Ce tutoriel explique comment exécuter des inférences de deep learning sur des charges de travail à grande échelle à l'aide de GPU NVIDIA TensorRT5 s'exécutant sur Compute Engine.
Avant de commencer, voici quelques notions de base à assimiler :
- L'inférence de deep learning est l'étape du processus de machine learning lors de laquelle un modèle entraîné est utilisé afin de reconnaître, de traiter et de classer des résultats.
- NVIDIA TensorRT est une plate-forme optimisée pour l'exécution de charges de travail de deep learning.
- Les GPU permettent d'accélérer les charges de travail qui consomment beaucoup de données, telles que le machine learning et le traitement des données. Une large gamme de GPU NVIDIA est disponible sur Compute Engine. Ce tutoriel utilise des GPU T4, car ils sont spécialement conçus pour les charges de travail d'inférence de deep learning.
Objectifs
Ce tutoriel décrit comment effectuer les opérations suivantes :
- Préparer un modèle à l'aide d'un graphe pré-entraîné
- Tester la vitesse d'inférence sur un modèle en utilisant différents modes d'optimisation
- Convertir un modèle personnalisé en graphe TensorRT
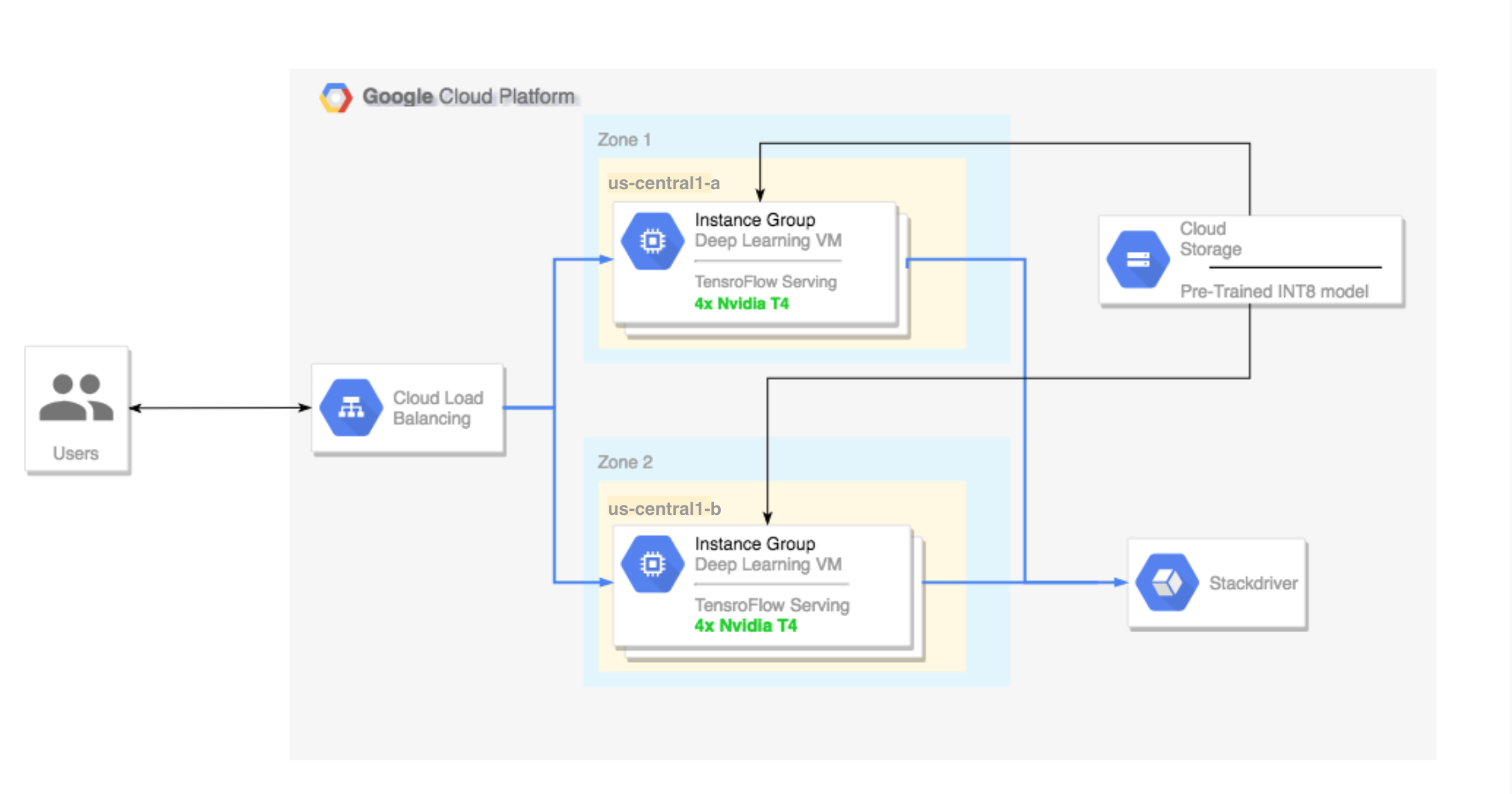
- Définir un cluster multizone configuré de la manière suivante :
- Le cluster est basé sur des instances Deep Learning VM Image. Les services TensorFlow, TensorFlow Serving et TensorRT5 sont pré-installés sur ces images.
- L'autoscaling est activé sur le cluster. L'autoscaling de ce tutoriel est basé sur l'utilisation du GPU.
- L'équilibrage de charge est activé sur le cluster.
- Le pare-feu est activé sur le cluster.
- Une charge de travail d'inférence est exécutée dans le cluster multizone.
Prérequis
Configuration du projet
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Compute Engine and Cloud Machine Learning APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Compute Engine and Cloud Machine Learning APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. - Installez la dernière version de Google Cloud CLI ou appliquez la mise à jour correspondante.
- (Facultatif) Définissez une région et une zone par défaut.
Configuration des outils
Pour utiliser Google Cloud CLI dans ce tutoriel, procédez comme suit :
Préparer le modèle
Cette section décrit comment créer une instance de machine virtuelle (VM) permettant d'exécuter le modèle. Elle explique également comment télécharger un modèle à partir du catalogue de modèles officiels de TensorFlow.
Créez l'instance de VM. Ce tutoriel est créé à l'aide de
tf-ent-2-10-cu113. Pour obtenir les versions d'image les plus récentes, consultez la section Choisir un système d'exploitation dans la documentation de Deep Learning VM Images.export IMAGE_FAMILY="tf-ent-2-10-cu113" export ZONE="us-central1-b" export INSTANCE_NAME="model-prep" gcloud compute instances create $INSTANCE_NAME \ --zone=$ZONE \ --image-family=$IMAGE_FAMILY \ --machine-type=n1-standard-8 \ --image-project=deeplearning-platform-release \ --maintenance-policy=TERMINATE \ --accelerator="type=nvidia-tesla-t4,count=1" \ --metadata="install-nvidia-driver=True"
Sélectionnez un modèle. Ce tutoriel utilise le modèle ResNet, qui a été entraîné à l'aide de l'ensemble de données ImageNet disponible dans TensorFlow.
Pour télécharger le modèle ResNet sur votre instance de VM, exécutez la commande suivante :
wget -q http://download.tensorflow.org/models/official/resnetv2_imagenet_frozen_graph.pb
Enregistrez l'emplacement du modèle ResNet dans la variable
$WORKDIR. RemplacezMODEL_LOCATIONpar le répertoire de travail qui contient le modèle téléchargé.export WORKDIR=MODEL_LOCATION
Tester la vitesse d'inférence
Cette section décrit comment effectuer les opérations suivantes :
- Configurer le modèle ResNet
- Exécuter des tests d'inférence avec différents modes d'optimisation
- Examiner les résultats des tests d'inférence
Présentation du processus de test
TensorRT peut accroître la vitesse des charges de travail d'inférence, mais l'amélioration la plus importante provient du processus de quantification.
La quantification de modèle est un processus permettant de réduire la précision des pondérations d'un modèle. Par exemple, si la pondération initiale d'un modèle correspond à FP32, vous pouvez réduire la précision à FP16, INT8 ou même INT4. Il est important de choisir le bon compromis entre la vitesse (précision des pondérations) et la justesse d'un modèle. Heureusement, TensorFlow inclut des fonctionnalités qui permettent d'effectuer cette démarche. Vous pouvez alors mesurer la justesse par rapport à la vitesse ou à d'autres métriques telles que le débit, la latence, les taux de conversion de nœud et la durée totale de l'entraînement.
Procédure
Configurez le modèle ResNet. Pour ce faire, exécutez les commandes suivantes :
git clone https://github.com/tensorflow/models.git cd models git checkout f0e10716160cd048618ccdd4b6e18336223a172f touch research/__init__.py touch research/tensorrt/__init__.py cp research/tensorrt/labellist.json . cp research/tensorrt/image.jpg ..
Exécutez le test. Cette opération peut prendre un certain temps.
python -m research.tensorrt.tensorrt \ --frozen_graph=$WORKDIR/resnetv2_imagenet_frozen_graph.pb \ --image_file=$WORKDIR/image.jpg \ --native --fp32 --fp16 --int8 \ --output_dir=$WORKDIR
Où :
$WORKDIRest le répertoire dans lequel vous avez téléchargé le modèle ResNet.- Les arguments
--nativecorrespondent aux différents modes de quantification à tester.
Examinez les résultats. Une fois le test terminé, vous pouvez comparer les résultats d'inférence pour chaque mode d'optimisation.
Predictions: Precision: native [u'seashore, coast, seacoast, sea-coast', u'promontory, headland, head, foreland', u'breakwater, groin, groyne, mole, bulwark, seawall, jetty', u'lakeside, lakeshore', u'grey whale, gray whale, devilfish, Eschrichtius gibbosus, Eschrichtius robustus'] Precision: FP32 [u'seashore, coast, seacoast, sea-coast', u'promontory, headland, head, foreland', u'breakwater, groin, groyne, mole, bulwark, seawall, jetty', u'lakeside, lakeshore', u'sandbar, sand bar'] Precision: FP16 [u'seashore, coast, seacoast, sea-coast', u'promontory, headland, head, foreland', u'breakwater, groin, groyne, mole, bulwark, seawall, jetty', u'lakeside, lakeshore', u'sandbar, sand bar'] Precision: INT8 [u'seashore, coast, seacoast, sea-coast', u'promontory, headland, head, foreland', u'breakwater, groin, groyne, mole, bulwark, seawall, jetty', u'grey whale, gray whale, devilfish, Eschrichtius gibbosus, Eschrichtius robustus', u'lakeside, lakeshore']
Pour afficher les résultats complets, exécutez la commande suivante :
cat $WORKDIR/log.txt
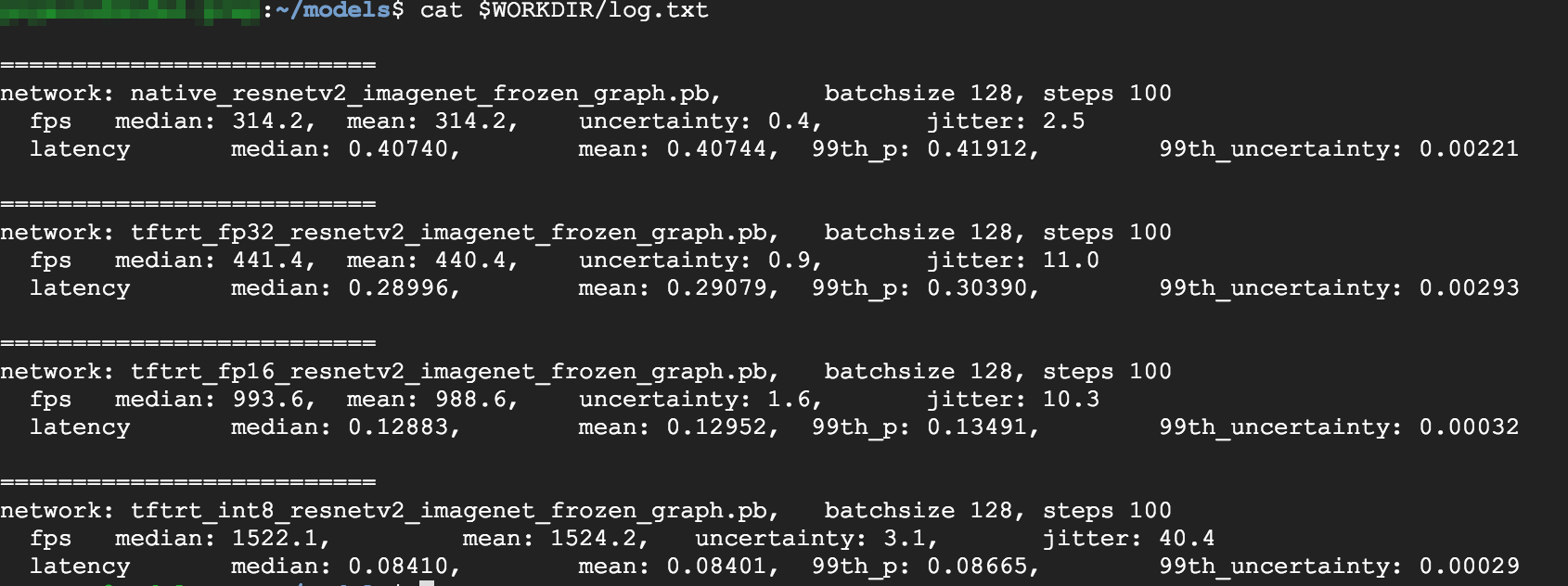
D'après les résultats, vous pouvez constater que les modes FP32 et FP16 sont identiques. Si vous êtes à l'aise avec TensorRT, vous pouvez donc directement commencer à utiliser FP16. Les résultats du mode INT8 sont légèrement moins bons.
En outre, vous pouvez constater que l'exécution du modèle avec TensorRT5 donne les résultats suivants :
- L'optimisation FP32 augmente le débit de 40 % (passe de 314 à 440 FPS). Elle réduit également la latence d'environ 30 % (0,28 ms au lieu de 0,40 ms).
- Par rapport au graphe natif de TensorFlow, l'optimisation FP16 augmente la vitesse de 214 % (passage de 314 à 988 FPS). La latence tombe également à 0,12 ms, soit presque trois fois moins que le graphe natif.
- Avec le mode INT8, vous pouvez observer une accélération de 385 %, avec une fréquence d'images passant de 314 à 1 524 FPS et une latence chutant à 0,08 ms.
Convertir un modèle personnalisé en graphe TensorRT
Pour effectuer cette conversion, vous pouvez utiliser un modèle INT8.
Téléchargez le modèle. Pour convertir un modèle personnalisé en graphe TensorRT, vous avez besoin d'un modèle enregistré. Exécutez la commande suivante pour obtenir un modèle ResNet INT8 enregistré :
wget http://download.tensorflow.org/models/official/20181001_resnet/savedmodels/resnet_v2_fp32_savedmodel_NCHW.tar.gz tar -xzvf resnet_v2_fp32_savedmodel_NCHW.tar.gz
Convertissez le modèle en graphe TensorRT à l'aide de TFTools. Pour ce faire, exécutez la commande suivante :
git clone https://github.com/GoogleCloudPlatform/ml-on-gcp.git cd ml-on-gcp/dlvm/tools python ./convert_to_rt.py \ --input_model_dir=$WORKDIR/resnet_v2_fp32_savedmodel_NCHW/1538687196 \ --output_model_dir=$WORKDIR/resnet_v2_int8_NCHW/00001 \ --batch_size=128 \ --precision_mode="INT8"
Vous disposez maintenant d'un modèle INT8 dans votre répertoire
$WORKDIR/resnet_v2_int8_NCHW/00001.Pour vous assurer que tout est bien configuré, essayez d'exécuter un test d'inférence.
tensorflow_model_server --model_base_path=$WORKDIR/resnet_v2_int8_NCHW/ --rest_api_port=8888
Importez le modèle dans Cloud Storage. Cette étape est nécessaire pour que le modèle puisse être utilisé à partir du cluster multizone, configuré dans la section suivante. Pour importer le modèle, procédez comme suit :
Créez une archive du modèle.
tar -zcvf model.tar.gz ./resnet_v2_int8_NCHW/
Importez l'archive. Remplacez
GCS_PATHpar le chemin d'accès à votre bucket Cloud Storage.export GCS_PATH=GCS_PATH gcloud storage cp model.tar.gz $GCS_PATH
Si nécessaire, vous pouvez obtenir un graphe INT8 figé dans Cloud Storage à l'adresse suivante :
gs://cloud-samples-data/dlvm/t4/model.tar.gz
Configurer un cluster multizone
Cette section explique les étapes à suivre pour configurer un cluster multizone.
Créer le cluster
Maintenant que vous disposez d'un modèle sur la plate-forme Cloud Storage, vous pouvez créer un cluster.
Créez un modèle d'instance. Un modèle d'instance est une ressource utile qui permet de créer des instances. Consultez la page Modèles d'instance pour en savoir plus. Remplacez
YOUR_PROJECT_NAMEpar l'ID de votre projet.export INSTANCE_TEMPLATE_NAME="tf-inference-template" export IMAGE_FAMILY="tf-ent-2-10-cu113" export PROJECT_NAME=YOUR_PROJECT_NAME gcloud beta compute --project=$PROJECT_NAME instance-templates create $INSTANCE_TEMPLATE_NAME \ --machine-type=n1-standard-16 \ --maintenance-policy=TERMINATE \ --accelerator=type=nvidia-tesla-t4,count=4 \ --min-cpu-platform=Intel\ Skylake \ --tags=http-server,https-server \ --image-family=$IMAGE_FAMILY \ --image-project=deeplearning-platform-release \ --boot-disk-size=100GB \ --boot-disk-type=pd-ssd \ --boot-disk-device-name=$INSTANCE_TEMPLATE_NAME \ --metadata startup-script-url=gs://cloud-samples-data/dlvm/t4/start_agent_and_inf_server_4.sh- Ce modèle d'instance inclut un script de démarrage spécifié par le paramètre "metadata".
- Exécutez ce script de démarrage lors de la création de l'instance sur chaque instance utilisant ce modèle.
- Le script de démarrage exécute les tâches suivantes :
- Il installe un agent chargé de surveiller l'utilisation du GPU sur l'instance.
- Il télécharge le modèle.
- Démarrage du service d'inférence
- Dans le script de démarrage, le fichier
tf_serve.pycontient la logique d'inférence. Cet exemple inclut un petit fichier Python basé sur le package TFServe. - Pour afficher le script de démarrage, accédez à la page startup_inf_script.sh.
- Ce modèle d'instance inclut un script de démarrage spécifié par le paramètre "metadata".
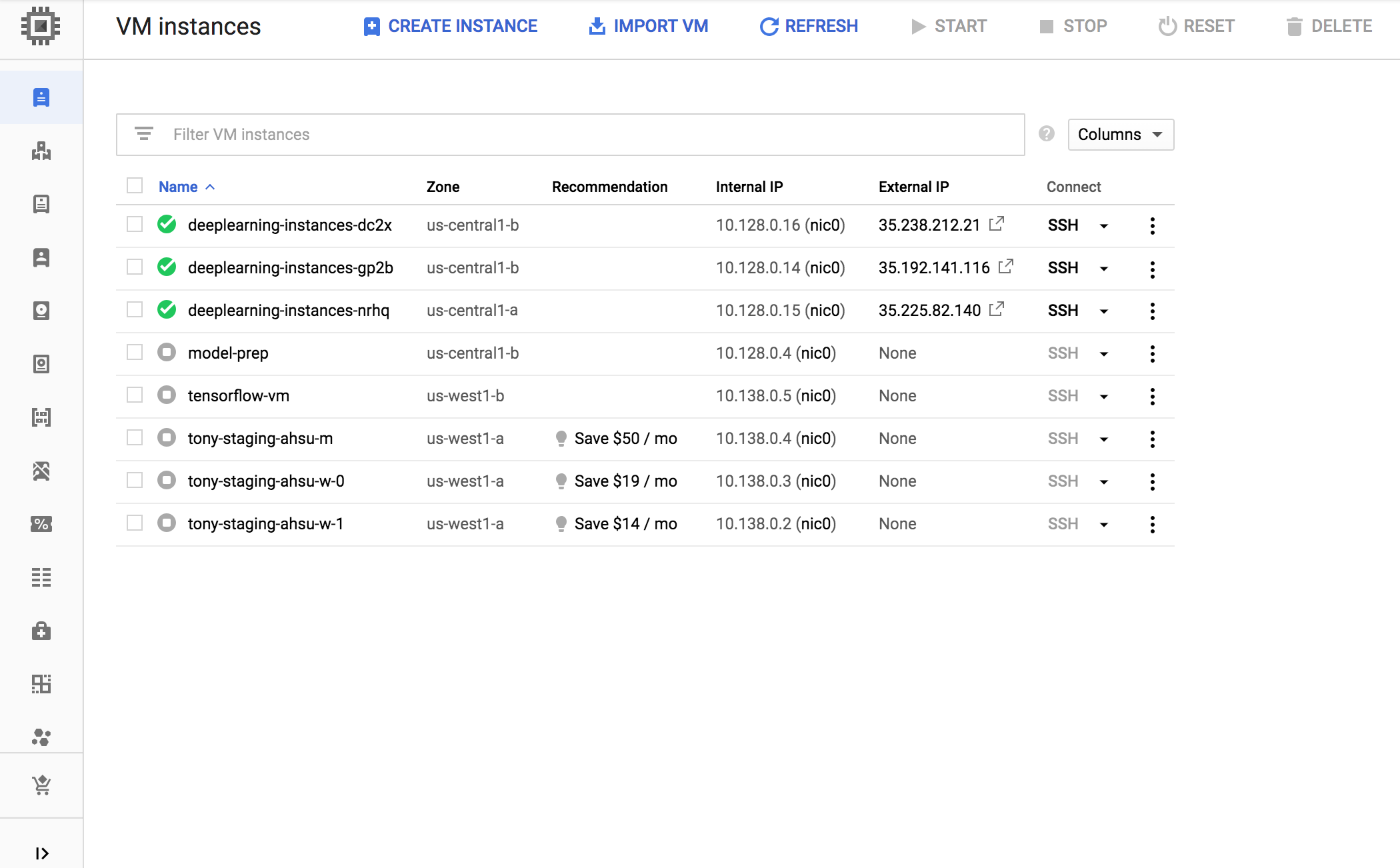
Créez un groupe d'instances géré (MIG, Managed Instance Group). Ce groupe permet de configurer plusieurs instances en cours d'exécution dans des zones spécifiques. Les instances sont créées en fonction du modèle d'instance généré à l'étape précédente.
export INSTANCE_GROUP_NAME="deeplearning-instance-group" export INSTANCE_TEMPLATE_NAME="tf-inference-template" gcloud compute instance-groups managed create $INSTANCE_GROUP_NAME \ --template $INSTANCE_TEMPLATE_NAME \ --base-instance-name deeplearning-instances \ --size 2 \ --zones us-central1-a,us-central1-b
Vous pouvez créer cette instance dans n'importe quelle zone disponible compatible avec les GPU T4. Assurez-vous de disposer d'un quota de GPU suffisant dans la zone.
La création de l'instance prend un certain temps. Vous pouvez suivre la progression de cette étape en exécutant les commandes suivantes :
export INSTANCE_GROUP_NAME="deeplearning-instance-group"
gcloud compute instance-groups managed list-instances $INSTANCE_GROUP_NAME --region us-central1

Une fois le groupe d'instances géré créé, un résultat semblable aux lignes suivantes doit s'afficher :

Vérifiez que les métriques sont disponibles sur la page Google Cloud Cloud Monitoring.
Dans la console Google Cloud , accédez à la page Monitoring.
Si l'explorateur de métriques s'affiche dans le volet de navigation, cliquez sur Metrics Explorer (Explorateur de métriques). Sinon, sélectionnez Resources (Ressources), puis Metrics Explorer (Explorateur de métriques).
Recherchez
gpu_utilization.
Si des données sont enregistrées, vous devriez voir un écran similaire à ceci :
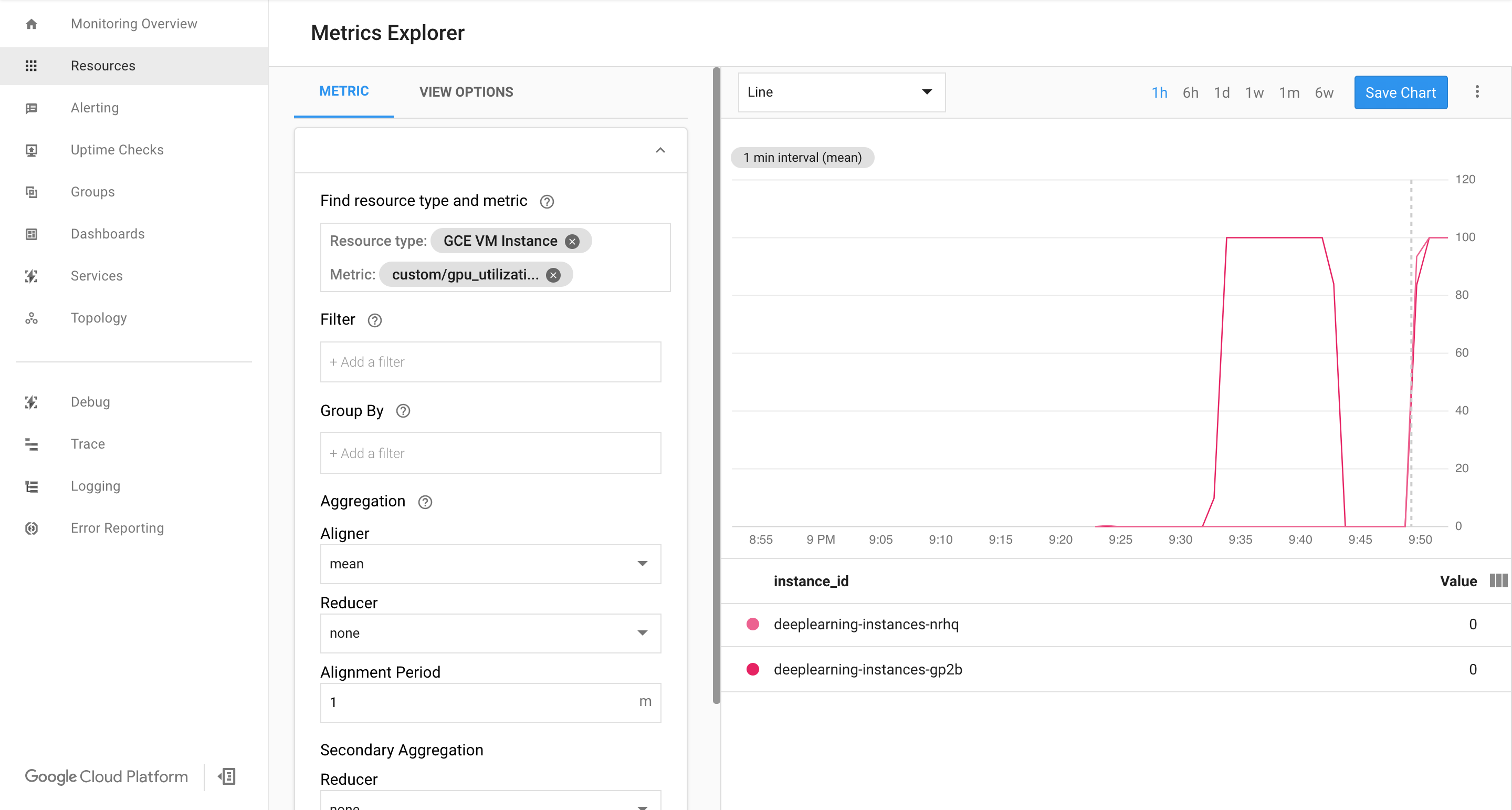
Activer l'autoscaling
Activez l'autoscaling sur le groupe d'instances géré.
export INSTANCE_GROUP_NAME="deeplearning-instance-group" gcloud compute instance-groups managed set-autoscaling $INSTANCE_GROUP_NAME \ --custom-metric-utilization metric=custom.googleapis.com/gpu_utilization,utilization-target-type=GAUGE,utilization-target=85 \ --max-num-replicas 4 \ --cool-down-period 360 \ --region us-central1
custom.googleapis.com/gpu_utilizationcorrespond au chemin d'accès complet à notre métrique. L'exemple spécifie le niveau 85, ce qui signifie que chaque fois que l'utilisation du GPU atteint 85 %, la plate-forme crée une instance dans notre groupe.Testez l'autoscaling. Pour ce faire, effectuez les étapes suivantes :
- Connectez-vous en SSH à l'instance. Consultez la page Se connecter à des instances pour en savoir plus.
À l'aide de l'outil
gpu-burn, faites grimper le taux d'utilisation du GPU à 100 % et maintenez-le à ce niveau pendant 600 secondes :git clone https://github.com/GoogleCloudPlatform/ml-on-gcp.git cd ml-on-gcp/third_party/gpu-burn git checkout c0b072aa09c360c17a065368294159a6cef59ddf make ./gpu_burn 600 > /dev/null &
Affichez la page Cloud Monitoring. Observez l'autoscaling. Le cluster ajoute une instance supplémentaire.
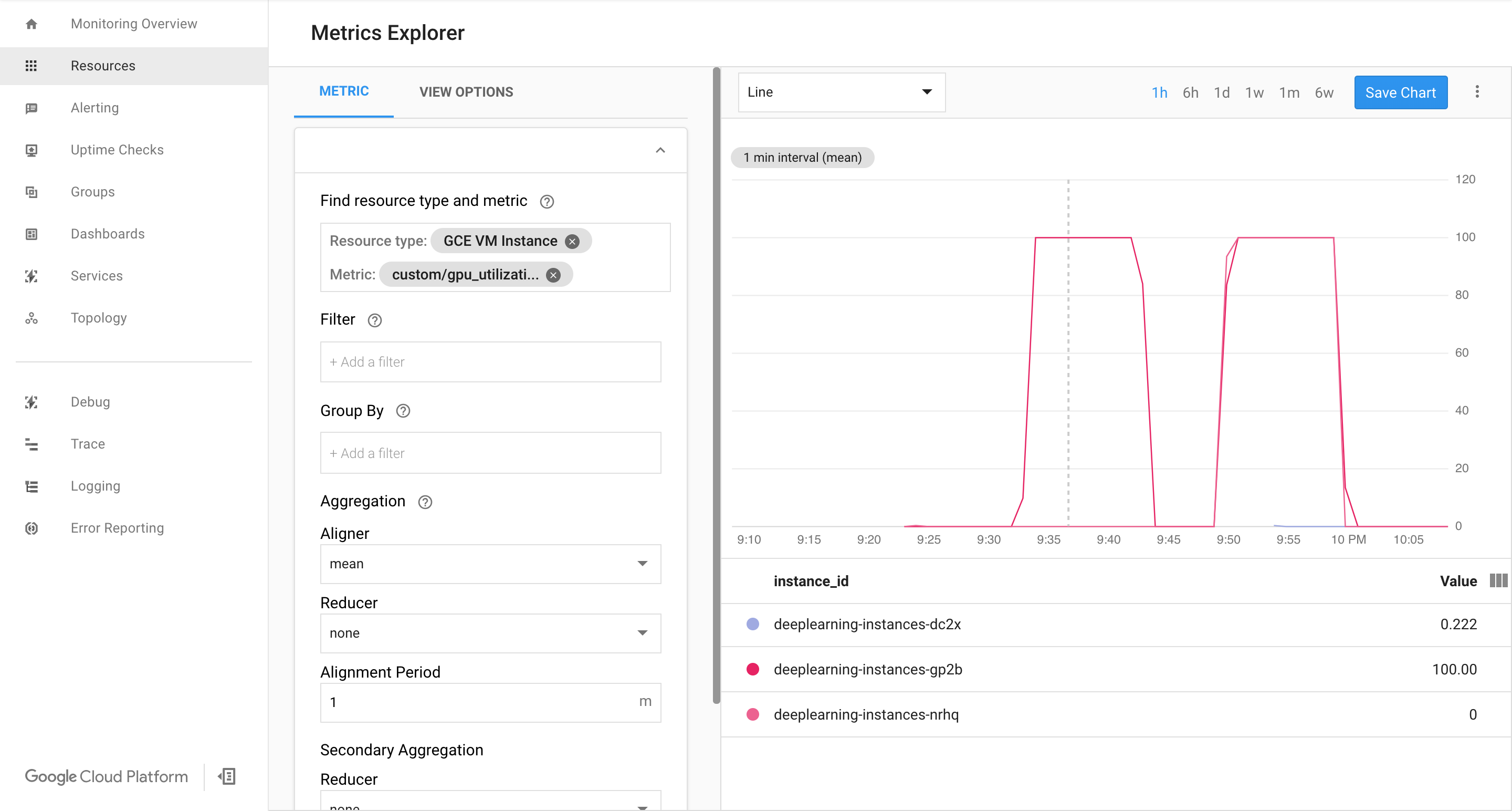
Dans la console Google Cloud , accédez à la page Groupes d'instances.
Cliquez sur le groupe d'instances géré
deeplearning-instance-group.Cliquez sur l'onglet Surveillance.
À ce stade, votre logique d'autoscaling devrait essayer de démarrer un maximum d'instances pour réduire la charge, sans succès.
Vous pouvez désormais arrêter de surmener les instances et observer comment le système réduit leur nombre.
Configurer un équilibreur de charge
Passons en revue les ressources à votre disposition :
- Un modèle entraîné, optimisé avec TensorRT5 (INT8)
- Un groupe d'instances géré (l'autoscaling est activé sur ces instances, dont le nombre dépend de l'utilisation du GPU)
Vous pouvez maintenant créer un équilibreur de charge devant les instances.
Créez des vérifications d'état. Elles permettent de déterminer si un hôte spécifique sur notre backend peut diffuser le trafic.
export HEALTH_CHECK_NAME="http-basic-check" gcloud compute health-checks create http $HEALTH_CHECK_NAME \ --request-path /v1/models/default \ --port 8888
Créez un backend comprenant un groupe d'instances et une vérification d'état.
Créez la vérification d'état.
export HEALTH_CHECK_NAME="http-basic-check" export WEB_BACKED_SERVICE_NAME="tensorflow-backend" gcloud compute backend-services create $WEB_BACKED_SERVICE_NAME \ --protocol HTTP \ --health-checks $HEALTH_CHECK_NAME \ --global
Ajoutez le groupe d'instances au nouveau service de backend.
export INSTANCE_GROUP_NAME="deeplearning-instance-group" export WEB_BACKED_SERVICE_NAME="tensorflow-backend" gcloud compute backend-services add-backend $WEB_BACKED_SERVICE_NAME \ --balancing-mode UTILIZATION \ --max-utilization 0.8 \ --capacity-scaler 1 \ --instance-group $INSTANCE_GROUP_NAME \ --instance-group-region us-central1 \ --global
Configurez l'URL de transfert. L'équilibreur de charge doit savoir quelle URL peut être transférée aux services de backend.
export WEB_BACKED_SERVICE_NAME="tensorflow-backend" export WEB_MAP_NAME="map-all" gcloud compute url-maps create $WEB_MAP_NAME \ --default-service $WEB_BACKED_SERVICE_NAME
Créez l'équilibreur de charge.
export WEB_MAP_NAME="map-all" export LB_NAME="tf-lb" gcloud compute target-http-proxies create $LB_NAME \ --url-map $WEB_MAP_NAME
Ajoutez une adresse IP externe à l'équilibreur de charge.
export IP4_NAME="lb-ip4" gcloud compute addresses create $IP4_NAME \ --ip-version=IPV4 \ --network-tier=PREMIUM \ --global
Recherchez l'adresse IP attribuée.
gcloud compute addresses list
Configurez la règle de transfert qui indique à Google Cloud de transférer toutes les requêtes provenant de l'adresse IP publique à l'équilibreur de charge.
export IP=$(gcloud compute addresses list | grep ${IP4_NAME} | awk '{print $2}') export LB_NAME="tf-lb" export FORWARDING_RULE="lb-fwd-rule" gcloud compute forwarding-rules create $FORWARDING_RULE \ --address $IP \ --global \ --load-balancing-scheme=EXTERNAL \ --network-tier=PREMIUM \ --target-http-proxy $LB_NAME \ --ports 80Une fois les règles de transfert globales créées, la propagation de votre configuration peut prendre plusieurs minutes.
Activer le pare-feu
Vérifiez que vous disposez de règles de pare-feu autorisant les connexions provenant de sources externes à vos instances de VM.
gcloud compute firewall-rules list
Si vous ne possédez pas de règles de pare-feu autorisant ces connexions, vous devez les créer. Pour ce faire, exécutez les commandes suivantes :
gcloud compute firewall-rules create www-firewall-80 \ --target-tags http-server --allow tcp:80 gcloud compute firewall-rules create www-firewall-8888 \ --target-tags http-server --allow tcp:8888
Exécuter une inférence
Vous pouvez exploiter le script Python suivant pour convertir des images dans un format pouvant être importé sur le serveur.
from PIL import Image import numpy as np import json import codecs
img = Image.open("image.jpg").resize((240, 240)) img_array=np.array(img) result = { "instances":[img_array.tolist()] } file_path="/tmp/out.json" print(json.dump(result, codecs.open(file_path, 'w', encoding='utf-8'), separators=(',', ':'), sort_keys=True, indent=4))Exécutez l'inférence.
curl -X POST $IP/v1/models/default:predict -d @/tmp/out.json