En este instructivo, se trata cómo ejecutar inferencias de aprendizaje profundo en cargas de trabajo a gran escala con GPU NVIDIA TensorRT5 que se ejecutan en Compute Engine.
Antes de comenzar, ten en cuenta la siguiente información importante:
- La inferencia de aprendizaje profundo es la etapa del proceso de aprendizaje automático en la que se usa un modelo entrenado para reconocer, procesar y clasificar los resultados.
- NVIDIA TensorRT es una plataforma optimizada para ejecutar cargas de trabajo de aprendizaje profundo.
- Las GPU se usan para acelerar las cargas de trabajo con grandes volúmenes de datos, como el aprendizaje automático y el procesamiento de datos. Hay una gran variedad de GPU NVIDIA disponibles en Compute Engine . En este instructivo, se usan las GPU T4, ya que están diseñadas específicamente para cargas de trabajo de inferencia de aprendizaje profundo.
Objetivos
En este instructivo, se abordan los siguientes procedimientos:
- Preparación de un modelo con un grafo previamente entrenado.
- Prueba de velocidad de inferencia para un modelo con diferentes modos de optimización.
- Conversión de un modelo personalizado en TensorRT.
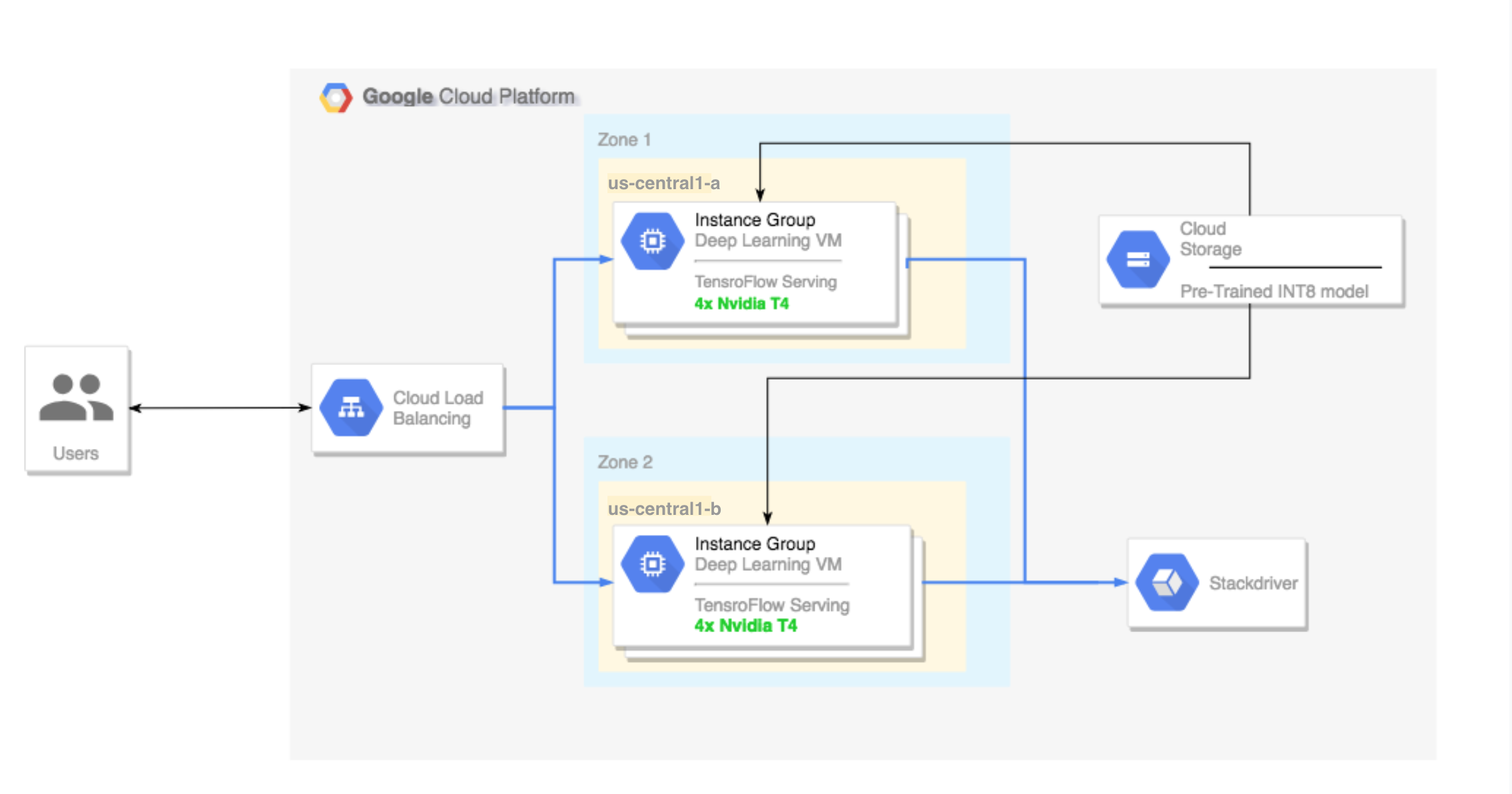
- Configuración de un clúster multizona. El clúster multizona se configura de la siguiente manera:
- Compilado en Deep Learning VM Images. Estas imágenes se preinstalan con TensorFlow, TensorFlow Serving y TensorRT5.
- El ajuste de escala automático está habilitado. En este instructivo, el ajuste de escala automático tiene base en el uso de la GPU.
- El balanceo de cargas está habilitado.
- Firewall está habilitado.
- Ejecución de una carga de trabajo de inferencia en el clúster multizona.
Requisitos previos
Configura el proyecto
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Compute Engine and Cloud Machine Learning APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Compute Engine and Cloud Machine Learning APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. - Instala Google Cloud CLI o actualízala a la última versión.
- Configura una región y una zona predeterminadas (opcional).
Configuración de las herramientas
Para usar Google Cloud CLI en este instructivo, sigue estos pasos:
Prepara el modelo
En esta sección, se abarca la creación de una instancia de máquina virtual (VM) que se usa para ejecutar el modelo. En esta sección, también se aborda cómo descargar un modelo del catálogo oficial de modelos de TensorFlow.
Crea la instancia de VM. Este instructivo se crea mediante
tf-ent-2-10-cu113. Para obtener las versiones de imágenes más recientes, consulta Elige un sistema operativo en la documentación de Deep Learning VM Images.export IMAGE_FAMILY="tf-ent-2-10-cu113" export ZONE="us-central1-b" export INSTANCE_NAME="model-prep" gcloud compute instances create $INSTANCE_NAME \ --zone=$ZONE \ --image-family=$IMAGE_FAMILY \ --machine-type=n1-standard-8 \ --image-project=deeplearning-platform-release \ --maintenance-policy=TERMINATE \ --accelerator="type=nvidia-tesla-t4,count=1" \ --metadata="install-nvidia-driver=True"
Selecciona un modelo. En este instructivo, se usa el modelo ResNet. Este modelo ResNet está entrenado en el conjunto de datos ImageNet que está en TensorFlow.
Para descargar el modelo ResNet a tu instancia de VM, ejecuta el siguiente comando:
wget -q http://download.tensorflow.org/models/official/resnetv2_imagenet_frozen_graph.pb
Guarda la ubicación de tu modelo ResNet en la variable
$WORKDIR. ReemplazaMODEL_LOCATIONpor el directorio de trabajo que contiene el modelo descargado.export WORKDIR=MODEL_LOCATION
Ejecuta la prueba de velocidad de inferencia
En esta sección, se abarcan los siguientes procedimientos:
- Configuración del modelo ResNet.
- Ejecución de pruebas de inferencia en diferentes modos de optimización.
- Revisión de los resultados de las pruebas de inferencia.
Descripción general del proceso de prueba
TensorRT puede mejorar la velocidad de rendimiento de las cargas de trabajo de inferencia, sin embargo, la mejora más importante proviene del proceso de cuantización.
La cuantización del modelo es el proceso mediante el cual se reduce la precisión de los pesos de un modelo. Por ejemplo, si el peso inicial de un modelo es FP32, puedes reducir la precisión a FP16, INT8 o incluso INT4. Es importante elegir el compromiso correcto entre la velocidad (precisión de los pesos) y la exactitud de un modelo. Por suerte, TensorFlow incluye una funcionalidad que hace exactamente esto y mide la exactitud frente a la velocidad o algunas otras métricas como la capacidad de procesamiento, la latencia, el porcentaje de conversiones de nodos y el tiempo total de entrenamiento.
Procedimiento
Configura el modelo ResNet. A fin de configurar el modelo, ejecuta los siguientes comandos:
git clone https://github.com/tensorflow/models.git cd models git checkout f0e10716160cd048618ccdd4b6e18336223a172f touch research/__init__.py touch research/tensorrt/__init__.py cp research/tensorrt/labellist.json . cp research/tensorrt/image.jpg ..
Ejecuta la prueba. Este comando tarda un poco en completarse.
python -m research.tensorrt.tensorrt \ --frozen_graph=$WORKDIR/resnetv2_imagenet_frozen_graph.pb \ --image_file=$WORKDIR/image.jpg \ --native --fp32 --fp16 --int8 \ --output_dir=$WORKDIR
Donde:
$WORKDIRes el directorio en el que descargaste el modelo ResNet.- Los argumentos
--nativeson los diferentes modos de cuantización que deseas probar.
Revisa los resultados. Cuando se complete la prueba, puedes hacer una comparación de los resultados de la inferencia para cada modo de optimización.
Predictions: Precision: native [u'seashore, coast, seacoast, sea-coast', u'promontory, headland, head, foreland', u'breakwater, groin, groyne, mole, bulwark, seawall, jetty', u'lakeside, lakeshore', u'grey whale, gray whale, devilfish, Eschrichtius gibbosus, Eschrichtius robustus'] Precision: FP32 [u'seashore, coast, seacoast, sea-coast', u'promontory, headland, head, foreland', u'breakwater, groin, groyne, mole, bulwark, seawall, jetty', u'lakeside, lakeshore', u'sandbar, sand bar'] Precision: FP16 [u'seashore, coast, seacoast, sea-coast', u'promontory, headland, head, foreland', u'breakwater, groin, groyne, mole, bulwark, seawall, jetty', u'lakeside, lakeshore', u'sandbar, sand bar'] Precision: INT8 [u'seashore, coast, seacoast, sea-coast', u'promontory, headland, head, foreland', u'breakwater, groin, groyne, mole, bulwark, seawall, jetty', u'grey whale, gray whale, devilfish, Eschrichtius gibbosus, Eschrichtius robustus', u'lakeside, lakeshore']
Para ver los resultados completos, ejecuta el siguiente comando:
cat $WORKDIR/log.txt
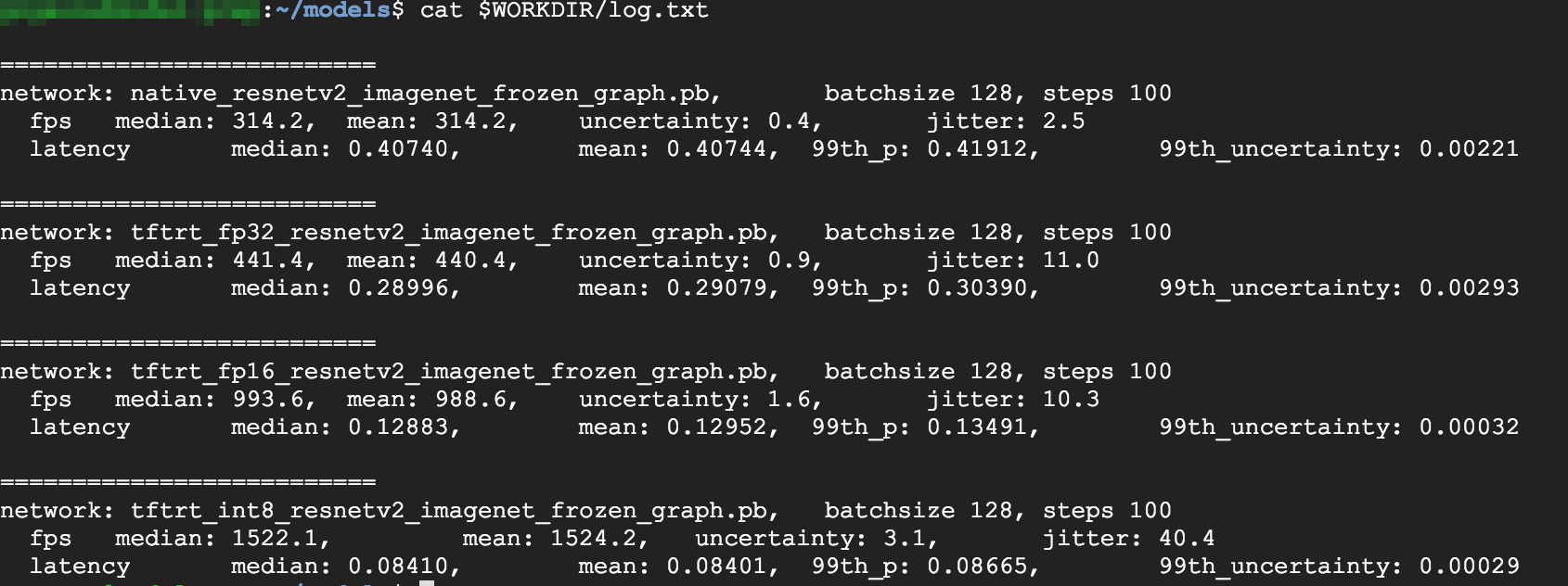
A partir de los resultados, puedes ver que FP32 y FP16 son idénticos. Esto significa que, si te sientes cómodo trabajando con TensorRT, puedes comenzar a usar FP16 de inmediato. INT8, muestra resultados un poco peores.
Además, puedes ver que la ejecución del modelo con TensorRT5 muestra los siguientes resultados:
- Con la optimización FP32, el rendimiento mejora un 40%, de 314 fps a 440 fps. Al mismo tiempo, la latencia disminuye casi un 30%, por lo que es 0.28 ms en lugar de 0.40 ms.
- Con la optimización FP16, en lugar del grafo nativo de TensorFlow, la velocidad aumenta un 214%, de 314 a 988 fps. Al mismo tiempo, la latencia disminuye en 0.12 ms, una disminución de casi el triple.
- Con INT8, se puede notar una aceleración del 385%, de 314 fps a 1,524 fps, con una latencia que disminuye a 0.08 ms.
Convierte un modelo personalizado en TensorRT
Para esta conversión, puedes usar un modelo INT8.
Descarga el modelo. Para convertir un modelo personalizado en un grafo TensorRT, necesitas un modelo guardado. Para obtener un modelo ResNet INT8 guardado, ejecuta el siguiente comando:
wget http://download.tensorflow.org/models/official/20181001_resnet/savedmodels/resnet_v2_fp32_savedmodel_NCHW.tar.gz tar -xzvf resnet_v2_fp32_savedmodel_NCHW.tar.gz
Convierte el modelo en el grafo de TensorRT con TFTools. Para convertir el modelo con TFTools, ejecuta el siguiente comando:
git clone https://github.com/GoogleCloudPlatform/ml-on-gcp.git cd ml-on-gcp/dlvm/tools python ./convert_to_rt.py \ --input_model_dir=$WORKDIR/resnet_v2_fp32_savedmodel_NCHW/1538687196 \ --output_model_dir=$WORKDIR/resnet_v2_int8_NCHW/00001 \ --batch_size=128 \ --precision_mode="INT8"
Ahora tienes un modelo INT8 en tu directorio
$WORKDIR/resnet_v2_int8_NCHW/00001.Para asegurarte de que todo esté configurado como corresponde, intenta ejecutar una prueba de inferencia.
tensorflow_model_server --model_base_path=$WORKDIR/resnet_v2_int8_NCHW/ --rest_api_port=8888
Sube el modelo a Cloud Storage. Este paso es necesario para que el modelo se pueda usar desde el clúster de varias zonas que se configura en la siguiente sección. Para subir el modelo, sigue estos pasos:
Archiva el modelo.
tar -zcvf model.tar.gz ./resnet_v2_int8_NCHW/
Sube el archivo. Reemplaza
GCS_PATHpor la ruta de acceso a tu bucket de Cloud Storage.export GCS_PATH=GCS_PATH gcloud storage cp model.tar.gz $GCS_PATH
Si es necesario, puedes obtener un grafo inmovilizado de INT8 desde Cloud Storage en esta URL:
gs://cloud-samples-data/dlvm/t4/model.tar.gz
Configura un clúster de varias zonas
En esta sección, se explican los pasos que debes seguir para configurar un clúster multizonal.
Crea el clúster
Ahora que tienes un modelo en la plataforma de Cloud Storage, puedes crear un clúster.
Crea una plantilla de instancias. Una plantilla de instancias es un recurso útil para crear instancias nuevas. Consulta Plantillas de instancias. Reemplaza
YOUR_PROJECT_NAMEpor el ID del proyecto.export INSTANCE_TEMPLATE_NAME="tf-inference-template" export IMAGE_FAMILY="tf-ent-2-10-cu113" export PROJECT_NAME=YOUR_PROJECT_NAME gcloud beta compute --project=$PROJECT_NAME instance-templates create $INSTANCE_TEMPLATE_NAME \ --machine-type=n1-standard-16 \ --maintenance-policy=TERMINATE \ --accelerator=type=nvidia-tesla-t4,count=4 \ --min-cpu-platform=Intel\ Skylake \ --tags=http-server,https-server \ --image-family=$IMAGE_FAMILY \ --image-project=deeplearning-platform-release \ --boot-disk-size=100GB \ --boot-disk-type=pd-ssd \ --boot-disk-device-name=$INSTANCE_TEMPLATE_NAME \ --metadata startup-script-url=gs://cloud-samples-data/dlvm/t4/start_agent_and_inf_server_4.sh- En esta plantilla de instancia, se incluye una secuencia de comandos de inicio especificada por el parámetro de metadatos.
- Ejecuta esta secuencia de comandos de inicio durante la creación de la instancia en cada instancia que use esta plantilla.
- Esta secuencia de comandos de inicio realiza los siguientes pasos:
- Instala un agente de supervisión que supervisa el uso de la GPU en la instancia.
- Descarga el modelo.
- Inicia el servicio de inferencia.
- En la secuencia de comandos de inicio,
tf_serve.pycontiene la lógica de inferencia. En este ejemplo, se incluye un archivo Python muy pequeño con base en el paquete TFServe. - Para ver la secuencia de comandos de inicio, consulta startup_inf_script.sh.
- En esta plantilla de instancia, se incluye una secuencia de comandos de inicio especificada por el parámetro de metadatos.
Crea un grupo de instancias administrado (MIG). Este grupo de instancias administrado es necesario para configurar varias instancias en ejecución en zonas específicas. Las instancias se crean en función de la plantilla de instancias que se generó en el paso anterior.
export INSTANCE_GROUP_NAME="deeplearning-instance-group" export INSTANCE_TEMPLATE_NAME="tf-inference-template" gcloud compute instance-groups managed create $INSTANCE_GROUP_NAME \ --template $INSTANCE_TEMPLATE_NAME \ --base-instance-name deeplearning-instances \ --size 2 \ --zones us-central1-a,us-central1-b
Puedes crear esta instancia en cualquier zona disponible que sea compatible con las GPU T4. Asegúrate de tener cuotas de GPU disponibles en la zona.
La creación de la instancia demora un poco. Para ver el progreso, puedes ejecutar los siguientes comandos:
export INSTANCE_GROUP_NAME="deeplearning-instance-group"
gcloud compute instance-groups managed list-instances $INSTANCE_GROUP_NAME --region us-central1

Cuando se crea el grupo de instancias administrado, debería aparecer un resultado similar al siguiente:

Confirma que las métricas están disponibles en la página de Google Cloud Cloud Monitoring.
En la consola de Google Cloud , ve a la página Monitoring.
Si el Explorador de métricas aparece en el panel de navegación, haz clic en Explorador de métricas. De lo contrario, selecciona Recursos y, luego, Explorador de métricas.
Busca
gpu_utilization.
Si entran datos, deberías ver algo como lo siguiente:
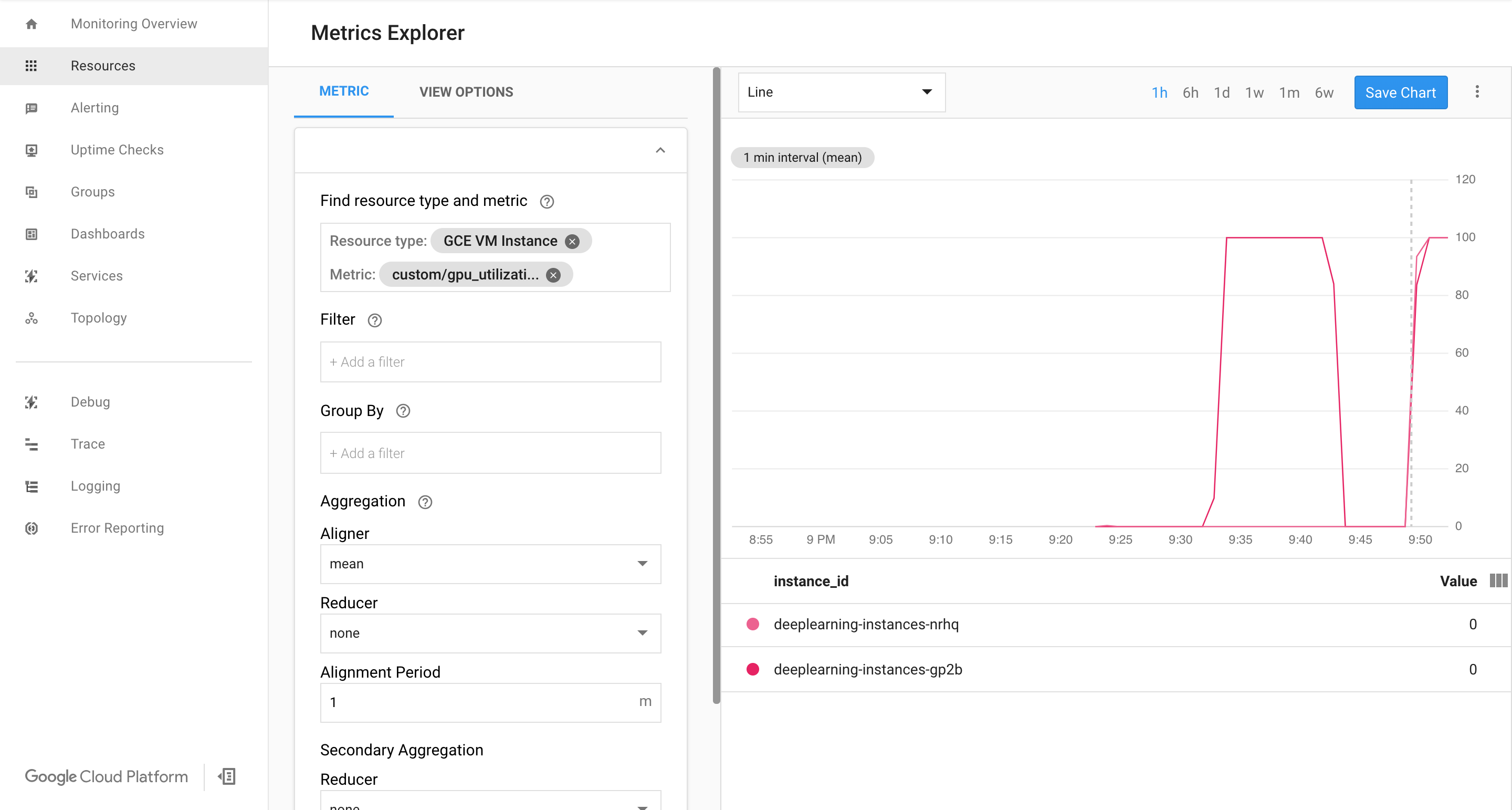
Habilitar ajuste de escala automático
Habilita el ajuste de escala automático para el grupo de instancias administrado.
export INSTANCE_GROUP_NAME="deeplearning-instance-group" gcloud compute instance-groups managed set-autoscaling $INSTANCE_GROUP_NAME \ --custom-metric-utilization metric=custom.googleapis.com/gpu_utilization,utilization-target-type=GAUGE,utilization-target=85 \ --max-num-replicas 4 \ --cool-down-period 360 \ --region us-central1
custom.googleapis.com/gpu_utilizationes la ruta completa de acceso a nuestra métrica. El ejemplo especifica el nivel 85, es decir, cuando el uso de GPU llega a 85, la plataforma crea una instancia nueva en nuestro grupo.Prueba el ajuste de escala automático. Para probar el ajuste de escala automático, sigue estos pasos:
- Establece una conexión SSH a la instancia. Consulta Conéctate a instancias.
Usa la herramienta
gpu-burnpara cargar tu GPU al 100% de uso durante 600 segundos:git clone https://github.com/GoogleCloudPlatform/ml-on-gcp.git cd ml-on-gcp/third_party/gpu-burn git checkout c0b072aa09c360c17a065368294159a6cef59ddf make ./gpu_burn 600 > /dev/null &
Visualiza la página de Cloud Monitoring. Observa el ajuste de escala automático. El clúster escala verticalmente mediante la adición de una instancia más.
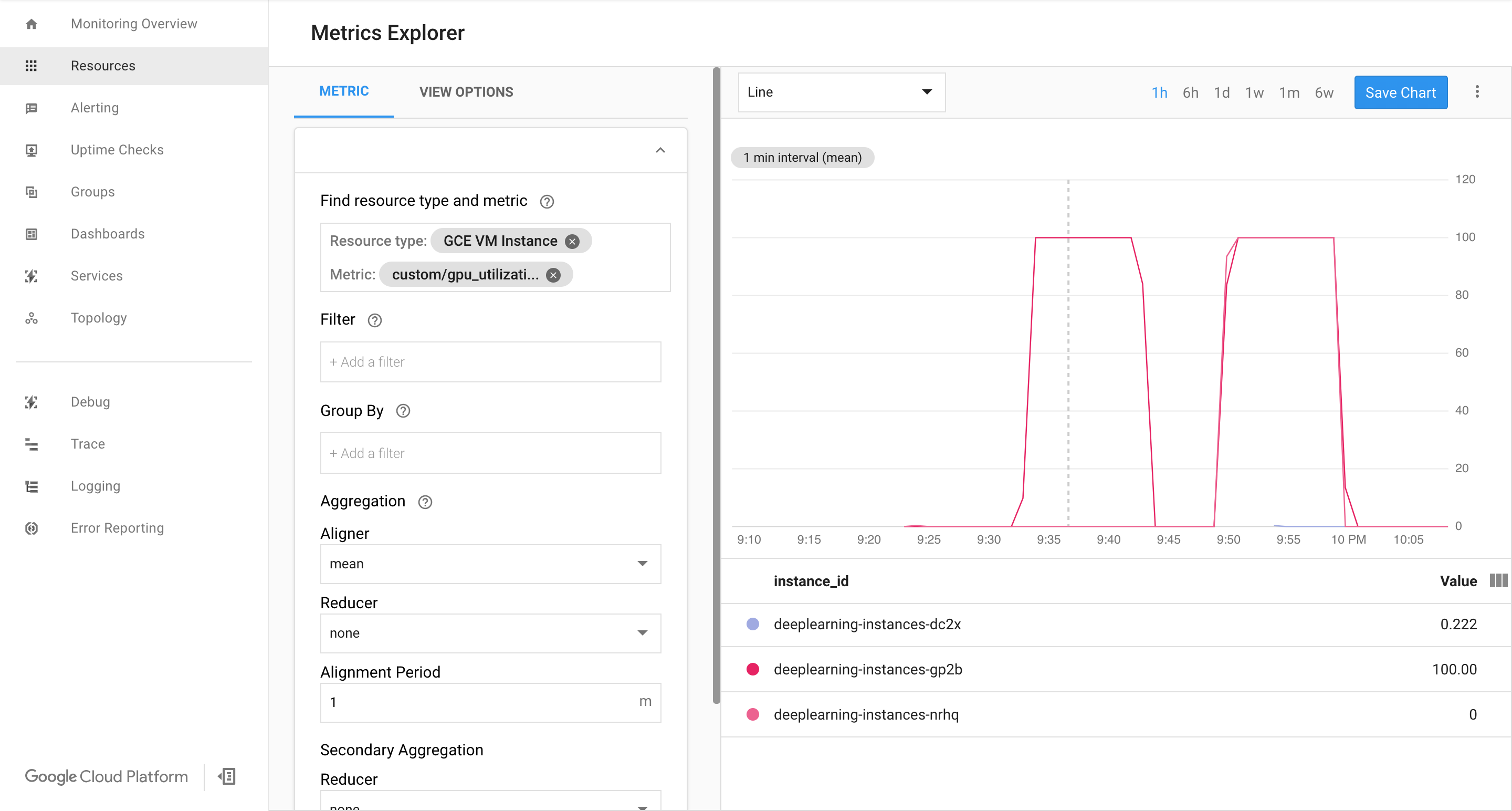
En la consola de Google Cloud , ve a la página Grupos de instancias.
Haz clic en el grupo de instancias administrado
deeplearning-instance-group.Haz clic en la pestaña Monitoring.
En este punto, tu lógica de ajuste de escala automático debería intentar activar la mayor cantidad de instancias posible para reducir la carga, sin lograrlo:
En este punto, puedes detener la grabación de instancias y observar cómo el sistema se escala hacia abajo.
Configura un balanceador de cargas
Revisemos lo que tienes hasta ahora:
- Un modelo entrenado, optimizado con TensorRT5 (INT8)
- Un grupo de instancias administrado. Estas instancias tienen habilitado el ajuste de escala automático según el uso de GPU habilitado
Ahora puedes crear un balanceador de cargas frente a las instancias.
Crea verificaciones de estado. Las verificaciones de estado se usan para determinar si un host en particular en nuestro backend puede entregar el tráfico.
export HEALTH_CHECK_NAME="http-basic-check" gcloud compute health-checks create http $HEALTH_CHECK_NAME \ --request-path /v1/models/default \ --port 8888
Crea un servicio de backend que incluya un grupo de instancias y una verificación de estado.
Crea la verificación de estado.
export HEALTH_CHECK_NAME="http-basic-check" export WEB_BACKED_SERVICE_NAME="tensorflow-backend" gcloud compute backend-services create $WEB_BACKED_SERVICE_NAME \ --protocol HTTP \ --health-checks $HEALTH_CHECK_NAME \ --global
Agrega el grupo de instancias al nuevo servicio de backend.
export INSTANCE_GROUP_NAME="deeplearning-instance-group" export WEB_BACKED_SERVICE_NAME="tensorflow-backend" gcloud compute backend-services add-backend $WEB_BACKED_SERVICE_NAME \ --balancing-mode UTILIZATION \ --max-utilization 0.8 \ --capacity-scaler 1 \ --instance-group $INSTANCE_GROUP_NAME \ --instance-group-region us-central1 \ --global
Configura la URL de reenvío. El balanceador de cargas necesita saber qué URL se puede reenviar a los servicios de backend.
export WEB_BACKED_SERVICE_NAME="tensorflow-backend" export WEB_MAP_NAME="map-all" gcloud compute url-maps create $WEB_MAP_NAME \ --default-service $WEB_BACKED_SERVICE_NAME
Crea el balanceador de cargas.
export WEB_MAP_NAME="map-all" export LB_NAME="tf-lb" gcloud compute target-http-proxies create $LB_NAME \ --url-map $WEB_MAP_NAME
Agrega una dirección IP externa al balanceador de cargas.
export IP4_NAME="lb-ip4" gcloud compute addresses create $IP4_NAME \ --ip-version=IPV4 \ --network-tier=PREMIUM \ --global
Encuentra la dirección IP que está asignada.
gcloud compute addresses list
Configura la regla de reenvío que le dice a Google Cloud que reenvíe todas las solicitudes desde la dirección IP pública al balanceador de cargas.
export IP=$(gcloud compute addresses list | grep ${IP4_NAME} | awk '{print $2}') export LB_NAME="tf-lb" export FORWARDING_RULE="lb-fwd-rule" gcloud compute forwarding-rules create $FORWARDING_RULE \ --address $IP \ --global \ --load-balancing-scheme=EXTERNAL \ --network-tier=PREMIUM \ --target-http-proxy $LB_NAME \ --ports 80Después de crear las reglas de reenvío globales, la configuración puede tardar varios minutos en propagarse.
Habilita firewall
Comprueba si tienes reglas de firewall que permitan conexiones de fuentes externas a tus instancias de VM.
gcloud compute firewall-rules list
Si no tienes reglas de firewall que permitan estas conexiones, debes crearlas. Para crear reglas de firewall, ejecuta los siguientes comandos:
gcloud compute firewall-rules create www-firewall-80 \ --target-tags http-server --allow tcp:80 gcloud compute firewall-rules create www-firewall-8888 \ --target-tags http-server --allow tcp:8888
Ejecuta una inferencia
Puedes usar la siguiente secuencia de comandos Python para convertir imágenes en un formato que se pueda subir al servidor.
from PIL import Image import numpy as np import json import codecs
img = Image.open("image.jpg").resize((240, 240)) img_array=np.array(img) result = { "instances":[img_array.tolist()] } file_path="/tmp/out.json" print(json.dump(result, codecs.open(file_path, 'w', encoding='utf-8'), separators=(',', ':'), sort_keys=True, indent=4))Ejecuta la inferencia.
curl -X POST $IP/v1/models/default:predict -d @/tmp/out.json