Questo documento descrive le cause comuni di arresti e riavvii imprevisti delle istanze Compute Engine e come evitarli.
Gli arresti e i riavvii delle istanze possono essere causati da eventi di sistema o da attività amministrative. Gli arresti e i riavvii dovuti a eventi di sistema vengono generati dai sistemi Google o dal sistema operativo delle tue istanze. Gli arresti e i riavvii dovuti ad attività amministrative vengono generati da una chiamata API dall'utente o dall'account di servizio. Vengono registrati tutti gli arresti e i riavvii, tranne i riavvii avviati dall'istanza.
Prima di iniziare
-
Se non l'hai ancora fatto, configura l'autenticazione.
L'autenticazione verifica la tua identità per l'accesso a Google Cloud servizi e API. Per eseguire
codice o esempi da un ambiente di sviluppo locale, puoi autenticarti su
Compute Engine selezionando una delle seguenti opzioni:
Select the tab for how you plan to use the samples on this page:
Console
When you use the Google Cloud console to access Google Cloud services and APIs, you don't need to set up authentication.
gcloud
-
Installa Google Cloud CLI. Dopo l'installazione, inizializza Google Cloud CLI eseguendo il seguente comando:
gcloud initSe utilizzi un provider di identità (IdP) esterno, devi prima accedere alla gcloud CLI con la tua identità federata.
- Set a default region and zone.
Diagnosi degli arresti e dei riavvii delle istanze
Per diagnosticare la causa dell'arresto o del riavvio spontanei di un'istanza, devi eseguire una query sui log delle istanze. Per identificare rapidamente la causa di futuri arresti o riavvii della VM, crea un dashboard che contenga i log. Dopo aver eseguito la query sui log, esamina i campi
methodeprincipalEmailper determinare quale evento e quale utente o servizio ha innescato l'arresto o il riavvio.Esecuzione di query su Cloud Audit Logs
Esegui una query su Cloud Audit Logs per visualizzare un elenco di eventi di sistema e attività amministrative che potrebbero aver causato l'arresto o il riavvio.
Console
Nella console Google Cloud , vai alla pagina Esplora log.
Nel campo Query, inserisci la seguente query:
resource.type="gce_instance" "VM_NAME" logName:("logs/cloudaudit.googleapis.com%2Fsystem_event" OR "logs/cloudaudit.googleapis.com%2Factivity")Sostituisci
VM_NAMEcon il nome della VM che è stata arrestata o riavviata.Se l'evento che stai cercando si è verificato più di un'ora fa, imposta un intervallo di tempo personalizzato facendo clic sul simbolo dell'orologio e inserendo l'intervallo che preferisci.
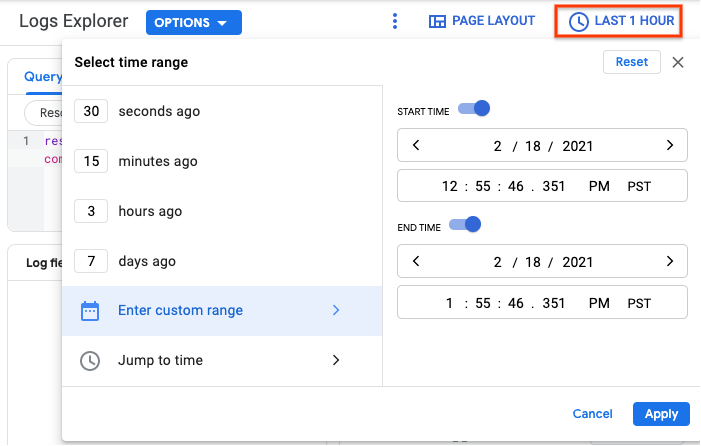
Fai clic su Esegui query. I risultati vengono visualizzati nella sezione Risultati delle query.
Fai clic sulla freccia di espansione accanto a ciascun risultato per visualizzare informazioni dettagliate.
Consulta la sezione Revisione di Cloud Audit Logs per scoprire di più sui campi
methodeprincipalEmailassociati agli arresti e ai riavvii e su cosa puoi fare per prevenirli.
gcloud
Visualizza Cloud Audit Logs utilizzando il comando
gcloud logging read:gcloud logging read --freshness=TIME 'resource.type="gce_instance" "VM_NAME" logName:("logs/cloudaudit.googleapis.com%2Fsystem_event" OR "logs/cloudaudit.googleapis.com%2Factivity")'Sostituisci quanto segue:
TIME: il periodo di tempo per cui vuoi eseguire la query. Ad esempio,1hesegue query sulle voci di log nell'ultima ora. Per informazioni sui formati di data e ora, consulta gcloud topic datetimes.VM_NAME: il nome della VM che è stata arrestata o riavviata.
Vengono visualizzati i risultati.
Consulta la sezione Revisione di Cloud Audit Logs per scoprire di più sui campi
methodeprincipalEmailassociati agli arresti e ai riavvii e su cosa puoi fare per prevenirli.
Analisi di Cloud Audit Logs
Esamina i campi
methodeprincipalEmaildi Cloud Audit Logs per determinare perché la tua VM è stata arrestata o riavviata.Esamina i campi
methoddi Cloud Audit Logs e confrontali con i metodi elencati nella tabella seguente.Metodo Tipo di arresto Descrizione compute.instances.repair.recreateInstanceEvento di sistema Se la VM appartiene a un gruppo di istanze gestite (MIG), il MIG ricrea la VM se il suo stato cambia da
RUNNINGe il MIG non ha avviato la modifica dello stato.Le modifiche dello stato dell'istanza non avviate dal MIG includono:
- Guasti hardware.
- Terminazione di un'istanza prerilasciabile .
- Eventi di manutenzione dell'infrastruttura quando l'istanza VM non è impostata per la migrazione live.
- Eliminazione di un'istanza MIG utilizzando uno dei seguenti metodi:
- Il metodo API
instances.delete - Il comando
gcloud compute instances delete
- Il metodo API
compute.instances.hostErrorEvento di sistema Un errore dell'host (
compute.instances.hostError) indica che si è verificato un problema hardware o software sulla macchina fisica o sull'infrastruttura del data center che ospita l'istanza di computing e ne ha causato l'arresto anomalo. Un errore dell'host che coinvolge un guasto hardware totale o altri problemi relativi all'hardware potrebbe impedire la migrazione live dell'istanza. Se l'istanza è impostata per il riavvio automatico, che è l'impostazione predefinita, Compute Engine la riavvia, in genere entro tre minuti dal rilevamento dell'errore. A seconda del problema, il riavvio potrebbe richiedere fino a 5,5 minuti.A volte, un'istanza di computing potrebbe non rispondere prima che venga segnalato un errore dell'host. Puoi ridurre il tempo di attesa di Compute Engine per riavviare o terminare l'istanza impostando il timeout per la correzione degli errori dell'host. Per saperne di più, consulta Imposta le policy di disponibilità.
A volte possono verificarsi guasti hardware e software fisici, ma si tratta di casi rari. Per proteggere le tue applicazioni e i tuoi servizi da questi eventi di sistema che potrebbero causare interruzioni, consulta le seguenti risorse:
- Progettazione di sistemi solidi
- Pattern per app scalabili e resilienti
- Creazione di gruppi di istanze gestite
Google offre anche servizi gestiti come App Engine e l'ambiente flessibile di App Engine.
compute.instances.automaticRestartEvento di sistema Questo evento si verifica dopo un evento
hostErroro un eventoterminateOnHostMaintenancese la policy di manutenzione dell'hostautomaticRestartdella VM è impostata sutrue. Nei log, questa voce di log è preceduta da una voce di loghostErroroterminateOnHostMaintenance.Se vuoi modificare la policy di manutenzione dell'host della VM, consulta Aggiornamento delle opzioni per un'istanza.
compute.instances.guestTerminateEvento di sistema L'arresto è stato avviato dal sistema operativo della VM. compute.instances.terminateOnHostMaintenanceEvento di sistema Se imposti la policy di manutenzione dell'host
onHostMaintenancedella VM suTERMINATE, Compute Engine arresta la VM quando si verifica un evento di manutenzione in cui Google deve spostare la VM su un altro host.Se vuoi modificare la policy
onHostMaintenancedella VM, consulta Aggiornamento delle opzioni per un'istanza.compute.instances.preemptedEvento di sistema Compute Engine ha prerilasciato la tua VM spot o la tua VM prerilasciabile legacy:
- Quando Compute Engine prerilascia una VM spot, la arresta o la elimina in base all' azione di terminazione. Le VM spot non hanno un tempo di esecuzione massimo.
- Quando Compute Engine prerilascia una VM prerilasciabile, la arresta dopo un tempo di esecuzione massimo di 24 ore. Per evitare queste limitazioni, utilizza invece le VM spot.
Le VM spot e prerilasciabili rappresentano capacità di Compute Engine in eccesso, per cui Compute Engine potrebbe prerilasciarle in qualsiasi momento se la capacità è necessaria altrove. Puoi contribuire a mitigare gli effetti della preemption seguendo le best practice. In alternativa, se hai bisogno di VM con runtime controllati dall'utente, crea VM standard.
compute.instances.stopAttività di amministrazione Un utente o un account di servizio ha arrestato la VM.
Continua al passaggio successivo per identificare l'utente o il account di servizio che ha arrestato la VM. Per informazioni sul riavvio della VM, consulta Riavvio di un'istanza arrestata.
compute.instances.deleteAttività di amministrazione o evento di sistema Un utente o un account di servizio ha eliminato la VM oppure la VM è stata configurata per essere eliminata automaticamente.
Nello specifico, un log per il metodo
compute.instances.deletepotrebbe indicare una delle seguenti richieste per la tua VM:- Le richieste di eliminazione diretta della VM da parte di un utente o di un account di servizio sono
indicate solo da un metodo
compute.instances.deleteda parte dell'utente o del account di servizio. Le richieste che eliminano automaticamente la VM sono indicate da un metodo
compute.instances.deletedisystem@google.com, ma il metodo che spiega la causa dell'eliminazione automatica potrebbe essere visualizzato o meno in Cloud Audit Logs.Ad esempio, se una VM spot è configurata per essere eliminata automaticamente durante il prerilascio e viene prerilasciata, viene visualizzato un metodo
compute.instances.deletedasystem@google.com, ma potresti visualizzare o meno anche un metodocompute.instances.preempted.Le richieste alla VM avvenute poco prima o dopo un metodo
compute.instances.deletepotrebbero essere visualizzate o meno in Cloud Audit Logs.Ad esempio, se una VM viene arrestata a causa della manutenzione dell'host poco prima dell'eliminazione della VM, viene visualizzato un metodo
compute.instances.delete, ma potresti o meno visualizzare anche un metodocompute.instances.terminateOnHostMaintenance.
Continua con il passaggio successivo per identificare l'utente o account di servizio che ha eliminato la tua VM. Per informazioni sulla creazione di una nuova VM, consulta Creazione e avvio di una VM.
compute.instances.insertAttività di amministrazione Un utente o un account di servizio ha creato la tua VM.
Continua con il passaggio successivo per identificare l'utente o il account di servizio che ha creato la tua VM. Per informazioni sulla creazione di una nuova VM, consulta Creazione e avvio di una VM.
compute.instances.resetAttività di amministrazione Un utente o un account di servizio ha reimpostato la VM.
Continua al passaggio successivo per identificare l'utente o il account di servizio che ha arrestato la VM.
Esamina i campi
principalEmaildi Cloud Audit Logs per identificare l'utente o il servizio che ha avviato l'arresto o il riavvio. La seguente tabella include i servizi gestiti di Google comuni che avviano arresti o riavvii.Email Descrizione system@google.comL'arresto o il riavvio è stato causato da un evento di sistema. project-number@cloudservices.gserviceaccount.comUn agente di servizio ha avviato l'arresto.
Per determinare da quale progetto il servizio ha avviato l'arresto, esamina
project-numberdell'agente di servizio.Per determinare quale servizio Google ha effettuato la richiesta, esamina il campo
protoPayload.requestMetadata.callerSuppliedUserAgent.Se un utente ha attivato l'arresto o il riavvio, il suo indirizzo email viene visualizzato nel campo
principalEmail. Ad esempio,cloudysanfrancisco@gmail.com.Gli amministratori possono impedire agli utenti di modificare lo stato delle VM del progetto modificando le autorizzazioni di Identity and Access Management sugli account utente. Per saperne di più, consulta Concessione, modifica e revoca dell'accesso alle risorse.
Monitora gli eventi del ciclo di vita delle VM
Puoi monitorare gli eventi del ciclo di vita delle VM (inclusi arresti, riavvii ed errori host) creando una dashboard di Cloud Monitoring.
Questo dashboard ti consente di visualizzare eventi di sistema e attività di amministrazione descritti in modo più dettagliato nella sezione Revisione dei log di controllo di questo documento.
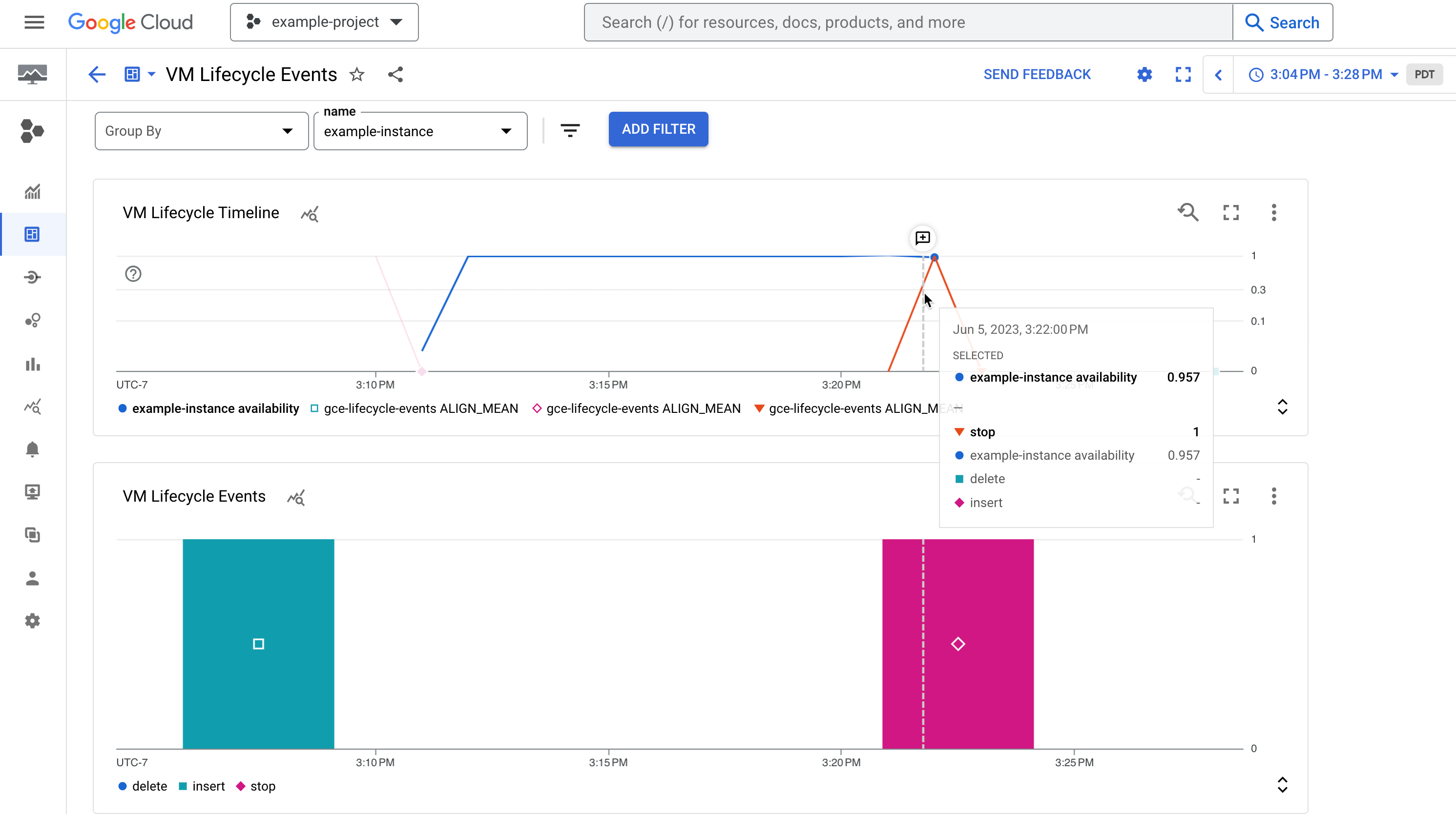 Figura 1. Una dashboard di esempio che mostra la disponibilità di un'istanza e i relativi eventi del ciclo di vita, ad esempio un'istanza arrestata.
Figura 1. Una dashboard di esempio che mostra la disponibilità di un'istanza e i relativi eventi del ciclo di vita, ad esempio un'istanza arrestata.Crea metrica basata su log
Per acquisire gli eventi del ciclo di vita della VM, crea una metrica basata su log definita dall'utente. Questa metrica utilizza i log di controllo per conteggiare il numero di volte in cui si è verificato un determinato evento del ciclo di vita della VM.
Per ottenere le autorizzazioni necessarie per creare la metrica, chiedi all'amministratore di concederti il ruolo IAM Logs Writer (
roles/logging.logWriter) nel progetto. Per saperne di più sulla concessione dei ruoli, consulta Gestisci l'accesso a progetti, cartelle e organizzazioni.Potresti anche riuscire a ottenere le autorizzazioni richieste tramite i ruoli personalizzati o altri ruoli predefiniti.
Crea una metrica basata su log definita dall'utente nel seguente modo:
Nella console Google Cloud , vai alla pagina Metriche basate su log.
Fai clic su Crea metrica.
Nella sezione Tipo di metrica, segui questi passaggi:
- Seleziona
Counter. - Lascia Distribuzione sull'impostazione predefinita di deselezione.
Nella sezione Dettagli, inserisci le seguenti informazioni:
- Nome metrica basata su log:
vm-lifecycle-events. Devi utilizzare questo nome esatto affinché la dashboard funzioni correttamente. - Descrizione: (facoltativo) inserisci una descrizione per questa metrica.
- Unità:
1
Nella sezione Selezione filtri, specifica quanto segue:
- Nel menu Seleziona il bucket di progetto o di log, seleziona: Log di progetto
- Nel campo Crea filtro, inserisci:
resource.type = "gce_instance" AND log_id("cloudaudit.googleapis.com/activity") OR log_id("cloudaudit.googleapis.com/system_event") operation.first="true"
Nella sezione Etichette, fai clic su Aggiungi etichetta.
Specifica quanto segue:
- Nome etichetta:
method - Tipo di etichetta:
STRING - Nome campo:
protoPayload.methodName - Espressione regolare:
(recreateInstance|hostError|automaticRestart|guestTerminate|terminateOnHostMaintenance|preempted|insert|stop|delete|reset|start)
- Nome etichetta:
Fai clic su Fine.
Fai clic su Crea metrica.
Utilizzare la dashboard
Nella dashboard non vengono visualizzati dati finché un'istanza non registra un evento di sistema o un'attività amministrativa. Per verificare che la dashboard funzioni, esegui un'attività di amministratore, ad esempio un'operazione
stopestart:- Esegui un'operazione
stopestartsu qualsiasi istanza esistente o crea una nuova VM a scopo di test.
Per ottenere le autorizzazioni necessarie per utilizzare la dashboard, chiedi all'amministratore di concederti il ruolo IAM Visualizzatore dashboard Monitoring (
roles/monitoring.dashboardViewer) sul progetto. Per saperne di più sulla concessione dei ruoli, consulta Gestisci l'accesso a progetti, cartelle e organizzazioni.Potresti anche riuscire a ottenere le autorizzazioni richieste tramite i ruoli personalizzati o altri ruoli predefiniti.
Apri Dashboard nella console Google Cloud .
Nella scheda Elenco dashboard, apri la dashboard
GCE VM Lifecycle Events Monitoring.Seleziona la VM dal menu a discesa Nome.
Restringi la serie temporale a un periodo di tempo pertinente.
Per altri modi per filtrare la dashboard, vedi Aggiungere un filtro temporaneo.
La dashboard contiene due grafici che mostrano una cronologia degli eventi di sistema e delle attività dell'amministratore che si verificano in un'istanza:
Il grafico Cronologia del ciclo di vita della VM mostra quanto segue:
- La metrica
compute.googleapis.com/instance/uptimeche indica se la VM era in esecuzione in un determinato momento, dove 1 indica che è attiva e 0 che è inattiva. Tieni presente che questa metrica riflette la disponibilità come risultato dell'attività utente e degli eventi di sistema e non è un'indicazione dello SLA di Compute Engine. - La metrica basata su log
vm-lifecycle-eventsper conteggiare il numero di azioni del ciclo di vita, comestopostart, eseguite sull'istanza in un determinato momento
- La metrica
Il grafico Eventi mostra la stessa metrica basata sui log
vm-lifecycle-events, ma in una visualizzazione ingrandita per una maggiore leggibilità. Tieni presente che, sebbene gli assi X siano allineati, i colori non sono sincronizzati tra i due grafici.
Indagine sull'arresto collettivo delle VM nei progetti
Compute Engine può arrestare più VM collegate a un progetto host del VPC condiviso, se la fatturazione del progetto host del VPC condiviso è inattiva o disabilitata.
Per determinare se le tue VM sono state arrestate da una richiesta di arresto collettivo, cerca le operazioni di arresto avviate da
cloud-cluster-manager@prod.google.com.L'avvio di un'istanza interessata restituisce un errore simile al seguente:
Starting instance(s) INSTANCE_NAME...failed. ERROR: (gcloud.compute.instances.start) The default network interface [nic0] is frozen.Per risolvere il problema, segui questi passaggi:
Identifica la VPC condiviso utilizzata dalle VM utilizzando il comando
gcloud compute instances describe:gcloud compute instances describe VM_NAME \ --format="flattened(networkInterfaces[].network)"
L'output è simile al seguente:
networkInterfaces[0].network: https://www.googleapis.com/compute/v1/projects/SHARED_VPC_PROJECT/global/networks/FROZEN_NETWORK
Verifica nel progetto host del VPC condiviso se la fatturazione è stata disabilitata.
resource.type="project" protoPayload.request.@type="type.googleapis.com/google.internal.cloudbilling.billingaccount.v1.DisableResourceBillingRequest" protoPayload.response.resourceBillingInfo.billingAccountAssignmentType="DISABLED"Se applicabile, abilita la fatturazione per il progetto host.
Per evitare che il problema si ripresenti, leggi Proteggere il collegamento tra un progetto e il relativo account di fatturazione.
Salvo quando diversamente specificato, i contenuti di questa pagina sono concessi in base alla licenza Creative Commons Attribution 4.0, mentre gli esempi di codice sono concessi in base alla licenza Apache 2.0. Per ulteriori dettagli, consulta le norme del sito di Google Developers. Java è un marchio registrato di Oracle e/o delle sue consociate.
Ultimo aggiornamento 2025-09-11 UTC.
-