Neste tutorial, mostramos como executar inferências de aprendizado profundo em cargas de trabalho de grande escala usando GPUs NVIDIA TensorRT5 em execução no Compute Engine.
Antes de começar, veja alguns fundamentos:
- A inferência de aprendizado profundo é o estágio no processo de machine learning em que um modelo treinado é usado para reconhecer, processar e classificar os resultados.
- O NVIDIA TensorRT é uma plataforma otimizada para executar cargas de trabalho de aprendizado profundo.
- As GPUs são usadas para acelerar cargas de trabalho com uso intensivo de dados, como machine learning e processamento de dados. Uma variedade de GPUs NVIDIA está disponível no Compute Engine. Este tutorial usa GPUs T4, já que elas são desenvolvidas especificamente para cargas de trabalho de inferência de aprendizado profundo.
Objetivos
Neste tutorial, são abordados os seguintes procedimentos:
- Como preparar um modelo usando um gráfico pré-treinado.
- Como testar a velocidade de inferência de um modelo com diferentes modos de otimização.
- Como converter um modelo personalizado em TensorRT.
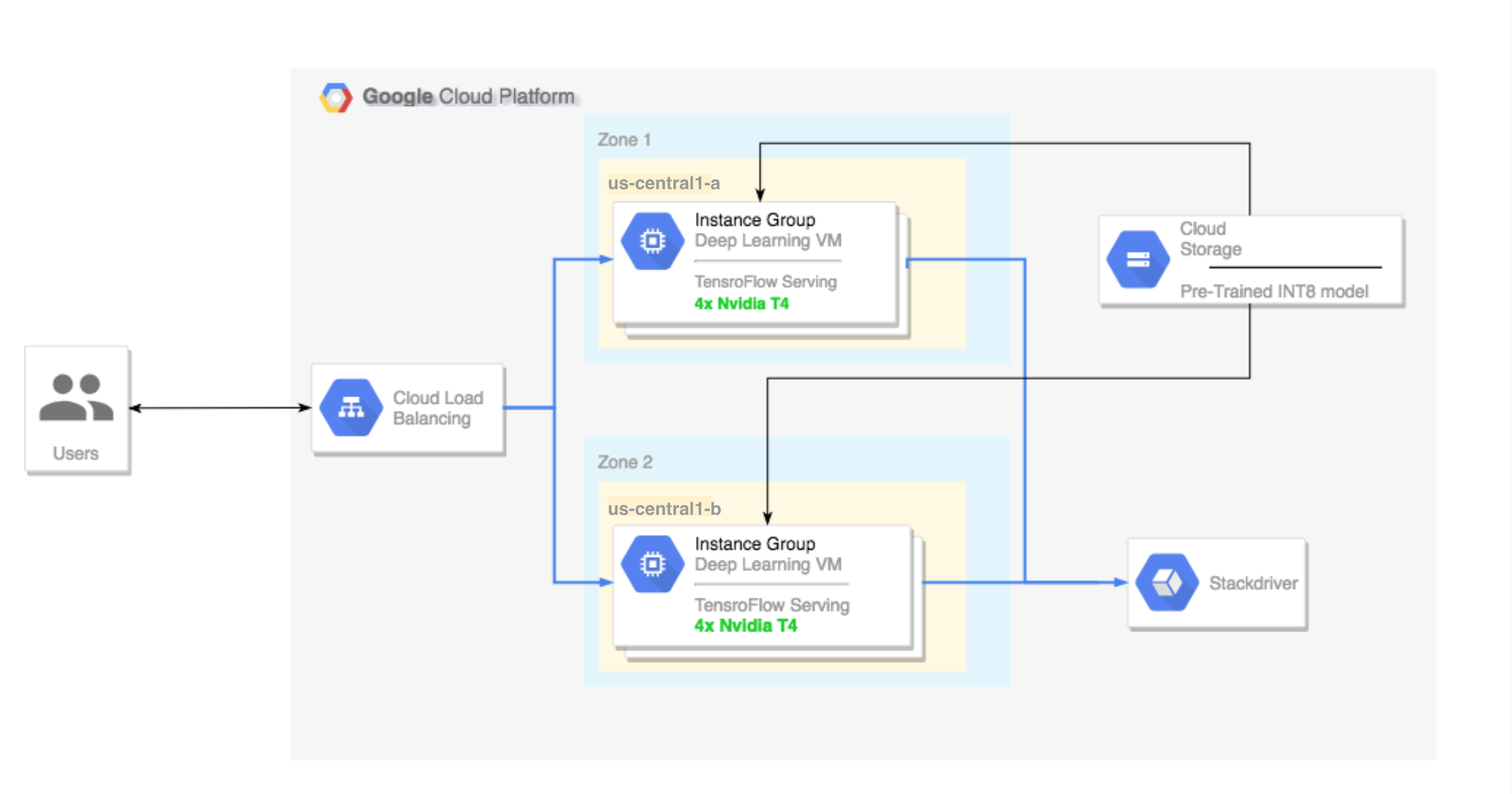
- Como configurar um cluster de várias zonas. Esse cluster é configurado da seguinte maneira:
- Criado no Deep Learning VM Images. Essas imagens são pré-instaladas com o TensorFlow, o TensorFlow Serving e a TensorRT5.
- Escalonamento automático ativado. Neste tutorial, o escalonamento automático é baseado na utilização da GPU.
- Balanceamento de carga ativado.
- Firewall ativado.
- Execução de uma carga de trabalho de inferência no cluster de várias zonas.
Pré-requisitos
Configurar o projeto
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Compute Engine and Cloud Machine Learning APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Compute Engine and Cloud Machine Learning APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. - Instale ou atualize para a versão mais recente da Google Cloud CLI.
- (Opcional) Defina uma região e uma zona padrão.
Configuração de ferramentas
Para usar a CLI do Google Cloud neste tutorial:
Como preparar o modelo
Nesta seção, mostramos como criar uma instância de máquina virtual (VM, na sigla em inglês), que é usada para executar o modelo. Também explicamos como fazer o download de um modelo do catálogo de modelos oficiais do TensorFlow.
Crie a instância de VM. Este tutorial é criado usando
tf-ent-2-10-cu113. Para as versões mais recentes das imagens, consulte Como escolher um sistema operacional na documentação do Deep Learning VM Images.export IMAGE_FAMILY="tf-ent-2-10-cu113" export ZONE="us-central1-b" export INSTANCE_NAME="model-prep" gcloud compute instances create $INSTANCE_NAME \ --zone=$ZONE \ --image-family=$IMAGE_FAMILY \ --machine-type=n1-standard-8 \ --image-project=deeplearning-platform-release \ --maintenance-policy=TERMINATE \ --accelerator="type=nvidia-tesla-t4,count=1" \ --metadata="install-nvidia-driver=True"
Selecione um modelo. Este tutorial usa o modelo ResNet. O modelo ResNet é treinado no conjunto de dados do ImageNet que está no TensorFlow.
Para fazer o download do modelo ResNet para sua instância de VM, execute o seguinte comando:
wget -q http://download.tensorflow.org/models/official/resnetv2_imagenet_frozen_graph.pb
Salve o local do modelo ResNet na variável
$WORKDIR. SubstituaMODEL_LOCATIONpelo diretório de trabalho que contém o modelo salvo.export WORKDIR=MODEL_LOCATION
Como executar o teste de velocidade de inferência
Esta seção abrange os seguintes procedimentos:
- Como configurar o modelo ResNet.
- Como executar testes de inferência em diferentes modos de otimização.
- Como revisar os resultados dos testes de inferência.
Visão geral do processo de teste
A TensorRT pode melhorar a velocidade de desempenho para cargas de trabalho de inferência. No entanto, a melhoria mais significativa é proveniente do processo de quantização.
A quantização de modelo é o processo pelo qual você reduz a precisão dos pesos de um modelo. Por exemplo, se o peso inicial de um modelo for FP32, será possível reduzir a precisão para FP16, INT8 ou até mesmo INT4. É importante escolher o ajuste correto entre a velocidade (precisão de pesos) e a acurácia de um modelo. O TensorFlow inclui uma funcionalidade que faz exatamente isso: mede a acurácia em relação à velocidade ou outras métricas, como capacidade, latência, taxas de conversão de nós e tempo total de treinamento.
Procedimento
Configure o modelo ResNet. Para configurar o modelo, execute os seguintes comandos:
git clone https://github.com/tensorflow/models.git cd models git checkout f0e10716160cd048618ccdd4b6e18336223a172f touch research/__init__.py touch research/tensorrt/__init__.py cp research/tensorrt/labellist.json . cp research/tensorrt/image.jpg ..
Execute o teste. Este comando leva algum tempo para terminar.
python -m research.tensorrt.tensorrt \ --frozen_graph=$WORKDIR/resnetv2_imagenet_frozen_graph.pb \ --image_file=$WORKDIR/image.jpg \ --native --fp32 --fp16 --int8 \ --output_dir=$WORKDIR
Em que:
$WORKDIRé o diretório em que você fez o download do modelo ResNet;- os argumentos
--nativesão os diferentes modos de quantização a serem testados.
Analise os resultados. Quando o teste é concluído, é possível fazer uma comparação dos resultados de inferência para cada modo de otimização.
Predictions: Precision: native [u'seashore, coast, seacoast, sea-coast', u'promontory, headland, head, foreland', u'breakwater, groin, groyne, mole, bulwark, seawall, jetty', u'lakeside, lakeshore', u'grey whale, gray whale, devilfish, Eschrichtius gibbosus, Eschrichtius robustus'] Precision: FP32 [u'seashore, coast, seacoast, sea-coast', u'promontory, headland, head, foreland', u'breakwater, groin, groyne, mole, bulwark, seawall, jetty', u'lakeside, lakeshore', u'sandbar, sand bar'] Precision: FP16 [u'seashore, coast, seacoast, sea-coast', u'promontory, headland, head, foreland', u'breakwater, groin, groyne, mole, bulwark, seawall, jetty', u'lakeside, lakeshore', u'sandbar, sand bar'] Precision: INT8 [u'seashore, coast, seacoast, sea-coast', u'promontory, headland, head, foreland', u'breakwater, groin, groyne, mole, bulwark, seawall, jetty', u'grey whale, gray whale, devilfish, Eschrichtius gibbosus, Eschrichtius robustus', u'lakeside, lakeshore']
Para ver os resultados completos, execute o comando a seguir:
cat $WORKDIR/log.txt
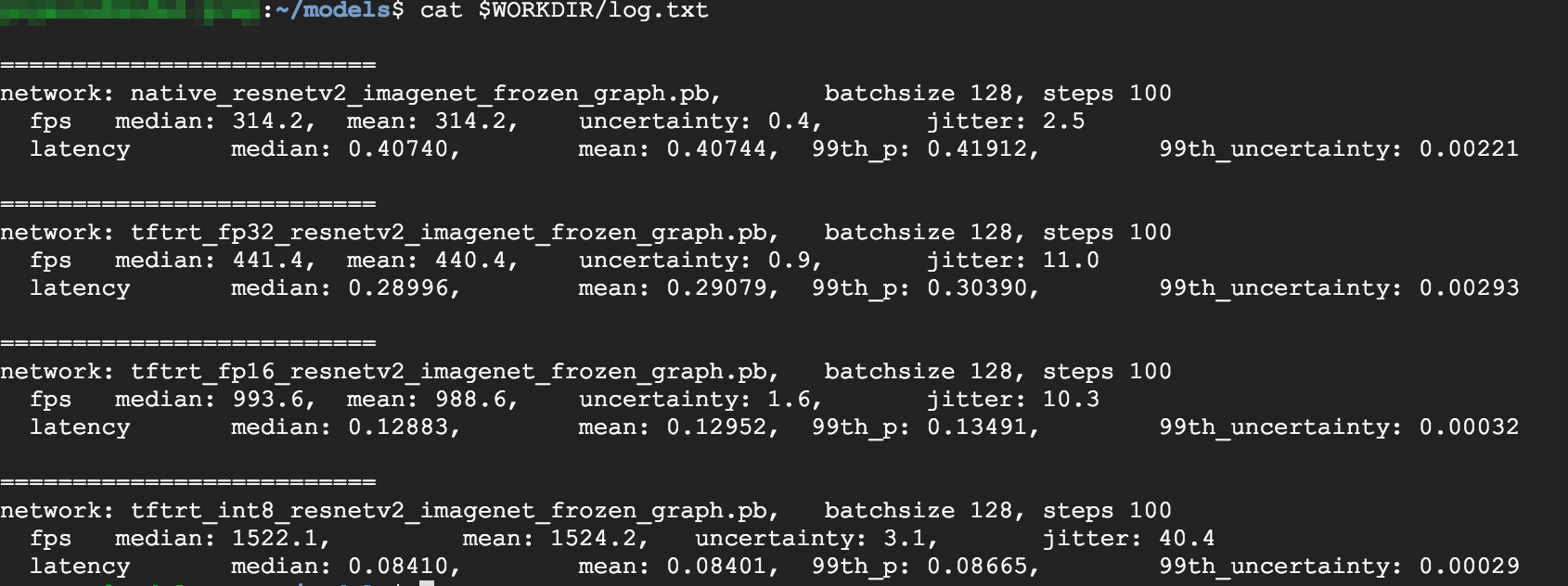
Nos resultados, é possível ver que FP32 e FP16 são idênticos. Isso significa que se você estiver satisfeito com o trabalho na TensorRT, será possível começar a usar o FP16 imediatamente. O INT8 mostra resultados um pouco piores.
Além disso, é possível ver que a execução do modelo com a TensorRT5 mostra os seguintes resultados:
- Usar a otimização do FP32 melhora o rendimento em 40%, de 314 fps para 440 fps. Ao mesmo tempo, a latência diminui em aproximadamente 30% passando de 0,28 ms para 0,40 ms.
- Usar a otimização do FP16, em vez do gráfico nativo do TensorFlow, aumenta a velocidade em 214% de 314 fps para 988 fps. Ao mesmo tempo, a latência diminui em 0,12 ms, um decréscimo de quase três vezes.
- Ao usar o INT8, podemos observar uma aceleração de 385%, de 314 fps para 1.524 fps, com a diminuição da latência para 0,08 ms.
Como converter um modelo personalizado em TensorRT
Para esta conversão, é possível usar um modelo INT8.
Faça o download do modelo. Para converter um modelo personalizado em um gráfico TensorRT, você precisa de um modelo salvo. Para conseguir um modelo ResNet INT8 salvo, execute o seguinte comando:
wget http://download.tensorflow.org/models/official/20181001_resnet/savedmodels/resnet_v2_fp32_savedmodel_NCHW.tar.gz tar -xzvf resnet_v2_fp32_savedmodel_NCHW.tar.gz
Converta o modelo no gráfico TensorRT usando o TFTools. Para converter o modelo usando o TFTools, execute o seguinte comando:
git clone https://github.com/GoogleCloudPlatform/ml-on-gcp.git cd ml-on-gcp/dlvm/tools python ./convert_to_rt.py \ --input_model_dir=$WORKDIR/resnet_v2_fp32_savedmodel_NCHW/1538687196 \ --output_model_dir=$WORKDIR/resnet_v2_int8_NCHW/00001 \ --batch_size=128 \ --precision_mode="INT8"
Agora você tem um modelo INT8 no diretório
$WORKDIR/resnet_v2_int8_NCHW/00001.Para garantir que tudo esteja configurado corretamente, tente executar um teste de inferência.
tensorflow_model_server --model_base_path=$WORKDIR/resnet_v2_int8_NCHW/ --rest_api_port=8888
Faça o upload do modelo para o Cloud Storage. Essa etapa é necessária para que o modelo possa ser usado no cluster de várias zonas que será configurado na próxima seção. Para fazer o upload do modelo, execute as etapas a seguir:
Arquive o modelo.
tar -zcvf model.tar.gz ./resnet_v2_int8_NCHW/
Faça o upload do arquivo. Substitua
GCS_PATHpelo caminho para o bucket do Cloud Storage.export GCS_PATH=GCS_PATH gcloud storage cp model.tar.gz $GCS_PATH
Se necessário, há um gráfico congelado INT8 do Cloud Storage neste URL:
gs://cloud-samples-data/dlvm/t4/model.tar.gz
Como configurar um cluster com várias zonas
Esta seção explica as etapas que você precisa seguir ao configurar um cluster multizona.
Crie o cluster
Agora que você tem um modelo na plataforma do Cloud Storage, já é possível criar um cluster.
Criar um modelo de instância. Esse modelo é um recurso útil para criar novas instâncias. Consulte Modelos de instância. Substitua
YOUR_PROJECT_NAMEpelo ID do projeto:export INSTANCE_TEMPLATE_NAME="tf-inference-template" export IMAGE_FAMILY="tf-ent-2-10-cu113" export PROJECT_NAME=YOUR_PROJECT_NAME gcloud beta compute --project=$PROJECT_NAME instance-templates create $INSTANCE_TEMPLATE_NAME \ --machine-type=n1-standard-16 \ --maintenance-policy=TERMINATE \ --accelerator=type=nvidia-tesla-t4,count=4 \ --min-cpu-platform=Intel\ Skylake \ --tags=http-server,https-server \ --image-family=$IMAGE_FAMILY \ --image-project=deeplearning-platform-release \ --boot-disk-size=100GB \ --boot-disk-type=pd-ssd \ --boot-disk-device-name=$INSTANCE_TEMPLATE_NAME \ --metadata startup-script-url=gs://cloud-samples-data/dlvm/t4/start_agent_and_inf_server_4.sh- Esse modelo de instância inclui um script de inicialização especificado pelo parâmetro de metadados.
- Execute esse script de inicialização durante a criação de todas as instâncias que usam esse modelo.
- Este script de inicialização executa as etapas a seguir:
- Instala um agente de monitoramento que monitora o uso da GPU na instância.
- Faz o download do modelo.
- Inicia o serviço de inferência.
- No script de inicialização,
tf_serve.pycontém a lógica de inferência. Esse exemplo inclui um arquivo python muito pequeno baseado no pacote TFServe (em inglês). - Para ver o script de inicialização, consulte startup_inf_script.sh.
- Esse modelo de instância inclui um script de inicialização especificado pelo parâmetro de metadados.
Crie um grupo de instâncias gerenciadas (MIG, na sigla em inglês). Esse grupo é necessário para configurar várias instâncias em execução nas zonas específicas. As instâncias são criadas com base no modelo de instância gerado na etapa anterior.
export INSTANCE_GROUP_NAME="deeplearning-instance-group" export INSTANCE_TEMPLATE_NAME="tf-inference-template" gcloud compute instance-groups managed create $INSTANCE_GROUP_NAME \ --template $INSTANCE_TEMPLATE_NAME \ --base-instance-name deeplearning-instances \ --size 2 \ --zones us-central1-a,us-central1-b
É possível criar essa instância em qualquer zona disponível compatível com GPUs T4. Verifique se você tem cotas de GPU disponíveis na zona.
A criação da instância leva algum tempo. Para acompanhar o progresso, execute os seguintes comandos:
export INSTANCE_GROUP_NAME="deeplearning-instance-group"
gcloud compute instance-groups managed list-instances $INSTANCE_GROUP_NAME --region us-central1

Quando o grupo de instâncias gerenciadas é criado, a saída esperada deve ser semelhante à seguinte:

Confirme se as métricas estão disponíveis na página do Google Cloud Cloud Monitoring.
No console do Google Cloud , acesse a página Monitoring.
Se o Metrics Explorer aparecer no painel de navegação, clique nele. Caso contrário, selecione Resources e, em seguida, Metrics Explorer.
Pesquise
gpu_utilization.
Se os dados estiverem entrando, você verá algo como:
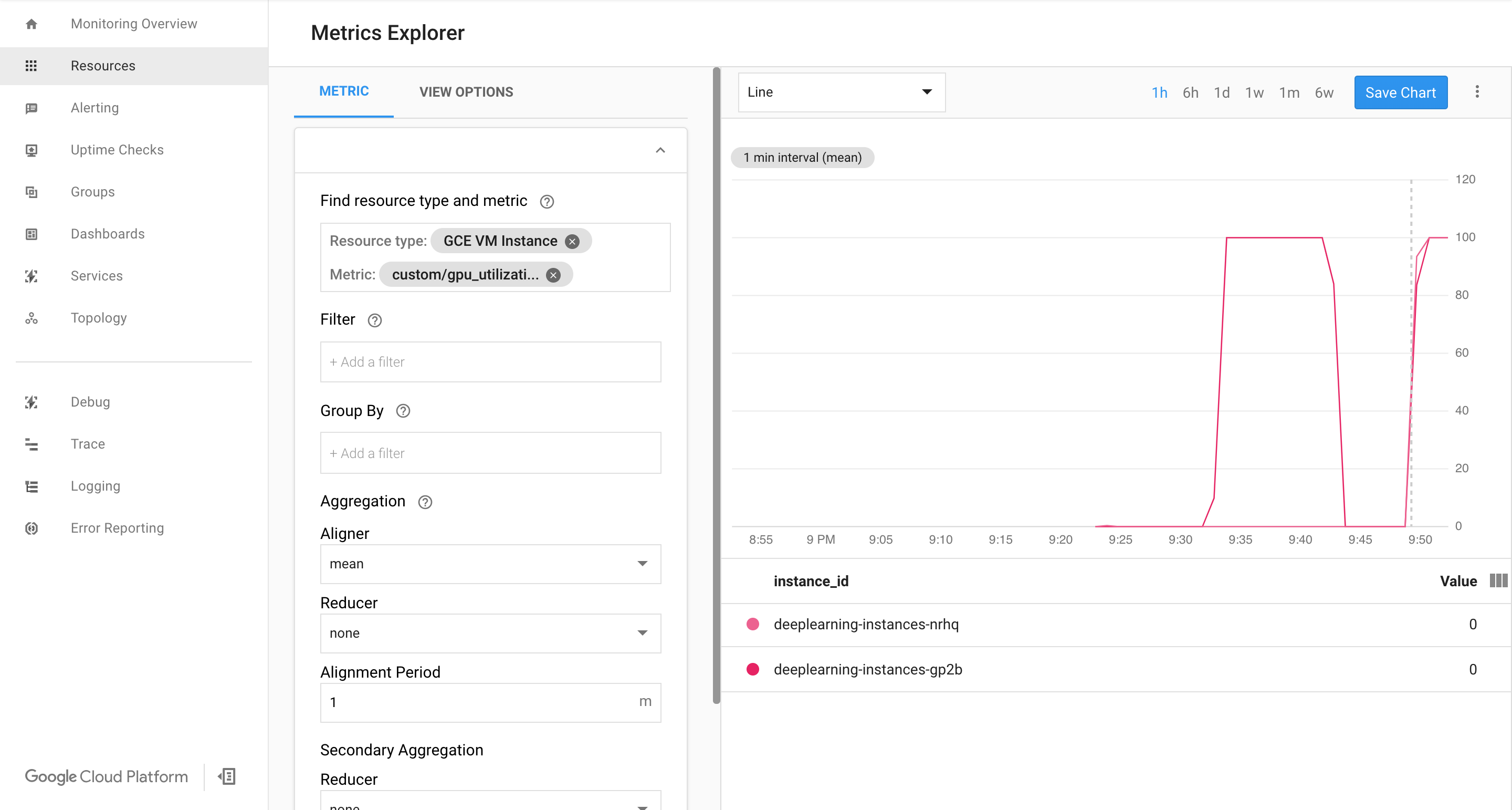
Ativar o escalonamento automático
Ative o escalonamento automático para o grupo de instâncias gerenciadas.
export INSTANCE_GROUP_NAME="deeplearning-instance-group" gcloud compute instance-groups managed set-autoscaling $INSTANCE_GROUP_NAME \ --custom-metric-utilization metric=custom.googleapis.com/gpu_utilization,utilization-target-type=GAUGE,utilization-target=85 \ --max-num-replicas 4 \ --cool-down-period 360 \ --region us-central1
custom.googleapis.com/gpu_utilizationé o caminho completo para nossa métrica. A amostra especifica o nível 85. Isso significa que sempre que a utilização da GPU atingir 85, a plataforma criará uma nova instância no grupo.Teste o escalonamento automático. Para isso, execute as seguintes etapas:
- SSH para a instância. Consulte Como se conectar a instâncias.
Use a ferramenta
gpu-burna fim de carregar a GPU para 100% de utilização por 600 segundos:git clone https://github.com/GoogleCloudPlatform/ml-on-gcp.git cd ml-on-gcp/third_party/gpu-burn git checkout c0b072aa09c360c17a065368294159a6cef59ddf make ./gpu_burn 600 > /dev/null &
Veja a página do Cloud Monitoring. Observe o escalonamento automático. Ao adicionar mais uma instância, o cluster é escalonado.
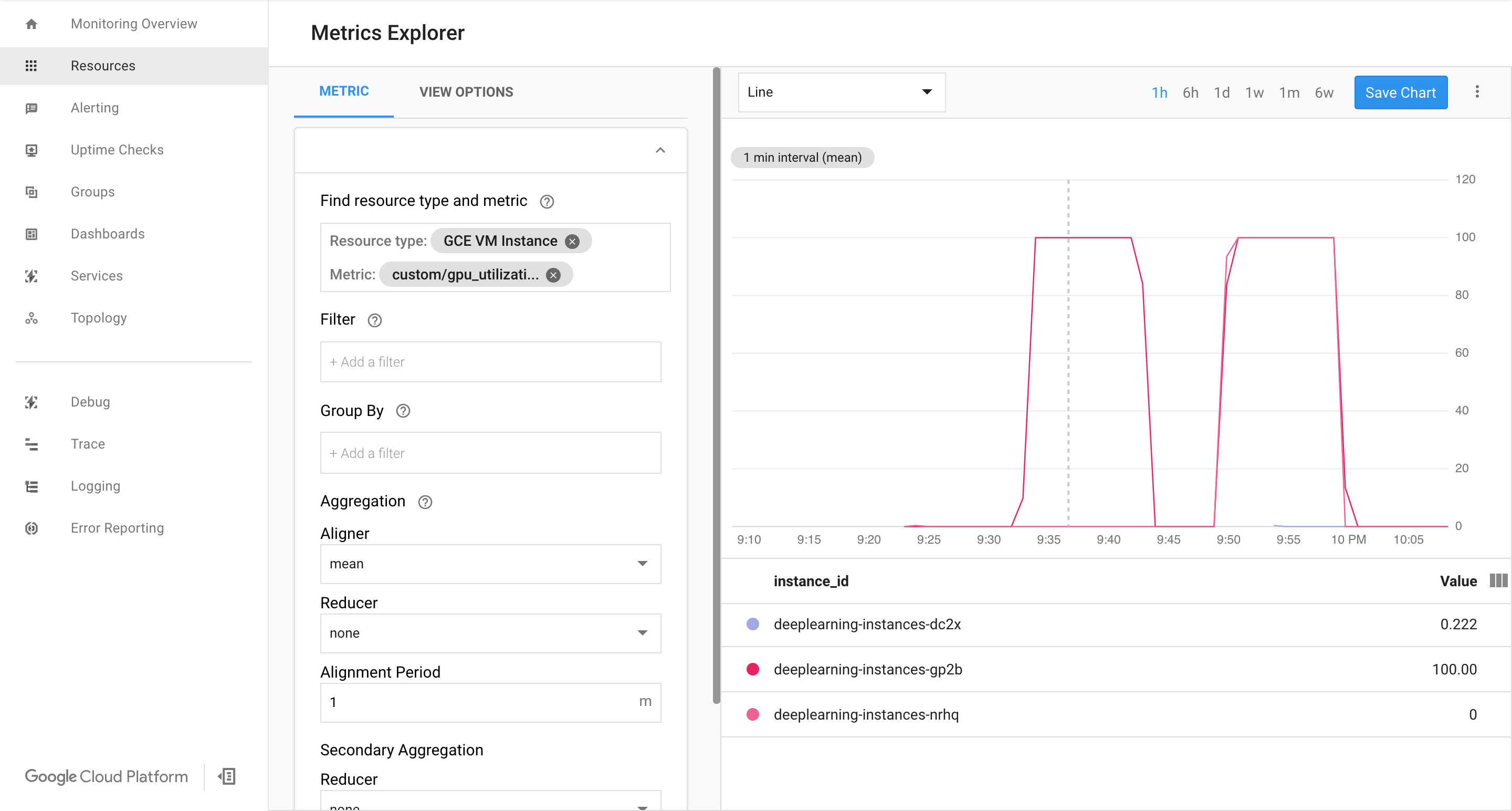
No console, do Google Cloud , acesse a página Grupos de instâncias.
Clique no grupo de instâncias gerenciadas
deeplearning-instance-group.Clique na guia Monitoramento.
Nessa etapa, sua lógica de escalonamento automático tentará girar o maior número possível de instâncias para reduzir a carga, mas não vai conseguir.
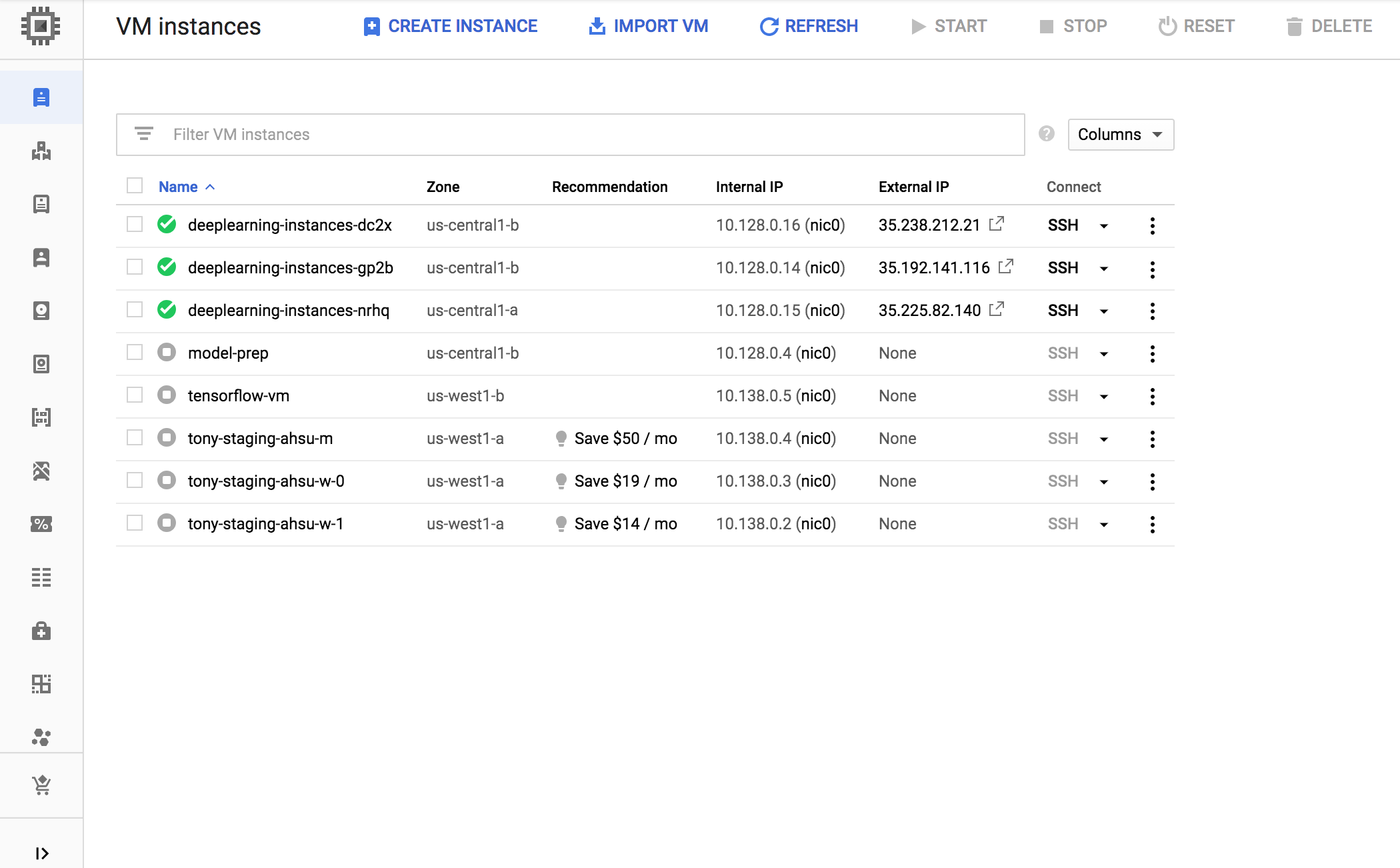
Nesse ponto, é possível parar de gravar instâncias e observar como o sistema é reduzido.
Configurar um balanceador de carga
Vamos recapitular o que você tem até o momento:
- Um modelo treinado, otimizado com a TensorRT5 (INT8).
- Um grupo de instâncias gerenciadas. Essas instâncias têm o recurso de escalonamento automático com base na utilização da GPU ativada.
Agora é possível criar um balanceador de carga na frente das instâncias.
Crie verificações de integridade. Essas verificações são usadas para determinar se um determinado host em nosso back-end pode disponibilizar o tráfego.
export HEALTH_CHECK_NAME="http-basic-check" gcloud compute health-checks create http $HEALTH_CHECK_NAME \ --request-path /v1/models/default \ --port 8888
Crie um serviço de back-end que inclua um grupo de instâncias e uma verificação de integridade.
Crie a verificação de integridade.
export HEALTH_CHECK_NAME="http-basic-check" export WEB_BACKED_SERVICE_NAME="tensorflow-backend" gcloud compute backend-services create $WEB_BACKED_SERVICE_NAME \ --protocol HTTP \ --health-checks $HEALTH_CHECK_NAME \ --global
Adicione o grupo de instâncias ao novo serviço de back-end.
export INSTANCE_GROUP_NAME="deeplearning-instance-group" export WEB_BACKED_SERVICE_NAME="tensorflow-backend" gcloud compute backend-services add-backend $WEB_BACKED_SERVICE_NAME \ --balancing-mode UTILIZATION \ --max-utilization 0.8 \ --capacity-scaler 1 \ --instance-group $INSTANCE_GROUP_NAME \ --instance-group-region us-central1 \ --global
Configure o URL de encaminhamento. O balanceador de carga precisa saber qual URL pode ser encaminhado para os serviços de back-end.
export WEB_BACKED_SERVICE_NAME="tensorflow-backend" export WEB_MAP_NAME="map-all" gcloud compute url-maps create $WEB_MAP_NAME \ --default-service $WEB_BACKED_SERVICE_NAME
Crie o balanceador de carga.
export WEB_MAP_NAME="map-all" export LB_NAME="tf-lb" gcloud compute target-http-proxies create $LB_NAME \ --url-map $WEB_MAP_NAME
Adicione um endereço IP externo ao balanceador de carga.
export IP4_NAME="lb-ip4" gcloud compute addresses create $IP4_NAME \ --ip-version=IPV4 \ --network-tier=PREMIUM \ --global
Encontre o endereço IP alocado.
gcloud compute addresses list
Configure a regra de encaminhamento que orienta o Google Cloud a encaminhar todas as solicitações do endereço IP público para o balanceador de carga.
export IP=$(gcloud compute addresses list | grep ${IP4_NAME} | awk '{print $2}') export LB_NAME="tf-lb" export FORWARDING_RULE="lb-fwd-rule" gcloud compute forwarding-rules create $FORWARDING_RULE \ --address $IP \ --global \ --load-balancing-scheme=EXTERNAL \ --network-tier=PREMIUM \ --target-http-proxy $LB_NAME \ --ports 80Após a criação das regras de encaminhamento globais, a propagação da configuração poderá demorar alguns minutos.
Ativar o firewall
Verifique se suas regras de firewall permitem conexões de fontes externas às instâncias de VM.
gcloud compute firewall-rules list
Se você não tiver regras de firewall que permitam essas conexões, precisará criá-las. Para criar regras de firewall, execute os seguintes comandos:
gcloud compute firewall-rules create www-firewall-80 \ --target-tags http-server --allow tcp:80 gcloud compute firewall-rules create www-firewall-8888 \ --target-tags http-server --allow tcp:8888
Como executar uma inferência
É possível usar o script python a seguir para converter imagens em um formato que pode ser carregado no servidor.
from PIL import Image import numpy as np import json import codecs
img = Image.open("image.jpg").resize((240, 240)) img_array=np.array(img) result = { "instances":[img_array.tolist()] } file_path="/tmp/out.json" print(json.dump(result, codecs.open(file_path, 'w', encoding='utf-8'), separators=(',', ':'), sort_keys=True, indent=4))Execute a inferência.
curl -X POST $IP/v1/models/default:predict -d @/tmp/out.json