En este documento se describen los nodos de único cliente. Para obtener información sobre cómo aprovisionar máquinas virtuales en nodos de único cliente, consulta el artículo Aprovisionar máquinas virtuales en nodos de único cliente.
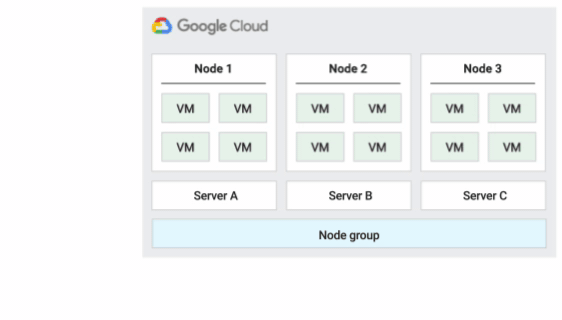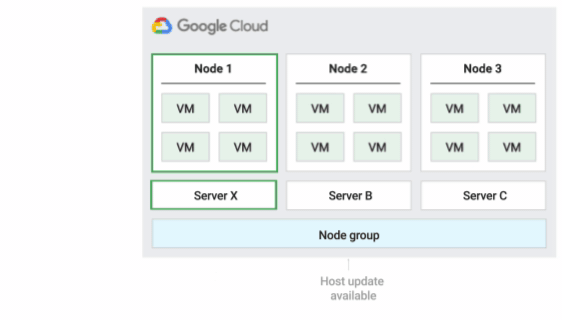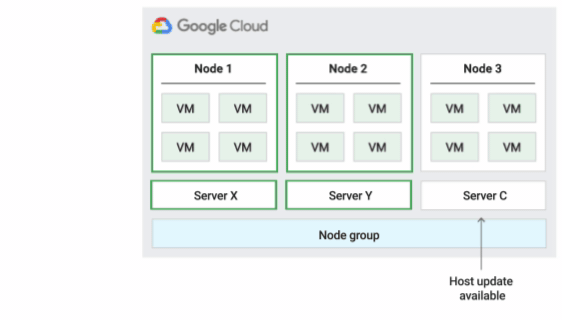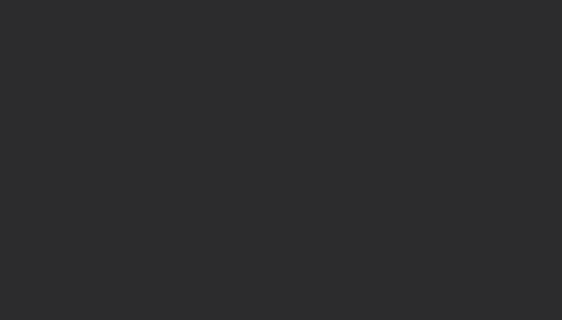
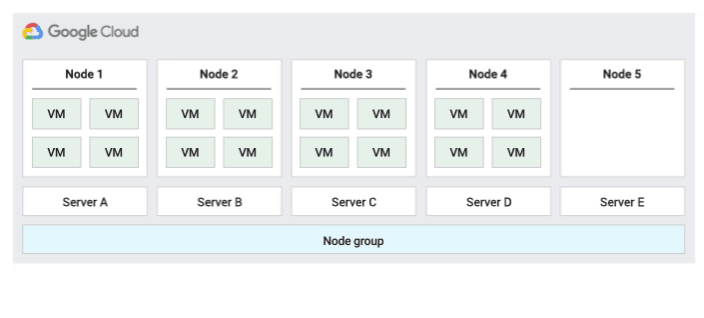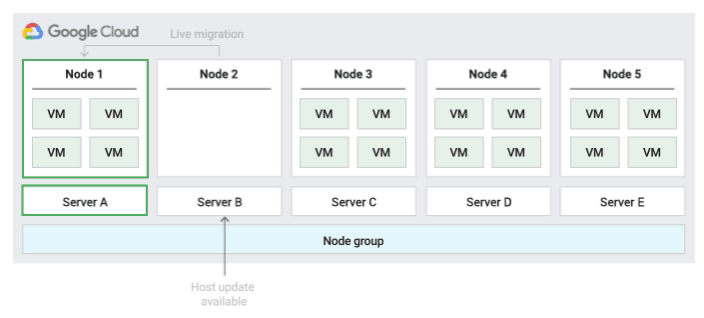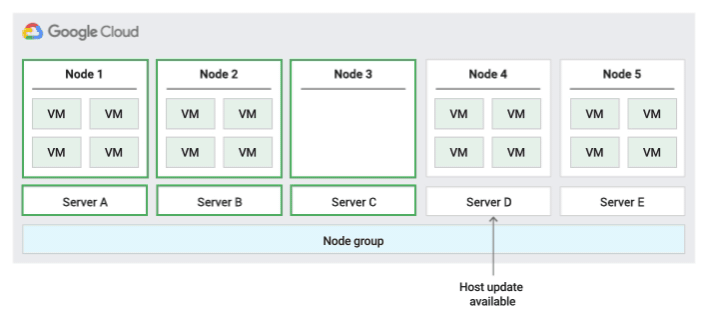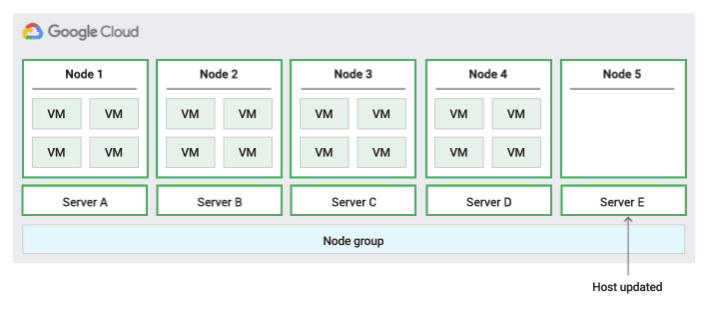
El único cliente te permite tener acceso exclusivo a un nodo de único cliente, que es un servidor físico de Compute Engine dedicado a alojar únicamente las máquinas virtuales de tu proyecto. Usa nodos de único cliente para separar físicamente tus máquinas virtuales de las de otros proyectos o para agruparlas en el mismo hardware de alojamiento, como se muestra en el siguiente diagrama. También puedes crear un grupo de nodos de un solo inquilino y especificar si quieres compartirlo con otros proyectos o con toda la organización.

Las VMs que se ejecutan en nodos de único cliente pueden usar las mismas funciones de Compute Engine que otras VMs, como la programación transparente y el almacenamiento en bloque, pero con una capa adicional de aislamiento de hardware. Para que tengas el control total de las máquinas virtuales del servidor físico, cada nodo de único propietario mantiene una asignación individual al servidor físico que lo respalda.
En un nodo de único inquilino, puedes aprovisionar varias máquinas virtuales en tipos de máquina de varios tamaños, lo que te permite usar de forma eficiente los recursos subyacentes del hardware del host dedicado. Además, si decides no compartir el hardware del host con otros proyectos, puedes cumplir los requisitos de seguridad o cumplimiento con cargas de trabajo que requieran aislamiento físico de otras cargas de trabajo o máquinas virtuales. Si tu carga de trabajo solo requiere el aislamiento de un único inquilino de forma temporal, puedes modificar el aislamiento de la VM según sea necesario.
Los nodos de único cliente te pueden ayudar a cumplir los requisitos de hardware dedicado en los casos de licencia adquirida por el usuario (BYOL) que requieren licencias por núcleo o por procesador. Cuando usas nodos de un solo inquilino, tienes cierta visibilidad del hardware subyacente, lo que te permite monitorizar el uso de los núcleos y los procesadores. Para hacer un seguimiento de este uso, Compute Engine informa del ID del servidor físico en el que se programa una VM. Después, con Cloud Logging, puedes consultar el historial de uso del servidor de una VM.
Para optimizar el uso del hardware del host, puede hacer lo siguiente:
Mediante una política de mantenimiento del host configurable, puedes controlar el comportamiento de las VMs de único cliente mientras se lleva a cabo el mantenimiento de su host. Puedes especificar cuándo se realiza el mantenimiento y si las VMs mantienen la afinidad con un servidor físico específico o se mueven a otros nodos de un solo inquilino dentro de un grupo de nodos.
Consideraciones sobre la carga de trabajo
Los siguientes tipos de cargas de trabajo pueden beneficiarse del uso de nodos de único cliente:
Cargas de trabajo de juegos con requisitos de rendimiento
Cargas de trabajo de los sectores financiero o sanitario con requisitos de seguridad y cumplimiento
Cargas de trabajo de Windows con requisitos de licencia
Cargas de trabajo de aprendizaje automático, procesamiento de datos o renderización de imágenes. Para estas cargas de trabajo, te recomendamos que reserves GPUs.
Cargas de trabajo que requieren más operaciones de entrada/salida por segundo (IOPS) y una latencia menor, o cargas de trabajo que usan almacenamiento temporal en forma de cachés, espacio de procesamiento o datos de poco valor. Para estas cargas de trabajo, te recomendamos que reserves discos SSD locales.
Plantillas de nodo
Una plantilla de nodo es un recurso regional que define las propiedades de cada nodo de un grupo de nodos. Cuando creas un grupo de nodos a partir de una plantilla de nodo, las propiedades de la plantilla de nodo se copian de forma inmutable en cada nodo del grupo de nodos.
Cuando creas una plantilla de nodo, debes especificar un tipo de nodo. Cuando creas una plantilla de nodo, puedes especificar etiquetas de afinidad de nodo. Solo puedes especificar etiquetas de afinidad de nodos en una plantilla de nodo. No puedes especificar etiquetas de afinidad de nodos en un grupo de nodos.
Tipos de nodos
Cuando configures una plantilla de nodo, especifica un tipo de nodo que se aplique a todos los nodos de un grupo de nodos creado a partir de la plantilla de nodo. El tipo de nodo de único propietario, al que hace referencia la plantilla de nodo, especifica la cantidad total de núcleos de vCPU y de memoria de los nodos creados en los grupos de nodos que usan esa plantilla. Por ejemplo, el tipo de nodo n2-node-80-640 tiene 80 vCPUs y 640 GB de memoria.
Las VMs que añadas a un nodo de un solo inquilino deben tener el mismo tipo de máquina que el tipo de nodo que especifiques en la plantilla de nodo. Por ejemplo, los tipos de nodo de único propietario n2
solo son compatibles con las máquinas virtuales creadas con el tipo de máquina n2. Puedes añadir VMs a un nodo de único propietario hasta que la cantidad total de vCPUs o de memoria supere la capacidad del nodo.
Cuando creas un grupo de nodos con una plantilla de nodo, cada nodo del grupo de nodos hereda las especificaciones del tipo de nodo de la plantilla de nodo. Un tipo de nodo se aplica a cada nodo de un grupo de nodos, no a todos los nodos del grupo de forma uniforme. Por lo tanto, si creas un grupo de nodos con dos nodos del tipo n2-node-80-640, a cada nodo se le asignarán 80 vCPUs y 640 GB de memoria.
En función de los requisitos de tu carga de trabajo, puedes llenar el nodo con varias VMs más pequeñas que se ejecuten en tipos de máquinas de varios tamaños, incluidos los tipos de máquinas predefinidos, los tipos de máquinas personalizadas y los tipos de máquinas con memoria ampliada. Cuando un nodo está lleno, no puedes programar más máquinas virtuales en él.
En la siguiente tabla se muestran los tipos de nodos disponibles. Para ver una lista de los tipos de nodos disponibles para tu proyecto, ejecuta el comando gcloud compute sole-tenancy node-types list o crea una solicitud REST nodeTypes.list.
| Tipo de nodo | Procesador | vCPU | GB | vCPU:GB | Sockets | Núcleos:Socket | Número total de núcleos | Número máximo de máquinas virtuales permitidas |
|---|---|---|---|---|---|---|---|---|
c2-node-60-240 |
Cascade Lake | 60 | 240 | 1:4 | 2 | 18 | 36 | 15 |
c3-node-176-352 |
Sapphire Rapids | 176 | 352 | 1:2 | 2 | 48 | 96 | 44 |
c3-node-176-704 |
Sapphire Rapids | 176 | 704 | 1:4 | 2 | 48 | 96 | 44 |
c3-node-176-704-lssd |
Sapphire Rapids | 176 | 704 | 1:4 | 2 | 48 | 96 | 40 |
c3-node-176-1408 |
Sapphire Rapids | 176 | 1408 | 1:8 | 2 | 48 | 96 | 44 |
c3d-node-360-708 |
AMD EPYC Genoa | 360 | 708 | 1:2 | 2 | 96 | 192 | 34 |
c3d-node-360-1440 |
AMD EPYC Genoa | 360 | 1440 | 1:4 | 2 | 96 | 192 | 40 |
c3d-node-360-2880 |
AMD EPYC Genoa | 360 | 2880 | 1:8 | 2 | 96 | 192 | 40 |
c4-node-192-384 |
Emerald Rapids | 192 | 384 | 1:2 | 2 | 60 | 120 | 40 |
c4-node-192-720 |
Emerald Rapids | 192 | 720 | 1:3,75 | 2 | 60 | 120 | 30 |
c4-node-192-1488 |
Emerald Rapids | 192 | 1488 | 1:7,75 | 2 | 60 | 120 | 30 |
c4a-node-72-144 |
Google Axion | 72 | 144 | 1:2 | 1 | 80 | 80 | 22 |
c4a-node-72-288 |
Google Axion | 72 | 288 | 1:4 | 1 | 80 | 80 | 22 |
c4a-node-72-576 |
Google Axion | 72 | 576 | 1:8 | 1 | 80 | 80 | 36 |
c4d-node-384-720 |
AMD EPYC Turin | 384 | 744 | 1:2 | 2 | 96 | 192 | 24 |
c4d-node-384-1488 |
AMD EPYC Turin | 384 | 1488 | 1:4 | 2 | 96 | 192 | 25 |
c4d-node-384-3024 |
AMD EPYC Turin | 384 | 3024 | 1:8 | 2 | 96 | 192 | 25 |
g2-node-96-384 |
Cascade Lake | 96 | 384 | 1:4 | 2 | 28 | 56 | 8 |
g2-node-96-432 |
Cascade Lake | 96 | 432 | 1:4,5 | 2 | 28 | 56 | 8 |
h3-node-88-352 |
Sapphire Rapids | 88 | 352 | 1:4 | 2 | 48 | 96 | 1 |
m1-node-96-1433 |
Skylake | 96 | 1433 | 1:14.93 | 2 | 28 | 56 | 1 |
m1-node-160-3844 |
Broadwell E7 | 160 | 3844 | 1:24 | 4 | 22 | 88 | 4 |
m2-node-416-8832 |
Cascade Lake | 416 | 8832 | 1:21.23 | 8 | 28 | 224 | 1 |
m2-node-416-11776 |
Cascade Lake | 416 | 11776 | 1:28.31 | 8 | 28 | 224 | 2 |
m3-node-128-1952 |
Ice Lake | 128 | 1952 | 1:15.25 | 2 | 36 | 72 | 2 |
m3-node-128-3904 |
Ice Lake | 128 | 3904 | 1:30.5 | 2 | 36 | 72 | 2 |
m4-node-224-2976 |
Emerald Rapids | 224 | 2976 | 1:13.3 | 2 | 112 | 224 | 1 |
m4-node-224-5952 |
Emerald Rapids | 224 | 5952 | 1:26.7 | 2 | 112 | 224 | 1 |
n1-node-96-624 |
Skylake | 96 | 624 | 1:6.5 | 2 | 28 | 56 | 96 |
n2-node-80-640 |
Cascade Lake | 80 | 640 | 1:8 | 2 | 24 | 48 | 80 |
n2-node-128-864 |
Ice Lake | 128 | 864 | 1:6,75 | 2 | 36 | 72 | 128 |
n2d-node-224-896 |
AMD EPYC Rome | 224 | 896 | 1:4 | 2 | 64 | 128 | 112 |
n2d-node-224-1792 |
AMD EPYC Milan | 224 | 1792 | 1:8 | 2 | 64 | 128 | 112 |
n4-node-224-1372 |
Emerald Rapids | 224 | 1372 | 1:6 | 2 | 60 | 120 | 90 |
Para obtener información sobre los precios de estos tipos de nodos, consulta los precios de los nodos de único propietario.
Todos los nodos te permiten programar VMs de diferentes formas. El tipo de nodo n son nodos de uso general en los que puedes programar instancias de tipo de máquina personalizado. Para obtener recomendaciones sobre qué tipo de nodo elegir, consulta Recomendaciones de tipos de máquinas.
Para obtener información sobre el rendimiento, consulta Plataformas de CPU.
Grupos de nodos y aprovisionamiento de VMs
Las plantillas de nodos de único propietario definen las propiedades de un grupo de nodos. Debes crear una plantilla de nodo antes de crear un grupo de nodos en una Google Cloud zona. Cuando crees un grupo, especifica la política de mantenimiento del host de las VMs del grupo de nodos, el número de nodos del grupo y si quieres compartirlo con otros proyectos o con toda la organización.
Un grupo de nodos puede tener cero o más nodos. Por ejemplo, puedes reducir el número de nodos de un grupo de nodos a cero cuando no necesites ejecutar ninguna VM en los nodos del grupo, o bien puedes habilitar la herramienta de autoescalado de grupos de nodos para gestionar el tamaño del grupo de nodos automáticamente.
Antes de aprovisionar VMs en nodos de único cliente, debes crear un grupo de nodos de único cliente. Un grupo de nodos es un conjunto homogéneo de nodos de único cliente en una zona específica. Los grupos de nodos pueden contener varias VMs de la misma serie de máquinas que se ejecutan en tipos de máquinas de varios tamaños, siempre que el tipo de máquina tenga 2 vCPUs o más.
Cuando crees un grupo de nodos, habilita el autoescalado para que el tamaño del grupo se ajuste automáticamente a los requisitos de tu carga de trabajo. Si los requisitos de tu carga de trabajo son estáticos, puedes especificar manualmente el tamaño del grupo de nodos.
Después de crear un grupo de nodos, puedes aprovisionar máquinas virtuales en el grupo o en un nodo específico del grupo. Para tener más control, usa etiquetas de afinidad de nodos para programar máquinas virtuales en cualquier nodo con etiquetas de afinidad coincidentes.
Después de aprovisionar VMs en grupos de nodos y, opcionalmente, asignar etiquetas de afinidad para aprovisionar VMs en grupos de nodos o nodos específicos, puedes etiquetar tus recursos para gestionar tus VMs. Las etiquetas son pares clave-valor que pueden ayudarte a clasificar tus máquinas virtuales para que puedas verlas de forma agregada por motivos como la facturación. Por ejemplo, puedes usar etiquetas para marcar el rol de una VM, su arrendamiento, el tipo de licencia o su ubicación.
Política de mantenimiento del host
En función de tus escenarios de licencias y cargas de trabajo, puede que te interese limitar el número de núcleos físicos que usan tus VMs. La política de mantenimiento del host que elijas puede depender, por ejemplo, de tus requisitos de licencias o de cumplimiento. También puedes elegir una política que te permita limitar el uso de servidores físicos. Con todas estas políticas, tus VMs permanecen en hardware dedicado.
Cuando programas VMs en nodos de un solo inquilino, puedes elegir entre las tres opciones siguientes de política de mantenimiento de hosts, que te permiten determinar cómo y si Compute Engine migra en tiempo real las VMs durante los eventos de host, que se producen aproximadamente cada 4-6 semanas. Durante el mantenimiento, Compute Engine migra en tiempo real, como grupo, todas las VMs del host a otro nodo de único propietario, pero, en algunos casos, Compute Engine puede dividir las VMs en grupos más pequeños y migrar en tiempo real cada grupo más pequeño de VMs a nodos de único propietario independientes.
Política de mantenimiento de anfitrión predeterminada
Esta es la política de mantenimiento de hosts predeterminada. Las VMs de los grupos de nodos configurados con esta política siguen el comportamiento de mantenimiento tradicional de las VMs que no son de único cliente. Es decir, en función de la configuración de mantenimiento en el host de este, las VMs se migran de forma activa a un nuevo nodo de único cliente del grupo de nodos antes de que se produzca un evento de mantenimiento del host. Este nuevo nodo de único cliente solo ejecuta las VMs del cliente.
Esta política es la más adecuada para las licencias por usuario o por dispositivo que requieren una migración en directo durante los eventos del host. Este ajuste no restringe la migración de las VMs a un grupo fijo de servidores físicos y se recomienda para cargas de trabajo generales que no tengan requisitos de servidores físicos y que no necesiten licencias.
Como las VMs se migran en directo a cualquier servidor sin tener en cuenta la afinidad del servidor con esta política, esta política no es adecuada para situaciones en las que se requiera minimizar el uso de los núcleos físicos durante los eventos del host.
En la siguiente figura se muestra una animación de la política de mantenimiento del host Predeterminada.
Reiniciar in situ la política de mantenimiento del host
Cuando usas esta política de mantenimiento del host, Compute Engine detiene las VMs durante los eventos del host y, a continuación, las reinicia en el mismo servidor físico después del evento del host. Cuando uses esta política, debes asignar el valor TERMINATE al ajuste de mantenimiento en el host de la VM.
Esta política es la más adecuada para cargas de trabajo tolerantes a fallos que pueden experimentar aproximadamente una hora de inactividad durante los eventos del host, cargas de trabajo que deben permanecer en el mismo servidor físico, cargas de trabajo que no requieren migración activa o si tienes licencias basadas en el número de núcleos o procesadores físicos.
Con esta política, la instancia se puede asignar al grupo de nodos mediante node-name, node-group-name o la etiqueta de afinidad de nodos.
En la siguiente imagen se muestra una animación de la política de mantenimiento Reiniciar en el mismo sitio.
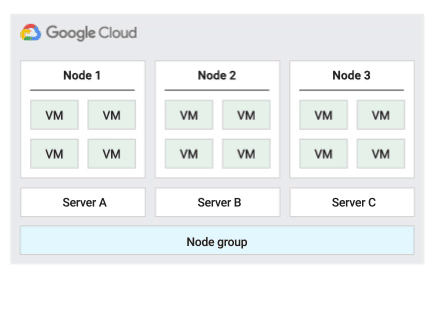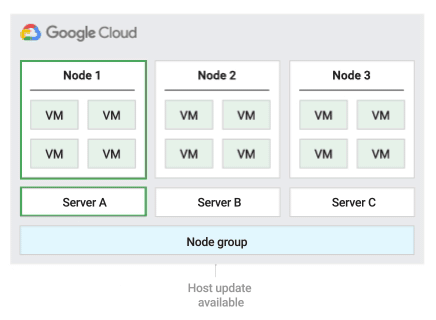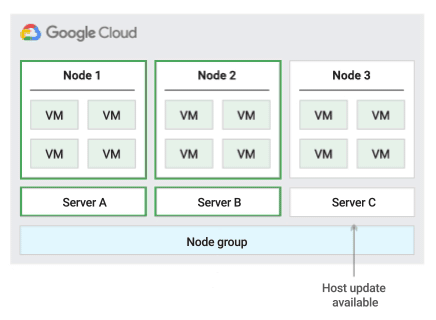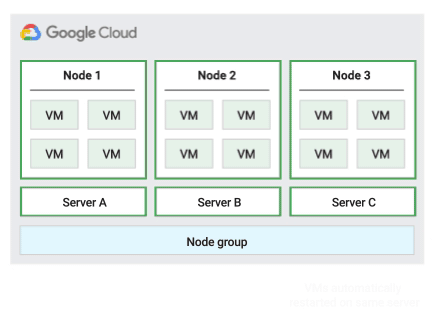
Política de mantenimiento de hosts de migración dentro del grupo de nodos
Cuando se usa esta política de mantenimiento del host, Compute Engine migra en tiempo real las VMs dentro de un grupo de tamaño fijo de servidores físicos durante los eventos del host, lo que ayuda a limitar el número de servidores físicos únicos que usa la VM.
Esta política es la más adecuada para cargas de trabajo de alta disponibilidad con licencias basadas en el número de núcleos o procesadores físicos, ya que, con esta política de mantenimiento de hosts, cada nodo de único propietario del grupo se asigna a un conjunto fijo de servidores físicos, que es diferente de la política predeterminada que permite que las VMs migren a cualquier servidor.
Para confirmar la capacidad de la migración activa, Compute Engine reserva 1 nodo de retención por cada 20 nodos que reserves. En la siguiente figura se muestra una animación de la política de mantenimiento de hosts Migrar dentro del grupo de nodos.
En la siguiente tabla se muestra cuántos nodos de retención reserva Compute Engine en función del número de nodos que reserves para tu grupo de nodos.
| Número total de nodos del grupo | Nodos de retención reservados para la migración en tiempo real |
|---|---|
| 1 | No aplicable Debes reservar al menos 2 nodos. |
| De 2 a 20 | 1 |
| De 21 a 40 | 2 |
| De 41 a 60 | 3 |
| De 61 a 80 | 4 |
| De 81 a 100 | 5 |
Fijar una instancia a varios grupos de nodos
Puedes fijar una instancia a varios grupos de nodos mediante la node-group-name
etiqueta de afinidad
en las siguientes condiciones:
- La instancia que quieres fijar usa una política de mantenimiento del host predeterminada (Migrar instancia de VM).
- La política de mantenimiento del host de todos los grupos de nodos a los que quieras fijar la instancia es Migrar dentro del grupo de nodos. Si intentas fijar una instancia a grupos de nodos con políticas de mantenimiento de host diferentes, la operación fallará y se mostrará un error.
Por ejemplo, si quieres fijar una instancia test-node a dos grupos de nodos, node-group1 y node-group2, comprueba lo siguiente:
- La política de mantenimiento del host de
test-nodees Migrar instancia de VM. - La política de mantenimiento del host de
node-group1ynode-group2es migrar dentro del grupo de nodos.
No puedes asignar una instancia a ningún nodo específico con la etiqueta de afinidad
node-name. Puede usar cualquier etiqueta de afinidad de nodo personalizada para sus instancias siempre que se les asigne node-group-name y no node-name.
Ventanas de mantenimiento
Si gestionas cargas de trabajo, como bases de datos optimizadas, que pueden ser sensibles al impacto en el rendimiento de la migración activa, puedes determinar cuándo empieza el mantenimiento en un grupo de nodos de un solo inquilino especificando una ventana de mantenimiento al crear el grupo de nodos. No puedes modificar la ventana de mantenimiento después de crear el grupo de nodos.
Las ventanas de mantenimiento son bloques de tiempo de 4 horas que puedes usar para especificar cuándo realiza Google el mantenimiento de tus máquinas virtuales de un solo inquilino. Los eventos de mantenimiento se producen aproximadamente una vez cada 4 o 6 semanas.
La ventana de mantenimiento se aplica a todas las VMs del grupo de nodos de un solo inquilino y solo especifica cuándo empieza el mantenimiento. No se garantiza que el mantenimiento finalice durante la ventana de mantenimiento, ni tampoco la frecuencia con la que se realiza. Las ventanas de mantenimiento no se admiten en grupos de nodos con la política de mantenimiento de hosts Migrar dentro del grupo de nodos.
Simular un evento de mantenimiento de host
Puedes simular un evento de mantenimiento del host para probar cómo se comportan tus cargas de trabajo que se ejecutan en nodos de único cliente durante un evento de mantenimiento del host. De esta forma, puedes ver los efectos de la política de mantenimiento del host de la VM de único cliente en las aplicaciones que se ejecutan en las VMs.
Errores de host
Cuando se produce un fallo de hardware crítico poco frecuente en el host (de un solo inquilino o de varios), Compute Engine hace lo siguiente:
Retira el servidor físico y su identificador único.
Revoca el acceso de tu proyecto al servidor físico.
Sustituye el hardware averiado por un nuevo servidor físico que tiene un nuevo identificador único.
Mueve las VMs del hardware que ha fallado al nodo de sustitución.
Reinicia las VMs afectadas si las has configurado para que se reinicien automáticamente.
Afinidad y antiafinidad de nodos
Los nodos de un solo inquilino aseguran que tus VMs no compartan el host con VMs de otros proyectos, a menos que uses grupos de nodos de un solo inquilino compartidos. Con los grupos de nodos de único inquilino compartidos, otros proyectos de la organización pueden aprovisionar máquinas virtuales en el mismo host. Sin embargo, es posible que quieras agrupar varias cargas de trabajo en el mismo nodo de un solo inquilino o aislar tus cargas de trabajo entre sí en nodos diferentes. Por ejemplo, para cumplir algunos requisitos, puede que tengas que usar etiquetas de afinidad para separar las cargas de trabajo sensibles de las que no lo son.
Cuando creas una VM, solicitas el uso exclusivo especificando la afinidad o la antiafinidad de nodos, haciendo referencia a una o varias etiquetas de afinidad de nodos. Puedes especificar etiquetas de afinidad de nodos personalizadas al crear una plantilla de nodo. Compute Engine incluye automáticamente algunas etiquetas de afinidad predeterminadas en cada nodo. Si especificas la afinidad al crear una VM, puedes programar VMs juntas en un nodo específico o en nodos de un grupo de nodos. Si especificas la antiafinidad al crear una VM, puedes asegurarte de que determinadas VMs no se programen juntas en el mismo nodo o en los mismos nodos de un grupo de nodos.
Las etiquetas de afinidad de nodos son pares clave-valor asignados a los nodos y se heredan de una plantilla de nodo. Las etiquetas de afinidad te permiten:
- Controla cómo se asignan las instancias de VM individuales a los nodos.
- Controla cómo se asignan a los nodos las instancias de VM creadas a partir de una plantilla, como las que crea un grupo de instancias gestionado.
- Agrupa las instancias de VM sensibles en nodos o grupos de nodos específicos, separados de otras VMs.
Etiquetas de afinidad predeterminadas
Compute Engine asigna las siguientes etiquetas de afinidad predeterminadas a cada nodo:
- Una etiqueta para el nombre del grupo de nodos:
- Tecla:
compute.googleapis.com/node-group-name - Valor: nombre del grupo de nodos.
- Tecla:
- Una etiqueta para el nombre del nodo:
- Tecla:
compute.googleapis.com/node-name - Valor: nombre del nodo individual.
- Tecla:
- Una etiqueta de los proyectos con los que se comparte el grupo de nodos:
- Tecla:
compute.googleapis.com/projects - Valor: ID de proyecto del proyecto que contiene el grupo de nodos.
- Tecla:
Etiquetas de afinidad personalizadas
Puedes crear etiquetas de afinidad de nodos personalizadas cuando crees una plantilla de nodo. Estas etiquetas de afinidad se asignan a todos los nodos de los grupos de nodos creados a partir de la plantilla de nodo. No puedes añadir más etiquetas de afinidad personalizadas a los nodos de un grupo de nodos una vez que se haya creado.
Para obtener información sobre cómo usar etiquetas de afinidad, consulta Configurar la afinidad de nodos.
Precios
Para ayudarte a minimizar el coste de tus nodos de único cliente, Compute Engine ofrece descuentos por compromiso de uso (CUDs) y descuentos por uso continuado (SUDs). Ten en cuenta que, en el caso de los cargos premium de único propietario, solo puedes recibir CUDs y SUDs flexibles, pero no CUDs basados en recursos.
Como ya se te factura por la vCPU y la memoria de tus nodos de único propietario, no pagas más por las VMs que creas en esos nodos.
Si aprovisionas nodos de único cliente con GPUs o discos SSD locales, se te cobrarán todas las GPUs o los discos SSD locales de cada nodo que aprovisiones. La prima de único propietario se basa únicamente en las vCPUs y la memoria que uses en el nodo de único propietario, y no incluye GPUs ni discos SSD locales.
Para obtener más información, consulta los precios de los nodos de un solo inquilino.
Disponibilidad
Los nodos de único cliente están disponibles en determinadas zonas. Para verificar la alta disponibilidad, programa VMs en nodos de único cliente de diferentes zonas.
Antes de usar GPUs o discos SSD locales en nodos de único cliente, asegúrate de tener suficiente cuota de GPU o SSD local en la zona en la que vas a reservar el recurso.
Compute Engine admite GPUs en los tipos de nodos de único cliente
n1yg2que se encuentran en zonas con compatibilidad con GPUs. En la siguiente tabla se muestran los tipos de GPUs que puedes asociar a nodosn1yg2, así como el número de GPUs que debes asociar al crear la plantilla de nodo.Tipo de GPU Cantidad de GPUs Tipo de nodo de único cliente NVIDIA L4 8 g2NVIDIA P100 4 n1NVIDIA P4 4 n1NVIDIA T4 4 n1NVIDIA V100 8 n1Compute Engine admite discos SSD locales en los tipos de nodos de un solo inquilino
n1,n2,n2dyg2que se usan en zonas que admiten esas series de máquinas.
Restricciones
No puedes usar máquinas virtuales de un solo inquilino con las siguientes series y tipos de máquinas: T2D, T2A, E2, C2D, A2, A3, A4, A4X, G4 o instancias de hardware desnudo.
Las VMs de único cliente no pueden especificar una plataforma de CPU mínima.
No puedes migrar una VM a un nodo de único inquilino si esa VM especifica una plataforma de CPU mínima. Para migrar una VM a un nodo de único inquilino, elimina la especificación de plataforma de CPU mínima y configúrala como automática antes de actualizar las etiquetas de afinidad de nodo de la VM.
Los nodos de único cliente no admiten instancias de máquinas virtuales interrumpibles.
Para obtener información sobre las limitaciones del uso de discos SSD locales en nodos de un solo inquilino, consulta Persistencia de datos de SSD local.
Para obtener información sobre cómo afecta el uso de GPUs a la migración activa, consulta las limitaciones de la migración activa.
Los nodos de único propietario con GPUs no admiten máquinas virtuales sin GPUs.
Solo los nodos de único cliente N1, N2, N2D y N4 admiten el exceso de compromiso de CPUs.
Las máquinas virtuales C3, C3D, C4, C4A, C4D y N4 se programan de forma que se alineen con la arquitectura NUMA subyacente del nodo de un solo cliente. Programar formas de VM completas y sub-NUMA en el mismo nodo puede provocar una fragmentación, por la que no se puede ejecutar una forma más grande, mientras que sí se pueden ejecutar varias formas más pequeñas que sumen los mismos requisitos de recursos.
Los nodos de único propietario C3 y C4 requieren que las máquinas virtuales tengan la misma proporción de vCPUs a memoria que el tipo de nodo. Por ejemplo, no puedes colocar una máquina virtual
c3-standarden un tipo de nodo-highmem.No puedes actualizar la política de mantenimiento de un grupo de nodos activo.
Siguientes pasos
Consulta cómo crear, configurar y consumir tus nodos de único propietario.
Consulta cómo comprometer de forma excesiva CPUs en máquinas virtuales de único propietario.
Consulta cómo traer tus propias licencias.
Consulta nuestras prácticas recomendadas para usar nodos de un solo inquilino para ejecutar cargas de trabajo de máquinas virtuales.