Vertex AI の Ray クラスタには、自動スケーリングと手動スケーリングの 2 つのスケーリング オプションがあります。自動スケーリングを使用すると、Ray のタスクやアクターなどで必要なリソースに基づいて、クラスタがワーカーノードの数を自動的に調整できます。負荷の高いワークロードを実行していて、必要なリソースが不明な場合は、自動スケーリングをおすすめします。手動スケーリングでは、ノードをより細かく制御できます。
自動スケーリングはワークロードの費用を削減できますが、ノードの起動オーバーヘッドが増加し、構成が難しい場合があります。Ray を初めて使用する場合は、自動スケーリング以外のクラスタから始めて、手動スケーリング機能を使用します。
自動スケーリング
ワーカープールの最小レプリカ数(min_replica_count)と最大レプリカ数(max_replica_count)を指定することで、Ray クラスタの自動スケーリング機能を有効にできます。
次の点にご注意ください。
- すべてのワーカープールの自動スケーリング仕様を構成する必要があります。
- カスタムのアップスケーリングとダウンスケーリングの速度はサポートされていません。デフォルト値については、Ray のドキュメントのアップスケーリングとダウンスケーリングの速度をご覧ください。
ワーカープールの自動スケーリング仕様を設定する
Ray クラスタの自動スケーリング機能を有効にするには、 Google Cloud コンソールまたは Vertex AI SDK for Python を使用します。
Ray on Vertex AI SDK
from google.cloud import aiplatform import vertex_ray from vertex_ray import AutoscalingSpec autoscaling_spec = AutoscalingSpec( min_replica_count=1, max_replica_count=3, ) head_node_type = Resources( machine_type="n1-standard-16", node_count=1, ) worker_node_types = [Resources( machine_type="n1-standard-16", accelerator_type="NVIDIA_TESLA_T4", accelerator_count=1, autoscaling_spec=autoscaling_spec, )] # Create the Ray cluster on Vertex AI CLUSTER_RESOURCE_NAME = vertex_ray.create_ray_cluster( head_node_type=head_node_type, worker_node_types=worker_node_types, ... )
コンソール
OSS Ray のベスト プラクティスの推奨事項に従い、ヘッドノードでワークロードを実行しないように、Ray ヘッドノードで論理 CPU 数を 0 に設定します。
Google Cloud コンソールで、[Vertex AI での Ray] ページに移動します。
[クラスタを作成] をクリックして [クラスタの作成] パネルを開きます。
[クラスタの作成] パネルの各ステップで、デフォルトのクラスタ情報を確認または置き換えます。[続行] をクリックして、各手順を完了します。
- [名前とリージョン] で名前を指定し、クラスタのロケーションを選択します。
[コンピューティング設定] で、マシンタイプ、アクセラレータ タイプと数、ディスクタイプとサイズ、レプリカ数など、ヘッドノードの Ray クラスタの構成を指定します。必要に応じて、カスタム イメージ URI を追加してカスタム コンテナ イメージを指定し、デフォルトのコンテナ イメージでは提供されていない Python の依存関係を追加できます。カスタム イメージをご覧ください。
[詳細オプション] で、次の操作を行います。
- 独自の暗号鍵を指定します。
- カスタム サービス アカウントを指定します。
- トレーニング中にワークロードのリソース統計情報をモニタリングする必要がない場合は、指標の収集を無効にします。
自動スケーリング ワーカープールを含むクラスタを作成するには、ワーカープールの最大レプリカ数を指定します。
[作成] をクリックします。
手動スケーリング
Vertex AI の Ray クラスタでワークロードが増加または減少したときに、需要に合わせてレプリカの数を手動でスケーリングできます。たとえば、余分な容量がある場合は、ワーカープールをスケールダウンして費用を節約します。
VPC ピアリングの制限事項
クラスタをスケーリングする場合は、既存のワーカープール内のレプリカの数のみを変更できます。たとえば、クラスタからワーカープールを追加または削除したり、ワーカープールのマシンタイプを変更したりすることはできません。また、ワーカープールのレプリカ数を 1 より小さくすることはできません。
VPC ピアリング接続を使用してクラスタに接続する場合、ノードの最大数に制限があります。ノードの最大数は、クラスタの作成時にクラスタに存在したノードの数によって異なります。詳細については、ノードの最大数の計算をご覧ください。この最大数には、ワーカープールだけでなくヘッドノードも含まれます。デフォルトのネットワーク構成を使用する場合、クラスタを作成するで説明されている上限を超えるノード数を指定することはできません。
サブネット割り当てのベスト プラクティス
プライベート サービス アクセス(PSA)を使用して Ray on Vertex AI をデプロイする場合は、割り当てられた IP アドレス範囲が、クラスタがスケールアップする可能性のある最大ノード数を収容するのに十分な大きさで、連続していることを確認することが重要です。PSA 接続用に予約された IP 範囲が小さすぎるか、断片化していると、IP アドレスが枯渇し、デプロイが失敗する可能性があります。
代わりに、Private Service Connect インターフェースを使用して Ray on Vertex AI をデプロイすることをおすすめします。これにより、IP の使用量が /28 サブネットに削減されます。
プライベート サービス アクセスのモニタリング
ベスト プラクティスとして、Google Cloud の Network Intelligence Center 内の診断ツールである ネットワーク アナライザを使用します。このツールは、Virtual Private Cloud(VPC)ネットワークの構成を自動的にモニタリングし、構成ミスや最適でない設定を検出します。ネットワーク アナライザは継続的に動作し、テストを事前に実行して分析情報を生成します。これにより、サービス可用性に影響を与える前に、ネットワークの問題を特定、診断、解決できます。
ネットワーク アナライザは、プライベート サービス アクセス(PSA)に使用されるサブネットをモニタリングし、それらに関連する特定の分析情報を提供できます。これは、PSA を使用する Cloud SQL、Memorystore、Vertex AI などのサービスを管理するための重要な機能です。
ネットワーク アナライザが PSA サブネットをモニタリングする主な方法は、割り当てられた範囲の IP アドレス使用率に関する分析情報を提供することです。
PSA 範囲の使用率: ネットワーク アナライザは、PSA に割り振った専用の CIDR ブロック内の IP アドレスの割り振り率をアクティブに追跡します。これは、マネージド サービス(Vertex AI など)を作成すると、Google がサービス プロデューサー VPC とそのサブネットを作成し、割り当てられたブロックから IP 範囲を取得するためです。
事前対応アラート: PSA 割り振り範囲の IP アドレス使用率が特定のしきい値(75% など)を超えると、ネットワーク アナライザは警告分析情報を生成します。これにより、容量に関する潜在的な問題が事前に警告されるため、新しいサービス リソースで使用可能なアドレスがなくなる前に、割り当てられた IP 範囲を拡張できます。
プライベート サービス アクセス サブネットの更新
Ray on Vertex AI のデプロイの場合、PSA 接続に /16 または /17 の CIDR ブロックを割り当てることをおすすめします。これにより、大規模なスケーリングをサポートするのに十分な連続した IP アドレス ブロックが提供され、それぞれ最大 65,536 個または 32,768 個の一意の IP アドレスに対応できます。これにより、大規模な Ray クラスタでも IP アドレスの枯渇を防ぐことができます。
割り振られた IP アドレス空間が枯渇すると、 Google Cloud は次のエラーを返します。
サブネットワークを作成できませんでした。割り振られた IP 範囲に空きブロックが見つかりませんでした。
現在のサブネット範囲を拡大するか、将来の成長に対応できる範囲を割り当てることをおすすめします。
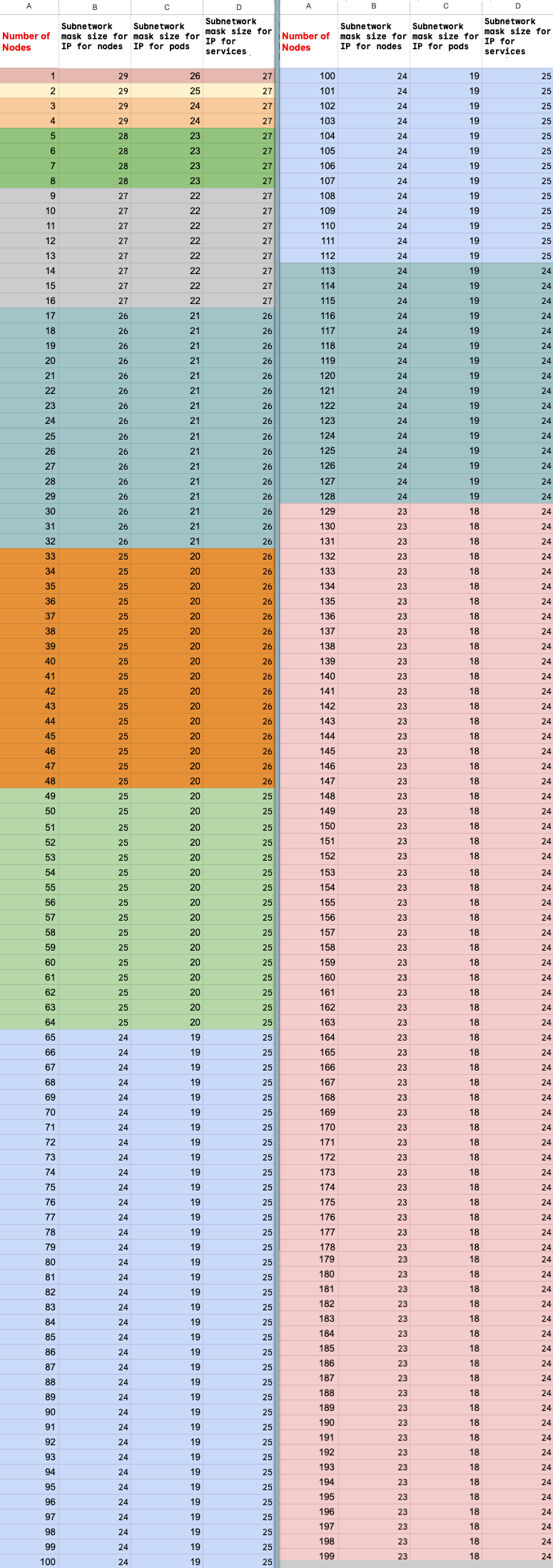
ノードの最大数の計算
プライベート サービス アクセス(VPC ピアリング)を使用してノードに接続する場合は、次の数式を使用して、ノードの最大数(M)を超えていないことを確認します。たとえば、f(x) = min(29, (32 -
ceiling(log2(x))) とします。
f(2 * M) = f(2 * N)f(64 * M) = f(64 * N)f(max(32, 16 + M)) = f(max(32, 16 + N))
スケールアップできる Ray on Vertex AI クラスタの最大合計ノード数(M)は、設定したノードの初期合計数(N)によって異なります。Ray on Vertex AI クラスタを作成したら、ノードの合計数を P から M までの任意の数にスケーリングできます。ここで、P はクラスタ内のプール数です。
クラスタ内の初期ノード数の合計とスケールアップ ターゲットの数は、同じカラーブロックにする必要があります。
レプリカ数を更新する
ワーカープールのレプリカ数を更新するには、 Google Cloud コンソールまたは Vertex AI SDK for Python を使用します。クラスタに複数のワーカープールが含まれている場合は、1 つのリクエストで各レプリカの数を個別に変更できます。
Ray on Vertex AI SDK
import vertexai import vertex_ray vertexai.init() cluster = vertex_ray.get_ray_cluster("CLUSTER_NAME") # Get the resource name. cluster_resource_name = cluster.cluster_resource_name # Create the new worker pools new_worker_node_types = [] for worker_node_type in cluster.worker_node_types: worker_node_type.node_count = REPLICA_COUNT # new worker pool size new_worker_node_types.append(worker_node_type) # Make update call updated_cluster_resource_name = vertex_ray.update_ray_cluster( cluster_resource_name=cluster_resource_name, worker_node_types=new_worker_node_types, )
コンソール
Google Cloud コンソールで、[Vertex AI での Ray] ページに移動します。
クラスタのリストで、変更するクラスタをクリックします。
[クラスタの詳細] ページで、[クラスタを編集] をクリックします。
[クラスタの編集] ペインで、更新するワーカープールを選択し、レプリカ数を変更します。
[更新] をクリックします。
クラスタが更新されるまで数分待ちます。更新が完了すると、[クラスタの詳細] ページに更新後のレプリカ数が表示されます。
[作成] をクリックします。