En esta página se describe cómo crear, gestionar e interpretar los resultados de las tareas de monitorización de modelos para modelos implementados en endpoints de predicción online. Vertex AI Model Monitoring admite la detección de sesgos y desviaciones de características de entrada categóricas y numéricas.
Cuando un modelo se despliega en producción con la monitorización de modelos habilitada, las solicitudes de predicción entrantes se registran en una tabla de BigQuery de tu Google Cloud proyecto. A continuación, se analizan los valores de las características de entrada incluidos en las solicitudes registradas para detectar sesgos o desviaciones.
Puedes habilitar la detección de sesgo si proporcionas el conjunto de datos de entrenamiento original de tu modelo. De lo contrario, debes habilitar la detección de deriva. Para obtener más información, consulta la introducción a Vertex AI Model Monitoring.
Requisitos previos
Para usar Model Monitoring, haz lo siguiente:
Tener un modelo disponible en Vertex AI que sea de tipo AutoML tabular o entrenamiento personalizado tabular importado.
- Si usas un endpoint, asegúrate de que todos los modelos implementados en él sean de AutoML tabular o de tipos de entrenamiento personalizados importados.
Si vas a habilitar la detección de sesgos, sube los datos de entrenamiento a Cloud Storage o BigQuery y obtén el enlace URI a los datos. Para la detección de la deriva, no es necesario usar datos de entrenamiento.
Opcional: En el caso de los modelos con entrenamiento personalizado, sube el esquema de la instancia de análisis de tu modelo a Cloud Storage. Para iniciar el proceso de monitorización y calcular la distribución de referencia para la detección de sesgos, Model Monitoring necesita el esquema. Si no proporcionas el esquema durante la creación del trabajo, este permanecerá en estado pendiente hasta que Monitorización de modelos pueda analizar automáticamente el esquema a partir de las primeras 1000 solicitudes de predicción que reciba el modelo.
Crear una tarea de monitorización de modelos
Para configurar la detección de sesgos o la detección de desviaciones, cree una tarea de monitorización de la implementación del modelo:
Consola
Para crear una tarea de monitorización de despliegue de modelos con la consola, Google Cloud crea un endpoint:
En la Google Cloud consola, ve a la página Endpoints de Vertex AI.
Haz clic en Crear punto de conexión.
En el panel Nuevo endpoint, asigna un nombre al endpoint y define una región.
Haz clic en Continuar.
En el campo Nombre del modelo, selecciona un modelo de entrenamiento personalizado importado o un modelo tabular de AutoML.
En el campo Versión, selecciona una versión para tu modelo.
Haz clic en Continuar.
En el panel Monitorización de modelos, comprueba que la opción Habilitar la monitorización de modelos en este endpoint esté activada. Los ajustes de monitorización que configures se aplicarán a todos los modelos desplegados en el endpoint.
Introduce un nombre visible de la tarea de monitorización.
Introduce la duración de la ventana de monitorización.
En Correos de notificación, introduzca una o varias direcciones de correo separadas por comas para recibir alertas cuando un modelo supere un umbral de alerta.
(Opcional) En Canales de notificación, añade canales de Cloud Monitoring para recibir alertas cuando un modelo supere un umbral de alerta. Puede seleccionar canales de Cloud Monitoring que ya tenga o crear uno haciendo clic en Gestionar canales de notificaciones. La consola admite canales de notificación de PagerDuty, Slack y Pub/Sub.
Introduzca una frecuencia de muestreo.
Opcional: Introduzca el esquema de entrada de la predicción y el esquema de entrada del análisis.
Haz clic en Continuar. Se abre el panel Objetivo de monitorización, con opciones para la detección de sesgo o deriva:
Detección de inclinación
- Selecciona Detección de sesgo entre entrenamiento y servicio.
- En Fuente de datos de entrenamiento, proporcione una fuente de datos de entrenamiento.
- En Columna de destino, introduzca el nombre de la columna de los datos de entrenamiento que el modelo debe predecir. Este campo se excluye del análisis de monitorización.
- Opcional: En Umbrales de alerta, especifica los umbrales en los que se activarán las alertas. Para obtener información sobre cómo dar formato a los umbrales, coloca el puntero sobre el icono de ayuda .
- Haz clic en Crear.
Detección de cambios
- Selecciona Detección de deriva de la predicción.
- Opcional: En Umbrales de alerta, especifica los umbrales en los que se activarán las alertas. Para obtener información sobre cómo dar formato a los umbrales, coloca el puntero sobre el icono de ayuda .
- Haz clic en Crear.
gcloud
Para crear un trabajo de monitorización de despliegue de modelos con la CLI de gcloud, primero despliega tu modelo en un endpoint:
Una configuración de tarea de monitorización se aplica a todos los modelos desplegados en un endpoint.
Ejecuta el comando gcloud ai model-monitoring-jobs create.
gcloud ai model-monitoring-jobs create \ --project=PROJECT_ID \ --region=REGION \ --display-name=MONITORING_JOB_NAME \ --emails=EMAIL_ADDRESS_1,EMAIL_ADDRESS_2 \ --endpoint=ENDPOINT_ID \ [--feature-thresholds=FEATURE_1=THRESHOLD_1, FEATURE_2=THRESHOLD_2] \ [--prediction-sampling-rate=SAMPLING_RATE] \ [--monitoring-frequency=MONITORING_FREQUENCY] \ [--analysis-instance-schema=ANALYSIS_INSTANCE_SCHEMA] \ --target-field=TARGET_FIELD \ --bigquery-uri=BIGQUERY_URI
donde:
PROJECT_ID es el ID de tu Google Cloud proyecto. Por ejemplo,
my-project.REGION es la ubicación de tu tarea de monitorización. Por ejemplo,
us-central1.MONITORING_JOB_NAME es el nombre de tu trabajo de monitorización. Por ejemplo,
my-job.EMAIL_ADDRESS es la dirección de correo a la que quieres recibir alertas de Monitorización de modelos. Por ejemplo,
example@example.com.ENDPOINT_ID es el ID del endpoint en el que se ha desplegado tu modelo. Por ejemplo,
1234567890987654321.Opcional: FEATURE_1=THRESHOLD_1 es el umbral de alerta de cada función que quieras monitorizar. Por ejemplo, si especifica
Age=0.4, Monitorización de modelos registra una alerta cuando la distancia estadística entre las distribuciones de entrada y de referencia de la funciónAgesupera 0,4. De forma predeterminada, se monitorizan todas las características categóricas y numéricas con valores de umbral de 0,3.Opcional: SAMPLING_RATE es la fracción de las solicitudes de predicción entrantes que quieres registrar. Por ejemplo,
0.5. Si no se especifica, Model Monitoring registra todas las solicitudes de predicción.Opcional: MONITORING_FREQUENCY es la frecuencia con la que quieres que se ejecute el trabajo de monitorización en las entradas registradas recientemente. La granularidad mínima es de 1 hora. El valor predeterminado es de 24 horas. Por ejemplo,
2.Opcional: ANALYSIS_INSTANCE_SCHEMA es el URI de Cloud Storage del archivo de esquema que describe el formato de los datos de entrada. Por ejemplo,
gs://test-bucket/schema.yaml.(obligatorio solo para la detección de sesgos) TARGET_FIELD es el campo que predice el modelo. Este campo se excluye del análisis de monitorización. Por ejemplo,
housing-price.(obligatorio solo para la detección de sesgos) BIGQUERY_URI es el enlace al conjunto de datos de entrenamiento almacenado en BigQuery, con el siguiente formato:
bq://\PROJECT.\DATASET.\TABLE
Por ejemplo,
bq://\my-project.\housing-data.\san-francisco.Puedes sustituir la marca
bigquery-uripor enlaces alternativos a tu conjunto de datos de entrenamiento:Para un archivo CSV almacenado en un segmento de Cloud Storage, usa
--data-format=csv --gcs-uris=gs://BUCKET_NAME/OBJECT_NAME.Para un archivo TFRecord almacenado en un segmento de Cloud Storage, usa
--data-format=tf-record --gcs-uris=gs://BUCKET_NAME/OBJECT_NAME.Para un conjunto de datos gestionado de AutoML tabular, usa
--dataset=DATASET_ID.
SDK de Python
Para obtener información sobre el flujo de trabajo completo de la API Model Monitoring, consulta el notebook de ejemplo.
API REST
Si aún no lo has hecho, implementa tu modelo en un endpoint. Durante el paso Obtener el ID del endpoint de las instrucciones de implementación del modelo, anota el valor de
deployedModels.iden la respuesta JSON para usarlo más adelante:Crea una solicitud de tarea de monitorización de modelos. Las instrucciones que se indican a continuación muestran cómo crear un trabajo de monitorización básico para la detección de desviaciones. Para personalizar la solicitud JSON, consulta la referencia de la tarea de monitorización.
Antes de usar los datos de la solicitud, haz las siguientes sustituciones:
- PROJECT_ID: es el ID de tu proyecto de Google Cloud . Por ejemplo,
my-project. - LOCATION: es la ubicación de tu trabajo de monitorización. Por ejemplo,
us-central1. - MONITORING_JOB_NAME es el nombre del trabajo de monitorización. Por ejemplo,
my-job. - PROJECT_NUMBER: es el número de tu proyecto Google Cloud . Por ejemplo,
1234567890. - ENDPOINT_ID es el ID del endpoint en el que se ha desplegado tu modelo. Por ejemplo,
1234567890. - DEPLOYED_MODEL_ID: es el ID del modelo implementado.
- FEATURE:VALUE es el umbral de alerta de cada función que quieras monitorizar. Por ejemplo, si especifica
"Age": {"value": 0.4}, Model Monitoring registra una alerta cuando la distancia estadística entre las distribuciones de entrada y de referencia de la funciónAgesupera 0,4. De forma predeterminada, se monitorizan todas las funciones categóricas y numéricas con valores de umbral de 0,3. - EMAIL_ADDRESS: es la dirección de correo a la que quieres recibir alertas de Monitorización de modelos. Por ejemplo,
example@example.com. - NOTIFICATION_CHANNELS:
una lista de canales de notificación de Cloud Monitoring
en los que quieras recibir alertas de Monitorización de modelos. Usa los nombres de los recursos de los canales de notificaciones, que puedes obtener consultando los canales de notificaciones de tu proyecto. Por ejemplo,
"projects/my-project/notificationChannels/1355376463305411567", "projects/my-project/notificationChannels/1355376463305411568". - Opcional: ANALYSIS_INSTANCE_SCHEMA es el URI de Cloud Storage del archivo de esquema que describe el formato de los datos de entrada. Por ejemplo,
gs://test-bucket/schema.yaml.
Cuerpo JSON de la solicitud:
{ "displayName":"MONITORING_JOB_NAME", "endpoint":"projects/PROJECT_NUMBER/locations/LOCATION/endpoints/ENDPOINT_ID", "modelDeploymentMonitoringObjectiveConfigs": { "deployedModelId": "DEPLOYED_MODEL_ID", "objectiveConfig": { "predictionDriftDetectionConfig": { "driftThresholds": { "FEATURE_1": { "value": VALUE_1 }, "FEATURE_2": { "value": VALUE_2 } } }, }, }, "loggingSamplingStrategy": { "randomSampleConfig": { "sampleRate": 0.5, }, }, "modelDeploymentMonitoringScheduleConfig": { "monitorInterval": { "seconds": 3600, }, }, "modelMonitoringAlertConfig": { "emailAlertConfig": { "userEmails": ["EMAIL_ADDRESS"], }, "notificationChannels": [NOTIFICATION_CHANNELS] }, "analysisInstanceSchemaUri": ANALYSIS_INSTANCE_SCHEMA }Para enviar tu solicitud, despliega una de estas opciones:
Deberías recibir una respuesta JSON similar a la siguiente:
{ "name": "projects/PROJECT_NUMBER/locations/LOCATION/modelDeploymentMonitoringJobs/MONITORING_JOB_NUMBER", ... "state": "JOB_STATE_PENDING", "scheduleState": "OFFLINE", ... "bigqueryTables": [ { "logSource": "SERVING", "logType": "PREDICT", "bigqueryTablePath": "bq://PROJECT_ID.model_deployment_monitoring_8451189418714202112.serving_predict" } ], ... }- PROJECT_ID: es el ID de tu proyecto de Google Cloud . Por ejemplo,
Una vez creada la tarea de monitorización, Model Monitoring registra las solicitudes de predicción entrantes en una tabla de BigQuery generada llamada PROJECT_ID.model_deployment_monitoring_ENDPOINT_ID.serving_predict.
Si el registro de solicitudes y respuestas está habilitado, Model Monitoring registra las solicitudes entrantes en la misma tabla de BigQuery que se usa para el registro de solicitudes y respuestas.
(Opcional) Configurar alertas para la tarea de monitorización del modelo
Puedes monitorizar y depurar tu trabajo de monitorización de modelos mediante alertas. Model Monitoring te notifica automáticamente las actualizaciones de los trabajos por correo electrónico, pero también puedes configurar alertas a través de los canales de notificaciones de Cloud Logging y Cloud Monitoring.
Correo electrónico
En los siguientes eventos, Monitorización de modelos envía una notificación por correo a cada dirección de correo que hayas especificado al crear el trabajo de Monitorización de modelos:
- Cada vez que se configura la detección de desfase o deriva.
- Cada vez que se actualiza una configuración de trabajo de monitorización de modelos.
- Cada vez que falla una ejecución de una canalización de monitorización programada.
Cloud Logging
Para habilitar los registros de las ejecuciones de la canalización de monitorización programada, asigna el valor true al campo enableMonitoringPipelineLogs de la configuración modelDeploymentMonitoringJobs. Los registros de depuración se escriben en Cloud Logging cuando se configura el trabajo de monitorización y en cada intervalo de monitorización.
Los registros de depuración se escriben en Cloud Logging con el nombre de registro:
model_monitoring. Por ejemplo:
logName="projects/model-monitoring-demo/logs/aiplatform.googleapis.com%2Fmodel_monitoring" resource.labels.model_deployment_monitoring_job=6680511704087920640
A continuación, se muestra un ejemplo de una entrada de registro de progreso de un trabajo:
{ "insertId": "e2032791-acb9-4d0f-ac73-89a38788ccf3@a1", "jsonPayload": { "@type": "type.googleapis.com/google.cloud.aiplatform.logging.ModelMonitoringPipelineLogEntry", "statusCode": { "message": "Scheduled model monitoring pipeline finished successfully for job projects/677687165274/locations/us-central1/modelDeploymentMonitoringJobs/6680511704087920640" }, "modelDeploymentMonitoringJob": "projects/677687165274/locations/us-central1/modelDeploymentMonitoringJobs/6680511704087920640" }, "resource": { "type": "aiplatform.googleapis.com/ModelDeploymentMonitoringJob", "labels": { "model_deployment_monitoring_job": "6680511704087920640", "location": "us-central1", "resource_container": "projects/677687165274" } }, "timestamp": "2022-02-04T15:33:54.778883Z", "severity": "INFO", "logName": "projects/model-monitoring-demo/logs/staging-aiplatform.sandbox.googleapis.com%2Fmodel_monitoring", "receiveTimestamp": "2022-02-04T15:33:56.343298321Z" }
Canales de notificación
Cada vez que falla una ejecución de una canalización de monitorización programada, Model Monitoring envía una notificación a los canales de notificación de Cloud Monitoring que especificaste al crear la tarea de Model Monitoring.
Configurar alertas de anomalías de funciones
Monitorización de modelos detecta una anomalía cuando se supera el umbral establecido para una función. Monitorización de modelos te notifica automáticamente las anomalías detectadas por correo electrónico, pero también puedes configurar alertas a través de los canales de notificación de Cloud Logging y Cloud Monitoring.
Correo electrónico
En cada intervalo de monitorización, si el umbral de al menos una característica supera el umbral, Monitorización de modelos envía una alerta por correo a cada dirección de correo que hayas especificado al crear el trabajo de Monitorización de modelos. El mensaje de correo incluye lo siguiente:
- La hora a la que se ejecutó la tarea de monitorización.
- Nombre de la función que tiene sesgo o deriva.
- El umbral de alerta y la medida de distancia estadística registrada.
Cloud Logging
Para habilitar las alertas de Cloud Logging, asigna el valor enableLogging al campo ModelMonitoringAlertConfig
de tu configuración true.
En cada intervalo de monitorización, se escribe un registro de anomalías en Cloud Logging si la distribución de al menos una característica supera el umbral de esa característica. Puede reenviar registros a cualquier servicio compatible con Cloud Logging, como Pub/Sub.
Las anomalías se escriben en Cloud Logging con el nombre de registro:
model_monitoring_anomaly. Por ejemplo:
logName="projects/model-monitoring-demo/logs/aiplatform.googleapis.com%2Fmodel_monitoring_anomaly" resource.labels.model_deployment_monitoring_job=6680511704087920640
Aquí tienes un ejemplo de una entrada de registro de anomalías:
{ "insertId": "b0e9c0e9-0979-4aff-a5d3-4c0912469f9a@a1", "jsonPayload": { "anomalyObjective": "RAW_FEATURE_SKEW", "endTime": "2022-02-03T19:00:00Z", "featureAnomalies": [ { "featureDisplayName": "age", "deviation": 0.9, "threshold": 0.7 }, { "featureDisplayName": "education", "deviation": 0.6, "threshold": 0.3 } ], "totalAnomaliesCount": 2, "@type": "type.googleapis.com/google.cloud.aiplatform.logging.ModelMonitoringAnomaliesLogEntry", "startTime": "2022-02-03T18:00:00Z", "modelDeploymentMonitoringJob": "projects/677687165274/locations/us-central1/modelDeploymentMonitoringJobs/6680511704087920640", "deployedModelId": "1645828169292316672" }, "resource": { "type": "aiplatform.googleapis.com/ModelDeploymentMonitoringJob", "labels": { "model_deployment_monitoring_job": "6680511704087920640", "location": "us-central1", "resource_container": "projects/677687165274" } }, "timestamp": "2022-02-03T19:00:00Z", "severity": "WARNING", "logName": "projects/model-monitoring-demo/logs/staging-aiplatform.sandbox.googleapis.com%2Fmodel_monitoring_anomaly", "receiveTimestamp": "2022-02-03T19:59:52.121398388Z" }
Canales de notificación
En cada intervalo de monitorización, si el umbral de al menos una característica supera el umbral, Model Monitoring envía una alerta a los canales de notificación de Cloud Monitoring que hayas especificado al crear la tarea de Model Monitoring. La alerta incluye información sobre el trabajo de monitorización de modelos que la ha activado.
Actualizar un trabajo de monitorización de modelos
Puedes ver, actualizar, pausar y eliminar un trabajo de monitorización de modelos. Debes pausar un trabajo para poder eliminarlo.
Consola
No se puede pausar ni eliminar en la consola de Google Cloud . En su lugar, usa la CLI de gcloud.
Para actualizar los parámetros de una tarea de monitorización de modelos, sigue estos pasos:
En la Google Cloud consola, ve a la página Endpoints de Vertex AI.
Haz clic en el nombre del endpoint que quieras editar.
Haz clic en Editar configuración.
En el panel Editar endpoint, selecciona Monitorización de modelos u Objetivos de monitorización.
Actualiza los campos que quieras cambiar.
Haz clic en Actualizar.
Para ver las métricas, las alertas y las propiedades de monitorización de un modelo, sigue estos pasos:
En la Google Cloud consola, ve a la página Endpoints de Vertex AI.
Haz clic en el nombre del endpoint.
En la columna Monitorización del modelo que quiera ver, haga clic en Habilitado.
gcloud
Ejecuta el siguiente comando:
gcloud ai model-monitoring-jobs COMMAND MONITORING_JOB_ID \ --PARAMETER=VALUE --project=PROJECT_ID --region=LOCATION
donde:
COMMAND es el comando que quieres ejecutar en el trabajo de monitorización. Por ejemplo,
update,pause,resumeodelete. Para obtener más información, consulta la referencia de la CLI de gcloud.MONITORING_JOB_ID es el ID de tu trabajo de monitorización. Por ejemplo,
123456789. Para encontrar el ID, [recupere la información del endpoint][retrieve-id] o consulte las propiedades de monitorización de un modelo en la consola de Google Cloud . El ID se incluye en el nombre del recurso de trabajo de monitorización con el formatoprojects/PROJECT_NUMBER/locations/LOCATION/modelDeploymentMonitoringJobs/MONITORING_JOB_ID.(Opcional) PARAMETER=VALUE es el parámetro que quieres actualizar. Esta marca solo es obligatoria cuando se usa el comando
update. Por ejemplo,monitoring-frequency=2. Para ver una lista de los parámetros que puedes actualizar, consulta la referencia de la CLI de gcloud.PROJECT_ID es el ID de tu Google Cloud proyecto. Por ejemplo,
my-project.LOCATION es la ubicación de tu tarea de monitorización. Por ejemplo,
us-central1.
API REST
Pausar una tarea
Antes de usar los datos de la solicitud, haz las siguientes sustituciones:
- PROJECT_NUMBER: el número de tu Google Cloud proyecto. Por ejemplo,
1234567890. - LOCATION: ubicación del trabajo de monitorización. Por ejemplo,
us-central1. - MONITORING_JOB_ID: ID de tu trabajo de monitorización. Por ejemplo,
0987654321.
Para enviar tu solicitud, despliega una de estas opciones:
Deberías recibir una respuesta JSON similar a la siguiente:
{}
Eliminar una tarea
Antes de usar los datos de la solicitud, haz las siguientes sustituciones:
- PROJECT_NUMBER: el número de tu Google Cloud proyecto. Por ejemplo,
my-project. - LOCATION: ubicación del trabajo de monitorización. Por ejemplo,
us-central1. - MONITORING_JOB_ID: ID de tu trabajo de monitorización. Por ejemplo,
0987654321.
Para enviar tu solicitud, despliega una de estas opciones:
Deberías recibir una respuesta JSON similar a la siguiente:
{
"name": "projects/PROJECT_NUMBER/locations/LOCATION/operations/MONITORING_JOB_ID",
...
"done": true,
...
}
Analizar los datos de sesgo y deriva
Puedes usar la Google Cloud consola para visualizar las distribuciones de cada función monitorizada y saber qué cambios han provocado sesgos o desviaciones a lo largo del tiempo. Puedes ver las distribuciones de los valores de las características como un histograma.
Consola
Para ir a los histogramas de distribución de funciones en la Google Cloud consola, ve a la página Endpoints (Endpoints).
En la página Puntos de conexión, haga clic en el punto de conexión que quiera analizar.
En la página de detalles del endpoint que has seleccionado, hay una lista de todos los modelos implementados en ese endpoint. Haga clic en el nombre de un modelo para analizarlo.
En la página de detalles del modelo se muestran las funciones de entrada del modelo, así como información pertinente, como el umbral de alerta de cada función y el número de alertas anteriores de la función.
Para analizar una función, haga clic en su nombre. En una página se muestran los histogramas de distribución de las funciones de esa característica.
En cada función monitorizada, puede ver las distribuciones de las 50 tareas de monitorización más recientes en la consola Google Cloud . Para detectar sesgos, la distribución de los datos de entrenamiento se muestra justo al lado de la distribución de los datos de entrada:
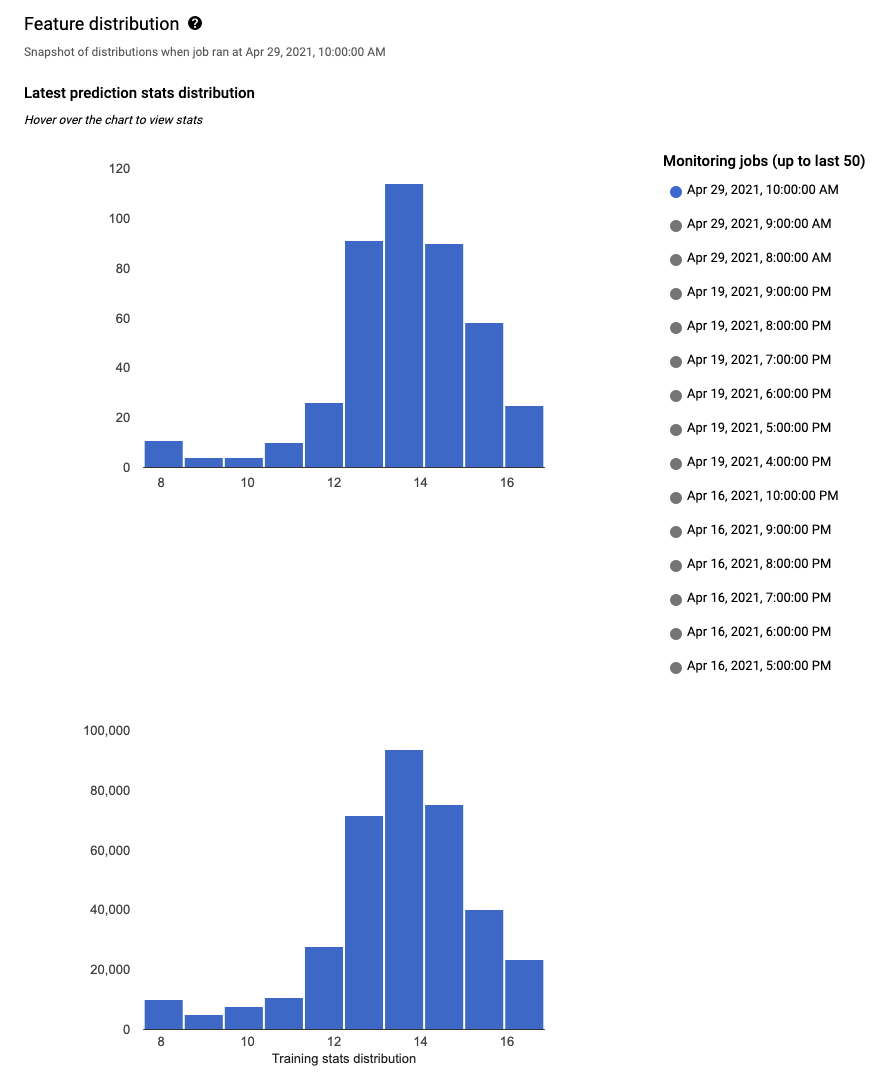
Visualizar la distribución de datos en forma de histogramas le permite centrarse rápidamente en los cambios que se han producido en los datos. Después, puedes decidir si quieres ajustar tu flujo de trabajo de generación de funciones o volver a entrenar el modelo.
Siguientes pasos
- Trabaja con Monitorización de modelos siguiendo la documentación de la API.
- Trabaja con la monitorización de modelos siguiendo la documentación de la CLI de gcloud.
- Prueba el cuaderno de ejemplo en Colab o consúltalo en GitHub.
- Consulta cómo calcula Monitorización de modelos la desviación entre el entrenamiento y el servicio, y la deriva de las predicciones.