Dokumen ini menjelaskan penyebab umum shutdown dan reboot tidak terduga pada instance Compute Engine dan cara mencegahnya.
Shutdown dan reboot instance dapat disebabkan oleh peristiwa sistem atau aktivitas administratif. Shutdown dan reboot karena peristiwa sistem dihasilkan oleh sistem Google atau sistem operasi instance Anda. Shutdown dan reboot karena aktivitas admin dihasilkan oleh panggilan API yang dibuat oleh pengguna atau akun layanan. Semua shutdown dan reboot dicatat dalam log, kecuali untuk reboot yang dimulai dari dalam instance.
Sebelum memulai
-
Jika Anda belum melakukannya, siapkan autentikasi.
Autentikasi memverifikasi identitas Anda untuk mengakses Google Cloud layanan dan API. Untuk menjalankan
kode atau sampel dari lingkungan pengembangan lokal, Anda dapat melakukan autentikasi ke
Compute Engine dengan memilih salah satu opsi berikut:
Select the tab for how you plan to use the samples on this page:
Console
When you use the Google Cloud console to access Google Cloud services and APIs, you don't need to set up authentication.
gcloud
-
Menginstal Google Cloud CLI. Setelah penginstalan, lakukan inisialisasi Google Cloud CLI dengan menjalankan perintah berikut:
gcloud initJika Anda menggunakan penyedia identitas (IdP) eksternal, Anda harus login ke gcloud CLI dengan identitas gabungan Anda terlebih dahulu.
- Set a default region and zone.
Mendiagnosis shutdown dan reboot instance
Untuk mendiagnosis penyebab instance mengalami shutdown atau reboot mendadak, Anda harus mengkueri log instance. Untuk mempercepat pengidentifikasian penyebab shutdown atau reboot VM di masa mendatang, buat dasbor yang berisi log. Setelah Anda mengkueri log ini, tinjau kolom
methoddanprincipalEmailuntuk menentukan peristiwa apa serta pengguna atau layanan mana yang memulai shutdown atau reboot.Mengkueri Cloud Audit Logs
Kueri Cloud Audit Logs untuk menampilkan daftar peristiwa sistem dan aktivitas administratif yang mungkin menyebabkan shutdown atau reboot.
Konsol
Di konsol Google Cloud , buka halaman Logs Explorer.
Di kolom Query, masukkan kueri berikut:
resource.type="gce_instance" "VM_NAME" logName:("logs/cloudaudit.googleapis.com%2Fsystem_event" OR "logs/cloudaudit.googleapis.com%2Factivity")Ganti
VM_NAMEdengan nama VM yang di-shutdown atau di-reboot.Jika peristiwa yang Anda cari terjadi lebih dari satu jam sebelumnya, tetapkan jangka waktu kustom dengan mengklik simbol jam dan memasukkan rentang kustom.
Klik Jalankan kueri. Hasilnya ditampilkan di bagian Query results.
Klik panah peluas di samping setiap hasil untuk menampilkan informasi mendetail.
Lihat Meninjau Cloud Audit Logs untuk mempelajari lebih lanjut kolom
methoddanprincipalEmailyang terkait dengan shutdown dan reboot, dan tindakan yang dapat Anda lakukan untuk mencegahnya.
gcloud
Lihat Cloud Audit Logs menggunakan perintah
gcloud logging read:gcloud logging read --freshness=TIME 'resource.type="gce_instance" "VM_NAME" logName:("logs/cloudaudit.googleapis.com%2Fsystem_event" OR "logs/cloudaudit.googleapis.com%2Factivity")'Ganti kode berikut:
TIME: lamanya waktu yang Anda ingin kueri. Misalnya,1hmengkueri entri log dalam satu jam terakhir. Untuk informasi tentang format tanggal dan waktu, lihat gcloud topic datetimes.VM_NAME: nama VM yang di-shutdown atau di-reboot.
Hasil akan ditampilkan.
Lihat Meninjau Cloud Audit Logs untuk mempelajari lebih lanjut kolom
methoddanprincipalEmailyang terkait dengan shutdown dan reboot, dan tindakan yang dapat Anda lakukan untuk mencegahnya.
Meninjau Cloud Audit Logs
Tinjau kolom
methoddanprincipalEmaildi Cloud Audit Logs untuk mengetahui alasan VM di-shutdown atau di-reboot.Tinjau kolom
methoddi Cloud Audit Logs dan bandingkan dengan metode yang tercantum dalam tabel berikut.Metode Jenis shutdown Deskripsi compute.instances.repair.recreateInstancePeristiwa sistem Jika VM Anda termasuk dalam grup instance terkelola (MIG), MIG akan membuat ulang VM jika status VM berubah dari
RUNNINGdan MIG tidak memulai perubahan itu.Perubahan status instance yang tidak dimulai oleh MIG meliputi:
- Kegagalan hardware.
- Menghentikan preemptible instance.
- Peristiwa pemeliharaan infrastruktur saat instance VM tidak ditetapkan ke live migrate.
- Menghapus instance MIG menggunakan salah satu metode berikut:
- Metode API
instances.delete - Perintah
gcloud compute instances delete
- Metode API
compute.instances.hostErrorPeristiwa sistem Error host (
compute.instances.hostError) berarti terjadi masalah hardware atau software pada mesin fisik atau infrastruktur pusat data yang menghosting instance komputasi Anda yang menyebabkan instance Anda error. Error host yang melibatkan kegagalan hardware total atau masalah hardware lainnya dapat mencegah migrasi langsung instance Anda. Jika instance Anda disetel untuk otomatis dimulai ulang, yang merupakan setelan default, Compute Engine akan memulai ulang instance Anda, biasanya dalam waktu tiga menit sejak error terdeteksi. Bergantung pada masalahnya, proses mulai ulang mungkin memerlukan waktu hingga 5,5 menit.Terkadang, instance komputasi mungkin menjadi tidak responsif sebelum error host ditandai. Anda dapat mengurangi jumlah waktu tunggu Compute Engine untuk memulai ulang atau menghentikan instance dengan menetapkan waktu tunggu pemulihan error host. Untuk mengetahui informasi selengkapnya, lihat Menetapkan kebijakan ketersediaan.
Kegagalan fisik dan software terkadang dapat terjadi, tetapi jarang terjadi. Untuk melindungi aplikasi dan layanan Anda dari peristiwa sistem yang berpotensi mengganggu ini, tinjau referensi berikut:
- Merancang sistem yang kuat
- Pola untuk aplikasi yang skalabel dan tangguh
- Membuat grup instance terkelola
Google juga menawarkan layanan terkelola seperti App Engine dan lingkungan fleksibel App Engine.
compute.instances.automaticRestartPeristiwa sistem Peristiwa ini terjadi setelah peristiwa
hostErroratau peristiwaterminateOnHostMaintenancejika kebijakan pemeliharaan hostautomaticRestartVM Anda ditetapkan ketrue. Dalam log, entri loghostErroratauterminateOnHostMaintenancemendahului log ini.Jika ingin mengubah kebijakan pemeliharaan host VM Anda, lihat Memperbarui opsi untuk instance.
compute.instances.guestTerminatePeristiwa sistem Sistem operasi VM Anda memulai shutdown. compute.instances.terminateOnHostMaintenancePeristiwa sistem Jika Anda menetapkan kebijakan pemeliharaan host
onHostMaintenanceVM keTERMINATE, Compute Engine akan menghentikan VM Anda saat ada peristiwa pemeliharaan di mana Google harus memindahkan VM Anda ke host lain.Jika ingin mengubah kebijakan
onHostMaintenanceVM Anda, lihat Memperbarui opsi untuk instance.compute.instances.preemptedPeristiwa sistem Compute Engine mem-preempt Spot VM atau preemptible VM lama Anda:
- Saat mem-preempt Spot VM, Compute Engine akan menghentikan atau menghapus Spot VM tersebut berdasarkan tindakan penghentiannya. Spot VM tidak memiliki runtime maksimum.
- Saat mem-preempt preemptible VM, Compute Engine akan menghentikan VM setelah runtime maksimum, yakni 24 jam. Untuk menghindari batasan ini, gunakan Spot VM.
Spot VM dan preemptible VM merupakan kapasitas Compute Engine ekstra, sehingga Compute Engine dapat mem-preempt instance tersebut setiap kali kapasitasnya diperlukan di tempat lain. Anda dapat membantu mengurangi dampak preemption dengan mengikuti praktik terbaik. Atau, jika Anda memerlukan VM dengan runtime yang dikontrol pengguna, buat VM standar.
compute.instances.stopAktivitas admin Pengguna atau akun layanan menghentikan VM Anda.
Lanjutkan ke langkah berikutnya untuk mengidentifikasi pengguna atau akun layanan yang menghentikan VM Anda. Untuk informasi tentang cara me-restart VM, lihat Memulai ulang instance yang dihentikan.
compute.instances.deleteAktivitas admin atau peristiwa sistem Pengguna atau akun layanan menghapus VM Anda, atau VM dikonfigurasi agar dihapus secara otomatis.
Secara khusus, log untuk metode
compute.instances.deletedapat menunjukkan salah satu permintaan berikut untuk VM Anda:- Permintaan dari pengguna atau akun layanan untuk menghapus VM Anda secara langsung hanya ditunjukkan oleh metode
compute.instances.deletedari pengguna atau akun layanan tersebut. Permintaan yang otomatis menghapus VM Anda ditunjukkan oleh metode
compute.instances.deletedarisystem@google.com, tetapi metode yang menjelaskan penyebab penghapusan otomatis mungkin atau mungkin tidak muncul di Cloud Audit Logs.Misalnya, jika Spot VM dikonfigurasi untuk dihapus secara otomatis selama preemption dan mengalami preemption, Anda akan melihat metode
compute.instances.deletedarisystem@google.com, tetapi Anda mungkin juga melihat atau tidak melihat metodecompute.instances.preempted.Permintaan ke VM yang terjadi sesaat sebelum atau setelah metode
compute.instances.deletemungkin atau mungkin tidak muncul di Cloud Audit Logs.Misalnya, jika VM dihentikan karena pemeliharaan host sesaat sebelum VM dihapus, Anda akan melihat metode
compute.instances.delete, tetapi Anda mungkin atau mungkin juga tidak melihat metodecompute.instances.terminateOnHostMaintenance.
Lanjutkan ke langkah berikutnya untuk mengidentifikasi pengguna atau akun layanan yang menghapus VM Anda. Untuk informasi tentang cara membuat VM baru, lihat Membuat dan memulai VM.
compute.instances.insertAktivitas admin Pengguna atau akun layanan membuat VM Anda.
Lanjutkan ke langkah berikutnya untuk mengidentifikasi pengguna atau akun layanan yang membuat VM Anda. Untuk informasi tentang cara membuat VM baru, lihat Membuat dan memulai VM.
compute.instances.resetAktivitas admin Pengguna atau akun layanan mereset VM Anda.
Lanjutkan ke langkah berikutnya untuk mengidentifikasi pengguna atau akun layanan yang menghentikan VM Anda.
Tinjau kolom
principalEmailpada Cloud Audit Logs untuk mengidentifikasi pengguna atau layanan yang memulai shutdown atau reboot. Tabel berikut mencantumkan layanan umum yang dikelola Google yang memulai shutdown atau reboot.Email Deskripsi system@google.comPeristiwa sistem menyebabkan shutdown atau reboot. project-number@cloudservices.gserviceaccount.comAgen layanan memulai shutdown.
Untuk menentukan dari project mana layanan memulai shutdown, tinjau
project-numberagen layanan.Untuk menentukan layanan Google mana yang membuat permintaan, tinjau kolom
protoPayload.requestMetadata.callerSuppliedUserAgent.Jika pengguna memicu shutdown atau reboot, alamat email mereka akan muncul di kolom
principalEmail. Contoh,cloudysanfrancisco@gmail.com.Administrator dapat mencegah pengguna mengubah status VM project dengan mengubah izin Identity and Access Management di akun pengguna. Untuk mengetahui informasi selengkapnya, lihat Memberikan, mengubah, dan mencabut akses ke resource.
Memantau peristiwa siklus proses VM
Anda dapat memantau peristiwa siklus proses VM (termasuk shutdown, reboot, dan error host) dengan membuat dasbor Cloud Monitoring.
Dasbor ini memungkinkan Anda memvisualisasikan peristiwa sistem dan aktivitas administrator yang dijelaskan secara lebih mendetail di bagian Meninjau Cloud Audit Logs dalam dokumen ini.
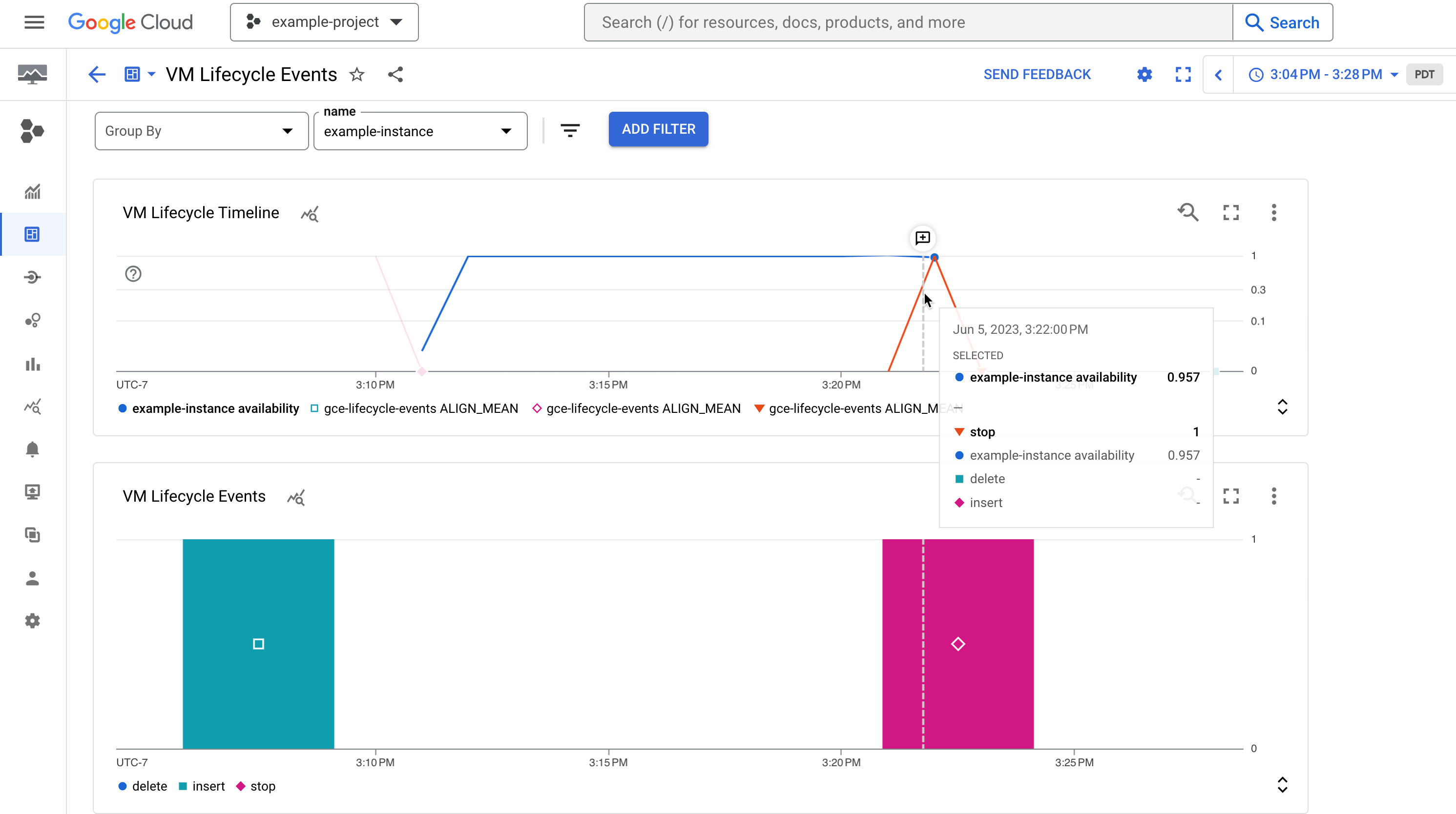 Gambar 1. Contoh dasbor yang menampilkan ketersediaan instance dan peristiwa siklus prosesnya seperti instance yang dihentikan.
Gambar 1. Contoh dasbor yang menampilkan ketersediaan instance dan peristiwa siklus prosesnya seperti instance yang dihentikan.Membuat metrik berbasis log
Untuk mencatat peristiwa siklus proses VM, buat metrik berbasis log yang ditentukan pengguna. Metrik ini menggunakan Cloud Audit Logs untuk mencatat berapa kali peristiwa siklus proses VM tertentu terjadi.
Untuk mendapatkan izin yang diperlukan guna membuat metrik, minta administrator untuk memberi Anda peran IAM Logs Writer (
roles/logging.logWriter) pada project. Untuk mengetahui informasi selengkapnya tentang cara memberikan peran, lihat Mengelola akses ke project, folder, dan organisasi.Anda mungkin juga bisa mendapatkan izin yang diperlukan melalui peran kustom atau peran yang telah ditentukan lainnya.
Buat metrik berbasis log yang ditentukan pengguna dengan melakukan langkah berikut:
Di konsol Google Cloud , buka halaman Log-based Metrics.
Klik Buat Metrik.
Di bagian Metric Type, lakukan hal berikut:
- Pilih
Counter. - Biarkan Distribution pada setelan default-nya, yaitu tidak dipilih.
Di bagian Details, masukkan informasi berikut:
- Log-based metric name:
vm-lifecycle-events. Anda harus menggunakan nama persis ini agar dasbor berfungsi dengan benar. - Description: Opsional — Masukkan deskripsi untuk metrik ini.
- Units:
1
Di bagian Filter selection, tentukan berikut ini:
- Dari menu Select project or log bucket, pilih: Project logs
- Di Build filter, masukkan:
resource.type = "gce_instance" AND log_id("cloudaudit.googleapis.com/activity") OR log_id("cloudaudit.googleapis.com/system_event") operation.first="true"
Di bagian Labels, klik Add label.
Tentukan nilai berikut:
- Label name:
method - Label type:
STRING - Field name:
protoPayload.methodName - Regular expression:
(recreateInstance|hostError|automaticRestart|guestTerminate|terminateOnHostMaintenance|preempted|insert|stop|delete|reset|start)
- Label name:
Klik Done
Klik Create Metric
Menggunakan dasbor
Data tidak akan muncul di dasbor hingga instance mengalami peristiwa sistem atau aktivitas administrator. Untuk menguji apakah dasbor berfungsi, lakukan aktivitas administrator, seperti operasi
stopdanstart:- Jalankan operasi
stopdanstartpada instance yang ada, atau buat VM baru untuk tujuan pengujian.
Untuk mendapatkan izin yang diperlukan untuk menggunakan dasbor, minta administrator untuk memberi Anda peran IAM Monitoring Dashboard Viewer (
roles/monitoring.dashboardViewer) pada project. Untuk mengetahui informasi selengkapnya tentang cara memberikan peran, lihat Mengelola akses ke project, folder, dan organisasi.Anda mungkin juga bisa mendapatkan izin yang diperlukan melalui peran kustom atau peran yang telah ditentukan lainnya.
Buka Dasbor di konsol Google Cloud .
Dari tab Dashboard List, buka dasbor
GCE VM Lifecycle Events Monitoring.Pilih VM dari menu drop-down Name.
Persempit deret waktu ke jangka waktu yang relevan.
Untuk mengetahui cara lainnya dalam memfilter dasbor, lihat Menambahkan filter sementara.
Dasbor ini berisi dua diagram yang menampilkan linimasa peristiwa sistem dan aktivitas administrator yang terjadi di sebuah instance:
Diagram VM Lifecycle Timeline menampilkan hal berikut:
- Metrik
compute.googleapis.com/instance/uptimeyang menunjukkan apakah VM berjalan pada titik waktu tertentu atau tidak, di mana 1 adalah berjalan dan 0 tidak berjalan. Perhatikan bahwa metrik ini mencerminkan ketersediaan sebagai akibat dari aktivitas pengguna serta peristiwa sistem, dan tidak mengindikasikan SLA Compute Engine. - Metrik berbasis log
vm-lifecycle-eventsuntuk menghitung jumlah tindakan siklus proses, sepertistopataustartyang dilakukan terhadap instance pada titik waktu tertentu
- Metrik
Diagram Events menunjukkan metrik berbasis log
vm-lifecycle-eventsyang sama, tetapi dalam tampilan yang diperbesar agar lebih mudah dibaca. Perhatikan bahwa meskipun sumbu X sejajar, warnanya tidak sinkron di antara kedua diagram.
Menyelidiki shutdown VM massal di banyak project
Compute Engine dapat mematikan banyak VM yang terhubung ke project host VPC Bersama, jika penagihan project host VPC Bersama tersebut tidak aktif atau dinonaktifkan.
Untuk menentukan apakah VM Anda dimatikan karena permintaan shutdown massal, temukan operasi stop yang dimulai oleh
cloud-cluster-manager@prod.google.com.Memulai instance yang terdampak akan menampilkan error yang mirip dengan berikut ini:
Starting instance(s) INSTANCE_NAME...failed. ERROR: (gcloud.compute.instances.start) The default network interface [nic0] is frozen.Untuk menyelesaikan masalah ini, lakukan tindakan berikut:
Identifikasi VPC Bersama yang digunakan oleh VM, dengan menggunakan perintah
gcloud compute instances describe:gcloud compute instances describe VM_NAME \ --format="flattened(networkInterfaces[].network)"
Output-nya mirip dengan berikut ini:
networkInterfaces[0].network: https://www.googleapis.com/compute/v1/projects/SHARED_VPC_PROJECT/global/networks/FROZEN_NETWORK
Verifikasi di project host VPC Bersama apakah penagihan telah dinonaktifkan.
resource.type="project" protoPayload.request.@type="type.googleapis.com/google.internal.cloudbilling.billingaccount.v1.DisableResourceBillingRequest" protoPayload.response.resourceBillingInfo.billingAccountAssignmentType="DISABLED"Jika berlaku, Aktifkan penagihan pada project host.
Untuk menghindari terulangnya masalah ini, baca Mengamankan link antara project dan akun penagihannya.
Kecuali dinyatakan lain, konten di halaman ini dilisensikan berdasarkan Lisensi Creative Commons Attribution 4.0, sedangkan contoh kode dilisensikan berdasarkan Lisensi Apache 2.0. Untuk mengetahui informasi selengkapnya, lihat Kebijakan Situs Google Developers. Java adalah merek dagang terdaftar dari Oracle dan/atau afiliasinya.
Terakhir diperbarui pada 2025-10-18 UTC.
-