An advanced LlamaIndex RAG implementation on Google Cloud
Sagar Kewalramani
Solutions Architect, Google
Ken Lee
Solutions Architect, Google
Introduction
Retrieval Augmented Generation (RAG) is revolutionizing how we build Large Language Model (LLM)-powered applications, but unlike tabular machine learning where XGBoost reigns supreme, there's no single "go-to" solution for RAG. Developers need efficient ways to experiment with different retrieval techniques and evaluate their performance. This post provides a practical guide to rapidly prototyping and evaluating RAG solutions using Llama-index, Streamlit, RAGAS, and Google Cloud's Gemini models. We'll move beyond simple tutorials and explore how to build reusable components, extend existing frameworks, and test performance reliably.
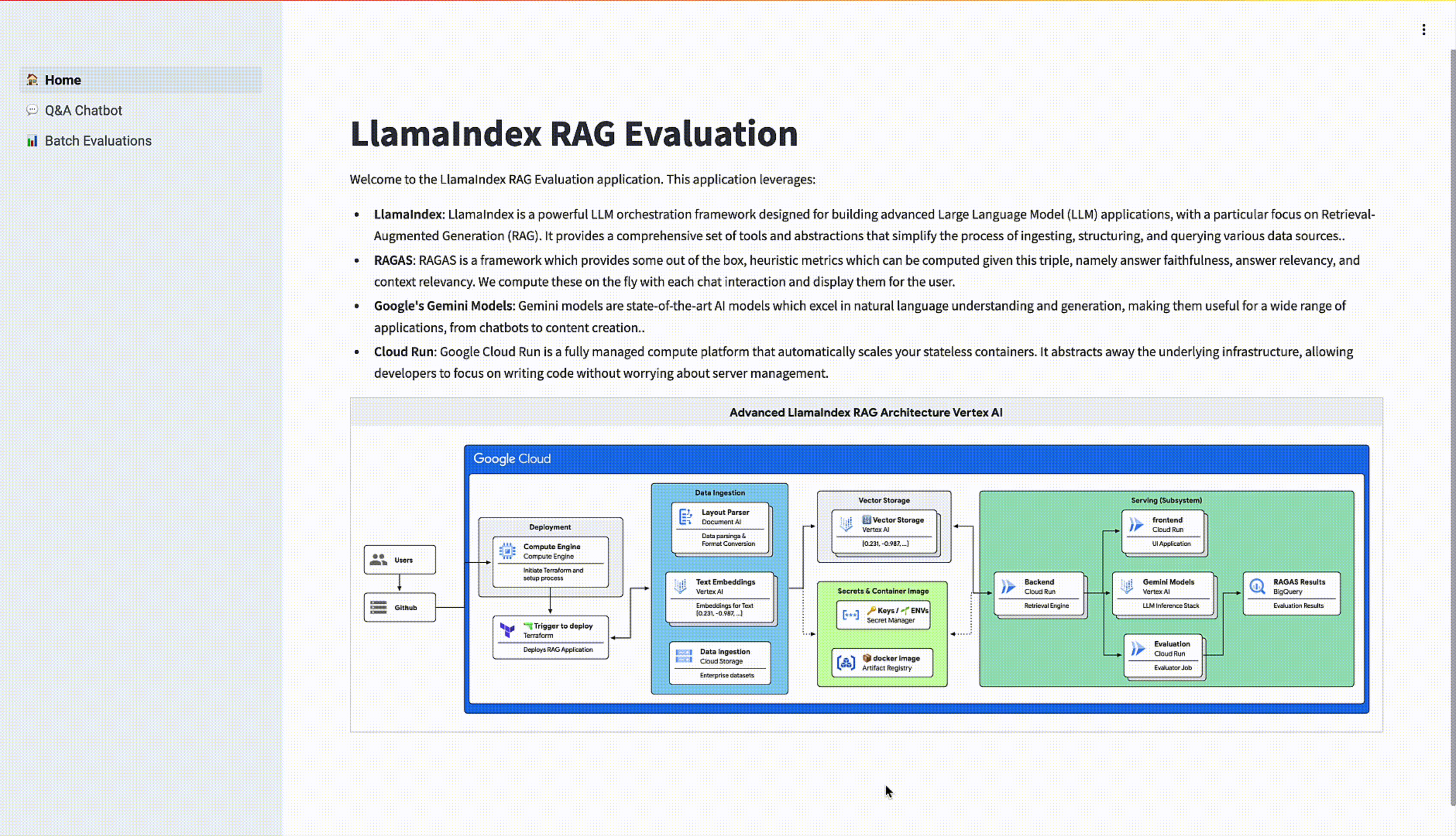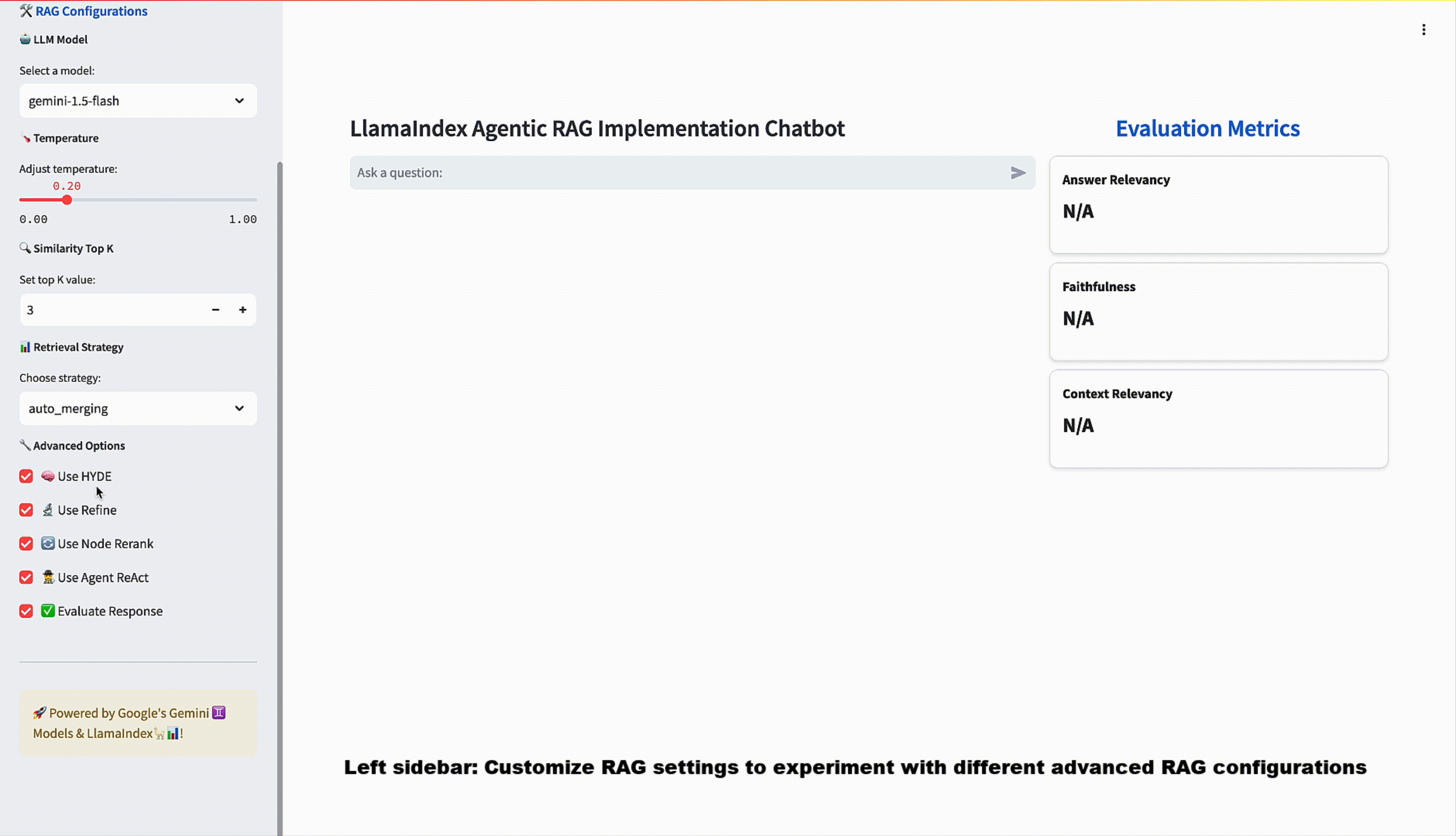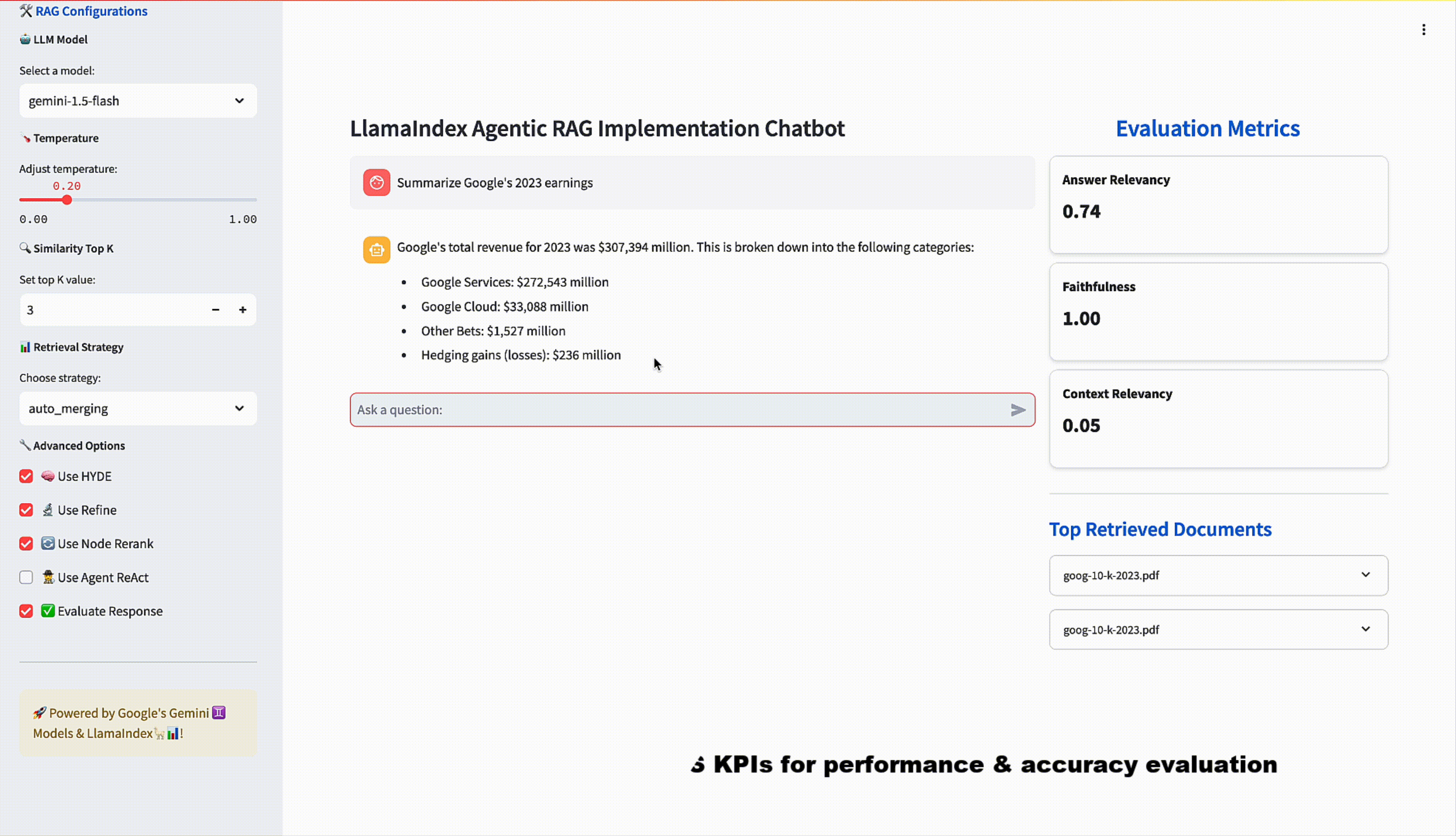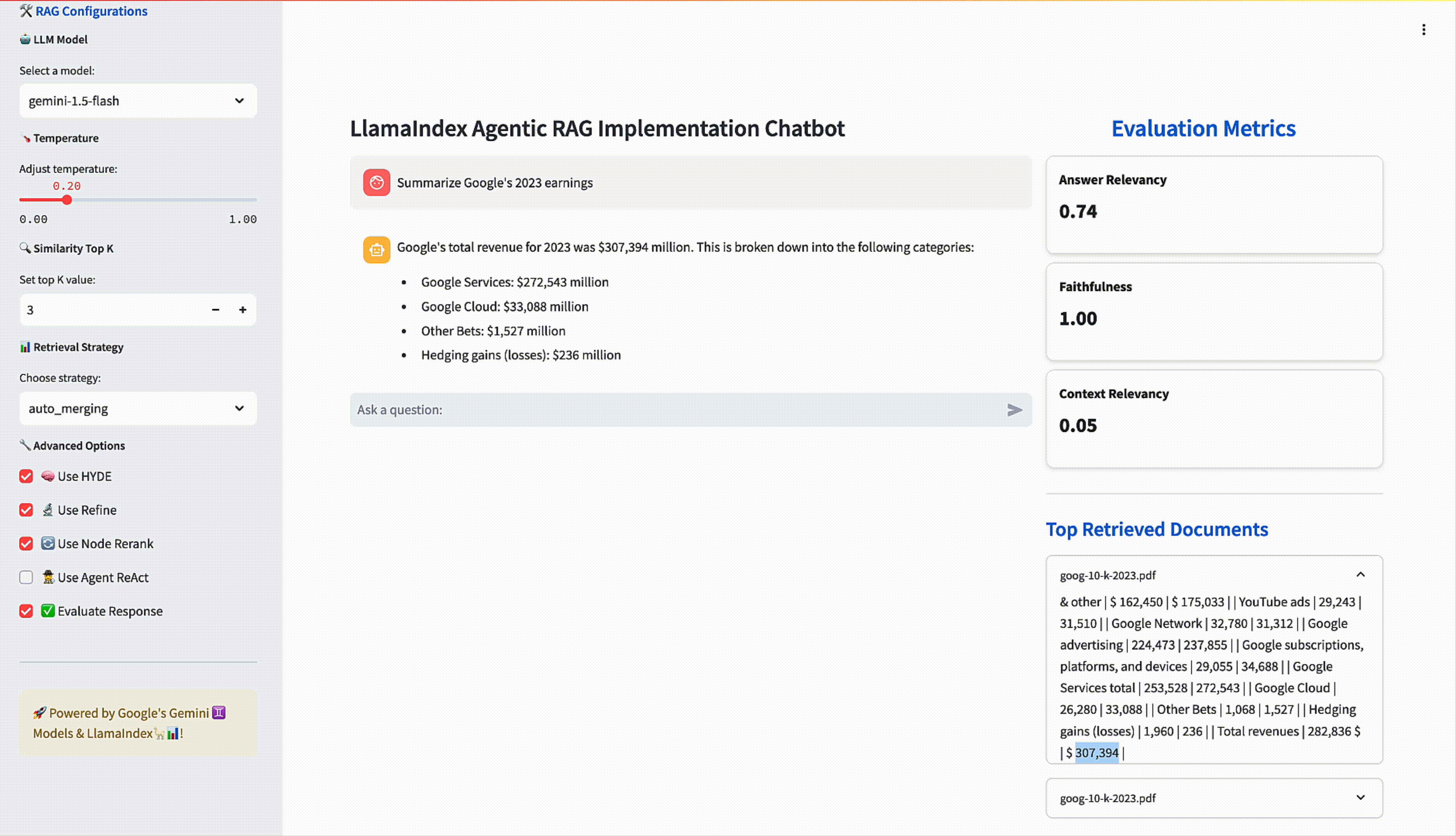
Explore the interactive chat experience provided by our full-stack application

Dive into the comprehensive batch evaluation process
RAG design and LlamaIndex
LlamaIndex is a powerful framework for building RAG applications. It simplifies the process of connecting to data sources, structuring information, and querying with LLMs..Here's how LlamaIndex breaks down the RAG workflow::
-
Indexing and storage - how do we chunk, embed, organize and structure the documents we want to query.
-
Retrieval - how do we retrieve relevant document chunks for a given user query. In LlamaIndex, chunks of documents retrieved from an index are called nodes.
-
Node (chunk) post-processing - given a set of relevant nodes, further process them to make them more relevant (e.g. re-ranking them).
-
Response synthesis - given a final set of relevant nodes, curate a response for the user.
LlamaIndex offers a wide variety of techniques and integrations to complete these steps, from simple keyword search all the way to agentic approaches. The list of techniques can be quite overwhelming at first, so it’s better to think of each step in terms of the trade-offs you’re making and the trying core questions you’re trying to address:
-
Indexing and storage: What is the structure/nature of documents we want to query?
-
Retrieval: Are the right documents being retrieved?
-
Node (chunk) post-processing: Are the raw retrieved documents in the right order and format for the LLM to curate a response?
-
Response synthesis: Are responses relevant to the query and faithful to the documents provided?
For each of these questions in the RAG design lifecycle, let's walk through sampling of proven techniques.
Indexing and storage
Indexing and storage consists of its own labyrinth of complex steps. You are faced with multiple choices for algorithms; techniques for parsing, chunking, and embedding; metadata extraction considerations; and the need to create separate indices for heterogeneous data sources. As complex as it may seem, in the end, indexing and storage is all about taking some group of documents, pre-processing them in such a way that a retrieval system can grab relevant chunks of those documents, and storing those pre-processed documents somewhere.
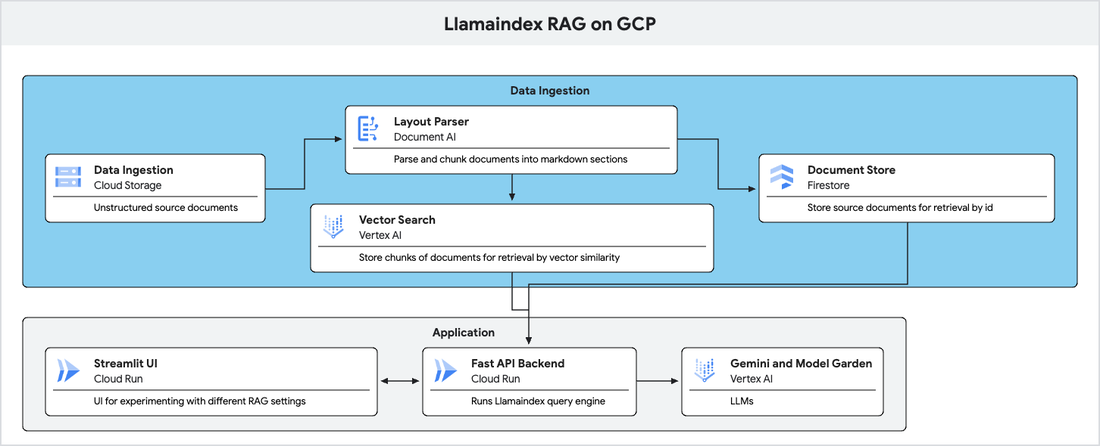
To help avoid much of the headache of choosing what path to take, Google Cloud provides the Document AI Layout Parser, which can process various file types including HTML, PDF, DOCX, and PPTX (in preview), identifying a wide range of content elements such as text blocks, paragraphs, tables, lists, titles, headings, and page headers and footers out of the box. By conducting a comprehensive layout analysis, Layout Parser maintains the document's organizational hierarchy, which is crucial for context-aware information retrieval. See the full code for implementation of DocAI Layout parser here
Once documents are chunked, we must then create LlamaIndex nodes from them. LlamaIndex nodes include metadata fields that can keep track of the structure of their parent documents. For instance, a long document split into consecutive chunks could be represented as a doubly-linked list in LlamaIndex as a list of nodes with PREV and NEXT relationships set to the previous and next node IDs.
Once we have LLamaIndex nodes, we can employ techniques to pre-process them before embedding for more advanced retrieval techniques (like auto-merging retrieval below). The Hierarchical Node Parser takes a list of nodes from a document and creates a hierarchy of nodes where smaller chunks link to larger chunks up the hierarchy. We might leaf chunks of 512 characters and link to parent chunks of 1024, and so on where each level up the hierarchy represents a larger and larger section of a given document. When we store this hierarchy, we only embed the leaf chunks and store the rest in a document store where we can query them by ID. At retrieval time, we perform vector similarity only on leaf chunks, and use the hierarchy relationship to obtain larger sections of the document for additional context. This logic is performed by the LlamaIndex Auto-merging Retriever.
We can then embed the nodes and choose how and where to store them for downstream retrieval. A vector database is an obvious choice, but we may need to store documents in another way to facilitate other search methods to combine with semantic retrieval — for instance, hybrid search. For this example, we illustrate how to create a hybrid store where we need to store document chunks both as embedded vectors and as a key-value store in Google Cloud’s Vertex AI Vector Store and Firestore, respectively. This has utility when we need to query documents by either vector similarity or an id/metadata match.
We should create multiple indices to explore the differences between combinations of approaches. For instance, we can create a flat, non-hierarchical index of fixed-sized chunks in addition to the hierarchical one.
Retrieval
Retrieval is the task of obtaining a small set of relevant documents from our vector store/docstore combination, which an LLM can use as context to curate a relevant response. The Retriever module in LlamaIndex provides a nice abstraction of this task. Subclasses of this module implement the _retrieve method, which takes as an argument a query and returns a list of NodesWithScore — basically a list of document chunks with a score indicating their relevance to the question. LlamaIndex has many popular implementations of retrievers. It is always good to try a baseline retriever that simply does vector similarity search to retrieve a specified top k number of NodesWithScore.
Auto-merging retrieval
The above baseline_retriever does not incorporate the structure of the hierarchical index we created earlier. An auto-merging retriever allows the retrieval of nodes not just based on vector similarity, but also based on the source document from which they came, through the hierarchy of chunks that we maintain in a document store. This allows us to retrieve additional content that may encapsulate the initial set of node chunks. For instance, a baseline_retriever may retrieve five node chunks based on vector similarity. Those chunks may be quite small (e.g., 512 characters) and if our query is complex, may not contain everything needed to answer the query properly. Of the five chunks returned, three may come from the same document and may be referencing different paragraphs of a single section. Because we stored the hierarchy of these chunks, their relation to larger chunks, and together they comprise the larger section, the auto-merging retriever can “walk” the hierarchy, retrieving the larger chunks and returning a larger section of the document for the LLM to compose a response. This balances out the trade-off between retrieval accuracy that comes with smaller chunk sizes and supplying the LLM with as much relevant data as possible.
LlamaIndex Query Engine
Now that we have a set of NodesWithScores, we need to assess if they are in the optimal order. You may want to do additional post-processing like removing PII or formatting. Finally we need to pass these chunks to an LLM which will provide an answer catered to the user’s original intention. Orchestration of retrieval with node post-processing and response synthesis happens through the LlamaIndex QueryEngine. You create a QueryEngine by first defining a retriever, a node-post-processing method (if any) and a response synthesizer and passing them in as arguments. QueryEngine exposes the query and aquery (asynchronous equivalent of query) methods, which take as input a string query and return a Response object, which includes not only the LLM-generated answer, but the list of NodeWithScores (the chunks passed to the LLM as context).
Hypothetical document embedding
Most Llama-index retrievers perform retrieval by embedding the user’s query and computing the vector similarity between the query’s embedding with those in the vector store. However, this can be suboptimal due to the fact that the linguistic structure of the question may differ significantly from that of the answer. Hypothetical document embedding (HyDE) is a technique that attempts to address this by using LLM hallucination as a strength. The idea is to first hallucinate a response to the user’s query, without any provided context, and then embed the hallucinated answer as the basis for vector similarity search in the vector store.
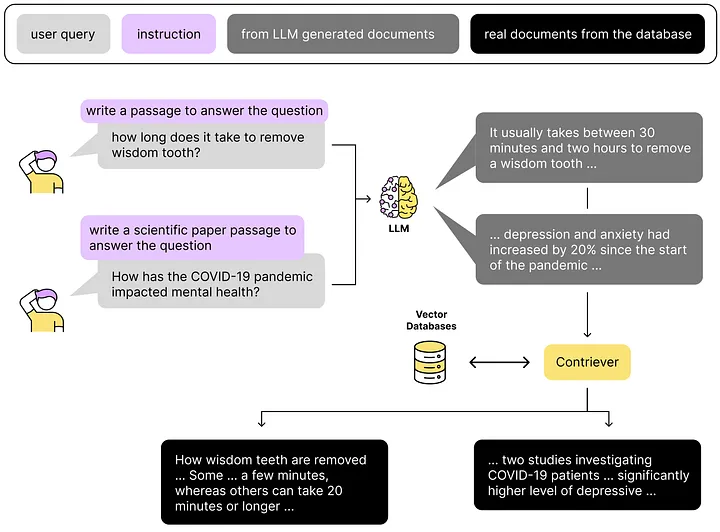
LLM node re-ranking
A Node Post-Processor in Llamaindex implements a _postprocess_nodes method, which takes as input the query and the list of NodesWithScores and returns a new list of NodesWithScores. The initial set of nodes obtained from the retriever may not be ranked optimally and it can be beneficial to perform reranking where we re-sort the nodes by relevance determined by an LLM. There exist explicit models fine-tuned explicitly for the purpose of re-ranking chunks for a given query, or we can use a generic LLM to do the re-ranking for us. We can use a prompt like below to ask an LLM to rank nodes from a retriever:
For an example of a custom LLM re-ranker class, see the gitlab repo.
Response synthesis
There are many ways to instruct an LLM to create a response given a list of NodeWithScores. If the nodes are especially large, we might want to condense the nodes via summarization before asking the LLM to give a final response. Or given an initial response, we might want to give the LLM another chance to refine it or correct any errors that may be present. The ResponseSynthesizer in LlamaIndex lets us determine how the LLM will formulate a response given a list of nodes.
ReAct agent
Reasoning and acting or ReAct (Yao, et al. 2022) introduces a reasoning loop on top of the query pipeline we have created. This allows an LLM to perform chain-of-thought reasoning to address complex queries or queries that may require multiple retrieval steps in order to get a correct answer. To implement a ReAct loop in Llamaindex we expose the query_engine created above as a tool which the ReAct agent can use as part of the reasoning and acting procedure. You can add multiple tools here to allow the ReAct agent to choose among them or consolidate results among many.
Creating the Final QueryEngine
Once you’ve decided on a few approaches across the steps outlined above, you will need to create logic to instantiate your QueryEngine based on an input configuration. You can find an example function here.
Evaluation metrics and techniques
Once we have a QueryEngine object, we have a simple way of passing queries and obtaining answers and associated context from the RAG pipeline. We can then go on to implement the QueryEngine object as part of a backend service such as FastAPI along with a simple front-end, which would allow us to experiment with this object in different ways (i.e., conversation vs. batch).
When chatting with the RAG pipeline, three pieces of information can be used to evaluate the response: the query, the retrieved context, and of course, the response. We can use these three fields to calculate evaluation metrics and help us compare responses more quantitatively. RAGAS is a framework which provides some out-of-the-box, heuristic metrics that can be computed given this triple, namely answer faithfulness, answer relevancy, and context relevancy. We compute these on the fly with each chat interaction and display them for the user.
Ideally, in parallel, we would attempt to obtain ground-truth answers as well through expert annotation. With ground truth, we can tell a lot more about how the RAG pipeline is performing. We can calculate LLM-graded accuracy, where we ask an LLM about whether the answer is consistent with the ground truth or calculate a variety of other metrics from RAGAS such as context precision and recall. Below is a summary of the metrics we can calculate as part of our evaluation:
Deployment
The FastAPI backend will implement two routes: /query_rag and /eval_batch. query_rag/ is used for one-shot chats with the query-engine with the option to perform evaluation on the answer on the fly. /eval_batch allows users to choose an eval_set from a Cloud Storage bucket and run batch evaluation on the dataset using the given query engine parameters.
Streamlit’s Chat elements make it very easy to spin up a UI, allowing us to interact with the QueryEngine object via a FastAPI backend, along with setting sliders and input forms to match the configurations we set forth earlier.
Click here for the full code repo.
Conclusion
In summary, building an advanced RAG application on GCP utilizing modular tools such as LlamaIndex, RAGAS, FastAPI and streamlit allow you maximum flexibility as you explore different techniques and tweak various aspects of the RAG pipeline. With any luck, you may end up finding that magical combination of parameters, prompts, and algorithms which can comprise the “XGBoost” equivalent for your RAG problem.



