En Vector Search, puedes restringir las búsquedas de coincidencia de vectores a un subconjunto del índice mediante reglas booleanas. Los predicados booleanos le indican a Vector Search qué vectores del índice debe ignorar. En esta página, aprenderás cómo funciona el filtrado, verás ejemplos y formas de consultar de manera eficiente tus datos según la similitud vectorial.
Con Vector Search, puedes restringir los resultados mediante restricciones categóricas y numéricas. Agregar restricciones o “filtrar” los resultados de índice es útil por varias razones, como los siguientes ejemplos:
Relevancia de resultados mejorada: La Búsqueda de Vectores es una herramienta potente para encontrar elementos semánticamente similares. El filtrado se puede usar para quitar resultados irrelevantes de los resultados de la búsqueda, como elementos que no están en el idioma, la categoría, el precio o el período correctos.
Cantidad reducida de resultados: La Búsqueda vectorial puede mostrar una gran cantidad de resultados, en especial para conjuntos de datos grandes. El filtrado se puede usar para reducir la cantidad de resultados a un número más administrable y, a la vez, mostrar los resultados más relevantes.
Resultados segmentados: El filtrado se puede usar para personalizar los resultados de la búsqueda según las necesidades y las preferencias individuales del usuario. Por ejemplo, es posible que un usuario desee filtrar los resultados para incluir solo los elementos que calificó con anterioridad o que se encuentren en un rango de precios específico.
Atributos vectoriales
En una búsqueda de similitud de vectores basada en una base de datos de vectores, cada vector se describe mediante cero o más atributos. Estos atributos se conocen como tokens para restricciones de token y valores para restricciones numéricas. Estas restricciones se pueden aplicar a cada una de las categorías de atributos, también conocidas como espacios de nombres.
En la siguiente aplicación de ejemplo, los vectores se etiquetan con un color, un price y un shape:
color,priceyshapeson espacios de nombres.redyblueson tokens del espacio de nombrescolor.squareycircleson tokens del espacio de nombresshape.100y50son valores del espacio de nombresprice.
Especifica atributos vectoriales
- Para especificar un “círculo rojo”, usa
{color: red}, {shape: circle}. - Para especificar un "cuadrado rojo y azul", usa
{color: red, blue}, {shape: square}. - Para especificar un objeto sin color, omite el espacio de nombres “color” en el campo
restricts. - A fin de especificar restricciones numéricas para un objeto, toma nota del espacio de nombres y el valor en el campo adecuado del tipo. El valor de número entero debe especificarse en
value_int, el valor de número de punto flotante se debe especificar envalue_floaty el valor de doble valor debe especificarse envalue_double. Solo se debe usar un tipo de número para un espacio de nombres determinado.
Si deseas obtener información sobre el esquema que se usa para especificar estos datos, consulta Especifica los espacios de nombres y tokens en los datos de entrada.
Consultas
- Las consultas expresan un operador lógico AND entre los espacios de nombres y un operador lógico OR dentro de cada espacio de nombres. Una consulta que especifica
{color: red, blue}, {shape: square, circle}coincide con todos los puntos de base de datos que satisfacen(red || blue) && (square || circle). - Una consulta que especifica
{color: red}, coincide con todos los objetosredde cualquier tipo, sin restricciones enshape. - Las restricciones numéricas en las consultas requieren
namespace, uno de los valores numéricos devalue_int,value_floatyvalue_double, y el operadorop. - El operador
opes uno deLESS,LESS_EQUAL,EQUAL,GREATER_EQUALyGREATER. Por ejemplo, si se usa el operadorLESS_EQUAL, los datos son aptos si su valor es más pequeño o igual que el valor que se usa en la consulta.
En los siguientes ejemplos de código se identifican atributos de vector en la aplicación de ejemplo:
{
namespace: "price"
value_int: 20
op: LESS
}
{
namespace: "length"
value_float: 0.3
op: GREATER_EQUAL
}
{
namespace: "width"
value_double: 0.5
op: EQUAL
}
Lista de bloqueo
Para habilitar situaciones más avanzadas, Google admite una forma de negación conocida como tokens de lista de bloqueo. Cuando una consulta incluye un token de la lista de bloqueo, se excluyen las coincidencias de cualquier dato que tenga este token. Si un espacio de nombres de consulta solo tiene tokens de lista de bloqueo, todos los puntos que no se encuentran en la lista de bloqueo de forma explícita, coinciden de la misma manera que un espacio de nombres vacío coincide con todos los puntos.
Los puntos de datos también pueden incluir en la lista de bloqueo un token, sin incluir las coincidencias con cualquier consulta que especifique ese token.
Por ejemplo, define los siguientes datos con los tokens especificados:
A: {} // empty set matches everything
B: {red} // only a 'red' token
C: {blue} // only a 'blue' token
D: {orange} // only an 'orange' token
E: {red, blue} // multiple tokens
F: {red, !blue} // deny the 'blue' token
G: {red, blue, !blue} // An unlikely edge-case
H: {!blue} // deny-only (similar to empty-set)
El sistema se comporta de la siguiente manera:
- Los espacios de nombres de consulta vacíos son comodines para coincidir con todos. Por ejemplo, Q:
{}coincide con DB:{color:red}. Los espacios de nombres de puntos de datos vacíos no son comodines coincidentes. Por ejemplo, Q:
{color:red}no coincide con DB:{}.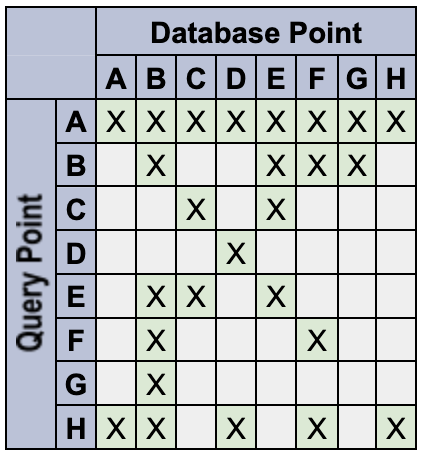
Especifica espacios de nombres y tokens o valores en los datos de entrada
Para obtener información sobre cómo estructurar tus datos de entrada de forma general, consulta Formato y estructura de los datos de entrada.
En las siguientes pestañas, se muestra cómo especificar los espacios de nombres y los tokens asociados con cada vector de entrada.
JSON
Para el registro de cada vector, agrega un campo llamado
restrictsa fin de que contenga un array de objetos, cada uno de los cuales es un espacio de nombres.- Cada objeto debe tener un campo llamado
namespace. Este campo es el espacio de nombresTokenNamespace.namespace. - El valor del campo
allow, si está presente, es un array de strings. Este array de strings es la listaTokenNamespace.string_tokens. - El valor del campo
deny, si está presente, es un array de strings. Este array de strings es la listaTokenNamespace.string_denylist_tokens.
- Cada objeto debe tener un campo llamado
Los siguientes son dos registros de ejemplo en formato JSON:
{"id": "42", "embedding": [0.5, 1.0], "restricts": [{"namespace": "class",
"allow": ["cat", "pet"]},{"namespace": "category", "allow": ["feline"]}]}
{"id": "43", "embedding": [0.6, 1.0], "restricts": [{"namespace":
"class", "allow": ["dog", "pet"]},{"namespace": "category", "allow":
["canine"]}]}
Para el registro de cada vector, agrega un campo llamado
numeric_restrictsa fin de que contenga un array de objetos, cada uno de los cuales es un número restringido.- Cada objeto debe tener un campo llamado
namespace. Este campo es el espacio de nombresNumericRestrictNamespace.namespace. - Cada objeto debe tener uno de los siguientes valores:
value_int,value_floatyvalue_double. - Cada objeto debe no tener un campo llamado
op. Este campo solo se usa para consultas.
- Cada objeto debe tener un campo llamado
Los siguientes son dos registros de ejemplo en formato JSON:
{"id": "42", "embedding": [0.5, 1.0], "numeric_restricts":
[{"namespace": "size", "value_int": 3},{"namespace": "ratio", "value_float": 0.1}]}
{"id": "43", "embedding": [0.6, 1.0], "numeric_restricts": [{"namespace":
"weight", "value_double": 0.3}]}
Avro
Los registros de Avro usan el siguiente esquema:
{
"type": "record",
"name": "FeatureVector",
"fields": [
{
"name": "id",
"type": "string"
},
{
"name": "embedding",
"type": {
"type": "array",
"items": "float"
}
},
{
"name": "restricts",
"type": [
"null",
{
"type": "array",
"items": {
"type": "record",
"name": "Restrict",
"fields": [
{
"name": "namespace",
"type": "string"
},
{
"name": "allow",
"type": [
"null",
{
"type": "array",
"items": "string"
}
]
},
{
"name": "deny",
"type": [
"null",
{
"type": "array",
"items": "string"
}
]
}
]
}
}
]
},
{
"name": "numeric_restricts",
"type": [
"null",
{
"type": "array",
"items": {
"name": "NumericRestrict",
"type": "record",
"fields": [
{
"name": "namespace",
"type": "string"
},
{
"name": "value_int",
"type": [ "null", "int" ],
"default": null
},
{
"name": "value_float",
"type": [ "null", "float" ],
"default": null
},
{
"name": "value_double",
"type": [ "null", "double" ],
"default": null
}
]
}
}
],
"default": null
},
{
"name": "crowding_tag",
"type": [
"null",
"string"
]
}
]
}
CSV
Restricciones de tokens
Para el registro de cada vector, agrega pares de formato
name=valueseparados por comas a fin de especificar restricciones de espacio de nombres de tokens. El mismo nombre se puede repetir si hay varios valores en un espacio de nombres.Por ejemplo,
color=red,color=bluerepresenta esteTokenNamespace:{ "namespace": "color" "string_tokens": ["red", "blue"] }Para el registro de cada vector, agrega pares de formato
name=!valueseparados por comas a fin de especificar el valor excluido de las restricciones de espacio de nombres del token.Por ejemplo,
color=!redrepresenta esteTokenNamespace:{ "namespace": "color" "string_blacklist_tokens": ["red"] }
Restricciones numéricas
Para el registro de cada vector, agrega pares de formato separados por comas
#name=numericValuecon sufijo de tipo numérico para especificar restricciones numéricas del espacios de nombres.El sufijo del tipo numérico es
ipara int,fpara número de punto flotante ydpara doble. El mismo nombre no se debe repetir, ya que debería haber un solo valor asociado por espacio de nombres.Por ejemplo,
#size=3irepresenta esteNumericRestrictNamespace:{ "namespace": "size" "value_int": 3 }#ratio=0.1frepresenta esteNumericRestrictNamespace:{ "namespace": "ratio" "value_float": 0.1 }#weight=0.3drepresenta esteNumericRestriction:{ "namespace": "weight" "value_double": 0.3 }
¿Qué sigue?
- Obtén información sobre cómo consultar tus índices para encontrar sus vecinos más cercanos.
- Obtén más información sobre cómo seleccionar, consultar y mostrar estas métricas en el Explorador de métricas.