルを作成し、パッケージにします。! touch training_package/__init__.py ! touch training_package/trainer/__init__.py新しいファイルとフォルダは、[ファイル] folder パネルで確認できます。
[ファイル] パネルで、training_package/trainer フォルダに
task.pyというファイルを作成し、次の内容を記述します。# Import the libraries from sklearn.model_selection import train_test_split, cross_val_score from sklearn.preprocessing import OneHotEncoder, StandardScaler from google.cloud import bigquery, bigquery_storage from sklearn.ensemble import RandomForestRegressor from sklearn.compose import ColumnTransformer from sklearn.pipeline import Pipeline from google import auth from scipy import stats import numpy as np import argparse import joblib import pickle import csv import os # add parser arguments parser = argparse.ArgumentParser() parser.add_argument('--project-id', dest='project_id', type=str, help='Project ID.') parser.add_argument('--training-dir', dest='training_dir', default=os.getenv("AIP_MODEL_DIR"), type=str, help='Dir to save the data and the trained model.') parser.add_argument('--bq-source', dest='bq_source', type=str, help='BigQuery data source for training data.') args = parser.parse_args() # data preparation code BQ_QUERY = """ with tmp_table as ( SELECT trip_seconds, trip_miles, fare, tolls, company, pickup_latitude, pickup_longitude, dropoff_latitude, dropoff_longitude, DATETIME(trip_start_timestamp, 'America/Chicago') trip_start_timestamp, DATETIME(trip_end_timestamp, 'America/Chicago') trip_end_timestamp, CASE WHEN (pickup_community_area IN (56, 64, 76)) OR (dropoff_community_area IN (56, 64, 76)) THEN 1 else 0 END is_airport, FROM `{}` WHERE dropoff_latitude IS NOT NULL and dropoff_longitude IS NOT NULL and pickup_latitude IS NOT NULL and pickup_longitude IS NOT NULL and fare > 0 and trip_miles > 0 and MOD(ABS(FARM_FINGERPRINT(unique_key)), 100) between 0 and 99 ORDER BY RAND() LIMIT 10000) SELECT *, EXTRACT(YEAR FROM trip_start_timestamp) trip_start_year, EXTRACT(MONTH FROM trip_start_timestamp) trip_start_month, EXTRACT(DAY FROM trip_start_timestamp) trip_start_day, EXTRACT(HOUR FROM trip_start_timestamp) trip_start_hour, FORMAT_DATE('%a', DATE(trip_start_timestamp)) trip_start_day_of_week FROM tmp_table """.format(args.bq_source) # Get default credentials credentials, project = auth.default() bqclient = bigquery.Client(credentials=credentials, project=args.project_id) bqstorageclient = bigquery_storage.BigQueryReadClient(credentials=credentials) df = ( bqclient.query(BQ_QUERY) .result() .to_dataframe(bqstorage_client=bqstorageclient) ) # Add 'N/A' for missing 'Company' df.fillna(value={'company':'N/A','tolls':0}, inplace=True) # Drop rows containing null data. df.dropna(how='any', axis='rows', inplace=True) # Pickup and dropoff locations distance df['abs_distance'] = (np.hypot(df['dropoff_latitude']-df['pickup_latitude'], df['dropoff_longitude']-df['pickup_longitude']))*100 # Remove extremes, outliers possible_outliers_cols = ['trip_seconds', 'trip_miles', 'fare', 'abs_distance'] df=df[(np.abs(stats.zscore(df[possible_outliers_cols].astype(float))) < 3).all(axis=1)].copy() # Reduce location accuracy df=df.round({'pickup_latitude': 3, 'pickup_longitude': 3, 'dropoff_latitude':3, 'dropoff_longitude':3}) # Drop the timestamp col X=df.drop(['trip_start_timestamp', 'trip_end_timestamp'],axis=1) # Split the data into train and test X_train, X_test = train_test_split(X, test_size=0.10, random_state=123) ## Format the data for batch predictions # select string cols string_cols = X_test.select_dtypes(include='object').columns # Add quotes around string fields X_test[string_cols] = X_test[string_cols].apply(lambda x: '\"' + x + '\"') # Add quotes around column names X_test.columns = ['\"' + col + '\"' for col in X_test.columns] # Save DataFrame to csv X_test.to_csv(os.path.join(args.training_dir,"test.csv"),index=False,quoting=csv.QUOTE_NONE, escapechar=' ') # Save test data without the target for batch predictions X_test.drop('\"fare\"',axis=1,inplace=True) X_test.to_csv(os.path.join(args.training_dir,"test_no_target.csv"),index=False,quoting=csv.QUOTE_NONE, escapechar=' ') # Separate the target column y_train=X_train.pop('fare') # Get the column indexes col_index_dict = {col: idx for idx, col in enumerate(X_train.columns)} # Create a column transformer pipeline ct_pipe = ColumnTransformer(transformers=[ ('hourly_cat', OneHotEncoder(categories=[range(0,24)], sparse = False), [col_index_dict['trip_start_hour']]), ('dow', OneHotEncoder(categories=[['Mon', 'Tue', 'Sun', 'Wed', 'Sat', 'Fri', 'Thu']], sparse = False), [col_index_dict['trip_start_day_of_week']]), ('std_scaler', StandardScaler(), [ col_index_dict['trip_start_year'], col_index_dict['abs_distance'], col_index_dict['pickup_longitude'], col_index_dict['pickup_latitude'], col_index_dict['dropoff_longitude'], col_index_dict['dropoff_latitude'], col_index_dict['trip_miles'], col_index_dict['trip_seconds']]) ]) # Add the random-forest estimator to the pipeline rfr_pipe = Pipeline([ ('ct', ct_pipe), ('forest_reg', RandomForestRegressor( n_estimators = 20, max_features = 1.0, n_jobs = -1, random_state = 3, max_depth=None, max_leaf_nodes=None, )) ]) # train the model rfr_score = cross_val_score(rfr_pipe, X_train, y_train, scoring = 'neg_mean_squared_error', cv = 5) rfr_rmse = np.sqrt(-rfr_score) print ("Crossvalidation RMSE:",rfr_rmse.mean()) final_model=rfr_pipe.fit(X_train, y_train) # Save the model pipeline with open(os.path.join(args.training_dir,"model.joblib"), 'wb') as model_file: pickle.dump(final_model, model_file)このコードは、次のタスクを実行します。
- 特徴を選択する。
- 乗車場所と降車場所の時刻を UTC からシカゴの現地時間に変換する。
- 乗車日時から日付、時間、曜日、月、年を抽出する。
- 開始時間と終了時間を使用してルートの所要時間を計算する。
- コミュニティ エリアに基づいて、空港を出発地または目的地とするルートを特定してマークする。
- ランダム フォレスト回帰モデルは、scikit-learn フレームワークを使用してタクシーの運賃を予測するようにトレーニングされます。
トレーニング済みのモデルは pickle ファイル
model.joblibに保存されます。選択したアプローチと特徴量エンジニアリングは、シカゴのタクシー運賃の予測のデータ探索と分析に基づいています。
[ファイル] パネルの training_package フォルダに
setup.pyというファイルを作成し、次の内容を記述します。from setuptools import find_packages from setuptools import setup REQUIRED_PACKAGES=["google-cloud-bigquery[pandas]","google-cloud-bigquery-storage"] setup( name='trainer', version='0.1', install_requires=REQUIRED_PACKAGES, packages=find_packages(), include_package_data=True, description='Training application package for chicago taxi trip fare prediction.' )ノートブックで
setup.pyを実行して、トレーニング アプリケーションのソース ディストリビューションを作成します。! cd training_package && python setup.py sdist --formats=gztar && cd ..
このセクションの最後の [ファイル] パネルには、training-package の下に次のファイルとフォルダが表示されています。
dist
trainer-0.1.tar.gz
trainer
__init__.py
task.py
trainer.egg-info
__init__.py
setup.py
カスタム トレーニング パッケージを Cloud Storage にアップロードする
Cloud Storage バケットを作成します。
REGION="REGION" BUCKET_NAME = "BUCKET_NAME" BUCKET_URI = f"gs://{BUCKET_NAME}" ! gcloud storage buckets create gs://$BUCKET_URI --location=$REGION --project=$PROJECT_ID次のパラメータ値を置き換えます。
REGION: Colab ノートブックの作成時に選択したリージョンを選択します。BUCKET_NAME: バケットの名前。
トレーニング パッケージを Cloud Storage バケットにアップロードします。
# Copy the training package to the bucket ! gcloud storage cp training_package/dist/trainer-0.1.tar.gz $BUCKET_URI/
パイプラインを構築する
パイプラインは、MLOps ワークフローをパイプライン タスクというステップのグラフとして記述したものです。
このセクションでは、パイプライン タスクを定義して YAML にコンパイルし、パイプラインを Artifact Registry に登録します。これにより、1 人または複数のユーザーがバージョン管理と実行を複数回行うことができます。
次の図は、パイプラインのタスク(モデルのトレーニング、モデルのアップロード、モデルの評価、メール通知など)を可視化したものです。
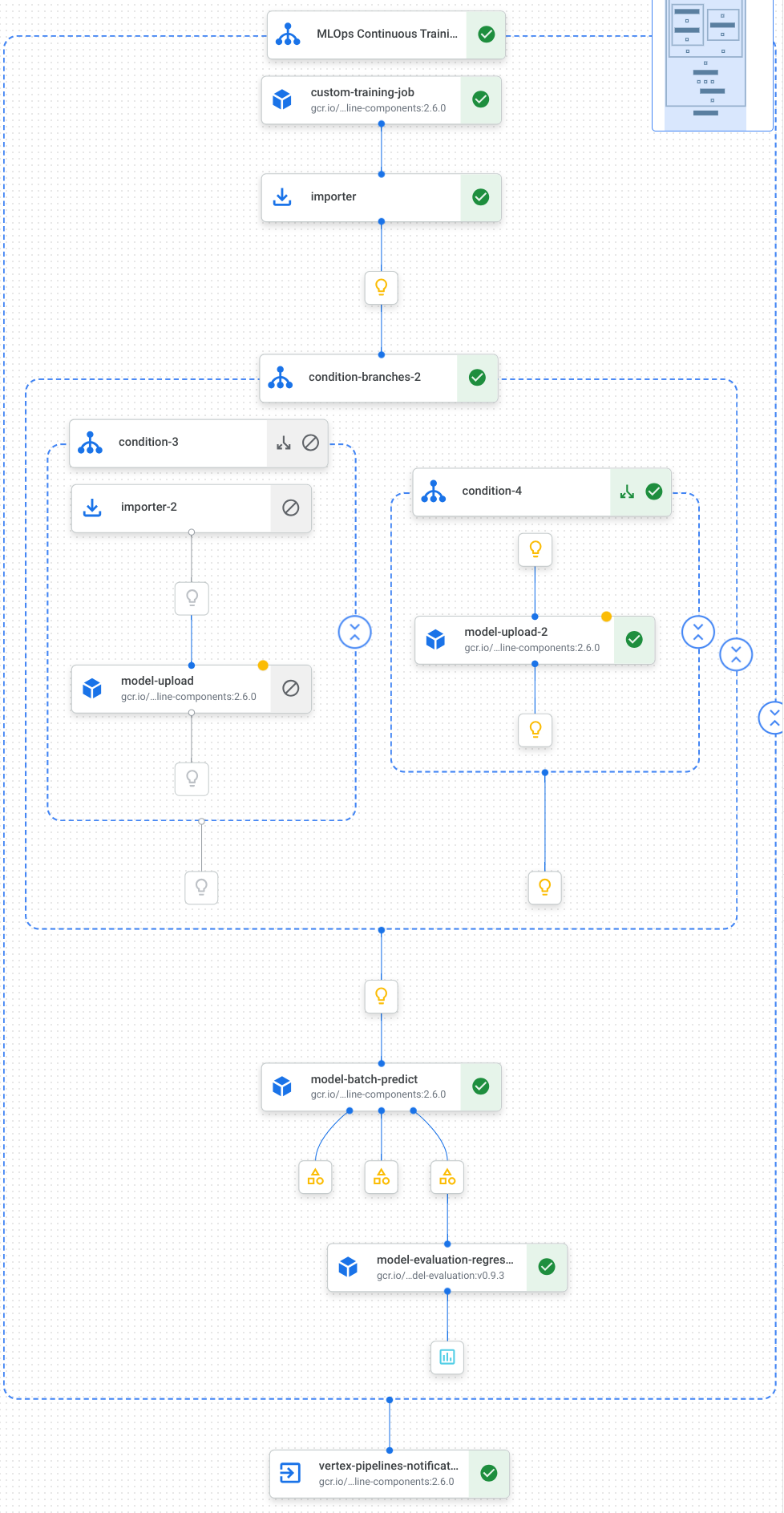
詳細については、パイプライン テンプレートの作成をご覧ください。
定数を定義してクライアントを初期化する
ノートブックで、後のステップで使用する定数を定義します。
import os EMAIL_RECIPIENTS = [ "NOTIFY_EMAIL" ] PIPELINE_ROOT = "{}/pipeline_root/chicago-taxi-pipe".format(BUCKET_URI) PIPELINE_NAME = "vertex-pipeline-datatrigger-tutorial" WORKING_DIR = f"{PIPELINE_ROOT}/mlops-datatrigger-tutorial" os.environ['AIP_MODEL_DIR'] = WORKING_DIR EXPERIMENT_NAME = PIPELINE_NAME + "-experiment" PIPELINE_FILE = PIPELINE_NAME + ".yaml"NOTIFY_EMAILは、メールアドレスに置き換えます。パイプライン ジョブが完了すると、結果の成否にかかわらず、このメールアドレスにメールが送信されます。プロジェクト、ステージング バケット、ロケーション、テストを使用して Vertex AI SDK を初期化します。
from google.cloud import aiplatform aiplatform.init( project=PROJECT_ID, staging_bucket=BUCKET_URI, location=REGION, experiment=EXPERIMENT_NAME) aiplatform.autolog()
パイプライン タスクを定義する
ノートブックで、パイプライン custom_model_training_evaluation_pipeline を定義します。
from kfp import dsl
from kfp.dsl import importer
from kfp.dsl import OneOf
from google_cloud_pipeline_components.v1.custom_job import CustomTrainingJobOp
from google_cloud_pipeline_components.types import artifact_types
from google_cloud_pipeline_components.v1.model import ModelUploadOp
from google_cloud_pipeline_components.v1.batch_predict_job import ModelBatchPredictOp
from google_cloud_pipeline_components.v1.model_evaluation import ModelEvaluationRegressionOp
from google_cloud_pipeline_components.v1.vertex_notification_email import VertexNotificationEmailOp
from google_cloud_pipeline_components.v1.endpoint import ModelDeployOp
from google_cloud_pipeline_components.v1.endpoint import EndpointCreateOp
from google.cloud import aiplatform
# define the train-deploy pipeline
@dsl.pipeline(name="custom-model-training-evaluation-pipeline")
def custom_model_training_evaluation_pipeline(
project: str,
location: str,
training_job_display_name: str,
worker_pool_specs: list,
base_output_dir: str,
prediction_container_uri: str,
model_display_name: str,
batch_prediction_job_display_name: str,
target_field_name: str,
test_data_gcs_uri: list,
ground_truth_gcs_source: list,
batch_predictions_gcs_prefix: str,
batch_predictions_input_format: str="csv",
batch_predictions_output_format: str="jsonl",
ground_truth_format: str="csv",
parent_model_resource_name: str=None,
parent_model_artifact_uri: str=None,
existing_model: bool=False
):
# Notification task
notify_task = VertexNotificationEmailOp(
recipients= EMAIL_RECIPIENTS
)
with dsl.ExitHandler(notify_task, name='MLOps Continuous Training Pipeline'):
# Train the model
custom_job_task = CustomTrainingJobOp(
project=project,
display_name=training_job_display_name,
worker_pool_specs=worker_pool_specs,
base_output_directory=base_output_dir,
location=location
)
# Import the unmanaged model
import_unmanaged_model_task = importer(
artifact_uri=base_output_dir,
artifact_class=artifact_types.UnmanagedContainerModel,
metadata={
"containerSpec": {
"imageUri": prediction_container_uri,
},
},
).after(custom_job_task)
with dsl.If(existing_model == True):
# Import the parent model to upload as a version
import_registry_model_task = importer(
artifact_uri=parent_model_artifact_uri,
artifact_class=artifact_types.VertexModel,
metadata={
"resourceName": parent_model_resource_name
},
).after(import_unmanaged_model_task)
# Upload the model as a version
model_version_upload_op = ModelUploadOp(
project=project,
location=location,
display_name=model_display_name,
parent_model=import_registry_model_task.outputs["artifact"],
unmanaged_container_model=import_unmanaged_model_task.outputs["artifact"],
)
with dsl.Else():
# Upload the model
model_upload_op = ModelUploadOp(
project=project,
location=location,
display_name=model_display_name,
unmanaged_container_model=import_unmanaged_model_task.outputs["artifact"],
)
# Get the model (or model version)
model_resource = OneOf(model_version_upload_op.outputs["model"], model_upload_op.outputs["model"])
# Batch prediction
batch_predict_task = ModelBatchPredictOp(
project= project,
job_display_name= batch_prediction_job_display_name,
model= model_resource,
location= location,
instances_format= batch_predictions_input_format,
predictions_format= batch_predictions_output_format,
gcs_source_uris= test_data_gcs_uri,
gcs_destination_output_uri_prefix= batch_predictions_gcs_prefix,
machine_type= 'n1-standard-2'
)
# Evaluation task
evaluation_task = ModelEvaluationRegressionOp(
project= project,
target_field_name= target_field_name,
location= location,
# model= model_resource,
predictions_format= batch_predictions_output_format,
predictions_gcs_source= batch_predict_task.outputs["gcs_output_directory"],
ground_truth_format= ground_truth_format,
ground_truth_gcs_source= ground_truth_gcs_source
)
return
パイプラインは、次の Google Cloud パイプライン コンポーネントを使用するタスクのグラフで構成されています。
CustomTrainingJobOp: Vertex AI でカスタム トレーニング ジョブを実行します。ModelUploadOp: トレーニング済みの ML モデルをモデル レジストリにアップロードします。ModelBatchPredictOp: バッチ予測ジョブを作成します。ModelEvaluationRegressionOp: 回帰バッチジョブを評価します。VertexNotificationEmailOp: メール通知を送信します。
パイプラインをコンパイルする
Kubeflow Pipelines(KFP)コンパイラを使用して、パイプラインの密閉表現を含む YAML ファイルにパイプラインをコンパイルします。
from kfp import dsl
from kfp import compiler
compiler.Compiler().compile(
pipeline_func=custom_model_training_evaluation_pipeline,
package_path="{}.yaml".format(PIPELINE_NAME),
)
作業ディレクトリに vertex-pipeline-datatrigger-tutorial.yaml という名前の YAML ファイルが表示されます。
パイプラインをテンプレートとしてアップロードする
Artifact Registry に
KFPタイプのリポジトリを作成します。REPO_NAME = "mlops" # Create a repo in the artifact registry ! gcloud artifacts repositories create $REPO_NAME --location=$REGION --repository-format=KFPコンパイルしたパイプラインをリポジトリにアップロードします。
from kfp.registry import RegistryClient host = f"https://{REGION}-kfp.pkg.dev/{PROJECT_ID}/{REPO_NAME}" client = RegistryClient(host=host) TEMPLATE_NAME, VERSION_NAME = client.upload_pipeline( file_name=PIPELINE_FILE, tags=["v1", "latest"], extra_headers={"description":"This is an example pipeline template."}) TEMPLATE_URI = f"https://{REGION}-kfp.pkg.dev/{PROJECT_ID}/{REPO_NAME}/{TEMPLATE_NAME}/latest"Google Cloud コンソールで、[Pipeline Templates] にテンプレートが表示されていることを確認します。
パイプラインを手動で実行する
パイプラインの動作を確認するには、パイプラインを手動で実行します。
ノートブックに、パイプラインをジョブとして実行するために必要なパラメータを指定します。
DATASET_NAME = "mlops" TABLE_NAME = "chicago" worker_pool_specs = [{ "machine_spec": {"machine_type": "e2-highmem-2"}, "replica_count": 1, "python_package_spec":{ "executor_image_uri": "us-docker.pkg.dev/vertex-ai/training/sklearn-cpu.1-0:latest", "package_uris": [f"{BUCKET_URI}/trainer-0.1.tar.gz"], "python_module": "trainer.task", "args":["--project-id",PROJECT_ID, "--training-dir",f"/gcs/{BUCKET_NAME}","--bq-source",f"{PROJECT_ID}.{DATASET_NAME}.{TABLE_NAME}"] }, }] parameters = { "project": PROJECT_ID, "location": REGION, "training_job_display_name": "taxifare-prediction-training-job", "worker_pool_specs": worker_pool_specs, "base_output_dir": BUCKET_URI, "prediction_container_uri": "us-docker.pkg.dev/vertex-ai/prediction/sklearn-cpu.1-0:latest", "model_display_name": "taxifare-prediction-model", "batch_prediction_job_display_name": "taxifare-prediction-batch-job", "target_field_name": "fare", "test_data_gcs_uri": [f"{BUCKET_URI}/test_no_target.csv"], "ground_truth_gcs_source": [f"{BUCKET_URI}/test.csv"], "batch_predictions_gcs_prefix": f"{BUCKET_URI}/batch_predict_output", "existing_model": False }パイプライン ジョブを作成して実行します。
# Create a pipeline job job = aiplatform.PipelineJob( display_name="triggered_custom_regression_evaluation", template_path=TEMPLATE_URI , parameter_values=parameters, pipeline_root=BUCKET_URI, enable_caching=False ) # Run the pipeline job job.run()ジョブが完了するまでに 30 分ほどかかります。
コンソールの [パイプライン] ページに、新しいパイプラインの実行が表示されます。
パイプラインの実行が完了すると、Vertex AI Model Registry に
taxifare-prediction-modelという名前の新しいモデルまたは新しいモデル バージョンが表示されます。新しいバッチ予測ジョブも表示されます。
パイプラインを自動的に実行する
パイプラインを自動的に実行する方法は 2 つあります。1 つは、スケジュールに基づいて実行する方法、もう 1 つはデータセットに新しいデータが挿入されたときに実行する方法です。
パイプラインをスケジュールで実行する
ノートブックで
PipelineJob.create_scheduleを呼び出します。job_schedule = job.create_schedule( display_name="mlops tutorial schedule", cron="0 0 1 * *", # max_concurrent_run_count=1, max_run_count=12, )cron式を使用して、毎月 1 日の午前 12 時(UTC)にジョブを実行するようにスケジュールします。このチュートリアルでは、複数のジョブを同時に実行しないため、
max_concurrent_run_countを 1 に設定します。Google Cloud コンソールで、[Pipelines Schedules] に
scheduleが表示されていることを確認します。
新しいデータがあるときにパイプラインを実行する
Eventarc トリガーを使用して関数を作成する
BigQuery テーブルに新しいデータが挿入されるたびにパイプラインを実行する Cloud Functions の関数(第 2 世代)を作成します。
具体的には、Eventarc を使用して、google.cloud.bigquery.v2.JobService.InsertJob イベントが発生するたびに関数をトリガーします。その後、この関数がパイプライン テンプレートを実行します。
詳細については、Eventarc トリガーとサポートされているイベントタイプをご覧ください。
Google Cloud コンソールで、Cloud Run functions に移動します。
[関数を作成] ボタンをクリックします。[構成] ページで次の操作を行います。
環境として [第 2 世代] を選択します。
[関数名] に mlops を使用します。
[リージョン] で、Cloud Storage バケットと Artifact Registry リポジトリに選択したリージョンを選択します。
[トリガー] で [その他のトリガー] を選択します。[Eventarc トリガー] ペインが開きます。
[トリガーのタイプ] で、[Google のソース] を選択します。
[イベント プロバイダ] で [BigQuery] を選択します。
[イベントタイプ] で [
google.cloud.bigquery.v2.JobService.InsertJob] を選択します。[リソース] で [特定のリソース] を選択し、BigQuery テーブルを指定します。
projects/PROJECT_ID/datasets/mlops/tables/chicago[リージョン] フィールドで、Eventarc トリガーのロケーションを選択します(該当する場合)。詳しくは、トリガーのロケーションをご覧ください。
[トリガーを保存] をクリックします。
サービス アカウントにロールを付与するように求められたら、[すべて付与] をクリックします。
[次へ] をクリックして [コード] ページに移動します。[コード] ページで、次の操作を行います。
[ランタイム] を python 3.12 に設定します。
[エントリ ポイント] を
mlops_entrypointに設定します。インライン エディタで
main.pyファイルを開き、次のように置き換えます。PROJECT_ID、REGION、BUCKET_NAMEは、前に使用した値に置き換えます。import json import functions_framework import requests import google.auth import google.auth.transport.requests # CloudEvent function to be triggered by an Eventarc Cloud Audit Logging trigger # Note: this is NOT designed for second-party (Cloud Audit Logs -> Pub/Sub) triggers! @functions_framework.cloud_event def mlops_entrypoint(cloudevent): # Print out the CloudEvent's (required) `type` property # See https://github.com/cloudevents/spec/blob/v1.0.1/spec.md#type print(f"Event type: {cloudevent['type']}") # Print out the CloudEvent's (optional) `subject` property # See https://github.com/cloudevents/spec/blob/v1.0.1/spec.md#subject if 'subject' in cloudevent: # CloudEvent objects don't support `get` operations. # Use the `in` operator to verify `subject` is present. print(f"Subject: {cloudevent['subject']}") # Print out details from the `protoPayload` # This field encapsulates a Cloud Audit Logging entry # See https://cloud.google.com/logging/docs/audit#audit_log_entry_structure payload = cloudevent.data.get("protoPayload") if payload: print(f"API method: {payload.get('methodName')}") print(f"Resource name: {payload.get('resourceName')}") print(f"Principal: {payload.get('authenticationInfo', dict()).get('principalEmail')}") row_count = payload.get('metadata', dict()).get('tableDataChange',dict()).get('insertedRowsCount') print(f"No. of rows: {row_count} !!") if row_count: if int(row_count) > 0: print ("Pipeline trigger Condition met !!") submit_pipeline_job() else: print ("No pipeline triggered !!!") def submit_pipeline_job(): PROJECT_ID = 'PROJECT_ID' REGION = 'REGION' BUCKET_NAME = "BUCKET_NAME" DATASET_NAME = "mlops" TABLE_NAME = "chicago" base_output_dir = BUCKET_NAME BUCKET_URI = "gs://{}".format(BUCKET_NAME) PIPELINE_ROOT = "{}/pipeline_root/chicago-taxi-pipe".format(BUCKET_URI) PIPELINE_NAME = "vertex-mlops-pipeline-tutorial" EXPERIMENT_NAME = PIPELINE_NAME + "-experiment" REPO_NAME ="mlops" TEMPLATE_NAME="custom-model-training-evaluation-pipeline" TRAINING_JOB_DISPLAY_NAME="taxifare-prediction-training-job" worker_pool_specs = [{ "machine_spec": {"machine_type": "e2-highmem-2"}, "replica_count": 1, "python_package_spec":{ "executor_image_uri": "us-docker.pkg.dev/vertex-ai/training/sklearn-cpu.1-0:latest", "package_uris": [f"{BUCKET_URI}/trainer-0.1.tar.gz"], "python_module": "trainer.task", "args":["--project-id",PROJECT_ID,"--training-dir",f"/gcs/{BUCKET_NAME}","--bq-source",f"{PROJECT_ID}.{DATASET_NAME}.{TABLE_NAME}"] }, }] parameters = { "project": PROJECT_ID, "location": REGION, "training_job_display_name": "taxifare-prediction-training-job", "worker_pool_specs": worker_pool_specs, "base_output_dir": BUCKET_URI, "prediction_container_uri": "us-docker.pkg.dev/vertex-ai/prediction/sklearn-cpu.1-0:latest", "model_display_name": "taxifare-prediction-model", "batch_prediction_job_display_name": "taxifare-prediction-batch-job", "target_field_name": "fare", "test_data_gcs_uri": [f"{BUCKET_URI}/test_no_target.csv"], "ground_truth_gcs_source": [f"{BUCKET_URI}/test.csv"], "batch_predictions_gcs_prefix": f"{BUCKET_URI}/batch_predict_output", "existing_model": False } TEMPLATE_URI = f"https://{REGION}-kfp.pkg.dev/{PROJECT_ID}/{REPO_NAME}/{TEMPLATE_NAME}/latest" print("TEMPLATE URI: ", TEMPLATE_URI) request_body = { "name": PIPELINE_NAME, "displayName": PIPELINE_NAME, "runtimeConfig":{ "gcsOutputDirectory": PIPELINE_ROOT, "parameterValues": parameters, }, "templateUri": TEMPLATE_URI } pipeline_url = "https://us-central1-aiplatform.googleapis.com/v1/projects/{}/locations/{}/pipelineJobs".format(PROJECT_ID, REGION) creds, project = google.auth.default() auth_req = google.auth.transport.requests.Request() creds.refresh(auth_req) headers = { 'Authorization': 'Bearer {}'.format(creds.token), 'Content-Type': 'application/json; charset=utf-8' } response = requests.request("POST", pipeline_url, headers=headers, data=json.dumps(request_body)) print(response.text)requirements.txtファイルを開き、内容を次のように置き換えます。requests==2.31.0 google-auth==2.25.1
[デプロイ] をクリックして Cloud Functions の関数をデプロイします。
データを挿入してパイプラインをトリガーする
Google Cloud コンソールで、[BigQuery Studio] に移動します。
[SQL クエリを作成] をクリックし、[ 実行] をクリックして、次の SQL クエリを実行します。
INSERT INTO `PROJECT_ID.mlops.chicago` ( WITH taxitrips AS ( SELECT trip_start_timestamp, trip_end_timestamp, trip_seconds, trip_miles, payment_type, pickup_longitude, pickup_latitude, dropoff_longitude, dropoff_latitude, tips, tolls, fare, pickup_community_area, dropoff_community_area, company, unique_key FROM `bigquery-public-data.chicago_taxi_trips.taxi_trips` WHERE pickup_longitude IS NOT NULL AND pickup_latitude IS NOT NULL AND dropoff_longitude IS NOT NULL AND dropoff_latitude IS NOT NULL AND trip_miles > 0 AND trip_seconds > 0 AND fare > 0 AND EXTRACT(YEAR FROM trip_start_timestamp) = 2022 ) SELECT trip_start_timestamp, EXTRACT(MONTH from trip_start_timestamp) as trip_month, EXTRACT(DAY from trip_start_timestamp) as trip_day, EXTRACT(DAYOFWEEK from trip_start_timestamp) as trip_day_of_week, EXTRACT(HOUR from trip_start_timestamp) as trip_hour, trip_seconds, trip_miles, payment_type, ST_AsText( ST_SnapToGrid(ST_GeogPoint(pickup_longitude, pickup_latitude), 0.1) ) AS pickup_grid, ST_AsText( ST_SnapToGrid(ST_GeogPoint(dropoff_longitude, dropoff_latitude), 0.1) ) AS dropoff_grid, ST_Distance( ST_GeogPoint(pickup_longitude, pickup_latitude), ST_GeogPoint(dropoff_longitude, dropoff_latitude) ) AS euclidean, CONCAT( ST_AsText(ST_SnapToGrid(ST_GeogPoint(pickup_longitude, pickup_latitude), 0.1)), ST_AsText(ST_SnapToGrid(ST_GeogPoint(dropoff_longitude, dropoff_latitude), 0.1)) ) AS loc_cross, IF((tips/fare >= 0.2), 1, 0) AS tip_bin, tips, tolls, fare, pickup_longitude, pickup_latitude, dropoff_longitude, dropoff_latitude, pickup_community_area, dropoff_community_area, company, unique_key, trip_end_timestamp FROM taxitrips LIMIT 1000000 )テーブルに新しい行を挿入する SQL クエリ。
イベントがトリガーされたかどうかを確認するには、関数のログで
pipeline trigger condition metを検索します。関数が正常にトリガーされると、Vertex AI Pipelines で新しいパイプラインが実行されます。パイプライン ジョブが完了するまでに 30 分ほどかかります。
クリーンアップ
このプロジェクトで使用しているすべての Google Cloud リソースをクリーンアップするには、チュートリアルで使用した Google Cloud プロジェクトを削除します。
それ以外の場合は、このチュートリアル用に作成した個々のリソースを削除できます。
次のようにモデルを削除します。
[Vertex AI] セクションで、[Model Registry] ページに移動します。
モデルの名前の横にある (アクション)メニューをクリックし、[モデルを削除] を選択します。
パイプライン実行を削除します。
[パイプラインの実行] ページに移動します。
各パイプライン実行の名前の横にある (アクション)メニューをクリックし、[パイプライン実行の削除] を選択します。
カスタム トレーニング ジョブを削除します。
各カスタム トレーニング ジョブの名前の横にある (アクション)メニューをクリックし、[Delete custom training job] を選択します。
次のようにバッチ予測ジョブを削除します。
バッチ予測ジョブの名前の横にある (アクション)メニューをクリックし、[バッチ予測ジョブを削除] を選択します。