このドキュメントでは、単一テナントノードについて説明します。単一テナントノードの VM をプロビジョニングする方法については、単一テナントノードでの VM のプロビジョニングをご覧ください。
単一テナンシーを使用すると、単一テナントノードに独占的にアクセスできます。単一テナントノードは、特定のプロジェクトの VM をホストすることに特化した物理 Compute Engine サーバーです。次の図に示すように、単一テナントノードを使用すると、VM を他のプロジェクトの VM から物理的に分離できます。また、同じホスト ハードウェア上で VM をグループ化することもできます。単一テナントノード グループを作成し、他のプロジェクトと共有するか、組織全体と共有するかを指定することもできます。

単一テナントノードで実行されている VM は、透過性スケジューリングやブロック ストレージなど、他の VM と同じ Compute Engine 機能を使用できますが、ハードウェアが分離されます。物理サーバー上の VM を完全に制御するため、各単一テナントノードは、ノードをサポートする物理サーバーとの 1 対 1 マッピングを維持します。
単一テナントノード内では、さまざまなサイズのマシンタイプに複数の VM をプロビジョニングでき、基盤となる専用ホスト ハードウェアのリソースを効率的に使用できます。また、ホスト ハードウェアを他のプロジェクトと共有しない場合は、他のワークロードや VM から物理的に隔離する必要があるワークロードで、セキュリティやコンプライアンスの要件を満たすことが可能です。ワークロードが単一テナンシーを必要とするのが一時的のみの場合、必要に応じて VM テナンシーを変更できます。
単一テナントノードは、コアごとまたはプロセッサごとのライセンスが必要なお客様所有ライセンスの使用(BYOL)シナリオでの専用ハードウェア要件を満たすうえで役立ちます。単一テナントノードを使用すると基盤となるハードウェアを可視化できるため、コアとプロセッサの使用状況を追跡できます。使用状況を追跡するため、Compute Engine は VM がスケジュールされている物理サーバーの ID を報告します。これにより、Cloud Logging を使用して、VM の過去のサーバー使用状況を表示できます。
ホスト ハードウェアの使用を最適化するには、次の操作を行います。
構成可能なメンテナンス ポリシーを使用すると、ホストのメンテナンス中に単一テナント VM の動作を制御できます。メンテナンスの時間、VM が特定の物理サーバーでアフィニティを維持するかどうか、VM をノードグループ内の他の単一テナントノードに移動するかどうかを指定できます。
ワークロードの考慮事項
次のようなタイプのワークロードは、単一テナントノードのメリットを活用できる場合があります。
パフォーマンス要件のあるゲーム ワークロード
セキュリティとコンプライアンスの要件がある財務または医療ワークロード
ライセンス要件がある Windows ワークロード
ML、データ処理、画像レンダリングのワークロード。こうしたワークロードについては、GPU の予約を検討してください。
高い IOPS(1 秒あたりの入出力オペレーション)および低いレイテンシを必要とするワークロードや、キャッシュ、処理空間、LOW-VALUE データなどを一時的なストレージとして使用するワークロード。このようなワークロードの場合は、ローカル SSD ディスクの予約を検討してください。
ノード テンプレート
ノード テンプレートは、ノードグループの各ノードのプロパティを定義するリージョン リソースです。ノード テンプレートからノードグループを作成すると、ノード テンプレートのプロパティがノードグループの各ノードに不変にコピーされます。
ノード テンプレートを作成する場合は、ノードタイプを指定する必要があります。ノード テンプレートを作成するときに、必要に応じてノード アフィニティ ラベルを指定できます。ノード アフィニティ ラベルはノード テンプレートにのみ指定できます。ノードグループにノード アフィニティ ラベルを指定することはできません。
ノードタイプ
ノード テンプレートを構成するときに、ノード テンプレートに基づいて作成されたノードグループ内のすべてのノードに適用するノードタイプを指定します。ノード テンプレートによって参照される単一テナントノード タイプは、そのテンプレートを使用するノードグループで作成されたノードに対し、vCPU コアとメモリの合計量を指定します。たとえば、n2-node-80-640 ノードタイプには 80 基の vCPU と 640 GB のメモリが指定されています。
単一テナントノードに追加する VM は、ノード テンプレートで指定するノードと同じマシンタイプである必要があります。たとえば、n2 タイプの単一テナントノードは、n2 マシンタイプで作成された VM とのみ互換性があります。vCPU またはメモリの合計がノードの容量を超過するまで、単一テナントノードに VM を追加できます。
ノード テンプレートを使用してノードグループを作成すると、ノードグループ内の各ノードはノード テンプレートのノードタイプの仕様を継承します。ノードタイプは、ノードグループ全体に一律に適用されるのではなく、ノードグループ内のノードに個別に適用されます。したがって、ノードタイプがいずれも n2-node-80-640 のノードを 2 つ含むノードグループを作成すると、各ノードに 80 基の vCPU と 640 GB のメモリが割り当てられます。
ワークロードの要件に応じて、さまざまなサイズのマシンタイプで実行される複数のより小さな VM をノードに配置することもできます。そのようなマシンタイプには、事前定義されたマシンタイプ、カスタム マシンタイプ、拡張メモリを持つマシンタイプがあります。ノードがインスタンスでいっぱいの場合、そのノードでは追加の VM はスケジュールできません。
次の表に、使用可能なノードタイプを示します。プロジェクトで使用可能なノードタイプのリストを表示するには、gcloud compute sole-tenancy node-types list コマンドを実行するか、nodeTypes.list REST リクエストを作成します。
| ノードタイプ | プロセッサ | vCPU | GB | vCPU:GB | ソケット | コア:ソケット | 合計コア数 | 許可される最大 VM 数 |
|---|---|---|---|---|---|---|---|---|
c2-node-60-240 |
Cascade Lake | 60 | 240 | 1:4 | 2 | 18 | 36 | 15 |
c3-node-176-352 |
Sapphire Rapids | 176 | 352 | 1:2 | 2 | 48 | 96 | 44 |
c3-node-176-704 |
Sapphire Rapids | 176 | 704 | 1:4 | 2 | 48 | 96 | 44 |
c3-node-176-1408 |
Sapphire Rapids | 176 | 1408 | 1:8 | 2 | 48 | 96 | 44 |
c3d-node-360-708 |
AMD EPYC Genoa | 360 | 708 | 1:2 | 2 | 96 | 192 | 34 |
c3d-node-360-1440 |
AMD EPYC Genoa | 360 | 1440 | 1:4 | 2 | 96 | 192 | 40 |
c3d-node-360-2880 |
AMD EPYC Genoa | 360 | 2880 | 1:8 | 2 | 96 | 192 | 40 |
c4-node-192-384 |
Emerald Rapids | 192 | 384 | 1:2 | 2 | 60 | 120 | 40 |
c4-node-192-720 |
Emerald Rapids | 192 | 720 | 1:3.75 | 2 | 60 | 120 | 30 |
c4-node-192-1488 |
Emerald Rapids | 192 | 1,488 | 1:7.75 | 2 | 60 | 120 | 30 |
c4a-node-72-144 |
Google Axion | 72 | 144 | 1:2 | 1 | 80 | 80 | 22 |
c4a-node-72-288 |
Google Axion | 72 | 288 | 1:4 | 1 | 80 | 80 | 22 |
c4a-node-72-576 |
Google Axion | 72 | 576 | 1:8 | 1 | 80 | 80 | 36 |
c4d-node-384-720 |
AMD EPYC Turin | 384 | 744 | 1:2 | 2 | 96 | 192 | 24 |
c4d-node-384-1488 |
AMD EPYC Turin | 384 | 1488 | 1:4 | 2 | 96 | 192 | 25 |
c4d-node-384-3024 |
AMD EPYC Turin | 384 | 3024 | 1:8 | 2 | 96 | 192 | 25 |
g2-node-96-384 |
Cascade Lake | 96 | 384 | 1:4 | 2 | 28 | 56 | 8 |
g2-node-96-432 |
Cascade Lake | 96 | 432 | 1:4.5 | 2 | 28 | 56 | 8 |
h3-node-88-352 |
Sapphire Rapids | 88 | 352 | 1:4 | 2 | 48 | 96 | 1 |
m1-node-96-1433 |
Skylake | 96 | 1433 | 1:14.93 | 2 | 28 | 56 | 1 |
m1-node-160-3844 |
Broadwell E7 | 160 | 3844 | 1:24 | 4 | 22 | 88 | 4 |
m2-node-416-8832 |
Cascade Lake | 416 | 8832 | 1:21.23 | 8 | 28 | 224 | 1 |
m2-node-416-11776 |
Cascade Lake | 416 | 11776 | 1:28.31 | 8 | 28 | 224 | 2 |
m3-node-128-1952 |
Ice Lake | 128 | 1952 | 1:15.25 | 2 | 36 | 72 | 2 |
m3-node-128-3904 |
Ice Lake | 128 | 3904 | 1:30.5 | 2 | 36 | 72 | 2 |
m4-node-224-2976 |
Emerald Rapids | 224 | 2976 | 1:13.3 | 2 | 112 | 224 | 1 |
m4-node-224-5952 |
Emerald Rapids | 224 | 5952 | 1:26.7 | 2 | 112 | 224 | 1 |
n1-node-96-624 |
Skylake | 96 | 624 | 1:6.5 | 2 | 28 | 56 | 96 |
n2-node-80-640 |
Cascade Lake | 80 | 640 | 1:8 | 2 | 24 | 48 | 80 |
n2-node-128-864 |
Ice Lake | 128 | 864 | 1:6.75 | 2 | 36 | 72 | 128 |
n2d-node-224-896 |
AMD EPYC Rome | 224 | 896 | 1:4 | 2 | 64 | 128 | 112 |
n2d-node-224-1792 |
AMD EPYC Milan | 224 | 1792 | 1:8 | 2 | 64 | 128 | 112 |
n4-node-224-1372 |
Emerald Rapids | 224 | 1372 | 1:6 | 2 | 60 | 120 | 90 |
これらのノードタイプの料金については、単一テナントノードの料金をご覧ください。
どのノードでも、異なるシェイプの VM をスケジュールできます。ノード n タイプは汎用ノードであり、カスタム マシンタイプのインスタンスをスケジュール設定できます。おすすめのノードタイプについては、マシンタイプに関する推奨事項をご覧ください。パフォーマンスについて詳しくは、CPU プラットフォームをご覧ください。
ノードグループと VM のプロビジョニング
単一テナントノード テンプレートは、ノードグループのプロパティを定義します。 Google Cloudゾーンにノードグループを作成する前に、ノード テンプレートを作成する必要があります。グループを作成するときに、ノードグループの VM のホスト メンテナンス ポリシー、ノードグループのノード数、ノードグループを他のプロジェクトと共有するか組織全体と共有するかどうかを指定します。
ノードグループには 0 以上のノードを含めることができます。たとえば、グループ内のノードで VM を実行する必要がない場合には、ノードグループのノード数を 0 にできます。また、ノードグループ オートスケーラーを有効にしてノードグループのサイズを自動で管理することもできます。
単一テナントノードに VM をプロビジョニングする前に、単一テナントノード グループを作成する必要があります。ノードグループは、特定のゾーン内の単一テナントノードの同種のセットです。マシンタイプに 2 つ以上の vCPU があれば、ノードグループには、さまざまなサイズのマシンタイプで実行される同じマシンシリーズの複数の VM を含めることができます。
ワークロードの要件に合わせてグループのサイズが自動的に調整されるよう、ノードグループの作成時に自動スケーリングを有効にします。ワークロードの要件が静的な場合は、ノードグループのサイズを手動で指定できます。
ノードグループを作成した後に、グループまたはグループ内の特定のノードに VM をプロビジョニングできます。ノード アフィニティ ラベルを使用すると、アフィニティ ラベルが一致する任意のノードで VM をスケジュールできます。
ノードグループに VM をプロビジョニングし、必要に応じてアフィニティ ラベルを割り当てて特定のノードグループまたはノードに VM をプロビジョニングしたら、VM の管理に役立つようリソースのラベル付けを検討します。ラベルは VM を分類する Key-Value ペアであり、VM を集約して表示できるため料金の把握などに役立ちます。たとえば、ラベルを使用して、VM の役割、テナンシー、ライセンス タイプ、ロケーションをマークできます。
ホスト メンテナンス ポリシー
ライセンスのシナリオとワークロードに応じて、VM によって使用される物理コアの数を制限できます。選択するホスト メンテナンス ポリシーは、ライセンスやコンプライアンスの要件などによって異なります。また、物理サーバーの使用を制限できるポリシーも選択できます。これらすべてのポリシーを使用しても、VM は専用のハードウェア上に残ります。
単一テナントノードで VM をスケジュールする場合、ホスト メンテナンス ポリシーを次の 3 つから選択できます。これにより、4~6 週間ごとに発生するホスト メンテナンス イベント中に Compute Engine が VM をライブ マイグレーションする方法と、ライブ マイグレーションするかどうかを決定できます。メンテナンス中、Compute Engine はホスト上のすべての VM を 1 つのグループとして異なる単一テナントノードにライブ マイグレーションします。ただし、場合によっては Compute Engine が VM を小規模なグループに分割し、その各グループを個別の単一テナントノードにライブ マイグレーションすることもあります。
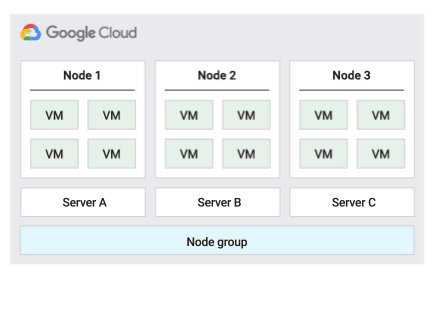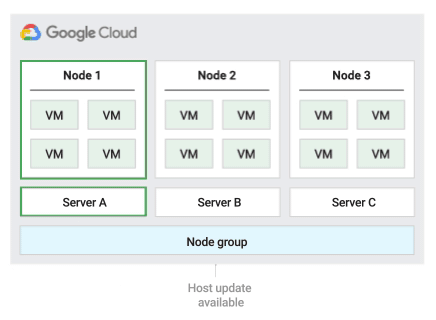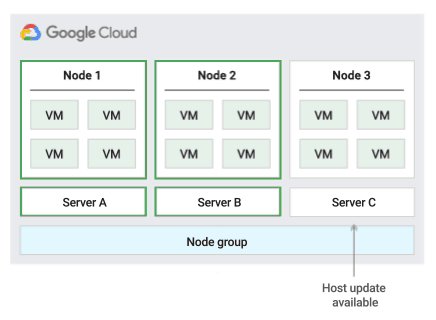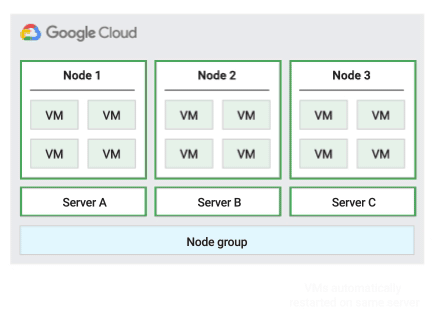
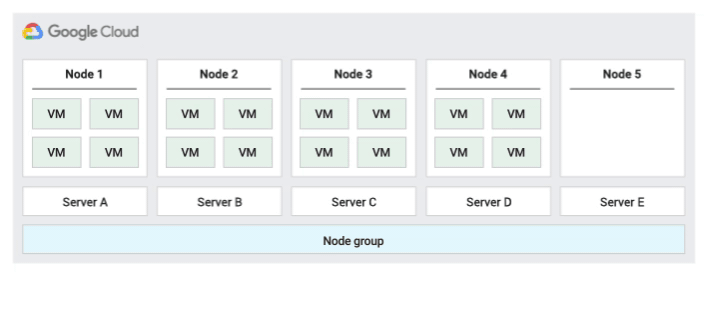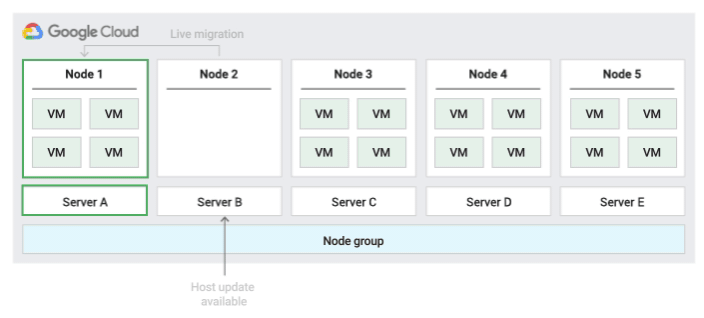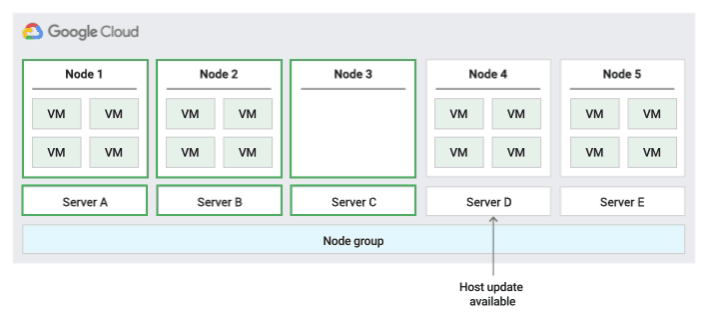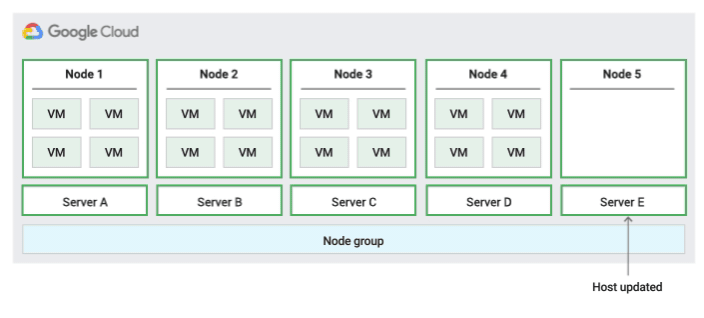
デフォルトのホスト メンテナンス ポリシー
これはデフォルトのメンテナンス ポリシーです。このポリシーで構成されたノードグループの VM は、非単一テナント VM の従来のメンテナンス動作に従います。すなわち、VM のホストの [ホスト メンテナンス時] 設定に応じて、VM はホスト メンテナンス イベント前にノードグループの新しい単一テナントノードにライブ マイグレーションされ、この新しい単一テナントノードはそのお客様の VM のみを実行します。
このポリシーは、メンテナンス イベント中にライブ マイグレーションが必要な、ユーザー単位またはデバイス単位のライセンスに最適です。この設定は、VM の移行を物理サーバーの固定プール内に制限するものではありません。この設定は、物理サーバーの要件がなく既存のライセンスを必要としない一般的なワークロードにおすすめします。
このポリシーでは、既存サーバーのアフィニティを考慮せずに VM が任意のサーバーにライブ マイグレーションされるため、このポリシーはメンテナンス イベント中に物理コアの使用量を最小限に抑える必要があるシナリオには適していません。
次の図に、デフォルト メンテナンス ポリシーのアニメーションを示します。
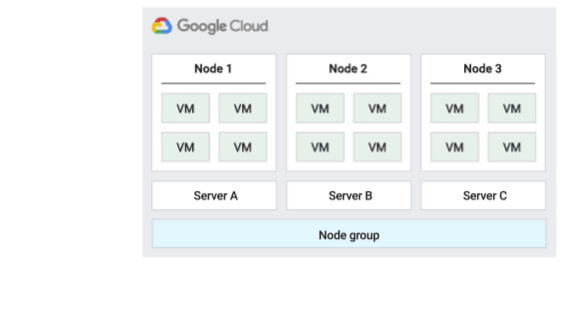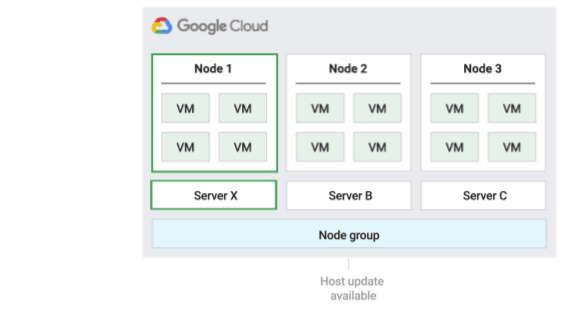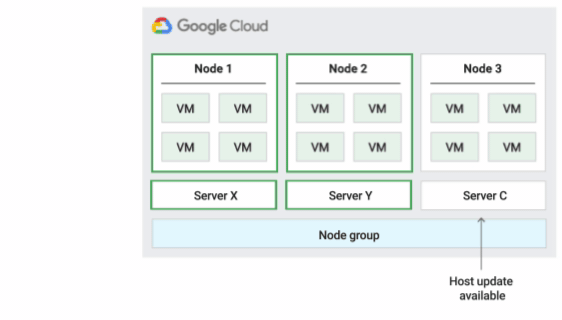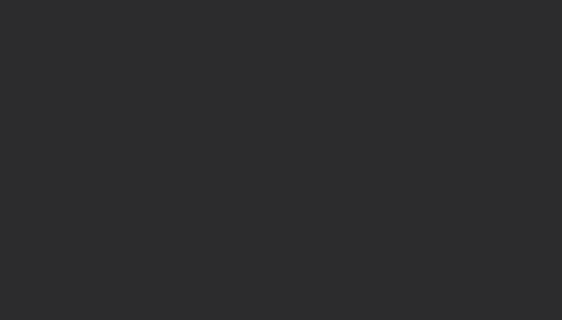
インプレース再起動ホスト メンテナンス ポリシー
このホスト メンテナンス ポリシーを使用すると、Compute Engine はホストイベント中に VM を停止し、ホストイベント後に同じ物理サーバー上で VM を再起動します。このポリシーを使用する場合、VM の [ホスト メンテナンス時] 設定を「TERMINATE」に設定する必要があります。
このポリシーは、ホスト メンテナンス イベント中に約 1 時間のダウンタイムが発生しても問題ないフォールト トレラントなワークロード、同じ物理サーバーに残す必要があるワークロード、ライブ マイグレーションを必要としないワークロード、または物理コア数やプロセッサ数に基づくライセンスを所有している場合に最適です。
このポリシーでは、node-name、node-group-name、またはノード アフィニティ ラベルを使用してノードグループにインスタンスを割り当てることができます。
次の図に、インプレース再起動のメンテナンス ポリシーのアニメーションを示します。
ノードグループ内の移行メンテナンス ポリシー
このメンテナンス ポリシーを使用すると、Compute Engine はメンテナンス イベント中に固定サイズの物理サーバー グループ内で VM をライブ マイグレーションします。これにより、VM が使用する一意の物理サーバーの数を制限できます。
このホスト メンテナンス ポリシーでは、グループ内の各単一テナントノードが一定のセットの物理サーバーに固定されます。そのため、このポリシーは、物理コア数またはプロセッサ数に基づくライセンスを持つ、高可用性ワークロードに最適です。これは、VM を任意のサーバーに移行できるデフォルトのポリシーとは異なります。
ライブ マイグレーション用の容量を確保するため、Compute Engine は予約された 20 ノードごとに 1 つのホールドバック ノードを予約します。次の図に、ノードグループ内での移行のメンテナンス ポリシーのアニメーションを示します。
次の表に、ノードグループ用に予約するノード数に応じて Compute Engine が予約するホールドバック ノードの数を示します。
| グループ内の総ノード数 | ライブ マイグレーション用に予約されたホールドバック ノード |
|---|---|
| 1 | 該当なし。少なくとも 2 つのノードを予約する必要があります。 |
| 2~20 | 1 |
| 21~40 | 2 |
| 41~60 | 3 |
| 61~80 | 4 |
| 81~100 | 5 |
インスタンスを複数のノードグループに固定する
次の条件で、node-group-name アフィニティ ラベルを使用してインスタンスを複数のノードグループに固定できます。
- 固定するインスタンスで、デフォルトのホスト メンテナンス ポリシー(VM インスタンスを移行)が使用されている。
- インスタンスを固定するすべてのノードグループのホスト メンテナンス ポリシーがノードグループ内で移行に設定されている。異なるホスト メンテナンス ポリシーを持つノードグループにインスタンスを固定しようとすると、オペレーションはエラーで失敗します。
たとえば、インスタンス test-node を 2 つのノードグループ node-group1 と node-group2 に固定する場合は、次のことを確認します。
test-nodeのホスト メンテナンス ポリシーは [VM インスタンスを移行] です。node-group1とnode-group2のホスト メンテナンス ポリシーは、ノードグループ内で移行です。
アフィニティ ラベル node-name を使用してインスタンスを特定のノードに割り当てることはできません。node-name ではなく node-group-name が割り当てられている限り、インスタンスには任意のカスタム ノード アフィニティ ラベルを使用できます。
メンテナンスの時間枠
ワークロード(精密に調整されたデータベースなど)を管理しているときに、ライブ マイグレーションのパフォーマンスに対する影響が問題になることがあります。この場合、ノードグループの作成時にメンテナンスの時間枠を指定すると、単一テナントノード グループでメンテナンスが開始する時間を確認できます。ノードグループを作成した後に、メンテナンスの時間枠を変更することはできません。
メンテナンスの時間枠は 4 時間単位です。これにより、Google が単一テナント VM にメンテナンスを実行するタイミングを指定できます。メンテナンス イベントは、4~6 週間に 1 回程度発生します。
メンテナンスの時間枠は単一テナントノードのすべての VM に適用されます。これは、メンテナンスの開始時のみ指定します。メンテナンスの時間枠内にメンテナンスが完了する保証はありません。また、メンテナンスが行われる頻繁の保証もありません。ノードグループ内で移行のメンテナンス ポリシーが使用されているノードグループでは、メンテナンスの時間枠は使用できません。
ホスト メンテナンス イベントをシミュレーションする
ホスト メンテナンス イベントをシミュレートして、単一テナントノードで実行されているワークロードがホスト メンテナンス イベント中にどのように動作するかをテストできます。これにより、単一テナント VM のホスト メンテナンス ポリシーが VM で実行中のアプリケーションに対して与える影響を確認できます。
ホストエラー
ホスト(単一テナントまたはマルチテナント)で重大なハードウェア障害が発生すると、Compute Engine は次の処理を行います。
物理サーバーとその固有識別子を廃止します。
プロジェクトの物理サーバーへのアクセスを取り消します。
障害が発生したハードウェアを、新しい一意の識別子を持つ新しい物理サーバーに置き換えます。
障害が発生したハードウェアから置換先のノードに VM を移動します。
影響を受ける VM を自動的に再起動するように構成した場合は、再起動します。
ノード アフィニティとアンチアフィニティ
共有単一テナントノード グループを使用しない限り、単一テナントノードでは、VM が他のプロジェクトの VM とホストを共有することはありません。共有単一テナントノード グループを使用すると、組織内の他のプロジェクトが同じホストに VM をプロビジョニングできます。ただし、同じ単一テナントノード上で複数のワークロードをグループ化することや、ワークロードを互いに異なるノードに分離する必要が生じることも考えられます。たとえば、コンプライアンス要件を満たすため、アフィニティ ラベルを使用して機密性の高いワークロードを機密性の低いワークロードから分離する場合です。
VM の作成時に、1 つ以上のノード アフィニティ ラベルを参照し、ノード アフィニティまたはアンチアフィニティを指定して単一テナンシーをリクエストします。ノード テンプレートの作成時にカスタム ノード アフィニティ ラベルを指定すると、Compute Engine は各ノードに複数のデフォルト アフィニティ ラベルを自動的に追加します。VM の作成時にアフィニティを指定すると、ノードグループ内の特定のノードで複数の VM を同時にスケジュールできます。VM の作成時にアンチアフィニティを指定すると、特定の VM がノードグループ内の同じノードまたは複数のノードで同時にスケジュール設定されないようにできます。
ノード アフィニティ ラベルは、ノードに割り当てられた Key-Value ペアであり、ノード テンプレートから継承されます。アフィニティ ラベルを使用すると、次のことができます。
- 個々の VM インスタンスをノードに割り当てる方法を制御する。
- テンプレートから作成された VM インスタンス(マネージド インスタンス グループによって作成されたものなど)をノードに割り当てる方法を制御する。
- 機密性の高い VM インスタンスを特定のノードまたはノードグループにグループ化し、他の VM から分離する。
デフォルト アフィニティ ラベル
Compute Engine は、各ノードに次のデフォルト アフィニティ ラベルを割り当てます。
- ノードグループ名のラベル:
- キー:
compute.googleapis.com/node-group-name - 値: ノードグループの名前。
- キー:
- ノード名のラベル:
- キー:
compute.googleapis.com/node-name - 値: 個々のノードの名前
- キー:
- ノードグループが共有されるプロジェクトのラベル:
- キー:
compute.googleapis.com/projects - 値: ノードグループを含むプロジェクトのプロジェクト ID。
- キー:
カスタム アフィニティ ラベル
ノード テンプレートを作成するときに、カスタムのノード アフィニティ ラベルを作成できます。これらのアフィニティ ラベルは、ノード テンプレートから作成されたノードグループ内のすべてのノードに割り当てられます。ノードグループを作成した後に、ノードグループ内のノードにカスタム アフィニティ ラベルを追加することはできません。
アフィニティ ラベルの使用方法については、ノード アフィニティの構成をご覧ください。
料金
単一テナントノードのコストを最小限に抑えるため、Compute Engine では確約利用割引(CUD)と継続利用割引(SUD)を実施しています。単一テナンシーのプレミアム料金については、フレキシブル CUD と SUD のみの適用を受けることができ、リソースベースの CUD の適用を受けることはできません。
単一テナントノードの vCPU とメモリについてはすでに課金されているため、これらのノードで作成する VM に対して追加料金は発生しません。
GPU またはローカル SSD ディスクを使用する単一テナントノードをプロビジョニングする場合は、プロビジョニングした各ノードのすべての GPU またはローカル SSD ディスクに対して課金されます。単一テナント プレミアム料金は、単一テナントノードに使用する vCPU とメモリに基づくものであり、GPU やローカル SSD ディスクには適用されません。
対象
単一テナントノードは、一部のゾーンでのみ使用可能です。高可用性を確保するため、異なるゾーンの単一テナントノードで VM をスケジュール設定します。
単一テナントノードで GPU またはローカル SSD ディスクを使用する前に、リソースを予約するゾーンに十分な GPU またはローカル SSD の割り当てがあることを確認してください。
Compute Engine は、GPU をサポートするゾーンにある、
n1およびg2単一テナントノード タイプの GPU をサポートします。次の表に、n1およびg2ノードに接続できる GPU のタイプと、ノード テンプレートの作成時に接続する必要がある GPU の数を示します。GPU のタイプ GPU 数 単一テナントノード タイプ NVIDIA L4 8 g2NVIDIA P100 4 n1NVIDIA P4 4 n1NVIDIA T4 4 n1NVIDIA V100 8 n1Compute Engine は、これらのマシンシリーズをサポートするゾーンで使用される
n1、n2、n2d、g2の単一テナントノード タイプのローカル SSD ディスクをサポートしています。
制限事項
単一テナント VM は、T2D、T2A、E2、C2D、A2、A3、A4、A4X、またはベアメタル インスタンスのマシンシリーズとタイプでは使用できません。
単一テナント VM では、最小 CPU プラットフォームを指定できません。
VM が最小 CPU プラットフォームを指定している場合、VM を単一テナントノードに移行することはできません。VM を単一テナントノードに移行するには、VM のノード アフィニティ ラベルを更新する前に、最小 CPU プラットフォームの指定を「自動」に設定し、最小 CPU プラットフォームの指定を削除します。
単一テナントノードは、プリエンプティブル VM インスタンスをサポートしていません。
単一テナントノードでローカル SSD ディスクを使用する際の制限事項については、ローカル SSD データの永続性をご覧ください。
GPU の使用がライブ マイグレーションに及ぼす影響については、ライブ マイグレーションの制限事項をご覧ください。
GPU を使用する単一テナントノードは、GPU を使用しない VM をサポートしていません。
- CPU のオーバーコミットをサポートするのは、N1、N2、N2D、N4 の単一テナントノードのみです。
C3 単一テナントノードと C4 単一テナントノードでは、VM の vCPU とメモリの比率がノードタイプと同じである必要があります。たとえば、
c3-standardVM を-highmemノードタイプに配置することはできません。ライブ ノードグループのメンテナンス ポリシーは更新できません。
次のステップ
- 単一テナントノードの作成、構成、使用の方法を学習する。
- 単一テナント VM の CPU をオーバーコミットする方法を学習する。
お客様所有ライセンスの使用(BYOL)について学習する。