This document describes sole-tenant nodes. For information about how to provision VMs on sole-tenant nodes, see Provisioning VMs on sole-tenant nodes.
Sole-tenancy lets you have exclusive access to a sole-tenant node, which is a physical Compute Engine server that is dedicated to hosting only your project's VMs. Use sole-tenant nodes to keep your VMs physically separated from VMs in other projects, or to group your VMs together on the same host hardware as shown in the following diagram. You can also create a sole-tenant node group and specify whether you want to share it with other projects or with the entire organization.

VMs running on sole-tenant nodes can use the same Compute Engine features as other VMs, including transparent scheduling and block storage, but with an added layer of hardware isolation. To give you full control over the VMs on the physical server, each sole-tenant node maintains a one-to-one mapping to the physical server that is backing the node.
Within a sole-tenant node, you can provision multiple VMs on machine types of various sizes, which lets you efficiently use the underlying resources of the dedicated host hardware. Also, if you choose not to share the host hardware with other projects, you can meet security or compliance requirements with workloads that require physical isolation from other workloads or VMs. If your workload requires sole tenancy only temporarily, you can modify VM tenancy as necessary.
Sole-tenant nodes can help you meet dedicated hardware requirements for bring your own license (BYOL) scenarios that require per-core or per-processor licenses. When you use sole-tenant nodes, you have some visibility into the underlying hardware, which lets you track core and processor usage. To track this usage, Compute Engine reports the ID of the physical server on which a VM is scheduled. Then, by using Cloud Logging, you can view the historical server usage of a VM.
To optimize the use of the host hardware, you can do the following:
Through a configurable host maintenance policy, you can control the behavior of sole-tenant VMs while their host is undergoing maintenance. You can specify when maintenance occurs, and whether the VMs maintain affinity with a specific physical server or are moved to other sole-tenant nodes within a node group.
Workload considerations
The following types of workloads might benefit from using sole-tenant nodes:
Gaming workloads with performance requirements
Finance or healthcare workloads with security and compliance requirements
Windows workloads with licensing requirements
Machine learning, data processing, or image rendering workloads. For these workloads, consider reserving GPUs.
Workloads requiring increased I/O operations per second (IOPS) and decreased latency, or workloads that use temporary storage in the form of caches, processing space, or low-value data. For these workloads, consider reserving Local SSD disks.
Node templates
A node template is a regional resource that defines the properties of each node in a node group. When you create a node group from a node template, the properties of the node template are immutably copied to each node in the node group.
When you create a node template you must specify a node type. You can optionally specify node affinity labels when you create a node template. You can only specify node affinity labels on a node template. You can't specify node affinity labels on a node group.
Node types
When configuring a node template, specify a node type to apply to all nodes
within a node group created based on the node template. The sole-tenant node
type, referenced by the node template, specifies the total amount of vCPU cores
and memory for nodes created in node groups that use that template. For example,
the n2-node-80-640 node type has 80 vCPUs and 640 GB of memory.
The VMs that you add to a sole-tenant node must have the same machine type as
the node type that you specify in the node template. For example, n2
sole-tenant node types are only compatible with VMs created with the n2
machine type. You can add VMs to a sole-tenant node until the total amount of
vCPUs or memory exceeds the capacity of the node.
When you create a node group using a node template, each node in the node group
inherits the node template's node type specifications. A node type applies to
each individual node within a node group, not to all of the nodes in the group
uniformly. So, if you create a node group with two nodes that are both of the
n2-node-80-640 node type, each node is allocated 80 vCPUs and 640 GB of
memory.
Depending on your workload requirements, you might fill the node with multiple smaller VMs running on machine types of various sizes, including predefined machine types, custom machine types, and machine types with extended memory. When a node is full, you cannot schedule additional VMs on that node.
The following table displays the available node types. To see a list of the
node types available for your project, run the
gcloud compute sole-tenancy node-types list
command or create a
nodeTypes.list REST request.
| Node type | Processor | vCPU | GB | vCPU:GB | Sockets | Cores:Socket | Total cores | Max VMs allowed |
|---|---|---|---|---|---|---|---|---|
a3-highgpu-node-208-1872-lssd 1 |
Sapphire Rapids | 208 | 1872 | 1:9 | 2 | 56 | 112 | 8 |
a3-megagpu-node-208-1872-lssd 1 |
Sapphire Rapids | 208 | 1872 | 1:9 | 2 | 56 | 112 | 1 |
c2-node-60-240 |
Cascade Lake | 60 | 240 | 1:4 | 2 | 18 | 36 | 15 |
c3-node-176-352 |
Sapphire Rapids | 176 | 352 | 1:2 | 2 | 48 | 96 | 44 |
c3-node-176-704 |
Sapphire Rapids | 176 | 704 | 1:4 | 2 | 48 | 96 | 44 |
c3-node-176-704-lssd |
Sapphire Rapids | 176 | 704 | 1:4 | 2 | 48 | 96 | 40 |
c3-node-176-1408 |
Sapphire Rapids | 176 | 1408 | 1:8 | 2 | 48 | 96 | 44 |
c3d-node-360-708 |
AMD EPYC Genoa | 360 | 708 | 1:2 | 2 | 96 | 192 | 34 |
c3d-node-360-1440 |
AMD EPYC Genoa | 360 | 1440 | 1:4 | 2 | 96 | 192 | 40 |
c3d-node-360-2880 |
AMD EPYC Genoa | 360 | 2880 | 1:8 | 2 | 96 | 192 | 40 |
c4-node-192-384 |
Emerald Rapids | 192 | 384 | 1:2 | 2 | 60 | 120 | 40 |
c4-node-192-720 |
Emerald Rapids | 192 | 720 | 1:3.75 | 2 | 60 | 120 | 30 |
c4-node-192-1488 |
Emerald Rapids | 192 | 1,488 | 1:7.75 | 2 | 60 | 120 | 30 |
c4a-node-72-144 |
Google Axion | 72 | 144 | 1:2 | 1 | 80 | 80 | 22 |
c4a-node-72-288 |
Google Axion | 72 | 288 | 1:4 | 1 | 80 | 80 | 22 |
c4a-node-72-576 |
Google Axion | 72 | 576 | 1:8 | 1 | 80 | 80 | 36 |
c4d-node-384-720 |
AMD EPYC Turin | 384 | 744 | 1:2 | 2 | 96 | 192 | 24 |
c4d-node-384-1488 |
AMD EPYC Turin | 384 | 1488 | 1:4 | 2 | 96 | 192 | 25 |
c4d-node-384-3024 |
AMD EPYC Turin | 384 | 3024 | 1:8 | 2 | 96 | 192 | 25 |
g2-node-96-384 |
Cascade Lake | 96 | 384 | 1:4 | 2 | 28 | 56 | 8 |
g2-node-96-432 |
Cascade Lake | 96 | 432 | 1:4.5 | 2 | 28 | 56 | 8 |
h3-node-88-352 |
Sapphire Rapids | 88 | 352 | 1:4 | 2 | 48 | 96 | 1 |
m1-node-96-1433 |
Skylake | 96 | 1433 | 1:14.93 | 2 | 28 | 56 | 1 |
m1-node-160-3844 |
Broadwell E7 | 160 | 3844 | 1:24 | 4 | 22 | 88 | 4 |
m2-node-416-8832 |
Cascade Lake | 416 | 8832 | 1:21.23 | 8 | 28 | 224 | 1 |
m2-node-416-11776 |
Cascade Lake | 416 | 11776 | 1:28.31 | 8 | 28 | 224 | 2 |
m3-node-128-1952 |
Ice Lake | 128 | 1952 | 1:15.25 | 2 | 36 | 72 | 2 |
m3-node-128-3904 |
Ice Lake | 128 | 3904 | 1:30.5 | 2 | 36 | 72 | 2 |
m4-node-224-2976 |
Emerald Rapids | 224 | 2976 | 1:13.3 | 2 | 112 | 224 | 1 |
m4-node-224-5952 |
Emerald Rapids | 224 | 5952 | 1:26.7 | 2 | 112 | 224 | 1 |
n1-node-96-624 |
Skylake | 96 | 624 | 1:6.5 | 2 | 28 | 56 | 96 |
n2-node-80-640 |
Cascade Lake | 80 | 640 | 1:8 | 2 | 24 | 48 | 80 |
n2-node-128-864 |
Ice Lake | 128 | 864 | 1:6.75 | 2 | 36 | 72 | 128 |
n2d-node-224-896 |
AMD EPYC Rome | 224 | 896 | 1:4 | 2 | 64 | 128 | 112 |
n2d-node-224-1792 |
AMD EPYC Milan | 224 | 1792 | 1:8 | 2 | 64 | 128 | 112 |
n4-node-224-1372 |
Emerald Rapids | 224 | 1372 | 1:6 | 2 | 60 | 120 | 90 |
1A3 high and mega node types:
For A3 node types specified without a suffix or with the -lssd
suffix, Local SSD disks are attached by default. If you don't want Local
SSD disks attached, specify the node type using the
-nolssd suffix. For example, a3-megagpu-node-208-1872-nolssd.
For information about the prices of these node types, see sole-tenant node pricing.
All nodes let you schedule VMs of different shapes. Node n type are
general-purpose nodes, on which you can schedule
custom machine type
instances. For recommendations about which node type to choose, see
Recommendations for machine types.
For information about performance, see
CPU platforms.
Node groups and VM provisioning
Sole-tenant node templates define the properties of a node group, and you must create a node template before creating a node group in a Google Cloud zone. When you create a group, specify the host maintenance policy for VMs on the node group, the number of nodes for the node group, and whether to share it with other projects or with the entire organization.
A node group can have zero or more nodes; for example, you can reduce the number of nodes in a node group to zero when you don't need to run any VMs on nodes in the group, or you can enable the node group autoscaler to manage the size of the node group automatically.
Before provisioning VMs on sole-tenant nodes, you must create a sole-tenant node group. A node group is a homogeneous set of sole-tenant nodes in a specific zone. Node groups can contain multiple VMs from the same machine series running on machine types of various sizes, as long as the machine type has 2 or more vCPUs.
When you create a node group, enable autoscaling so that the size of the group adjusts automatically to meet the requirements of your workload. If your workload requirements are static, you can manually specify the size of the node group.
After creating a node group, you can provision VMs on the group or on a specific node within the group. For further control, use node affinity labels to schedule VMs on any node with matching affinity labels.
After you've provisioned VMs on node groups, and optionally assigned affinity labels to provision VMs on specific node groups or nodes, consider labeling your resources to help manage your VMs. Labels are key-value pairs that can help you categorize your VMs so that you can view them in aggregate for reasons such as billing. For example, you can use labels to mark the role of a VM, its tenancy, the license type, or its location.
Host maintenance policy
Depending on your licensing scenarios and workloads, you might want to limit the number of physical cores used by your VMs. The host maintenance policy you choose might depend on, for example, your licensing or compliance requirements, or, you might want to choose a policy that lets you limit usage of physical servers. With all of these policies, your VMs remain on dedicated hardware.
When you schedule VMs on sole-tenant nodes, you can choose from the following three different host maintenance policy options, which let you determine how and whether Compute Engine live migrates VMs during host events, which occur approximately every 4 to 6 weeks. During maintenance, Compute Engine live migrates, as a group, all of the VMs on the host to a different sole-tenant node, but, in some cases, Compute Engine might break up the VMs into smaller groups and live migrate each smaller group of VMs to separate sole-tenant nodes.
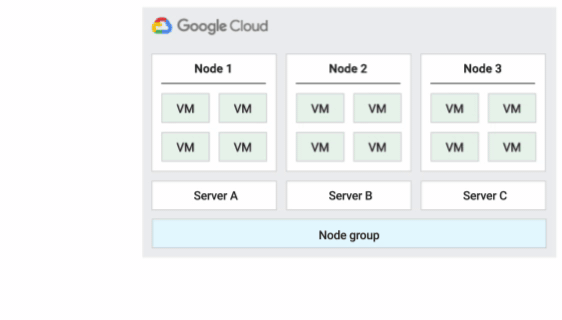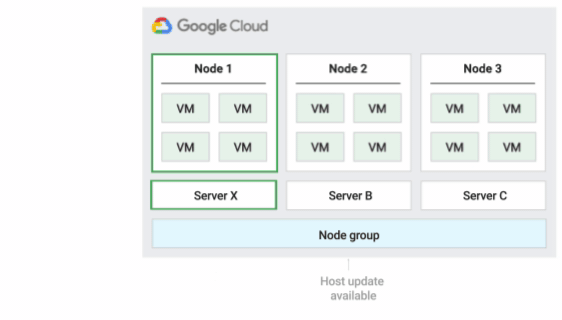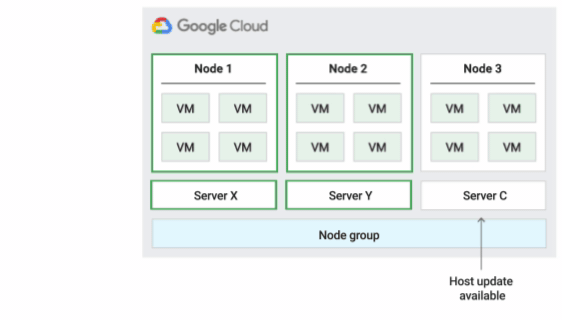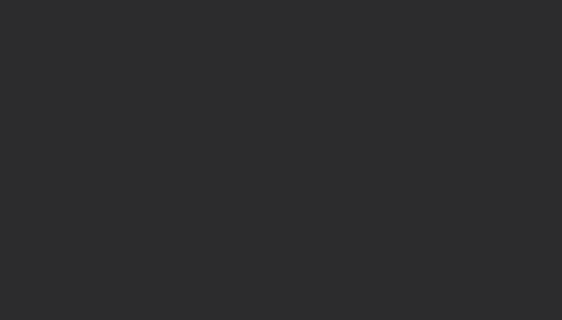
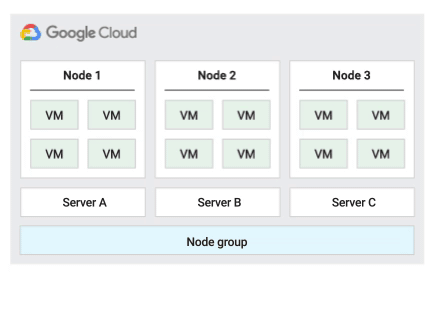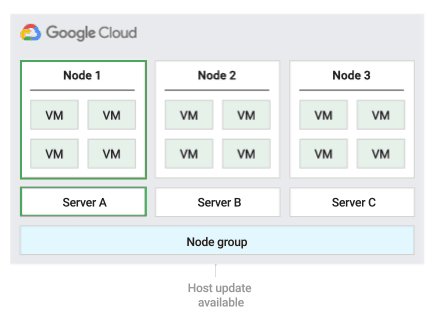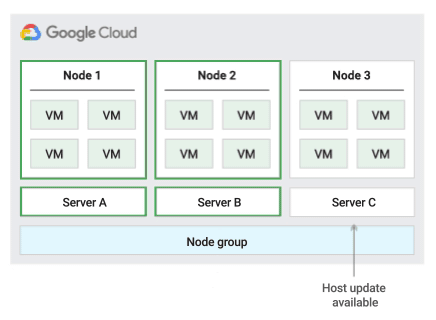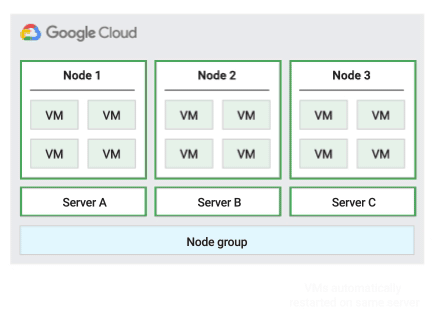
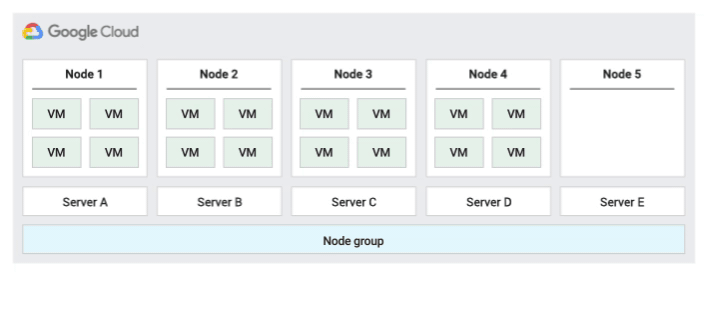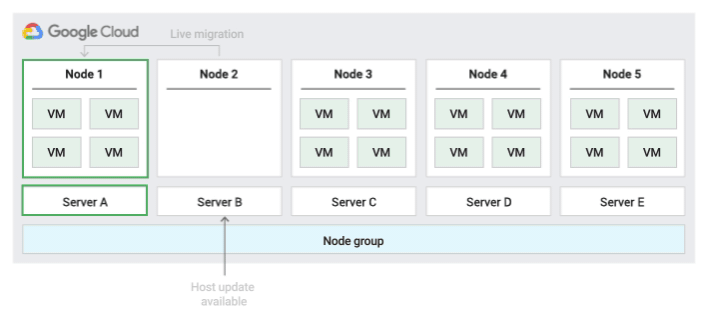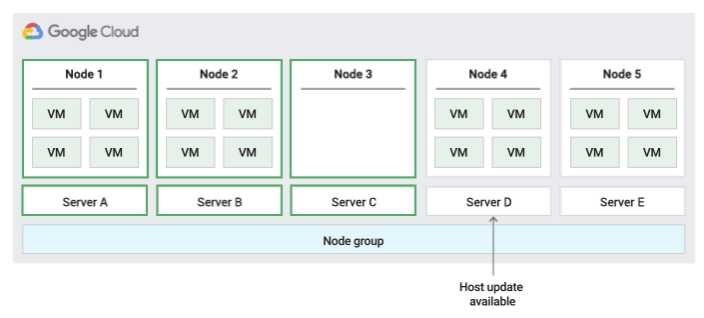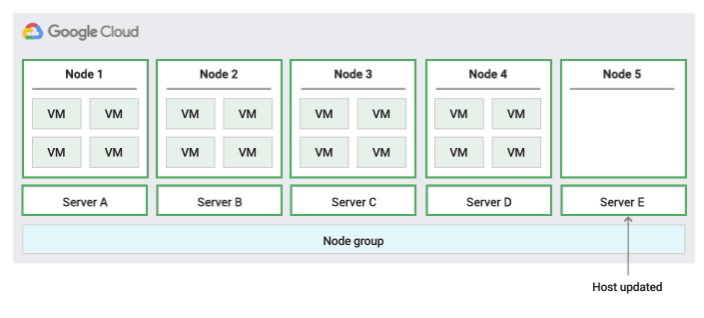
Default host maintenance policy
This is the default host maintenance policy, and VMs on nodes groups configured with this policy follow traditional maintenance behavior for non-sole-tenant VMs. That is, depending on the on-host maintenance setting of the VM's host, VMs live migrate to a new sole-tenant node in the node group before a host maintenance event, and this new sole-tenant node only runs the customer's VMs.
This policy is most suitable for per-user or per-device licenses that require live migration during host events. This setting doesn't restrict migration of VMs to within a fixed pool of physical servers, and is recommended for general workloads without physical server requirements and that don't require existing licenses.
Because VMs live migrate to any server without considering existing server affinity with this policy, this policy is not suitable for scenarios requiring minimization of the use of physical cores during host events.
The following figure shows an animation of the Default host maintenance policy.
Restart in place host maintenance policy
When you use this host maintenance policy, Compute Engine stops VMs
during host events, and then restarts the VMs on the same physical server after
the host event. You must set the VM's on host maintenance setting to
TERMINATE when using this policy.
This policy is most suitable for workloads that are fault-tolerant and can experience approximately one hour of downtime during host events, workloads that must remain on the same physical server, workloads that don't require live migration, or if you have licenses that are based on the number of physical cores or processors.
With this policy, the instance can be assigned to the node group using
node-name, node-group-name, or node affinity label.
The following figure shows an animation of the Restart in place maintenance policy.
Migrate within node group host maintenance policy
When using this host maintenance policy, Compute Engine live migrates VMs within a fixed-sized group of physical servers during host events, which helps limit the number of unique physical servers used by the VM.
This policy is most suitable for high-availability workloads with licenses that are based on the number of physical cores or processors, because with this host maintenance policy, each sole-tenant node in the group is pinned to a fixed set of physical servers, which is different than the default policy that lets VMs migrate to any server.
To confirm the capacity for live migration, Compute Engine reserves 1 holdback node for every 20 nodes that you reserve. The following figure shows an animation of the Migrate within node group host maintenance policy.
The following table shows how many holdback nodes Compute Engine reserves depending on how many nodes you reserve for your node group.
| Total nodes in group | Holdback nodes reserved for live migration |
|---|---|
| 1 | Not applicable. Must reserve at least 2 nodes. |
| 2 to 20 | 1 |
| 21 to 40 | 2 |
| 41 to 60 | 3 |
| 61 to 80 | 4 |
| 81 to 100 | 5 |
Pin an instance to multiple node groups
You can pin an instance to multiple node groups using the node-group-name
affinity label
under the following conditions:
- The instance that you want to pin is using a default host maintenance policy (Migrate VM instance).
- The host maintenance policy of all the node groups that you want to pin the instance to is migrate within node group. If you try to pin an instance to node groups with different host maintenance policies, the operation fails with an error.
For example, if you want to pin an instance test-node to two node groups
node-group1 and node-group2, verify the following:
- The host maintenance policy of
test-nodeis Migrate VM instance. - The host maintenance policy of
node-group1andnode-group2is migrate within node group.
You cannot assign an instance to any specific node with the affinity label
node-name. You can use any custom node affinity labels for your instances as
long as they are assigned the node-group-name and not the node-name.
Maintenance windows
If you are managing workloads—for example—finely tuned databases, that might be sensitive to the performance impact of live migration, then you can determine when maintenance begins on a sole-tenant node group by specifying a maintenance window when you create the node group. You can't modify the maintenance window after you create the node group.
Maintenance windows are 4-hour blocks of time that you can use to specify when Google performs maintenance on your sole-tenant VMs. Maintenance events occur approximately once every 4 to 6 weeks.
The maintenance window applies to all VMs in the sole-tenant node group, and it only specifies when the maintenance begins. Maintenance is not guaranteed to finish during the maintenance window, and there is no guarantee on how frequently maintenance occurs. Maintenance windows are not supported on node groups with the Migrate within node group host maintenance policy.
Simulate a host maintenance event
You can simulate a host maintenance event to test how your workloads that are running on sole-tenant nodes behave during a host maintenance event. This lets you see the effects of the sole-tenant VM's host maintenance policy on the applications running on the VMs.
Host errors
When there is a rare critical hardware failure on the host—sole-tenant or multi-tenant—Compute Engine does the following:
Retires the physical server and its unique identifier.
Revokes your project's access to the physical server.
Replaces the failed hardware with a new physical server that has a new unique identifier.
Moves the VMs from the failed hardware to the replacement node.
Restarts the affected VMs if you configured them to automatically restart.
Node affinity and anti-affinity
Sole-tenant nodes make sure that your VMs don't share host with VMs from other projects unless you use shared sole-tenant node groups. With shared sole-tenant node groups, other projects within the organization can provision VMs on the same host. However, you still might want to group several workloads together on the same sole-tenant node or isolate your workloads from one another on different nodes. For example, to help meet some compliance requirements, you might need to use affinity labels to separate sensitive workloads from non-sensitive workloads.
When you create a VM, you request sole-tenancy by specifying node affinity or anti-affinity, referencing one or more node affinity labels. You specify custom node affinity labels when you create a node template, and Compute Engine automatically includes some default affinity labels on each node. By specifying affinity when you create a VM, you can schedule VMs together on a specific node or nodes in a node group. By specifying anti-affinity when you create a VM, you can make sure that certain VMs are not scheduled together on the same node or nodes in a node group.
Node affinity labels are key-value pairs assigned to nodes, and are inherited from a node template. Affinity labels let you:
- Control how individual VM instances are assigned to nodes.
- Control how VM instances created from a template, such as those created by a managed instance group, are assigned to nodes.
- Group sensitive VM instances on specific nodes or node groups, separate from other VMs.
Default affinity labels
Compute Engine assigns the following default affinity labels to each node:
- A label for the node group name:
- Key:
compute.googleapis.com/node-group-name - Value: Name of the node group.
- Key:
- A label for the node name:
- Key:
compute.googleapis.com/node-name - Value: Name of the individual node.
- Key:
- A label for the projects the node group is shared with:
- Key:
compute.googleapis.com/projects - Value: Project ID of the project containing the node group.
- Key:
Custom affinity labels
You can create custom node affinity labels when you create a node template. These affinity labels are assigned to all nodes in node groups created from the node template. You can't add more custom affinity labels to nodes in a node group after the node group has been created.
For information about how to use affinity labels, see Configuring node affinity.
Pricing
To help you to minimize the cost of your sole-tenant nodes, Compute Engine provides committed use discounts (CUDs) and sustained use discounts (SUDs). Note that for sole-tenancy premium charges, you can receive only flexible CUDs and SUDs, but not resource-based CUDs.
Because you are already billed for the vCPU and memory of your sole-tenant nodes, you don't pay extra for the VMs that you create on those nodes.
If you provision sole-tenant nodes with GPUs or Local SSD disks, you are billed for all of the GPUs or Local SSD disks on each node that you provision. The sole-tenancy premium is based only on the vCPUs and memory that you use for the sole-tenant node, and doesn't include GPUs or Local SSD disks.
For more information, see Sole-tenant node pricing.
Availability
Sole-tenant nodes are available in select zones. To verify high-availability, schedule VMs on sole-tenant nodes in different zones.
Before using GPUs or Local SSD disks on sole-tenant nodes, make sure you have enough GPU or Local SSD quota in the zone where you are reserving the resource.
Compute Engine supports GPUs on
n1,g2,a3-highgpu, anda3-megagpusole-tenant node types that are in zones with GPU support. The following table shows the types of GPUs that you can attach ton1,g2, anda3nodes and how many GPUs you must attach when you create the node template.GPU type GPU quantity Sole-tenant node type NVIDIA H100 8 a3-highgpuNVIDIA H100 8 a3-megagpuNVIDIA L4 8 g2NVIDIA P100 4 n1NVIDIA P4 4 n1NVIDIA T4 4 n1NVIDIA V100 8 n1Compute Engine supports Local SSD disks on
n1,n2,n2d,g2,a3-highgpu, anda3-megagpusole-tenant node types that are used in zones that support those machine series.
Restrictions
You can't use sole-tenant VMs with the follow machine series and types: T2D, T2A, E2, C2D, A2, A3 Ultra, A3 Edge, A4, A4X, G4, or bare metal instances.
Sole-tenant VMs can't specify a minimum CPU platform.
You can't migrate a VM to a sole-tenant node if that VM specifies a minimum CPU platform. To migrate a VM to a sole-tenant node, remove the minimum CPU platform specification by setting it to automatic before updating the VM's node affinity labels.
Sole-tenant nodes don't support preemptible VM instances.
For information about the limitations of using Local SSD disks on sole-tenant nodes, see Local SSD data persistence.
For information about how using GPUs affects live migration, see the limitations of live migration.
Sole-tenant nodes with GPUs don't support VMs without GPUs.
Only N1, N2, N2D, and N4 sole-tenant nodes support overcommitting CPUs.
C3, C3D, C4, C4A, C4D, and N4 VMs are scheduled with alignment to the underlying NUMA architecture of the sole tenant node. Scheduling full and sub-NUMA VM shapes on the same node might lead to fragmentation, whereby a larger shape can't be run while several smaller shapes totaling the same resource requirements can.
C3 and C4 sole-tenant nodes require that VMs have the same vCPU-to-memory ratio as the node type—for example—you can't place a
c3-standardVM on a-highmemnode type.You can't update the maintenance policy on a live node group.
What's next
Learn how to create, configure, and consume your sole-tenant nodes.
Learn how to overcommit CPUs on sole-tenant VMs.
Learn how to bring your own licenses.
Review our best practices for using sole-tenant nodes to run VM workloads.