このチュートリアルでは、Compute Engine 上で動作する NVIDIA TensorRT5 GPU を使用して、大規模なワークロードに対し、ディープ ラーニングでの推論を行う方法について説明します。
始める前に、次の内容をふまえておいてください。
- ディープ ラーニングでの推論とは、ML プロセスの一段階であり、トレーニング済みモデルを使用して、認識、処理、結果の分類を行うものです。
- NVIDIA TensorRT は、ディープ ラーニングのワークロードを実行するために最適化されたプラットフォームです。
- GPU を使用して、ML やデータ処理などのデータ集約型ワークロードを高速化します。さまざまな NVIDIA GPU を Compute Engine で利用できます。このチュートリアルでは T4 GPU を使用します。T4 GPU は、ディープ ラーニングで推論を行う際のワークロードに特化して設計されたものです。
目標
このチュートリアルでは、次の手順について説明します。
- 事前トレーニング済みのグラフを使用したモデルの準備。
- モデルの推論速度を、異なる最適化モードでテスト。
- カスタムモデルを TensorRT に変換。
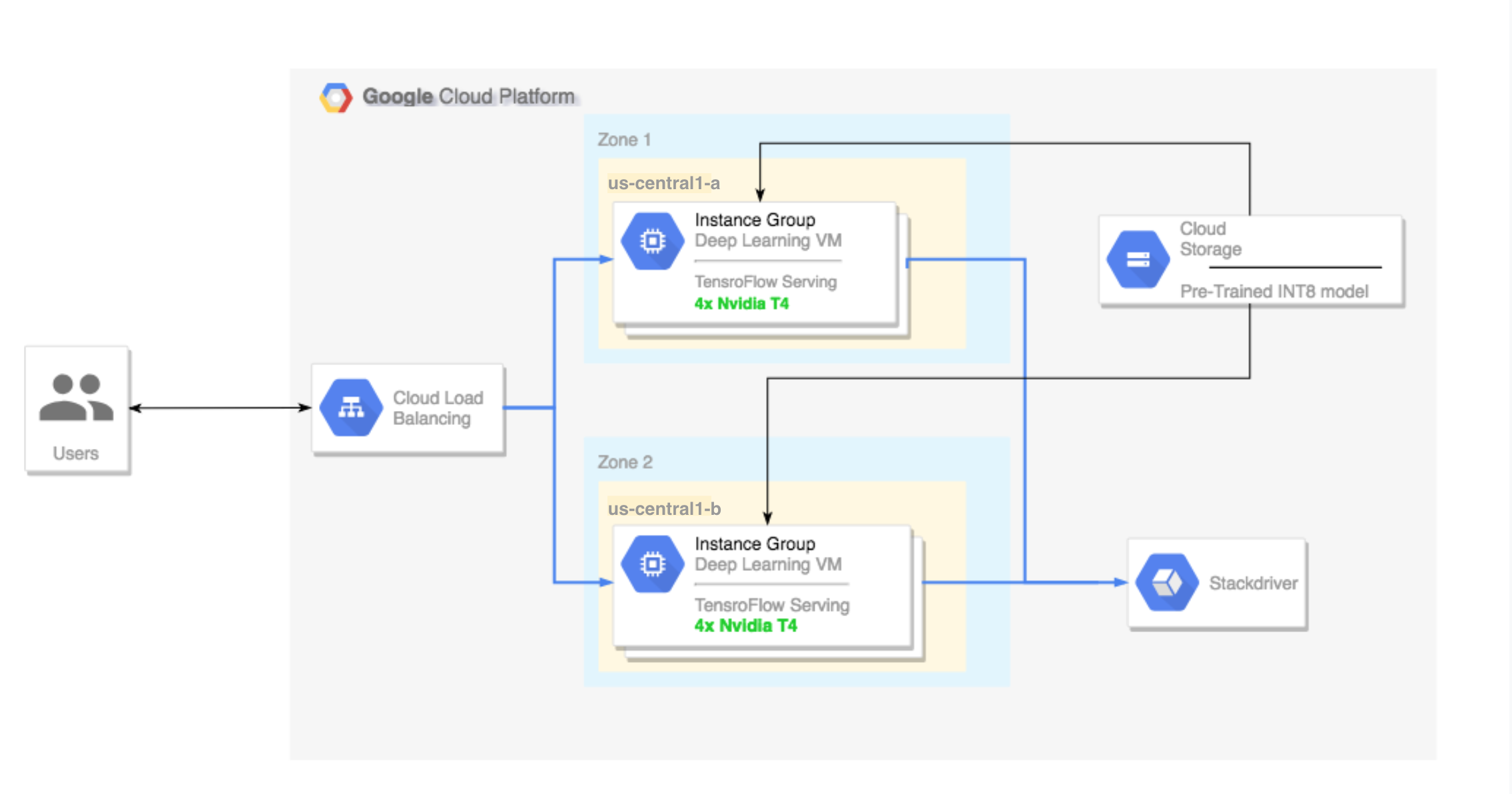
- マルチゾーン クラスタの設定。次のような構成になります。
- Deep Learning VM Image にビルドされます。イメージには、TensorFlow、TensorFlow Serving、TensorRT5 がプリインストールされます。
- 自動スケーリングが有効。このチュートリアルでは、GPU の使用率に基づいて自動スケーリングされます。
- ロード バランシングが有効。
- ファイアウォールが有効。
- マルチゾーン クラスタでの推論ワークロードの実行。
料金
このチュートリアルの実施にかかる費用は、セクションによって異なります。
料金計算ツールを使用して費用を計算できます。
モデルを準備し、さまざまな最適化速度で推論速度をテストする費用を見積もるには、次の仕様を使用します。
- VM インスタンス 1 台:
n1-standard-8(vCPU: 8、RAM 30 GB) - NVIDIA T4 GPU 1 基
マルチゾーン クラスタの設定費用を見積もるには、次の仕様を使用します。
- VM インスタンス 2 台:
n1-standard-16(vCPU: 16、RAM 60 GB) - VM インスタンスごとに NVIDIA T4 GPU 4 基
- VM インスタンスごとに 100 GB SSD
- 転送ルール 1 つ
始める前に
プロジェクトの設定
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
Enable the Compute Engine and Cloud Machine Learning APIs.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
Enable the Compute Engine and Cloud Machine Learning APIs.
- Google Cloud CLI の最新バージョンをインストールするか、最新バージョンに更新します。
- デフォルトのリージョンとゾーンを設定します(省略可)。
ツール設定
このチュートリアルで Google Cloud CLI を使用するには:
モデルの準備
このセクションでは、モデルの実行に使用する仮想マシン(VM)インスタンスの作成について説明します。TensorFlow の公式モデルの一覧からモデルをダウンロードする方法についても説明します。
VM インスタンスを作成します。このチュートリアルは、
tf-ent-2-10-cu113を使用して作成されています。最新のイメージ バージョンについては、Deep Learning VM Image のドキュメントのオペレーティング システムの選択をご覧ください。export IMAGE_FAMILY="tf-ent-2-10-cu113" export ZONE="us-central1-b" export INSTANCE_NAME="model-prep" gcloud compute instances create $INSTANCE_NAME \ --zone=$ZONE \ --image-family=$IMAGE_FAMILY \ --machine-type=n1-standard-8 \ --image-project=deeplearning-platform-release \ --maintenance-policy=TERMINATE \ --accelerator="type=nvidia-tesla-t4,count=1" \ --metadata="install-nvidia-driver=True"
モデルを選択します。このチュートリアルでは、ResNet モデルを使用します。ResNet モデルは、TensorFlow にある ImageNet データセットでトレーニングされています。
ResNet モデルを VM インスタンスにダウンロードするには、次のコマンドを実行します。
wget -q http://download.tensorflow.org/models/official/resnetv2_imagenet_frozen_graph.pb
ResNet モデルのロケーションを
$WORKDIR変数に保存します。MODEL_LOCATIONは、ダウンロードしたモデルを含む作業ディレクトリに置き換えます。export WORKDIR=MODEL_LOCATION
推論速度テストの実行
このセクションでは、次の手順について説明します。
- ResNet モデルの設定。
- 異なる最適化モードでの推論テストの実行。
- 推論テストの結果の確認。
テストプロセスの概要
TensorRT では、推論の際のワークロードの処理速度を向上させることができますが、その最も大きな要因となっているのが量子化プロセスです。
モデルの量子化とは、モデルにおける重みの精度を下げる処理のことです。たとえば、モデルの重みが FP32 であったとするならば、それを FP16、INT8、さらには INT4 というように精度を下げることができます。この場合、速度(重みの精度)とモデルの正確さを勘案し、妥当な水準を検討することが重要です。TensorFlow にはまさにそのための機能が含まれており、速度と精度の対比に加え、スループット、レイテンシ、ノード変換率、総トレーニング時間などの指標も測定できます。
手順
ResNet モデルを設定します。モデルを設定するには、次のコマンドを実行します。
git clone https://github.com/tensorflow/models.git cd models git checkout f0e10716160cd048618ccdd4b6e18336223a172f touch research/__init__.py touch research/tensorrt/__init__.py cp research/tensorrt/labellist.json . cp research/tensorrt/image.jpg ..
テストを実行します。このコマンドは、完了するまでにしばらく時間がかかります。
python -m research.tensorrt.tensorrt \ --frozen_graph=$WORKDIR/resnetv2_imagenet_frozen_graph.pb \ --image_file=$WORKDIR/image.jpg \ --native --fp32 --fp16 --int8 \ --output_dir=$WORKDIR
ここで
$WORKDIRは、ResNet モデルをダウンロードしたディレクトリです。--native引数は、テストに使用する量子化モードです。
結果を確認します。テストが完了したら、最適化モードごとに推論結果を比較できます。
Predictions: Precision: native [u'seashore, coast, seacoast, sea-coast', u'promontory, headland, head, foreland', u'breakwater, groin, groyne, mole, bulwark, seawall, jetty', u'lakeside, lakeshore', u'grey whale, gray whale, devilfish, Eschrichtius gibbosus, Eschrichtius robustus'] Precision: FP32 [u'seashore, coast, seacoast, sea-coast', u'promontory, headland, head, foreland', u'breakwater, groin, groyne, mole, bulwark, seawall, jetty', u'lakeside, lakeshore', u'sandbar, sand bar'] Precision: FP16 [u'seashore, coast, seacoast, sea-coast', u'promontory, headland, head, foreland', u'breakwater, groin, groyne, mole, bulwark, seawall, jetty', u'lakeside, lakeshore', u'sandbar, sand bar'] Precision: INT8 [u'seashore, coast, seacoast, sea-coast', u'promontory, headland, head, foreland', u'breakwater, groin, groyne, mole, bulwark, seawall, jetty', u'grey whale, gray whale, devilfish, Eschrichtius gibbosus, Eschrichtius robustus', u'lakeside, lakeshore']
すべての結果を見るには、次のコマンドを実行します。
cat $WORKDIR/log.txt
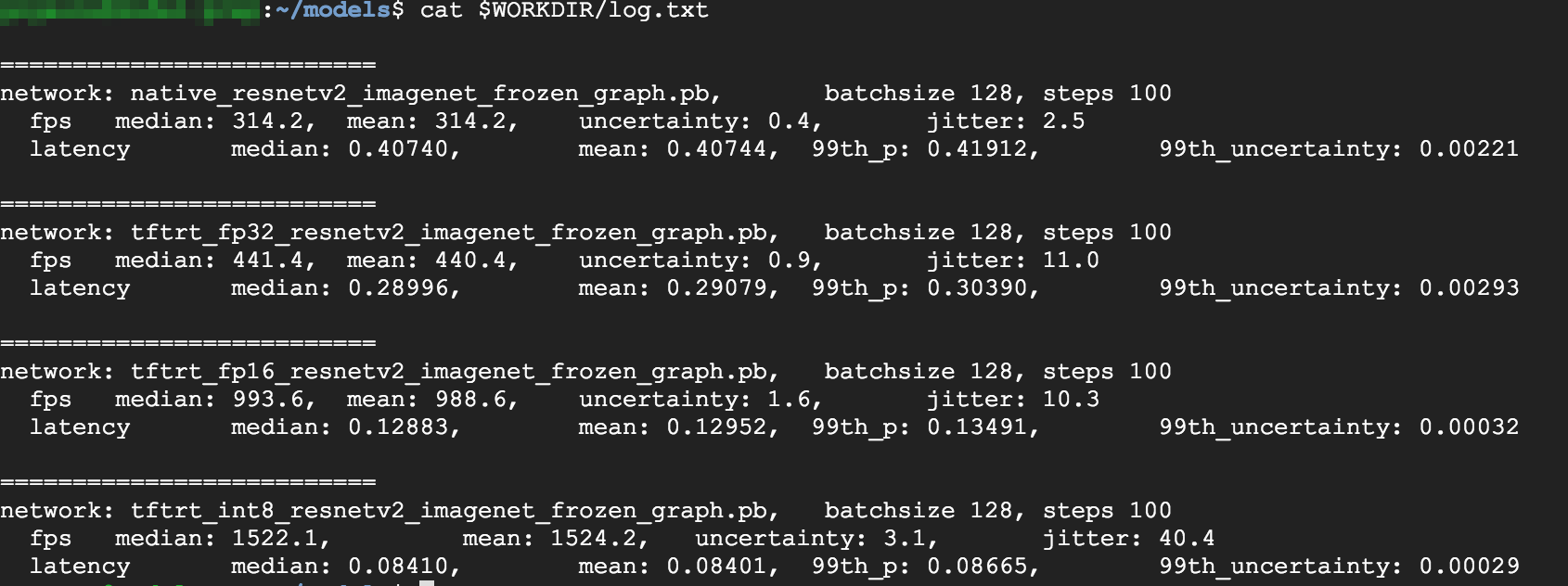
FP32 と FP16 では同一の結果が出ています。したがって、TensorRT の動作に問題がなければ、FP16 から使用すべきでしょう。INT8 では、やや悪い結果になっています。
さらに、TensorRT5 を使用してモデルを実行すると、次の結果が得られます。
- FP32 に最適化すると、スループットが 314 fps から 440 fps に 40% 向上します。また、レイテンシは約 30% 短縮され、0.40 ミリ秒から 0.28 ミリ秒になります。
- 元の TensorFlow グラフから FP16 に最適化すると、速度が 314 fps から 988 fps へと 214% 向上します。また、レイテンシは 0.12 ミリ秒になり、ほぼ 3 分の 1 に短縮されます。
- INT8 を使用すると、314 fps から 1,524 fps へ、385% 高速化することがわかります。レイテンシは 0.08 ミリ秒に短縮されます。
カスタムモデルの TensorRT への変換
この変換には、INT8 モデルを使用できます。
モデルをダウンロードします。カスタムモデルを TensorRT グラフに変換するには、保存済みのモデルが必要です。保存済みの INT8 ResNet モデルを入手するには、次のコマンドを実行します。
wget http://download.tensorflow.org/models/official/20181001_resnet/savedmodels/resnet_v2_fp32_savedmodel_NCHW.tar.gz tar -xzvf resnet_v2_fp32_savedmodel_NCHW.tar.gz
TFTools を使用してモデルを TensorRT グラフに変換します。TFTools を使用してモデルを変換するには、次のコマンドを実行します。
git clone https://github.com/GoogleCloudPlatform/ml-on-gcp.git cd ml-on-gcp/dlvm/tools python ./convert_to_rt.py \ --input_model_dir=$WORKDIR/resnet_v2_fp32_savedmodel_NCHW/1538687196 \ --output_model_dir=$WORKDIR/resnet_v2_int8_NCHW/00001 \ --batch_size=128 \ --precision_mode="INT8"
これで、INT8 モデルが
$WORKDIR/resnet_v2_int8_NCHW/00001ディレクトリに格納されました。すべてが正しく設定されていることを確認するために、推論テストを実行してみます。
tensorflow_model_server --model_base_path=$WORKDIR/resnet_v2_int8_NCHW/ --rest_api_port=8888
モデルを Cloud Storage にアップロードします。この手順は、次のセクションで設定するマルチゾーン クラスタからモデルを使用できるようにするため必要です。モデルをアップロードするには、次の手順を実行します。
モデルをアーカイブします。
tar -zcvf model.tar.gz ./resnet_v2_int8_NCHW/
アーカイブをアップロードします。
GCS_PATHは、Cloud Storage バケットへのパスに置き換えます。export GCS_PATH=GCS_PATH gcloud storage cp model.tar.gz $GCS_PATH
必要に応じて、Cloud Storage の次の URL から INT8 のフリーズされたグラフを入手できます。
gs://cloud-samples-data/dlvm/t4/model.tar.gz
マルチゾーン クラスタの設定
このセクションでは、マルチゾーン クラスタの設定時に必要な手順について説明します。
クラスタを作成する
これで、Cloud Storage プラットフォームにモデルを用意できたので、クラスタを作成できます。
インスタンス テンプレートを作成します。インスタンス テンプレートは、新しいインスタンスの作成時に便利なリソースです。インスタンス テンプレートをご覧ください。
YOUR_PROJECT_NAMEは実際のプロジェクト ID に置き換えます。export INSTANCE_TEMPLATE_NAME="tf-inference-template" export IMAGE_FAMILY="tf-ent-2-10-cu113" export PROJECT_NAME=YOUR_PROJECT_NAME gcloud beta compute --project=$PROJECT_NAME instance-templates create $INSTANCE_TEMPLATE_NAME \ --machine-type=n1-standard-16 \ --maintenance-policy=TERMINATE \ --accelerator=type=nvidia-tesla-t4,count=4 \ --min-cpu-platform=Intel\ Skylake \ --tags=http-server,https-server \ --image-family=$IMAGE_FAMILY \ --image-project=deeplearning-platform-release \ --boot-disk-size=100GB \ --boot-disk-type=pd-ssd \ --boot-disk-device-name=$INSTANCE_TEMPLATE_NAME \ --metadata startup-script-url=gs://cloud-samples-data/dlvm/t4/start_agent_and_inf_server_4.sh- このインスタンス テンプレートには、メタデータ パラメータで指定された起動スクリプトが含まれています。
- このテンプレートを使用するすべてのインスタンスで、インスタンス作成中にこの起動スクリプトを実行します。
- この起動スクリプトによって次の手順が実行されます。
- インスタンス上の GPU の使用状況をモニタリングするモニタリング エージェントのインストール。
- モデルのダウンロード。
- 推論サービスの開始。
- 起動スクリプトでは、
tf_serve.pyに推論ロジックが含まれています。今回の例では、TFServe パッケージを基にして、非常に小さな python ファイルを作成しました。 - 起動スクリプトを表示するには、startup_inf_script.sh をご覧ください。
- このインスタンス テンプレートには、メタデータ パラメータで指定された起動スクリプトが含まれています。
マネージド インスタンス グループ(MIG)を作成します。このマネージド インスタンス グループは、特定のゾーンに複数の実行中インスタンスを設定する際に必要です。インスタンスは、前の手順で作成したインスタンス テンプレートに基づいて作成されます。
export INSTANCE_GROUP_NAME="deeplearning-instance-group" export INSTANCE_TEMPLATE_NAME="tf-inference-template" gcloud compute instance-groups managed create $INSTANCE_GROUP_NAME \ --template $INSTANCE_TEMPLATE_NAME \ --base-instance-name deeplearning-instances \ --size 2 \ --zones us-central1-a,us-central1-b
このインスタンスは、T4 GPU をサポートしているゾーンであれば、どの利用可能なゾーンにでも作成できます。なお、ゾーンに利用可能な GPU 割り当てがあることを確認してください。
インスタンスの作成にはしばらく時間がかかります。次のコマンドを実行すれば、進行状況を確認できます。
export INSTANCE_GROUP_NAME="deeplearning-instance-group"
gcloud compute instance-groups managed list-instances $INSTANCE_GROUP_NAME --region us-central1

マネージド インスタンス グループが作成されると、次のような出力が表示されます。

Google Cloud の Cloud Monitoring ページで指標が使用可能であることを確認します。
Google Cloud コンソールで、[モニタリング] ページに移動します。
ナビゲーション パネルに Metrics Explorer が表示されている場合は、[Metrics Explorer] をクリックします。それ以外の場合は、[Resources] を選択して [Metrics Explorer] を選択します。
gpu_utilizationを検索します。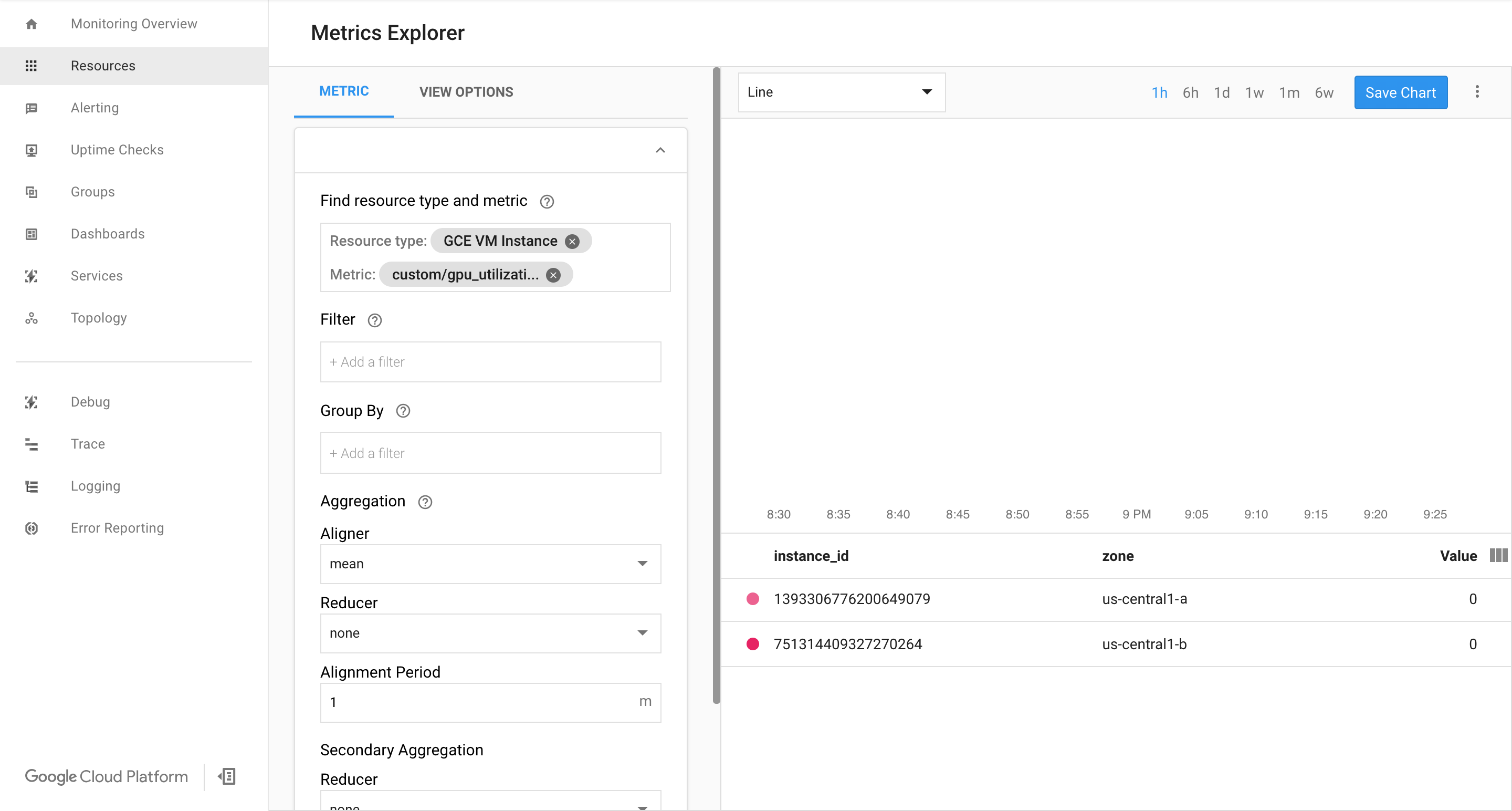
データがきていれば、次のように表示されます。
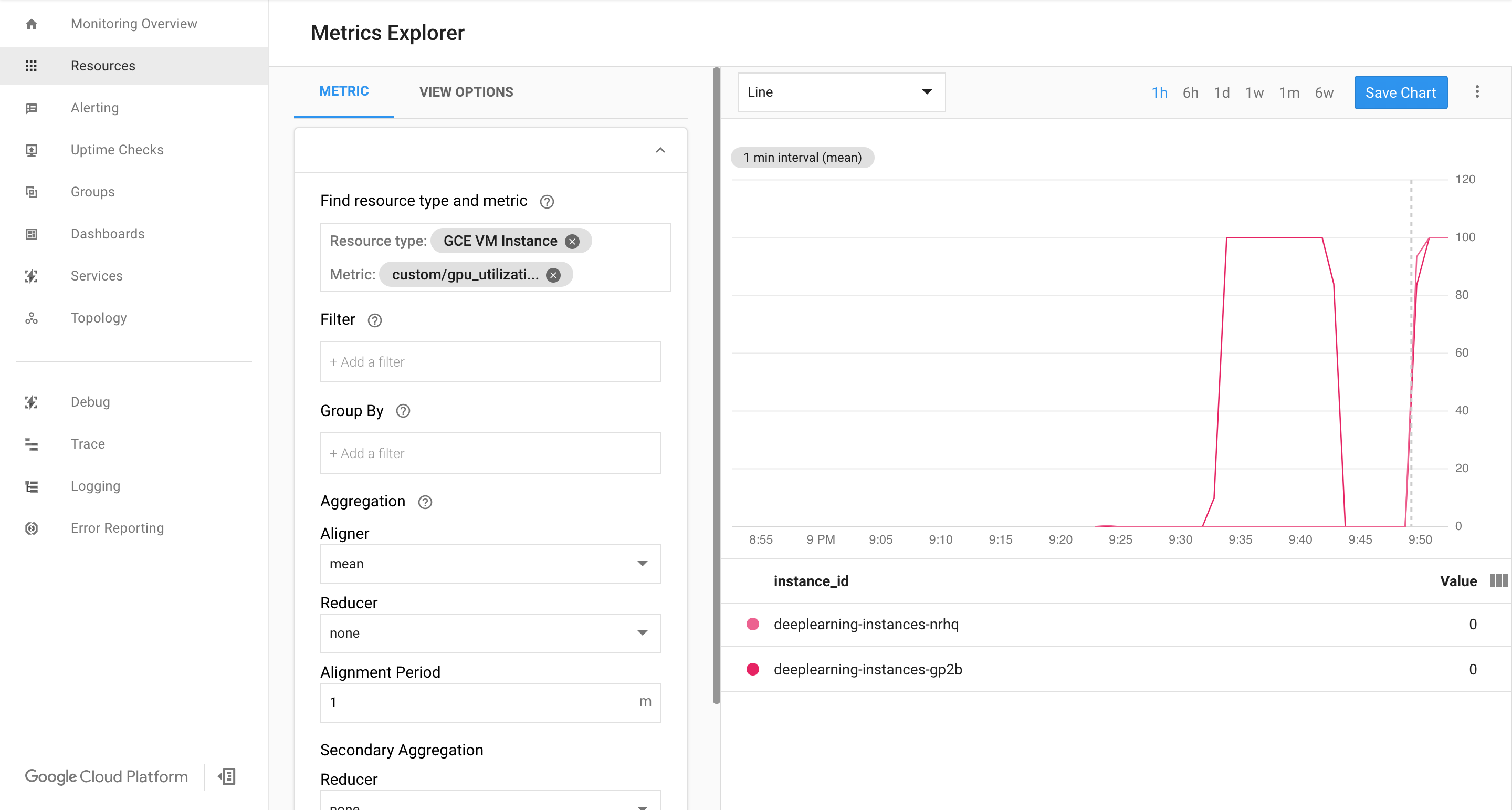
自動スケーリングを有効にする
マネージド インスタンス グループの自動スケーリングを有効にします。
export INSTANCE_GROUP_NAME="deeplearning-instance-group" gcloud compute instance-groups managed set-autoscaling $INSTANCE_GROUP_NAME \ --custom-metric-utilization metric=custom.googleapis.com/gpu_utilization,utilization-target-type=GAUGE,utilization-target=85 \ --max-num-replicas 4 \ --cool-down-period 360 \ --region us-central1
custom.googleapis.com/gpu_utilizationは指標へのフルパスです。今回のサンプルでは、レベル 85 を指定しています。これは、GPU 使用率が 85 に達するたびに、プラットフォームがグループに新しいインスタンスを作成することを意味します。自動スケーリングをテストします。自動スケーリングをテストするには、次の手順を実行する必要があります。
- インスタンスに SSH で接続します。インスタンスへの接続をご覧ください。
gpu-burnツールを使用して、GPU に使用率 100% で 600 秒間の負荷をかけます。git clone https://github.com/GoogleCloudPlatform/ml-on-gcp.git cd ml-on-gcp/third_party/gpu-burn git checkout c0b072aa09c360c17a065368294159a6cef59ddf make ./gpu_burn 600 > /dev/null &
Cloud Monitoring ページを表示します。自動スケーリングを確認します。クラスタがインスタンスをもう 1 つ追加して、スケールアップしています。
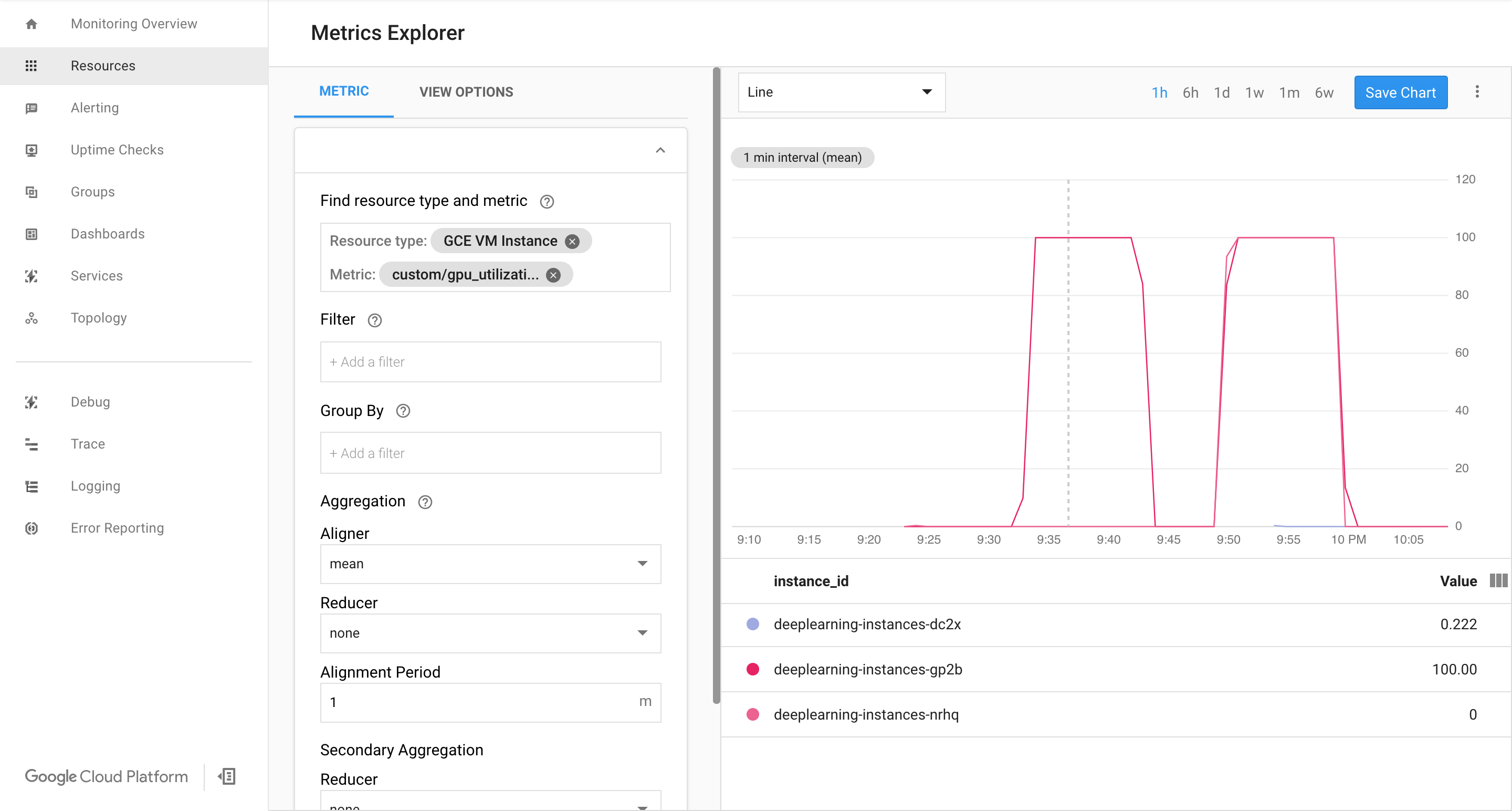
Google Cloud コンソールで、[インスタンス グループ] ページに移動します。
deeplearning-instance-groupマネージド インスタンス グループをクリックします。[Monitoring] タブをクリックします。
この時点で、自動スケーリングのロジックが、可能な限り多くのインスタンスを起動させて負荷を軽減しようとしますが、対処しきれません。
この時点でインスタンスへの負荷を停止させると、システムのスケールダウンの様子が確認できます。
ロードバランサを設定する
ここまでで次のリソースの準備ができました。
- TensorRT5(INT8)で最適化されたトレーニング済みのモデル。
- インスタンスのマネージド グループ。これらのインスタンスは、使用可能な GPU 使用率に基づいて自動スケーリングを有効化します。
これで、各インスタンスの前にロードバランサを作成できます。
ヘルスチェックを作成します。ヘルスチェックは、バックエンドの特定のホストがトラフィックを処理できるかどうかを判別するために使用します。
export HEALTH_CHECK_NAME="http-basic-check" gcloud compute health-checks create http $HEALTH_CHECK_NAME \ --request-path /v1/models/default \ --port 8888
インスタンス グループとヘルスチェックを含むバックエンド サービスを作成します。
ヘルスチェックを作成します。
export HEALTH_CHECK_NAME="http-basic-check" export WEB_BACKED_SERVICE_NAME="tensorflow-backend" gcloud compute backend-services create $WEB_BACKED_SERVICE_NAME \ --protocol HTTP \ --health-checks $HEALTH_CHECK_NAME \ --global
インスタンス グループを新しいバックエンド サービスに追加します。
export INSTANCE_GROUP_NAME="deeplearning-instance-group" export WEB_BACKED_SERVICE_NAME="tensorflow-backend" gcloud compute backend-services add-backend $WEB_BACKED_SERVICE_NAME \ --balancing-mode UTILIZATION \ --max-utilization 0.8 \ --capacity-scaler 1 \ --instance-group $INSTANCE_GROUP_NAME \ --instance-group-region us-central1 \ --global
転送先 URL を設定します。ロードバランサにバックエンド サービスへの転送が可能な URL を定めておく必要があります。
export WEB_BACKED_SERVICE_NAME="tensorflow-backend" export WEB_MAP_NAME="map-all" gcloud compute url-maps create $WEB_MAP_NAME \ --default-service $WEB_BACKED_SERVICE_NAME
ロードバランサを作成します。
export WEB_MAP_NAME="map-all" export LB_NAME="tf-lb" gcloud compute target-http-proxies create $LB_NAME \ --url-map $WEB_MAP_NAME
ロードバランサに外部 IP アドレスを追加します。
export IP4_NAME="lb-ip4" gcloud compute addresses create $IP4_NAME \ --ip-version=IPV4 \ --network-tier=PREMIUM \ --global
割り振られている IP アドレスを見つけます。
gcloud compute addresses list
パブリック IP アドレスからのすべてのリクエストをロードバランサに転送するように Google Cloud に指示する転送ルールを設定します。
export IP=$(gcloud compute addresses list | grep ${IP4_NAME} | awk '{print $2}') export LB_NAME="tf-lb" export FORWARDING_RULE="lb-fwd-rule" gcloud compute forwarding-rules create $FORWARDING_RULE \ --address $IP \ --global \ --load-balancing-scheme=EXTERNAL \ --network-tier=PREMIUM \ --target-http-proxy $LB_NAME \ --ports 80グローバル転送ルールの作成後、構成が反映されるまで数分かかることがあります。
ファイアウォールを有効にする
外部の接続元から VM インスタンスへの接続を許可するファイアウォール ルールがあるかどうかを確認します。
gcloud compute firewall-rules list
そのような接続を許可するファイアウォール ルールがない場合、作成する必要があります。ファイアウォール ルールを作成するには、次のコマンドを実行します。
gcloud compute firewall-rules create www-firewall-80 \ --target-tags http-server --allow tcp:80 gcloud compute firewall-rules create www-firewall-8888 \ --target-tags http-server --allow tcp:8888
推論の実行
次の python スクリプトを実行して、画像をサーバーにアップロードできる形式に変換します。
from PIL import Image import numpy as np import json import codecs
img = Image.open("image.jpg").resize((240, 240)) img_array=np.array(img) result = { "instances":[img_array.tolist()] } file_path="/tmp/out.json" print(json.dump(result, codecs.open(file_path, 'w', encoding='utf-8'), separators=(',', ':'), sort_keys=True, indent=4))推論を実行します。
curl -X POST $IP/v1/models/default:predict -d @/tmp/out.json
クリーンアップ
このチュートリアルで使用したリソースについて、Google Cloud アカウントに課金されないようにするには、リソースを含むプロジェクトを削除するか、プロジェクトを維持して個々のリソースを削除します。
転送ルールを削除します。
gcloud compute forwarding-rules delete $FORWARDING_RULE --global
IPV4 アドレスを削除します。
gcloud compute addresses delete $IP4_NAME --global
ロードバランサを削除します。
gcloud compute target-http-proxies delete $LB_NAME
転送先 URL を削除します。
gcloud compute url-maps delete $WEB_MAP_NAME
バックエンド サービスを削除します。
gcloud compute backend-services delete $WEB_BACKED_SERVICE_NAME --global
ヘルスチェックを削除します。
gcloud compute health-checks delete $HEALTH_CHECK_NAME
マネージド インスタンス グループを削除します。
gcloud compute instance-groups managed delete $INSTANCE_GROUP_NAME --region us-central1
インスタンス テンプレートを削除します。
gcloud beta compute --project=$PROJECT_NAME instance-templates delete $INSTANCE_TEMPLATE_NAME
ファイアウォール ルールを削除します。
gcloud compute firewall-rules delete www-firewall-80
gcloud compute firewall-rules delete www-firewall-8888