이 문서에서는 Compute Engine 인스턴스의 예기치 않은 종료 및 재부팅의 일반적인 원인과 이를 방지하는 방법을 설명합니다.
인스턴스 종료 및 재부팅은 시스템 이벤트 또는 관리 활동으로 인해 발생할 수 있습니다. 시스템 이벤트 종료 및 재부팅은 Google 시스템 또는 인스턴스의 운영체제를 통해 생성됩니다. 관리 활동 종료 및 재부팅은 사용자 또는 서비스 계정 생성 API 호출을 통해 생성됩니다. 인스턴스 내에서 시작된 재부팅을 제외한 모든 종료 및 재부팅은 로깅됩니다.
시작하기 전에
-
아직 인증을 설정하지 않았다면 설정합니다.
인증은 Google Cloud 서비스 및 API에 액세스하기 위해 ID를 확인합니다. 로컬 개발 환경에서 코드 또는 샘플을 실행하려면 다음 옵션 중 하나를 선택하여 Compute Engine에 인증하면 됩니다.
Select the tab for how you plan to use the samples on this page:
Console
When you use the Google Cloud console to access Google Cloud services and APIs, you don't need to set up authentication.
gcloud
-
Google Cloud CLI를 설치합니다. 설치 후 다음 명령어를 실행하여 Google Cloud CLI를 초기화합니다.
gcloud init외부 ID 공급업체(IdP)를 사용하는 경우 먼저 제휴 ID로 gcloud CLI에 로그인해야 합니다.
- Set a default region and zone.
인스턴스 종료 및 재부팅 진단
인스턴스의 자발적 종료나 재부팅의 원인을 진단하려면 인스턴스의 로그를 쿼리해야 합니다. 향후 VM 종료 또는 재부팅의 원인을 빠르게 식별하려면 로그가 포함된 대시보드를 빌드하세요. 로그를 쿼리한 후
method및principalEmail필드를 검토하여 어떤 이벤트, 사용자 또는 서비스에서 종료나 재부팅이 시작되었는지 파악합니다.Cloud 감사 로그 쿼리
Cloud 감사 로그를 쿼리하여 종료 또는 재부팅을 유발했을 수 있는 시스템 이벤트 및 관리 활동 목록을 표시합니다.
콘솔
Google Cloud 콘솔에서 로그 탐색기 페이지로 이동합니다.
쿼리 필드에 다음 쿼리를 입력합니다.
resource.type="gce_instance" "VM_NAME" logName:("logs/cloudaudit.googleapis.com%2Fsystem_event" OR "logs/cloudaudit.googleapis.com%2Factivity")VM_NAME을 종료 또는 재부팅된 VM 이름으로 바꿉니다.찾고 있는 이벤트가 1시간 이상 전에 발생한 경우 시계 기호를 클릭하고 커스텀 범위를 입력하여 커스텀 기간을 설정합니다.
쿼리 실행을 클릭합니다. 쿼리 결과 섹션에 결과가 표시됩니다.
각 결과 옆의 확장 화살표를 클릭하여 자세한 정보를 표시합니다.
종료 및 재부팅과 관련된
method및principalEmail필드와 이를 방지하기 위해 취할 수 있는 조치에 대한 자세한 내용은 Cloud 감사 로그 검토를 참조하세요.
gcloud
gcloud logging read명령어를 사용하여 Cloud 감사 로그를 확인합니다.gcloud logging read --freshness=TIME 'resource.type="gce_instance" "VM_NAME" logName:("logs/cloudaudit.googleapis.com%2Fsystem_event" OR "logs/cloudaudit.googleapis.com%2Factivity")'다음을 바꿉니다.
TIME: 쿼리할 기간입니다. 예를 들어1h는 지난 1시간의 로그 항목을 쿼리합니다. 날짜 및 시간 형식에 대한 자세한 내용은 gcloud topic datetimes를 참조하세요.VM_NAME: 종료 또는 재부팅된 VM의 이름입니다.
결과가 표시됩니다.
종료 및 재부팅과 관련된
method및principalEmail필드와 이를 방지하기 위해 취할 수 있는 조치에 대한 자세한 내용은 Cloud 감사 로그 검토를 참조하세요.
Cloud 감사 로그 검토
Cloud 감사 로그의
method및principalEmail필드를 검토하여 VM이 종료되거나 재부팅된 이유를 파악합니다.Cloud 감사 로그의
method필드를 검토하여 다음 표에 나열된 메서드와 비교합니다.메서드 종료 유형 설명 compute.instances.repair.recreateInstance시스템 이벤트 VM이 관리형 인스턴스 그룹(MIG)에 속하는 경우 VM의 상태가
RUNNING에서 변경되었는데 MIG에서 상태 변경을 시작한 것이 아니라면 MIG에서 VM을 다시 만듭니다.MIG에서 시작하지 않는 인스턴스 상태 변경사항은 다음과 같습니다.
- 하드웨어 오류
- 선점형 인스턴스 종료
- VM 인스턴스가 라이브 마이그레이션으로 설정되지 않은 경우의 인프라 유지보수 이벤트
- 다음 메서드 중 하나를 사용하여 MIG 인스턴스 삭제
instances.deleteAPI 메서드gcloud compute instances delete명령어
compute.instances.hostError시스템 이벤트 호스트 오류(
compute.instances.hostError)는 컴퓨팅 인스턴스를 호스팅하는 실제 머신 또는 데이터 센터 인프라에서 하드웨어 또는 소프트웨어 문제가 발생하여 인스턴스가 비정상 종료되었음을 의미합니다. 총 하드웨어 오류 또는 기타 하드웨어 문제가 포함된 호스트 오류는 인스턴스의 라이브 마이그레이션을 방해할 수 있습니다. 인스턴스가 자동으로 다시 시작하도록 설정된 경우(기본 설정) Compute Engine은 일반적으로 오류가 감지된 시간부터 3분 내로 인스턴스를 다시 시작합니다. 문제에 따라 다시 시작하는 데 최대 5.5분이 걸릴 수 있습니다.호스트 오류가 감지되기 전에 컴퓨팅 인스턴스가 응답하지 않는 경우가 있습니다. 호스트 오류 복구 제한 시간을 설정하여 Compute Engine이 인스턴스를 다시 시작하거나 종료하기 위해 대기하는 시간을 줄일 수 있습니다. 자세한 내용은 가용성 정책 설정을 참조하세요.
물리적인 하드웨어 및 소프트웨어 오류가 간혹 발생할 수 있지만 매우 드물게 발생합니다. 이와 같은 시스템 중단 이벤트로부터 애플리케이션과 서비스를 보호하기 위해 다음 리소스를 검토하세요.
Google은 또한 App Engine 및 App Engine 가변형 환경과 같은 관리형 서비스를 제공합니다.
compute.instances.automaticRestart시스템 이벤트 이 이벤트는
automaticRestart호스트 유지보수 정책이true로 설정된 경우hostError이벤트 또는terminateOnHostMaintenance이벤트 다음에 발생합니다. 로그에서hostError또는terminateOnHostMaintenance로그 항목이 이 로그 앞에 옵니다.VM의 호스트 유지보수 정책을 변경하려면 인스턴스 옵션 업데이트를 참조하세요.
compute.instances.guestTerminate시스템 이벤트 VM 운영체제에서 종료가 시작되었습니다. compute.instances.terminateOnHostMaintenance시스템 이벤트 VM의
onHostMaintenance호스트 유지보수 정책을TERMINATE로 설정하면 Google에서 VM을 다른 호스트로 이동해야 하는 유지보수 이벤트가 있을 때 Compute Engine에서 VM을 중지합니다.VM의
onHostMaintenance정책을 변경하려면 인스턴스 옵션 업데이트를 참조하세요.compute.instances.preempted시스템 이벤트 Compute Engine이 스팟 VM 또는 기존 선점형 VM을 선점했습니다.
- Compute Engine이 스팟 VM을 선점한 경우 Compute Engine은 해당 종료 작업을 기준으로 스팟 VM을 중지하거나 삭제합니다. 스팟 VM에는 최대 런타임이 없습니다.
- Compute Engine이 선점형 VM을 선점하면 최대 런타임 24시간 후에 VM을 중지합니다. 이러한 제한을 적용하지 않으려면 Spot VM을 대신 사용하세요.
Spot VM 및 선점형 VM은 초과 Compute Engine 용량이므로, 용량이 필요할 때마다 언제든지 Compute Engine이 이를 선점할 수 있습니다. 권장사항에 따라 선점 효과를 완화할 수 있습니다 또는 사용자 제어 런타임이 있는 VM이 필요하면 대신 표준 VM을 만듭니다.
compute.instances.stop관리자 활동 사용자 또는 서비스 계정에서 VM을 중지했습니다.
다음 단계로 이동하여 VM을 중지한 사용자 또는 서비스 계정을 확인합니다. VM 다시 시작에 대한 자세한 내용은 중지된 인스턴스 다시 시작을 참조하세요.
compute.instances.delete관리자 활동 또는 시스템 이벤트 사용자 또는 서비스 계정에서 VM을 삭제했거나 VM이 자동으로 삭제되도록 구성되었습니다.
특히
compute.instances.delete메서드의 로그는 VM에 대한 다음 요청 중 하나를 나타낼 수 있습니다.- 사용자 또는 서비스 계정에서 VM을 직접 삭제하도록 요청하는 경우 사용자 또는 서비스 계정의
compute.instances.delete메서드로만 표시됩니다. VM을 자동으로 삭제하는 요청은
system@google.com의compute.instances.delete메서드로 표시되지만 자동 삭제의 원인을 설명하는 메서드는 Cloud 감사 로그에 표시될 수도 있고 표시되지 않을 수도 있습니다.예를 들어 스팟 VM이 선점 중에 자동으로 삭제되도록 구성되어 있고 선점된 경우
system@google.com에서compute.instances.delete메서드가 표시되지만compute.instances.preempted메서드도 표시될 수도 있고 표시되지 않을 수도 있습니다.compute.instances.delete메서드 직전 또는 직후에 발생한 VM 요청은 Cloud 감사 로그에 표시될 수도 있고 표시되지 않을 수도 있습니다.예를 들어 VM이 삭제되기 직전에 호스트 유지보수로 인해 VM이 중지되면
compute.instances.delete메서드가 표시되지만compute.instances.terminateOnHostMaintenance메서드는 표시될 수도 있고 표시되지 않을 수도 있습니다.
다음 단계로 이동하여 VM을 삭제한 사용자 또는 서비스 계정을 확인합니다. 새 VM 만들기에 대한 자세한 내용은 VM 만들기 및 시작을 참조하세요.
compute.instances.insert관리자 활동 사용자 또는 서비스 계정에서 VM을 만들었습니다.
다음 단계로 이동하여 VM을 만든 사용자 또는 서비스 계정을 확인합니다. 새 VM 만들기에 대한 자세한 내용은 VM 만들기 및 시작을 참조하세요.
compute.instances.reset관리자 활동 사용자 또는 서비스 계정에서 VM을 재설정합니다.
다음 단계로 이동하여 VM을 중지한 사용자 또는 서비스 계정을 확인합니다.
Cloud 감사 로그의
principalEmail필드를 검토하여 종료 또는 재부팅을 시작한 사용자 또는 서비스를 확인합니다. 다음 표에는 종료 또는 재부팅을 시작하는 일반적인 Google 관리형 서비스가 포함되어 있습니다.이메일 설명 system@google.com시스템 이벤트로 인해 종료 또는 재부팅이 발생했습니다. project-number@cloudservices.gserviceaccount.com서비스 에이전트에서 종료를 시작했습니다.
서비스에서 종료를 시작한 프로젝트를 확인하려면 서비스 에이전트의
project-number를 검토하세요.요청한 Google 서비스를 확인하려면
protoPayload.requestMetadata.callerSuppliedUserAgent필드를 검토하세요.사용자가 종료 또는 재부팅을 트리거한 경우 사용자의 이메일 주소가
principalEmail필드에 표시됩니다. 예를 들면cloudysanfrancisco@gmail.com입니다.관리자는 사용자 계정에 대한 Identity and Access Management 권한을 변경하여 사용자가 프로젝트 VM 상태를 변경하지 못하도록 할 수 있습니다. 자세한 내용은 리소스에 대한 액세스 권한 부여, 변경, 취소를 참조하세요.
VM 수명 주기 이벤트 모니터링
Cloud Monitoring 대시보드를 빌드하여 VM 수명 주기 이벤트(종료, 재부팅, 호스트 오류 포함)를 모니터링할 수 있습니다.
이 대시보드를 사용하면 이 문서의 감사 로그 검토 섹션에 자세히 설명된 시스템 이벤트 및 관리자 활동을 시각화할 수 있습니다.
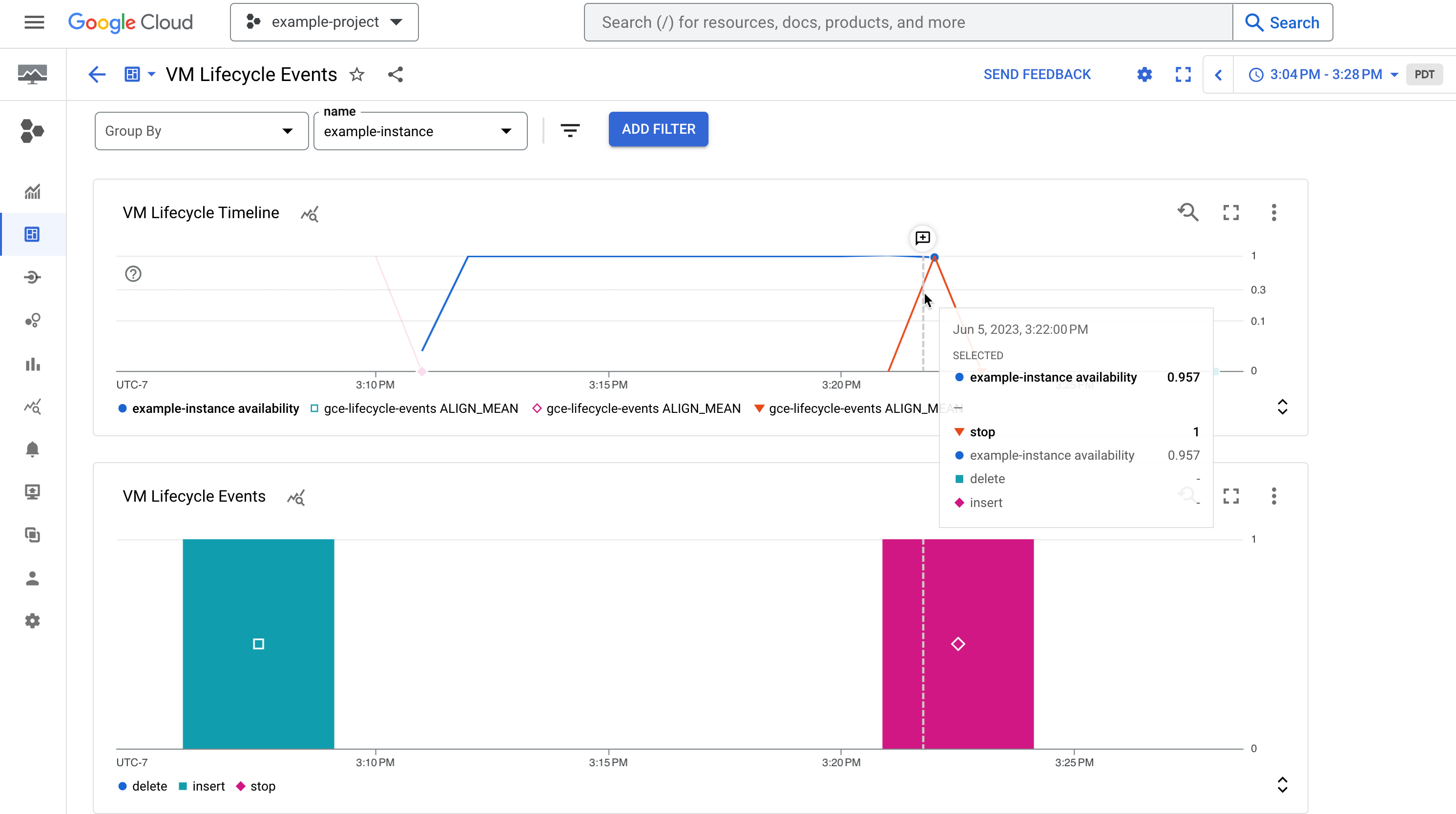 그림 1. 인스턴스의 가용성과 중지된 인스턴스와 같은 수명 주기 이벤트를 보여주는 대시보드의 예시
그림 1. 인스턴스의 가용성과 중지된 인스턴스와 같은 수명 주기 이벤트를 보여주는 대시보드의 예시로그 기반 측정항목 만들기
VM 수명 주기 이벤트를 캡처하려면 사용자 정의 로그 기반 측정항목을 만드세요. 이 측정항목은 감사 로그를 사용하여 특정 VM 수명 주기 이벤트가 발생한 횟수를 셉니다.
측정항목을 만드는 데 필요한 권한을 얻으려면 관리자에게 프로젝트에 대한 로그 작성자(
roles/logging.logWriter) IAM 역할을 부여해 달라고 요청하세요. 역할 부여에 대한 자세한 내용은 프로젝트, 폴더, 조직에 대한 액세스 관리를 참조하세요.커스텀 역할이나 다른 사전 정의된 역할을 통해 필요한 권한을 얻을 수도 있습니다.
사용자 정의 로그 기반 측정항목을 만들려면 다음 안내를 따르세요.
Google Cloud 콘솔에서 로그 기반 측정항목 페이지로 이동합니다.
측정항목 만들기를 클릭합니다.
측정항목 유형 섹션에서 다음을 수행합니다.
Counter를 선택합니다.- 배포를 선택 해제된 기본 설정으로 둡니다.
세부정보 섹션에서 다음 정보를 입력합니다.
- 로그 기반 측정항목 이름:
vm-lifecycle-events. 대시보드가 올바르게 작동하려면 이 정확한 이름을 사용해야 합니다. - 설명: (선택사항) 이 측정항목에 대한 설명을 입력합니다.
- 단위:
1
필터 선택 섹션에서 다음을 지정합니다.
- 프로젝트 또는 로그 버킷 선택 메뉴에서 프로젝트 로그를 선택합니다.
- 필터 빌드에 다음을 입력합니다.
resource.type = "gce_instance" AND log_id("cloudaudit.googleapis.com/activity") OR log_id("cloudaudit.googleapis.com/system_event") operation.first="true"
라벨 섹션에서 라벨 추가를 클릭합니다.
다음 사항을 지정합니다.
- 라벨 이름:
method - 라벨 유형:
STRING - 필드 이름:
protoPayload.methodName - 정규 표현식:
(recreateInstance|hostError|automaticRestart|guestTerminate|terminateOnHostMaintenance|preempted|insert|stop|delete|reset|start)
- 라벨 이름:
완료를 클릭합니다.
측정항목 만들기를 클릭합니다.
대시보드 사용
인스턴스에서 시스템 이벤트 또는 관리자 활동이 발생할 때까지는 대시보드에 데이터가 표시되지 않습니다. 대시보드가 작동하는지 테스트하려면
stop및start작업과 같은 관리자 활동을 실행합니다.- 기존 인스턴스에서
stop및start작업을 수행하거나 테스트 목적으로 새 VM을 만듭니다.
대시보드를 사용하는 데 필요한 권한을 얻으려면 관리자에게 프로젝트에 대한 Monitoring 대시보드 뷰어(
roles/monitoring.dashboardViewer) IAM 역할을 부여해 달라고 요청하세요. 역할 부여에 대한 자세한 내용은 프로젝트, 폴더, 조직에 대한 액세스 관리를 참조하세요.커스텀 역할이나 다른 사전 정의된 역할을 통해 필요한 권한을 얻을 수도 있습니다.
Google Cloud 콘솔에서 대시보드를 엽니다.
대시보드 목록 탭에서
GCE VM Lifecycle Events Monitoring대시보드를 엽니다.이름 드롭다운 메뉴에서 VM을 선택합니다.
시계열을 해당 기간으로 좁힙니다.
대시보드를 필터링하는 다른 방법은 임시 필터 추가를 참조하세요.
대시보드에는 인스턴스에서 발생하는 시스템 이벤트 및 관리자 활동의 타임라인을 표시하는 두 개의 차트가 포함됩니다.
VM 수명 주기 타임라인 차트에는 다음이 표시됩니다.
- 1이 업이고 0이 다운인 특정 시점에 VM이 실행되었는지 여부를 나타내는
compute.googleapis.com/instance/uptime측정항목. 이 측정항목은 사용자 활동 및 시스템 이벤트의 결과로 인한 가용성을 반영하며 Compute Engine SLA를 나타내지 않습니다. - 특정 시점에 인스턴스에 대해 수행된
stop또는start와 같은 수명 주기 작업 수를 계산하는vm-lifecycle-events로그 기반 측정항목
- 1이 업이고 0이 다운인 특정 시점에 VM이 실행되었는지 여부를 나타내는
이벤트 차트에는 동일한
vm-lifecycle-events로그 기반 측정항목이 표시되지만, 가독성을 높이기 위해 확대된 뷰로 표시됩니다. X축은 정렬되어 있지만 두 차트 간에 색상은 동기화되어 있지 않습니다.
프로젝트 간 대량 VM 종료 조사
공유 VPC 호스트 프로젝트의 결제가 비활성 상태이거나 중지되면 Compute Engine이 공유 VPC 호스트 프로젝트에 연결된 VM 여러 개를 종료할 수 있습니다.
대규모 종료 요청으로 인해 VM이 종료되었는지 확인하려면
cloud-cluster-manager@prod.google.com에서 시작한 중지 작업을 찾습니다.영향을 받는 인스턴스를 시작하면 다음과 비슷한 오류가 반환됩니다.
Starting instance(s) INSTANCE_NAME...failed. ERROR: (gcloud.compute.instances.start) The default network interface [nic0] is frozen.이 문제를 해결하려면 다음 단계를 따르세요.
gcloud compute instances describe명령어를 사용하여 VM에서 사용하는 공유 VPC를 식별합니다.gcloud compute instances describe VM_NAME \ --format="flattened(networkInterfaces[].network)"
출력은 다음과 비슷합니다.
networkInterfaces[0].network: https://www.googleapis.com/compute/v1/projects/SHARED_VPC_PROJECT/global/networks/FROZEN_NETWORK
공유 VPC의 호스트 프로젝트에서 결제가 중지되었는지 확인합니다.
resource.type="project" protoPayload.request.@type="type.googleapis.com/google.internal.cloudbilling.billingaccount.v1.DisableResourceBillingRequest" protoPayload.response.resourceBillingInfo.billingAccountAssignmentType="DISABLED"해당하는 경우 호스트 프로젝트에서 결제를 사용 설정합니다.
이 문제가 반복되지 않도록 하려면 프로젝트와 결제 계정 간의 링크 보안을 참조하세요.
달리 명시되지 않는 한 이 페이지의 콘텐츠에는 Creative Commons Attribution 4.0 라이선스에 따라 라이선스가 부여되며, 코드 샘플에는 Apache 2.0 라이선스에 따라 라이선스가 부여됩니다. 자세한 내용은 Google Developers 사이트 정책을 참조하세요. 자바는 Oracle 및/또는 Oracle 계열사의 등록 상표입니다.
최종 업데이트: 2025-10-30(UTC)
-