本文說明單一用戶群節點。如要瞭解如何在單一用戶群節點上佈建 VM,請參閱「在單一用戶群節點上佈建 VM」。
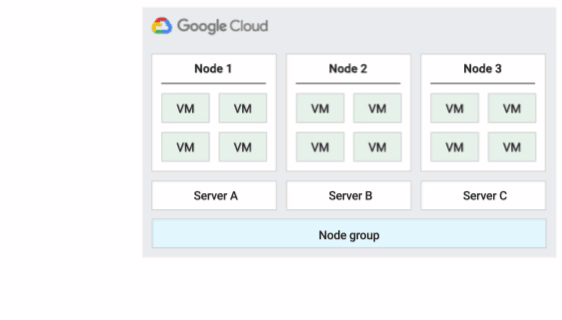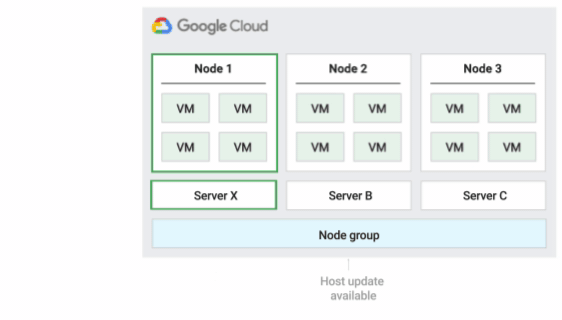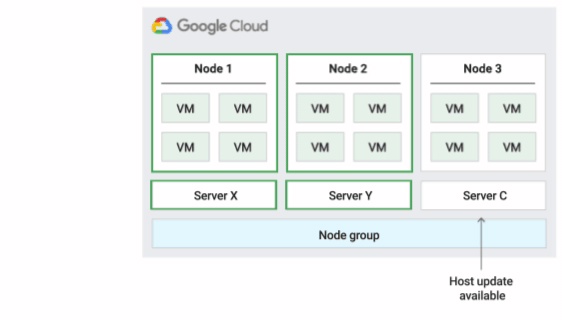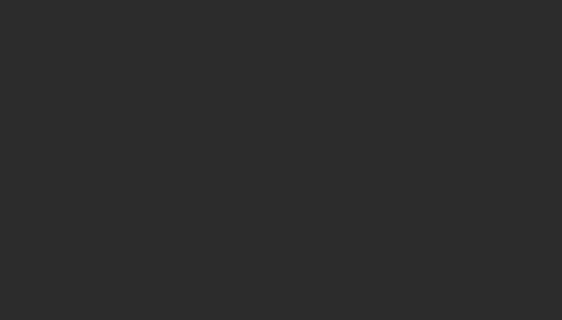
單一用戶群可讓您專屬存取單一用戶群節點,也就是專門用於託管專案 VM 的實體 Compute Engine 伺服器。使用單一用戶群節點,將您的 VM 與其他專案中的 VM 隔開,或將您的 VM 聚集在同一個託管硬體中,如下圖所示。您也可以建立單一租戶節點群組,並指定要與其他專案或整個機構共用。

在單一租戶節點上執行的 VM 可以使用與其他 VM 相同的 Compute Engine 功能,包括透明排程和區塊儲存空間,但會增加一層硬體隔離。為讓您完全掌控實體伺服器上的 VM,每個單一租戶節點都會與支援該節點的實體伺服器維持一對一對應關係。
在單一專屬節點中,您可以在各種大小的機器類型上佈建多個 VM,有效運用專屬主機硬體的基礎資源。此外,如果您選擇不與其他專案共用主機硬體,就能以實體方式區隔特定工作負載與其他工作負載或 VM,滿足安全或法規遵循需求。如果工作負載只需要暫時單獨租用,您可以視需要修改 VM 租用。
單一用戶群節點可協助您滿足自備授權 (BYOL) 專屬硬體需求,適用於需要每核心或每處理器授權的案例。使用單一租戶節點時,您可以查看部分基礎硬體,追蹤核心和處理器用量。如要追蹤這項用量,Compute Engine 會回報 VM 排程所在的實體伺服器 ID。接著,您可以使用 Cloud Logging 查看 VM 的歷來伺服器用量。
如要盡量發揮主機硬體效能,請採取下列做法:
您可以透過可設定的主機維護政策,控管單一租戶 VM 在主機維護期間的行為。您可以指定維護作業的發生時間,以及 VM 是否要與特定實體伺服器維持相依性,或是移至節點群組中的其他單一租戶節點。
工作負載考量事項
下列類型的工作負載可能適合使用單一租戶節點:
有效能需求的遊戲工作負載
有安全防護和法規遵循要求的金融或醫療保健工作負載
有授權需求的 Windows 工作負載
機器學習、資料處理或圖片算繪工作負載。如要執行這類工作負載,請考慮預留 GPU。
需要提高每秒 I/O 作業數 (IOPS) 和縮短延遲時間的工作負載,或是使用快取、處理空間或低價值資料等形式的暫時儲存空間的工作負載。對於這些工作負載,請考慮預留本機 SSD 磁碟。
節點範本
節點範本是區域資源,可定義節點群組中每個節點的屬性。從節點範本建立節點群組時,節點範本的屬性會不可變動地複製到節點群組中的每個節點。
建立節點範本時,必須指定節點類型。建立節點範本時,您可以選擇指定節點親和性標籤。您只能在節點範本上指定節點相依性標籤。您無法在節點群組中指定節點相依性標籤。
節點類型
設定節點範本時,請指定要套用至節點範本所建立節點群組中所有節點的節點類型。節點範本參照的單一用戶群節點類型,會指定使用該範本的節點群組中,所建立節點的 vCPU 核心總數和記憶體總容量。舉例來說,n2-node-80-640 節點類型具備 80 個 vCPU 和 640 GB 記憶體。
新增至單一租戶節點的 VM 必須與您在節點範本中指定的節點類型具有相同的機器類型。舉例來說,n2
單一租戶節點類型僅與使用n2
機器類型建立的 VM 相容。您可以將 VM 新增至單一用戶群節點,直到 vCPU 或記憶體總量超過節點容量為止。
使用節點範本建立節點群組時,節點群組中的每個節點都會沿用節點範本的節點類型規格。節點類型會套用至節點群組中的每個節點,而不是統一套用至群組中的所有節點。因此,如果您建立的節點群組中包含兩個 n2-node-80-640 節點類型節點,則每個節點會各自分配 80 個 vCPU 和 640 GB 的記憶體。
視工作負載需求而定,您可能會在節點中建立多個較小的 VM,這些 VM 執行於大小各異的機器類型,包括預先定義的機器類型、自訂機器類型,以及具備擴充記憶體的機器類型。當節點滿載,即無法在該節點上排入額外的 VM。
下表列出可用的節點類型。如要查看專案可用的節點類型清單,請執行 gcloud compute sole-tenancy node-types list 指令,或建立 nodeTypes.list REST 要求。
| 節點類型 | 處理器 | vCPU | GB | vCPU:GB | 通訊端 | 核心:插槽 | 核心總數 | 允許的 VM 數量上限 |
|---|---|---|---|---|---|---|---|---|
c2-node-60-240 |
Cascade Lake | 60 | 240 | 1:4 | 2 | 18 | 36 | 15 |
c3-node-176-352 |
Sapphire Rapids | 176 | 352 | 1:2 | 2 | 48 | 96 | 44 |
c3-node-176-704 |
Sapphire Rapids | 176 | 704 | 1:4 | 2 | 48 | 96 | 44 |
c3-node-176-704-lssd |
Sapphire Rapids | 176 | 704 | 1:4 | 2 | 48 | 96 | 40 |
c3-node-176-1408 |
Sapphire Rapids | 176 | 1408 | 1:8 | 2 | 48 | 96 | 44 |
c3d-node-360-708 |
AMD EPYC Genoa | 360 | 708 | 1:2 | 2 | 96 | 192 | 34 |
c3d-node-360-1440 |
AMD EPYC Genoa | 360 | 1440 | 1:4 | 2 | 96 | 192 | 40 |
c3d-node-360-2880 |
AMD EPYC Genoa | 360 | 2880 | 1:8 | 2 | 96 | 192 | 40 |
c4-node-192-384 |
Emerald Rapids | 192 | 384 | 1:2 | 2 | 60 | 120 | 40 |
c4-node-192-720 |
Emerald Rapids | 192 | 720 | 1:3.75 | 2 | 60 | 120 | 30 |
c4-node-192-1488 |
Emerald Rapids | 192 | 1,488 | 1:7.75 | 2 | 60 | 120 | 30 |
c4a-node-72-144 |
Google Axion | 72 | 144 | 1:2 | 1 | 80 | 80 | 22 |
c4a-node-72-288 |
Google Axion | 72 | 288 | 1:4 | 1 | 80 | 80 | 22 |
c4a-node-72-576 |
Google Axion | 72 | 576 | 1:8 | 1 | 80 | 80 | 36 |
c4d-node-384-720 |
AMD EPYC Turin | 384 | 744 | 1:2 | 2 | 96 | 192 | 24 |
c4d-node-384-1488 |
AMD EPYC Turin | 384 | 1488 | 1:4 | 2 | 96 | 192 | 25 |
c4d-node-384-3024 |
AMD EPYC Turin | 384 | 3024 | 1:8 | 2 | 96 | 192 | 25 |
g2-node-96-384 |
Cascade Lake | 96 | 384 | 1:4 | 2 | 28 | 56 | 8 |
g2-node-96-432 |
Cascade Lake | 96 | 432 | 1:4.5 | 2 | 28 | 56 | 8 |
h3-node-88-352 |
Sapphire Rapids | 88 | 352 | 1:4 | 2 | 48 | 96 | 1 |
m1-node-96-1433 |
Skylake | 96 | 1433 | 1:14.93 | 2 | 28 | 56 | 1 |
m1-node-160-3844 |
Broadwell E7 | 160 | 3844 | 1:24 | 4 | 22 | 88 | 4 |
m2-node-416-8832 |
Cascade Lake | 416 | 8832 | 1:21.23 | 8 | 28 | 224 | 1 |
m2-node-416-11776 |
Cascade Lake | 416 | 11776 | 1:28.31 | 8 | 28 | 224 | 2 |
m3-node-128-1952 |
Ice Lake | 128 | 1952 | 1:15.25 | 2 | 36 | 72 | 2 |
m3-node-128-3904 |
Ice Lake | 128 | 3904 | 1:30.5 | 2 | 36 | 72 | 2 |
m4-node-224-2976 |
Emerald Rapids | 224 | 2976 | 1:13.3 | 2 | 112 | 224 | 1 |
m4-node-224-5952 |
Emerald Rapids | 224 | 5952 | 1:26.7 | 2 | 112 | 224 | 1 |
n1-node-96-624 |
Skylake | 96 | 624 | 1:6.5 | 2 | 28 | 56 | 96 |
n2-node-80-640 |
Cascade Lake | 80 | 640 | 1:8 | 2 | 24 | 48 | 80 |
n2-node-128-864 |
Ice Lake | 128 | 864 | 1:6.75 | 2 | 36 | 72 | 128 |
n2d-node-224-896 |
AMD EPYC Rome | 224 | 896 | 1:4 | 2 | 64 | 128 | 112 |
n2d-node-224-1792 |
AMD EPYC Milan | 224 | 1792 | 1:8 | 2 | 64 | 128 | 112 |
n4-node-224-1372 |
Emerald Rapids | 224 | 1372 | 1:6 | 2 | 60 | 120 | 90 |
如要瞭解這些節點類型的價格,請參閱單一用戶群節點計價方式。
所有節點都可讓您排定不同形狀的 VM。節點 n 類型為一般用途節點,您可以在這類節點上排定自訂機器類型執行個體。如需節點類型選擇建議,請參閱機器類型建議。
如要瞭解效能,請參閱「CPU 平台」。
節點群組和 VM 佈建
單一租戶節點範本會定義節點群組的屬性,您必須先建立節點範本,才能在 Google Cloud區域中建立節點群組。建立群組時,請為節點群組中的 VM 指定主機維護政策、節點群組的節點數量,以及是否與其他專案或整個機構共用。
節點群組可以有零或多個節點;舉例來說,如果不需要在群組中的節點上執行任何 VM,您可以將節點群組中的節點數量減少至零,也可以啟用節點群組自動配置器,自動管理節點群組的大小。
在單一用戶群節點上佈建 VM 之前,您必須先建立單一用戶群節點群組。節點群組是特定可用區中性質相同的單一用戶節點集合。節點群組可包含多個來自相同機器系列的 VM,這些 VM 執行於各種大小的機器類型,只要機器類型有 2 個以上的 vCPU 即可。
建立節點群組時,請啟用自動調度資源,讓群組大小自動調整,以滿足工作負載需求。如果工作負載需求是靜態的,您可以手動指定節點群組的大小。
建立節點群組後,您可以在群組或群組內的特定節點上佈建 VM。如要進一步控管,請使用節點相依性標籤,在任何具有相符相依性標籤的節點上排定 VM。
在節點群組上佈建 VM,並視需要指派親和性標籤,在特定節點群組或節點上佈建 VM 後,請考慮為資源加上標籤,方便管理 VM。標籤是鍵/值組合,可協助您分類 VM,以便查看帳單等匯總資訊。舉例來說,您可以使用標籤標示 VM 的角色、租戶、授權類型或位置。
主機維護政策
根據授權情境和工作負載,您可能需要限制 VM 使用的實體核心數量。您選擇的主機維護政策可能取決於授權或法規遵循需求,或者您可能想選擇可限制實體伺服器用量的政策。有了這些政策,您的 VM 仍會保留在專屬硬體上。
在單一租戶節點上排程 VM 時,您可以從下列三種不同的主機維護政策選項中選擇,決定 Compute Engine 在主機事件期間 (大約每 4 到 6 週發生一次) 即時遷移 VM 的方式和時機。維護期間,Compute Engine 會將主機上的所有 VM 即時遷移至其他專屬節點,但有時可能會將 VM 分成較小的群組,並將每個較小的 VM 群組即時遷移至不同的專屬節點。
預設主機維護政策
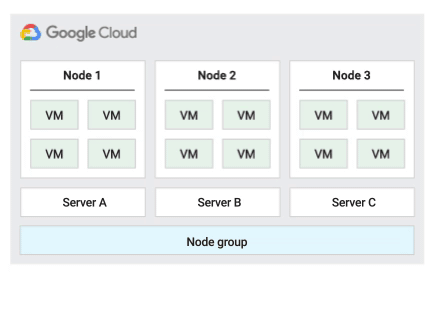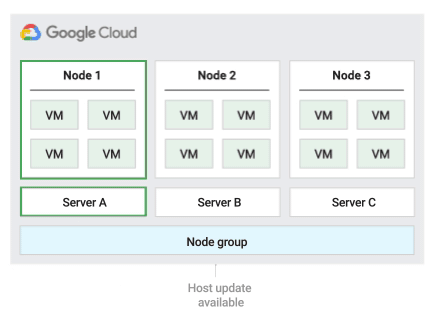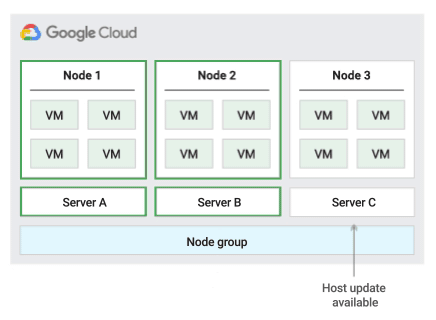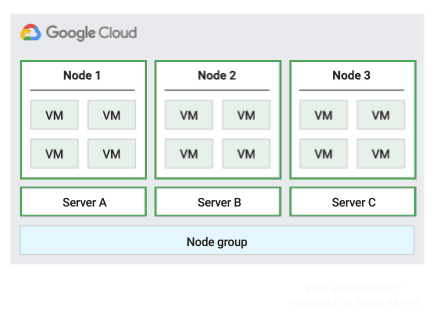
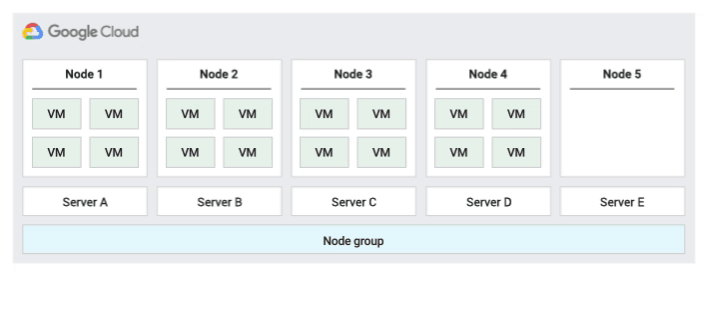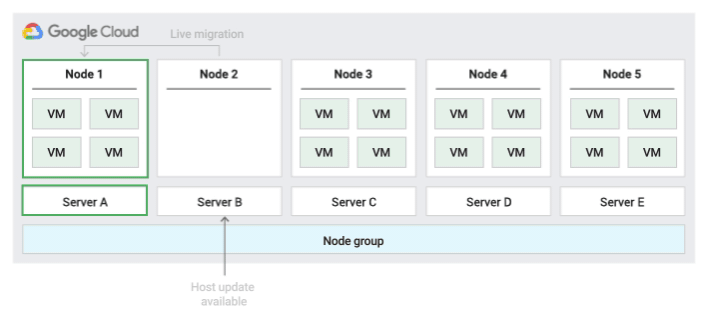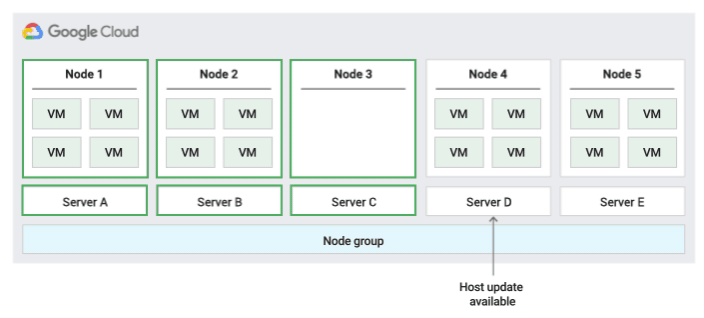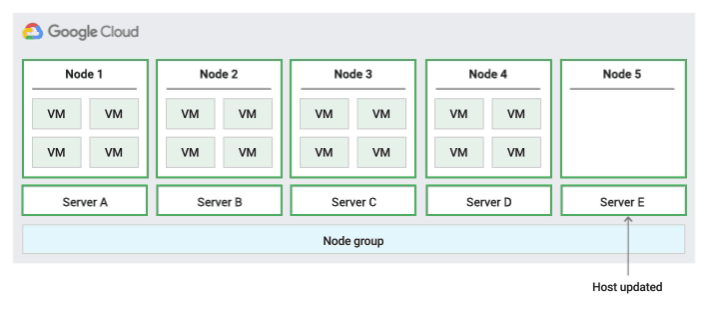
這是預設的主機維護政策,如果節點群組設定了這項政策,VM 會遵循非單一用戶群 VM 的傳統維護行為。也就是說,視 VM 主機的維護設定而定,VM 會在主機維護事件發生前即時遷移至節點群組中的新單一用戶群節點,而這個新節點只會執行客戶的 VM。
這項政策最適合需要主機事件期間即時遷移的單一使用者或單一裝置授權。這項設定不會限制 VM 遷移至固定實體伺服器集區,建議用於沒有實體伺服器需求,且不需要現有授權的一般工作負載。
由於 VM 會遷移至任何伺服器,且不會考量現有伺服器與這項政策的親和性,因此這項政策不適合用於需要盡量減少主機事件期間實體核心使用量的案例。
下圖為「預設」主機維護政策的動畫。
就地重新啟動主機維護政策
使用這項主機維護政策時,Compute Engine 會在主機事件期間停止 VM,然後在主機事件結束後,在同一部實體伺服器上重新啟動 VM。使用這項政策時,您必須將 VM 的主機維護設定設為 TERMINATE。
這項政策最適合容錯的工作負載,這類工作負載在主機事件期間可能會停機約一小時;此外,這項政策也適合必須留在同一部實體伺服器上的工作負載、不需要即時遷移的工作負載,或是授權是按照實體核心或處理器數量計算的工作負載。
有了這項政策,執行個體就能使用 node-name、node-group-name 或節點相依性標籤指派給節點群組。
下圖顯示「就地重新啟動」維護政策的動畫。
在節點群組內遷移主機維護政策
使用這項主機維護政策時,Compute Engine 會在主機事件期間,即時遷移固定大小實體伺服器群組中的 VM,藉此限制 VM 使用的實體伺服器數量。
這項政策最適合高可用性工作負載,而且這類工作負載的授權是按照實體核心或處理器數量計算,因為採用這項主機維護政策時,群組中的每個單一用戶群節點都會固定在特定實體伺服器上,與允許 VM 遷移至任何伺服器的預設政策不同。
為確認即時遷移的容量,Compute Engine 會為您保留的每 20 個節點保留 1 個保留節點。下圖以動畫形式呈現「在節點群組內遷移」主機維護政策。
下表顯示 Compute Engine 會保留多少備用節點,取決於您為節點群組預留的節點數量。
| 群組中的節點總數 | 為即時遷移保留的保留節點 |
|---|---|
| 1 | 不適用。至少須預留 2 個節點。 |
| 2 至 20 | 1 |
| 21 至 40 | 2 |
| 41 至 60 歲 | 3 |
| 61 至 80 | 4 |
| 81 到 100 分 | 5 |
將執行個體固定至多個節點群組
在下列情況下,您可以使用node-group-name
親和性標籤將執行個體固定至多個節點群組:
- 您要釘選的執行個體使用預設主機維護政策 (遷移 VM 執行個體)。
- 要將執行個體釘選至的所有節點群組,其主機維護政策皆為「在節點群組中遷移」。如果嘗試將執行個體固定至具有不同主機維護政策的節點群組,作業會失敗並顯示錯誤。
舉例來說,如要將執行個體 test-node 固定至兩個節點群組 node-group1 和 node-group2,請確認下列事項:
test-node的主機維護政策為「遷移 VM 執行個體」。node-group1和node-group2的主機維護政策為「在節點群組內遷移」。
您無法使用相依性標籤 node-name 將執行個體指派給任何特定節點。只要為執行個體指派 node-group-name,而非 node-name,您就可以使用任何自訂節點相依性標籤。
維護期間
如果您管理的工作負載 (例如經過微調的資料庫) 可能會受到即時遷移的效能影響,那麼您可以在建立節點群組時指定維護期間,決定單一租戶節點群組的維護作業開始時間。節點群組建立後,就無法修改維護時間範圍。
維護期間是 4 小時的時間區塊,可用於指定 Google 對單一用戶群 VM 執行維護作業的時間。維護作業大約每 4 到 6 週執行一次。
維護期間會套用至單一租戶節點群組中的所有 VM,且只會指定維護作業的開始時間。我們無法保證維護作業會在維護期間完成,也無法保證維護作業的執行頻率。如果節點群組採用「在節點群組內遷移」主機維護政策,則不支援維護期間。
模擬主機維護事件
您可以模擬主機維護事件,測試在主機維護事件期間,單一租戶節點上執行的工作負載行為。這樣一來,您就能瞭解單一租戶 VM 的主機維護政策,對 VM 上執行的應用程式有何影響。
主機錯誤
如果主機發生罕見的重大硬體故障 (單一或多租戶),Compute Engine 會執行下列操作:
淘汰實體伺服器及其專屬 ID。
撤銷專案的實體伺服器存取權。
以具有新專屬 ID 的實體伺服器,取代故障的硬體。
將 VM 從故障的硬體移至替代節點。
如果已將受影響的 VM 設定為自動重新啟動,系統會重新啟動這些 VM。
節點相依性和反相依性
單一用戶群節點可確保您的 VM 不會與其他專案的 VM 共用主機,除非您使用共用的單一用戶群節點群組。使用共用單一租戶節點群組時,機構內的其他專案可以在相同主機上佈建 VM。不過,您可能仍想將數個工作負載聚集在相同的專屬節點上,或在不同節點上將工作負載彼此隔開。舉例來說,為符合部分法規遵循要求,您可能需要使用親和性標籤,將機密工作負載與非機密工作負載分開。
建立 VM 時,您可以指定節點相依性或反相依性,並參照一或多個節點相依性標籤,要求專屬租戶。建立節點範本時,您可以指定自訂節點親和性標籤,而 Compute Engine 會自動在每個節點上加入一些預設親和性標籤。建立 VM 時指定相依性,即可在特定節點或節點群組中的節點上,一併排定 VM。建立 VM 時指定反相依性,即可確保特定 VM 不會一起排定在同一節點或節點群組的節點上。
節點親和性標籤是分配給節點的鍵/值組合,並從節點範本繼承而來。相依性標籤可讓您:
- 控管個別 VM 執行個體指派給節點的方式。
- 控管如何將透過範本建立的 VM 執行個體 (例如代管執行個體群組建立的執行個體) 指派給節點。
- 將機密 VM 執行個體分組至特定節點或節點群組,與其他 VM 隔離。
預設相依性標籤
Compute Engine 會為每個節點指派下列預設相依性標籤:
- 節點群組名稱的標籤:
- 鍵:
compute.googleapis.com/node-group-name - 值:節點群組的名稱。
- 鍵:
- 節點名稱的標籤:
- 鍵:
compute.googleapis.com/node-name - 值:個別節點的名稱。
- 鍵:
- 節點群組共用專案的標籤:
- 鍵:
compute.googleapis.com/projects - 值:節點群組所屬專案的專案 ID。
- 鍵:
自訂相依性標籤
您可以在建立節點範本時,建立自訂節點親和性標籤。這些相依性標籤會指派給從節點範本建立的節點群組中所有節點。節點群組建立完成後,您就無法在節點群組的節點中新增更多自訂親和性標籤。
如要瞭解如何使用親和性標籤,請參閱「設定節點親和性」。
定價
為協助您盡量降低單一租戶節點的成本,Compute Engine 提供承諾使用折扣 (CUD) 和續用折扣 (SUD)。請注意,單一用戶群附加費只能套用彈性 CUD 和 SUD,無法套用依資源計算的 CUD。
由於系統已向您收取單一租戶節點的 vCPU 和記憶體費用,因此您在這些節點上建立 VM 時,不必再額外付費。
如果您佈建的單一租戶節點含有 GPU 或本機 SSD 磁碟,系統會針對您佈建的每個節點,收取所有 GPU 或本機 SSD 磁碟的費用。單一用戶群附加費只會根據您用於單一用戶群節點的 vCPU 和記憶體計算,不含 GPU 或本機 SSD 磁碟。
詳情請參閱單一租戶節點定價。
可用性
單一用戶群節點只在特定區域中提供。如要驗證高可用性,請在不同區域的單一用戶群節點上排程 VM。
在單一租戶節點上使用 GPU 或本機 SSD 磁碟之前,請確認您在保留資源的區域中,有足夠的 GPU 或本機 SSD 配額。
Compute Engine 支援
n1和g2單一租戶節點類型上的 GPU,這些類型位於支援 GPU 的區域。下表列出可附加至n1和g2節點的 GPU 類型,以及建立節點範本時必須附加的 GPU 數量。GPU 類型 GPU 數量 單一租戶節點類型 NVIDIA L4 8 g2NVIDIA P100 4 n1NVIDIA P4 4 n1NVIDIA T4 4 n1NVIDIA V100 8 n1Compute Engine 支援
n1、n2、n2d和g2單一租戶節點類型上的本機 SSD 磁碟,這些節點類型用於支援這些機器系列的區域。
限制
您無法將單一租戶 VM 與下列機型系列和類型搭配使用: T2D、 T2A、 E2、 C2D、 A2、 A3、 A4、 A4X、 G4 或 裸機執行個體。
單一租戶 VM 無法指定最低 CPU 平台。
如果 VM 指定了最低 CPU 平台,您就無法將 VM 遷移至單一租戶節點。如要將 VM 遷移至單一租戶節點,請將最低 CPU 平台規格設為自動,藉此移除該規格,然後更新 VM 的節點親和性標籤。
單一租戶節點不支援先占 VM 執行個體。
如要瞭解在單一租戶節點上使用本機 SSD 磁碟的限制,請參閱「本機 SSD 資料保存」一文。
如要瞭解使用 GPU 對即時遷移的影響,請參閱即時遷移的限制。
搭載 GPU 的專屬節點不支援沒有 GPU 的 VM。
只有 N1、N2、N2D 和 N4 單一租戶節點支援超額配置 CPU。
C3、C3D、C4、C4A、C4D 和 N4 VM 會根據單一租戶節點的基礎 NUMA 架構排程。在同一個節點上排定完整和子 NUMA VM 形狀,可能會導致片段化,也就是說,雖然多個較小的形狀加總起來的資源需求相同,但較大的形狀無法執行。
C3 和 C4 單一用戶群節點規定 VM 的 vCPU 與記憶體比例必須與節點類型相同,例如,您無法將
c3-standardVM 放在-highmem節點類型上。您無法更新運作中節點群組的維護政策。
後續步驟
瞭解如何建立、設定及使用單一用戶群節點。
瞭解如何超額配置單一用戶群 VM 的 CPU。
瞭解如何自備授權。