Este tutorial descreve como ativar a replicação assíncrona balanceada do Hyperdisk em duas regiões do Google Cloud como uma solução de recuperação de desastres (DR) e como criar as instâncias de DR em caso de desastre.
As instâncias de cluster de failover (FCI) do Microsoft SQL Server são uma única instância do SQL Server de alta disponibilidade implantada em vários nós do cluster de failover do Windows Server (WSFC). A qualquer momento, um dos nós do cluster hospeda ativamente a instância do SQL. Em caso de interrupção zonal ou problema na VM, o WSFC transfere automaticamente a propriedade dos recursos da instância para outro nó no cluster, permitindo que os clientes se reconectem O FCI do SQL Server exige que os dados estejam localizados em discos compartilhados para que possam ser acessados em todos os nós do WSFC.
Para garantir que a implantação do SQL Server possa resistir a uma interrupção regional, replique os dados do disco da região principal em uma região secundária ativando a replicação assíncrona. Este tutorial usa discos de vários gravadores de alta disponibilidade equilibrada do Hyperdisk para ativar a replicação assíncrona em duas regiões Google Cloud como uma solução de recuperação de desastres (DR) para FCI do SQL Server e como criar as instâncias de DR em caso de desastre. Neste documento, um desastre é um evento em que um cluster de banco de dados primário falha ou fica indisponível porque a região do cluster fica indisponível, talvez devido a um desastre natural.
Este tutorial se destina a arquitetos de bancos de dados, administradores e engenheiros.
Recuperação de desastres em Google Cloud
A DR no Google Cloud envolve manter o acesso contínuo aos dados quando uma região falha ou fica inacessível. Há várias opções de implantação para o site de DR e elas serão determinadas pelos requisitos do objetivo do ponto de recuperação (RPO) e do objetivo do tempo de recuperação (RTO). Este tutorial aborda uma das opções em que os discos anexados à máquina virtual são replicados da região principal para a região de DR.
Recuperação de desastres usando a replicação assíncrona do Hyperdisk
A replicação assíncrona do Hyperdisk é uma opção de armazenamento que oferece uma cópia de armazenamento assíncrona para replicação de discos entre duas regiões. No caso improvável de uma interrupção de serviço regional, a replicação assíncrona do Hyperdisk permite fazer failover dos dados para uma região secundária e reiniciar as cargas de trabalho nessa região.
A replicação assíncrona do Hyperdisk replica dados de um disco que está conectado a uma carga de trabalho em execução, chamada de disco principal, até um disco separado localizado em outra região. O disco que recebe a replicação é chamado de disco secundário. A região em que o disco principal está sendo executado é chamada de região primária, e a região em que o disco secundário está sendo executado é a região secundária. Para garantir que as réplicas de todos os discos conectados a cada nó do SQL Server tenham dados do mesmo ponto no tempo, os discos são adicionados a um grupo de consistência. Os grupos de consistência permitem realizar DR e testes de DR em vários discos.
Arquitetura de recuperação de desastres
Para a replicação assíncrona do Hyperdisk, o diagrama a seguir mostra uma arquitetura mínima que oferece suporte à alta disponibilidade do banco de dados em uma região primária, R1, e à replicação de disco da região primária para a região secundária, R2.
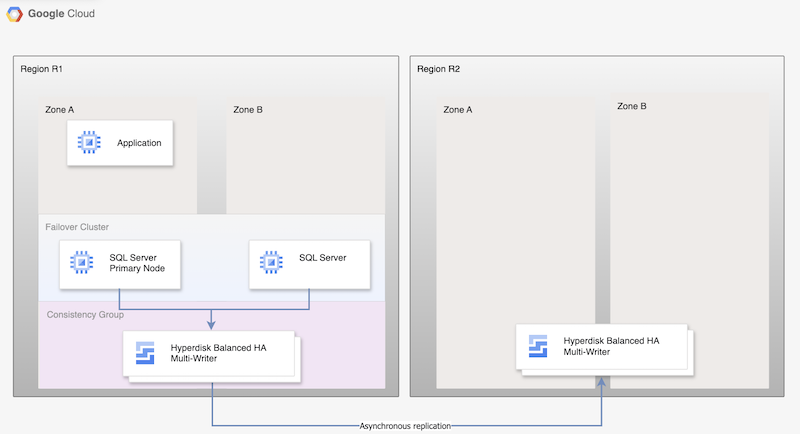
Figura 1. Arquitetura de recuperação de desastres com o Microsoft SQL Server e a replicação assíncrona do Hyperdisk
Essa arquitetura funciona da seguinte forma:
- Duas instâncias do Microsoft SQL Server, uma primária e uma de espera, fazem parte de um cluster de FCI e estão localizadas na região primária (R1), mas em zonas diferentes (zonas A e B). As duas instâncias compartilham um disco do Hyperdisk Balanced High Availability, permitindo o acesso aos dados das duas VMs. Para instruções, consulte Como configurar um cluster FCI do SQL Server com o modo de vários gravadores de alta disponibilidade balanceada do hiperdisco.
- Os discos dos dois nós SQL são adicionados aos grupos de consistência e replicados para a região de DR, R2. O Compute Engine replica os dados de forma assíncrona de R1 para R2.
- A replicação assíncrona replica apenas os dados nos discos para o R2 e não replica os metadados da VM. Durante a DR, novas VMs são criadas e os discos replicados existentes são anexados às VMs para colocar os nós on-line.
Processo de recuperação de desastres
O processo de DR descreve as etapas operacionais que precisam ser executadas depois que uma região fica indisponível para retomar a carga de trabalho em outra região.
Um processo básico de DR do banco de dados consiste nas seguintes etapas:
- A primeira região (R1), que está executando a instância primária do banco de dados, fica indisponível.
- A equipe de operações reconhece e confirma formalmente o desastre e decide se um failover é necessário.
- Se for necessário um failover, encerre a replicação entre os discos principal e secundário. Uma nova VM é criada com base nas réplicas do disco e colocada on-line.
- O banco de dados na região de DR, R2, é validado e colocado on-line. O banco de dados em R2 se torna o novo banco de dados principal, permitindo a conectividade.
- Os usuários retomam o processamento no novo banco de dados primário e acessam a instância primária na R2.
Embora esse processo básico estabeleça um banco de dados principal de trabalho novamente, ele não estabelece uma arquitetura de alta disponibilidade completa, porque o novo banco de dados principal não está sendo replicado.
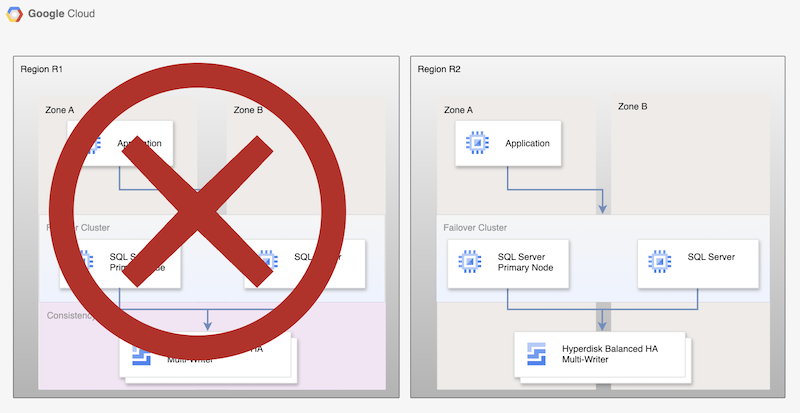
Figura 2. Implantação do SQL Server após a recuperação de desastres com a replicação assíncrona do disco permanente
Fallback para uma região recuperada
Quando a região primária (R1) voltar a ficar on-line, você poderá planejar e executar o processo de failback. O processo de failback consiste em todas as etapas descritas neste tutorial; mas, neste caso, R2 é a origem e R1 é a região de recuperação.
Escolher uma edição do SQL Server
Este tutorial considera as seguintes versões do Microsoft SQL Server:
- SQL Server 2016 Enterprise e Standard Edition
- SQL Server 2017 Enterprise e Standard Edition
- SQL Server 2019 Enterprise e Standard Edition
- SQL Server 2022 Enterprise e Standard Edition
O tutorial usa a instância de cluster de failover do SQL Server com o disco Hyperdisk equilibrado de alta disponibilidade.
Se você não precisar dos recursos do SQL Server Enterprise, use a edição Standard do SQL Server:
As versões 2016, 2017, 2019 e 2022 do SQL Server têm o Microsoft SQL Server Management Studio instalado na imagem. Você não precisa instalá-lo separadamente. No entanto, em um ambiente de produção, recomendamos instalar uma instância do Microsoft SQL Server Management Studio em uma VM separada em cada região. Se você configurar um ambiente de alta disponibilidade, convém instalar o Microsoft SQL Server Management Studio uma vez em cada zona para garantir que ele continue disponível se outra zona ficar indisponível.
Configurar a recuperação de desastres para o Microsoft SQL Server
Este tutorial usa a imagem sql-ent-2022-win-2022 do Microsoft SQL Server
Enterprise.
Para obter uma lista completa de imagens, consulte Imagens do SO.
Configurar um cluster de alta disponibilidade de duas instâncias
Para configurar a replicação de disco para SQL Server entre duas regiões, primeiro
crie um cluster de alta disponibilidade de duas instâncias em uma região.
Uma instância serve como primária e a outra como de espera. Para realizar esta etapa, siga as instruções em
Como configurar um cluster de FCI do SQL Server com o modo de vários gravadores de alta disponibilidade balanceada do Hyperdisk.
Neste tutorial, usamos us-central1 para a região primária R1.
Se você seguiu as etapas em
Como configurar um cluster de FCI do SQL Server com o modo de gravação múltipla de alta disponibilidade balanceada do Hyperdisk,
você criou duas instâncias do SQL Server na mesma região (us-central1). Você implantou uma instância primária do SQL Server (node-1) em
us-central1-a e uma instância de espera (node-2) em us-central1-b.
Ativar a replicação assíncrona de disco
Depois de criar e configurar todas as VMs, ative a replicação de disco entre as duas regiões seguindo estas etapas:
Crie um grupo de consistência para os dois nós do SQL Server e o nó que hospeda as funções de testemunha e controlador de domínio. Uma das limitações dos grupos de consistência é que eles não podem abranger várias zonas. Portanto, é necessário adicionar cada nó a um grupo de consistência separado.
gcloud compute resource-policies create disk-consistency-group node-1-disk-const-grp \ --region=$REGION gcloud compute resource-policies create disk-consistency-group node-2-disk-const-grp \ --region=$REGION gcloud compute resource-policies create disk-consistency-group witness-disk-const-grp \ --region=$REGION gcloud compute resource-policies create disk-consistency-group multiwriter-disk-const-grp \ --region=$REGION
Adicione os discos das VMs primárias e de espera aos grupos de consistência correspondentes.
gcloud compute disks add-resource-policies node-1 \ --zone=$REGION-a \ --resource-policies=node-1-disk-const-grp gcloud compute disks add-resource-policies node-2 \ --zone=$REGION-b \ --resource-policies=node-2-disk-const-grp gcloud compute disks add-resource-policies mw-datadisk-1 \ --region=$REGION \ --resource-policies=multiwriter-disk-const-grp gcloud compute disks add-resource-policies witness \ --zone=$REGION-c \ --resource-policies=witness-disk-const-grp
Crie discos secundários em branco na região secundária.
DR_REGION="us-west1" gcloud compute disks create node-1-replica \ --zone=$DR_REGION-a \ --size=50 \ --primary-disk=node-1 \ --primary-disk-zone=$REGION-a gcloud compute disks create node-2-replica \ --zone=$DR_REGION-b \ --size=50 \ --primary-disk=node-2 \ --primary-disk-zone=$REGION-b gcloud compute disks create multiwriter-datadisk-1-replica \ --replica-zones=$DR_REGION-a,$DR_REGION-b \ --size=$PD_SIZE \ --type=hyperdisk-balanced-high-availability \ --access-mode READ_WRITE_MANY \ --primary-disk=multiwriter-datadisk-1 \ --primary-disk-region=$REGION gcloud compute disks create witness-replica \ --zone=$DR_REGION-c \ --size=50 \ --primary-disk=witness \ --primary-disk-zone=$REGION-c
Inicie a replicação do disco. Os dados são replicados do disco principal para o disco em branco recém-criado na região de DR.
gcloud compute disks start-async-replication node-1 \ --zone=$REGION-a \ --secondary-disk=node-1-replica \ --secondary-disk-zone=$DR_REGION-a gcloud compute disks start-async-replication node-2 \ --zone=$REGION-b \ --secondary-disk=node-2-replica \ --secondary-disk-zone=$DR_REGION-b gcloud compute disks start-async-replication multiwriter-datadisk-1 \ --region=$REGION \ --secondary-disk=multiwriter-datadisk-1-replica \ --secondary-disk-region=$DR_REGION gcloud compute disks start-async-replication witness \ --zone=$REGION-c \ --secondary-disk=witness-replica \ --secondary-disk-zone=$DR_REGION-c
Os dados devem estar sendo replicados entre regiões neste ponto.
O status de replicação de cada disco precisa indicar Active.
Simular uma recuperação de desastres
Nesta seção, você vai testar a arquitetura de recuperação de desastres configurada neste tutorial.
Simular uma interrupção de serviço e executar um failover de recuperação de desastres
Durante um failover, você cria novas VMs na região de DR e anexa os discos replicados a elas. Para simplificar o failover, você pode usar uma nuvem privada virtual (VPC) diferente na região de DR para a recuperação a fim de que o mesmo endereço IP seja usado.
Antes de iniciar o failover, verifique se node-1 é o nó principal do
grupo de disponibilidade AlwaysOn que você criou. Ative o controlador de domínio e o
nó principal do SQL Server para evitar problemas de sincronização de dados, uma vez que os dois nós são protegidos por dois grupos de consistência separados.
Para simular uma interrupção, siga estas etapas:
Crie uma VPC de recuperação.
DRVPC_NAME="default-dr" DRSUBNET_NAME="default-recovery" gcloud compute networks create $DRVPC_NAME \ --subnet-mode=custom CIDR=$(gcloud compute networks subnets describe default \ --region=$REGION --format=value\(ipCidrRange\)) gcloud compute networks subnets create $DRSUBNET_NAME \ --network=$DRVPC_NAME --range=$CIDR --region=$DR_REGION
Encerre ou interrompa a replicação de dados.
PROJECT=$(gcloud config get-value project) gcloud compute disks stop-group-async-replication projects/$PROJECT/regions/$REGION/resourcePolicies/node-1-disk-const-grp \ --zone=$REGION-a gcloud compute disks stop-group-async-replication projects/$PROJECT/regions/$REGION/resourcePolicies/node-2-disk-const-grp \ --zone=$REGION-b gcloud compute disks stop-group-async-replication projects/$PROJECT/regions/$REGION/resourcePolicies/multiwriter-disk-const-grp \ --zone=$REGION-c gcloud compute disks stop-group-async-replication projects/$PROJECT/regions/$REGION/resourcePolicies/witness-disk-const-grp \ --zone=$REGION-c
Pare as VMs de origem na região principal.
gcloud compute instances stop node-1 \ --zone=$REGION-a gcloud compute instances stop node-2 \ --zone=$REGION-b gcloud compute instances stop witness \ --zone=$REGION-c
Renomeie as VMs atuais para evitar nomes duplicados no projeto.
gcloud compute instances set-name witness \ --new-name=witness-old \ --zone=$REGION-c gcloud compute instances set-name node-1 \ --new-name=node-1-old \ --zone=$REGION-a gcloud compute instances set-name node-2 \ --new-name=node-2-old \ --zone=$REGION-b
Crie VMs na região de DR usando os discos secundários. Essas VMs terão o endereço IP da VM de origem.
NODE1IP=$(gcloud compute instances describe node-1-old --zone $REGION-a --format=value\(networkInterfaces[0].networkIP\)) NODE2IP=$(gcloud compute instances describe node-2-old --zone $REGION-b --format=value\(networkInterfaces[0].networkIP\)) WITNESSIP=$(gcloud compute instances describe witness-old --zone $REGION-c --format=value\(networkInterfaces[0].networkIP\)) gcloud compute instances create node-1 \ --zone=$DR_REGION-a \ --machine-type $MACHINE_TYPE \ --network=$DRVPC_NAME \ --subnet=$DRSUBNET_NAME \ --private-network-ip $NODE1IP\ --disk=boot=yes,device-name=node-1-replica,mode=rw,name=node-1-replica \ --disk=boot=no,device-name=mw-datadisk-1-replica,mode=rw,name=mw-datadisk-1-replica,scope=regional gcloud compute instances create witness \ --zone=$DR_REGION-c \ --machine-type=n2-standard-2 \ --network=$DRVPC_NAME \ --subnet=$DRSUBNET_NAME \ --private-network-ip $WITNESSIP \ --disk=boot=yes,device-name=witness-replica,mode=rw,name=witness-replica gcloud compute instances create node-2 \ --zone=$DR_REGION-b \ --machine-type $MACHINE_TYPE \ --network=$DRVPC_NAME \ --subnet=$DRSUBNET_NAME \ --private-network-ip $NODE2IP\ --disk=boot=yes,device-name=node-2-replica,mode=rw,name=node-2-replica \ --disk=boot=no,device-name=mw-datadisk-1-replica,mode=rw,name=mw-datadisk-1-replica,scope=regional
Você simulou uma interrupção e fez failover para a região de DR. Agora você pode testar se a instância secundária está funcionando corretamente.
Verifique a conectividade do SQL Server
Depois de criar as VMs, verifique se os bancos de dados foram recuperados com êxito e se o servidor está funcionando conforme o esperado. Para testar o banco de dados, execute uma consulta do banco de dados recuperado.
- Conecte-se à VM do SQL Server usando a Área de trabalho remota.
- Abra o SQL Server Management Studio.
- Na caixa de diálogo Conectar-se ao servidor, verifique se o nome do servidor está definido para
node-1e selecione Conectar. No menu de arquivos, selecione Arquivo > Novo > Consulta com a conexão atual.
USE [bookshelf]; SELECT * FROM Books;