Este documento descreve as causas comuns de encerramentos e reinícios inesperados das instâncias do Compute Engine e como evitá-los.
Os encerramentos e os reinícios de instâncias podem ser causados por eventos do sistema ou atividades administrativas. Os encerramentos e os reinícios de eventos do sistema são gerados pelos sistemas Google ou pelo sistema operativo das suas instâncias. Os encerramentos e os reinícios da atividade de administrador são gerados por uma chamada API gerada por um utilizador ou uma conta de serviço. Todos os encerramentos e reinícios são registados, exceto os reinícios iniciados a partir da instância.
Antes de começar
-
Se ainda não o tiver feito, configure a autenticação.
A autenticação valida a sua identidade para aceder a Google Cloud serviços e APIs. Para executar código ou exemplos a partir de um ambiente de desenvolvimento local, pode autenticar-se no Compute Engine selecionando uma das seguintes opções:
Select the tab for how you plan to use the samples on this page:
Console
When you use the Google Cloud console to access Google Cloud services and APIs, you don't need to set up authentication.
gcloud
-
Instale a CLI Google Cloud. Após a instalação, inicialize a CLI gcloud executando o seguinte comando:
gcloud initSe estiver a usar um fornecedor de identidade (IdP) externo, primeiro tem de iniciar sessão na CLI gcloud com a sua identidade federada.
- Set a default region and zone.
Diagnosticar encerramentos e reinícios de instâncias
Para diagnosticar a causa do encerramento ou do reinício espontâneo de uma instância, tem de consultar os registos da instância. Para identificar rapidamente a causa de futuros encerramentos ou reinícios de VMs, crie um painel de controlo que contenha os registos. Depois de consultar os registos, reveja os campos
methodeprincipalEmailpara determinar que evento e que utilizador ou serviço iniciou o encerramento ou o reinício.Consultar registos de auditoria do Cloud
Consulte os registos de auditoria na nuvem para apresentar uma lista de eventos do sistema e atividades administrativas que podem ter causado o encerramento ou o reinício.
Consola
Na Google Cloud consola, aceda à página Explorador de registos.
No campo Consulta, introduza a seguinte consulta:
resource.type="gce_instance" "VM_NAME" logName:("logs/cloudaudit.googleapis.com%2Fsystem_event" OR "logs/cloudaudit.googleapis.com%2Factivity")Substitua
VM_NAMEpelo nome da VM que foi encerrada ou reiniciada.Se o evento que procura ocorreu há mais de uma hora, defina um intervalo de tempo personalizado clicando no símbolo de relógio e introduzindo um intervalo personalizado.
Clique em Executar consulta. Os resultados são apresentados na secção Resultados da consulta.
Clique na seta de expansão junto a cada resultado para mostrar informações detalhadas.
Consulte o artigo Rever registos de auditoria do Cloud para saber mais acerca dos campos
methodeprincipalEmailassociados a encerramentos e reinícios, e o que pode fazer para os evitar.
gcloud
Veja os registos de auditoria do Cloud com o comando
gcloud logging read:gcloud logging read --freshness=TIME 'resource.type="gce_instance" "VM_NAME" logName:("logs/cloudaudit.googleapis.com%2Fsystem_event" OR "logs/cloudaudit.googleapis.com%2Factivity")'Substitua o seguinte:
TIME: o período durante o qual quer consultar. Por exemplo,1hconsulta as entradas de registo na última hora. Para obter informações sobre os formatos de data e hora, consulte o artigo gcloud topic datetimes.VM_NAME: o nome da VM que foi encerrada ou reiniciada.
Os resultados são apresentados.
Consulte o artigo Rever registos de auditoria do Cloud para saber mais acerca dos campos
methodeprincipalEmailassociados a encerramentos e reinícios, e o que pode fazer para os evitar.
Rever registos de auditoria do Cloud
Reveja os campos
methodeprincipalEmaildos registos de auditoria na nuvem para determinar por que motivo a sua VM foi encerrada ou reiniciada.Reveja os campos
methoddos registos de auditoria da nuvem e compare-os com os métodos indicados na tabela seguinte.Método Tipo de encerramento Descrição compute.instances.repair.recreateInstanceEvento do sistema Se a sua VM pertencer a um grupo de instâncias gerido (MIG), o MIG recria a VM se o estado da VM mudar de
RUNNINGe o MIG não tiver iniciado a alteração do estado.As alterações ao estado da instância que não são iniciadas pelo MIG incluem:
- Falhas de hardware.
- Terminar uma instância preemptiva.
- Manutenção da infraestrutura eventos quando a instância de VM não está definida para migração em direto.
- Eliminar uma instância de MIG através de um dos seguintes métodos:
- O método da API
instances.delete - O comando
gcloud compute instances delete
- O método da API
compute.instances.hostErrorEvento do sistema Um erro de anfitrião (
compute.instances.hostError) significa que ocorreu um problema de hardware ou software na máquina física ou na infraestrutura do centro de dados que aloja a sua instância de computação, o que fez com que a instância falhasse. Um erro do anfitrião que envolva uma falha de hardware total ou outros problemas de hardware pode impedir a migração em direto da sua instância. Se a sua instância estiver definida para ser reiniciada automaticamente, que é a predefinição, o Compute Engine reinicia a instância, normalmente, no prazo de três minutos a partir do momento em que o erro foi detetado. Consoante o problema, o reinício pode demorar até 5,5 minutos.Ocasionalmente, uma instância de computação pode deixar de responder antes de ser sinalizado um erro do anfitrião. Pode reduzir o tempo que o Compute Engine aguarda para reiniciar ou terminar a instância ao definir o limite de tempo de recuperação de erros do anfitrião. Para mais informações, consulte o artigo Defina políticas de disponibilidade.
As falhas físicas de hardware e software podem ocorrer ocasionalmente, mas são raras. Para proteger as suas aplicações e serviços destes eventos do sistema potencialmente disruptivos, reveja os seguintes recursos:
- Conceber sistemas robustos
- Padrões para apps escaláveis e resilientes
- Criar grupos de instâncias geridas
A Google também oferece serviços geridos, como o App Engine e o ambiente flexível do App Engine.
compute.instances.automaticRestartEvento do sistema Este evento ocorre após um evento
hostErrorou um eventoterminateOnHostMaintenancese a política de manutenção do anfitrião da sua VM estiver definida comotrue.automaticRestartNos registos, uma entrada de registohostErrorouterminateOnHostMaintenanceprecede este registo.Se quiser alterar a política de manutenção do anfitrião da sua VM, consulte o artigo Atualizar opções de uma instância.
compute.instances.guestTerminateEvento do sistema O sistema operativo da VM iniciou o encerramento. compute.instances.terminateOnHostMaintenanceEvento do sistema Se definir a política de manutenção do anfitrião da VM como
TERMINATE, o Compute Engine para a VM quando existir um evento de manutenção em que a Google tem de mover a VM para outro anfitrião.onHostMaintenanceSe quiser alterar a
onHostMaintenancepolítica da VM, consulte o artigo Atualizar opções de uma instância.compute.instances.preemptedEvento do sistema O Compute Engine anulou a sua VM do Spot ou VM anulável antiga:
- Quando o Compute Engine antecipa uma VM do Spot, o Compute Engine para ou elimina a VM do Spot com base na respetiva ação de encerramento. As VMs de spot não têm um tempo de execução máximo.
- Quando o Compute Engine antecipa uma VM antecipável, o Compute Engine para a VM após um tempo de execução máximo de 24 horas. Para evitar estas limitações, use VMs de spot.
As VMs de capacidade instantânea e as VMs preemptíveis são capacidade excessiva do Compute Engine, pelo que o Compute Engine pode preemptá-las em qualquer altura que essa capacidade seja necessária noutro local. Pode ajudar a mitigar os efeitos da preempção seguindo as práticas recomendadas. Em alternativa, se precisar de VMs com tempos de execução controlados pelo utilizador, crie VMs padrão em vez disso.
compute.instances.stopAtividade do administrador Um utilizador ou uma conta de serviço parou a sua VM.
Continue para o passo seguinte para identificar o utilizador ou a conta de serviço que parou a sua VM. Para obter informações sobre como reiniciar a VM, consulte o artigo Reiniciar uma instância parada.
compute.instances.deleteAtividade do administrador ou evento do sistema Um utilizador ou uma conta de serviço eliminou a sua VM, ou a VM foi configurada para ser eliminada automaticamente.
Especificamente, um registo do método
compute.instances.deletepode indicar qualquer um dos seguintes pedidos para a sua VM:- Os pedidos de um utilizador ou de uma conta de serviço para eliminar diretamente a sua VM são
indicados apenas por um método
compute.instances.deletedo utilizador ou da conta de serviço. Os pedidos que eliminam automaticamente a sua VM são indicados por um método
compute.instances.deletedesystem@google.com, mas o método que explica a causa da eliminação automática pode ou não aparecer nos registos de auditoria do Cloud.Por exemplo, se uma VM Spot estiver configurada para ser eliminada automaticamente durante a preempção e for preempted, vê um método
compute.instances.deletedesystem@google.com, mas também pode ver ou não um métodocompute.instances.preempted.Os pedidos à VM que ocorreram pouco antes ou depois de um método
compute.instances.deletepodem ou não aparecer nos registos de auditoria da nuvem.Por exemplo, se uma VM for interrompida devido à manutenção do anfitrião pouco antes de ser eliminada, vê um método
compute.instances.delete, mas também pode ver ou não um métodocompute.instances.terminateOnHostMaintenance.
Continue para o passo seguinte para identificar o utilizador ou a conta de serviço que eliminou a sua VM. Para obter informações sobre como criar uma nova VM, consulte o artigo Criar e iniciar uma VM.
compute.instances.insertAtividade do administrador A VM foi criada por um utilizador ou uma conta de serviço.
Continue para o passo seguinte para identificar o utilizador ou a conta de serviço que criou a sua VM. Para obter informações sobre como criar uma nova VM, consulte o artigo Criar e iniciar uma VM.
compute.instances.resetAtividade do administrador Um utilizador ou uma conta de serviço repôs a sua VM.
Continue para o passo seguinte para identificar o utilizador ou a conta de serviço que parou a sua VM.
Reveja os campos
principalEmaildos registos de auditoria na nuvem para identificar o utilizador ou o serviço que iniciou o encerramento ou o reinício. A tabela seguinte inclui serviços geridos pela Google comuns que iniciam encerramentos ou reinícios.Se um utilizador tiver acionado o encerramento ou o reinício, o respetivo endereço de email é apresentado no campo
principalEmail. Por exemplo,cloudysanfrancisco@gmail.com.Os administradores podem impedir que os utilizadores alterem o estado das VMs do projeto alterando as autorizações de gestão de identidades e acessos nas contas de utilizador. Para mais informações, consulte Conceder, alterar e revogar o acesso a recursos.
Monitorize eventos de ciclo de vida de VMs
Pode monitorizar eventos do ciclo de vida da VM (incluindo encerramentos, reinícios e erros do anfitrião) criando um painel de controlo do Cloud Monitoring.
Este painel de controlo permite-lhe visualizar os eventos do sistema e as atividades do administrador descritos mais detalhadamente na secção de revisão dos registos de auditoria deste documento.
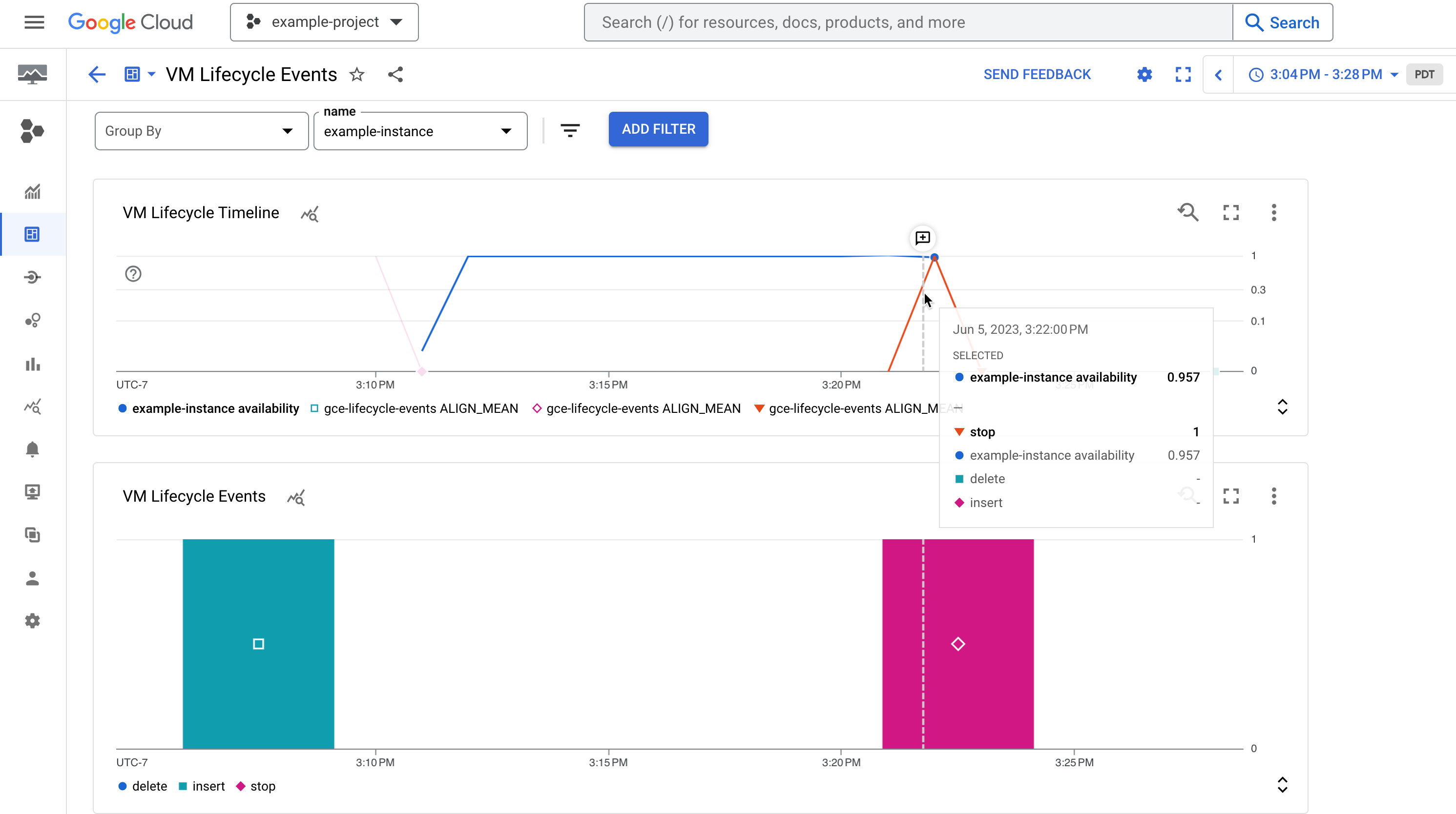 Figura 1. Um painel de controlo de exemplo que mostra a disponibilidade de uma instância e os respetivos eventos do ciclo de vida, como uma instância parada.
Figura 1. Um painel de controlo de exemplo que mostra a disponibilidade de uma instância e os respetivos eventos do ciclo de vida, como uma instância parada.Crie uma métrica baseada em registos
Para captar eventos do ciclo de vida da VM, crie uma métrica baseada em registos definida pelo utilizador. Esta métrica usa os registos de auditoria para manter a contagem do número de vezes que ocorreu um evento específico do ciclo de vida da VM.
Para obter as autorizações de que precisa para criar a métrica, peça ao seu administrador que lhe conceda a função de IAM de escritor de registos (
roles/logging.logWriter) no projeto. Para mais informações sobre a atribuição de funções, consulte o artigo Faça a gestão do acesso a projetos, pastas e organizações.Também pode conseguir as autorizações necessárias através de funções personalizadas ou outras funções predefinidas.
Crie uma métrica baseada em registos definida pelo utilizador fazendo o seguinte:
Na Google Cloud consola, aceda à página Métricas baseadas em registos.
Clique em Criar métrica.
Na secção Tipo de métrica, faça o seguinte:
- Selecione
Counter. - Mantenha a Distribuição na predefinição de não selecionada.
Na secção Detalhes, introduza as seguintes informações:
- Nome da métrica baseada em registos:
vm-lifecycle-events. Tem de usar este nome exato para que o painel de controlo funcione corretamente. - Descrição: opcional. Introduza uma descrição para esta métrica.
- Unidades:
1
Na secção Seleção de filtros, especifique o seguinte:
- No menu Selecionar projeto ou contentor de registos, selecione: Registos do projeto
- Em Criar filtro, introduza:
resource.type = "gce_instance" AND log_id("cloudaudit.googleapis.com/activity") OR log_id("cloudaudit.googleapis.com/system_event") operation.first="true"
Na secção Etiquetas, clique em Adicionar etiqueta.
Especifique o seguinte:
- Nome da etiqueta:
method - Tipo de etiqueta:
STRING - Nome do campo:
protoPayload.methodName - Expressão regular:
(recreateInstance|hostError|automaticRestart|guestTerminate|terminateOnHostMaintenance|preempted|insert|stop|delete|reset|start)
- Nome da etiqueta:
Clique em Concluído
Clique em Criar métrica.
Use o painel de controlo
Não são apresentados dados no painel de controlo até que uma instância tenha um evento do sistema ou uma atividade de administrador. Para testar se o painel de controlo funciona, execute uma atividade de administrador, como uma operação
stopestart:- Realize uma operação
stopestartem qualquer instância existente ou crie uma nova VM para fins de teste.
Para receber as autorizações de que precisa para usar o painel de controlo, peça ao seu administrador para lhe conceder a função de IAM Visualizador do painel de controlo de monitorização (
roles/monitoring.dashboardViewer) no projeto. Para mais informações sobre a atribuição de funções, consulte o artigo Faça a gestão do acesso a projetos, pastas e organizações.Também pode conseguir as autorizações necessárias através de funções personalizadas ou outras funções predefinidas.
Abra Painéis de controlo na Google Cloud consola.
No separador Lista de painéis de controlo, abra o painel de controlo
GCE VM Lifecycle Events Monitoring.Selecione a VM no menu pendente Nome.
Restrinja a série cronológica a um intervalo de tempo relevante.
Para ver mais formas de filtrar o painel de controlo, consulte o artigo Adicione um filtro temporário.
O painel de controlo contém dois gráficos que apresentam uma cronologia dos eventos do sistema e das atividades do administrador que ocorrem numa instância:
O gráfico Linha cronológica do ciclo de vida da VM apresenta o seguinte:
- A métrica
compute.googleapis.com/instance/uptimeque indica se a VM estava em execução num determinado momento, em que 1 significa em funcionamento e 0 significa inativo. Tenha em atenção que esta métrica reflete a disponibilidade como resultado da atividade do utilizador e dos eventos do sistema, e não é uma indicação do ANS do Compute Engine. - A métrica baseada em registos para contar o número de ações do ciclo de vida, como
stopoustart, que foram realizadas na instância num determinado momentovm-lifecycle-events
- A métrica
O gráfico Eventos mostra a mesma métrica baseada em registos, mas numa vista ampliada para facilitar a leitura.
vm-lifecycle-eventsTenha em atenção que, embora os eixos X estejam alinhados, as cores não estão sincronizadas entre os dois gráficos.
Investigação do encerramento em massa de VMs em vários projetos
O Compute Engine pode encerrar várias VMs ligadas a um projeto anfitrião de VPC partilhada se a faturação do projeto anfitrião de VPC partilhada estiver inativa ou desativada.
Para determinar se as suas VMs foram encerradas por um pedido de encerramento em massa, procure operações de paragem iniciadas por
cloud-cluster-manager@prod.google.com.O início de uma instância afetada devolve um erro semelhante ao seguinte:
Starting instance(s) INSTANCE_NAME...failed. ERROR: (gcloud.compute.instances.start) The default network interface [nic0] is frozen.Para resolver este problema, faça o seguinte:
Identifique a VPC partilhada usada pelas VMs através do comando
gcloud compute instances describe:gcloud compute instances describe VM_NAME \ --format="flattened(networkInterfaces[].network)"
O resultado é semelhante ao seguinte:
networkInterfaces[0].network: https://www.googleapis.com/compute/v1/projects/SHARED_VPC_PROJECT/global/networks/FROZEN_NETWORK
Verifique no projeto anfitrião da VPC partilhada se a faturação foi desativada.
resource.type="project" protoPayload.request.@type="type.googleapis.com/google.internal.cloudbilling.billingaccount.v1.DisableResourceBillingRequest" protoPayload.response.resourceBillingInfo.billingAccountAssignmentType="DISABLED"Se aplicável, ative a faturação no projeto anfitrião.
Para ajudar a evitar que este problema se repita, leia o artigo Proteja a associação entre um projeto e a respetiva conta de faturação.
Exceto em caso de indicação contrária, o conteúdo desta página é licenciado de acordo com a Licença de atribuição 4.0 do Creative Commons, e as amostras de código são licenciadas de acordo com a Licença Apache 2.0. Para mais detalhes, consulte as políticas do site do Google Developers. Java é uma marca registrada da Oracle e/ou afiliadas.
Última atualização 2025-09-19 UTC.
-