多くの場合、ML モデルは「ブラック ボックス」です。その設計者でさえ、モデルが特定の推論を行った方法やその理由を説明することができません。Vertex Explainable AI では、特徴ベースの説明と例に基づく説明が用意されており、モデルの意思決定について深く理解できます。
モデルの動作とトレーニング データセットがモデルに及ぼす影響を理解することで、ML の新機能を構築または使用するユーザーは、モデルを改善し、推論の信頼性を高め、問題が発生するタイミングと理由を把握できます。
例ベースの説明
例に基づく説明では、Vertex AI は最近傍探索を使用して、入力に最も類似した例(通常はトレーニング セットから)のリストを返します。通常、類似した入力から同様の推論が得られると予想されるため、これらの説明を使用してモデルの動作を調査し、説明できます。
例に基づく説明は、次のようないくつかのシナリオで役立ちます。
データまたはモデルを改善する: 例に基づく説明の主要なユースケースの 1 つは、モデルが推論で特定の間違いを犯した理由を把握できるようにし、それらの分析情報を使用してデータやモデルを改善することです。これを行うには、まず目的のテストデータを選択します。これは、ビジネスニーズ、またはモデルに最も重大な誤りがあるデータなどのヒューリスティックスによって引き起こされる可能性があります。
たとえば、画像を鳥または飛行機のいずれかとして分類するモデルがあり、そのモデルが高い信頼度で次の鳥を飛行機として誤って分類しているとします。例に基づく説明を使用して、トレーニング セットから類似した画像を取得し、何が起こっているかを把握します。

説明はすべて飛行機のクラスの暗いシルエットであるため、これは鳥のシルエットを増やすというシグナルです。
しかし、説明が主に鳥のクラスからのものである場合、データが豊富な場合でもモデルは関係を学習できないというシグナルであるため、モデルの複雑度を上げることを検討する必要があります(例: レイヤの追加)。
新しいデータの解釈: モデルは鳥と飛行機を分類するようトレーニングされたものの、現実にはモデルは凧、ドローン、ヘリコプターの画像にも遭遇します。最近傍データセットに、凧、ドローン、ヘリコプターのラベル付き画像が含まれている場合、例に基づく説明を使用して、最近傍に最も頻繁に出現するラベルを適用して新しい画像を分類できます。これが可能なのは、凧の潜在表現が、鳥や飛行機の潜在表現とは異なり、最近傍データセット内のラベル付き凧により類似していると予想されるためです。
異常を検出: 直感的には、インスタンスがトレーニング セット内のすべてのデータからかけ離れている場合、外れ値である可能性があります。ニューラル ネットワークでは、誤りに対して過信があることがわかっているため、エラーが隠されます。例に基づく説明を使用してモデルをモニタリングすると、最も大きな外れ値を特定できます。
能動的学習: 例に基づく説明により、ヒューマン ラベリングが役立つ可能性のあるインスタンスを特定できます。これは、ラベル付けが遅い場合やコストがかかる場合に特に有用で、制限付きのラベル付けリソースから可能な限り多くのデータセットを取得できます。
たとえば、医療患者を風邪またはインフルエンザのいずれかに分類するモデルがあるとします。患者がインフルエンザにかかっていると分類され、すべての例に基づく説明がインフルエンザのクラスからのものである場合、医師は詳しく見なくても、モデルの推論に信頼を置くことができます。ただし、一部の説明がインフルエンザのクラスから来ており、その他の説明が風邪のクラスからのものである場合は、医師の意見を取り入れる価値があります。これは、難しいインスタンスにより多くのラベルが付けられているデータセットにつながります。これにより、ダウンストリーム モデルが複雑な関係を簡単に学習できるようになります。
例に基づく説明をサポートするモデルを作成するには、例に基づく説明の構成をご覧ください。
サポートされているモデルタイプ
入力のエンベディング(潜在表現)を提供できる TensorFlow モデルであれば、すべてサポートされます。ディシジョン ツリーなどのツリーベース モデルはサポートされていません。PyTorch や XGBoost など、他のフレームワークのモデルはまだサポートされていません。
ディープ ニューラル ネットワークの場合、上位レイヤ(出力レイヤに近い)は「意味のある」ことを学習済みであると通常は想定されるため、埋め込みには最後から 2 番目のレイヤが選択されることがよくあります。いくつかの異なるレイヤでテストし、得られる例を調査して、定量的(クラスマッチ)な尺度または定性的(合理的に見える)な尺度に基づいてレイヤを選択します。
TensorFlow モデルから埋め込みを抽出して最近傍探索を実行する方法のデモについては、例に基づく説明のノートブックをご覧ください。
特徴ベースの説明
Vertex Explainable AI は特徴アトリビューションを Vertex AI に統合します。このセクションでは、Vertex AI で使用可能な特徴アトリビューション方式の概念的な概要を簡単に説明します。
特徴アトリビューションは、モデル内の各特徴が各インスタンスの推論にどの程度影響を及ぼしたかを示します。推論をリクエストすると、モデルに適した値が得られます。説明をリクエストすると、推論に加えて、特徴アトリビューションの情報を得られます。
特徴アトリビューションは表形式のデータで機能します。また、画像データ用の可視化機能が組み込まれています。以下の例を考えてみましょう。
気象データと以前のライドシェアリング データに基づいて、自転車の走行時間が予測されるようにトレーニングされているディープ ニューラル ネットワークがあるとします。このモデルについて推論のみをリクエストすると、自転車の予測走行時間を分単位で返されます。説明をリクエストすると、自転車の予測走行時間に加えて、説明のリクエストに基づき、特徴ごとのアトリビューション スコアが返されます。アトリビューション スコアは、指定したベースライン値と比較して、その特徴が推論値の変化にどの程度影響を及ぼしたかを示します。モデルに適した有意義なベースラインを選択します。この場合は、自転車の平均走行時間を選択します。特徴アトリビューション スコアをプロットして、推論結果に最も影響を及ぼした特徴を確認できます。
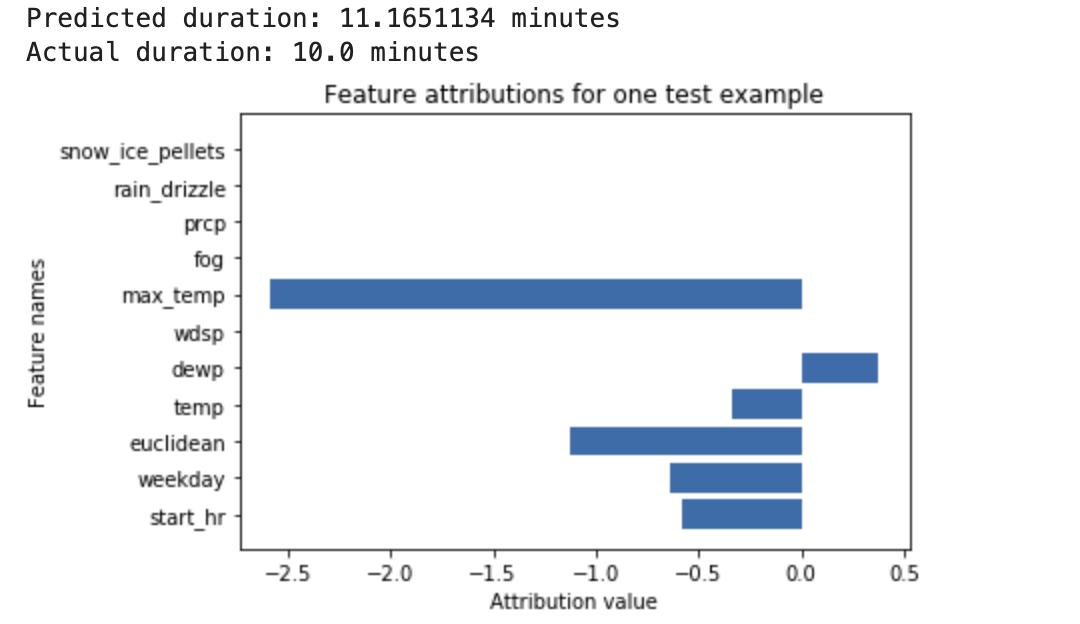
指定された画像にイヌとネコのどちらが含まれているかを予測するようにトレーニングされている画像分類モデルがあるとします。新しい画像セットでこのモデルから推論をリクエストすると、画像ごとに推論(dog または cat)を受け取ります。説明をリクエストすると、予測されたクラスに加えて、推論結果に最も強く影響を及ぼした画像内の部分を示す画像のオーバーレイが返されます。

特徴アトリビューション オーバーレイを含むネコの写真 
特徴アトリビューション オーバーレイを含むイヌの写真 画像分類モデルは、画像に含まれる花の種類を予測するようにトレーニングされます。このモデルから新しい画像セットの推論をリクエストすると、各画像(デイジーまたはタンポポ)の推論を受け取ります。説明をリクエストすると、予測されたクラスに加えて、推論結果に最も強く影響を及ぼした画像内の部分を示す領域のオーバーレイが返されます。

特徴アトリビューション オーバーレイを含むデイジーの写真
サポートされているモデルタイプ
特徴アトリビューションは、すべてのタイプのモデル(AutoML とカスタム トレーニングの両方)、フレームワーク(TensorFlow、scikit、XGBoost)、BigQuery ML モデル、方式(画像、テキスト、表形式、動画)でサポートされています。
特徴アトリビューションを使用するには、モデルを Vertex AI Model Registry にアップロードまたは登録するときに、特徴アトリビューション用のモデルを構成します。
さらに、次のタイプの AutoML モデルでは、特徴アトリビューションが Google Cloud コンソールに統合されています。
- AutoML 画像モデル(分類モデルのみ)
- AutoML 表形式モデル(分類モデルと回帰モデルのみ)
統合されている AutoML モデルタイプの場合、トレーニング中に Google Cloud コンソールで特徴アトリビューションを有効にし、モデル全体のモデル特徴量の重要度と、オンライン推論とバッチ推論の両方のローカル特徴量の重要度を表示できます。
統合されていない AutoML モデルタイプの場合、モデル アーティファクトを Vertex AI Model Registry にアップロードするときに、モデル アーティファクトをエクスポートして特徴アトリビューションを構成することで、特徴アトリビューションを引き続き有効にできます。
利点
特定のインスタンスを調べて、トレーニング データセット全体で特徴アトリビューションを集計することで、モデルの仕組みをより詳しく分析できます。次の点を考慮してください。
モデルのデバッグ: 特徴アトリビューションは、標準的なモデル評価技法では見落としてしまうことが多いデータ内の問題を検出するのに役立ちます。
たとえば、胸部 X 線画像のテスト データセットにおいて、画像病理モデルによって得られた結果の信頼性があまり高くない場合があります。特徴アトリビューションにより、モデルの精度の高さが、放射線科医が画像内に記したマークによって左右されることが明らかになりました。この例の詳細については、AI Explanations のホワイトペーパーをご覧ください。
モデルの最適化: 重要度の低い特徴を特定して削除し、より効率的なモデルを作成できます。
特徴アトリビューション方式
いずれの特徴アトリビューション方式も、特定の結果に対してゲーム内の各プレーヤーにクレジットを割り当てる協力ゲーム理論アルゴリズムである Shapley 値に基づいています。機械学習モデルに適用されます。つまり、各モデル特徴がゲームの「プレーヤー」として扱われます。Vertex Explainable AI は特定の推論結果を得るために、各特徴に比例クレジットを割り当てます。
Shapley 値サンプリング方式
Shapley 値サンプリング方式では、正確な Shapley 値のサンプリング近似が提供されます。AutoML 表形式モデルでは、Shapley 値サンプリング方式を使用して特徴量の重要度を求めます。Shapley 値サンプリング方式は、ツリーとニューラル ネットワークを使用したメタ アンサンブル学習を行うこのモデルでよく機能します。
Shapley 値サンプリング方式の詳しい仕組みについては、サンプリング ベースの推論エラーの予測方法をご覧ください。
統合勾配方式
統合勾配方式では、推論結果の勾配が、入力値の特徴に対して積分経路に沿って計算されます。
- 勾配は、スケーリング パラメータのさまざまな間隔で計算されます各間隔のサイズはガウス求積法で計算されます(画像データでは、このスケーリング パラメータは画像内のすべてのピクセルを黒にスケーリングする「スライダー」であると仮定されます)。
- 勾配は次のように統合されます。
- 積分は、加重平均を使用して近似されます。
- 平均勾配と元の入力値の要素別の積が計算されます。
画像に適用されるこのプロセスのわかりやすい説明については、ブログ投稿「Attributing a deep network's inference to its input features」をご覧ください。統合勾配に関する元の論文(Axiomatic Attribution for Deep Networks)の著者は、以前のブログ投稿で、プロセスの各ステップで画像がどのように見えるかを示しています。
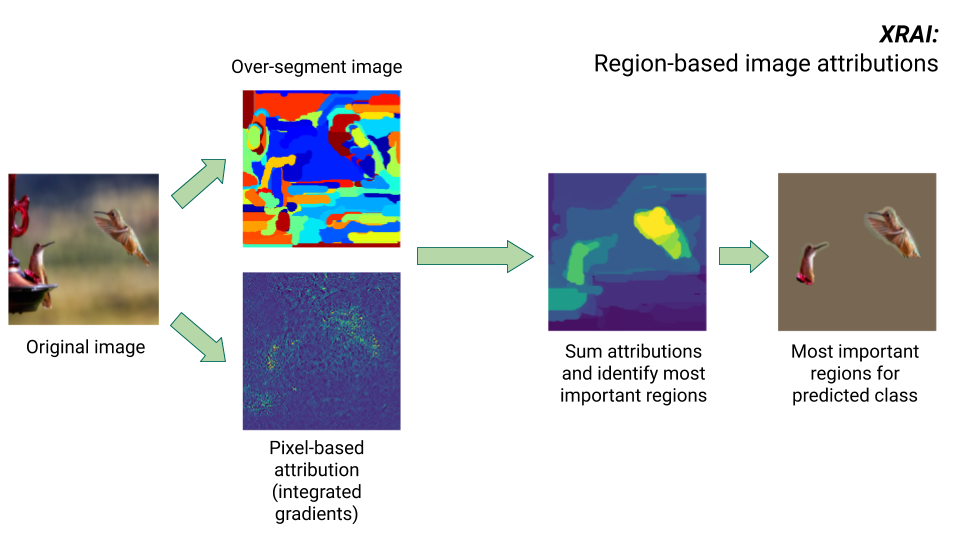
XRAI 方式
XRAI 方式は、統合勾配方式に追加ステップを組み合わせて、画像のどの領域が特定のクラス推論に最も大きく貢献するかを決定します。
- ピクセルレベルのアトリビューション: XRAI は、入力画像に対してピクセルレベルのアトリビューションを実行します。このステップでは、XRAI は統合勾配方式を採用し、黒のベースラインと白のベースラインを使用します。
- オーバーセグメント化: XRAI は、ピクセルレベルのアトリビューションから独立して画像をオーバーセグメント化し、小さな領域のパッチワークを作成します。XRAI は Felzenswalb のグラフベースの方式を使用して、画像セグメントを作成します。
- リージョンの選択: XRAI は各セグメント内のピクセルレベルのアトリビューションを集計して、アトリビューションの密度を決定します。これらの値を使用して、XRAI は各セグメントをランク付けし、正のアトリビューション値が高い順に並べます。これにより、画像のどの領域が最も顕著か、または特定のクラス推論に最も大きく貢献するかが決まります。
特徴アトリビューション方式の比較
Vertex Explainable AI には、サンプリングされた Shapley、統合勾配、XRAI という特徴アトリビューションに使用できる 3 つの方式があります。
| メソッド | 基本的な説明 | 推奨モデルタイプ | サンプル ユースケース | 対応する Vertex AI の Model リソース |
|---|---|---|---|---|
| サンプリングされた Shapley | 各特徴に結果のクレジットを割り当て、特徴のさまざまな置換を検討します。この方式では、正確な Shapley 値のサンプリング近似が提供されます。 | 微分不可能なモデル(ツリーとニュートラル ネットワークの集合体など) |
|
|
| 統合勾配 | Shapley 値と同じ公理プロパティを使用して、特徴アトリビューションを効率的に計算する勾配ベースの方式。 | 微分可能なモデル(ニューラル ネットワークなど)。特に、特徴スペースが大きいモデルにおすすめします。 X 線などのコントラストの低い画像に適しています。 |
|
|
| XRAI(eXplanation with Ranked Area Integrals) | XRAI は統合勾配方式に基づいて画像の重複領域を評価し、ピクセルではなく画像の関連領域をハイライト表示する顕著性マップを作成します。 | 画像入力を受け取るモデル。複数のオブジェクトを含む実世界の光景など、自然な画像に特に適しています。 |
|
|
アトリビューション方式の詳細な比較については、AI Explanations のホワイトペーパーをご覧ください。
微分可能モデルと微分不可能モデル
微分可能モデルでは、TensorFlow グラフのすべての演算の導関数を計算できます。このプロパティは、そのようなモデルで誤差逆伝播を行えるようにするのに役立ちます。たとえば、ニューラル ネットワークは微分可能です。微分可能なモデルの特徴アトリビューションを取得するには、統合勾配方式を使用します。
統合勾配方式は、微分不可能方式では機能しません。統合勾配方式で処理するための微分不可能な入力値のエンコードについて学習してください。
微分不可能モデルには、デコードや丸め処理を実行するオペレーションなど、TensorFlow グラフでの微分不可能オペレーションが含まれます。たとえば、ツリーとニューラル ネットワークの集合体として構築されたモデルは微分不可能です。微分不可能なモデルの特徴アトリビューションを取得するには、サンプリングされた Shapley 方式を使用します。サンプリングされた Shapley は微分可能なモデルにも対応していますが、その場合、必要以上に計算コストがかかります。
概念上の制限
特徴アトリビューションには、次の制限があります。
AutoML のローカル特徴量の重要度など、特徴アトリビューションは個々の推論に固有のものです。個々の推論の特徴アトリビューションを調べることで詳細な洞察を得ることができますが、それらの個々のインスタンスのクラス全体やモデル全体にその洞察を当てはめることができない場合があります。
AutoML モデルについて、より一般的な洞察を入手するには、モデル特徴量の重要度を参照してください。他のモデルの一般的な洞察を得るには、データセットのサブセット、またはデータセット全体でアトリビューションを集約します。
特徴アトリビューションはモデルのデバッグに役立ちますが、ある問題が特定のモデルから発生しているのか、モデルをトレーニングしたデータから発生しているのかを必ずしも明確に示すものではありません。最良の判断を下し、共通のデータ問題を診断することで、原因を特定してください。
複雑なモデルでは、特徴アトリビューションは推論と類似する敵対的攻撃を受けます。
制限の詳細については、制限の概要リストと AI Explanations のホワイトペーパーをご覧ください。
リファレンス
特徴アトリビューションの場合、サンプリングされた Shapley、統合勾配、XRAI の実装は、それぞれ以下の参照に基づいています。
Vertex Explainable AI の実装について詳しくは、AI Explanations に関するホワイトペーパーをご覧ください。
Notebooks
Vertex Explainable AI の使用を開始するには、次のノートブックを使用します。
| ノートブック | 説明可能性のメソッド | ML フレームワーク | モダリティ | タスク |
|---|---|---|---|---|
| GitHub のリンク | 例に基づく説明 | TensorFlow | イメージ | 指定された入力画像のクラスを予測する分類モデルをトレーニングし、オンライン説明を取得する |
| GitHub のリンク | 特徴ベース | AutoML | 表形式 | 銀行の顧客が定期預金を契約するかどうかを予測するバイナリ分類モデルをトレーニングし、バッチ説明を取得する |
| GitHub のリンク | 特徴ベース | AutoML | 表形式 | アヤメの種の種類を予測する分類モデルをトレーニングし、オンライン説明を取得する |
| GitHub のリンク | 特徴ベース(サンプリングされた Shapley) | scikit-learn | 表形式 | タクシー料金を予測する線形回帰モデルをトレーニングし、オンライン説明を取得する |
| GitHub のリンク | 特徴ベース(統合勾配) | TensorFlow | イメージ | 指定された入力画像のクラスを予測する分類モデルをトレーニングし、バッチ説明を取得する |
| GitHub のリンク | 特徴ベース(統合勾配) | TensorFlow | イメージ | 指定された入力画像のクラスを予測する分類モデルをトレーニングし、オンライン説明を取得する |
| GitHub のリンク | 特徴ベース(統合勾配) | TensorFlow | 表形式 | 住宅価格の中央値を予測する回帰モデルをトレーニングし、バッチ説明を取得する |
| GitHub のリンク | 特徴ベース(統合勾配) | TensorFlow | 表形式 | 住宅価格の中央値を予測する回帰モデルをトレーニングし、オンライン説明を取得する |
| GitHub のリンク | 特徴ベース(サンプリングされた Shapley) | TensorFlow | テキスト | 映画のレビューをレビューの文章を使用してポジティブとネガティブに分類する LSTM モデルをトレーニングし、オンライン説明を取得する |
教育リソース
次のリソースから、さらに役立つ教材を得ることができます。
- 実務担当者向け Explainable AI
- Interpretable Machine Learning: Shapley values
- Ankur Taly's Integrated Gradients GitHub repository
- Introduction to Shapley values