Le inferenze batch sono richieste asincrone che richiedono inferenze direttamente dalla risorsa del modello senza la necessità di eseguire il deployment del modello in un endpoint.
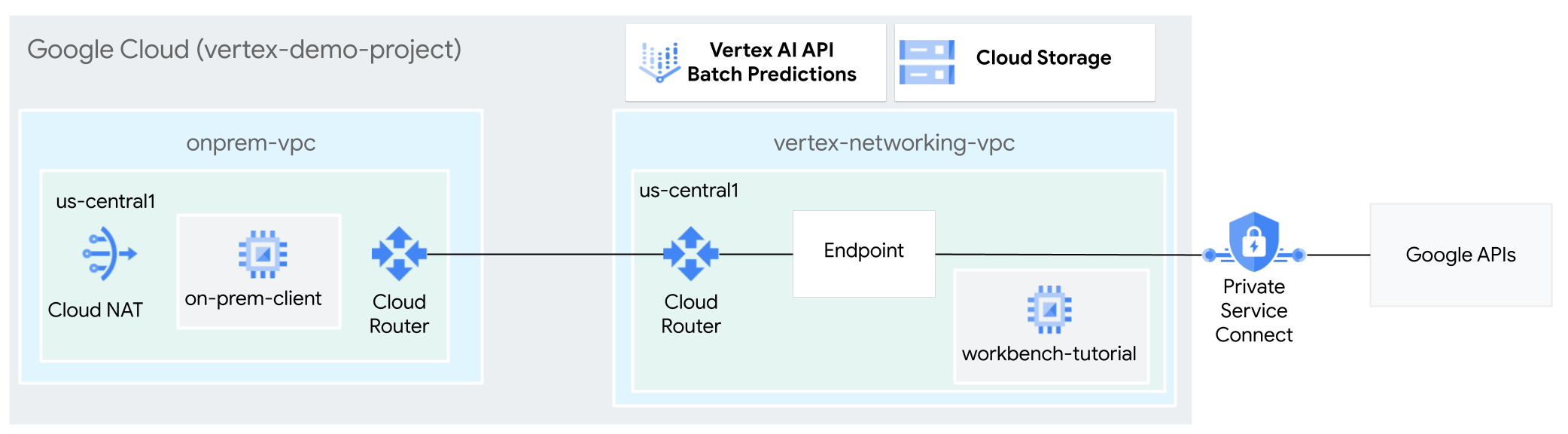
In questo tutorial, utilizzi la VPN ad alta disponibilità per inviare richieste di inferenza batch a un modello addestrato in modalità privata, tra due reti Virtual Private Cloud che possono fungere da base per la connettività privata multicloud e on-premise.
Questo tutorial è destinato ad amministratori di rete aziendali, data scientist e ricercatori che hanno familiarità con Vertex AI, Virtual Private Cloud (VPC), la console Google Cloud e Cloud Shell. La familiarità con Vertex AI Workbench è utile, ma non obbligatoria.
Crea le reti VPC
In questa sezione, crei due reti VPC: una per accedere alle API di Google per l'inferenza batch e l'altra per simulare una rete on-premise. In ciascuna delle due reti VPC, crei un router Cloud e un gateway Cloud NAT. Un gateway Cloud NAT fornisce connettività in uscita per le istanze di macchine virtuali (VM) Compute Engine senza indirizzi IP esterni.
Crea la rete VPC
vertex-networking-vpc:gcloud compute networks create vertex-networking-vpc \ --subnet-mode customNella rete
vertex-networking-vpc, crea una subnet denominataworkbench-subnet, con un intervallo IPv4 principale di10.0.1.0/28:gcloud compute networks subnets create workbench-subnet \ --range=10.0.1.0/28 \ --network=vertex-networking-vpc \ --region=us-central1 \ --enable-private-ip-google-accessCrea la rete VPC per simulare la rete on-premise (
onprem-vpc):gcloud compute networks create onprem-vpc \ --subnet-mode customNella rete
onprem-vpc, crea una subnet denominataonprem-vpc-subnet1, con un intervallo IPv4 principale di172.16.10.0/29:gcloud compute networks subnets create onprem-vpc-subnet1 \ --network onprem-vpc \ --range 172.16.10.0/29 \ --region us-central1
Verifica che le reti VPC siano configurate correttamente
Nella console Google Cloud , vai alla scheda Reti nel progetto attuale nella pagina Reti VPC.
Nell'elenco delle reti VPC, verifica che siano state create le due reti:
vertex-networking-vpceonprem-vpc.Fai clic sulla scheda Subnet nel progetto attuale.
Nell'elenco delle subnet VPC, verifica che siano state create le subnet
workbench-subneteonprem-vpc-subnet1.
Configura la connettività ibrida
In questa sezione crei due gateway VPN ad alta disponibilità connessi tra loro. Una si trova nella rete VPC vertex-networking-vpc. L'altro si trova nella rete VPC onprem-vpc. Ogni gateway contiene un router Cloud e una coppia di tunnel VPN.
Crea i gateway VPN ad alta disponibilità
In Cloud Shell, crea il gateway VPN ad alta disponibilità per la rete VPC
vertex-networking-vpc:gcloud compute vpn-gateways create vertex-networking-vpn-gw1 \ --network vertex-networking-vpc \ --region us-central1Crea il gateway VPN ad alta disponibilità per la rete VPC
onprem-vpc:gcloud compute vpn-gateways create onprem-vpn-gw1 \ --network onprem-vpc \ --region us-central1Nella console Google Cloud , vai alla scheda Gateway Cloud VPN nella pagina VPN.
Verifica che siano stati creati i due gateway (
vertex-networking-vpn-gw1eonprem-vpn-gw1) e che ognuno abbia due indirizzi IP di interfaccia.
Crea router Cloud e gateway Cloud NAT
In ciascuna delle due reti VPC, crei due router Cloud: uno generale e uno regionale. In ognuno dei router Cloud regionali, crei un gateway Cloud NAT. I gateway Cloud NAT forniscono connettività in uscita per le istanze di macchine virtuali (VM) Compute Engine che non dispongono di indirizzi IP esterni.
In Cloud Shell, crea un router Cloud per la rete VPC
vertex-networking-vpc:gcloud compute routers create vertex-networking-vpc-router1 \ --region us-central1\ --network vertex-networking-vpc \ --asn 65001Crea un router Cloud per la rete VPC
onprem-vpc:gcloud compute routers create onprem-vpc-router1 \ --region us-central1\ --network onprem-vpc\ --asn 65002Crea un router Cloud regionale per la rete VPC
vertex-networking-vpc:gcloud compute routers create cloud-router-us-central1-vertex-nat \ --network vertex-networking-vpc \ --region us-central1Configura un gateway Cloud NAT sul router Cloud regionale:
gcloud compute routers nats create cloud-nat-us-central1 \ --router=cloud-router-us-central1-vertex-nat \ --auto-allocate-nat-external-ips \ --nat-all-subnet-ip-ranges \ --region us-central1Crea un router Cloud regionale per la rete VPC
onprem-vpc:gcloud compute routers create cloud-router-us-central1-onprem-nat \ --network onprem-vpc \ --region us-central1Configura un gateway Cloud NAT sul router Cloud regionale:
gcloud compute routers nats create cloud-nat-us-central1-on-prem \ --router=cloud-router-us-central1-onprem-nat \ --auto-allocate-nat-external-ips \ --nat-all-subnet-ip-ranges \ --region us-central1Nella Google Cloud console, vai alla pagina Cloud Router.
Nell'elenco Router Cloud, verifica che siano stati creati i seguenti router:
cloud-router-us-central1-onprem-natcloud-router-us-central1-vertex-natonprem-vpc-router1vertex-networking-vpc-router1
Potresti dover aggiornare la scheda del browser della console Google Cloud per visualizzare i nuovi valori.
Nell'elenco dei router Cloud, fai clic su
cloud-router-us-central1-vertex-nat.Nella pagina Dettagli router, verifica che sia stato creato il gateway Cloud NAT
cloud-nat-us-central1.Fai clic sulla freccia indietro per tornare alla pagina Router Cloud.
Nell'elenco dei router, fai clic su
cloud-router-us-central1-onprem-nat.Nella pagina Dettagli router, verifica che sia stato creato il gateway Cloud NAT
cloud-nat-us-central1-on-prem.
Crea tunnel VPN
In Cloud Shell, nella rete
vertex-networking-vpc, crea un tunnel VPN denominatovertex-networking-vpc-tunnel0:gcloud compute vpn-tunnels create vertex-networking-vpc-tunnel0 \ --peer-gcp-gateway onprem-vpn-gw1 \ --region us-central1 \ --ike-version 2 \ --shared-secret [ZzTLxKL8fmRykwNDfCvEFIjmlYLhMucH] \ --router vertex-networking-vpc-router1 \ --vpn-gateway vertex-networking-vpn-gw1 \ --interface 0Nella rete
vertex-networking-vpc, crea un tunnel VPN denominatovertex-networking-vpc-tunnel1:gcloud compute vpn-tunnels create vertex-networking-vpc-tunnel1 \ --peer-gcp-gateway onprem-vpn-gw1 \ --region us-central1 \ --ike-version 2 \ --shared-secret [bcyPaboPl8fSkXRmvONGJzWTrc6tRqY5] \ --router vertex-networking-vpc-router1 \ --vpn-gateway vertex-networking-vpn-gw1 \ --interface 1Nella rete
onprem-vpc, crea un tunnel VPN denominatoonprem-vpc-tunnel0:gcloud compute vpn-tunnels create onprem-vpc-tunnel0 \ --peer-gcp-gateway vertex-networking-vpn-gw1 \ --region us-central1\ --ike-version 2 \ --shared-secret [ZzTLxKL8fmRykwNDfCvEFIjmlYLhMucH] \ --router onprem-vpc-router1 \ --vpn-gateway onprem-vpn-gw1 \ --interface 0Nella rete
onprem-vpc, crea un tunnel VPN denominatoonprem-vpc-tunnel1:gcloud compute vpn-tunnels create onprem-vpc-tunnel1 \ --peer-gcp-gateway vertex-networking-vpn-gw1 \ --region us-central1\ --ike-version 2 \ --shared-secret [bcyPaboPl8fSkXRmvONGJzWTrc6tRqY5] \ --router onprem-vpc-router1 \ --vpn-gateway onprem-vpn-gw1 \ --interface 1Nella console Google Cloud , vai alla pagina VPN.
Nell'elenco dei tunnel VPN, verifica che siano stati creati i quattro tunnel VPN.
Definizione di sessioni BGP
Router Cloud utilizza il protocollo BGP (Border Gateway Protocol) per scambiare le route tra la tua rete VPC (in questo caso, vertex-networking-vpc) e la tua rete on-premise (rappresentata da onprem-vpc). Su Cloud Router, configuri un'interfaccia e un peer BGP per il tuo router on-premise.
L'abbinamento dell'interfaccia e della configurazione peer BGP crea una sessione BGP.
In questa sezione creerai due sessioni BGP per vertex-networking-vpc e
due per onprem-vpc.
Una volta configurate le interfacce e i peer BGP tra i router, questi inizieranno automaticamente a scambiare le route.
Definisci sessioni BGP per vertex-networking-vpc
In Cloud Shell, nella rete
vertex-networking-vpc, crea un'interfaccia BGP pervertex-networking-vpc-tunnel0:gcloud compute routers add-interface vertex-networking-vpc-router1 \ --interface-name if-tunnel0-to-onprem \ --ip-address 169.254.0.1 \ --mask-length 30 \ --vpn-tunnel vertex-networking-vpc-tunnel0 \ --region us-central1Nella rete
vertex-networking-vpc, crea un peer BGP perbgp-onprem-tunnel0:gcloud compute routers add-bgp-peer vertex-networking-vpc-router1 \ --peer-name bgp-onprem-tunnel0 \ --interface if-tunnel0-to-onprem \ --peer-ip-address 169.254.0.2 \ --peer-asn 65002 \ --region us-central1Nella rete
vertex-networking-vpc, crea un'interfaccia BGP pervertex-networking-vpc-tunnel1:gcloud compute routers add-interface vertex-networking-vpc-router1 \ --interface-name if-tunnel1-to-onprem \ --ip-address 169.254.1.1 \ --mask-length 30 \ --vpn-tunnel vertex-networking-vpc-tunnel1 \ --region us-central1Nella rete
vertex-networking-vpc, crea un peer BGP perbgp-onprem-tunnel1:gcloud compute routers add-bgp-peer vertex-networking-vpc-router1 \ --peer-name bgp-onprem-tunnel1 \ --interface if-tunnel1-to-onprem \ --peer-ip-address 169.254.1.2 \ --peer-asn 65002 \ --region us-central1
Definisci sessioni BGP per onprem-vpc
Nella rete
onprem-vpc, crea un'interfaccia BGP peronprem-vpc-tunnel0:gcloud compute routers add-interface onprem-vpc-router1 \ --interface-name if-tunnel0-to-vertex-networking-vpc \ --ip-address 169.254.0.2 \ --mask-length 30 \ --vpn-tunnel onprem-vpc-tunnel0 \ --region us-central1Nella rete
onprem-vpc, crea un peer BGP perbgp-vertex-networking-vpc-tunnel0:gcloud compute routers add-bgp-peer onprem-vpc-router1 \ --peer-name bgp-vertex-networking-vpc-tunnel0 \ --interface if-tunnel0-to-vertex-networking-vpc \ --peer-ip-address 169.254.0.1 \ --peer-asn 65001 \ --region us-central1Nella rete
onprem-vpc, crea un'interfaccia BGP peronprem-vpc-tunnel1:gcloud compute routers add-interface onprem-vpc-router1 \ --interface-name if-tunnel1-to-vertex-networking-vpc \ --ip-address 169.254.1.2 \ --mask-length 30 \ --vpn-tunnel onprem-vpc-tunnel1 \ --region us-central1Nella rete
onprem-vpc, crea un peer BGP perbgp-vertex-networking-vpc-tunnel1:gcloud compute routers add-bgp-peer onprem-vpc-router1 \ --peer-name bgp-vertex-networking-vpc-tunnel1 \ --interface if-tunnel1-to-vertex-networking-vpc \ --peer-ip-address 169.254.1.1 \ --peer-asn 65001 \ --region us-central1
Convalida la creazione della sessione BGP
Nella console Google Cloud , vai alla pagina VPN.
Nell'elenco dei tunnel VPN, verifica che il valore nella colonna Stato sessione BGP per ciascun tunnel sia cambiato da Configura sessione BGP a BGP stabilito. Potresti dover aggiornare la scheda del browser della console Google Cloud per visualizzare i nuovi valori.
Convalida le route apprese vertex-networking-vpc
Nella console Google Cloud , vai alla pagina Reti VPC.
Nell'elenco delle reti VPC, fai clic su
vertex-networking-vpc.Fai clic sulla scheda Percorsi.
Seleziona us-central1 (Iowa) nell'elenco Regione e fai clic su Visualizza.
Nella colonna Intervallo IP di destinazione, verifica che l'intervallo IP della subnet
onprem-vpc-subnet1(172.16.10.0/29) venga visualizzato due volte.
Convalida le route apprese onprem-vpc
Fai clic sulla Freccia indietro per tornare alla pagina Reti VPC.
Nell'elenco delle reti VPC, fai clic su
onprem-vpc.Fai clic sulla scheda Percorsi.
Seleziona us-central1 (Iowa) nell'elenco Regione e fai clic su Visualizza.
Nella colonna Intervallo IP di destinazione, verifica che l'intervallo IP della subnet
workbench-subnet(10.0.1.0/28) venga visualizzato due volte.
Crea l'endpoint consumer Private Service Connect
In Cloud Shell, prenota un indirizzo IP endpoint consumer che verrà utilizzato per accedere alle API di Google:
gcloud compute addresses create psc-googleapi-ip \ --global \ --purpose=PRIVATE_SERVICE_CONNECT \ --addresses=192.168.0.1 \ --network=vertex-networking-vpcCrea una regola di forwarding per connettere l'endpoint alle API e ai servizi Google.
gcloud compute forwarding-rules create pscvertex \ --global \ --network=vertex-networking-vpc\ --address=psc-googleapi-ip \ --target-google-apis-bundle=all-apis
Crea route annunciate personalizzate per vertex-networking-vpc
In questa sezione, configura la modalità di annuncio personalizzato del router Cloud per Annuncia intervalli IP personalizzati per vertex-networking-vpc-router1 (il router Cloud per vertex-networking-vpc) per annunciare l'indirizzo IP dell'endpoint PSC alla rete onprem-vpc.
Nella Google Cloud console, vai alla pagina Cloud Router.
Nell'elenco dei router Cloud, fai clic su
vertex-networking-vpc-router1.Nella pagina Dettagli router, fai clic su Modifica.
Nella sezione Route pubblicizzate, per Route, seleziona Crea route personalizzate.
Seleziona la casella di controllo Annuncia tutte le subnet visibili al router Cloud per continuare ad annunciare le subnet disponibili per il router Cloud. L'attivazione di questa opzione simula il comportamento del router Cloud in modalità di pubblicità predefinita.
Fai clic su Aggiungi un percorso personalizzato.
In Origine, seleziona Intervallo IP personalizzato.
In Intervallo di indirizzi IP, inserisci il seguente indirizzo IP:
192.168.0.1Per Descrizione, inserisci il seguente testo:
Custom route to advertise Private Service Connect endpoint IP addressFai clic su Fine e poi su Salva.
Verifica che onprem-vpc abbia appreso le route annunciate
Nella console Google Cloud , vai alla pagina Route.
Nella scheda Route operative, procedi nel seguente modo:
- In Rete, scegli
onprem-vpc. - In Regione, scegli
us-central1 (Iowa). - Fai clic su Visualizza.
Nell'elenco delle route, verifica che siano presenti voci i cui nomi iniziano con
onprem-vpc-router1-bgp-vertex-networking-vpc-tunnel0eonprem-vpc-router1-bgp-vfertex-networking-vpc-tunnel1e che entrambe abbiano un intervallo IP di destinazione di192.168.0.1.Se queste voci non vengono visualizzate immediatamente, attendi qualche minuto, quindi aggiorna la scheda del browser della console Google Cloud .
- In Rete, scegli
Crea una VM in onprem-vpc che utilizza un account di servizio gestito dall'utente
In questa sezione, creerai un'istanza VM che simula un'applicazione client on-premise che invia richieste di inferenza batch. Seguendo le best practice di Compute Engine e IAM, questa VM utilizza un account di servizio gestito dall'utente anziché il service account predefinito di Compute Engine.
Crea un account di servizio gestito dall'utente
In Cloud Shell, esegui i seguenti comandi, sostituendo PROJECT_ID con il tuo ID progetto:
projectid=PROJECT_ID gcloud config set project ${projectid}Crea un account di servizio denominato
onprem-user-managed-sa:gcloud iam service-accounts create onprem-user-managed-sa \ --display-name="onprem-user-managed-sa-onprem-client"Assegna il ruolo Utente Vertex AI (
roles/aiplatform.user) al account di servizio:gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:onprem-user-managed-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/aiplatform.user"Assegna il ruolo Visualizzatore oggetti Storage (
storage.objectViewer) al account di servizio:gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:onprem-user-managed-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/storage.objectViewer"
Crea l'istanza VM on-prem-client
L'istanza VM che crei non ha un indirizzo IP esterno e non consente l'accesso diretto su internet. Per abilitare l'accesso amministrativo alla VM, utilizza l'inoltro TCP di Identity-Aware Proxy (IAP).
In Cloud Shell, crea l'istanza VM
on-prem-client:gcloud compute instances create on-prem-client \ --zone=us-central1-a \ --image-family=debian-11 \ --image-project=debian-cloud \ --subnet=onprem-vpc-subnet1 \ --scopes=https://www.googleapis.com/auth/cloud-platform \ --no-address \ --shielded-secure-boot \ --service-account=onprem-user-managed-sa@$projectid.iam.gserviceaccount.com \ --metadata startup-script="#! /bin/bash sudo apt-get update sudo apt-get install tcpdump dnsutils -y"Crea una regola firewall per consentire a IAP di connettersi alla tua istanza VM:
gcloud compute firewall-rules create ssh-iap-on-prem-vpc \ --network onprem-vpc \ --allow tcp:22 \ --source-ranges=35.235.240.0/20
Convalida l'accesso pubblico all'API Vertex AI
In questa sezione utilizzi l'utilità dig per eseguire una ricerca DNS dall'istanza VM on-prem-client all'API Vertex AI (us-central1-aiplatform.googleapis.com). L'output di dig mostra che l'accesso predefinito utilizza solo VIP pubblici per accedere all'API Vertex AI.
Nella sezione successiva, configurerai l'accesso privato all'API Vertex AI.
In Cloud Shell, accedi all'istanza VM
on-prem-clientutilizzando IAP:gcloud compute ssh on-prem-client \ --zone=us-central1-a \ --tunnel-through-iapNell'istanza VM
on-prem-client, esegui il comandodig:dig us-central1-aiplatform.googleapis.comDovresti vedere un output di
digsimile al seguente, in cui gli indirizzi IP nella sezione della risposta sono indirizzi IP pubblici:; <<>> DiG 9.16.44-Debian <<>> us-central1.aiplatfom.googleapis.com ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 42506 ;; flags: qr rd ra; QUERY: 1, ANSWER: 16, AUTHORITY: 0, ADDITIONAL: 1 ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags:; udp: 512 ;; QUESTION SECTION: ;us-central1.aiplatfom.googleapis.com. IN A ;; ANSWER SECTION: us-central1.aiplatfom.googleapis.com. 300 IN A 173.194.192.95 us-central1.aiplatfom.googleapis.com. 300 IN A 142.250.152.95 us-central1.aiplatfom.googleapis.com. 300 IN A 172.217.219.95 us-central1.aiplatfom.googleapis.com. 300 IN A 209.85.146.95 us-central1.aiplatfom.googleapis.com. 300 IN A 209.85.147.95 us-central1.aiplatfom.googleapis.com. 300 IN A 142.250.125.95 us-central1.aiplatfom.googleapis.com. 300 IN A 142.250.136.95 us-central1.aiplatfom.googleapis.com. 300 IN A 142.250.148.95 us-central1.aiplatfom.googleapis.com. 300 IN A 209.85.200.95 us-central1.aiplatfom.googleapis.com. 300 IN A 209.85.234.95 us-central1.aiplatfom.googleapis.com. 300 IN A 142.251.171.95 us-central1.aiplatfom.googleapis.com. 300 IN A 108.177.112.95 us-central1.aiplatfom.googleapis.com. 300 IN A 142.250.128.95 us-central1.aiplatfom.googleapis.com. 300 IN A 142.251.6.95 us-central1.aiplatfom.googleapis.com. 300 IN A 172.217.212.95 us-central1.aiplatfom.googleapis.com. 300 IN A 74.125.124.95 ;; Query time: 8 msec ;; SERVER: 169.254.169.254#53(169.254.169.254) ;; WHEN: Wed Sep 27 04:10:16 UTC 2023 ;; MSG SIZE rcvd: 321
Configura e convalida l'accesso privato all'API Vertex AI
In questa sezione configurerai l'accesso privato all'API Vertex AI in modo che quando invii richieste di inferenza batch, queste vengano reindirizzate al tuo endpoint PSC. L'endpoint PSC a sua volta inoltra queste richieste private all'API REST di Vertex AI batch inference.
Aggiorna il file /etc/hosts in modo che punti all'endpoint PSC
In questo passaggio, aggiungi una riga al file /etc/hosts che fa sì che le richieste
inviate all'endpoint del servizio pubblico (us-central1-aiplatform.googleapis.com)
vengano reindirizzate all'endpoint PSC (192.168.0.1).
Nell'istanza VM
on-prem-client, utilizza un editor di testo comevimonanoper aprire il file/etc/hosts:sudo vim /etc/hostsAggiungi la seguente riga al file:
192.168.0.1 us-central1-aiplatform.googleapis.comQuesta riga assegna l'indirizzo IP dell'endpoint PSC (
192.168.0.1) al nome di dominio completo per l'API Google Vertex AI (us-central1-aiplatform.googleapis.com).Il file modificato dovrebbe avere il seguente aspetto:
127.0.0.1 localhost ::1 localhost ip6-localhost ip6-loopback ff02::1 ip6-allnodes ff02::2 ip6-allrouters 192.168.0.1 us-central1-aiplatform.googleapis.com # Added by you 172.16.10.6 on-prem-client.us-central1-a.c.vertex-genai-400103.internal on-prem-client # Added by Google 169.254.169.254 metadata.google.internal # Added by GoogleSalva il file come segue:
- Se utilizzi
vim, premi il tastoEsc, quindi digita:wqper salvare il file e uscire. - Se utilizzi
nano, digitaControl+Oe premiEnterper salvare il file, quindi digitaControl+Xper uscire.
- Se utilizzi
Esegui il ping dell'endpoint Vertex AI come segue:
ping us-central1-aiplatform.googleapis.comIl comando
pingdovrebbe restituire l'output seguente.192.168.0.1è l'indirizzo IP dell'endpoint PSC:PING us-central1-aiplatform.googleapis.com (192.168.0.1) 56(84) bytes of data.Digita
Control+Cper uscire daping.Digita
exitper uscire dall'istanza VMon-prem-client.
Crea un account di servizio gestito dall'utente per Vertex AI Workbench in vertex-networking-vpc
In questa sezione, per controllare l'accesso all'istanza di Vertex AI Workbench, crei un account di servizio gestito dall'utente e poi assegni i ruoli IAM al account di servizio. Quando crei l'istanza, specifica l'account di servizio.
In Cloud Shell, esegui i seguenti comandi, sostituendo PROJECT_ID con il tuo ID progetto:
projectid=PROJECT_ID gcloud config set project ${projectid}Crea un account di servizio denominato
workbench-sa:gcloud iam service-accounts create workbench-sa \ --display-name="workbench-sa"Assegna il ruolo IAM Utente Vertex AI (
roles/aiplatform.user) al account di servizio:gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:workbench-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/aiplatform.user"Assegna il ruolo IAM Utente BigQuery (
roles/bigquery.user) al account di servizio:gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:workbench-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/bigquery.user"Assegna il ruolo IAM Storage Admin (
roles/storage.admin) al account di servizio:gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:workbench-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/storage.admin"Assegna il ruolo IAM Visualizzatore log (
roles/logging.viewer) al account di servizio:gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:workbench-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/logging.viewer"
Crea l'istanza di Vertex AI Workbench
In Cloud Shell, crea un'istanza di Vertex AI Workbench, specificando ilaccount di serviziot
workbench-sa:gcloud workbench instances create workbench-tutorial \ --vm-image-project=deeplearning-platform-release \ --vm-image-family=common-cpu-notebooks \ --machine-type=n1-standard-4 \ --location=us-central1-a \ --subnet-region=us-central1 \ --shielded-secure-boot=True \ --subnet=workbench-subnet \ --disable-public-ip \ --service-account-email=workbench-sa@$projectid.iam.gserviceaccount.comNella console Google Cloud , vai alla scheda Istanze nella pagina Vertex AI Workbench.
Accanto al nome dell'istanza di Vertex AI Workbench (
workbench-tutorial), fai clic su Apri JupyterLab.L'istanza di Vertex AI Workbench apre JupyterLab.
Seleziona File > Nuovo > Blocco note.
Nel menu Seleziona kernel, seleziona Python 3 (locale) e fai clic su Seleziona.
Quando si apre il nuovo notebook, è presente una cella di codice predefinita in cui puoi inserire il codice. Sembra che ci sia
[ ]:seguito da un campo di testo. Il campo di testo è il punto in cui incolli il codice.Per installare l'SDK Vertex AI Python, incolla il seguente codice nella cella e fai clic su Esegui le celle selezionate e vai avanti:
!pip3 install --upgrade google-cloud-bigquery scikit-learn==1.2In questo passaggio e in ognuno dei seguenti, aggiungi una nuova cella di codice (se necessario) facendo clic su Inserisci una cella sotto, incolla il codice nella cella e poi fai clic su Esegui le celle selezionate e vai avanti.
Per utilizzare i pacchetti appena installati in questo runtime Jupyter, devi riavviare il runtime:
# Restart kernel after installs so that your environment can access the new packages import IPython app = IPython.Application.instance() app.kernel.do_shutdown(True)Imposta le seguenti variabili di ambiente nel notebook JupyterLab, sostituendo PROJECT_ID con il tuo ID progetto.
# set project ID and location PROJECT_ID = "PROJECT_ID" REGION = "us-central1"Crea un bucket Cloud Storage per preparare il job di addestramento:
BUCKET_NAME = f"{PROJECT_ID}-ml-staging" BUCKET_URI = f"gs://{BUCKET_NAME}" !gcloud storage buckets create {BUCKET_URI} --location={REGION} --project={PROJECT_ID}
prepara i dati di addestramento
In questa sezione, prepari i dati da utilizzare per addestrare un modello di inferenza.
Nel notebook JupyterLab, crea un client BigQuery:
from google.cloud import bigquery bq_client = bigquery.Client(project=PROJECT_ID)Recupera i dati dal set di dati pubblico BigQuery
ml_datasets:DATA_SOURCE = "bigquery-public-data.ml_datasets.census_adult_income" # Define the SQL query to fetch the dataset query = f""" SELECT * FROM `{DATA_SOURCE}` LIMIT 20000 """ # Download the dataset to a dataframe df = bq_client.query(query).to_dataframe() df.head()Utilizza la libreria
sklearnper dividere i dati per l'addestramento e il test:from sklearn.model_selection import train_test_split # Split the dataset X_train, X_test = train_test_split(df, test_size=0.3, random_state=43) # Print the shapes of train and test sets print(X_train.shape, X_test.shape)Esporta i dataframe di addestramento e test in file CSV nel bucket di staging:
X_train.to_csv(f"{BUCKET_URI}/train.csv",index=False, quoting=1, quotechar='"') X_test[[i for i in X_test.columns if i != "income_bracket"]].iloc[:20].to_csv(f"{BUCKET_URI}/test.csv",index=False,quoting=1, quotechar='"')
Preparare l'applicazione di addestramento
In questa sezione creerai e compilerai l'applicazione di addestramento Python e la salverai nel bucket di gestione temporanea.
Nel notebook JupyterLab, crea una nuova cartella per i file dell'applicazione di addestramento:
!mkdir -p training_package/trainerOra dovresti vedere una cartella denominata
training_packagenel menu di navigazione di JupyterLab.Definisci le funzionalità, il target, l'etichetta e i passaggi per l'addestramento e l'esportazione del modello in un file:
%%writefile training_package/trainer/task.py from sklearn.ensemble import RandomForestClassifier from sklearn.feature_selection import SelectKBest from sklearn.pipeline import FeatureUnion, Pipeline from sklearn.preprocessing import LabelBinarizer import pandas as pd import argparse import joblib import os TARGET = "income_bracket" # Define the feature columns that you use from the dataset COLUMNS = ( "age", "workclass", "functional_weight", "education", "education_num", "marital_status", "occupation", "relationship", "race", "sex", "capital_gain", "capital_loss", "hours_per_week", "native_country", ) # Categorical columns are columns that have string values and # need to be turned into a numerical value to be used for training CATEGORICAL_COLUMNS = ( "workclass", "education", "marital_status", "occupation", "relationship", "race", "sex", "native_country", ) # load the arguments parser = argparse.ArgumentParser() parser.add_argument('--training-dir', dest='training_dir', default=os.getenv('AIP_MODEL_DIR'), type=str,help='get the staging directory') args = parser.parse_args() # Load the training data X_train = pd.read_csv(os.path.join(args.training_dir,"train.csv")) # Remove the column we are trying to predict ('income-level') from our features list # Convert the Dataframe to a lists of lists train_features = X_train.drop(TARGET, axis=1).to_numpy().tolist() # Create our training labels list, convert the Dataframe to a lists of lists train_labels = X_train[TARGET].to_numpy().tolist() # Since the census data set has categorical features, we need to convert # them to numerical values. We'll use a list of pipelines to convert each # categorical column and then use FeatureUnion to combine them before calling # the RandomForestClassifier. categorical_pipelines = [] # Each categorical column needs to be extracted individually and converted to a numerical value. # To do this, each categorical column will use a pipeline that extracts one feature column via # SelectKBest(k=1) and a LabelBinarizer() to convert the categorical value to a numerical one. # A scores array (created below) will select and extract the feature column. The scores array is # created by iterating over the COLUMNS and checking if it is a CATEGORICAL_COLUMN. for i, col in enumerate(COLUMNS): if col in CATEGORICAL_COLUMNS: # Create a scores array to get the individual categorical column. # Example: # data = [39, 'State-gov', 77516, 'Bachelors', 13, 'Never-married', 'Adm-clerical', # 'Not-in-family', 'White', 'Male', 2174, 0, 40, 'United-States'] # scores = [0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0] # # Returns: [['Sate-gov']] scores = [] # Build the scores array for j in range(len(COLUMNS)): if i == j: # This column is the categorical column we want to extract. scores.append(1) # Set to 1 to select this column else: # Every other column should be ignored. scores.append(0) skb = SelectKBest(k=1) skb.scores_ = scores # Convert the categorical column to a numerical value lbn = LabelBinarizer() r = skb.transform(train_features) lbn.fit(r) # Create the pipeline to extract the categorical feature categorical_pipelines.append( ( "categorical-{}".format(i), Pipeline([("SKB-{}".format(i), skb), ("LBN-{}".format(i), lbn)]), ) ) # Create pipeline to extract the numerical features skb = SelectKBest(k=6) # From COLUMNS use the features that are numerical skb.scores_ = [1, 0, 1, 0, 1, 0, 0, 0, 0, 0, 1, 1, 1, 0] categorical_pipelines.append(("numerical", skb)) # Combine all the features using FeatureUnion preprocess = FeatureUnion(categorical_pipelines) # Create the classifier classifier = RandomForestClassifier() # Transform the features and fit them to the classifier classifier.fit(preprocess.transform(train_features), train_labels) # Create the overall model as a single pipeline pipeline = Pipeline([("union", preprocess), ("classifier", classifier)]) # Save the model pipeline joblib.dump(pipeline, os.path.join(args.training_dir,"model.joblib"))Crea un file
__init__.pyin ogni sottodirectory per trasformarla in un pacchetto:!touch training_package/__init__.py !touch training_package/trainer/__init__.pyCrea uno script di configurazione del pacchetto Python:
%%writefile training_package/setup.py from setuptools import find_packages from setuptools import setup setup( name='trainer', version='0.1', packages=find_packages(), include_package_data=True, description='Training application package for census income classification.' )Utilizza il comando
sdistper creare la distribuzione di origine dell'applicazione di addestramento:!cd training_package && python setup.py sdist --formats=gztarCopia il pacchetto Python nel bucket di staging:
!gcloud storage cp training_package/dist/trainer-0.1.tar.gz $BUCKET_URI/Verifica che il bucket di staging contenga tre file:
!gcloud storage ls $BUCKET_URIL'output dovrebbe essere:
gs://$BUCKET_NAME/test.csv gs://$BUCKET_NAME/train.csv gs://$BUCKET_NAME/trainer-0.1.tar.gz
Addestra il modello
In questa sezione, addestri il modello creando ed eseguendo un job di addestramento personalizzato.
Nel notebook JupyterLab, esegui questo comando per creare un job di addestramento personalizzato:
!gcloud ai custom-jobs create --display-name=income-classification-training-job \ --project=$PROJECT_ID \ --worker-pool-spec=replica-count=1,machine-type='e2-highmem-2',executor-image-uri='us-docker.pkg.dev/vertex-ai/training/sklearn-cpu.1-0:latest',python-module=trainer.task \ --python-package-uris=$BUCKET_URI/trainer-0.1.tar.gz \ --args="--training-dir","/gcs/$BUCKET_NAME" \ --region=$REGIONL'output dovrebbe essere simile al seguente. Il primo numero in ogni percorso del job personalizzato è il numero di progetto (PROJECT_NUMBER). Il secondo numero è l'ID job personalizzato (CUSTOM_JOB_ID). Prendi nota di questi numeri per poterli utilizzare nel passaggio successivo.
Using endpoint [https://us-central1-aiplatform.googleapis.com/] CustomJob [projects/721032480027/locations/us-central1/customJobs/1100328496195960832] is submitted successfully. Your job is still active. You may view the status of your job with the command $ gcloud ai custom-jobs describe projects/721032480027/locations/us-central1/customJobs/1100328496195960832 or continue streaming the logs with the command $ gcloud ai custom-jobs stream-logs projects/721032480027/locations/us-central1/customJobs/1100328496195960832Esegui il job di addestramento personalizzato e mostra l'avanzamento trasmettendo in streaming i log del job durante l'esecuzione:
!gcloud ai custom-jobs stream-logs projects/PROJECT_NUMBER/locations/us-central1/customJobs/CUSTOM_JOB_IDSostituisci i seguenti valori:
- PROJECT_NUMBER: il numero di progetto dall'output del comando precedente
- CUSTOM_JOB_ID: l'ID job personalizzato dall'output del comando precedente
Il job di addestramento personalizzato è ora in esecuzione. Il completamento richiede circa 10 minuti.
Al termine del job, puoi importare il modello dal bucket di staging in Vertex AI Model Registry.
Importa il modello
Il job di addestramento personalizzato carica il modello addestrato nel bucket di staging. Al termine del job, puoi importare il modello dal bucket a Vertex AI Model Registry.
Nel notebook JupyterLab, importa il modello eseguendo questo comando:
!gcloud ai models upload --container-image-uri="us-docker.pkg.dev/vertex-ai/prediction/sklearn-cpu.1-2:latest" \ --display-name=income-classifier-model \ --artifact-uri=$BUCKET_URI \ --project=$PROJECT_ID \ --region=$REGIONElenca i modelli Vertex AI nel progetto nel seguente modo:
!gcloud ai models list --region=us-central1L'output dovrebbe essere simile al seguente. Se sono elencati due o più modelli, il primo nell'elenco è quello che hai importato più di recente.
Prendi nota del valore nella colonna MODEL_ID. Ti serve per creare la richiesta di inferenza batch.
Using endpoint [https://us-central1-aiplatform.googleapis.com/] MODEL_ID DISPLAY_NAME 1871528219660779520 income-classifier-modelIn alternativa, puoi elencare i modelli nel tuo progetto nel seguente modo:
Nella console Google Cloud , nella sezione Vertex AI, vai alla pagina Vertex AI Model Registry.
Vai alla pagina Vertex AI Model Registry
Per visualizzare gli ID modello e altri dettagli di un modello, fai clic sul nome del modello e poi sulla scheda Dettagli versione.
Ottenere inferenze batch dal modello
Ora puoi richiedere inferenze batch dal modello. Le richieste di inferenza batch vengono effettuate dall'istanza VM on-prem-client.
Crea la richiesta di inferenza batch
In questo passaggio, utilizzi ssh per accedere all'istanza VM on-prem-client.
Nell'istanza VM, crea un file di testo denominato request.json che contiene
il payload per una richiesta curl di esempio che invii al modello per ottenere
inferenze batch.
In Cloud Shell, esegui i seguenti comandi, sostituendo PROJECT_ID con il tuo ID progetto:
projectid=PROJECT_ID gcloud config set project ${projectid}Accedi all'istanza VM
on-prem-clientutilizzandossh:gcloud compute ssh on-prem-client \ --project=$projectid \ --zone=us-central1-aNell'istanza VM
on-prem-client, utilizza un editor di testo comevimonanoper creare un nuovo file denominatorequest.jsoncontenente il seguente testo:{ "displayName": "income-classification-batch-job", "model": "projects/PROJECT_ID/locations/us-central1/models/MODEL_ID", "inputConfig": { "instancesFormat": "csv", "gcsSource": { "uris": ["BUCKET_URI/test.csv"] } }, "outputConfig": { "predictionsFormat": "jsonl", "gcsDestination": { "outputUriPrefix": "BUCKET_URI" } }, "dedicatedResources": { "machineSpec": { "machineType": "n1-standard-4", "acceleratorCount": "0" }, "startingReplicaCount": 1, "maxReplicaCount": 2 } }Sostituisci i seguenti valori:
- PROJECT_ID: il tuo ID progetto
- MODEL_ID: l'ID modello del modello
- BUCKET_URI: l'URI del bucket di archiviazione in cui hai eseguito lo staging del modello
Esegui questo comando per inviare la richiesta di inferenza batch:
curl -X POST \ -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json; charset=utf-8" \ -d @request.json \ "https://us-central1-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/batchPredictionJobs"Sostituisci PROJECT_ID con l'ID progetto.
Nella risposta dovresti vedere la seguente riga:
"state": "JOB_STATE_PENDING"Il job di inferenza batch viene ora eseguito in modo asincrono. L'esecuzione richiede circa 20 minuti.
Nella Google Cloud console, nella sezione Vertex AI, vai alla pagina Previsioni batch.
Vai alla pagina Previsioni batch
Mentre il job di inferenza batch è in esecuzione, il suo stato è
Running. Al termine, lo stato cambia inFinished.Fai clic sul nome del job di inferenza batch (
income-classification-batch-job), poi sul link Posizione di esportazione nella pagina dei dettagli per visualizzare i file di output del job batch in Cloud Storage.In alternativa, puoi fare clic sull'icona Visualizza output della previsione su Cloud Storage (tra la colonna Ultimo aggiornamento e il menu Azioni).
Fai clic sul link del file
prediction.results-00000-of-00002oprediction.results-00001-of-00002, quindi fai clic sul link URL di autenticazione per aprire il file.L'output del job di inferenza batch dovrebbe essere simile a questo esempio:
{"instance": ["27", " Private", "391468", " 11th", "7", " Divorced", " Craft-repair", " Own-child", " White", " Male", "0", "0", "40", " United-States"], "prediction": " <=50K"} {"instance": ["47", " Self-emp-not-inc", "192755", " HS-grad", "9", " Married-civ-spouse", " Machine-op-inspct", " Wife", " White", " Female", "0", "0", "20", " United-States"], "prediction": " <=50K"} {"instance": ["32", " Self-emp-not-inc", "84119", " HS-grad", "9", " Married-civ-spouse", " Craft-repair", " Husband", " White", " Male", "0", "0", "45", " United-States"], "prediction": " <=50K"} {"instance": ["32", " Private", "236543", " 12th", "8", " Divorced", " Protective-serv", " Own-child", " White", " Male", "0", "0", "54", " Mexico"], "prediction": " <=50K"} {"instance": ["60", " Private", "160625", " HS-grad", "9", " Married-civ-spouse", " Prof-specialty", " Husband", " White", " Male", "5013", "0", "40", " United-States"], "prediction": " <=50K"} {"instance": ["34", " Local-gov", "22641", " HS-grad", "9", " Never-married", " Protective-serv", " Not-in-family", " Amer-Indian-Eskimo", " Male", "0", "0", "40", " United-States"], "prediction": " <=50K"} {"instance": ["32", " Private", "178623", " HS-grad", "9", " Never-married", " Other-service", " Not-in-family", " Black", " Female", "0", "0", "40", " ?"], "prediction": " <=50K"} {"instance": ["28", " Private", "54243", " HS-grad", "9", " Divorced", " Transport-moving", " Not-in-family", " White", " Male", "0", "0", "60", " United-States"], "prediction": " <=50K"} {"instance": ["29", " Local-gov", "214385", " 11th", "7", " Divorced", " Other-service", " Unmarried", " Black", " Female", "0", "0", "20", " United-States"], "prediction": " <=50K"} {"instance": ["49", " Self-emp-inc", "213140", " HS-grad", "9", " Married-civ-spouse", " Exec-managerial", " Husband", " White", " Male", "0", "1902", "60", " United-States"], "prediction": " >50K"}