Ce document décrit les causes les plus fréquentes d'arrêts et de redémarrages inattendus des instances Compute Engine, et explique comment les éviter.
Les arrêts et redémarrages d'instances peuvent être dus à des événements système ou à des activités d'administration. Les arrêts et les redémarrages des événements système sont générés par les systèmes Google ou le système d'exploitation de vos instances. Les arrêts et les redémarrages d'activités d'administration sont générés par un appel d'API généré par un utilisateur ou un compte de service. Tous les arrêts et redémarrages sont consignés, à l'exception des redémarrages initiés à partir de l'instance.
Avant de commencer
-
Si ce n'est pas déjà fait, configurez l'authentification.
L'authentification permet de valider votre identité pour accéder aux services et aux API Google Cloud . Pour exécuter du code ou des exemples depuis un environnement de développement local, vous pouvez vous authentifier auprès de Compute Engine en sélectionnant l'une des options suivantes :
Select the tab for how you plan to use the samples on this page:
Console
When you use the Google Cloud console to access Google Cloud services and APIs, you don't need to set up authentication.
gcloud
-
Installez la Google Cloud CLI. Une fois l'installation terminée, initialisez la Google Cloud CLI en exécutant la commande suivante :
gcloud initSi vous utilisez un fournisseur d'identité (IdP) externe, vous devez d'abord vous connecter à la gcloud CLI avec votre identité fédérée.
- Set a default region and zone.
Diagnostiquer les arrêts et les redémarrages d'instances
Pour diagnostiquer la cause de l'arrêt ou du redémarrage spontanés d'une instance, vous devez interroger les journaux de vos instances. Pour identifier rapidement la cause des futurs arrêts ou redémarrages de VM, créez un tableau de bord contenant les journaux. Après avoir interrogé les journaux, examinez les champs
methodetprincipalEmailpour déterminer quel événement et quel utilisateur ou service a déclenché l'arrêt ou le redémarrage.Interroger les journaux d'audit Cloud
Interrogez les journaux d'audit Cloud pour afficher la liste des événements système et des activités d'administration qui ont pu entraîner l'arrêt ou le redémarrage.
Console
Dans la console Google Cloud , accédez à la page Explorateur de journaux.
Dans le champ Requête, saisissez la requête suivante :
resource.type="gce_instance" "VM_NAME" logName:("logs/cloudaudit.googleapis.com%2Fsystem_event" OR "logs/cloudaudit.googleapis.com%2Factivity")Remplacez
VM_NAMEpar le nom de la VM qui s'est arrêtée ou a redémarré.Si l'événement que vous recherchez s'est produit il y a plus d'une heure, définissez une période personnalisée en cliquant sur le symbole de l'horloge et en saisissant une plage personnalisée.
Cliquez sur Exécuter la requête. Les résultats sont affichés dans la section Résultats de la requête.
Cliquez sur la flèche de développement à côté de chaque résultat pour afficher des informations détaillées.
Consultez la page Examiner les journaux d'audit Cloud pour en savoir plus sur les champs
methodetprincipalEmailassociés aux arrêts et aux redémarrages, et découvrir comment y remédier.
gcloud
Affichez les journaux d'audit Cloud à l'aide de la commande
gcloud logging read:gcloud logging read --freshness=TIME 'resource.type="gce_instance" "VM_NAME" logName:("logs/cloudaudit.googleapis.com%2Fsystem_event" OR "logs/cloudaudit.googleapis.com%2Factivity")'Remplacez les éléments suivants :
TIME: période que vous souhaitez interroger. Par exemple,1hinterroge les entrées du journal de la dernière heure. Pour en savoir plus sur les formats de date et d'heure, consultez Date et heure gcloud.VM_NAME: nom de la VM qui s'est arrêtée ou a redémarré.
Les résultats s'affichent.
Consultez la page Examiner les journaux d'audit Cloud pour en savoir plus sur les champs
methodetprincipalEmailassociés aux arrêts et aux redémarrages, et découvrir comment y remédier.
Examiner les journaux d'audit Cloud
Consultez les champs
methodetprincipalEmaildes journaux d'audit Cloud pour déterminer pourquoi votre VM s'est arrêtée ou a redémarré.Consultez les champs
methoddes journaux d'audit Cloud et comparez-les aux méthodes répertoriées dans le tableau suivant.Méthode Type d'arrêt Description compute.instances.repair.recreateInstanceÉvénement système Si votre VM appartient à un groupe d'instances géré (MIG), celui-ci recrée la VM si la VM a quitté l'état
RUNNINGet que le MIG n'a pas initié ce changement d'état.Parmi les modifications de l'état d'une instance qui ne sont pas générées par le MIG, citons :
- les défaillances matérielles ;
- l'arrêt d'une instance préemptive ;
- les événements de maintenance de l'infrastructure dans le cas d'une instance de VM pour laquelle la migration à chaud n'est pas activée.
- Pour supprimer une instance MIG, utilisez l'une des méthodes suivantes :
- La méthode d'API
instances.delete - La commande
gcloud compute instances delete
- La méthode d'API
compute.instances.hostErrorÉvénement système Une erreur d'hôte (
compute.instances.hostError) signifie qu'un problème matériel ou logiciel s'est produit sur la machine physique ou l'infrastructure du centre de données hébergeant votre instance de calcul, ce qui a entraîné le plantage de votre instance. Une erreur d'hôte impliquant une défaillance matérielle totale ou d'autres problèmes matériels peut empêcher la migration à chaud de votre instance. Si votre instance est configurée pour redémarrer automatiquement, ce qui est le paramètre par défaut, Compute Engine la redémarre, généralement dans les trois minutes suivant la détection de l'erreur. Selon le problème, le redémarrage peut prendre jusqu'à 5,5 minutes.Il peut arriver qu'une instance de calcul ne réponde plus avant qu'une erreur d'hôte ne soit signalée. Vous pouvez réduire le temps d'attente de Compute Engine avant le redémarrage ou l'arrêt de l'instance en définissant le délai avant expiration de récupération d'erreur de l'hôte. Pour en savoir plus, consultez Définir des règles de disponibilité.
Des pannes matérielles et logicielles peuvent se produire occasionnellement, mais sont rares. Pour protéger vos applications et vos services des événements système potentiellement perturbateurs, consultez les ressources suivantes :
- Concevoir des systèmes robustes
- Modèles d'applications évolutives et résilientes
- Créer des groupes d'instances gérés
Google propose également des services gérés tels que App Engine et l'environnement flexible App Engine.
compute.instances.automaticRestartÉvénement système Cet événement se produit après un événement
hostErrorouterminateOnHostMaintenancesi la stratégie de maintenance de l'hôteautomaticRestartde votre VM est définie surtrue. Dans les journaux, une entrée de journal de typehostErrorouterminateOnHostMaintenanceprécède ce journal.Si vous souhaitez modifier la stratégie de maintenance de l'hôte de votre VM, consultez la section Mettre à jour les options d'une instance.
compute.instances.guestTerminateÉvénement système Le système d'exploitation de votre VM a déclenché l'arrêt. compute.instances.terminateOnHostMaintenanceÉvénement système Si vous définissez la stratégie de maintenance de l'hôte
onHostMaintenancede votre VM surTERMINATE, Compute Engine arrête votre VM lors d'un événement de maintenance nécessitant que Google la déplace vers un autre hôte.Si vous souhaitez modifier la règle
onHostMaintenancede votre VM, consultez la section Mettre à jour les options pour une instance.compute.instances.preemptedÉvénement système Compute Engine a préempté votre VM Spot ou votre ancienne VM préemptive :
- Lorsque Compute Engine préempte une VM Spot, il l'arrête ou la supprime en fonction de son action d'arrêt. Les VM Spot n'ont pas de durée d'exécution maximale.
- Lorsque Compute Engine préempte une VM préemptive, il l'arrête après un délai d'exécution maximal de 24 heures. Pour éviter ces problèmes, utilisez plutôt des VM Spot.
Les VM Spot et les VM préemptives représentent la capacité excédentaire de Compute Engine. Par conséquent, Compute Engine peut les préempter chaque fois que la capacité est requise ailleurs. Vous pouvez contribuer à limiter les effets de la préemption en suivant les bonnes pratiques. Si vous avez besoin de VM avec des environnements d'exécution contrôlés par l'utilisateur, vous pouvez également créer des VM standards.
compute.instances.stopActivité d'administration Un utilisateur ou un compte de service a arrêté votre VM.
Passez à l'étape suivante pour identifier l'utilisateur ou le compte de service qui a arrêté votre VM. Pour en savoir plus sur le redémarrage de votre VM, consultez la section Redémarrer une instance arrêtée.
compute.instances.deleteActivité d'administration ou événement système Un utilisateur ou un compte de service a supprimé votre VM, ou celle-ci a été configurée pour être supprimée automatiquement.
Plus précisément, un journal de la méthode
compute.instances.deletepeut indiquer l'une des requêtes suivantes pour votre VM :- Les requêtes d'un utilisateur ou d'un compte de service visant à supprimer directement votre VM ne sont indiquées que par une méthode
compute.instances.deletede l'utilisateur ou du compte de service. Les requêtes qui suppriment automatiquement votre VM sont indiquées par une méthode
compute.instances.deletedesystem@google.com, mais la méthode qui explique la cause de la suppression automatique peut apparaître ou non dans les journaux d'audit Cloud.Par exemple, si une VM Spot est configurée pour être automatiquement supprimée lors de la préemption et qu'elle est préemptée, vous verrez une méthode
compute.instances.deleteà partir desystem@google.com, mais vous verrez peut-être aussi une méthodecompute.instances.preempted.Les requêtes adressées à la VM peu avant ou après une méthode
compute.instances.deletepeuvent apparaître ou non dans Cloud Audit Logs.Par exemple, si une VM est arrêtée en raison d'une maintenance de l'hôte peu de temps avant d'être supprimée, vous verrez une méthode
compute.instances.delete, mais vous verrez peut-être aussi une méthodecompute.instances.terminateOnHostMaintenance.
Passez à l'étape suivante pour identifier l'utilisateur ou le compte de service qui a supprimé votre VM. Pour en savoir plus sur la création d'une VM, consultez la section Créer et démarrer une VM.
compute.instances.insertActivité d'administration Un utilisateur ou un compte de service a créé votre VM.
Passez à l'étape suivante pour identifier l'utilisateur ou le compte de service qui a créé votre VM. Pour en savoir plus sur la création d'une VM, consultez la section Créer et démarrer une VM.
compute.instances.resetActivité d'administration Un utilisateur ou un compte de service a réinitialisé votre VM.
Passez à l'étape suivante pour identifier l'utilisateur ou le compte de service qui a arrêté votre VM.
Examinez les champs
principalEmaildes journaux d'audit Cloud pour identifier l'utilisateur ou le service qui a lancé l'arrêt ou le redémarrage. Le tableau suivant présente les services gérés par Google fréquents qui lancent des arrêts ou des redémarrages.E-mail Description system@google.comUn événement système est à l'origine de l'arrêt ou du redémarrage. project-number@cloudservices.gserviceaccount.comUn agent de service a lancé l'arrêt.
Pour déterminer le projet à partir duquel le service a initié l'arrêt, consultez le fichier
project-numberde l'agent de service.Pour déterminer quel service Google a émis la requête, consultez le champ
protoPayload.requestMetadata.callerSuppliedUserAgent.Si un utilisateur a déclenché l'arrêt ou le redémarrage, son adresse e-mail apparaît dans le champ
principalEmail. Exemple :cloudysanfrancisco@gmail.comLes administrateurs peuvent empêcher les utilisateurs de modifier l'état des VM du projet en modifiant les autorisations Identity and Access Management sur les comptes d'utilisateur. Pour en savoir plus, consultez la page Accorder, modifier et révoquer les accès à des ressources.
Surveiller les événements de cycle de vie d'une VM
Vous pouvez surveiller les événements de cycle de vie des VM (y compris les arrêts, les redémarrages et les erreurs d'hôte) en créant un tableau de bord Cloud Monitoring.
Ce tableau de bord vous permet de visualiser les événements système et les activités d'administration décrits plus en détail dans la section Examiner les journaux d'audit du présent document.
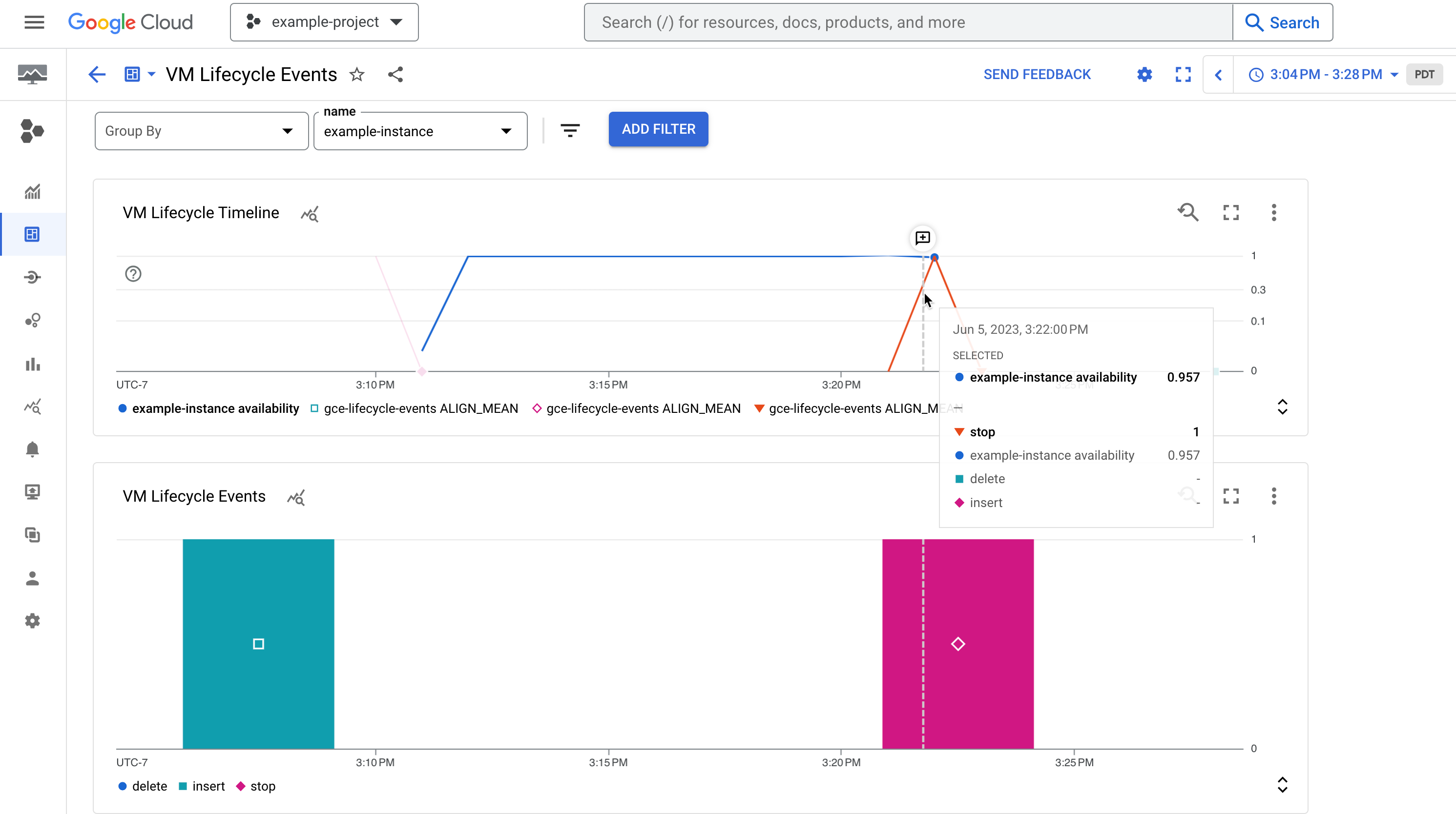 Figure 1. Exemple de tableau de bord indiquant la disponibilité d'une instance et ses événements de cycle de vie, tels que les arrêts d'instance.
Figure 1. Exemple de tableau de bord indiquant la disponibilité d'une instance et ses événements de cycle de vie, tels que les arrêts d'instance.Créer une métrique basée sur les journaux
Pour capturer des événements de cycle de vie de VM, créez une métrique basée sur les journaux définie par l'utilisateur. Cette métrique utilise les journaux d'audit pour comptabiliser le nombre d'occurrences d'un événement de cycle de vie de VM particulier.
Pour obtenir les autorisations nécessaires pour créer la métrique, demandez à votre administrateur de vous accorder le rôle IAM Rédacteur de journaux (
roles/logging.logWriter) sur le projet. Pour en savoir plus sur l'attribution de rôles, consultez la page Gérer l'accès aux projets, aux dossiers et aux organisations.Vous pouvez également obtenir les autorisations requises via des rôles personnalisés ou d'autres rôles prédéfinis.
Créez une métrique basée sur les journaux définie par l'utilisateur en procédant comme suit :
Dans la console Google Cloud , accédez à la page Métriques basées sur les journaux.
Cliquez sur Créer une métrique.
Dans la section Type de métrique, procédez comme suit :
- Sélectionnez
Counter. - Laissez le champ Distribution défini sur le paramètre par défaut (non sélectionné).
Dans la section Détails, saisissez les informations suivantes :
- Nom de la métrique basée sur les journaux :
vm-lifecycle-events. Vous devez utiliser ce nom exact pour que le tableau de bord fonctionne correctement. - Description : facultatif) - saisissez une description de la métrique.
- Unités :
1
Dans la section Sélection de filtres, spécifiez les éléments suivants :
- Dans le menu Sélectionner un projet ou un bucket de journaux, sélectionnez : Journaux de projet.
- Dans le champ Construire un filtre, saisissez :
resource.type = "gce_instance" AND log_id("cloudaudit.googleapis.com/activity") OR log_id("cloudaudit.googleapis.com/system_event") operation.first="true"
Dans la section Libellés, cliquez sur Ajouter un libellé.
Renseignez les champs suivants :
- Nom du libellé :
method - Type de libellé :
STRING - Nom du champ :
protoPayload.methodName - Expression régulière :
(recreateInstance|hostError|automaticRestart|guestTerminate|terminateOnHostMaintenance|preempted|insert|stop|delete|reset|start)
- Nom du libellé :
Cliquez sur Terminé.
Cliquez sur Créer une métrique.
Utiliser le tableau de bord
Aucune donnée n'apparaît dans le tableau de bord tant qu'une instance ne rencontre pas d'événement système ni d'activité d'administration. Pour vérifier que le tableau de bord fonctionne, effectuez une activité d'administrateur, telle qu'une opération
stopetstart:- Effectuez une opération
stopetstartsur n'importe quelle instance existante, ou créez-en une à des fins de test.
Pour obtenir les autorisations nécessaires pour utiliser le tableau de bord, demandez à votre administrateur de vous accorder le rôle IAM Lecteur de tableau de bord Monitoring (
roles/monitoring.dashboardViewer) sur le projet. Pour en savoir plus sur l'attribution de rôles, consultez la page Gérer l'accès aux projets, aux dossiers et aux organisations.Vous pouvez également obtenir les autorisations requises avec des rôles personnalisés ou d'autres rôles prédéfinis.
Ouvrez Tableaux de bord dans la console Google Cloud .
Dans l'onglet Liste de tableaux de bord, ouvrez le tableau de bord
GCE VM Lifecycle Events Monitoring.Sélectionnez la VM dans le menu déroulant Nom.
Limitez la série temporelle à une période pertinente.
Pour découvrir d'autres moyens de filtrer le tableau de bord, consultez Ajouter un filtre temporaire.
Le tableau de bord contient deux graphiques qui affichent une chronologie des événements système et des activités d'administration sur une instance :
Le graphique Chronologie de cycle de vie de la VM affiche les éléments suivants :
- La métrique
compute.googleapis.com/instance/uptime, qui indique si la VM était en cours d'exécution à un moment donné, 1 signifiant que la VM est opérationnelle et 0 qu'elle est indisponible. Notez que cette métrique reflète la disponibilité déduite de l'activité des utilisateurs et des événements système. Cette métrique n'a pas de validité au regard du Contrat de niveau de service de Compute Engine. - La métrique basée sur les journaux
vm-lifecycle-eventspour compter le nombre d'actions de cycle de vie, telles questopoustart, effectuées sur l'instance à un moment donné.
- La métrique
Le graphique "Événements" affiche la même métrique basée sur les journaux
vm-lifecycle-events, mais dans une vue agrandie pour faciliter la lisibilité. Bien que les axes X soient alignés, les couleurs ne sont pas synchronisées entre les deux graphiques.
Enquêter sur l'arrêt massif de VM entre les projets
Compute Engine peut arrêter plusieurs VM connectées à un projet hôte de VPC partagé si la facturation de ce projet est inactive ou désactivée.
Pour déterminer si vos VM ont été arrêtées par une requête d'arrêt de masse, recherchez les opérations d'arrêt lancées par
cloud-cluster-manager@prod.google.com.Le démarrage d'une instance concernée renvoie une erreur semblable à celle-ci :
Starting instance(s) INSTANCE_NAME...failed. ERROR: (gcloud.compute.instances.start) The default network interface [nic0] is frozen.Pour résoudre ce problème, procédez comme suit :
Identifiez le VPC partagé utilisé par les VM à l'aide de la commande
gcloud compute instances describe:gcloud compute instances describe VM_NAME \ --format="flattened(networkInterfaces[].network)"
Le résultat ressemble à ce qui suit :
networkInterfaces[0].network: https://www.googleapis.com/compute/v1/projects/SHARED_VPC_PROJECT/global/networks/FROZEN_NETWORK
Vérifiez dans le projet hôte du VPC partagé si la facturation a été désactivée.
resource.type="project" protoPayload.request.@type="type.googleapis.com/google.internal.cloudbilling.billingaccount.v1.DisableResourceBillingRequest" protoPayload.response.resourceBillingInfo.billingAccountAssignmentType="DISABLED"Le cas échéant, activez la facturation sur le projet hôte.
Pour éviter que ce problème ne se reproduise, consultez la section Sécuriser l'association entre un projet et son compte de facturation.
Sauf indication contraire, le contenu de cette page est régi par une licence Creative Commons Attribution 4.0, et les échantillons de code sont régis par une licence Apache 2.0. Pour en savoir plus, consultez les Règles du site Google Developers. Java est une marque déposée d'Oracle et/ou de ses sociétés affiliées.
Dernière mise à jour le 2025/10/18 (UTC).
-