Enhancing your gen AI use case with Vertex AI embeddings and task types
Parashar Shah
Product Manager
Kaz Sato
Developer Advocate, Cloud AI
Retrieval Augmented Generation (RAG) is a powerful technique for enhancing large language models (LLMs) by grounding them in external knowledge sources. This blog post looks into a common challenge in RAG implementations: achieving high-quality semantic search. We'll explore why traditional similarity search often falls short, and how new "task type" embeddings in Vertex AI offer a streamlined solution to significantly improve the accuracy and effectiveness of your RAG system.
Questions and answers are not “similar”
When building Retrieval Augmented Generation (RAG) systems, most designs we’ve seen use text embeddings and vector search to conduct a semantic similarity search. In many cases, this leads to degraded search quality, because of the "question is not the answer" problem. For example, a question like "Why is the sky blue?" and its answer, "The scattering of sunlight causes the blue color", have distinctly different meanings as separate statements. Likewise, if you ask "What's the best birthday present for my kid?" to a RAG system with a similarity search, it would be hard to find items like "Nintendo Switch" or "Lego sets", as those answers are not semantically similar to the question.
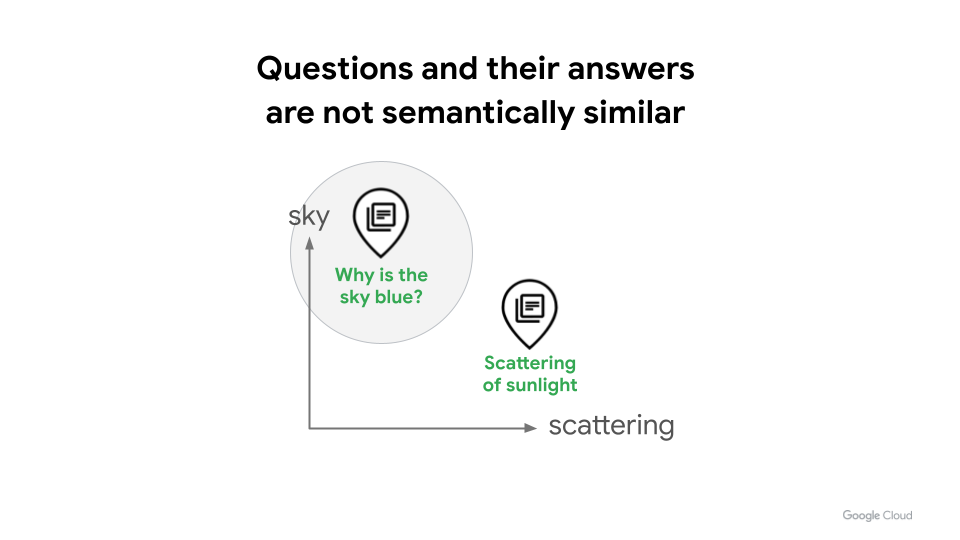
Technically speaking, the distribution of the question embedding space and answer embedding space have a major gap, and the simple similarity search doesn't work well. To fill the gap, you need to have an AI/ML model that learns the relationship between the query and answer.
The history of "filling the gap"
This is actually a classic problem of semantic search for information retrieval, and Google has a long history of optimizing the semantic search quality for billions of users. Google Search started incorporating semantic search in 2015, with the introduction of AI search innovations like our deep learning ranking system RankBrain. This innovation was quickly followed with neural matching to improve the accuracy of document retrieval in Search. Neural matching contains deep learning models that learn the relationship between the query intention and relevant documents. For example, a vague search query like “insights how to manage a green”. If a friend asked you this, you’d probably be stumped. But with neural matching, Google search is able to make sense of it.

Google Search can find relevant documents
for an ambiguous query "how to manage a green"
Dual encoder model
For developers that want to incorporate sophisticated semantic search like neural matching into their RAG system the popular approach has been to train a dual encoder model (aka two-tower) that learns the relationship between the query embeddings and answer embeddings. The following diagram depicts how a dual encoder model maps queries with relevant documents.
But it is not easy to design, train and build a production retrieval system with a customized dual encoder model. It requires data science and ML engineering experience, and significant effort to train a dataset with pairs of questions and answers.
LLM-based "Advanced RAG"
In the era of Large Language Models (LLM), some "Advanced RAG" approaches emerged to solve this problem. HyDE uses LLM reasoning capabilities to generate possible answer texts, and use the text for similarity search. Additionally, query expansion with LLM uses the LLM reasoning for expanding the original query with possible answer candidates as query texts.
The downside of these LLM-based approaches is that it adds the LLM prediction latency and high cost for every query. While the vector search itself can finish within milliseconds, and can handle thousands of queries per second at low cost, the LLM reasoning will add a few seconds latency for every single query with significantly higher cost than generating embeddings.
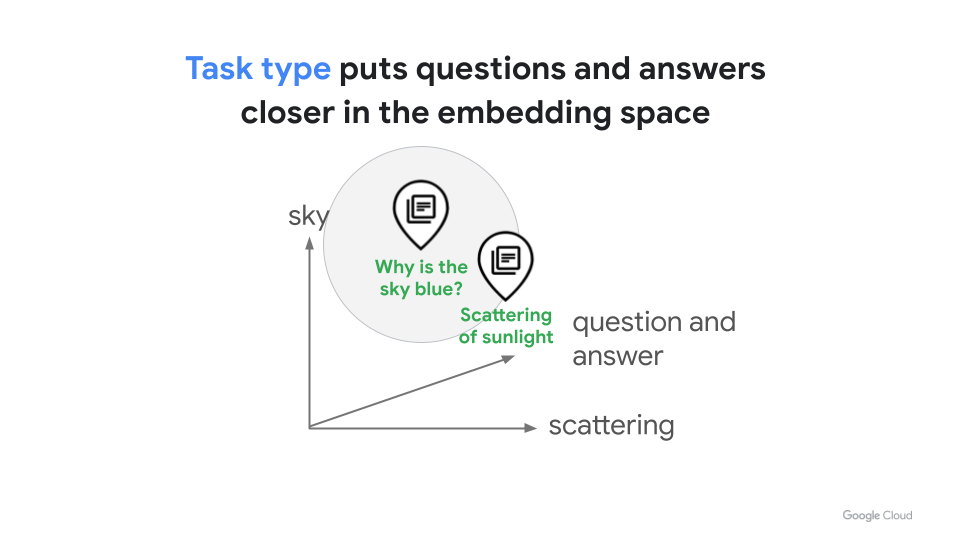
New "task type" embedding
Recently Vertex AI Embeddings API launched new text embedding models, "text-embedding-004" and "text-multilingual-embedding-002" based on the new embedding models developed by the Google DeepMind and Research team.
The unique feature of these models is that they can generate optimized embeddings based on task types. With task types, you don't have to build your own dual encoder models or advanced RAG systems - significantly reducing the time and cost to improve the search quality for specific tasks like question and answering, document retrieval by query, fact verification, etc.
For example, to generate embeddings for question and answering, all you have to do is to specify a task type QUESTION_ANSWERING for query texts and RETRIEVAL_DOCUMENT for answer texts when generating their embeddings. In the embedding space optimized with the task types, the query embedding "Why is the sky blue?" and the answer embedding "The scattering..." will be placed much closer together, because the embedding models are trained to learn that they have the question-and-answer relationship. Thus you should be able to get higher search quality with vector databases to find the right answer for the query.
Behind the scene: LLM distillation + dual encoder
How do the new embedding models enable this? The novel part of the model design is that the Google DeepMind and Research team used LLM distillation (a process to train a smaller model from a larger model) to pre-train a dual encoder based embedding model.
Here's the distillation steps. The team used an LLM for generating two kinds of data: 1) synthetic queries and 2) query-and-document pairs. First, the team generated numerous synthetic queries from the training dataset (corpus) for each task.

Then, with the generated queries, find possibly relevant documents to create query-and-document pairs. For those pairs, use the LLM to determine if the pair is considered as an appropriate query-and-document (positive pair), or not (negative pair).

With those pairs, the team trained a dual-encoder based embedding model. The result is an embedding model that inherits a subset of the reasoning capability of the LLM as a distilled model for the specific tasks. Significantly smaller, faster and inexpensive to generate embeddings, and yet, provides the capability of smart matching between queries and relevant documents.
Task types improve search quality
With the novel approach, the new embedding model provides optimized performance for each task. Let’s demonstrate this with an example; consider this question "What is the best birthday present for my son?". As an answer to this question, we prepared two example answers: "My son says Taylor Swift's birthday is December 13th" (which doesn't answer to the question) and "Lego set" (an appropriate answer), and we generate two distinct sets of embeddings for them, one for the task SEMANTIC_SIMILARITY and one for QUESTION_ANSWERING . With a task type SEMANTIC_SIMILARITY, the first answer has higher similarity to the question because both phrases discuss “birthdays” and “my son”. It’s similar but not the expected answer for the question. By specifying a task type QUESTION_ANSWERING, the second answer gets much higher similarity than the first as the embedding space captures the question-and-answer relationships inherited from the LLM.


Search quality is improved significantly with task types (MRR measurements with NQ-Open dataset)
You can try the examples above with a sample notebook Using "task type" embeddings for improving RAG search quality. If you are interested in more details of the model design and other performance comparison results, check out the paper published by the DeepMind team.
Supported task types
The new embeddings models support the following task types:
For example, if you are building a RAG system for a question and answering use case, you may specify task type RETRIEVAL_DOCUMENT for generating embeddings for building with vector search, and specify QUESTION_ANSWERING for embeddings for question texts. Thus you should see improved search quality compared to using SEMANTIC_SIMILARITY for both query and document. Likewise, you may use RETRIEVAL_QUERY for queries for document search, and FACT_VERIFICATION for queries for finding documents for fact checking. If your RAG system has to support multiple tasks, you can let the LLM to specify an appropriate task type when generating a query for the retrieval.
Not only the document retrieval and Q&A use cases, but also Embedding models support optimized embeddings for text classification and clustering. Embeddings with task type CLASSIFICATION are useful for classifying texts with its semantics for use cases such as customer and product segmentation.
Using task types is quite easy. The following code generates embeddings for a question "Why is the sky blue?" with a task type QUESTION_ANSWERING:
This will print out the embeddings like:
New task type for code retrieval
With the latest model "text-embedding-preview-0815", we launched a new task type CODE_RETRIEVAL_QUERY as a preview release.
This task type can be used to retrieve relevant code blocks using plain text queries. To use this feature, code blocks should be embedded using the RETRIEVAL_DOCUMENT task type, while text queries embedded using CODE_RETRIEVAL_QUERY:
These embeddings are optimized for finding code blocks with a text query, like the example "A Python function to print Fibonacci numbers".
Getting Started
As we saw, Google has been tackling this issue to optimize the semantic search quality of its largest services for many years, and the knowledge and expertise is packaged as easy-to-use "task type" embedding models. These solutions can help you build your RAG or enterprise search systems and improve the user experience of gen AI applications.
To get started with task type embeddings, try a sample notebook Using "task type" embeddings for improving RAG search quality. Also, here's a list of resources to get started with the new embedding models and use vector search with it.



