En este documento, se explica cómo usar Google Kubernetes Engine (GKE) para implementar un framework de prueba de carga distribuida que use varios contenedores para crear tráfico para una API simple basada en REST. En este documento, se realizan pruebas de carga a una aplicación web implementada en App Engine que expone extremos de estilo REST para responder a las solicitudes HTTP POST entrantes.
Puedes usar este mismo patrón con el fin de frameworks de pruebas de carga para una variedad de situaciones y aplicaciones, como los sistemas de mensajería, los sistemas de administración de flujos de datos y los sistemas de bases de datos.
Objetivos
- Definir variables de entorno para controlar la configuración de implementación
- Crear un clúster de GKE
- Realizar pruebas de carga
- Escalar la cantidad de usuarios o extender el patrón para otros casos prácticos, opcionalmente
Costos
En este documento, usarás los siguientes componentes facturables de Google Cloud:
- App Engine
- Artifact Registry
- Cloud Build
- Cloud Storage
- Google Kubernetes Engine
Para generar una estimación de costos en función del uso previsto, usa la calculadora de precios.
Antes de comenzar
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
Enable the App Engine, Artifact Registry, Cloud Build, Compute Engine, Resource Manager, Google Kubernetes Engine, and Identity and Access Management APIs.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
Enable the App Engine, Artifact Registry, Cloud Build, Compute Engine, Resource Manager, Google Kubernetes Engine, and Identity and Access Management APIs.
-
Grant roles to your user account. Run the following command once for each of the following IAM roles:
roles/serviceusage.serviceUsageAdmin, roles/container.admin, roles/appengine.appAdmin, roles/appengine.appCreator, roles/artifactregistry.admin, roles/resourcemanager.projectIamAdmin, roles/compute.instanceAdmin.v1, roles/iam.serviceAccountUser, roles/cloudbuild.builds.builder, roles/iam.serviceAccountAdmingcloud projects add-iam-policy-binding PROJECT_ID --member="user:USER_IDENTIFIER" --role=ROLE
- Replace
PROJECT_IDwith your project ID. -
Replace
USER_IDENTIFIERwith the identifier for your user account. For example,user:myemail@example.com. - Replace
ROLEwith each individual role.
- Replace
- La imagen de contenedor de Locust Docker
- El mecanismo de organización y administración de contenedores
- Implementa un principal de prueba de carga, que Locust denomina principal.
- Implementa un grupo de trabajadores de pruebas de carga. Con estos trabajadores de pruebas de carga, puedes crear una cantidad sustancial de tráfico para fines de prueba.
8089para la interfaz web5557y5558para comunicarse con los trabajadoresAbre Cloud Shell:
Ejecuta todos los comandos de terminal de este documento desde Cloud Shell.
Configura las variables de entorno que requieran personalización:
export GKE_CLUSTER=GKE_CLUSTER export AR_REPO=AR_REPO export REGION=REGION export ZONE=ZONE export SAMPLE_APP_LOCATION=SAMPLE_APP_LOCATION
Reemplaza lo siguiente:
GKE_CLUSTER: Es el nombre del clúster de GKE.AR_REPO: Es el nombre de tu repositorio de Artifact Registry.REGION: Es la región en la que se creará el repositorio de clúster de GKE y el repositorio de Artifact Registry.ZONE: La zona de tu región en la que se creará tu instancia de Compute Engine.SAMPLE_APP_LOCATION: la ubicación(regional) en la que se implementará tu aplicación de App Engine de ejemplo
Los comandos deben ser similares al siguiente ejemplo:
export GKE_CLUSTER=gke-lt-cluster export AR_REPO=dist-lt-repo export REGION=us-central1 export ZONE=us-central1-b export SAMPLE_APP_LOCATION=us-central
Configura las siguientes variables de entorno adicionales:
export GKE_NODE_TYPE=e2-standard-4 export GKE_SCOPE="https://www.googleapis.com/auth/cloud-platform" export PROJECT=$(gcloud config get-value project) export SAMPLE_APP_TARGET=${PROJECT}.appspot.comEstablece la zona predeterminada para que no tengas que especificar estos valores en los comandos posteriores:
gcloud config set compute/zone ${ZONE}Crea una cuenta de servicio con los permisos mínimos que requiere el clúster:
gcloud iam service-accounts create dist-lt-svc-acc gcloud projects add-iam-policy-binding ${PROJECT} --member=serviceAccount:dist-lt-svc-acc@${PROJECT}.iam.gserviceaccount.com --role=roles/artifactregistry.reader gcloud projects add-iam-policy-binding ${PROJECT} --member=serviceAccount:dist-lt-svc-acc@${PROJECT}.iam.gserviceaccount.com --role=roles/container.nodeServiceAccountCrea el clúster de GKE:
gcloud container clusters create ${GKE_CLUSTER} \ --service-account=dist-lt-svc-acc@${PROJECT}.iam.gserviceaccount.com \ --region ${REGION} \ --machine-type ${GKE_NODE_TYPE} \ --enable-autoscaling \ --num-nodes 3 \ --min-nodes 3 \ --max-nodes 10 \ --scopes "${GKE_SCOPE}"Conéctate al clúster de GKE:
gcloud container clusters get-credentials ${GKE_CLUSTER} \ --region ${REGION} \ --project ${PROJECT}Clona el repositorio de muestra de GitHub:
git clone https://github.com/GoogleCloudPlatform/distributed-load-testing-using-kubernetes
Cambia tu directorio de trabajo al repositorio clonado:
cd distributed-load-testing-using-kubernetes
Crea un repositorio de Artifact Registry:
gcloud artifacts repositories create ${AR_REPO} \ --repository-format=docker \ --location=${REGION} \ --description="Distributed load testing with GKE and Locust"
Compila la imagen del contenedor y guárdala en tu repositorio de Artifact Registry:
export LOCUST_IMAGE_NAME=locust-tasks export LOCUST_IMAGE_TAG=latest gcloud builds submit \ --tag ${REGION}-docker.pkg.dev/${PROJECT}/${AR_REPO}/${LOCUST_IMAGE_NAME}:${LOCUST_IMAGE_TAG} \ docker-imageLa imagen de Docker de Locust que se encuentra adjunta incorpora una tarea de prueba que llama a los extremos
/loginy/metricsen la aplicación de muestra. En este conjunto de tareas de prueba de ejemplo, la proporción respectiva de las solicitudes enviadas a estos dos extremos será1a999.Verifica que la imagen de Docker esté en tu repositorio de Artifact Registry:
gcloud artifacts docker images list ${REGION}-docker.pkg.dev/${PROJECT}/${AR_REPO} | \ grep ${LOCUST_IMAGE_NAME}El resultado es similar a este:
Listing items under project
PROJECT, locationREGION, repositoryAR_REPOREGION-docker.pkg.dev/PROJECT/AR_REPO/locust-tasks sha256:796d4be067eae7c82d41824791289045789182958913e57c0ef40e8d5ddcf283 2022-04-13T01:55:02 2022-04-13T01:55:02Crea y, luego, implementa la aplicación web de muestra como App Engine:
gcloud app create --region=${SAMPLE_APP_LOCATION} gcloud app deploy sample-webapp/app.yaml \ --project=${PROJECT}Cuando se te solicite, escribe
ypara continuar con la implementación.El resultado es similar a este:
File upload done. Updating service [default]...done. Setting traffic split for service [default]...done. Deployed service [default] to [https://
PROJECT.appspot.com]La aplicación de App Engine de ejemplo implementa los extremos
/loginy/metrics:Sustituye los valores de las variables de entorno por los parámetros de imagen, proyecto y host de destino en los archivos
locust-master-controller.yamlylocust-worker-controller.yaml, y crea las implementaciones principales y de trabajador de Locust:envsubst < kubernetes-config/locust-master-controller.yaml.tpl | kubectl apply -f - envsubst < kubernetes-config/locust-worker-controller.yaml.tpl | kubectl apply -f - envsubst < kubernetes-config/locust-master-service.yaml.tpl | kubectl apply -f -
Verifica las implementaciones de Locust:
kubectl get pods -o wide
El resultado presenta el siguiente aspecto:
NAME READY STATUS RESTARTS AGE IP NODE locust-master-87f8ffd56-pxmsk 1/1 Running 0 1m 10.32.2.6 gke-gke-load-test-default-pool-96a3f394 locust-worker-58879b475c-279q9 1/1 Running 0 1m 10.32.1.5 gke-gke-load-test-default-pool-96a3f394 locust-worker-58879b475c-9frbw 1/1 Running 0 1m 10.32.2.8 gke-gke-load-test-default-pool-96a3f394 locust-worker-58879b475c-dppmz 1/1 Running 0 1m 10.32.2.7 gke-gke-load-test-default-pool-96a3f394 locust-worker-58879b475c-g8tzf 1/1 Running 0 1m 10.32.0.11 gke-gke-load-test-default-pool-96a3f394 locust-worker-58879b475c-qcscq 1/1 Running 0 1m 10.32.1.4 gke-gke-load-test-default-pool-96a3f394Verifica los Services:
kubectl get services
El resultado presenta el siguiente aspecto:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubernetes ClusterIP 10.87.240.1 <none> 443/TCP 12m locust-master ClusterIP 10.87.245.22 <none> 5557/TCP,5558/TCP 1m locust-master-web LoadBalancer 10.87.246.225 <pending> 8089:31454/TCP 1mEjecuta un bucle de observación mientras la dirección IP interna del balanceador de cargas de red de transferencia interno (dirección IP externa de GKE) se aprovisiona para el Service de aplicación web principal de Locust:
kubectl get svc locust-master-web --watch
Presiona
Ctrl+Cpara salir del bucle de observación una vez que se aprovisiona una dirección EXTERNAL-IP.Toma nota de la dirección IP del balanceador de cargas interno del servicio de host web:
export INTERNAL_LB_IP=$(kubectl get svc locust-master-web \ -o jsonpath="{.status.loadBalancer.ingress[0].ip}") && \ echo $INTERNAL_LB_IPSegún tu configuración de red, hay dos formas de conectarte a la aplicación web de Locust a través de la dirección IP aprovisionada:
Enrutamiento de red. Si la red está configurada para permitir el enrutamiento desde la estación de trabajo a la red de VPC del proyecto, puedes acceder directamente a la dirección IP del balanceador de cargas de red de transferencia interno desde la estación de trabajo.
Proxy y túnel SSH. Si no hay una ruta de red entre tu estación de trabajo y tu red de VPC, puedes enrutar el tráfico a la dirección IP del balanceador de cargas de red de transferencia interno si creas una instancia de Compute Engine con un proxy
nginxy un túnel SSH entre tu estación de trabajo y la instancia.
Configura una variable de entorno con el nombre de la instancia.
export PROXY_VM=locust-nginx-proxy
Inicia una instancia con un contenedor de Docker
ngnixconfigurado para usar un proxy en el puerto de aplicación web Locust8089en el balanceador de cargas de red de transferencia interno:gcloud compute instances create-with-container ${PROXY_VM} \ --zone ${ZONE} \ --container-image gcr.io/cloud-marketplace/google/nginx1:latest \ --container-mount-host-path=host-path=/tmp/server.conf,mount-path=/etc/nginx/conf.d/default.conf \ --metadata=startup-script="#! /bin/bash cat <<EOF > /tmp/server.conf server { listen 8089; location / { proxy_pass http://${INTERNAL_LB_IP}:8089; } } EOF"Abre un túnel SSH desde Cloud Shell a la instancia de proxy:
gcloud compute ssh --zone ${ZONE} ${PROXY_VM} \ -- -N -L 8089:localhost:8089Haz clic en el ícono Vista previa en la Web (
 ) y selecciona Cambiar puerto en las opciones mencionadas.
) y selecciona Cambiar puerto en las opciones mencionadas.En el cuadro de diálogo Cambiar puerto de vista previa, ingresa 8089 en el campo Número de puerto y selecciona Cambiar y obtener vista previa.
En un momento, se abrirá una pestaña del navegador con la interfaz web de Locust.
Después de abrir el frontend de Locust en tu navegador, verás un cuadro de diálogo que se puede usar para iniciar una nueva prueba de carga.
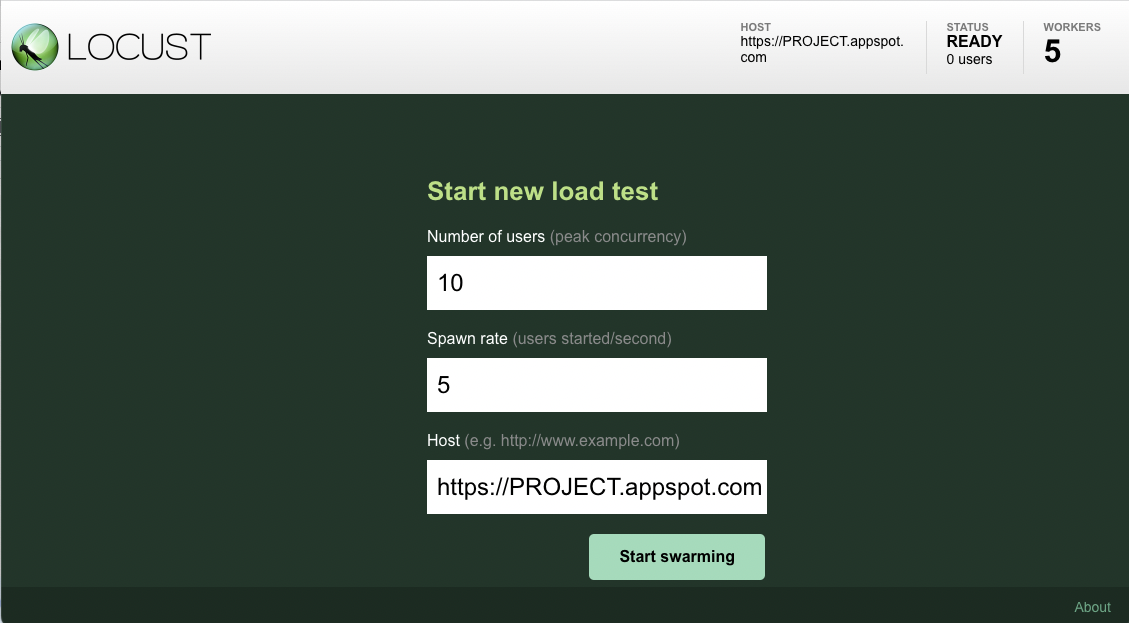
Especifica la cantidad total de usuarios (simultaneidad máxima) como
10y la tasa de generación (usuarios iniciados/segundo) como usuarios de5por segundo.A continuación, haz clic en Comenzar a generar (Start swarming) para comenzar la simulación.
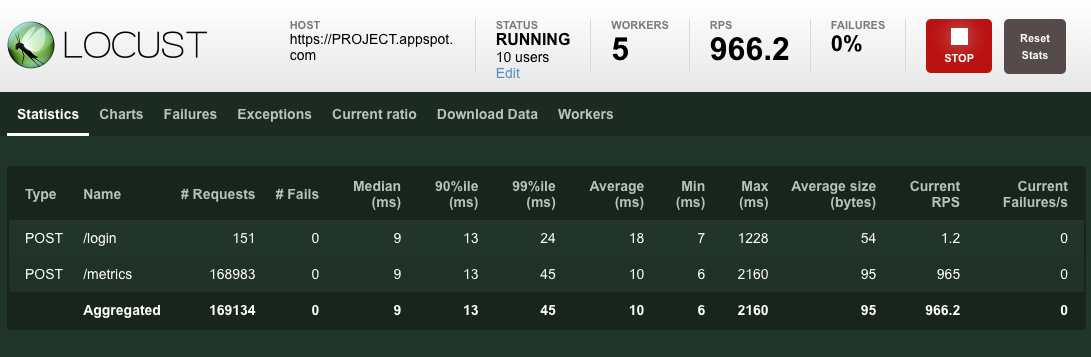
Después de que las solicitudes comienzan a generarse, las estadísticas empiezan a agregarse para las métricas de simulación, como la cantidad de solicitudes y las solicitudes por segundo, como se muestra en la siguiente imagen:
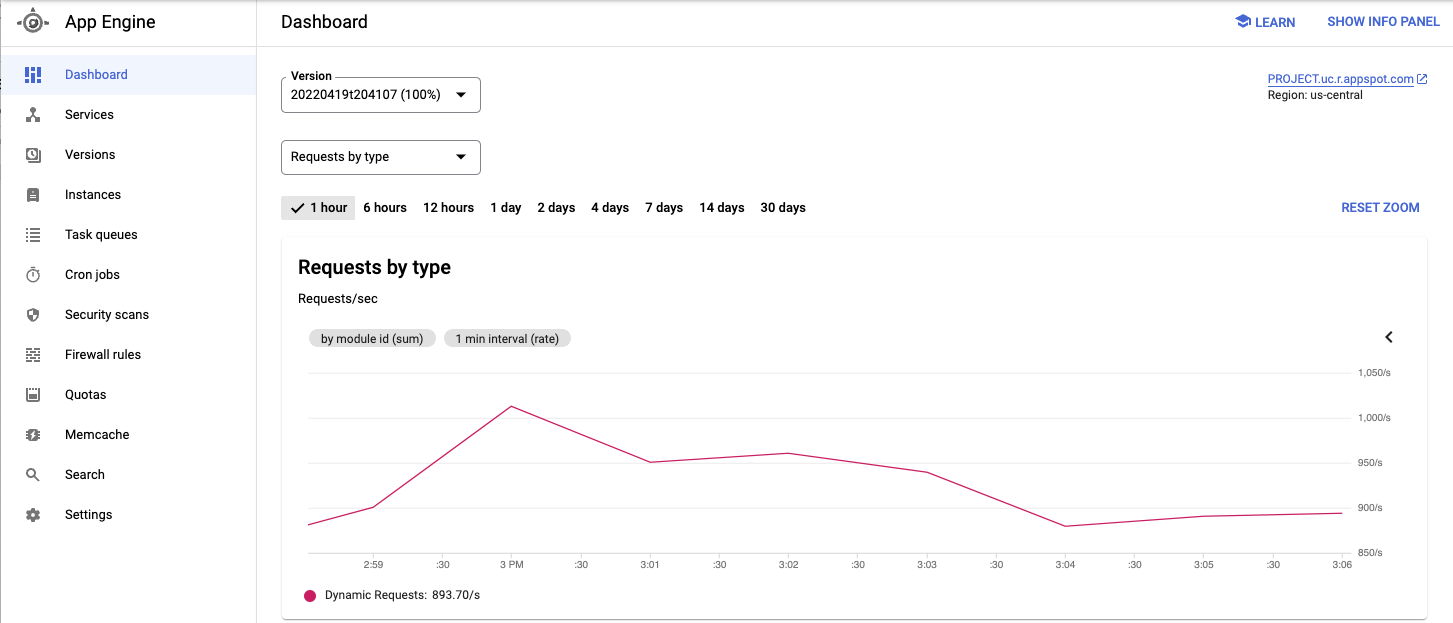
Consulta el servicio implementado y otras métricas desde la consola deGoogle Cloud .
Cuando hayas observado el comportamiento de la aplicación sometida a prueba, haz clic en Detener para terminar la prueba.
Escala el grupo de pods trabajadores de Locust a 20.
kubectl scale deployment/locust-worker --replicas=20
Implementa e inicia los Pods nuevos lleva unos minutos.
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
- Cómo compilar aplicaciones web escalables y resistentes.
- Revisa la documentación de GKE con más detalle.
- Prueba los instructivos sobre GKE.
- Para obtener más información sobre las arquitecturas de referencia, los diagramas y las prácticas recomendadas, explora Cloud Architecture Center.
Cuando finalices las tareas que se describen en este documento, puedes borrar los recursos que creaste para evitar que continúe la facturación. Para obtener más información, consulta Cómo realizar una limpieza.
Carga de trabajo de ejemplo
En el siguiente diagrama, se muestra una carga de trabajo de ejemplo en la que las solicitudes van del cliente a la aplicación.

Para modelar esta interacción, puedes usar Locust, una herramienta de prueba de carga distribuida basada en Python que puede distribuir solicitudes a través de varias rutas de destino. Por ejemplo, Locust puede distribuir solicitudes a las rutas de destino /login y /metrics. La carga de trabajo se modela como un conjunto de tareas en Locust.
Arquitectura
Esta arquitectura incluye dos componentes principales:
La imagen de contenedor de Locust Docker contiene el software Locust. El Dockerfile, que se obtiene después de clonar el repositorio de GitHub que acompaña a este documento, utiliza una imagen de Python básica y también incluye secuencias de comandos para iniciar el servicio de Locust y ejecutar las tareas. Para aproximarse a los clientes del mundo real, cada tarea de Locust está ponderada. Por ejemplo, el registro se realiza una vez por cada mil solicitudes totales de clientes.
GKE proporciona organización y administración de contenedores. Con GKE, puedes especificar el número de nodos de contenedor que proporcionan la base para tu framework de pruebas de carga. También puedes organizar tus trabajadores de pruebas de carga en pods y especificar cuántos pods deseas que GKE siga ejecutando.
Para implementar las tareas de prueba de carga, haz lo siguiente:
En el siguiente diagrama, se muestra la arquitectura que demuestra las pruebas de carga mediante una aplicación de muestra. El Pod principal entrega la interfaz web que se usa para operar y supervisar las pruebas de carga. Los Pods trabajadores generan el tráfico de la solicitud de REST para la aplicación que se somete a prueba y envían métricas a la instancia principal.

Información acerca de la instancia principal de pruebas de carga
El principal de Locust es el punto de entrada para ejecutar las tareas de prueba de carga. La configuración del principal de Locust especifica varios elementos, incluidos los puertos predeterminados que usa el contenedor:
Esta información se usa más tarde para configurar los trabajadores de Locust.
Implementa un objeto Service para asegurarte de que otros Pods dentro del clúster puedan acceder a los puertos necesarios a través de hostname:port. También se puede hacer referencia a estos puertos a través de un nombre de puerto descriptivo.
Este Service permite que los trabajadores de Locust detecten fácilmente y se comuniquen de manera confiable con el principal, incluso si el principal falla y la implementación lo reemplaza por un nuevo Pod.
Se implementa un segundo Service con la anotación necesaria para crear un balanceador de cargas de red de transferencia interno que haga que el Service de la aplicación web de Locust sea accesible para los clientes fuera de tu clúster que usan la misma red de VPC y se encuentren en la misma Google Cloud región que tu clúster.
Después de implementar la instancia principal de Locust, puedes abrir la interfaz web con la dirección IP interna aprovisionada por el balanceador de cargas de red de transferencia interno. Después de implementar los trabajadores de Locust, puedes iniciar la simulación y ver estadísticas adicionales a través de la interfaz web de Locust.
Sobre los trabajadores de pruebas de carga
Los trabajadores de Locust ejecutan las tareas de prueba de carga. Usas una única implementación para crear múltiples Pods. Los Pods se extienden a través del clúster de Kubernetes. Cada Pod usa variables de entorno para controlar la información de configuración, como el nombre de host del sistema a prueba y el nombre de host de la instancia principal de Locust.
En el siguiente diagrama, se muestra la relación entre el principal y los trabajadores de Locust.

Inicializa variables comunes
Debes definir muchas variables que controlen dónde se implementan los elementos de la infraestructura.
Crea un clúster de GKE
Configure el entorno
Compila la imagen del contenedor
Implementa la aplicación de ejemplo
Implementa el Pod principal y los Pods trabajadores:
Conéctate al frontend web de Locust
Puedes utilizar la interfaz web principal de Locust para ejecutar las tareas de prueba de carga en el sistema a prueba.
Enrutamiento de herramientas de redes
Si hay una ruta para el tráfico de red entre tu estación de trabajo y tu red de VPC del proyecto deGoogle Cloud , abre tu navegador y, luego, abre la interfaz web principal de Locust. Para abrir la interfaz de Locust, ve a la siguiente URL:
http://INTERNAL_LB_IP:8089
Reemplaza INTERNAL_LB_IP por la URL y la dirección IP que anotaste en el paso anterior.
Proxy y túnel SSH
Ejecuta una prueba de carga básica en tu aplicación de ejemplo
Escala verticalmente la cantidad de usuarios (opcional)
Si deseas probar una mayor carga en la aplicación, puedes agregar usuarios simulados. Para poder agregar usuarios simulados, debes asegurarte de que haya suficientes recursos para soportar el aumento de la carga. Con Google Cloud, puedes agregar Pods de trabajadores de Locust a la Deployment sin volver a implementar los Pods existentes, siempre que tengas los recursos de VM subyacentes para admitir una mayor cantidad de Pods. El clúster de GKE inicial comienza con 3 nodos y puede escalar de forma automática hasta 10 nodos.
Si ves el error Pod no programable, debes agregar más nodos al clúster. Para obtener más información, consulta Cambia el tamaño de un clúster de GKE.
Después de que se inicien los Pods, vuelve a la interfaz web del principal de Locust y reinicia las pruebas de carga.
Extiende el patrón
Para extender este patrón, puedes crear nuevas tareas de Locust o incluso cambiar a un framework de pruebas de carga diferente.
Puedes personalizar las métricas que recopilas. Por ejemplo, es posible que desees medir las solicitudes por segundo, supervisar la latencia de la respuesta a medida que aumenta la carga o verificar las tasas de error de respuesta y los tipos de errores.
Para obtener más información, consulta la documentación de Cloud Monitoring.
Limpia
Para evitar que se apliquen cargos a tu Google Cloud cuenta por los recursos usados en este documento, borra el proyecto que contiene los recursos o conserva el proyecto y borra los recursos individuales.
Borra el proyecto
Borra el clúster de GKE
Si no quieres borrar todo el proyecto, ejecuta el comando siguiente para borrar el clúster de GKE:
gcloud container clusters delete ${GKE_CLUSTER} --region ${REGION}