Vector Search is a powerful vector search engine built on groundbreaking technology developed by Google Research. Leveraging the ScaNN algorithm, Vector Search lets you build next-generation search and recommendation systems as well as generative AI applications.
You can benefit from the very same research and technology that power core Google products, including Google Search, YouTube, and Google Play. This means you get the scalability, availability, and performance that's trusted to handle massive datasets and deliver lightning-fast results at a global scale. With Vector Search, you have an enterprise-grade solution for implementing cutting-edge semantic search capabilities in your own applications.

|

|

Infinite Fleurs: Discover AI-assisted creativity in full bloom |

|
Get Started
Vector Search interactive demo: Check out the live demo for a realistic example of what vector search technology can do and get a headstart with Vector Search.
Vector Search quickstart: Try Vector Search in 30 minutes by building, deploying, and querying a Vector Search index using a sample dataset. This tutorial covers setup, data preparation, index creation, deployment, querying, and cleanup.
Before you begin: Prepare your embeddings by choosing and training a model, and preparing your data. Then, choose a public or private endpoint to deploy your query index to.
Vector Search pricing and pricing calculator: Vector Search pricing includes the cost of virtual machines used to host deployed indexes, as well as expenses for building and updating indexes. Even a minimal setup (under $100 per month) can accommodate high throughput for moderate-sized use cases. To estimate your monthly costs:
- Go to Google Cloud's pricing calculator.
- Click Add to estimate.
- Search for Vertex AI.
- Click the Vertex AI button.
- Choose Vertex AI Vector Search from the Service type drop-down.
- Keep the default settings or configure your own. The estimated cost per month is shown in the Cost details panel.
Documentation
Manage indexes and endpoints
Advanced topics
Use cases and blogs
Vector search technology is becoming a central hub for businesses using AI. Similar to how relational databases function in IT systems, it connects various business elements like documents, content, products, users, events, and other entities based on their relevance. Beyond searching conventional media like documents and images, Vector Search can also power intelligent recommendations, match business problems with solutions, and even link IoT signals to monitoring alerts. It's a versatile tool that's essential for navigating the growing landscape of AI-enabled enterprise data.
|
Search / Information Retrieval
Recommendation |
How Vertex AI vector search helps unlock high-performance gen AI apps: Vector Search powers diverse applications, including ecommerce, RAG systems, and recommendation engines, alongside chatbots, multimodal search, and more. Hybrid search further enhances results for niche terms. Customers like Bloomreach, eBay, and Mercado Libre use Vertex AI for its performance, scalability, and cost-effectiveness, achieving benefits like faster search and increased conversions. eBay uses Vector Search for recommendations: Highlights how eBay uses Vector Search for its recommendation system. This technology allows eBay to find similar products within its extensive catalog, improving the user experience. Mercari leverages Google's vector search technology to create a new marketplace: Explains how Mercari uses Vector Search to improve its new marketplace platform. Vector Search powers the platform's recommendations, helping users find relevant products more effectively. Vertex AI Embeddings for Text: Grounding LLMs made easy: Focuses on grounding LLMs using Vertex AI Embeddings for text data. Vector Search plays an important role in finding relevant text passages that ensure the model's responses are grounded in factual information. What is Multimodal Search: "LLMs with vision" change businesses: Discusses Multimodal Search, which combines LLMs with visual understanding. It explains how Vector Search processes and compares both text and image data, allowing for more comprehensive search experiences. Unlock multimodal search at scale: Combine text & image power with Vertex AI: Describes building a multimodal search engine with Vertex AI that combines text and image search using a weighted Rank-Biased Reciprocal Rank ensemble method. This improves user experience and provides more relevant results. Scaling deep retrieval with TensorFlow Recommenders and Vector Search: Explains how to build a playlist recommendation system using TensorFlow Recommenders and Vector Search, covering deep retrieval models, training, deployment, and scaling. |
|
Gen AI: retrieval for RAG and Agents |
Vertex AI and Denodo unlock enterprise data with Gen AI: Showcases how Vertex AI's integration with Denodo enables businesses to use generative AI for gaining insights from their data. Vector Search is key for efficiently accessing and analyzing relevant data within an enterprise environment. Infinite Nature and the nature of industries: This 'wild' demo shows the diverse possibilities of AI: Showcases a demo that illustrates AI's potential across different industries. It utilizes Vector Search to power generative recommendations and multimodal semantic search. Infinite Fleurs: Discover AI-assisted creativity in full bloom: Google's Infinite Fleurs, an AI experiment using Vector Search, Gemini and Imagen models, generates unique flower bouquets based on user prompts. This technology showcases AI's potential to inspire creativity across various industries. LlamaIndex for RAG on Google Cloud: Describes how to use LlamaIndex to facilitate Retrieval Augmented Generation (RAG) with large language models. LlamaIndex utilizes Vector Search to retrieve relevant information from a knowledge base, resulting in more accurate and contextually appropriate responses. RAG and grounding on Vertex AI: Examines RAG and grounding techniques on Vertex AI. Vector Search helps identify relevant grounding information during retrieval, which makes generated content more accurate and reliable. Vector Search on LangChain: provides a guide to using Vector Search with LangChain for building and deploying a vector database index for text data, including question-answering and PDF processing. |
|
BI, data analytics, monitoring, and more |
Enabling real-time AI with Streaming Ingestion in Vertex AI: Explores Streaming Update in Vector Search and how it provides real-time AI capabilities. This technology allows for real-time processing and analysis of incoming data streams. |
Related resources
You can use the following resources to get started with Vector Search:
Notebooks and solutions

|

|
|
Vertex AI Vector Search Quickstart: Provides an overview of Vector Search. It is designed for users who are new to the platform and want to get started quickly. |
Getting Started with Text Embeddings and Vector Search: Introduces text embeddings and vector search. It explains how these technologies work and how they can be used to improve search results. |

|

|
|
Combining Semantic & Keyword Search: A Hybrid Search Tutorial with Vertex AI Vector Search: Provides instructions on how to use Vector Search for hybrid search. It covers the steps involved in setting up and configuring a hybrid search system. |
Vertex AI RAG Engine with Vector Search: Explores the use of Vertex AI RAG Engine with Vector Search. It discusses the benefits of using these two technologies together and provides examples of how they can be used in real-world applications. |

|
|
|
Infrastructure for a RAG-capable generative AI application using Vertex AI and Vector Search: Details the architecture for building a generative AI application and RAG using Vector Search, Cloud Run and Cloud Storage, covering use cases, design choices, and key considerations. |
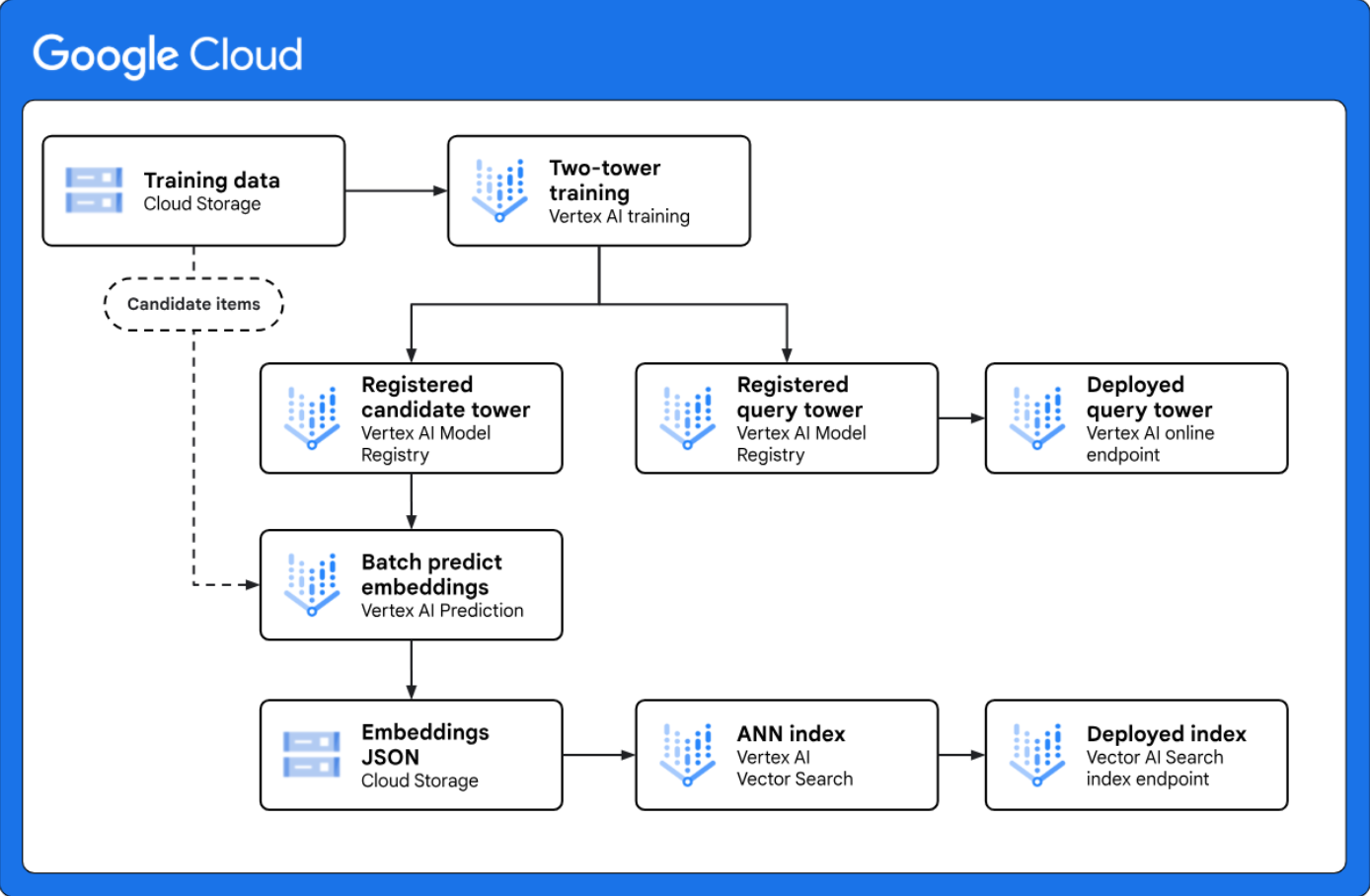
Implement two-tower retrieval for large-scale candidate generation: Provides a reference architecture that shows you how to implement an end-to-end two-tower candidate generation workflow with Vertex AI. The two-tower modeling framework is a powerful retrieval technique for personalization use cases because it learns the semantic similarity between two different entities, such as web queries and candidate items. |
Training
Getting Started with Vector Search and Embeddings Vector Search is used to find similar or related items. It can be used for recommendations, search, chatbots, and text classification. The process involves creating embeddings, uploading them to Google Cloud, and indexing them for querying. This lab focuses on text embeddings using Vertex AI, but embeddings can be generated for other data types.
Vector Search and Embeddings This course introduces Vector Search and describes how it can be used to build a search application with large language model (LLM) APIs for embeddings. The course consists of conceptual lessons on Vector Search and text embeddings, practical demos on how to build Vector Search on Vertex AI, and a practice lab.
Understanding and Applying Text Embeddings
The Vertex AI Embeddings API generates text embeddings, which are
numerical representations of text used for tasks like identifying similar items.
In this course, you'll use text embeddings for tasks like classification and semantic search, and combine semantic search with LLMs to build question-answering systems using Vertex AI.
Machine Learning Crash Course: Embeddings This course introduces word embeddings, contrasting them with sparse representations. It explores methods for obtaining embeddings and differentiates between static and contextual embeddings.
Related products
Vertex AI Embeddings Provides an overview of Embeddings API. Text and multimodal embedding use cases, along with links to additional resources and related Google Cloud services.
Vertex AI Search ranking API The ranking API reranks documents based on relevance to a query using a pre-trained language model, providing precise scores. It's ideal for improving search results from various sources including Vector Search.
Vertex AI Feature Store Lets you manage and serve feature data using BigQuery as the data source. It provisions resources for online serving, acting as a metadata layer to serve the latest feature values directly from BigQuery. Feature Store allows for the instant retrieval of feature values for the items Vector Store returned for queries.
Vertex AI Pipelines Vertex AI Pipelines enables the automation, monitoring, and governance of your ML systems in a serverless manner by orchestrating ML workflows with ML pipelines. You can run ML pipelines defined using Kubeflow Pipelines or the TensorFlow Extended (TFX) framework in batches. Pipelines allows for building automated pipelines to generate embeddings, create and update Vector Search indexes, and form an MLOps setup for production search and recommendation systems.
Deep dive resources
Enhancing your gen AI use case with Vertex AI embeddings and task types Focuses on improving Generative AI applications using Vertex AI Embeddings and task types. Vector Search can be used with task type embeddings to enhance the context and accuracy of generated content by finding more relevant information.
TensorFlow Recommenders An open-source library for building recommendation systems. It simplifies the process from data preparation to deployment and supports flexible model building. TFRS offers tutorials and resources and enables the creation of sophisticated recommendation models.
TensorFlow Ranking TensorFlow Ranking is an open-source library for building scalable neural learning-to-rank (LTR) models. It supports various loss functions and ranking metrics, with applications in search, recommendation, and other fields. The library is actively developed by Google AI.
Announcing ScaNN: Efficient Vector Similarity Search Google's ScaNN, an algorithm for efficient vector similarity search, utilizes a novel technique to improve accuracy and speed in finding nearest neighbors. It outperforms existing methods and has broad applications in machine learning tasks requiring semantic search. Google's research efforts span various areas, including foundational ML and societal impacts of AI.
SOAR: New algorithms for even faster Vector Search with ScaNN Google's SOAR algorithm improves Vector Search efficiency by introducing controlled redundancy, allowing faster searches with smaller indexes. SOAR assigns vectors to multiple clusters, creating "backup" search paths for improved performance.
Related videos
Get Started with Vector Search using Vertex AI
Vector Search is a powerful tool for building AI-powered applications. This video introduces the technology and provides a step-by-step guide to getting started.
Learn Hybrid Search with Vector Search
Vector Search can be used for hybrid search, allowing you to combine the power of vector search with the flexibility and speed of a conventional search engine. This video introduces hybrid search and shows you how to use Vector Search for hybrid search.
You're Already Using Vector Search! Here's How to Be an Expert
Did you know you're probably using vector search every day without realizing it? From finding that elusive product on social media to tracking down a song stuck in your head, vector search is the AI magic behind these everyday experiences.
New "task type" embedding from the DeepMind team improves RAG search quality
Improve the accuracy and relevance of your RAG systems with new task type embeddings developed by the Google DeepMind team. Watch along and learn about the common challenges in RAG search quality and how task type embeddings can effectively bridge the semantic gap between questions and answers, leading to more effective retrieval and enhanced RAG performance.
Vector Search terminology
This list contains some important terminology that you'll need to understand to use Vector Search:
Vector: A vector is a list of float values that has magnitude and direction. It can be used to represent any kind of data, such as numbers, points in space, and directions.
Embedding: An embedding is a type of vector that's used to represent data in a way that captures its semantic meaning. Embeddings are typically created using machine learning techniques, and they are often used in natural language processing (NLP) and other machine learning applications.
Dense embeddings: Dense embeddings represent the semantic meaning of text, using arrays that mostly contain non-zero values. With dense embeddings, similar search results can be returned based on semantic similarity.
Sparse embeddings: Sparse embeddings represent text syntax, using high-dimensional arrays that contain very few non-zero values compared to dense embeddings. Sparse embeddings are often used for keyword searches.
Hybrid search: Hybrid search uses both dense and sparse embeddings, which lets you search based on a combination of keyword search and semantic search. Vector Search supports search based on dense embeddings, sparse embeddings, and hybrid search.
Index: A collection of vectors deployed together for similarity search. Vectors can be added to or removed from an index. Similarity search queries are issued to a specific index and search the vectors in that index.
Ground truth: A term that refers to verifying machine learning for accuracy against the real world, like a ground truth dataset.
Recall: The percentage of nearest neighbors returned by the index that are actually true nearest neighbors. For example, if a nearest neighbor query for 20 nearest neighbors returned 19 of the ground truth nearest neighbors, the recall is 19/20x100 = 95%.
Restrict: Feature that limits searches to a subset of the index by using Boolean rules. Restrict is also referred to as "filtering". With Vector Search, you can use numeric filtering and text attribute filtering.