Ce document décrit les nœuds à locataire unique. Pour savoir comment provisionner des VM sur des nœuds à locataire unique, consultez la page Provisionner des VM sur des nœuds à locataire unique.
La location unique vous permet d'avoir un accès exclusif à un nœud à locataire unique, qui est un serveur physique Compute Engine entièrement dédié à l'hébergement des VM de votre projet. Utilisez des nœuds à locataire unique pour séparer physiquement vos VM des VM d'autres projets ou pour regrouper vos VM sur le même matériel hôte, comme indiqué dans le schéma suivant. Vous pouvez également créer un groupe de nœuds à locataire unique et spécifier si vous souhaitez le partager avec d'autres projets ou avec l'ensemble de l'organisation.

Les VM s'exécutant sur des nœuds à locataire unique peuvent utiliser les mêmes fonctionnalités Compute Engine que les autres VM, y compris la planification transparente et le stockage de blocs, mais avec une couche d'isolation matérielle supplémentaire. Pour vous donner un contrôle total sur les VM du serveur physique, chaque nœud à locataire unique conserve un mappage un à un sur le serveur physique qui sauvegarde le nœud.
Dans un nœud à locataire unique, vous pouvez provisionner plusieurs VM sur des types de machines de différentes tailles, ce qui vous permet d'utiliser efficacement les ressources sous-jacentes du matériel hôte dédié. En outre, si vous choisissez de ne pas partager le matériel hôte avec d'autres projets, vous pouvez répondre aux exigences de sécurité ou de conformité avec des charges de travail nécessitant l'isolation physique des autres charges de travail ou VM. Si votre charge de travail ne nécessite la location unique que temporairement, vous pouvez modifier la location de VM si nécessaire.
Les nœuds à locataire unique peuvent vous aider à répondre aux exigences de matériel dédié pour les scénarios Bring Your Own License (BYOL), qui nécessitent des licences par cœur ou par processeur. Lorsque vous utilisez des nœuds à locataire unique, vous avez une certaine visibilité sur le matériel sous-jacent, ce qui vous permet de suivre l'utilisation du cœur et du processeur. Compute Engine indique pour cela l'ID du serveur physique sur lequel une VM est planifiée. Ensuite, à l'aide de Cloud Logging, vous pouvez afficher l'historique d'utilisation du serveur d'une VM.
Pour optimiser l'utilisation du matériel hôte, vous pouvez procéder comme suit :
Grâce à une stratégie de maintenance de l'hôte configurable, vous pouvez contrôler le comportement des VM à locataire unique pendant la maintenance de leur hôte. Vous pouvez spécifier le moment où la maintenance a lieu et si les VM conservent l'affinité avec un serveur physique spécifique ou sont transférées vers d'autres nœuds à locataire unique au sein d'un groupe de nœuds.
Considérations relatives à la charge de travail
L'utilisation de nœuds à locataire unique peut présenter un avantage pour les types de charges de travail suivants :
Charges de travail de jeu avec des exigences de performances
Charges de travail financières ou de santé ayant des exigences liées à la sécurité et à la conformité.
Charges de travail Windows ayant des exigences liées à l'attribution de licences
Charges de travail de machine learning, de traitement de données ou de rendu d'images. Pour ces charges de travail, envisagez de réserver des GPU.
Charges de travail nécessitant des opérations d'entrée/sortie par seconde (IOPS) plus élevées, une diminution de la latence, ou charges de travail qui utilisent le stockage temporaire sous forme de mise en cache, d'espace de traitement ou de données de faible valeur. Pour ces charges de travail, envisagez de réserver des disques SSD locaux.
Modèles de nœud
Un modèle de nœud est une ressource régionale qui définit les propriétés de chaque nœud d'un groupe de nœuds. Lorsque vous créez un groupe de nœuds à partir d'un modèle de nœud, les propriétés du modèle de nœud sont copiées de manière immuable sur chaque nœud du groupe de nœuds.
Lorsque vous créez un modèle de nœud, vous devez spécifier un type de nœud. Vous pouvez éventuellement spécifier des libellés d'affinité de nœuds lorsque vous créez un modèle de nœud. Vous ne pouvez spécifier des libellés d'affinité de nœud que sur un modèle de nœud. Vous ne pouvez pas spécifier de libellés d'affinité de nœud sur un groupe de nœuds.
Types de nœuds
Lorsque vous configurez un modèle de nœud, spécifiez un type de nœud à appliquer à tous les nœuds d'un groupe de nœuds créé à partir du modèle de nœud. Le type de nœud à locataire unique, auquel le modèle de nœud fait référence, spécifie la quantité totale de cœurs de processeur virtuel et de mémoire pour les nœuds créés dans les groupes de nœuds qui utilisent ce modèle. Par exemple, le type de nœud n2-node-80-640 dispose de 80 processeurs virtuels et de 640 Go de mémoire.
Les VM que vous ajoutez à un nœud à locataire unique doivent avoir le même type que le type de nœud spécifié dans le modèle de nœud. Par exemple, les types de nœuds à locataire unique n2 ne sont compatibles qu'avec les VM créées avec le type de machine n2. Vous pouvez ajouter des VM à un nœud à locataire unique jusqu'à ce que la quantité totale de processeurs virtuels ou de mémoire dépasse la capacité du nœud.
Lorsque vous créez un groupe de nœuds à l'aide d'un modèle de nœud, chaque nœud du groupe hérite des spécifications de type de nœud du modèle. Un type de nœud s'applique à chaque nœud d'un groupe de nœuds. Il ne s'applique pas uniformément à l'ensemble des nœuds du groupe. Ainsi, si vous créez un groupe de nœuds avec deux nœuds de type n2-node-80-640, chaque nœud se voit attribuer 80 processeurs virtuels et 640 Go de mémoire.
Selon les exigences de votre charge de travail, vous pouvez remplir le nœud avec plusieurs VM plus petites exécutées sur des types de machines de différentes tailles, y compris des types de machines prédéfinis, des types de machines personnalisés et des types de machines avec une mémoire étendue. Lorsqu'un nœud est plein, vous ne pouvez pas planifier de VM supplémentaires sur ce nœud.
Le tableau suivant affiche les types de nœuds disponibles. Pour afficher la liste des types de nœuds disponibles pour votre projet, exécutez la commande gcloud compute sole-tenancy node-types list ou créez une requête REST nodeTypes.list.
| Type de nœud | Processeur | Processeur virtuel | Go | Processeur virtuel par Go | Sockets | Cœurs par socket | Nombre total de cœurs | Nombre maximal de VM autorisées |
|---|---|---|---|---|---|---|---|---|
c2-node-60-240 |
Cascade Lake | 60 | 240 | 1:4 | 2 | 18 | 36 | 15 |
c3-node-176-352 |
Sapphire Rapids | 176 | 352 | 1:2 | 2 | 48 | 96 | 44 |
c3-node-176-704 |
Sapphire Rapids | 176 | 704 | 1:4 | 2 | 48 | 96 | 44 |
c3-node-176-1408 |
Sapphire Rapids | 176 | 1408 | 1:8 | 2 | 48 | 96 | 44 |
c3d-node-360-708 |
AMD EPYC Genoa | 360 | 708 | 1:2 | 2 | 96 | 192 | 34 |
c3d-node-360-1440 |
AMD EPYC Genoa | 360 | 1440 | 1:4 | 2 | 96 | 192 | 40 |
c3d-node-360-2880 |
AMD EPYC Genoa | 360 | 2880 | 1:8 | 2 | 96 | 192 | 40 |
c4-node-192-384 |
Emerald Rapids | 192 | 384 | 1:2 | 2 | 60 | 120 | 40 |
c4-node-192-720 |
Emerald Rapids | 192 | 720 | 1:3.75 | 2 | 60 | 120 | 30 |
c4-node-192-1488 |
Emerald Rapids | 192 | 1,488 | 1:7.75 | 2 | 60 | 120 | 30 |
c4a-node-72-144 |
Google Axion | 72 | 144 | 1:2 | 1 | 80 | 80 | 22 |
c4a-node-72-288 |
Google Axion | 72 | 288 | 1:4 | 1 | 80 | 80 | 22 |
c4a-node-72-576 |
Google Axion | 72 | 576 | 1:8 | 1 | 80 | 80 | 36 |
c4d-node-384-720 |
AMD EPYC Turin | 384 | 744 | 1:2 | 2 | 96 | 192 | 24 |
c4d-node-384-1488 |
AMD EPYC Turin | 384 | 1488 | 1:4 | 2 | 96 | 192 | 25 |
c4d-node-384-3024 |
AMD EPYC Turin | 384 | 3024 | 1:8 | 2 | 96 | 192 | 25 |
g2-node-96-384 |
Cascade Lake | 96 | 384 | 1:4 | 2 | 28 | 56 | 8 |
g2-node-96-432 |
Cascade Lake | 96 | 432 | 1:4,5 | 2 | 28 | 56 | 8 |
h3-node-88-352 |
Sapphire Rapids | 88 | 352 | 1:4 | 2 | 48 | 96 | 1 |
m1-node-96-1433 |
Skylake | 96 | 1433 | 1:14.93 | 2 | 28 | 56 | 1 |
m1-node-160-3844 |
Broadwell E7 | 160 | 3 844 | 1:24 | 4 | 22 | 88 | 4 |
m2-node-416-8832 |
Cascade Lake | 416 | 8832 | 1:21.23 | 8 | 28 | 224 | 1 |
m2-node-416-11776 |
Cascade Lake | 416 | 11776 | 1:28.31 | 8 | 28 | 224 | 2 |
m3-node-128-1952 |
Ice Lake | 128 | 1952 | 1:15.25 | 2 | 36 | 72 | 2 |
m3-node-128-3904 |
Ice Lake | 128 | 3904 | 1:30.5 | 2 | 36 | 72 | 2 |
m4-node-224-2976 |
Emerald Rapids | 224 | 2976 | 1:13.3 | 2 | 112 | 224 | 1 |
m4-node-224-5952 |
Emerald Rapids | 224 | 5952 | 1:26.7 | 2 | 112 | 224 | 1 |
n1-node-96-624 |
Skylake | 96 | 624 | 1:6.5 | 2 | 28 | 56 | 96 |
n2-node-80-640 |
Cascade Lake | 80 | 640 | 1:8 | 2 | 24 | 48 | 80 |
n2-node-128-864 |
Ice Lake | 128 | 864 | 1:6.75 | 2 | 36 | 72 | 128 |
n2d-node-224-896 |
AMD EPYC Rome | 224 | 896 | 1:4 | 2 | 64 | 128 | 112 |
n2d-node-224-1792 |
AMD EPYC Milan | 224 | 1792 | 1:8 | 2 | 64 | 128 | 112 |
n4-node-224-1372 |
Emerald Rapids | 224 | 1372 | 1:6 | 2 | 60 | 120 | 90 |
Pour connaître le tarif de ces types de nœuds, consultez la page Tarifs applicables aux nœuds à locataire unique.
Tous les nœuds vous permettent de planifier des VM de formes différentes. Les nœuds de type n sont des nœuds à usage général sur lesquels vous pouvez planifier des instances de type de machine personnalisé. Pour obtenir des recommandations sur le type de nœud à choisir, consultez Recommandations pour les types de machines.
Pour en savoir plus sur les performances, consultez la page Plates-formes de processeur.
Groupes de nœuds et provisionnement de VM
Les modèles de nœud à locataire unique définissent les propriétés d'un groupe de nœuds. Vous devez créer un modèle de nœud avant de créer un groupe de nœuds dans une zone Google Cloud. Lorsque vous créez un groupe, spécifiez la règle de maintenance de l'hôte des VM sur le groupe de nœuds, le nombre de nœuds du groupe de nœuds, et s'il est nécessaire de le partager avec d'autres projets ou avec l'ensemble de l'organisation.
Un groupe de nœuds peut avoir zéro ou plusieurs nœuds. Par exemple, vous pouvez réduire à zéro le nombre de nœuds d'un groupe de nœuds lorsque vous n'avez pas besoin d'exécuter d'instances de VM sur les nœuds du groupe, ou activer l'autoscaler de groupe de nœuds pour gérer automatiquement la taille du groupe de nœuds.
Avant de provisionner des VM sur des nœuds à locataire unique, vous devez créer un groupe de nœuds à locataire unique. Un groupe de nœuds est un ensemble homogène de nœuds à locataire unique dans une zone spécifique. Les groupes de nœuds peuvent contenir plusieurs VM de la même série de machines s'exécutant sur des types de machines de différentes tailles, à condition que le type de machine comporte 2 processeurs virtuels ou plus.
Lorsque vous créez un groupe de nœuds, activez l'autoscaling afin que la taille du groupe s'ajuste automatiquement pour répondre aux exigences de votre charge de travail. Si vos exigences de charge de travail sont statiques, vous pouvez spécifier manuellement la taille du groupe de nœuds.
Après avoir créé un groupe de nœuds, vous pouvez provisionner des VM sur le groupe ou sur un nœud spécifique du groupe. Pour plus de contrôle, utilisez des libellés d'affinité de nœuds pour planifier des VM sur n'importe quel nœud avec des libellés d'affinité correspondants.
Après avoir provisionné des VM sur des groupes de nœuds et éventuellement attribué des libellés d'affinité pour provisionner des VM sur des groupes de nœuds ou des nœuds spécifiques, envisagez de libeller vos ressources pour faciliter la gestion de vos VM. Les libellés sont des paires clé/valeur qui vous aident à classer vos VM afin de les afficher de manière agrégée pour des raisons telles que la facturation. Par exemple, vous pouvez utiliser des libellés pour indiquer le rôle d'une VM, sa location, son type de licence ou son emplacement.
Stratégie de maintenance de l'hôte
Selon vos scénarios de licences et vos charges de travail, vous voudrez peut-être limiter le nombre de cœurs physiques utilisés par vos VM. La stratégie de maintenance de l'hôte que vous choisissez peut dépendre, par exemple, de vos exigences en termes de licences ou de conformité. Il se peut également que vous choisissiez une règle qui vous permet de limiter l'utilisation des serveurs physiques. Avec toutes ces règles, vos VM restent sur du matériel dédié.
Lorsque vous planifiez des VM sur des nœuds à locataire unique, vous avez le choix entre les trois options de stratégies de maintenance de l'hôte décrites ci-dessous, qui vous permettent de déterminer si et comment Compute Engine effectue la migration à chaud des VM lors des événements hôtes, qui ont lieu environ toutes les quatre à six semaines. Lors de la maintenance, Compute Engine effectue la migration à chaud groupée de toutes les VM de l'hôte vers un autre nœud à locataire unique. Cependant, dans certains cas, Compute Engine peut répartir les VM dans des groupes de plus petite taille et effectuer la migration à chaud de chaque petit groupe de VM vers un nœud à locataire unique spécifique.
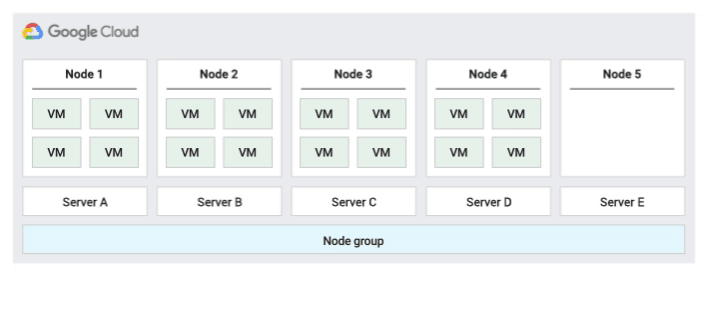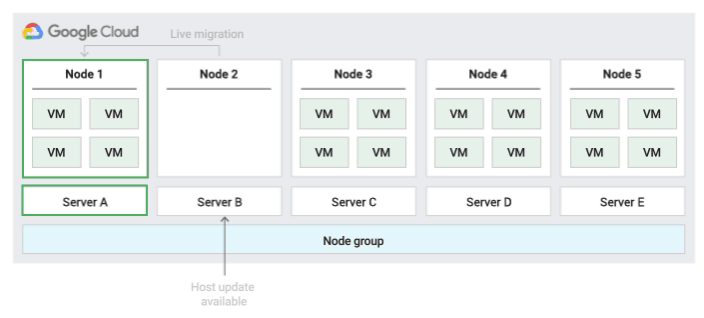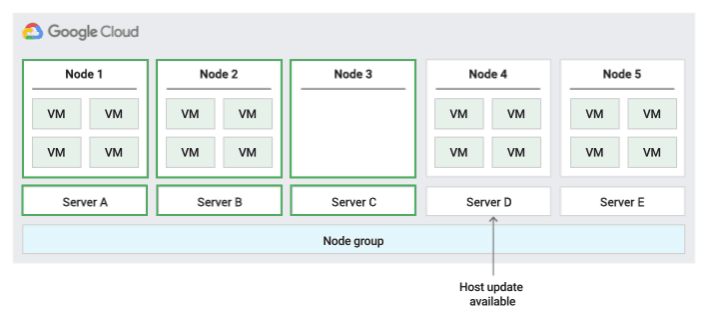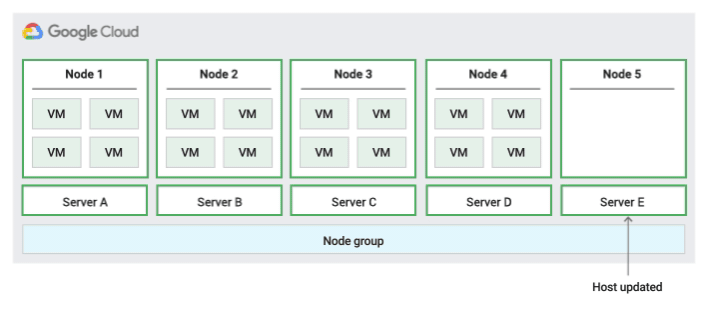
Stratégie de maintenance de l'hôte par défaut
Il s'agit de la stratégie de maintenance de l'hôte par défaut. Les VM des groupes de nœuds configurés avec cette stratégie suivent le comportement de maintenance traditionnel applicable aux VM qui ne relèvent pas d'un locataire unique. Autrement dit, en fonction du paramètre de maintenance défini sur l'hôte des VM, celles-ci migrent à chaud vers un nouveau nœud à locataire unique du groupe avant un événement de maintenance de l'hôte, et ce nouveau nœud à locataire unique n'exécute que les VM du client.
Cette stratégie convient particulièrement aux licences par utilisateur ou par appareil nécessitant une migration à chaud lors des événements hôtes. Ce paramètre ne limite pas la migration des VM vers un pool fixe de serveurs physiques. Il est recommandé pour les charges de travail générales ne requérant pas de serveur physique et ne nécessitant pas de licences existantes.
Étant donné que les VM migrent à chaud vers n'importe quel serveur sans tenir compte de l'affinité de serveur existante avec cette stratégie, celle-ci ne convient pas aux scénarios nécessitant une minimisation de l'utilisation des cœurs physiques lors d'événements hôtes.
La figure suivante montre une animation de la stratégie de maintenance de l'hôte par défaut.
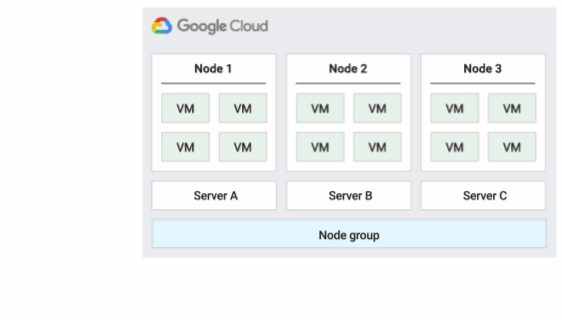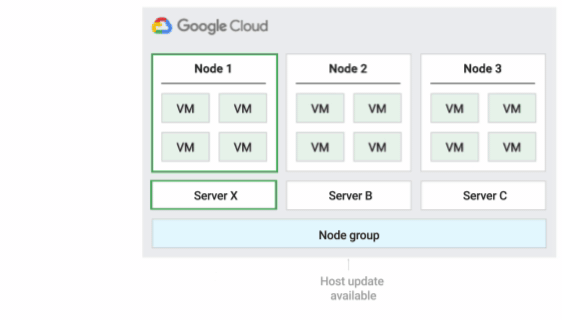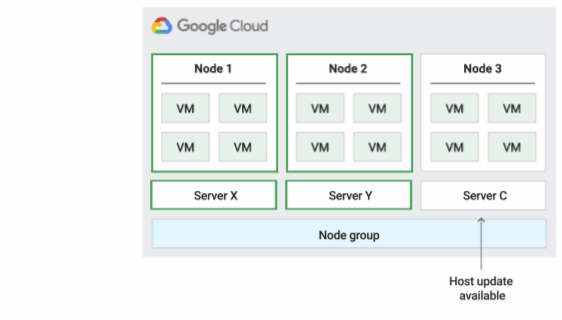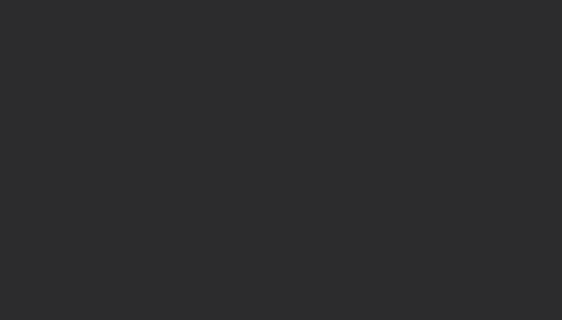
Redémarrer la stratégie de maintenance de l'hôte sur place
Lorsque vous utilisez cette stratégie de maintenance de l'hôte, Compute Engine arrête les VM pendant les événements hôtes, puis les redémarre sur le même serveur physique à l'issue de ces événements. Vous devez définir le paramètre de maintenance de l'hôte sur TERMINATE en cas d'utilisation de cette règle.
Cette stratégie est particulièrement adaptée aux charges de travail qui sont tolérantes aux pannes et qui peuvent être interrompues pendant environ une heure lors d'événements hôtes, aux charges de travail qui doivent rester sur le même serveur physique et aux charges de travail ne nécessitant pas de migration à chaud, ou si vous avez des licences basées sur le nombre de cœurs physiques ou de processeurs.
Avec cette règle, l'instance peut être attribuée au groupe de nœuds à l'aide de node-name, de node-group-name ou du libellé d'affinité de nœuds.
La figure suivante montre une animation de la règle de maintenance Redémarrer sur place.
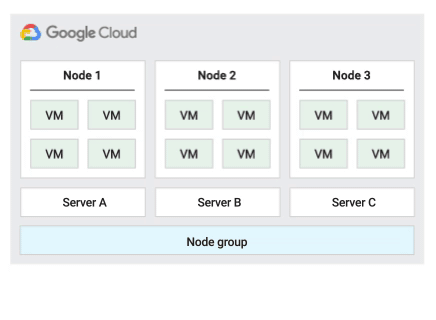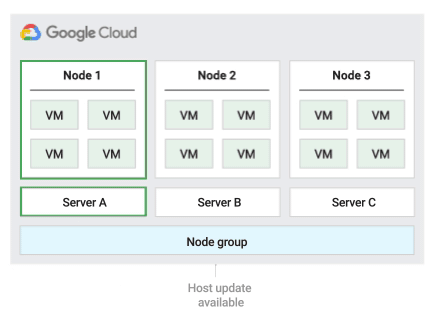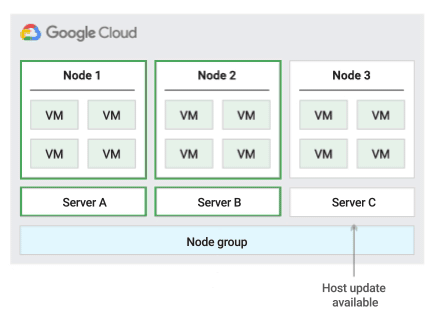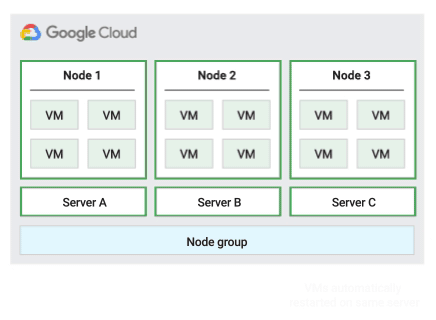
Migrer dans la stratégie de maintenance de l'hôte d'un groupe de nœuds
Lorsque vous utilisez cette stratégie de maintenance de l'hôte, Compute Engine migre à chaud les VM au sein d'un groupe fixe de serveurs physiques pendant les événements hôtes, ce qui permet de limiter le nombre de serveurs physiques uniques utilisés par les VM.
Cette stratégie convient particulièrement aux charges de travail à haute disponibilité avec des licences basées sur le nombre de cœurs physiques ou de processeurs, car avec cette stratégie de maintenance, chaque nœud à locataire unique du groupe est épinglé à un ensemble fixe de serveurs physiques, ce qui diffère de la stratégie par défaut qui permet aux VM de migrer vers n'importe quel serveur.
Pour confirmer la capacité de migration à chaud, Compute Engine réserve un nœud de retenue pour 20 nœuds que vous réservez. La figure suivante montre une animation de la stratégie de maintenance de l'hôte Migrer dans le groupe de nœuds.
Le tableau suivant indique le nombre de nœuds réservés par Compute Engine en fonction du nombre de nœuds que vous réservez pour votre groupe de nœuds.
| Nombre total de nœuds dans le groupe | Nœuds réservés pour la migration à chaud |
|---|---|
| 1 | Non applicable. Vous devez réserver au moins deux nœuds. |
| De 2 à 20 | 1 |
| De 21 à 40 | 2 |
| De 41 à 60 | 3 |
| De 61 à 80 | 4 |
| De 81 à 100 | 5 |
Épingler une instance à plusieurs groupes de nœuds
Vous pouvez associer une instance à plusieurs groupes de nœuds à l'aide du libellé d'affinité node-group-name dans les conditions suivantes :
- L'instance que vous souhaitez épingler utilise une stratégie de maintenance de l'hôte par défaut (Transférer l'instance de VM).
- La stratégie de maintenance de l'hôte de tous les groupes de nœuds auxquels vous souhaitez épingler l'instance est migrer dans le groupe de nœuds. Si vous essayez d'épingler une instance à des groupes de nœuds avec des règles de maintenance de l'hôte différentes, l'opération échoue et une erreur s'affiche.
Par exemple, si vous souhaitez épingler une instance test-node à deux groupes de nœuds node-group1 et node-group2, vérifiez les éléments suivants :
- La stratégie de maintenance de l'hôte de
test-nodeest définie sur Transférer l'instance de VM. - La stratégie de maintenance de l'hôte de
node-group1etnode-group2est migrer dans un groupe de nœuds.
Vous ne pouvez pas attribuer d'instance à un nœud spécifique avec le libellé d'affinité node-name. Vous pouvez utiliser n'importe quel libellé d'affinité de nœud personnalisé pour vos instances tant qu'il est associé à node-group-name et non à node-name.
Intervalles de maintenance
Si vous gérez des charges de travail liées, par exemple, à des bases de données affinées qui peuvent être sensibles à l'impact de la migration à chaud sur les performances, vous pouvez déterminer à quel moment la maintenance commence sur un groupe de nœuds à locataire unique en spécifiant un intervalle de maintenance lors de la création du groupe de nœuds. Vous ne pouvez pas modifier l'intervalle de maintenance après avoir créé le groupe de nœuds.
Les intervalles de maintenance sont des blocs de quatre heures pour vous permettre de spécifier à quel moment Google effectue une maintenance sur vos VM à locataire unique. Les événements de maintenance se produisent environ une fois toutes les quatre à six semaines.
L'intervalle de maintenance s'applique à toutes les VM du groupe de nœuds à locataire unique et n'est spécifié qu'au début de la maintenance. Il n'est pas garanti que les opérations de maintenance se terminent dans l'intervalle spécifié, ni que la périodicité des opérations soit respectée. Les intervalles de maintenance ne sont pas disponibles sur les groupes de nœuds pour lesquels la stratégie de maintenance de l'hôte Migrer dans le groupe de nœuds est activée.
Simuler un événement de maintenance d'hôte
Vous pouvez simuler un événement de maintenance de l'hôte pour tester le comportement de vos charges de travail exécutées sur des nœuds à locataire unique lors d'un événement de maintenance de l'hôte. Cela vous permet de voir les effets de la stratégie de maintenance de l'hôte sur la VM à locataire unique sur les applications exécutées sur les VM.
Erreurs de l'hôte
En cas de défaillance matérielle critique rare sur l'hôte (locataire unique ou mutualisé), Compute Engine effectue les opérations suivantes :
supprime le serveur physique et son identifiant unique ;
révoque l'accès de votre projet au serveur physique ;
remplace le matériel défaillant par un nouveau serveur physique doté d'un nouvel identifiant unique ;
déplace les VM du matériel défaillant vers le nœud de remplacement ;
redémarre les VM concernées si vous les avez configurées pour redémarrer automatiquement.
Affinité ou anti-affinité de nœuds
Les nœuds à locataire unique garantissent que vos VM ne partagent pas d'hôte avec les VM d'autres projets, sauf si vous utilisez des groupes de nœuds à locataire unique partagés. Les groupes de nœuds à locataire unique partagés permettent à d'autres projets de l'organisation de provisionner des VM sur le même hôte. Cependant, vous pouvez toujours regrouper plusieurs charges de travail sur le même nœud à locataire unique ou isoler vos charges de travail les unes des autres sur des nœuds différents. Par exemple, pour répondre à certaines exigences de conformité, vous devrez peut-être utiliser des libellés d'affinité pour séparer les charges de travail sensibles des charges de travail non sensibles.
Lorsque vous créez une VM, vous demandez une location unique en spécifiant l'affinité ou l'anti-affinité de nœuds, en faisant référence à un ou plusieurs libellés d'affinité de nœuds. Vous spécifiez des libellés d'affinité de nœuds personnalisés lorsque vous créez un modèle de nœud. Compute Engine inclut automatiquement des libellés d'affinité par défaut sur chaque nœud. En spécifiant l'affinité lorsque vous créez une VM, vous pouvez planifier des VM ensemble sur un ou plusieurs nœuds spécifiques d'un groupe de nœuds. En spécifiant une anti-affinité lorsque vous créez une VM, vous pouvez vous assurer que certaines VM ne sont pas planifiées ensemble sur le ou les nœuds d'un groupe de nœuds.
Les libellés d'affinité de nœuds sont des paires clé/valeur attribuées aux nœuds et sont hérités d'un modèle de nœud. Les libellés d'affinité vous permettent d'effectuer les opérations suivantes :
- Contrôler la manière dont les différentes instances de VM sont attribuées aux nœuds
- Contrôler la manière dont les instances de VM créées à partir d'un modèle, telles que celles créées par un groupe d'instances géré, sont attribuées aux nœuds
- Regrouper les instances de VM sensibles sur des nœuds ou des groupes de nœuds spécifiques, indépendamment des autres VM
Libellés d'affinité par défaut
Compute Engine attribue les libellés d'affinité par défaut suivants à chaque nœud :
- Libellé du nom du groupe de nœuds :
- Clé :
compute.googleapis.com/node-group-name - Valeur : nom du groupe de nœuds
- Clé :
- Libellé du nom du nœud :
- Clé :
compute.googleapis.com/node-name - Valeur : nom du nœud
- Clé :
- Libellé des projets avec lesquels le groupe de nœuds est partagé :
- Clé :
compute.googleapis.com/projects - Valeur : ID du projet contenant le groupe de nœuds.
- Clé :
Libellés d'affinité personnalisés
Vous pouvez créer des libellés d'affinité de nœuds personnalisés lorsque vous créez un modèle de nœud. Ces libellés d'affinité sont attribués à tous les nœuds des groupes de nœuds créés à partir du modèle de nœud. Vous ne pouvez pas ajouter d'autres libellés d'affinité personnalisés aux nœuds d'un groupe de nœuds après sa création.
Pour en savoir plus sur l'utilisation des libellés d'affinité, consultez la section Configurer l'affinité de nœuds.
Tarifs
Pour vous aider à réduire le coût de vos nœuds à locataire unique, Compute Engine propose des remises sur engagement d'utilisation et des remises automatiques proportionnelles à une utilisation soutenue. Notez que pour les frais de location unique premium, vous ne pouvez bénéficier que de remises sur engagement d'utilisation et de remises automatiques proportionnelles à une utilisation soutenue flexibles, mais pas de remises sur engagement d'utilisation basées sur les ressources.
Comme vous êtes déjà facturé pour le processeur virtuel et la mémoire de vos nœuds à locataire unique, vous ne payez pas de frais supplémentaires pour les VM que vous créez sur ces nœuds.
Si vous provisionnez des nœuds à locataire unique avec des GPU ou des disques SSD locaux, vous serez facturé pour tous les GPU ou disques SSD locaux sur chaque nœud que vous provisionnez. La prime de location unique est basée uniquement sur les processeurs virtuels et la mémoire que vous utilisez pour le nœud à locataire unique. Elle n'inclut pas les GPU ni les disques SSD locaux.
Disponibilité
Les nœuds à locataire unique sont disponibles dans certaines zones. Pour vérifier la haute disponibilité, planifiez les VM sur des nœuds à locataire unique dans différentes zones.
Avant d'utiliser des GPU ou des disques SSD locaux sur des nœuds à locataire unique, assurez-vous de disposer d'un quota de GPU ou de disques SSD locaux suffisant dans la zone où vous réservez la ressource.
Compute Engine est compatible avec les GPU sur les nœuds à locataire unique de type
n1oug2qui se trouvent dans des zones où la compatibilité avec les GPU est assurée. Le tableau suivant indique les types de GPU que vous pouvez associer à des nœudsn1etg2ainsi que le nombre de GPU que vous devez associer lorsque vous créez le modèle de nœud.Type de GPU Nombre de GPU Type de nœud à locataire unique NVIDIA L4 8 g2NVIDIA P100 4 n1NVIDIA P4 4 n1NVIDIA T4 4 n1NVIDIA V100 8 n1Compute Engine est compatible avec les disques SSD locaux sur les nœuds à locataire unique de type
n1,n2,n2detg2qui sont utilisés dans les zones compatibles avec ces séries de machines.
Restrictions
Vous ne pouvez pas utiliser de VM à locataire unique avec les séries et types de machines suivants : T2D, T2A, E2, C2D, A2, A3, A4, A4X, G4 ni avec les instances Bare Metal.
Les VM à locataire unique ne peuvent pas spécifier une configuration minimum de plate-forme de processeur.
Vous ne pouvez pas migrer une VM vers un nœud à locataire unique si cette VM spécifie une configuration minimale de plate-forme de processeur. Pour migrer une VM vers un nœud à locataire unique, supprimez la spécification minimale de la plate-forme de processeur en la définissant sur Automatique avant de mettre à jour les libellés d'affinité de nœuds de la VM.
Les nœuds à locataire unique ne sont pas compatibles avec les instances de VM préemptives.
Pour en savoir plus sur les limites d'utilisation des disques SSD locaux sur des nœuds à locataire unique, consultez la section Persistance des données des disques SSD locaux.
Pour savoir comment l'utilisation des GPU impacte la migration à chaud, consultez la section limites de la migration à chaud.
Les nœuds à locataire unique comportant des GPU ne sont pas compatibles avec les VM sans GPU.
Seuls les nœuds à locataire unique N1, N2, N2D et N4 sont compatibles avec la sursollicitation des processeurs.
Les VM C3, C3D, C4, C4A, C4D et N4 sont planifiées en fonction de l'architecture NUMA sous-jacente du nœud à locataire unique. La planification de formes de VM complètes et sous-NUMA sur le même nœud peut entraîner une fragmentation, ce qui signifie qu'une forme plus grande ne peut pas être exécutée alors que plusieurs formes plus petites totalisant les mêmes exigences en termes de ressources le peuvent.
Les nœuds à locataire unique C3 et C4 exigent que les VM aient le même ratio processeur virtuel/mémoire que le type de nœud. Par exemple, vous ne pouvez pas placer une VM
c3-standardsur un type de nœud-highmem.Vous ne pouvez pas mettre à jour la stratégie de maintenance sur un groupe de nœuds actif.
Étapes suivantes
Découvrez comment créer, configurer et utiliser vos nœuds à locataire unique.
Découvrez comment sursolliciter des processeurs sur les VM à locataire unique.
Découvrez comment apporter vos propres licences.
Consultez les Bonnes pratiques d'utilisation des nœuds à locataire unique pour exécuter des charges de travail de VM.