En este documento, se describen varios enfoques para usar la captura de datos modificados (CDC) a fin de integrar varias fuentes de datos a BigQuery. En este documento, se proporciona un análisis de las compensaciones entre la coherencia de los datos, la facilidad de uso y los costos de cada uno de los enfoques. Te ayudará a comprender las soluciones existentes, aprender sobre los diferentes enfoques para consumir datos replicados por los CDC y cómo crear un análisis de costos y beneficios de los enfoques.
El objetivo de este documento es ayudar a los arquitectos de datos, los ingenieros de datos y los analistas de datos a fin de desarrollar un enfoque óptimo para acceder a datos replicados en BigQuery. Suponemos que estás familiarizado con BigQuery, SQL y las herramientas de línea de comandos.
Descripción general de la replicación de datos de los CDC
Las bases de datos como MySQL, Oracle y SAP son las fuentes de datos de los CDC más comunes. Sin embargo, cualquier sistema puede considerarse una fuente de datos si captura y proporciona modificaciones en los elementos de datos identificados por claves primarias. Si un sistema no proporciona un proceso integrado de los CDC, como un registro de transacciones, puedes implementar un lector de lotes incremental para obtener cambios.
En este documento, se analizan los procesos de los CDC que cumplen con los siguientes criterios:
- La replicación de datos captura los cambios de cada tabla por separado.
- Cada tabla tiene una clave primaria o una clave primaria compuesta.
- A cada evento de los CDC emitido se le asigna un ID de cambio que aumenta monótonamente, un valor numérico, como un ID de transacción o una marca de tiempo.
- Cada evento de los CDC contiene el estado completo de la fila que cambió.
En el siguiente diagrama, se muestra una arquitectura genérica que usa los CDC para replicar fuentes de datos a BigQuery:
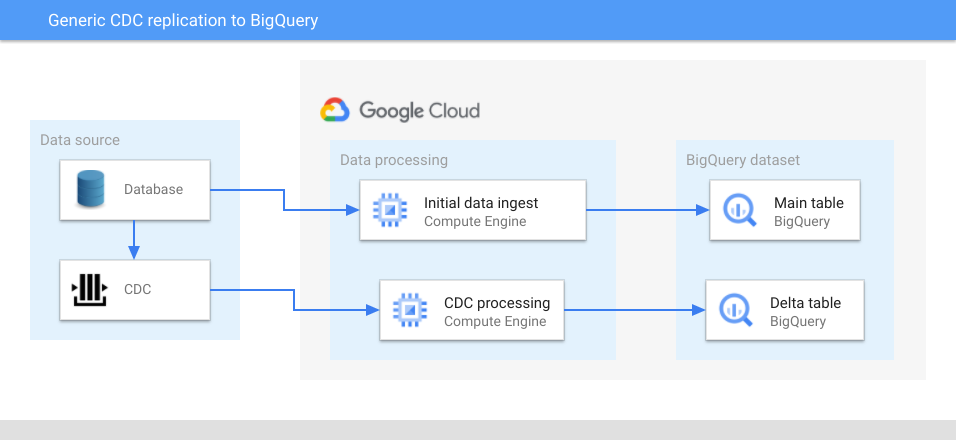
En el diagrama anterior, se crea una tabla principal y una tabla delta en BigQuery para cada tabla de datos de origen. La tabla principal contiene todas las columnas de la tabla de origen, además de una columna para el valor del ID del cambio más reciente. Puedes considerar el valor de ID de cambio más reciente como el ID de versión de la entidad identificada por la clave primaria del registro y usarlo para buscar la versión más reciente.
La tabla delta contiene todas las columnas de la tabla de origen, además de una columna de tipo de operación (una de actualización, inserción o eliminación) y el valor del ID de cambio.
A continuación, se describe el proceso general para replicar datos en BigQuery mediante los CDC:
- Se extrae un volcado de datos inicial de una tabla de origen.
- Los datos extraídos se transforman de forma opcional y se cargan en su tabla principal correspondiente. Si la tabla no tiene una columna que se pueda usar como ID de cambio, como una marca de tiempo de última actualización, el ID de cambio se establece en el valor más bajo posible para el tipo de datos de esa columna. Esto permite que el procesamiento posterior identifique los registros de la tabla principal que se actualizaron después del volcado de datos inicial.
- El proceso de captura de los CDC captura las filas que cambian después del volcado inicial de los datos.
- Si es necesario, la capa de procesamiento de los CDC realiza la transformación de datos adicional. Por ejemplo, la capa de procesamiento de CDC podría cambiar el formato de la marca de tiempo para que BigQuery la use, dividir columnas verticalmente o quitarlas.
- Los datos se insertan en la tabla delta correspondiente en BigQuery, con cargas de microlotes o inserciones de transmisión.
Si se realizan transformaciones adicionales antes de que los datos se inserten en BigQuery, la cantidad y el tipo de columnas pueden diferir de la tabla de origen. Sin embargo, existe el mismo conjunto de columnas en las tablas principal y delta.
Las tablas delta contienen todos los eventos de cambio para una tabla en particular desde la carga inicial. Tener todos los eventos de cambio disponibles puede ser valioso para identificar tendencias, el estado de las entidades que representa una tabla en un momento determinado o cambiar la frecuencia.
Para obtener el estado actual de una entidad representada por una clave primaria en particular, puedes consultar la tabla principal y la tabla delta para el registro que tiene el ID de cambio más reciente. Esta consulta puede ser costosa, ya que es posible que debas realizar una unión entre las tablas principal y delta y completar un análisis de tabla completo de una o ambas tablas para encontrar la entrada más reciente de una clave primaria en particular. Puedes evitar realizar un análisis de tablas completo mediante la agrupación en clústeres o la partición de las tablas según la clave primaria, pero eso no siempre es posible.
En este documento, se comparan los siguientes enfoques genéricos que pueden ayudarte a obtener el estado actual de una entidad cuando no puedes particionar o agrupar en clústeres las tablas:
- Enfoque de coherencia inmediata: las consultas reflejan el estado actual de los datos replicados. La coherencia inmediata requiere una consulta que une la tabla principal y la delta, y selecciona la fila más reciente para cada clave primaria.
- Enfoque de optimización de los costos: las consultas más rápidas y menos costosas se ejecutan a expensas de un retraso en la disponibilidad de los datos. Puedes combinar los datos de forma periódica en la tabla principal.
- Enfoque híbrido: Usas el enfoque de coherencia inmediata o el enfoque optimizado para los costos, según tus requisitos y presupuesto.
En el documento, se analizan más formas de mejorar el rendimiento, además de estos enfoques.
Antes de comenzar
En este documento, se demuestra el uso de la herramienta de línea de comandos de bq y las instrucciones de SQL para ver y consultar los datos de BigQuery. Los diseños y las consultas de las tablas de ejemplo se muestran más adelante en este documento. Si deseas experimentar con datos de muestra, completa la siguiente configuración:
- Selecciona un proyecto o crea un proyecto y habilita la facturación.
- Si creas un proyecto, BigQuery se habilita de forma automática.
- Si seleccionas un proyecto existente, habilita la API de BigQuery.
- En la consola de Google Cloud, abre Cloud Shell.
Para actualizar tu archivo de configuración de BigQuery, abre el archivo
~/.bigqueryrcen un editor de texto y agrega o actualiza las siguientes líneas en cualquier lugar del archivo:[query] --use_legacy_sql=false [mk] --use_legacy_sql=falseClona el repositorio de GitHub que contiene las secuencias de comandos para configurar el entorno de BigQuery:
git clone https://github.com/GoogleCloudPlatform/bq-mirroring-cdc.gitCrea las tablas del conjunto de datos, principal y delta:
cd bq-mirroring-cdc/tutorial chmod +x *.sh ./create-tables.sh
Para evitar cargos potenciales cuando termines de experimentar, cierra el proyecto o borra el conjunto de datos.
Configura datos de BigQuery
A fin de demostrar diferentes soluciones para la replicación de datos de los CDC en BigQuery, usa un par de tablas principales y delta que se propagan con datos de ejemplo, como las siguientes tablas de ejemplo simples.
Para trabajar con una configuración más sofisticada que la que se describe en este documento, puedes usar la demostración de integración de BigQuery de los CDC. La demostración automatiza el proceso de propagación de tablas y, además, incluye secuencias de comandos para supervisar el proceso de replicación. Si deseas ejecutar la demostración, sigue las instrucciones del archivo README que se encuentran en la raíz del repositorio de GitHub que clonaste en Antes de comenzar.
Los datos de ejemplo usan un modelo de datos simple: una sesión web que contiene un ID de sesión que genera el sistema y un nombre de usuario opcional. Cuando se inicia la sesión, el nombre de usuario es nulo. Después de que el usuario accede, se propaga el nombre de usuario.
Para cargar datos en la tabla principal desde las secuencias de comandos del entorno de BigQuery, puedes ejecutar un comando como el siguiente:
bq load cdc_tutorial.session_main init.csv
Para obtener el contenido principal de la tabla, puedes ejecutar una consulta como la siguiente:
bq query "select * from cdc_tutorial.session_main limit 1000"
El resultado luce de la siguiente manera:
+-----+----------+-----------+ | id | username | change_id | +-----+----------+-----------+ | 100 | NULL | 1 | | 101 | Sam | 2 | | 102 | Jamie | 3 | +-----+----------+-----------+
A continuación, debes cargar el primer lote de cambios de los CDC en la tabla delta. Para cargar el primer lote de cambios de los CDC en la tabla delta desde las secuencias de comandos del entorno de BigQuery, puedes ejecutar un comando como el siguiente:
bq load cdc_tutorial.session_delta first-batch.csv
Para obtener el contenido de la tabla delta, puedes ejecutar una consulta como la siguiente:
bq query "select * from cdc_tutorial.session_delta limit 1000"
El resultado luce de la siguiente manera:
+-----+----------+-----------+-------------+ | id | username | change_id | change_type | +-----+----------+-----------+-------------+ | 100 | Cory | 4 | U | | 101 | Sam | 5 | D | | 103 | NULL | 6 | I | | 104 | Jamie | 7 | I | +-----+----------+-----------+-------------+
En el resultado anterior, el valor change_id es el ID único de un cambio en la fila de la tabla. Los valores en la columna change_type representan lo siguiente:
U: operaciones de actualizaciónD: operaciones que se borraronI: operaciones de inserción
La tabla principal contiene información sobre las sesiones 100, 101 y 102. La tabla delta tiene los siguientes cambios:
- La sesión 100 se actualiza con el nombre de usuario “Cory”.
- Se borró la sesión 101.
- Se crean nuevas sesiones 103 y 104.
El estado actual de las sesiones en el sistema de origen es el siguiente:
+-----+----------+ | id | username | +-----+----------+ | 100 | Cory | | 102 | Jamie | | 103 | NULL | | 104 | Jamie | +-----+----------+
Aunque el estado actual se muestra como una tabla, esta tabla no existe de forma materializada. Esta tabla es la combinación de la tabla principal y la delta.
Consulta los datos
Existen varios enfoques que puedes usar para determinar el estado general de las sesiones. Las ventajas y desventajas de cada enfoque se describen en las siguientes secciones.
Enfoque de coherencia inmediata
Si la coherencia inmediata de datos es tu objetivo principal y los datos de origen cambian con frecuencia, puedes usar una consulta única que une las tablas principal y delta y selecciona la fila más reciente (la fila con la marca de tiempo más reciente o el valor de número más alto).
Para crear una vista de BigQuery que une las tablas principal y delta y encuentra la fila más reciente, puedes ejecutar un comando de la herramienta bq como el siguiente:
bq mk --view \
"SELECT * EXCEPT(change_type, row_num)
FROM (
SELECT *, ROW_NUMBER() OVER (PARTITION BY id ORDER BY change_id DESC) AS row_num
FROM (
SELECT * EXCEPT(change_type), change_type
FROM \`$(gcloud config get-value project).cdc_tutorial.session_delta\` UNION ALL
SELECT *, 'I'
FROM \`$(gcloud config get-value project).cdc_tutorial.session_main\`))
WHERE
row_num = 1
AND change_type <> 'D'" \
cdc_tutorial.session_latest_v
La instrucción de SQL en la vista de BigQuery anterior realiza lo siguiente:
- El
UNION ALLmás interno produce las filas de las tablas principal y delta:SELECT * EXCEPT(change_type), change_type FROM session_deltaobliga a la columnachange_typea ser la última columna de la lista.SELECT *, 'I' FROM session_mainselecciona la fila de la tabla principal como si fuera una fila de inserción.- Usar el operador
*mantiene el ejemplo simple. Si hubo columnas adicionales o un orden de columnas diferente, reemplaza el acceso directo por listas de columnas explícitas.
SELECT *, ROW_NUMBER() OVER (PARTITION BY id ORDER BY change_id DESC) AS row_numusa una función analítica en BigQuery para asignar números de filas secuenciales que comienzan con 1 a cada uno de los grupos de filas que tienen el mismo valor deid, definido porPARTITION BY. Las filas se ordenan porchange_iden orden descendente dentro de ese grupo. Debido a que se garantiza un aumento dechange_id, el último cambio tiene una columnarow_numque tiene un valor de 1.WHERE row_num = 1 AND change_type <> 'D'selecciona solo la última fila de cada grupo. Esta es una técnica común de deduplicación en BigQuery. Esta cláusula también quita la fila del resultado si se borra su tipo de cambio.- El
SELECT * EXCEPT(change_type, row_num)superior quita las columnas adicionales que se ingresaron para su procesamiento y que no son relevantes de otra manera.
En el ejemplo anterior, no se usan los tipos de cambio de inserción y actualización en la vista porque se hace referencia al valor change_id más alto mediante la inserción original o la actualización más reciente. En este caso, cada fila contiene los datos completos de todas las columnas.
Después de crear la vista, puedes ejecutar consultas en ella. Para obtener los cambios más recientes, puedes ejecutar una consulta como la siguiente:
bq query 'select * from cdc_tutorial.session_latest_v order by id limit 10'
El resultado luce de la siguiente manera:
+-----+----------+-----------+ | id | username | change_id | +-----+----------+-----------+ | 100 | Cory | 4 | | 102 | Jamie | 3 | | 103 | NULL | 6 | | 104 | Jamie | 7 | +-----+----------+-----------+
Cuando consultas la vista, los datos en la tabla delta están visibles de inmediato si actualizaste los datos en la tabla delta con una declaración de lenguaje de manipulación de datos (DML) o casi de inmediato si transmites datos.
Enfoque de la optimización de costos
El enfoque de coherencia inmediata es simple, pero puede resultar ineficiente, ya que requiere que BigQuery lea todos los registros históricos, ordene por clave primaria y procese las otras operaciones en la consulta para implementar la vista. Si consultas con regularidad el estado de la sesión, el enfoque de coherencia inmediata podría disminuir el rendimiento y aumentar los costos de almacenamiento y procesar datos en BigQuery.
Para minimizar los costos, puedes combinar los cambios de la tabla delta en la tabla principal y borrar de forma definitiva las filas combinadas de la tabla delta. Hay un costo adicional por combinar y borrar, pero, si realizas consultas en la tabla principal con frecuencia, el costo es insignificante en comparación con el costo de buscar de forma continua el registro más reciente de una clave en la tabla delta.
Para combinar datos de la tabla delta en la tabla principal, puedes ejecutar una declaración MERGE como la siguiente:
bq query \
'MERGE `cdc_tutorial.session_main` m
USING
(
SELECT * EXCEPT(row_num)
FROM (
SELECT *, ROW_NUMBER() OVER(PARTITION BY delta.id ORDER BY delta.change_id DESC) AS row_num
FROM `cdc_tutorial.session_delta` delta )
WHERE row_num = 1) d
ON m.id = d.id
WHEN NOT MATCHED
AND change_type IN ("I", "U") THEN
INSERT (id, username, change_id)
VALUES (d.id, d.username, d.change_id)
WHEN MATCHED
AND d.change_type = "D" THEN
DELETE
WHEN MATCHED
AND d.change_type = "U"
AND (m.change_id < d.change_id) THEN
UPDATE
SET username = d.username, change_id = d.change_id'
La declaración MERGE anterior afecta a cuatro filas, y la tabla principal tiene el estado actual de las sesiones. Para consultar la tabla principal en esta vista, puedes ejecutar una consulta como la que se muestra a continuación:
bq query 'select * from cdc_tutorial.session_main order by id limit 10'
El resultado se verá de la siguiente manera:
+-----+----------+-----------+ | id | username | change_id | +-----+----------+-----------+ | 100 | Cory | 4 | | 102 | Jamie | 3 | | 103 | NULL | 6 | | 104 | Jamie | 7 | +-----+----------+-----------+
Los datos en la tabla principal reflejan los estados de las sesiones más recientes.
La mejor manera de combinar los datos con frecuencia y de forma coherente es usar una declaración MERGE, que te permite combinar varias INSERT, UPDATE y DELETE en una sola operación atómica. A continuación, se incluyen algunos de los matices de la declaración MERGE anterior:
- La tabla
session_mainse combina con la fuente de datos especificada en la cláusulaUSING, una subconsulta en este caso. - La subconsulta usa la misma técnica que la vista en el enfoque de coherencia inmediata: selecciona la fila más reciente del grupo de registros que tienen el mismo valor
id, una combinación deROW_NUMBER() OVER(PARTITION BY id ORDER BY change_id DESC) row_numyWHERE row_num = 1. - La combinación se realiza en las columnas
idde ambas tablas, que es la clave primaria. - La cláusula
WHEN NOT MATCHEDverifica si hay una coincidencia. Si no hay coincidencia, la consulta verifica que el último registro se inserte o actualice y, luego, inserta el registro.- Cuando se detecta una coincidencia con el registro y se borra el tipo de cambio, el registro se borra en la tabla principal.
- Cuando se detecta una coincidencia con el registro, se actualiza el tipo de cambio y el valor
change_idde la tabla delta es mayor que el valor dechange_iddel registro principal, los datos se actualizan, incluido el valorchange_idmás reciente.
La declaración MERGE anterior funciona correctamente para cualquier combinación de los siguientes cambios:
- Varias filas de actualización para la misma clave primaria: solo se aplicará la última actualización.
Actualizaciones que no coinciden en la tabla principal: si la tabla principal no tiene el registro en la clave primaria, se inserta un registro nuevo.
Este enfoque omite la extracción principal de la tabla y comienza con la tabla delta. La tabla principal se propaga automáticamente.
Inserta y actualiza filas en el lote delta no procesado. Se usa la fila de actualización más reciente y se inserta un registro nuevo en la tabla principal.
Insertar y borrar filas en el lote no procesado. No se insertó el registro.
La declaración MERGE anterior es idempotente: ejecutarla varias veces da como resultado el mismo estado de la tabla principal y no produce efectos secundarios.
Si vuelves a ejecutar la declaración MERGE sin agregar filas nuevas a la tabla delta, el resultado se verá de la siguiente manera:
Number of affected rows: 0
Puedes ejecutar la declaración MERGE en un intervalo regular para actualizar la tabla principal después de cada combinación. La actualidad de los datos en la tabla principal depende de la frecuencia de las combinaciones. Si deseas obtener información para ejecutar la declaración MERGE de forma automática, consulta la sección “Programa combinaciones” en el archivo README de demostración que descargaste antes.
Enfoque híbrido
El enfoque de coherencia inmediata y el enfoque optimizado para los costos no son no son mutuamente excluyentes. Si ejecutas consultas con la vista session_latest_v y en la tabla session_main, muestran los mismos resultados. Puedes seleccionar el enfoque que se usará en función de los requisitos y presupuesto: un costo más alto y una mayor coherencia inmediata, o costos más bajos, pero datos potencialmente inactivos. En las siguientes secciones, se analiza cómo comparar enfoques y posibles alternativas.
Compara enfoques
En esta sección, se describe cómo comparar enfoques mediante el costo y el rendimiento de cada solución, y el equilibrio entre la latencia de datos aceptables y el costo de ejecución de las combinaciones.
Costo de las consultas
Para evaluar el costo y el rendimiento de cada solución, en el siguiente ejemplo, se proporciona un análisis de unas 500,000 sesiones que generó la demostración de integración de los CDC en BigQuery. El modelo de sesión en la demostración es un poco más complejo que el modelo que se introdujo antes en este documento, y se implementa en un conjunto de datos diferente, pero los conceptos son los mismos.
Puedes comparar el costo de las consultas con una simple consulta de agregación. En la siguiente consulta de ejemplo, se prueba el enfoque de coherencia inmediata con la vista que combina los datos delta con la tabla principal:
SELECT status, count(*) FROM `cdc_demo.session_latest_v`
GROUP BY status ORDER BY status
La consulta da como resultado el siguiente costo:
Slot time consumed: 15.115 sec, Bytes shuffled 80.66 MB
En la siguiente consulta de ejemplo, se prueba el enfoque de optimización de costos en la tabla principal:
SELECT status, count(*) FROM `cdc_demo.session_main`
GROUP BY status ORDER BY status
La consulta da como resultado el siguiente costo más bajo:
Slot time consumed: 1.118 sec, Bytes shuffled 609 B
El consumo de tiempo de ranura puede variar cuando ejecutas las mismas consultas varias veces, pero los promedios son bastante coherentes. El valor Bytes shuffled es coherente entre diferentes ejecuciones.
Los resultados de las pruebas de rendimiento varían según los tipos de consulta y de diseño de la tabla. En la demostración anterior, no se usan clústeres ni particiones de datos.
Latencia de datos
Cuando usas el enfoque de costo optimizado, la latencia de los datos es la suma de los siguientes elementos:
- Demora del activador de replicación de datos. Este es el tiempo que transcurre desde que los datos se mantienen durante el evento de origen y el momento en el que el sistema de replicación activa el proceso de replicación.
- Tiempo para insertar los datos en BigQuery (varía según la solución de replicación).
- Tiempo para que los datos del búfer de transmisión de BigQuery aparezcan en la tabla delta. Si usas inserciones de transmisión, por lo general, esto toma unos segundos.
- Demora entre las ejecuciones de combinación.
- Momento de ejecutar la combinación.
Cuando usas el enfoque de coherencia inmediata, la latencia de datos es la suma de los siguientes elementos:
- Demora del activador de replicación de datos.
- Momento de insertar los datos en BigQuery.
- Momento para que los datos del búfer de transmisión de BigQuery aparezcan en la tabla delta.
Puedes configurar la demora entre las ejecuciones de combinación según la compensación entre los costos de ejecución de las combinaciones y la necesidad de que los datos sean más coherentes. Si es necesario, puedes usar un esquema más complejo, como combinaciones frecuentes que se realizan durante el horario de atención y las combinaciones por hora durante las horas fuera del horario.
Alternativas que debes tener en cuenta
El enfoque de coherencia inmediata y el enfoque optimizado para los costos son las opciones de los CDC más genéricas a fin de integrar varias fuentes de datos con BigQuery. En esta sección, se describen las opciones de integración de datos más simples y menos costosas.
Tabla delta como fuente de información única
Si la tabla delta contiene el historial completo de los cambios, puedes crear una vista solo en la tabla delta y no usar la tabla principal. El uso de una tabla delta como la única fuente de información es un ejemplo de una base de datos de eventos. Este enfoque proporciona coherencia instantánea a bajo costo con poco costo de rendimiento. Considera este enfoque si tienes una tabla de dimensiones muy lenta con una cantidad pequeña de registros.
Volcado de datos completo sin los CDC
Si tienes tablas de tamaño administrable (por ejemplo, inferior a 1 GB), puede ser más simple realizar un volcado de datos completo en la siguiente secuencia:
- Importa el volcado de datos inicial en una tabla con un nombre único.
- Crea una vista que solo haga referencia a la tabla nueva.
- Ejecuta consultas con la vista, no con la tabla subyacente.
- Importa el siguiente volcado de datos a otra tabla.
- Vuelve a crear la vista para que apunte a los datos recién subidos.
- De manera opcional, borra la tabla original.
- Repite los pasos anteriores para importar, volver a crear y borrar con regularidad.
Conserva el historial de cambios en la tabla principal
En el enfoque de costo optimizado, el historial de cambios no se conserva y el último cambio reemplaza los datos anteriores. Si necesitas mantener el historial, puedes almacenarlo mediante un arreglo de cambios, y no así no exceder el límite máximo de tamaño de fila. Cuando conservas el historial de cambios en la tabla principal, el DML combinado no es más complejo, ya que una sola operación MERGE puede fusionar varias filas de la tabla delta en una sola fila en la tabla principal.
Usa fuentes de datos federadas
En algunos casos, puedes replicar a una fuente de datos distinta de BigQuery y, luego, exponer esa fuente de datos mediante una consulta federada. BigQuery es compatible con varias fuentes de datos externas. Por ejemplo, si replicas un esquema similar a una estrella de una base de datos MySQL, puedes replicar las dimensiones que cambian con lentitud con una versión de MySQL de solo lectura mediante la replicación nativa de MySQL. Cuando usas este método, solo replicas la tabla de hechos que cambia con frecuencia a BigQuery. Si deseas usar fuentes de datos federadas, ten en cuenta que existen varias limitaciones para realizar consultas en fuentes federadas.
Mejora aún más el rendimiento
En esta sección, se explica cómo puedes mejorar el rendimiento mediante el agrupamiento en clústeres y la partición de tus tablas, y la reducción de los datos combinados.
Tablas de BigQuery de clústeres y particiones
Si tienes un conjunto de datos consultado con frecuencia, analiza el uso de cada tabla y ajusta el diseño de la tabla mediante el agrupamiento en clústeres y la partición. La agrupación de una o ambas tablas principales y delta por clave primaria puede dar como resultado un mejor rendimiento en comparación con los otros enfoques. Para verificar el rendimiento, prueba las consultas en un conjunto de datos que sea de al menos 10 GB.
Reduce los datos combinados
La tabla delta crece con el tiempo, y cada solicitud de fusión desperdicia recursos, lee una cantidad de filas que no necesitas para el resultado final. Si solo usas los datos de la tabla delta para calcular el estado más reciente, la reducción de los registros combinados puede reducir el costo de la combinación y puede reducir tu costo general mediante la reducción de la cantidad de datos almacenados en BigQuery.
Puedes reducir los datos combinados de las siguientes maneras:
- Consulta de manera periódica la tabla principal para obtener el valor de
change_idmáximo y borra todos los registros delta que tienen un valorchange_idmenor que ese máximo. Si transmites inserciones en la tabla delta, es posible que las inserciones no se borren durante cierto período. - Usa la partición basada en transferencia de las tablas delta y ejecuta una secuencia de comandos diaria para descartar las particiones que ya se procesaron. Cuando una partición de BigQuery más detallada esté disponible, puedes aumentar la frecuencia de borrado definitiva. Para obtener más información acerca de la implementación, consulta la sección “Borra datos procesados” en el archivo
READMEde demostración que descargaste antes.
Conclusiones
Para seleccionar el enfoque correcto (o varios enfoques), considera los casos de uso que intentas resolver. Es posible que puedas resolver tus necesidades de replicación de datos si usas tecnologías de migración de bases de datos existentes. Si tienes necesidades complejas, por ejemplo, si necesitas resolver un caso de uso de datos en tiempo real y optimizar el resto del patrón de acceso a los datos, es posible que debas configurar una Frecuencia de migración de base de datos personalizada basándonos en otros productos o soluciones de código abierto. Los enfoques y las técnicas que se describen en este documento pueden ayudarte a implementar esta solución de forma correcta.
¿Qué sigue?
- Revisa Migra canalizaciones de datos.
- Lee Diseña la arquitectura ETL para un almacén de datos nativo de la nube en Google Cloud y la Realiza operaciones ETL desde una base de datos relacional en BigQuery con Dataflow.
- Explora arquitecturas de referencia, diagramas y prácticas recomendadas sobre Google Cloud. Consulta nuestro Cloud Architecture Center.