이 튜토리얼에서는 두 Google Cloud 리전 간에 재해 복구(DR) 솔루션으로 Hyperdisk Balanced 비동기 복제를 사용 설정하는 방법과 재해 발생 시 DR 인스턴스를 가져오는 방법을 설명합니다.
Microsoft SQL Server 장애 조치 클러스터 인스턴스(FCI)는 여러 Windows Server 장애 조치 클러스터(WSFC) 노드에 배포되는 단일 고가용성 SQL Server 인스턴스입니다. 언제든지 클러스터 노드 중 하나가 SQL 인스턴스를 적극적으로 호스팅합니다. 영역 서비스 중단 또는 VM 문제가 발생하면 WSFC는 인스턴스 리소스의 소유권을 클러스터 내 다른 노드로 자동 전송하여 클라이언트가 다시 연결할 수 있도록 합니다. SQL Server FCI는 모든 WSFC 노드에서 액세스할 수 있도록 데이터를 공유 디스크에 저장해야 합니다.
SQL Server 배포가 리전 서비스 중단을 견딜 수 있도록 하려면 비동기 복제를 사용 설정하여 기본 리전의 디스크 데이터를 보조 리전으로 복제합니다. 이 튜토리얼에서는 Hyperdisk Balanced High Availability 멀티 작성자 디스크를 사용하여 두 Google Cloud 리전 간에 SQL Server FCI의 재해 복구(DR) 솔루션으로 비동기 복제를 사용 설정하고 재해 발생 시 DR 인스턴스를 가져오는 방법을 설명합니다. 이 문서에서 재해는 자연 재해로 인해 클러스터의 리전을 사용할 수 없게 되어 기본 데이터베이스 클러스터에 장애가 발생하거나 사용할 수 없는 상태를 의미합니다.
이 튜토리얼은 데이터베이스 설계자, 관리자, 엔지니어를 대상으로 합니다.
목표
- Google Cloud에서 실행되는 모든 SQL Server FCI 클러스터 노드에 Hyperdisk 비동기 복제를 사용 설정합니다.
- 재해 이벤트를 시뮬레이션하고 전체 DR 프로세스를 수행하여 DR 구성을 검사합니다.
비용
이 문서에서는 비용이 청구될 수 있는 Google Cloud구성요소( )를 사용합니다.
프로젝트 사용량을 기준으로 예상 비용을 산출하려면 가격 계산기를 사용합니다.
이 문서에 설명된 태스크를 완료했으면 만든 리소스를 삭제하여 청구가 계속되는 것을 방지할 수 있습니다. 자세한 내용은 삭제를 참조하세요.
시작하기 전에
이 튜토리얼을 진행하려면 Google Cloud 프로젝트가 필요합니다. 새 프로젝트를 만들거나 기존에 만든 프로젝트를 선택할 수 있습니다.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, activate Cloud Shell.
이 Hyperdisk Balanced High Availability 멀티 작성자 모드로 SQL Server FCI 클러스터 구성 가이드의 단계를 수행하여 기본 리전에 SQL Server 클러스터를 설정합니다. 클러스터를 설정한 후 이 튜토리얼로 돌아가 보조 리전에서 DR을 사용 설정합니다.
백업 및 복원을 수행하기 위해 Google Cloud 프로젝트와 SQL Server 모두에 적절한 권한이 있어야 합니다.
- Microsoft SQL Server의 두 인스턴스인 기본 인스턴스와 보조 인스턴스는 FCI 클러스터의 일부이며 기본 리전(R1)에 배치되지만 영역은 서로 다릅니다(A 및 B 영역). 두 인스턴스는 Hyperdisk Balanced High Availability 디스크를 공유하므로 두 VM 모두에서 데이터에 액세스할 수 있습니다. 자세한 내용은 Hyperdisk Balanced High Availability 멀티 작성자 모드로 SQL Server FCI 클러스터 구성을 참조하세요.
- 두 SQL 노드의 디스크가 일관성 그룹에 추가되고 DR 리전(R2)에 복제됩니다. Compute Engine은 R1에서 R2로 데이터를 비동기식으로 복제합니다.
- 비동기 복제는 디스크의 데이터만 R2에 복제하고 VM 메타데이터는 복제하지 않습니다. DR 중에 새 VM이 생성되고 노드를 온라인으로 전환하기 위해 기존에 복제된 디스크가 VM에 연결됩니다.
- 기본 데이터베이스 인스턴스를 실행하는 첫 번째 리전(R1)이 사용할 수 없는 상태가 됩니다.
- 운영팀이 재해 상태를 인식하고, 공식적으로 재해를 인정하고, 장애 조치가 필요한지 여부를 결정합니다.
- 장애 조치가 필요한 경우 기본 디스크와 보조 디스크 간의 복제를 종료해야 합니다. 디스크 복제본에서 새 VM이 생성되고 온라인으로 전환됩니다.
- DR 리전(R2)의 데이터베이스가 검증되고 온라인으로 전환됩니다. R2의 데이터베이스가 연결을 지원하는 새 기본 데이터베이스가 됩니다.
- 사용자가 새로운 기본 데이터베이스에서 처리를 재개하고 R2의 기본 인스턴스에 액세스합니다.
- SQL Server 2016 Enterprise 및 Standard 버전
- SQL Server 2017 Enterprise 및 Standard 버전
- SQL Server 2019 Enterprise 및 Standard 버전
- SQL Server 2022 Enterprise 및 Standard 버전
SQL Server 노드와 감시 및 도메인 컨트롤러 역할을 호스팅하는 노드 모두에 대한 일관성 그룹을 만듭니다. 일관성 그룹의 제한사항 중 하나는 여러 영역에 걸쳐 있을 수 없다는 것입니다. 따라서 각 노드를 별도의 일관성 그룹에 추가해야 합니다.
gcloud compute resource-policies create disk-consistency-group node-1-disk-const-grp \ --region=$REGION gcloud compute resource-policies create disk-consistency-group node-2-disk-const-grp \ --region=$REGION gcloud compute resource-policies create disk-consistency-group witness-disk-const-grp \ --region=$REGION gcloud compute resource-policies create disk-consistency-group multiwriter-disk-const-grp \ --region=$REGION
기본 및 대기 VM의 디스크를 해당 일관성 그룹에 추가합니다.
gcloud compute disks add-resource-policies node-1 \ --zone=$REGION-a \ --resource-policies=node-1-disk-const-grp gcloud compute disks add-resource-policies node-2 \ --zone=$REGION-b \ --resource-policies=node-2-disk-const-grp gcloud compute disks add-resource-policies mw-datadisk-1 \ --region=$REGION \ --resource-policies=multiwriter-disk-const-grp gcloud compute disks add-resource-policies witness \ --zone=$REGION-c \ --resource-policies=witness-disk-const-grp
보조 리전에 빈 보조 디스크를 만듭니다.
DR_REGION="us-west1" gcloud compute disks create node-1-replica \ --zone=$DR_REGION-a \ --size=50 \ --primary-disk=node-1 \ --primary-disk-zone=$REGION-a gcloud compute disks create node-2-replica \ --zone=$DR_REGION-b \ --size=50 \ --primary-disk=node-2 \ --primary-disk-zone=$REGION-b gcloud compute disks create multiwriter-datadisk-1-replica \ --replica-zones=$DR_REGION-a,$DR_REGION-b \ --size=$PD_SIZE \ --type=hyperdisk-balanced-high-availability \ --access-mode READ_WRITE_MANY \ --primary-disk=multiwriter-datadisk-1 \ --primary-disk-region=$REGION gcloud compute disks create witness-replica \ --zone=$DR_REGION-c \ --size=50 \ --primary-disk=witness \ --primary-disk-zone=$REGION-c
디스크 복제를 시작합니다. 데이터가 기본 디스크에서 DR 리전의 새로 생성된 빈 디스크로 복제됩니다.
gcloud compute disks start-async-replication node-1 \ --zone=$REGION-a \ --secondary-disk=node-1-replica \ --secondary-disk-zone=$DR_REGION-a gcloud compute disks start-async-replication node-2 \ --zone=$REGION-b \ --secondary-disk=node-2-replica \ --secondary-disk-zone=$DR_REGION-b gcloud compute disks start-async-replication multiwriter-datadisk-1 \ --region=$REGION \ --secondary-disk=multiwriter-datadisk-1-replica \ --secondary-disk-region=$DR_REGION gcloud compute disks start-async-replication witness \ --zone=$REGION-c \ --secondary-disk=witness-replica \ --secondary-disk-zone=$DR_REGION-c
복구 VPC를 만듭니다.
DRVPC_NAME="default-dr" DRSUBNET_NAME="default-recovery" gcloud compute networks create $DRVPC_NAME \ --subnet-mode=custom CIDR=$(gcloud compute networks subnets describe default \ --region=$REGION --format=value\(ipCidrRange\)) gcloud compute networks subnets create $DRSUBNET_NAME \ --network=$DRVPC_NAME --range=$CIDR --region=$DR_REGION
데이터 복제를 종료하거나 중지합니다.
PROJECT=$(gcloud config get-value project) gcloud compute disks stop-group-async-replication projects/$PROJECT/regions/$REGION/resourcePolicies/node-1-disk-const-grp \ --zone=$REGION-a gcloud compute disks stop-group-async-replication projects/$PROJECT/regions/$REGION/resourcePolicies/node-2-disk-const-grp \ --zone=$REGION-b gcloud compute disks stop-group-async-replication projects/$PROJECT/regions/$REGION/resourcePolicies/multiwriter-disk-const-grp \ --zone=$REGION-c gcloud compute disks stop-group-async-replication projects/$PROJECT/regions/$REGION/resourcePolicies/witness-disk-const-grp \ --zone=$REGION-c
기본 리전에서 소스 VM을 중지합니다.
gcloud compute instances stop node-1 \ --zone=$REGION-a gcloud compute instances stop node-2 \ --zone=$REGION-b gcloud compute instances stop witness \ --zone=$REGION-c
프로젝트에서 이름이 중복되지 않도록 기존 VM의 이름을 바꿉니다.
gcloud compute instances set-name witness \ --new-name=witness-old \ --zone=$REGION-c gcloud compute instances set-name node-1 \ --new-name=node-1-old \ --zone=$REGION-a gcloud compute instances set-name node-2 \ --new-name=node-2-old \ --zone=$REGION-b
보조 디스크를 사용하여 DR 리전에 VM을 만듭니다. 이러한 VM에는 소스 VM의 IP 주소가 있습니다.
NODE1IP=$(gcloud compute instances describe node-1-old --zone $REGION-a --format=value\(networkInterfaces[0].networkIP\)) NODE2IP=$(gcloud compute instances describe node-2-old --zone $REGION-b --format=value\(networkInterfaces[0].networkIP\)) WITNESSIP=$(gcloud compute instances describe witness-old --zone $REGION-c --format=value\(networkInterfaces[0].networkIP\)) gcloud compute instances create node-1 \ --zone=$DR_REGION-a \ --machine-type $MACHINE_TYPE \ --network=$DRVPC_NAME \ --subnet=$DRSUBNET_NAME \ --private-network-ip $NODE1IP\ --disk=boot=yes,device-name=node-1-replica,mode=rw,name=node-1-replica \ --disk=boot=no,device-name=mw-datadisk-1-replica,mode=rw,name=mw-datadisk-1-replica,scope=regional gcloud compute instances create witness \ --zone=$DR_REGION-c \ --machine-type=n2-standard-2 \ --network=$DRVPC_NAME \ --subnet=$DRSUBNET_NAME \ --private-network-ip $WITNESSIP \ --disk=boot=yes,device-name=witness-replica,mode=rw,name=witness-replica gcloud compute instances create node-2 \ --zone=$DR_REGION-b \ --machine-type $MACHINE_TYPE \ --network=$DRVPC_NAME \ --subnet=$DRSUBNET_NAME \ --private-network-ip $NODE2IP\ --disk=boot=yes,device-name=node-2-replica,mode=rw,name=node-2-replica \ --disk=boot=no,device-name=mw-datadisk-1-replica,mode=rw,name=mw-datadisk-1-replica,scope=regional
- 원격 데스크톱을 사용하여 SQL Server VM에 연결합니다.
- SQL Server 관리 스튜디오를 엽니다.
- 서버에 연결 대화상자에서 서버 이름이
node-1로 설정되어 있는지 확인하고 연결을 선택합니다. 파일 메뉴에서 현재 연결로 File > New > Query를 선택합니다.
USE [bookshelf]; SELECT * FROM Books;
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
- Google Cloud에 대한 참조 아키텍처, 다이어그램, 권장사항 살펴보기. Cloud 아키텍처 센터 살펴보기
Google Cloud의 재해 복구
Google Cloud 의 DR은 리전이 실패하거나 액세스할 수 없게 될 때 데이터에 대한 지속적인 액세스를 유지하는 것을 의미합니다. DR 사이트에는 여러 배포 옵션이 있으며 목표 복구 시간(RPO) 및 복구 시간 목표(RTO) 요구사항에 따라 결정됩니다. 이 튜토리얼에서는 가상 머신에 연결된 디스크가 기본 리전에서 DR 리전으로 복제되는 옵션 중 하나를 설명합니다.
Hyperdisk 비동기 복제를 사용한 재해 복구
Hyperdisk 비동기 복제는 두 리전 간의 디스크 복제를 위한 비동기 스토리지 사본을 제공하는 스토리지 옵션입니다. 드물게 발생하는 리전 중단의 경우에도 Hyperdisk 비동기 복제를 사용하면 데이터를 보조 리전으로 장애 조치하고 이 리전에서 워크로드를 다시 시작할 수 있습니다.
Hyperdisk 비동기 복제는 실행 중인 워크로드에 연결된 디스크(기본 디스크라고 함)의 데이터를 다른 리전에 있는 별도의 디스크에 복제합니다. 복제된 데이터를 수신하는 디스크를 보조 디스크라고 합니다. 기본 디스크가 실행되는 리전을 기본 리전이라고 하고 보조 디스크가 실행되는 리전을 보조 리전이라고 합니다. 각 SQL Server 노드에 연결된 모든 디스크의 복제본에 동일한 시점의 데이터가 포함되도록 하려면 디스크를 일관성 그룹에 추가합니다. 일관성 그룹을 사용하면 여러 디스크 간에 DR 및 DR 테스트를 수행할 수 있습니다.
재해 복구 아키텍처
Hyperdisk 비동기 복제의 경우 다음 다이어그램은 기본 리전(R1)의 데이터베이스 HA를 지원하고 기본 리전에서 보조 리전(R2)으로의 디스크 복제를 지원하는 최소 아키텍처를 보여줍니다.
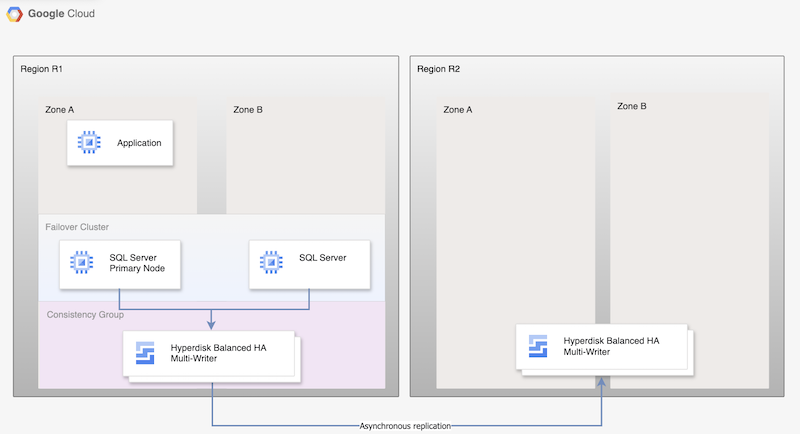
그림 1. Microsoft SQL Server 및 Hyperdisk 비동기 복제를 사용한 재해 복구 아키텍처
이 아키텍처의 동작은 다음과 같습니다.
재해 복구 프로세스
DR 프로세스에는 리전을 사용할 수 없게 된 후 다른 리전에서 워크로드를 재개하기 위해 취해야 하는 작업 단계가 기술됩니다.
기본 데이터베이스 DR 프로세스는 다음 단계들로 구성됩니다.
이러한 기본 프로세스는 작동하는 기본 데이터베이스를 다시 설정하지만, 새 기본 데이터베이스가 복제되지 않으므로 전체 HA 아키텍처를 설정하지 않습니다.
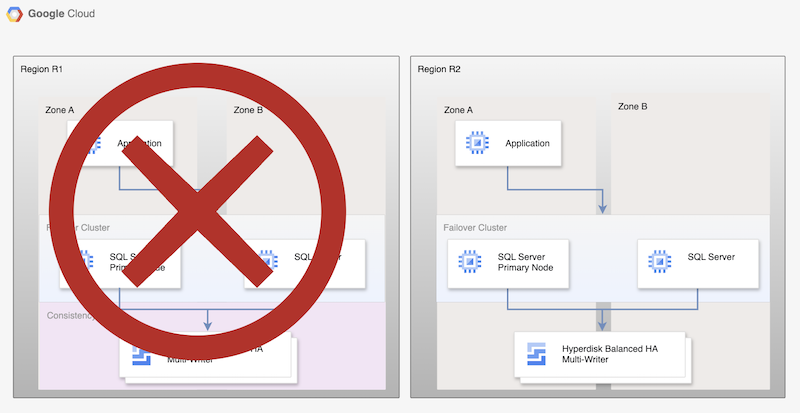
그림 2. Persistent Disk 비동기 복제를 사용한 재해 복구 후 SQL Server 배포
복구된 리전으로 대체
기본 리전(R1)이 온라인으로 전환되면 장애 복구 프로세스를 계획하고 실행할 수 있습니다. 장애 복구 프로세스는 이 튜토리얼에 설명된 모든 단계로 구성되지만 이 경우 R2가 소스이고 R1이 복구 리전입니다.
SQL Server 버전 선택
이 가이드에서 지원되는 Microsoft SQL Server 버전은 다음과 같습니다.
이 튜토리얼에서는 Hyperdisk Balanced High Availability 디스크가 있는 SQL Server 장애 조치 클러스터 인스턴스를 사용합니다.
SQL Server Enterprise 기능이 필요하지 않은 경우 SQL Server의 Standard 버전을 사용할 수 있습니다.
SQL Server의 2016, 2017, 2019, 2022 버전에서는 Microsoft SQL Server Management Studio가 이미지에 설치되어 있습니다. 따라서 이를 별도로 설치할 필요가 없습니다. 하지만 프로덕션 환경에서는 Microsoft SQL Server Management Studio의 한 인스턴스를 각 리전의 개별 VM에 설치하는 것이 좋습니다. HA 환경을 설정할 때는 한 영역을 사용할 수 없을 때 다른 영역을 사용할 수 있도록 각 영역에 대해 한 번씩 Microsoft SQL Server Management Studio를 설치해야 합니다.
Microsoft SQL Server 재해 복구 설정
이 튜토리얼에서는 Microsoft SQL Server Enterprise용
sql-ent-2022-win-2022이미지를 사용합니다.전체 이미지 목록은 OS 이미지를 참조하세요.
2인스턴스 고가용성 클러스터 설정
두 리전 간에 SQL Server의 디스크 복제를 설정하려면 먼저 리전에 2인스턴스 HA 클러스터를 만듭니다. 한 인스턴스는 기본 인스턴스로, 다른 인스턴스는 대기 인스턴스로 사용됩니다. 이 단계를 수행하려면 Hyperdisk Balanced High Availability 멀티 작성자 모드로 SQL Server FCI 클러스터 구성의 안내를 수행합니다. 이 튜토리얼에서는 기본 리전 R1에
us-central1이 사용됩니다. Hyperdisk Balanced High Availability 멀티 작성자 모드로 SQL Server FCI 클러스터 구성의 단계를 수행했으면 같은 리전(us-central1)에 SQL Server 인스턴스 2개가 생성됩니다.us-central1-a에 기본 SQL Server 인스턴스(node-1)를 배포하고us-central1-b에 대기 인스턴스(node-2)를 배포합니다.디스크 비동기 복제 사용 설정
모든 VM을 만들고 구성한 후 다음 단계를 완료하여 두 리전 간에 디스크 복제를 사용 설정합니다.
이 시점에서 데이터가 리전 간에 복제되고 있어야 합니다. 각 디스크의 복제 상태는
Active로 표시됩니다.재해 복구 시뮬레이션
이 섹션에서는 이 튜토리얼에서 설정한 재해 복구 아키텍처를 테스트합니다.
서비스 중단 시뮬레이션 및 재해 복구 장애 조치 실행
장애 조치 중에 DR 리전에 새 VM을 만들고 복제된 디스크를 VM에 연결합니다. 장애 조치를 단순화하기 위해서는 동일한 IP 주소를 사용하기 위해 복구용으로 DR 리전에서 다른 가상 프라이빗 클라우드(VPC)를 사용할 수 있습니다.
장애 조치를 시작하기 전에
node-1이 생성한 AlwaysOn 가용성 그룹의 기본 노드인지 확인합니다. 두 노드가 두 개의 별도 일관성 그룹으로 보호되므로 데이터 동기화 문제를 방지하려면 도메인 컨트롤러와 기본 SQL Server 노드를 가져옵니다. 서비스 중단을 시뮬레이션하려면 다음 단계를 따르세요.서비스 중단을 시뮬레이션하고 DR 리전으로 장애 조치했습니다. 이제 보조 인스턴스가 올바르게 작동하는지 테스트할 수 있습니다.
SQL Server 연결 확인
VM을 만든 후 데이터베이스가 복구되었는지, 서버가 예상대로 작동하는지 확인합니다. 데이터베이스를 테스트하려면 복구된 데이터베이스에서 쿼리를 실행합니다.
삭제
이 튜토리얼에서 사용한 리소스의 비용이 Google Cloud 계정에 청구되지 않도록 하려면 이 섹션의 단계에 따라 만든 리소스를 삭제합니다.
프로젝트 삭제
다음 단계
-